
Smart Assistive Architecture for the Integration of IoT Devices, Robotic Systems, and Multimodal Interfaces in Healthcare Environments





Abstract
1. Introduction
2. State-of-the-Art
3. System Architecture
3.1. Main Controller
- control the physical devices connected to the Zwave network as well as the visualization of their data via the VeraLite controller, which controls the Zwave network. The connection with the VeraLite controller is by TCP/IP (Transmission Control Protocol/Internet Protocol) and REST (REpresentational State Transfer) commands;
- control the physical devices connected to the 6LoWPAN network via a border router connected via USB, which allows communication with the 6LoWPAN wireless sensor network;
- control devices connected to the 802.15.4 networks (like the robotic arm) thanks to the Xbee module, connected via USB; and
- control the physical devices connected to the Wi-Fi/Bluetooth network;
3.2. IoT Interface
3.3. Robot Interface
3.4. User Interface
- touch: provided directly by the tablet. The GUI will emit events as a result of the interaction with its elements on the touch screen;
- eye control: based on the data given by the device Tobii EyeX, the system is able to react to commands made by the user’s gaze and winks;
- voice control: based on the Sphinx library, it allows for control of the room with voice commands (equivalent to the commands written in the tablet PC); and
- gesture control: based on the 3D Kinect sensor by which the system is able to react to gestures made by the user.
4. Assistive Robotic Arm
4.1. Design Requirements
- The arm should be low-cost.
- The arm must be able to support, in all its ranges of movement, the weight of the tablet PC (Microsoft Surface model), with a weight of around 770 g.
