
Self-Difference Convolutional Neural Network for Facial Expression Recognition


Abstract
1. Introduction
- (1)
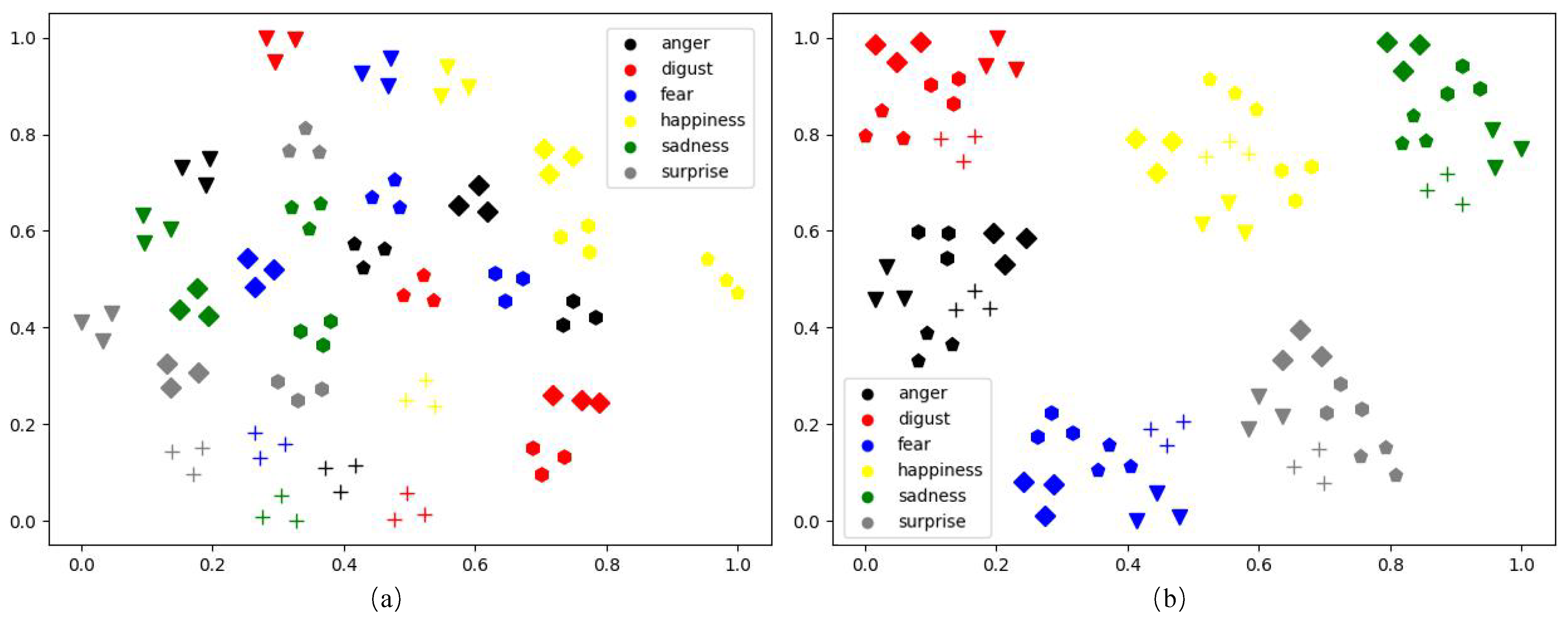
- We propose a novel approach called SD-CNN for FER. The self-difference feature output by our SD-CNN can significantly alleviate the intra-class variation issue in FER an is discriminative for fical expression classification.
