
Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks


Abstract
1. Introduction
2. Related Work
3. Process of Text Document Clustering
3.1. Text Document Preprocessing
- Tokenization: Tokenization is a process that splits a stream of text documents into words or terms and removes empty sequences. Here, each word or symbol is taken from the first character to the last character, where each word is called a token [28]. However, sometimes defining a “word” is difficult. A tokenizer often depends on simple heuristics such as [29]:
- -
- the resulting list of tokens may or may not include punctuation and white space;
- -
- tokens are separated by white space characters such as spaces, line breaks, or punctuation characters.
- Stop word removal: Stop words such as an, are, for, be, and other common words are more frequent and short functional words also take small weighting. These words should be removed from the document to increase the performance of text document clustering. The list of stop words is available at http://members.unine.ch/jacques.savoy/clef/index.html (accessed on 22 April 2021) and includes 571 words [28].
- Stemming: Stemming is the process of reducing inflectional words to the same root by removing the affixes (prefixes and suffixes) of each word. For example [26,29]:
- -
- section, dissect, and intersect all have a common origin or source Sect called the feature;
- -
- if the word ends with ed or ing or ly, we remove the ed or ing or ly, respectively.
- Term weighting: The term weighting is assigned for each term or feature by considering the frequency of each term in the document. The term frequency-inverse document frequency (TF-IDF) is widely used in weighting methods. Each document is represented as a vector of term weights as shown in Equation (1) [28].
3.2. General Process of SI Algorithms in Text Document Clustering
3.3. Clustering Evaluation Metrics
3.3.1. Purity
3.3.2. Homogeneity, Completeness, and V-Measure
3.3.3. ARI
4. Algorithms for Text Document Clustering
4.1. K-Means Clustering Algorithm
| Algorithm 1:K-means Document Clustering Algorithm |
Step 1. Randomly select K points as the initial cluster centers. Step 2. Assign all points (documents) to the closest centroid. Step 3. Recalculate the centroid of each cluster. Step 4. Repeat steps 2 and 3 until termination condition is reached. |
4.2. SI Algorithms for Document Clustering
4.2.1. PSO Algorithm
| Algorithm 2: PSO document clustering algorithm |
 |
4.2.2. BA Algorithm
| Algorithm 3: BA document clustering algorithm |
 |
4.2.3. GWO Algorithm
| Algorithm 4: GWO document clustering algorithm |
 |
4.2.4. Parameter Set of SI Algorithms
4.2.5. Features of SI Algorithms
5. Experiment
5.1. Benchmark Data Sets
5.2. Experimental Conditions
5.3. Results
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramkumar, A.S.; Nethravathy, R. Text Document Clustering using K-means Algorithm. Int. Res. J. Eng. Technol. 2019, 6, 1164–1168. [Google Scholar]
- Chen, F.; Deng, P.; Wan, J.; Zhang, D.; Vasilakos, A.V.; Rong, X. Data mining for the internet of things: Literature review and challenges. Int. J. Distrib. Sens. Netw. 2015, 11, 431047. [Google Scholar] [CrossRef]
- Singh, V.K.; Tiwari, N.; Garg, S. Document Clustering Using K-Means, Heuristic K-Means and Fuzzy C-Means. In Proceedings of the 2011 International Conference on Computational Intelligence and Communication Networks, Gwalior, India, 7–9 October 2011; pp. 297–301. [Google Scholar] [CrossRef]
- Jensi, R.; Wiselin, J. A Survey on Optimization Approaches to Text Document Clustering. Int. J. Comput. Sci. Appl. 2013, 3, 31–44. [Google Scholar] [CrossRef]
- Hamerly, G.; Drake, J. Accelerating Lloyd’s Algorithm for k-Means Clustering. In Partitional Clustering Algorithms; Celebi, M.E., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 41–78. [Google Scholar] [CrossRef]
- Hassanien, A.E. Swarm Intelligence: Principles, Advances, and Applications/Aboul Ella Hassanien, Eid Emary; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Selvaraj, S.; Choi, E. Survey of Swarm Intelligence Algorithms. In ICSIM ’20: Proceedings of the 3rd International Conference on Software Engineering and Information Management; Association for Computing Machinery: New York, NY, USA, 2020; pp. 69–73. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef]
- BBC News Datasets. Available online: http://mlg.ucd.ie/datasets/bbc.html (accessed on 22 April 2021).
- 20 Newsgroups. Available online: https://kdd.ics.uci.edu/databases/20newsgroups/20newsgroups.html (accessed on 22 April 2021).