- The use of motors with low torque is required. In this way, it becomes physically impossible for them to pose a risk to users since the force they are able to generate is not sufficient to pose a danger.
- The use of low-torque motors implies a compensation of the weight of the arm itself so that the motors must be loaded with the lowest possible weight. This is achieved through mechanisms of four coupled bars.
- The choice of these motors implies a mechanical amplification in the transmission of the movement. The motors are located in the base, and the torque is transmitted to the joints by threads. This lowers the inertia of the arm and eases gravitational compensation. The transmission works only in one direction, that is, to raise the end of the arm. The opposite direction will be achieved by releasing the thread and by letting the weight of the arm lower it down. The patient cannot suffer any damage if he or she is in the trajectory of the robot because it is not able to exert an active force on the patient. The only load supported will be the weight of the tablet once the load is compensated.
- As shown in Figure 4a, horizontal movement is made by friction. In this way, in the case of impact, the actuator would slide, ensuring its intrinsic safety.
4.2. Electromechanical Design
4.3. Final Prototype
5. Multimodal Interface
5.1. Eye-Based Control
5.2. Gesture-Based Control
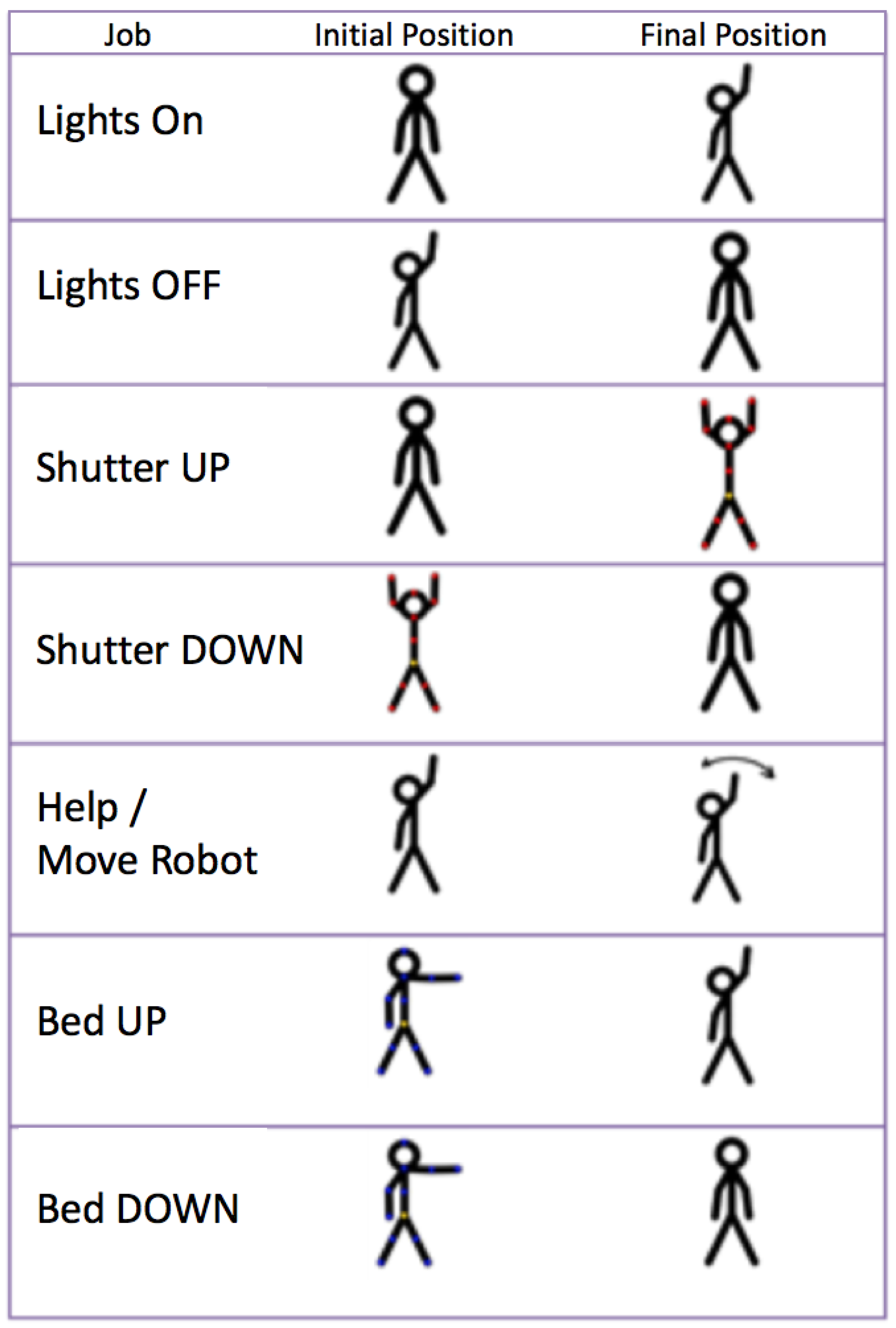
- Turn on and off the lighting of the room.
- Open and close the blinds.
- Request attention or move the robot in front of the user.
- Raise and lower the backrest of the bed.
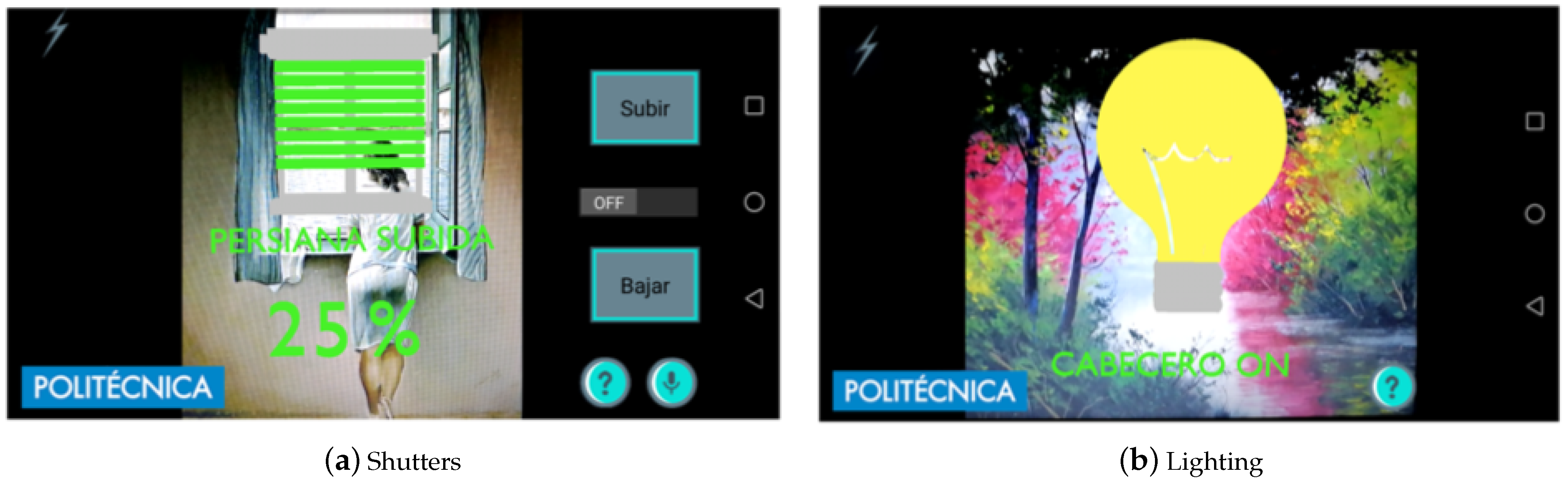
5.3. Voice-Based Control
5.4. Augmented Reality Interface
6. Results and Discussion
6.1. Smart Room
- The Zwave network connects Zwave devices: lights; shutters; and water, temperature, and door sensors. It is based on commercial devices.
