
Discriminative Learning Approach Based on Flexible Mixture Model for Medical Data Categorization and Recognition





Abstract
1. Introduction
Motivations and Contributions
2. Finite Shifted-Scaled Dirichlet Mixture Model
- Initialization-step: Apply K-means algorithm to initialize the parameters of the mixture.
- E-step: Calculate the posterior probability as:
- M-step: Update the model’s parameter by maximizing the log-likelihood function as:where the membership , with:
3. Discriminative Learning Approach Based on SSDMM
4. Complete Algorithm
| Algorithm 1: Discriminative learning approach based on SSDMM. |
 |
5. Experimental Results
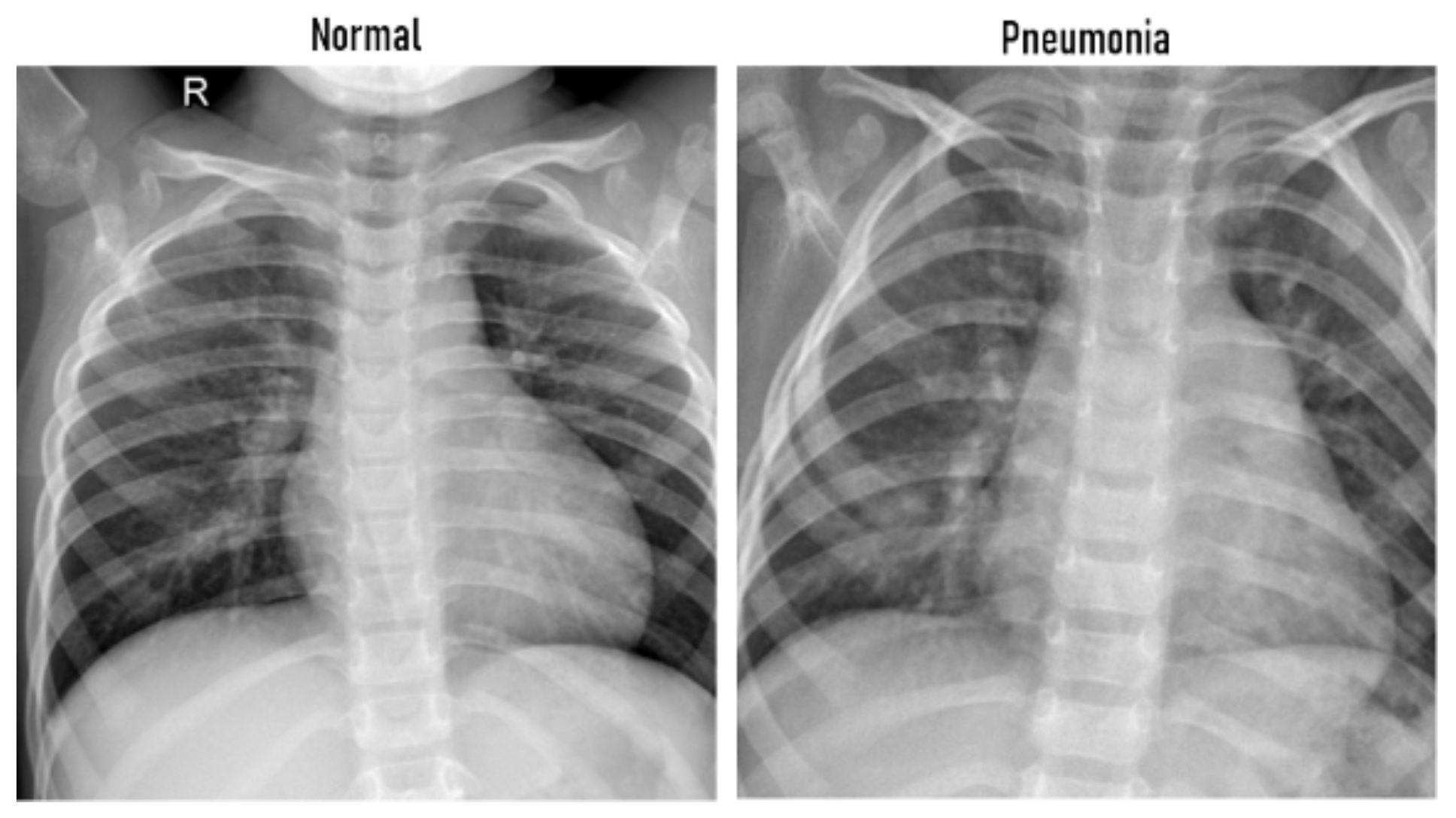
5.1. Lung Disease Recognition
5.2. Retinopathy Detection
- E-ophtha [59]: this first dataset contains 47 images with EX and 35 normal images and includes 148 images with MA and 233 normal images.