- Shima Sabet, M.S.; Farokhi, F. A comparison between swarm intelligence algorithms for routing problems. Electr. Comput. Eng. Int. J. (ECIJ) 2016, 5, 17–33. [Google Scholar] [CrossRef]
- Basir, M.A.; Ahmad, F. Comparison on Swarm Algorithms for Feature Selections/Reductions. Int. J. Sci. Eng. Res. 2014, 5, 479–486. [Google Scholar]
- Fan, J.; Hu, M.; Chu, X.; Yang, D. A comparison analysis of swarm intelligence algorithms for robot swarm learning. In Proceedings of the 2017 Winter Simulation Conference (WSC), Las Vegas, NV, USA, 3–6 December 2017; pp. 3042–3053. [Google Scholar] [CrossRef]
- Mohana, S.J.; Saroja, M.; Venkatachalam, M. Comparative Analysis of Swarm Intelligence Optimization Techniques for Cloud Scheduling. Int. J. Innov. Sci. Eng. Technol. 2014, 1, 15–19. [Google Scholar]
- Elhady, G.F.; Tawfeek, M.A. A comparative study into swarm intelligence algorithms for dynamic tasks scheduling in cloud computing. In Proceedings of the 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; pp. 362–369. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, Y.; Ma, Z.; Li, X. A Comparative Study of Swarm Intelligence Algorithms for UCAV Path-Planning Problems. Mathematics 2021, 9, 171. [Google Scholar] [CrossRef]
- Gong, X.; Liu, L.; Fong, S.; Xu, Q.; Wen, T.; Liu, Z. Comparative Research of Swarm Intelligence Clustering Algorithms for Analyzing Medical Data. IEEE Access 2019, 7, 137560–137569. [Google Scholar] [CrossRef]
- Figueiredo, E.; Macedo, M.; Siqueira, H.V.; Santana, C.J.; Gokhale, A.; Bastos-Filho, C.J. Swarm intelligence for clustering—A systematic review with new perspectives on data mining. Eng. Appl. Artif. Intell. 2019, 82, 313–329. [Google Scholar] [CrossRef]
- Yeoh, J.M.; Caraffini, F.; Homapour, E.; Santucci, V.; Milani, A. A Clustering System for Dynamic Data Streams Based on Metaheuristic Optimisation. Mathematics 2019, 7, 1229. [Google Scholar] [CrossRef]
- Florez-Lozano, J.M.; Caraffini, F.; Parra, C.; Gongora, M. A Robust Decision-Making Framework Based on Collaborative Agents. IEEE Access 2020, 8, 150974–150988. [Google Scholar] [CrossRef]
- Florez-Lozano, J.; Caraffini, F.; Parra, C.; Gongora, M. Cooperative and distributed decision-making in a multi-agent perception system for improvised land mines detection. Inf. Fusion 2020, 64, 32–49. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, S.; Li, S.; Zhou, C. Text Clustering via Particle Swarm Optimization. In Proceedings of the 2009 IEEE Swarm Intelligence Symposium, Nashville, TN, USA, 30 March–2 April 2009; pp. 45–51. [Google Scholar] [CrossRef]
- Judith, J.; Jayakumari, J. Distributed document clustering analysis based on a hybrid method. China Commun. 2017, 14, 131–142. [Google Scholar] [CrossRef]
- Abualigah, L.; Gandomi, A.H.; Elaziz, M.A.; Hussien, A.G.; Khasawneh, A.M.; Alshinwan, M.; Houssein, E.H. Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis. Algorithms 2020, 13, 345. [Google Scholar] [CrossRef]
- Rashaideh, H.; Sawaie, A.; Al-Betar, M.A.; Abualigah, L.M.; Al-laham, M.M.; Al-Khatib, R.M.; Braik, M. A Grey Wolf Optimizer for Text Document Clustering. J. Intell. Syst. 2020, 29, 814–830. [Google Scholar] [CrossRef]
- Abualigah, L.M. Unsupervised text feature selection technique based on hybrid particle swarm optimization algorithm with genetic operators for the text clustering. J. Supercomput. 2017, 73, 4773–4795. [Google Scholar] [CrossRef]
- Suganya Selvaraj, H.K.; Choi, E. Offline-to-Online Service and Big Data Analysis for End-to-end Freight Management System. J. Inf. Process. Syst. 2020, 16, 377–393. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Sailaja, D.; Kishore, M.; Jyothi, B.; Prasad, N. An Overview of Pre-Processing Text Clustering Methods. Int. J. Comput. Sci. Inform. Technol. 2015, 6, 3119–3124. [Google Scholar]
- Tan, Y. Chapter 1—Introduction. In Gpu-Based Parallel Implementation of Swarm Intelligence Algorithms; Tan, Y., Ed.; Morgan Kaufmann: San Fransisco, CA, USA, 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Karol, S.; Mangat, V. Evaluation of text document clustering approach based on particle swarm optimization. Open Comput. Sci. 2013, 3, 69–90. [Google Scholar] [CrossRef]
- Purity Metric. Available online: http://www.cse.chalmers.se/~richajo/dit862/L13/Text%20clustering.html (accessed on 22 April 2021).