- The 6LowPAN network is based on Zolertia Z1 motes running the Contiki OS. They are used to control the bed and to monitor its position. The bed is an electrically adjustable model that has been modified to connect it to the network. The head and feet parts have been sensorized and the motor can be remotely actuated by a relay, but the original wired remote controller of the bed remains operative at any moment. The bed system becomes consequently another node of the room. These modules form a small sensor network, with one of the modules (connected to the Raspberry) acting as the border router.
- The Xbee-based network is used to communicate with the robotic arm. It uses the 802.15.4 protocol (as well as 6LoWPAN in its lower levels), which is a light low-consuming protocol.
- Finally, the Wi-Fi network is used to communicate the main controller (Raspberry Pi) with the Zwave controller (VeraLite), the tablet PC, and other devices or robots in the room.
6.2. Validation Tests
6.2.1. Participants
Eligibility Criteria
6.2.2. Eye-Control Test: Blinking Time
6.2.3. Eye-Control Test: User Experience
- 1.
- When you start the program, click on the connect button to interact with the room.
- 2.
- From the main screen, press the configuration button and create your own user using the Create User button.
- 3.
- Add a favorite on the main screen of the application.
- 4.
- Press the Back button to return to the main screen and, once inside it, press the Eyes button. From this moment, the application can be used only with the eyes. To accomplish this, you must stare at the button you want to press.
- 5.
- Press the Alert button in the Favourite box of the main screen.
- 6.
- Access the Actuators screen to observe the changes made.
- 7.
- Interact with the different actuators until they are all turned off.
- 8.
- Return to the main screen using the Back button.
- 9.
- Change the operating mode to Wink mode (to do this, close your eyes for the amount of time you have set in the configuration screen and make sure that the mode has been changed to wink in the main screen) and enter the sensor screen.
- 10.
- Once all the sensors are observed, return to the main screen and interact with the buttons previously added to the favorite group.
- 11.
- Activate the Staring mode again (performing the same operation as in the previous step) and, finally, select the Touch operation mode.
- 1.
- Are the instructions for the use of the application clear and adequate?
- 2.
- Is the use of the various buttons intuitive?
- 3.
- How difficult was the interaction with the buttons in the winking-mode?
- 4.
- How difficult was the interaction with the buttons in the staring-mode?
- 5.
- How difficult was it to make the change between both modes of operation?
- 6.
- How well do you think you understand what state each actuator is in?
- 7.
- How difficult was the interaction with the available predefined users?
- 8.
- To what degree do you think the application will be useful for patients?
- 9.
- What overall score would you give to the application after your user experience?
6.2.4. Voice Control Test
User: Larry.Larry: Hello! What do you want to do?User: Lights.Larry: Entering the menu lights. Accept or cancel.User: AcceptUser: LarryLarry: Hello! What do you want to do?User: HeadboardLarry: Do you want to turn on the headboard light? Accept or cancel.User: Accept.