- (2)
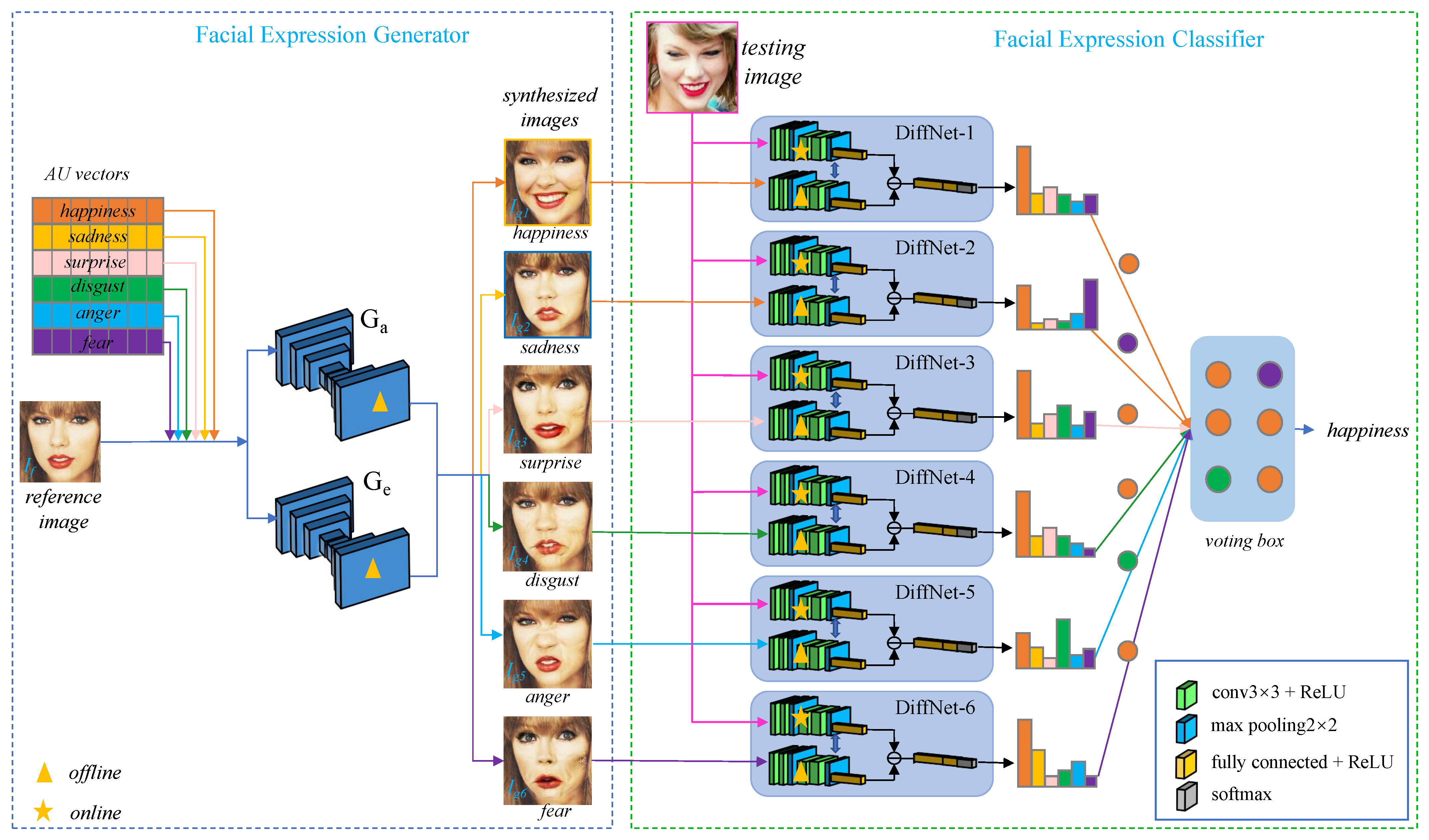
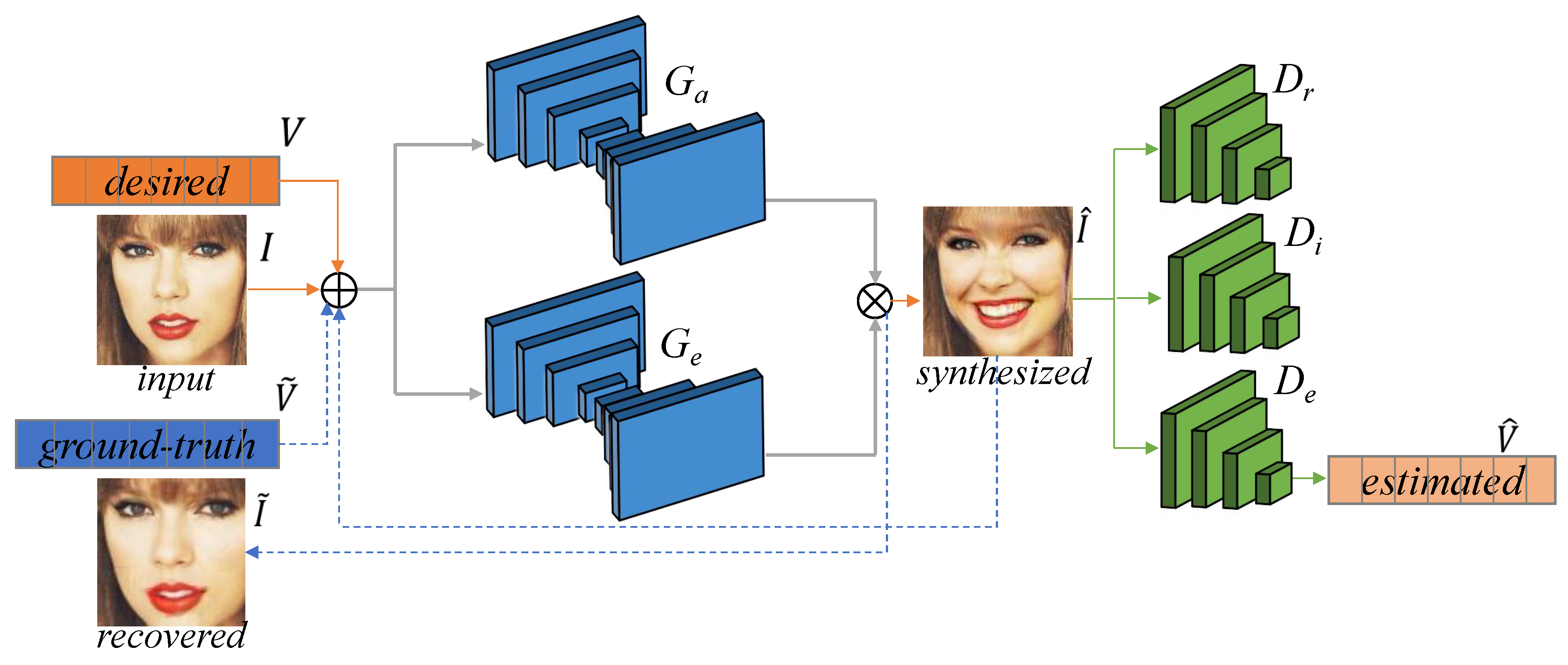
- We present a cGAN-base facial expression generator to synthesize reference images with the six typical facial expressions. Conditioned by empirical action unit intensities, the generator can synthesize photo-realistic images with the desired expressions from any input face image.
- (3)
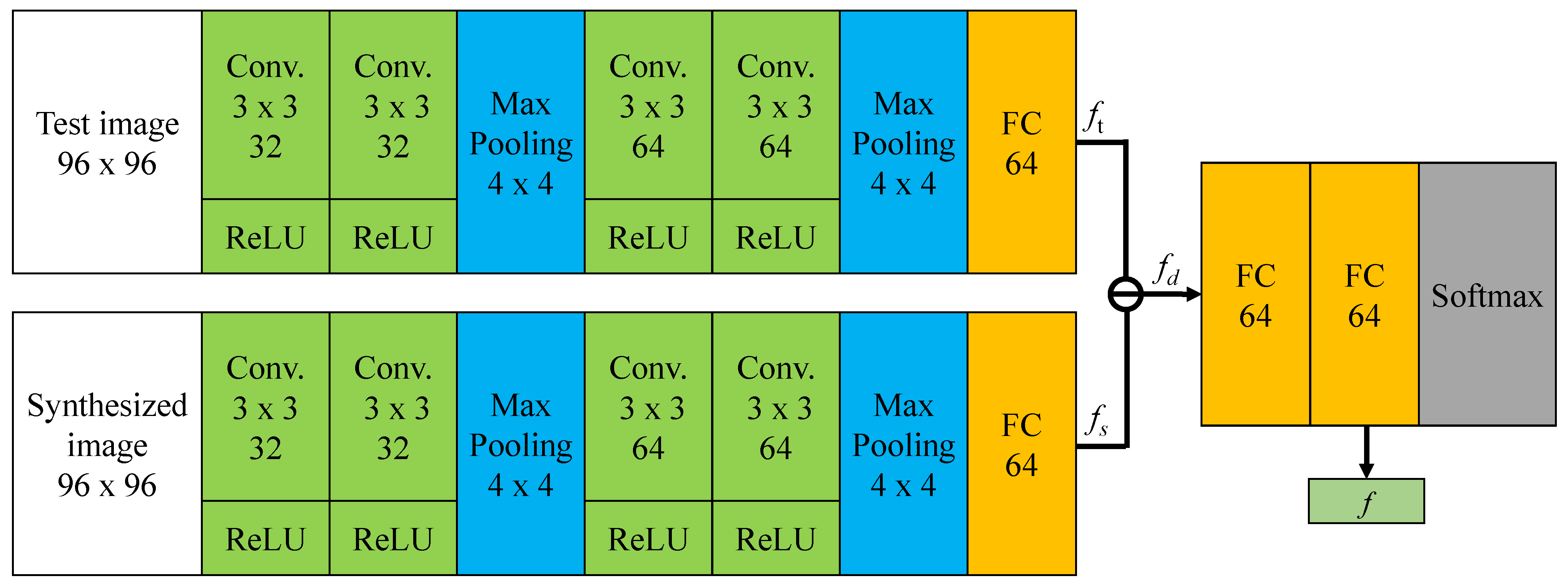
- We design networks called DiffNets to extract the self-difference feature between the testing image and the synthesized expression image. Despite the fact that DiffNets are compact and light-weighted, they achieve state-of-the-art performance on public FER datasets.
2. Related Work
2.1. Static Image-Based FER Methods
2.2. Sequence-Based FER Methods
3. Methodology
3.1. Overview
3.2. Facial Expression Generator
3.3. Facial Expression Classifier
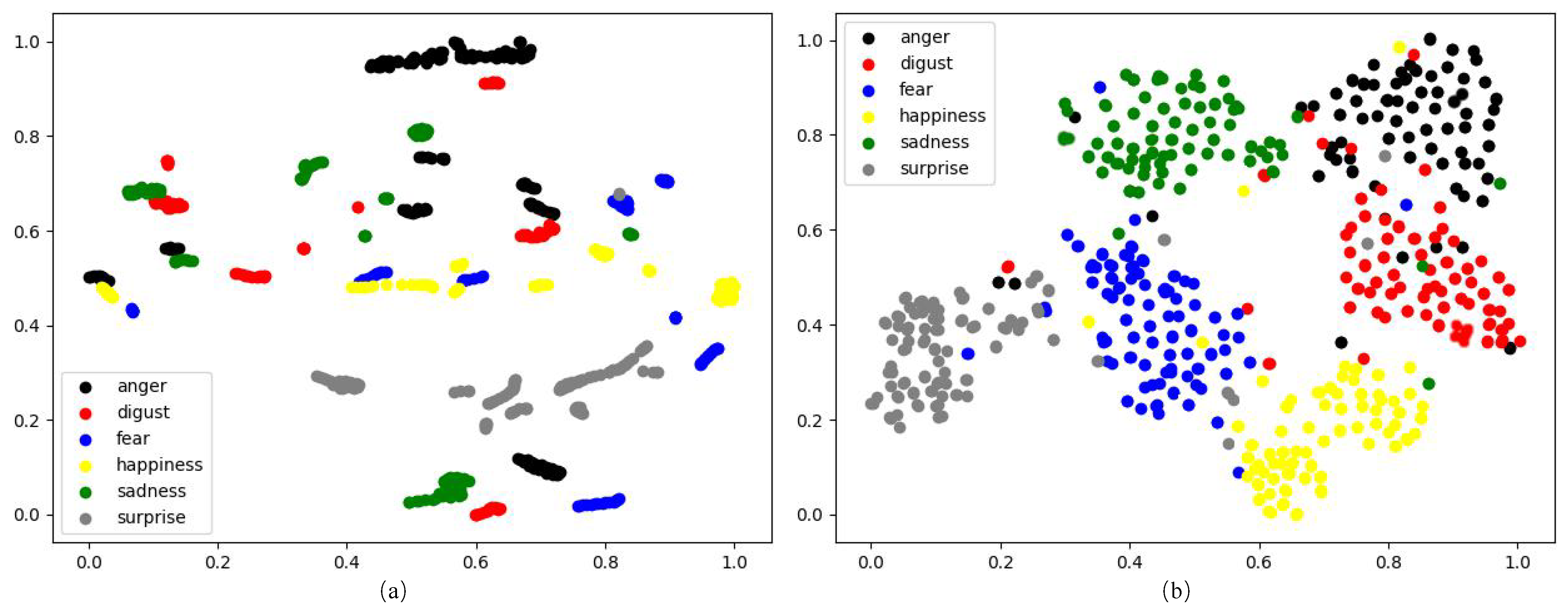
4. Experimental Results
4.1. Implementation Details
4.2. Datasets and Performance Metric
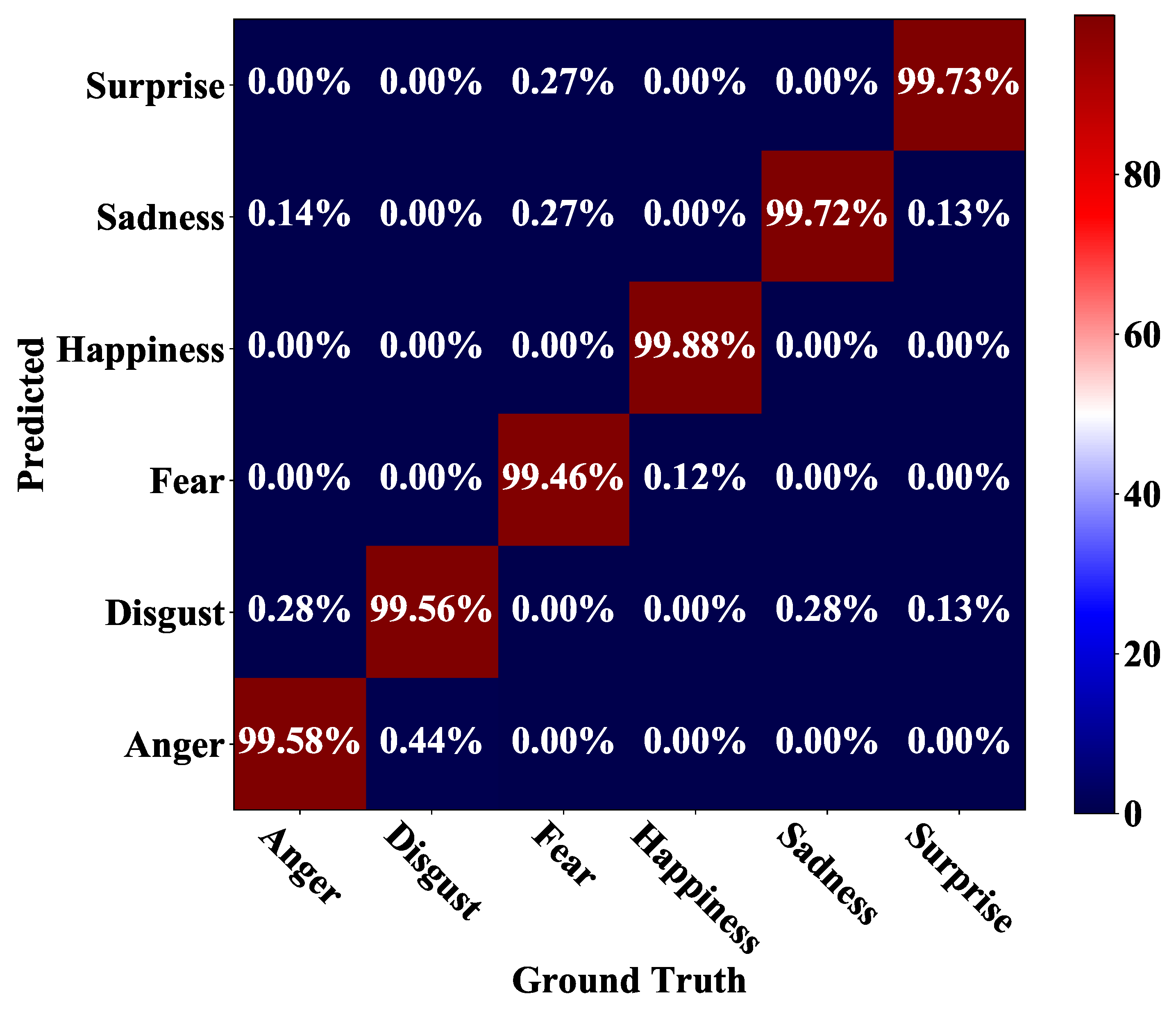
4.3. Experiments on CK+
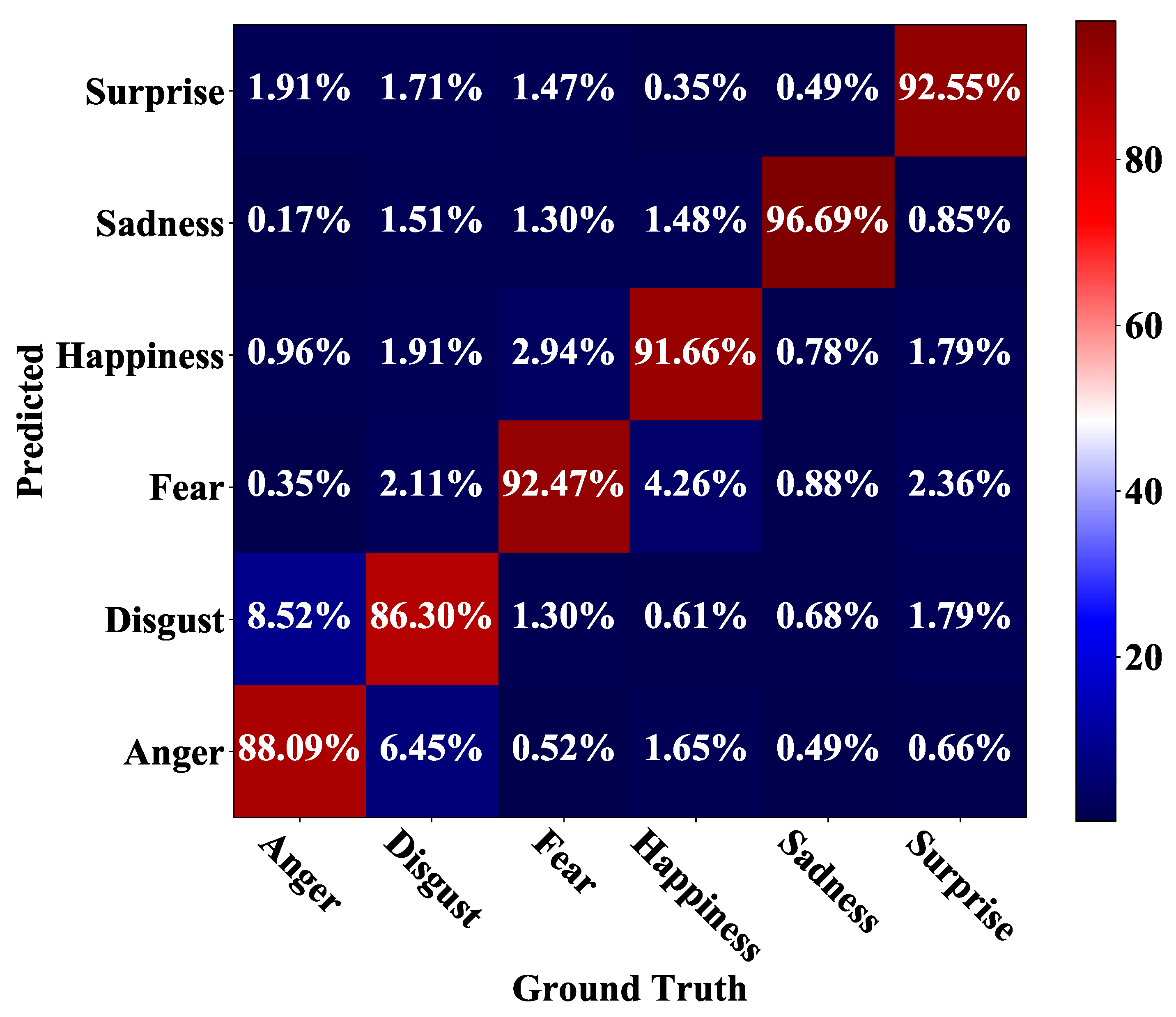
