
Small Object Detection in Traffic Scenes Based on Attention Feature Fusion


Abstract
1. Introduction
2. Related Works
2.1. Object Detection
2.2. Attention Mechanism
2.3. Feature Fusion
3. Benchmark Model and Proposed Methods
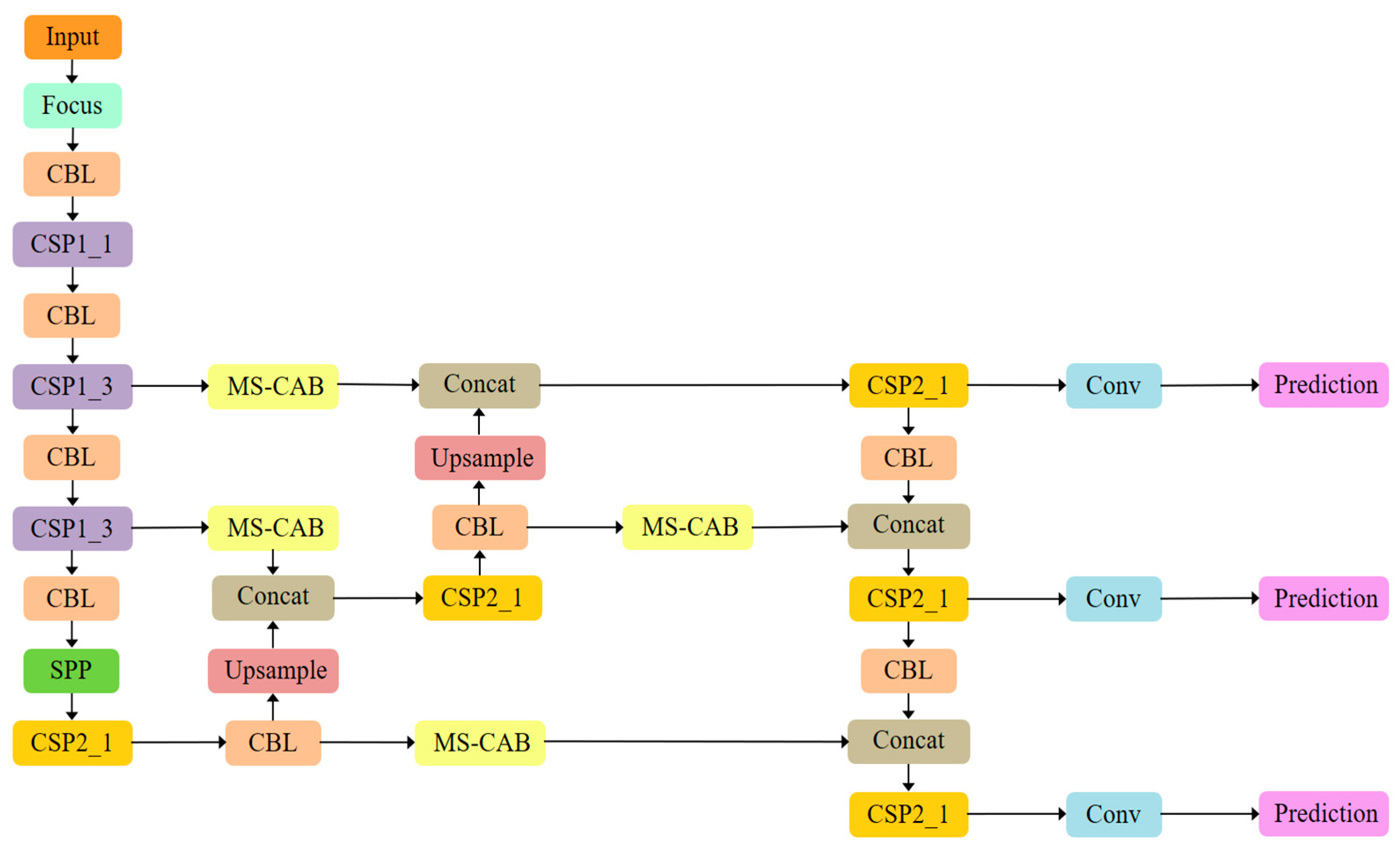
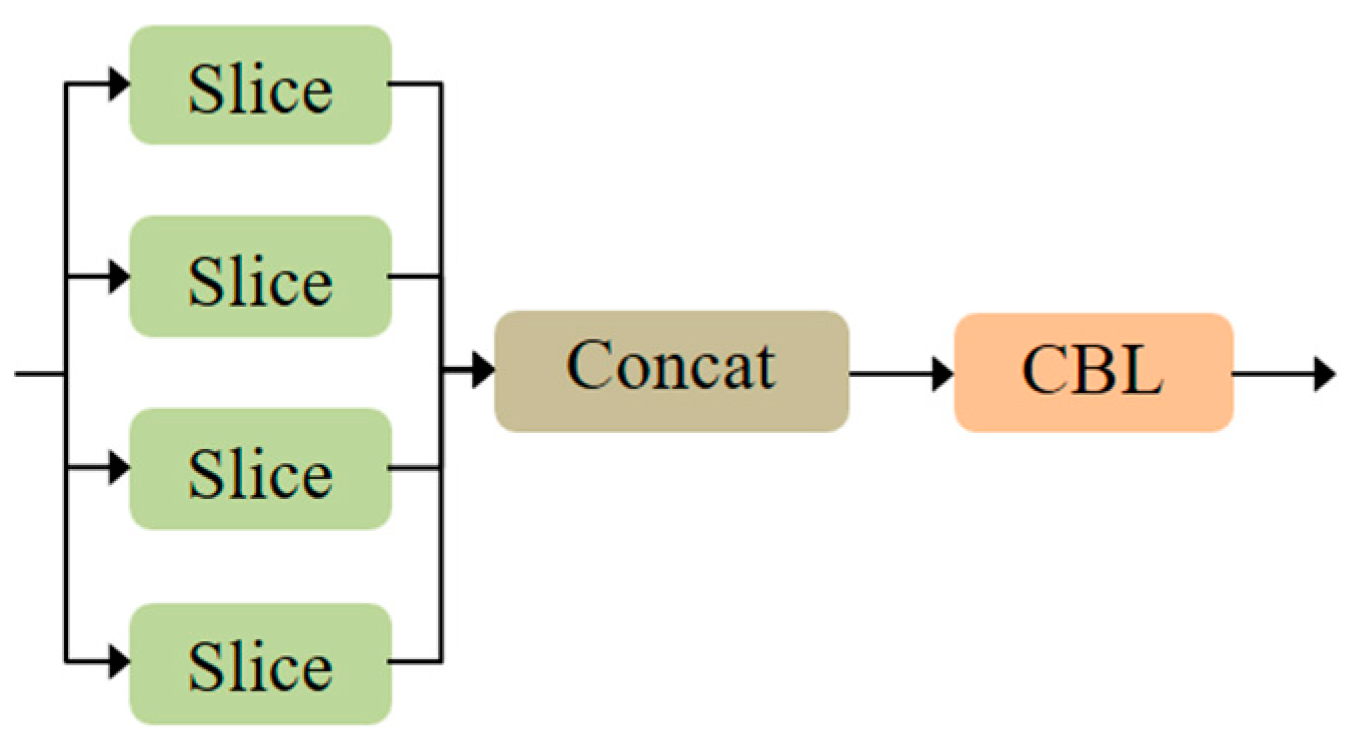
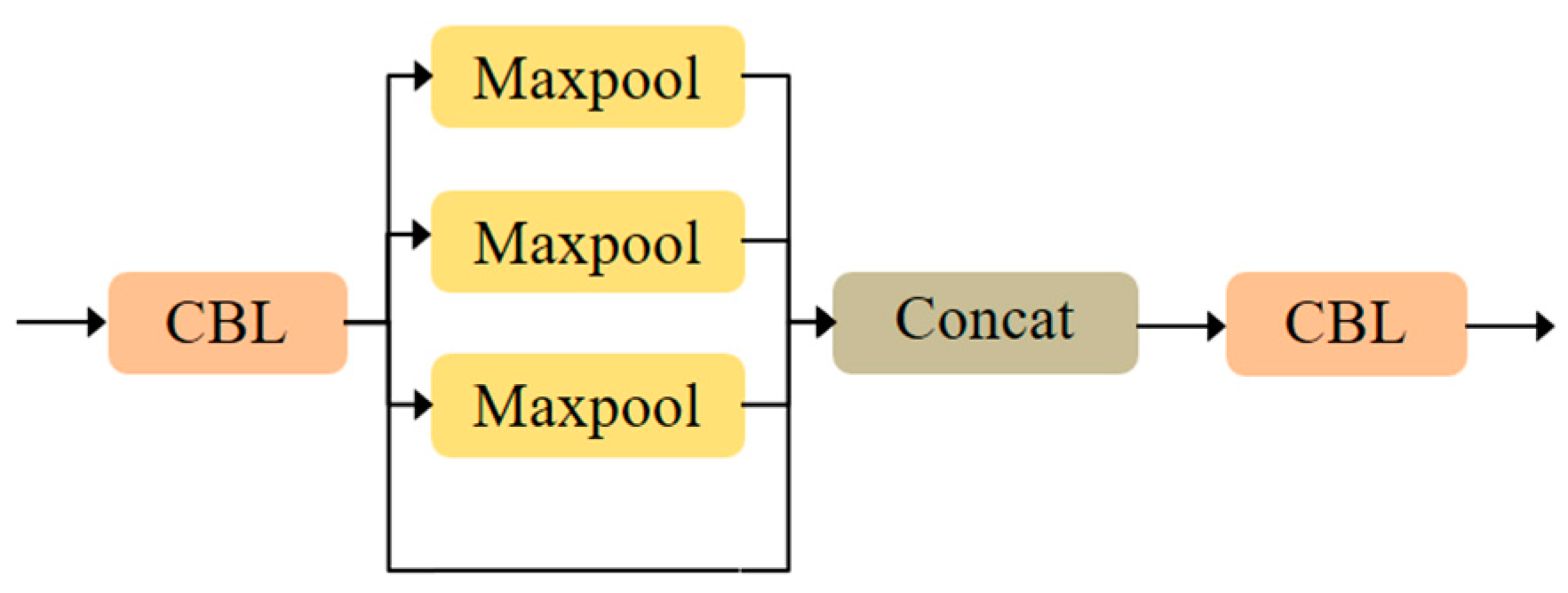
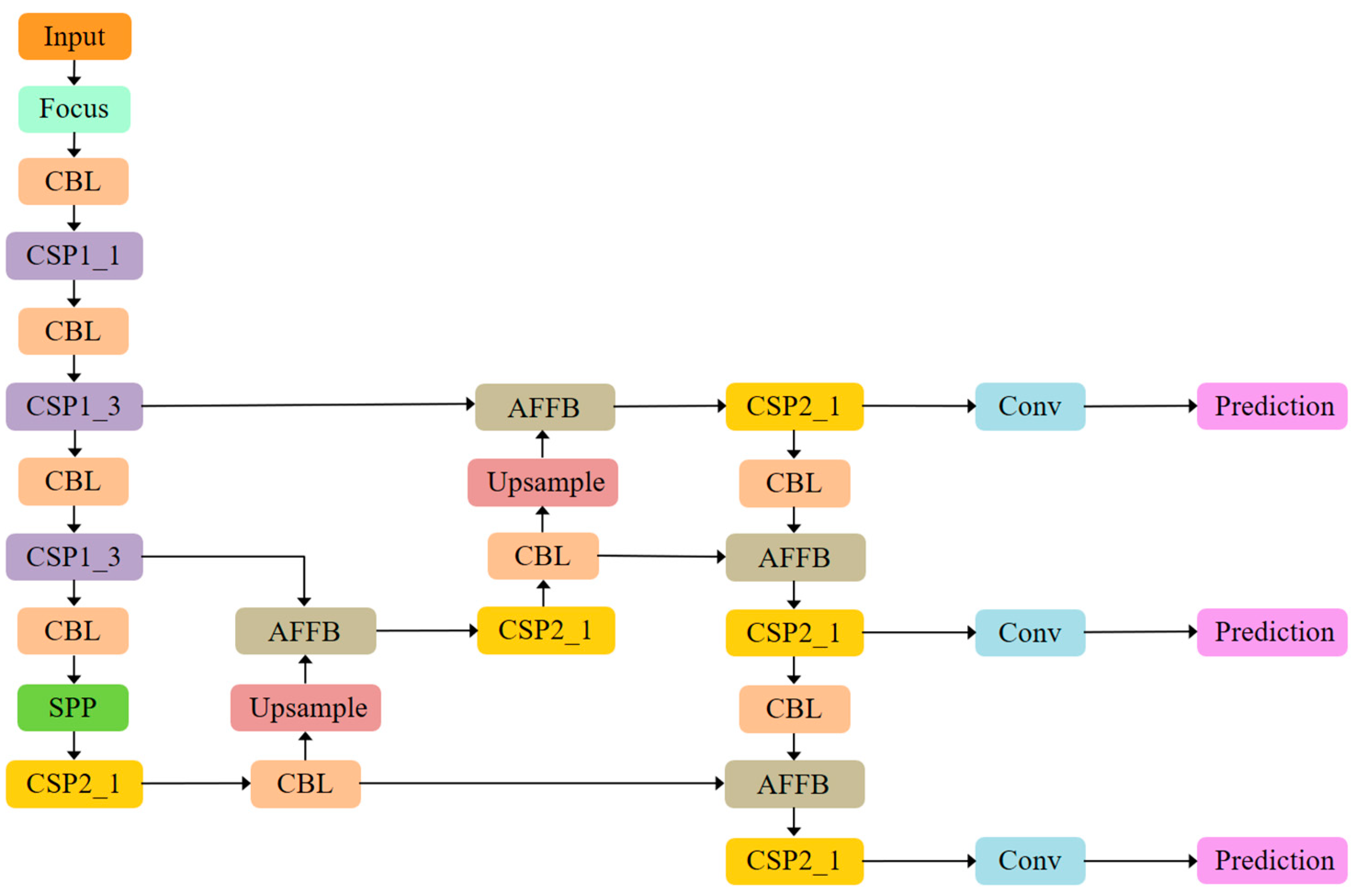
3.1. The YOLOv5s Benchmark Model
3.2. Multi-Scale Channel Attention Block
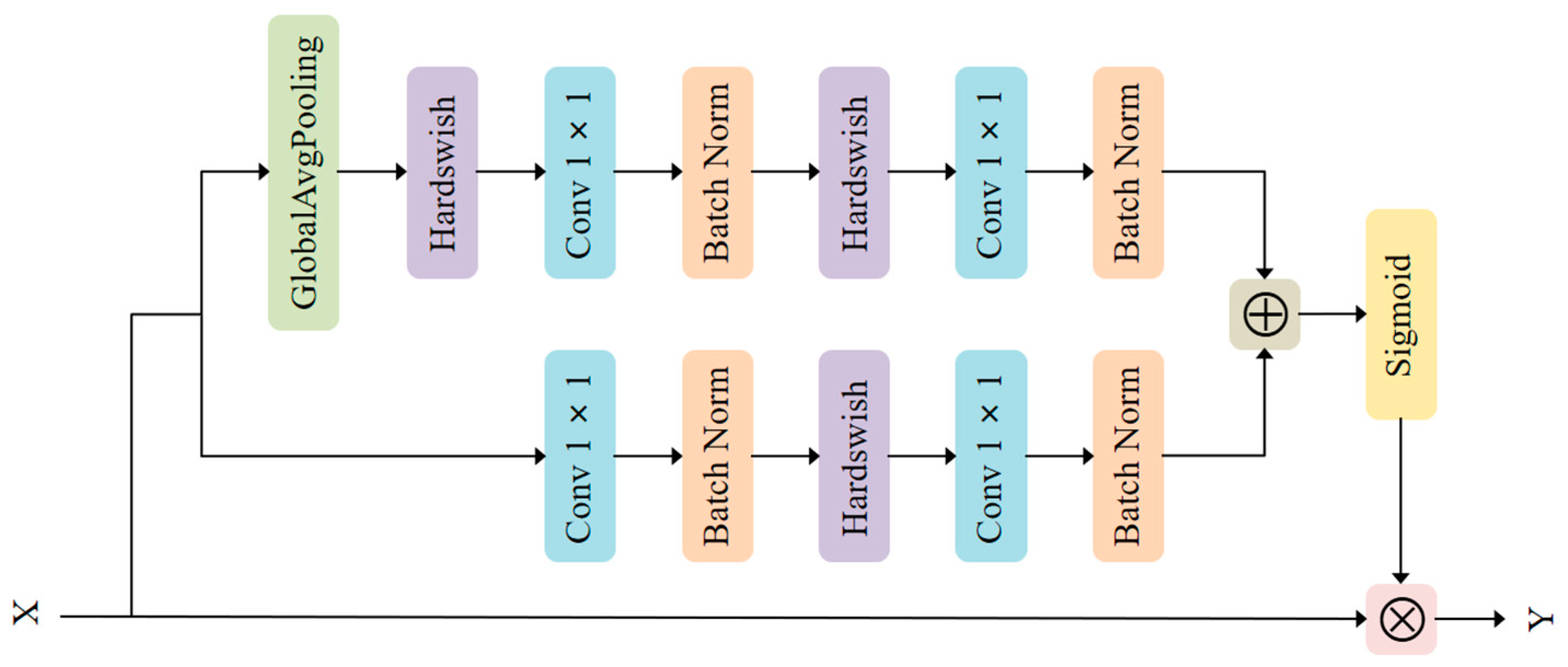