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In EMNLP-CoNLL ’12: Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 410–420. [Google Scholar]
- Sklearn Metrics. Available online: https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics (accessed on 22 April 2021).
- Steinley, D. Properties of the Hubert-Arable Adjusted Rand Index. Psychol. Methods 2004, 9, 386–396. [Google Scholar] [CrossRef] [PubMed]
- Cui, X.; Potok, T.E.; Palathingal, P. Document clustering using particle swarm optimization. In Proceedings of the 2005 IEEE Swarm Intelligence Symposium, SIS 2005, Pasadena, CA, USA, 8–10 June 2005; pp. 185–191. [Google Scholar] [CrossRef]
- PSO Code. Available online: https://github.com/dandynaufaldi/particle-swarm-optimized-clustering (accessed on 22 April 2021).
- Wang, G.; Chang, B.; Zhang, Z. A multi-swarm bat algorithm for global optimization. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 480–485. [Google Scholar] [CrossRef]
- BA Code. Available online: https://github.com/herukurniawan/bat-algorithm/blob/master/BatAlgorithm.py (accessed on 22 April 2021).
- GWO Code 1. Available online: https://github.com/7ossam81/EvoloPy (accessed on 22 April 2021).
- GWO Code 2. Available online: https://github.com/czeslavo/gwo/blob/master/optimization/grey_wolf_optimizer.cpp (accessed on 22 April 2021).
- PySwarms. Available online: https://pyswarms.readthedocs.io/en/latest/api/pyswarms.single.html (accessed on 22 April 2021).
- Li, M.; Du, W.; Nian, F. An Adaptive Particle Swarm Optimization Algorithm Based on Directed Weighted Complex Network. Math. Probl. Eng. 2014, 2014, 434972. [Google Scholar] [CrossRef]
- Hameed, I.A.; Bye, R.T.; Osen, O.L. Grey wolf optimizer (GWO) for automated offshore crane design. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, X.; He, X. Bat algorithm: Literature review and applications. arXiv 2013, arXiv:1308.3900. [Google Scholar]
- Mechelen, I.; Boulesteix, A.; Dangl, R.; Dean, N.; Guyon, I.; Hennig, C.; Leisch, F.; Steinley, D. Benchmarking in cluster analysis: A white paper. arXiv 2018, arXiv:1809.10496. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSO | Values | BA | Values | BA | Values |
|---|---|---|---|---|---|
| k | 10 | k | 10 | k | 10 |
| 0.9 | A | 0.5 | |||
| C1 | 0.5 | r | 0.5 | ||
| C2 | 0.3 | Qmin | 0.0 | ||