- DRIVE [60]: This dataset includes 40 images with the size of 565 × 584 pixels where 7 are mild DR images, and the rest are normal retinal images.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Razzak, M.I.; Naz, S.; Zaib, A. Deep learning for medical image processing: Overview, challenges and future. In Classification in BioApps; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Ker, J.; Wang, L.; Rao, J.; Lim, T.C.C. Deep Learning Applications in Medical Image Analysis. IEEE Access 2018, 6, 9375–9389. [Google Scholar] [CrossRef]
- De Bruijne, M. Machine learning approaches in medical image analysis: From detection to diagnosis. Med. Image Anal. 2016, 33, 94–97. [Google Scholar] [CrossRef] [PubMed]
- Wernick, M.N.; Yang, Y.; Brankov, J.G.; Yourganov, G.; Strother, S.C. Machine Learning in Medical Imaging. IEEE Signal Process. Mag. 2010, 27, 25–38. [Google Scholar] [CrossRef] [PubMed]
- Alroobaea, R.; Rubaiee, S.; Bourouis, S.; Bouguila, N.; Alsufyani, A. Bayesian inference framework for bounded generalized Gaussian-based mixture model and its application to biomedical images classification. Int. J. Imaging Syst. Technol. 2020, 30, 18–30. [Google Scholar] [CrossRef]
- Zhu, R.; Dornaika, F.; Ruichek, Y. Learning a discriminant graph-based embedding with feature selection for image categorization. Neural Netw. 2019, 111, 35–46. [Google Scholar] [CrossRef]
- Zhou, H.; Zhou, S. Scene categorization towards urban tunnel traffic by image quality assessment. J. Vis. Commun. Image Represent. 2019, 65, 102655. [Google Scholar] [CrossRef]
- Sánchez, D.L.; Arrieta, A.G.; Corchado, J.M. Visual content-based web page categorization with deep transfer learning and metric learning. Neurocomputing 2019, 338, 418–431. [Google Scholar] [CrossRef]
- Bourouis, S.; Zaguia, A.; Bouguila, N.; Alroobaea, R. Deriving Probabilistic SVM Kernels From Flexible Statistical Mixture Models and its Application to Retinal Images Classification. IEEE Access 2019, 7, 1107–1117. [Google Scholar] [CrossRef]
- Najar, F.; Bourouis, S.; Bouguila, N.; Belghith, S. Unsupervised learning of finite full covariance multivariate generalized Gaussian mixture models for human activity recognition. Multim. Tools Appl. 2019, 78, 18669–18691. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Khan, A.M.; El-Daly, H.; Rajpoot, N.M. A Gamma-Gaussian mixture model for detection of mitotic cells in breast cancer histopathology images. In Proceedings of the 21st International Conference on Pattern Recognition, ICPR 2012, Tsukuba, Japan, 11–15 November 2012; pp. 149–152. [Google Scholar]
- Bourouis, S.; Channoufi, I.; Alroobaea, R.; Rubaiee, S.; Andejany, M.; Bouguila, N. Color object segmentation and tracking using flexible statistical model and level-set. Multimed. Tools Appl. 2021, 80, 5809–5831. [Google Scholar] [CrossRef]
- Najar, F.; Bourouis, S.; Bouguila, N.; Belghith, S. A new hybrid discriminative/generative model using the full-covariance multivariate generalized Gaussian mixture models. Soft Comput. 2020, 24, 10611–10628. [Google Scholar] [CrossRef]