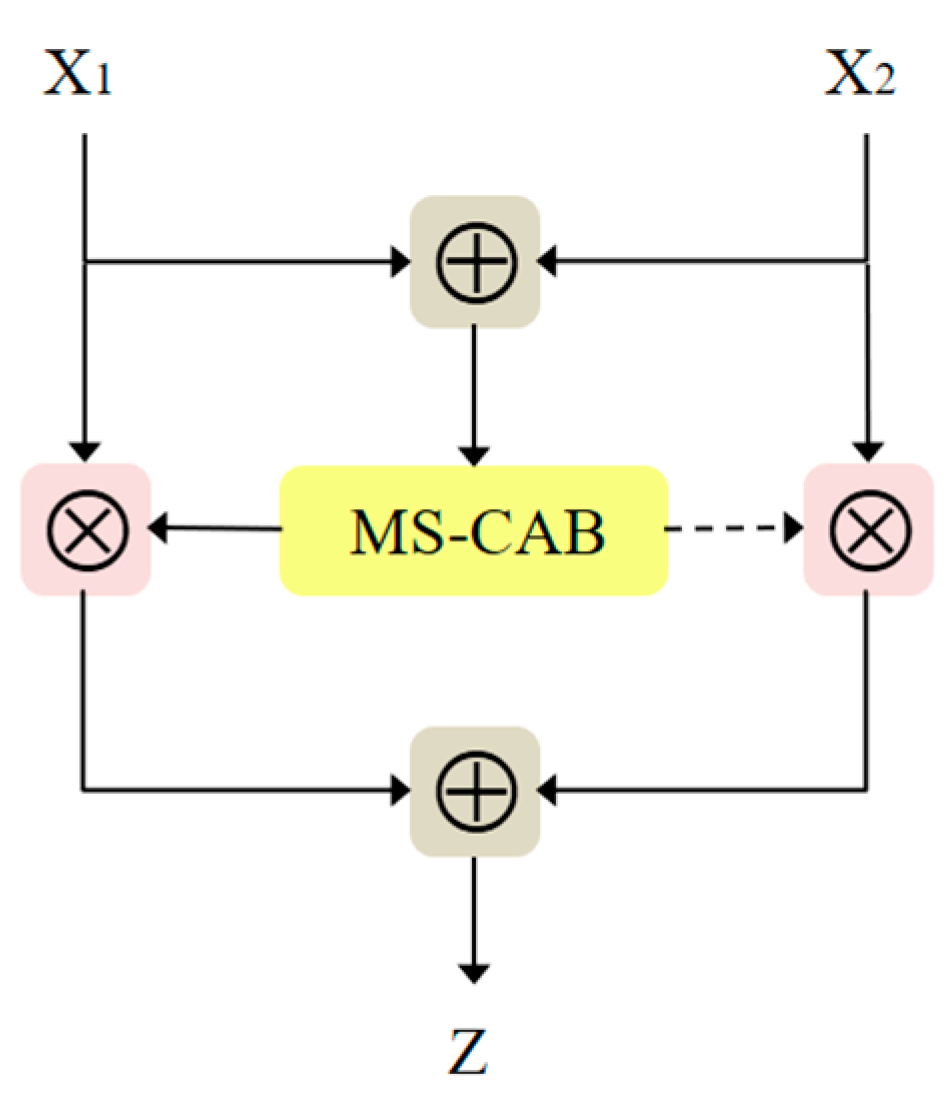
3.3. Attention Feature Fusion Block
4. Experiments and Result Analysis
4.1. Datasets and Experimental Settings
4.1.1. Datasets
4.1.2. Experimental Settings
- (a)
- Network loss function
- (b)
- Training parameter settings
- (c)
- Testing parameter settings
4.2. Quantitative Result Analysis
4.3. Comparative Analysis of Detection Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision-ECCV 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards real-time generic object detection. arXiv 2019, arXiv:1903.11752. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. YOLOv5. Available online: http://doi.org/10.5281/zenodo.4154370 (accessed on 16 November 2020).