| Qmax | 2.0 |
| Algorithms | Parameters | Features | Best Performing Area |
|---|---|---|---|
| PSO | Control: , , and ; Local Search: , and are drawn from uniform distribution . | Simple, fast computing speed, and parallel processing [43]. | Clustering and scheduling [14,17,18]. |
| GWO | Control: and C; Local Search: , and are random vectors . | Faster convergence due to continuous reduction of search space and fewer decision variables (i.e., , , and ; avoiding local minima; better stability and robustness [44]. | Robot swarm learning [13]. |
| BA | Control: loudness (A), pulse rate (r), pulse rate adaptation (), loudness decrements (), local search radius, and frequency band parameters (Q); Local Search: is random vector uniform distribution , is random walk normal distribution . | Provides very quick convergence at a very initial stage by switching from exploration to exploitation [45]. | Clustering and feature selection [6,17]. |
| Data Set | Source | No. of Documents | No. of Terms | No. of Clusters |
|---|---|---|---|---|
| 1 | 20 newsgroups | 1427 | 23,057 | 2 |
| 2 | BBC Sport | 737 | 4613 | 5 |
| 3 | BBC Sport | 40 | 2596 | 5 |
| 4 | 20 newsgroups | 200 | 8716 | 4 |
| 5 | 20 newsgroups | 100 | 5549 | 3 |
| 6 | BBC Sport | 100 | 3876 | 2 |
| Data Sets | Metrics | K-Means | PSO | GWO | BA | |
|---|---|---|---|---|---|---|
| Mean (Std.) | ||||||
| 1 | Purity | 0.665 (0.04) | 0.724 (0.028) | 0.695 (0.018) | 0.636 (0.02) | |
| Homogeneity | 0.081 (0.041) | 0.149 (0.036) | 0.108 (0.023) | 0.052 (0.014) | ||
| Completeness | 0.085 (0.39) | 0.153 (0.039) | 0.112 (0.023) | 0.057 (0.016) | ||
| V-measure | 0.083 (0.04) | 0.151 (0.037) | 0.110 (0.023) | 0.054 (0.014) | ||
| ARI | 0.112 (0.057) | 0.203 (0.045) | 0.156 (0.029) | 0.0732 (0.019) | ||
| Rank | 3 | 1 | 2 | 4 | ||
| 2 | Purity | 0.929 (0.066) | 0.775 (0.042) | 0.74 (0.02) | 0.692 (0.034) | |
| Homogeneity | 0.833 (0.097) | 0.525 (0.067) | 0.468 (0.041) | 0.408 (0.058) | ||
| Completeness | 0.854 (0.076) | 0.527 (0.068) | 0.472 (0.05)) | 0.413 (0.059) | ||
| V-measure | 0.843 (0.088) | 0.525 (0.066) | 0.470 (0.045) | 0.410 (0.058) | ||
| ARI | 0.832 (0.118) | 0.536 (0.089) | 0.462 (0.051) | 0.393 (0.0665) | ||
| Rank | 1 | 2 | 3 | 4 | ||
| 3 | Purity | 0.734 (0.049) | 0.873 (0.025) | 0.839 (0.025) | 0.786 (0.027) | |