- Fan, W.; Bouguila, N. Expectation propagation learning of a Dirichlet process mixture of Beta-Liouville distributions for proportional data clustering. Eng. Appl. Artif. Intell. 2015, 43, 1–14. [Google Scholar] [CrossRef]
- Oboh, B.S.; Bouguila, N. Unsupervised learning of finite mixtures using scaled dirichlet distribution and its application to software modules categorization. In Proceedings of the IEEE International Conference on Industrial Technology, ICIT, Toronto, ON, Canada, 22–25 March 2017; pp. 1085–1090. [Google Scholar]
- Bourouis, S.; Al-Osaimi, F.R.; Bouguila, N.; Sallay, H.; Aldosari, F.M.; Mashrgy, M.A. Bayesian inference by reversible jump MCMC for clustering based on finite generalized inverted Dirichlet mixtures. Soft Comput. 2019, 23, 5799–5813. [Google Scholar] [CrossRef]
- Fan, W.; Sallay, H.; Bouguila, N.; Bourouis, S. Variational learning of hierarchical infinite generalized Dirichlet mixture models and applications. Soft Comput. 2016, 20, 979–990. [Google Scholar] [CrossRef]
- Bourouis, S.; Mashrgy, M.A.; Bouguila, N. Bayesian learning of finite generalized inverted Dirichlet mixtures: Application to object classification and forgery detection. Expert Syst. Appl. 2014, 41, 2329–2336. [Google Scholar] [CrossRef]
- Alsuroji, R.; Zamzami, N.; Bouguila, N. Model selection and estimation of a finite shifted-scaled dirichlet mixture model. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2018; pp. 707–713. [Google Scholar]
- Bourouis, S.; Alharbi, A.; Bouguila, N. Bayesian Learning of Shifted-Scaled Dirichlet Mixture Models and Its Application to Early COVID-19 Detection in Chest X-ray Images. J. Imaging 2021, 7, 7. [Google Scholar] [CrossRef]
- Baxter, R.A.; Oliver, J.J. Finding overlapping components with MML. Stat. Comput. 2000, 10, 5–16. [Google Scholar] [CrossRef]
- Jaakkola, T.S.; Haussler, D. Exploiting generative models in discriminative classifiers. In Proceedings of the Advances in Neural Information Processing Systems 11, NIPS Conference, Denver, CO, USA, 30 November–5 December 1998; Kearns, M.J., Solla, S.A., Cohn, D.A., Eds.; pp. 487–493. [Google Scholar]
- Moreno, P.J.; Ho, P.; Vasconcelos, N. A Kullback-Leibler divergence based kernel for SVM classification in multimedia applications. In Proceedings of the Advances in Neural Information Processing Systems 16 Neural Information Processing Systems, NIPS, Vancouver, BC, Canada, 8–13 December 2003; Thrun, S., Saul, L.K., Schölkopf, B., Eds.; pp. 1385–1392. [Google Scholar]
- Jebara, T.; Kondor, R. Bhattacharyya and expected likelihood kernels. In Learning Theory and Kernel Machines. In Proceedings of the 16th Annual Conference on Learning Theory (COLT), Graz, Austria, 9–12 July 2020; Springer: Berlin/Heidelberg, Germany, 2003; pp. 57–71. [Google Scholar]
- Monti, G.S.; Mateu i Figueras, G.; Pawlowsky-Glahn, V.; Egozcue, J.J. The shifted-scaled Dirichlet distribution in the simplex. In Proceedings of the 4th International Workshop on Compositional Data Analysis, Girona, Spain, 10–13 May 2011. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. Methodol. 1977, 39, 1–38. [Google Scholar]
- Wallace, C.S.; Freeman, P.R. Estimation and inference by compact coding. J. R. Stat. Soc. Ser. B 1987, 49, 240–265. [Google Scholar] [CrossRef]