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-resolution detection network for small Objects. arXiv 2020, arXiv:2006.07607. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.H.; Borji, A. Salient Object Detection with Pyramid Attention and Salient Edges. In Proceedings of the 2019 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Computer Vision-ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Fan, D.; Wang, W.; Cheng, M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8546–8556. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision-ECCV 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks. Med Image Comput. Comput. Assist. Interv. 2018, 11070, 421–429. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med Image Comput. Comput. Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified multi-scale deep convolutional neural network for fast object detection. In Computer Vision-ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2018, arXiv:1712.00960. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep Feature Fusion for VHR Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Lim, J.; Astrid, M. Small object detection using context and attention. arXiv 2019, arXiv:1912.06319. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Ghiasi, G.; Lin, T.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Gao, F.; Wang, C.; Li, C. A combined object detection method with application to pedestrian detection. IEEE Access 2020, 8, 194457–194465. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking wider to see better. arXiv 2015, arXiv:1506.04579, 2015. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), 5–9 January 2021; pp. 3560–3569. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 6–11 July 2015; pp. 448–456. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Everingham, M.; Zisserman, A.; Williams, C.; Gool, L.V.; Allan, M.; Bishop, C.M.; Chapelle, O.; Dalal, N.; Deselaers, T.; Dorkó, G.; et al. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch SGD: Training ImageNet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision-ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Content |
|---|---|
| CPU | Intel Xeon E5-2620 v4 |
| RAM | 32GB |
| GPU | NVIDIA TITAN Xp |
| Operating System | Ubuntu 18.04.5 LTS |
| Cuda | Cuda 10.1 with Cudnn 7.5.1 |
| Data Processing | Python 3.8, OpenCV |
| Deep Learning Framework | Pytorch 1.7.0 |
| Model | Precision (%) | Recall (%) | mAP (%) | FPS | Parameters (M) |
|---|---|---|---|---|---|
| YOLOv5s | 32.5 | 57.7 | 50.6 | 77 | 7.28 |
| MS-CAB_YOLOv5s | 32.5 | 58.1 | 51.0 | 63 | 7.45 |
| AFFB_YOLOv5s | 33.0 | 58.3 | 51.5 | 63 | 7.20 |
| Model | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| YOLOv5s | 11.7 | 51.9 | 21.5 |
| MS-CAB_YOLOv5s | 16.4 | 49.8 | 23.1 |
| AFFB_YOLOv5s | 23.1 | 48.6 | 25.0 |
| Model | Precision (%) | Recall (%) | mAP (%) | FPS | Parameters (M) |
|---|---|---|---|---|---|
| YOLOv5s | 60.3 | 82.3 | 79.4 | 76 | 7.31 |
| MS-CAB_YOLOv5s | 62.0 | 82.7 | 80.2 | 61 | 7.48 |
| AFFB_YOLOv5s | 63.4 | 82.9 | 80.8 | 61 | 7.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, J.; Yin, Y.; Li, L.; Wang, Z.; Zhou, Y. Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors 2021, 21, 3031. https://doi.org/10.3390/s21093031
Lian J, Yin Y, Li L, Wang Z, Zhou Y. Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors. 2021; 21(9):3031. https://doi.org/10.3390/s21093031
Chicago/Turabian StyleLian, Jing, Yuhang Yin, Linhui Li, Zhenghao Wang, and Yafu Zhou. 2021. "Small Object Detection in Traffic Scenes Based on Attention Feature Fusion" Sensors 21, no. 9: 3031. https://doi.org/10.3390/s21093031
APA StyleLian, J., Yin, Y., Li, L., Wang, Z., & Zhou, Y. (2021). Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors, 21(9), 3031. https://doi.org/10.3390/s21093031