| Homogeneity | 0.591 (0.082) | 0.793 (0.059) | 0.733 (0.039) | 0.637 (0.046) | ||
| Completeness | 0.605 (0.082) | 0.797 (0.058) | 0.735 (0.041) | 0.65 (0.046) | ||
| V-measure | 0.598 (0.081) | 0.795 (0.058) | 0.734 (0.04) | 0.643 (0.045) | ||
| ARI | 0.478 (0.087) | 0.727 (0.058) | 0.659 (0.067) | 0.552 (0.07) | ||
| Rank | 3 | 1 | 2 | 4 | ||
| 4 | Purity | 0.592 (0.046) | 0.689 (0.04) | 0.652 (0.027) | 0.607 (0.039) | |
| Homogeneity | 0.271 (0.059) | 0.36 (0.056) | 0.322 (0.033) | 0.284 (0.046) | ||
| Completeness | 0.284 (0.062) | 0.37 (0.058) | 0.336 (0.036) | 0.301 (0.051) | ||
| V-measure | 0.278 (0.06) | 0.365 (0.057) | 0.329 (0.034) | 0.292 (0.048) | ||
| ARI | 0.248 (0.058) | 0.363 (0.057) | 0.318 (0.029) | 0.263 (0.059) | ||
| Rank | 3 | 1 | 2 | 4 | ||
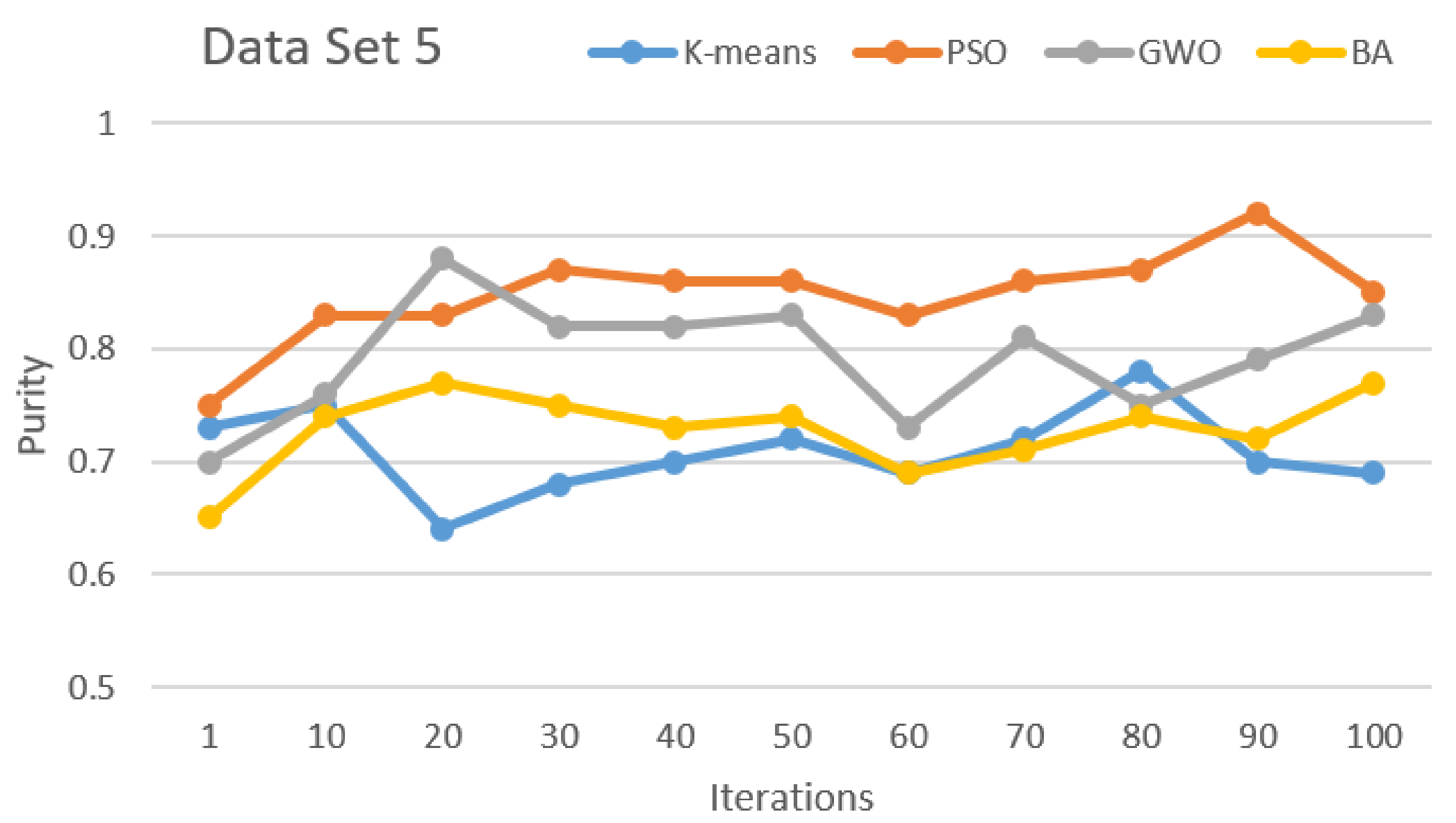
| 5 | Purity | 0.709 (0.036) | 0.848 (0.04) | 0.793 (0.05) | 0.728 (0.034) | |
| Homogeneity | 0.309 (0.052) | 0.541 (0.098) | 0.427 (0.075) | 0.314 (0.049) | ||
| Completeness | 0.323 (0.063) | 0.556 (0.084) | 0.448 (0.082) | 0.347 (0.076) | ||
| V-measure | 0.315 (0.540) | 0.548 (0.091) | 0.437 (0.078) | 0.329 (0.059) | ||
| ARI | 0.321 (0.069) | 0.598 (0.080) | 0.473 (0.117) | 0.344 (0.066) | ||
| Rank | 3 | 1 | 2 | 4 | ||
| 6 | Purity | 0.994 (0.008) | 0.998 (0.006) | 0.995 (0.009) | 0.976 (0.023) | |
| Homogeneity | 0.958 (0.049) | 0.987 (0.041) | 0.45 (0.491) | 0.864 (0.093) | ||
| Completeness | 0.959 (0.048) | 0.987 (0.04) | 0.972 (0.051) | 0.867 (0.089) | ||
| V-measure | 0.958 (0.049) | 0.987 (0.04) | 0.972 (0.051) | 0.866 (0.091) | ||
| ARI | 0.975 (0.031) | 0.992 (0.027) | 0.982 (0.035) | 0.909 (0.085) | ||
| Rank | 3 | 1 | 2 | 4 | ||
| Total rank | 3 | 1 | 2 | 4 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Selvaraj, S.; Choi, E. Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors 2021, 21, 3196. https://doi.org/10.3390/s21093196
Selvaraj S, Choi E. Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors. 2021; 21(9):3196. https://doi.org/10.3390/s21093196
Chicago/Turabian StyleSelvaraj, Suganya, and Eunmi Choi. 2021. "Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks" Sensors 21, no. 9: 3196. https://doi.org/10.3390/s21093196
APA StyleSelvaraj, S., & Choi, E. (2021). Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors, 21(9), 3196. https://doi.org/10.3390/s21093196