- Bdiri, T.; Bouguila, N. Positive vectors clustering using inverted Dirichlet finite mixture models. Expert Syst. Appl. 2012, 39, 1869–1882. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Campbell, W.M.; Sturim, D.E.; Reynolds, D.A. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Process. Lett. 2006, 13, 308–311. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N.; Moreno, P.J. A family of Probabilistic Kernels Based on Information Divergence; Technical Report; Tech. Rep. SVCL-TR-2004-1; Statistical Visual Computing Laboratory: San Diego, CA, USA, 2004. [Google Scholar]
- Wang, L.S.; Wang, Y.R.; Ye, D.W.; Liu, Q.Q. Review of the 2019 Novel Coronavirus (COVID-19) based on current evidence. Int. J. Antimicrob. Agents 2020, 55, 105948. [Google Scholar] [CrossRef]
- Bourouis, S.; Sallay, H.; Bouguila, N. A Competitive Generalized Gamma Mixture Model for Medical Image Diagnosis. IEEE Access 2021, 9, 13727–13736. [Google Scholar] [CrossRef]
- Bharati, S.; Podder, P.; Mondal, M.R.H. Hybrid deep learning for detecting lung diseases from X-ray images. Inform. Med. Unlocked 2020, 20, 100391. [Google Scholar] [CrossRef]
- Vellingiri, B.; Jayaramayya, K.; Iyer, M.; Narayanasamy, A.; Govindasamy, V.; Giridharan, B.; Ganesan, S.; Venugopal, A.; Venkatesan, D.; Ganesan, H.; et al. COVID-19: A promising cure for the global panic. Sci. Total Environ. 2020, 725, 138277. [Google Scholar] [CrossRef] [PubMed]
- Jacobi, A.; Chung, M.; Bernheim, A.; Eber, C. Portable chest X-ray in coronavirus disease-19 (COVID-19): A pictorial review. Clin. Imaging 2020, 64, 35–42. [Google Scholar] [CrossRef]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Cohen, J.P.; Morrison, P.; Dao, L.; Roth, K.; Duong, T.Q.; Ghassemi, M. COVID-19 Image Data Collection: Prospective Predictions Are the Future. arXiv 2020, arXiv:2006.11988. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.S.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Sallay, H.; Bourouis, S.; Bouguila, N. Online Learning of Finite and Infinite Gamma Mixture Models for COVID-19 Detection in Medical Images. Computers 2021, 10, 6. [Google Scholar] [CrossRef]
- Pourghassem, H.; Ghassemian, H. Content-based medical image classification using a new hierarchical merging scheme. Comput. Med. Imaging Graph. 2008, 32, 651–661. [Google Scholar] [CrossRef]
- Taylor, R.; Batey, D. Handbook of Retinal Screening in Diabetes; Wiley Online Library: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bourne, R.R.; Stevens, G.A.; White, R.A.; Smith, J.L.; Flaxman, S.R.; Price, H.; Jonas, J.B.; Keeffe, J.; Leasher, J.; Naidoo, K.; et al. Causes of vision loss worldwide, 1990–2010: A systematic analysis. Lancet Glob. Health 2013, 1, e339–e349. [Google Scholar] [CrossRef]