4.4. Experiments on Oulu-CASIA
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Paul, E.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, M.; Su, W.; Wu, M.; She, J.; Hirota, K. Softmax regression based deep sparse autoencoder network for facial emotion recognition in human-robot interaction. Inf. Sci. 2018, 428, 49–61. [Google Scholar] [CrossRef]
- Chen, J.; Luo, N.; Liu, Y.; Liu, L.; Zhang, K.; Kolodziej, J. A hybrid intelligence-aided approach to affect-sensitive e-learning. Computing 2016, 98, 215–233. [Google Scholar] [CrossRef]
- Luo, Z.; Liu, L.; Chen, J.; Liu, Y.; Su, Z. Spontaneous smile recognition for interest detection. In Proceedings of the 2016 7th Chinese Conference on Pattern Recognition (CCPR), Chengdu, China, 3–7 November 2016; pp. 119–130. [Google Scholar] [CrossRef]
- Chen, J.; Wang, G.S.; Zhang, K.; Wang, G.H.; Liu, L. A pilot study on evaluating children with autism spectrum disorder using computer games. Comput. Hum. Behav. 2019, 90, 204–214. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 23th IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops (CVPR-Workshops), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the 2015 26th British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar] [CrossRef]
- Chen, J.; Xu, R.; Liu, L. Deep peak-neutral difference feature for facial expression recognition. Multimed. Tools Appl. 2018, 77, 29871–29887. [Google Scholar] [CrossRef]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y. Peak-piloted deep network for facial expression recognition. In Proceedings of the 2016 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 425–442. [Google Scholar] [CrossRef]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the 2018 31th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 2168–2177. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July; pp. 1125–1134. [CrossRef]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; PietikäInen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Liu, L.; Gui, W.; Zhang, L.; Chen, J. Real-time pose invariant spontaneous smile detection using conditional random regression forests. Optik 2019, 182, 637–657. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the 2016 IEEE Winter Conference on Application of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.K.; Chellappa, R. Facenet2expnet: Regularizing a deep face recognition net for expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, T.; Mao, Q.; Xu, C. Joint pose and expression modeling for facial expression recognition. In Proceedings of the 2018 31th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 3359–3368. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Z.; Yin, L. Identity-adaptive facial expression recognition through expression regeneration using conditional generative adversarial networks. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 294–301. [Google Scholar] [CrossRef]
- Fabiano, D.; Canavan, S. Deformable synthesis model for emotion recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the 2020 33th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 6897–6906. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Gan, Y.; Chen, J.; Yang, Z.; Xu, L. Multiple Attention Network for Facial Expression Recognition. IEEE Access 2020, 8, 7383–7393. [Google Scholar] [CrossRef]
- Zhu, J.; Luo, B.; Zhao, S.; Ying, S.; Zhao, X.; Gao, Y. IExpressNet: Facial Expression Recognition with Incremental Classes. In Proceedings of the 2020 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2899–2908. [Google Scholar] [CrossRef]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Q.; Liu, G. Deeper cascaded peak-piloted network for weak expression recognition. Vis. Comput. 2018, 34, 1691–1699. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Chen, S.; Shi, Z.; Cai, J. Facial motion prior networks for facial expression recognition. In Proceedings of the 2019 33th IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the 2015 15th IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 2983–2991. [Google Scholar] [CrossRef]
- Kuo, C.M.; Lai, S.H.; Sarkis, M. A compact deep learning model for robust facial expression recognition. In Proceedings of the 2018 31th IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-Workshops), Salt Lake City, UT, USA, 19–21 June 2018; pp. 2121–2129. [Google Scholar] [CrossRef]
- Meng, D.; Peng, X.; Wang, K.; Qiao, Y. Frame attention networks for facial expression recognition in videos. In Proceedings of the 2019 26th IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3866–3870. [Google Scholar] [CrossRef]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the 2018 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar] [CrossRef]
- Ekman, R. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, UK, 1997. [Google Scholar] [CrossRef]
- Cugu, I.; Sener, E.; Akbas, E. MicroExpNet: An Extremely Small and Fast Model For Expression Recognition From Face Images. In Proceedings of the 2019 9th International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Justin, J.; Alexandre, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the 2016 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Fabian Benitez-Quiroz, C.; Srinivasan, R.; Martinez, A.M. Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the 2016 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar] [CrossRef]
- FiveCrop. Available online: https://pytorch.org/docs/stable/torchvision/transforms.html (accessed on 23 March 2021).