- Scanlon, P.H.; Sallam, A.; Van Wijngaarden, P. A Practical Manual of Diabetic Retinopathy Management; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Bandello, F.; Zarbin, M.A.; Lattanzio, R.; Zucchiatti, I. Clinical Strategies in the Management of Diabetic Retinopathy; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Acharya, R.; Chua, C.K.; Ng, E.; Yu, W.; Chee, C. Application of higher order spectra for the identification of diabetes retinopathy stages. J. Med. Syst. 2008, 32, 481–488. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Webster, D.R. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. J. Am. Med. Assoc. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Agurto, C.; Murray, V.; Barriga, E.; Murillo, S.; Pattichis, M.; Davis, H.; Russell, S.; Abràmoff, M.; Soliz, P. Multiscale AM-FM methods for diabetic retinopathy lesion detection. IEEE Trans. Med. Imaging 2010, 29, 502–512. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, X.; You, J.; Li, Q.; Karray, F. Detection of microaneurysms using multi-scale correlation coefficients. Pattern Recognit. 2010, 43, 2237–2248. [Google Scholar] [CrossRef]
- Quellec, G.; Lamard, M.; Josselin, P.M.; Cazuguel, G.; Cochener, B.; Roux, C. Optimal wavelet transform for the detection of microaneurysms in retina photographs. IEEE Trans. Med. Imaging 2008, 27, 1230–1241. [Google Scholar] [CrossRef] [PubMed]
- Antal, B.; Hajdu, A. An ensemble-based system for microaneurysm detection and diabetic retinopathy grading. IEEE Trans. Biomed. Eng. 2012, 59, 1720–1726. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Shi, G.; Chen, Y.; Shi, F.; Chen, X.; Coatrieux, G.; Yang, J.; Luo, L.; Li, S. Coarse-to-fine classification for diabetic retinopathy grading using convolutional neural network. Artif. Intell. Med. 2020, 108, 101936. [Google Scholar] [CrossRef]
- Sopharak, A.; Uyyanonvara, B.; Barman, S.; Williamson, T.H. Automatic detection of diabetic retinopathy exudates from non-dilated retinal images using mathematical morphology methods. Comput. Med. Imaging Graph. 2008, 32, 720–727. [Google Scholar] [CrossRef]
- Tsao, H.; Chan, P.; Su, E.C. Predicting diabetic retinopathy and identifying interpretable biomedical features using machine learning algorithms. BMC Bioinform. 2018, 19, 195–205. [Google Scholar] [CrossRef] [PubMed]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Decencière, E.; Cazuguel, G.; Zhang, X.; Thibault, G.; Klein, J.C.; Meyer, F.; Marcotegui, B.; Quellec, G.; Lamard, M.; Danno, R.; et al. TeleOphta: Machine learning and image processing methods for teleophthalmology. IRBM 2013, 34, 196–203. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Fleming, A.D.; Philip, S.; Goatman, K.A.; Williams, G.J.; Olson, J.A.; Sharp, P.F. Automated detection of exudates for diabetic retinopathy screening. Phys. Med. Biol. 2007, 52, 7385. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.; Hornero, R.; Sanchez, C.I.; López, M.I.; Díez, A. Feature extraction and selection for the automatic detection of hard exudates in retinal images. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; pp. 4969–4972. [Google Scholar]
- Li, H.; Chutatape, O. A model-based approach for automated feature extraction in fundus images. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; p. 394. [Google Scholar]
- Wang, H.; Hsu, W.; Goh, K.G.; Lee, M.L. An effective approach to detect lesions in color retinal images. In Proceedings of the Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; Volume 2, pp. 181–186. [Google Scholar]
- Colomer, A.; Igual, J.; Naranjo, V. Detection of Early Signs of Diabetic Retinopathy Based on Textural and Morphological Information in Fundus Images. Sensors 2020, 20, 1005. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Approach/Metrics | ACC(%) | DR(%) | FPR(%) |
|---|---|---|---|
| Generative Models | |||
| Gaussian Mixture | 82.11 | 81.02 | 0.18 |
| Gamma Mixture | 85.22 | 83.76 | 0.16 |
| Dirichlet Mixture | 87.80 | 85.92 | 0.13 |
| Scaled Dirichlet Mixture | 87.96 | 86.02 | 0.13 |
| Shifted Scaled Dirichlet Mixture | 88.01 | 86.12 | 0.12 |
| Hybrid Models | |||
| Gaussian Mixture + Fisher Kernel | 83.43 | 82.29 | 0.17 |
| Gaussian Mixture + Kullback–Leibler Kernel | 83.27 | 82.20 | 0.17 |
| Gaussian Mixture + Bhattacharyya Kernel | 83.25 | 82.18 | 0.17 |
| Gamma Mixture + Fisher Kernel | 86.01 | 84.11 | 0.16 |
| Gamma Mixture + Kullback–Leibler Kernel | 85.99 | 84.08 | 0.16 |
| Gamma Mixture + Bhattacharyya Kernel | 85.94 | 84.03 | 0.16 |
| generalized Gamma Mixture + Fisher Kernel | 87.01 | 87.90 | 0.12 |
| generalized Gamma Mixture + Kullback–Leibler Kernel | 87.71 | 87.01 | 0.12 |
| generalized Gamma Mixture + Bhattacharyya Kernel | 87.67 | 86.96 | 0.12 |
| Dirichlet Mixture + Fisher Kernel | 87.80 | 85.92 | 0.13 |
| Scaled Dirichlet Mixture + Fisher Kernel | 87.96 | 86.02 | 0.13 |
| Shifted Scaled Dirichlet Mixture + Fisher Kernel | 88.81 | 86.91 | 0.11 |
| Shifted Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 88.77 | 86.85 | 0.11 |
| Shifted Scaled Dirichlet Mixture + Bhattacharyya Kernel | 88.74 | 86.82 | 0.11 |
| Approach/Metrics | ACC(%) | DR(%) | FPR(%) |
|---|---|---|---|
| Generative Models | |||
| Gaussian Mixture | 87.66 | 85.80 | 0.13 |
| Gamma Mixture | 90.54 | 88.54 | 0.10 |
| Dirichlet Mixture | 93.01 | 90.94 | 0.07 |
| Scaled Dirichlet Mixture | 93.33 | 91.90 | 0.07 |
| Shifted Scaled Dirichlet Mixture | 93.62 | 92.14 | 0.07 |
| Hybrid Models | |||
| Gaussian Mixture + Fisher Kernel | 88.25 | 86.90 | 0.12 |
| Gaussian Mixture + Kullback–Leibler Kernel | 88.22 | 86.83 | 0.12 |
| Gaussian Mixture + Bhattacharyya Kernel | 88.18 | 86.79 | 0.12 |
| Gamma Mixture + Fisher Kernel | 90.88 | 88.60 | 0.10 |
| Gamma Mixture + Kullback–Leibler Kernel | 90.85 | 88.53 | 0.10 |
| Gamma Mixture + Bhattacharyya Kernel | 90.84 | 88,51 | 0.10 |
| generalized Gamma Mixture + Fisher Kernel | 91.98 | 91.11 | 0.09 |
| generalized Gamma Mixture + Kullback–Leibler Kernel | 91.77 | 91.05 | 0.09 |
| generalized Gamma Mixture + Bhattacharyya Kernel | 91.75 | 91.02 | 0.09 |
| Dirichlet Mixture + Fisher Kernel | 93.01 | 90.94 | 0.07 |
| Scaled Dirichlet Mixture + Fisher Kernel | 93.33 | 91.90 | 0.07 |
| Shifted Scaled Dirichlet Mixture + Fisher Kernel | 94.83 | 93.99 | 0.06 |
| Shifted Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 94.51 | 93.82 | 0.06 |
| Shifted Scaled Dirichlet Mixture + Bhattacharyya Kernel | 94.48 | 93.77 | 0.06 |
| Approach/Metrics | AUC | ACC |
|---|---|---|
| Generative Models | ||
| Gaussian Mixture | 0.70 | 84.01 |
| Dirichlet Mixture | 0.72 | 84.79 |
| Scaled Dirichlet Mixture | 0.75 | 84.99 |
| Shifted Scaled Dirichlet Mixture | 0.77 | 85.36 |
| Hybrid Models | ||
| Gaussian Mixture + Fisher Kernel | 0.81 | 87.84 |