- Kim, Y.; Yoo, B.; Kwak, Y.; Choi, C.; Kim, J. Deep generative-contrastive networks for facial expression recognition. arXiv 2017, arXiv:1703.07140. [Google Scholar]
- Ming, Z.; Xia, J.; Luqman, M.M.; Burie, J.C.; Zhao, K. Dynamic Multi-Task Learning for Face Recognition with Facial Expression. arXiv 2019, arXiv:1911.03281. [Google Scholar]
- Sikka, K.; Sharma, G.; Bartlett, M. Lomo: Latent ordinal model for facial analysis in videos. In Proceedings of the 2016 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5580–5589. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anger | Disgust | Fear | Happiness | Sadness | Surprise | |
|---|---|---|---|---|---|---|
| CK+ | 13.07% | 20.07% | 10.68% | 24.35% | 10.20% | 21.63% |
| Oulu-CASIA | 17.58% | 15.18% | 17.68% | 17.60% | 15.73% | 16.22% |
| Methods | ACC(%) | Image/Sequence |
|---|---|---|
| SD-CNN (Ours) | 99.7 | Image |
| DeRL [12] | 99.3 | Image |
| FN2EN [18] | 98.6 | Image |
| FMPN [28] | 98.0 | Image |
| VGG-face (fine-tuned) [8] | 94.9 | Image |
| GoogLeNet (fine-tuned) [17] | 95.3 | Image |
| MicroExpNet [34] | 96.9 | Image |
| MultiAttention [24] | 96.4 | Image |
| DSAE [26] | 95.8 | Image |
| GCNet [40] | 97.3 | Image |
| DynamicMTL [41] | 99.1 | Image |
| CompactCNN (frame-based) [30] | 97.4 | Image |
| IA-gen [20] | 96.6 | Image |
| FAN [31] | 99.7 | Sequence |
| FAN(w/o attention) [31] | 99.1 | Sequence |
| CompactCNN [30] | 98.5 | Sequence |
| DTAGN(Joint) [29] | 97.3 | Sequence |
| CPPN [27] | 98.3 | Sequence |
| DPND [10] | 94.4 | Sequence |
| PPDN [11] | 99.3 | Sequence |
| Methods | ACC(%) | Image/Sequence |
|---|---|---|
| SD-CNN (Ours) | 91.3 | Image |
| FN2EN [18] | 87.7 | Image |
| DeRL [12] | 88.0 | Image |
| GoogLeNet (fine-tuned) [17] | 79.2 | Image |
| VGG-face (fine-tuned) [8] | 72.5 | Image |
| GCNet [40] | 86.4 | Image |
| DynamicMTL [41] | 89.6 | Image |
| MicroExpNet [34] | 85.8 | Image |
| MultiAttention [24] | 80.2 | Image |
| IA-gen [20] | 88.92 | Image |
| PPDN [11] | 84.6 | Sequence |
| DPND [10] | 75.3 | Sequence |
| DTAGN(Joint) [29] | 81.5 | Sequence |
| LOMO [42] | 82.1 | Sequence |
| CompactCNN [30] | 88.6 | Sequence |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Jiang, R.; Huo, J.; Chen, J. Self-Difference Convolutional Neural Network for Facial Expression Recognition. Sensors 2021, 21, 2250. https://doi.org/10.3390/s21062250
Liu L, Jiang R, Huo J, Chen J. Self-Difference Convolutional Neural Network for Facial Expression Recognition. Sensors. 2021; 21(6):2250. https://doi.org/10.3390/s21062250
Chicago/Turabian StyleLiu, Leyuan, Rubin Jiang, Jiao Huo, and Jingying Chen. 2021. "Self-Difference Convolutional Neural Network for Facial Expression Recognition" Sensors 21, no. 6: 2250. https://doi.org/10.3390/s21062250
APA StyleLiu, L., Jiang, R., Huo, J., & Chen, J. (2021). Self-Difference Convolutional Neural Network for Facial Expression Recognition. Sensors, 21(6), 2250. https://doi.org/10.3390/s21062250