| Gaussian Mixture + Bhattacharyya Kernel | 0.81 | 89.02 |
| Gaussian Mixture + Kullback–Leibler Kernel | 0.81 | 87.11 |
| Dirichlet Mixture + Fisher Kernel | 0.84 | 88.54 |
| Dirichlet Mixture + Bhattacharyya Kernel | 0.86 | 90.67 |
| Dirichlet Mixture + Kullback–Leibler Kernel | 0.84 | 88.01 |
| Scaled Dirichlet Mixture + Fisher Kernel | 0.87 | 90.87 |
| Scaled Dirichlet Mixture + Bhattacharyya Kernel | 0.90 | 91.33 |
| Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 0.85 | 88.14 |
| Shifted Scaled Dirichlet Mixture + Fisher Kernel | 0.88 | 91.13 |
| Shifted Scaled Dirichlet Mixture + Bhattacharyya Kernel | 0.91 | 91.65 |
| Shifted Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 0.91 | 88.98 |
| Other Methods | ||
| Fleming et al. [61] | 89.80 | |
| Garcia et al. [62] | 73.55 | |
| Li and Chutatape [63] | 85.50 | |
| Wang et al. [64] | 85.00 |
| Approach/Metrics | AUC | ACC |
|---|---|---|
| Generative Models | ||
| Gaussian Mixture | 0.81 | 81.45 |
| Dirichlet Mixture | 0.83 | 84.95 |
| Scaled Dirichlet Mixture | 0.83 | 85.34 |
| Shifted Scaled Dirichlet Mixture | 0.84 | 86.10 |
| Hybrid Models | ||
| Gaussian Mixture + Fisher Kernel | 0.90 | 94.84 |
| Gaussian Mixture + Bhattacharyya Kernel | 0.89 | 92.81 |
| Gaussian Mixture + Kullback–Leibler Kernel | 0.85 | 92.53 |
| Dirichlet Mixture + Fisher Kernel | 0.92 | 95.42 |
| Dirichlet Mixture + Bhattacharyya Kernel | 0.91 | 93.08 |
| Dirichlet Mixture + Kullback–Leibler Kernel | 0.88 | 93.77 |
| Scaled Dirichlet Mixture + Fisher Kernel | 0.95 | 96.07 |
| Scaled Dirichlet Mixture + Bhattacharyya Kernel | 0.94 | 95.91 |
| Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 0.90 | 94.33 |
| Shifted Scaled Dirichlet Mixture + Fisher Kernel | 0.96 | 96.88 |
| Shifted Scaled Dirichlet Mixture + Bhattacharyya Kernel | 0.96 | 96.72 |
| Shifted Scaled Dirichlet Mixture + Kullback–Leibler Kernel | 0.93 | 95.12 |
| Other Methods | ||
| linear-SVM [65] | 0.89 | 85.33 |
| RBF-SVM [65] | 0.92 | 87.96 |
| Random Forests [65] | 0.92 | 95.08 |
| Gaussian Processes [65] | 0.93 | 87.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharithi, F.; Almulihi, A.; Bourouis, S.; Alroobaea, R.; Bouguila, N. Discriminative Learning Approach Based on Flexible Mixture Model for Medical Data Categorization and Recognition. Sensors 2021, 21, 2450. https://doi.org/10.3390/s21072450
Alharithi F, Almulihi A, Bourouis S, Alroobaea R, Bouguila N. Discriminative Learning Approach Based on Flexible Mixture Model for Medical Data Categorization and Recognition. Sensors. 2021; 21(7):2450. https://doi.org/10.3390/s21072450
Chicago/Turabian StyleAlharithi, Fahd, Ahmed Almulihi, Sami Bourouis, Roobaea Alroobaea, and Nizar Bouguila. 2021. "Discriminative Learning Approach Based on Flexible Mixture Model for Medical Data Categorization and Recognition" Sensors 21, no. 7: 2450. https://doi.org/10.3390/s21072450
APA StyleAlharithi, F., Almulihi, A., Bourouis, S., Alroobaea, R., & Bouguila, N. (2021). Discriminative Learning Approach Based on Flexible Mixture Model for Medical Data Categorization and Recognition. Sensors, 21(7), 2450. https://doi.org/10.3390/s21072450