6.2.5. Gesture Control Test
6.2.6. Augmented Reality Test: Recognition Distance
6.2.7. Augmented Reality Test: Usability
6.3. Discussion
7. Conclusions and Future Work
Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 6LoWPAN | IPv6 over Low-Power Wireless Personal Area Networks |
| AAL | Ambient Assisted Living |
| AR | Augmented Reality |
| EMG | Electromyography |
| GUI | Graphical User Interface |
| IoT | Internet of Things |
| IoMT | Internet of Medical Things |
| IP | Internet Protocol |
| IrDA | Infrared Data Association |
| LAN | Local Area Network |
| MQTT | Message Queuing Telemetry Transport |
| REST | Representational State Transfer |
| ROS | Robot Operating System |
| SDK | Software Development Kit) |
| TCP | Transmission Control Protocol |
| UAV | Unmanned Aerial Vehicle |
| VR | Virtual Reality |
| WPAN | Wireless Personal Area Networks |
References
- Raffaeli, L.; Montanini, L.; Gambi, E.; Spinsante, S. User interfaces in smart assistive environments: Requirements, devices, applications. In Handbook of Research on Human-Computer Interfaces, Developments, and Applications; IGI Global: Pennsylvania, PA, USA, 2016; pp. 420–443. [Google Scholar] [CrossRef]
- Bui, H.; Chong, N.Y. An Integrated Approach to Human-Robot-Smart Environment Interaction Interface for Ambient Assisted Living. In Proceedings of the IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO), Genova, Italy, 27–29 September 2018; pp. 32–37. [Google Scholar] [CrossRef]
- Sacristan, M.; Brunete, A.; Hernando, M.; Gambao, E. Robohealth: Smart Room Interface for Hospital Patients. In Proceedings of the Robots for Assisted Living Workshop, IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 5 October 2018. [Google Scholar]
- Wada, K.; Shibata, T.; Saito, T.; Tanie, K. Effects of robot-assisted activity for elderly people and nurses at a day service center. Proc. IEEE 2004, 92, 1780–1788. [Google Scholar] [CrossRef]
- Chang, W.; Šabanovic, S. Potential use of robots in Taiwanese nursing homes. In Proceedings of the 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Tokyo, Japan, 3–6 March 2013; pp. 99–100. [Google Scholar] [CrossRef]
- Park, C.; Kang, S.; Kim, J.; Oh, J. A study on service robot system for elder care. In Proceedings of the 9th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Daejeon, Korea, 26–28 November 2012; pp. 546–547. [Google Scholar] [CrossRef]
- Stojmenski, A.; Joksimoski, B.; Chorbev, I.; Trajkovikj, V. Smart home environment aimed for people with physical disabilities. In Proceedings of the IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016; pp. 13–18. [Google Scholar] [CrossRef]
- Broxvall, M.; Gritti, M.; ASaffiotti, A.; Seo, B.-S.; Cho, Y.-J. PEIS Ecology: Integrating robots into smart environments. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; pp. 212–218. [Google Scholar] [CrossRef]
- Park, K.; Lee, H.; Kim, Y.; Bien, Z.Z. A Steward Robot for Human-Friendly Human-Machine Interaction in a Smart House Envi-ronment. IEEE Trans. Autom. Sci. Eng. 2008, 5, 21–25. [Google Scholar] [CrossRef]
- Cavallo, F.; Aquilano, M.; Bonaccorsi, M.; Limosani, R.; Manzi, A.; Carrozza, M.C.; Dario, P. On the design, development and experimentation of the ASTRO assistive robot integrated in smart environments. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4310–4315. [Google Scholar] [CrossRef]
- Matsumoto, S. Echonet: A Home Network Standard. IEEE Pervasive Comput. 2010, 9, 88–92. [Google Scholar] [CrossRef]
- Anghel, I.; Cioara, T.; Moldovan, D.; Antal, M.; Pop, C.D.; Salomie, I.; Pop, C.B.; Chifu, V.R. Smart Environments and Social Ro-bots for Age-Friendly Integrated Care Services. Int. J. Environ. Res. Public Health 2020, 17, 3801. [Google Scholar] [CrossRef] [PubMed]
- Marquez, P.C.; Alfredo, J. Avances en el desarrollo de un prototipo de robot asistencial para personas con limitaciones de mo-vilidad. Ingenio Magno 2013, 4, 53–56. [Google Scholar]
- Uehara, T.S.H.; Higa, H. A mobile robotic arm for people with severe disabilities. In Proceedings of the 3rd IEEE RAS and EMBS International Conference on Biomedical Robotics and Biomechatronics, University of Tokyo, Tokyo, Japan, 26–29 September 2010. [Google Scholar]
- Arai, K.; Yajima, K. Robot arm utilized having meal support system based on computer input by human eyes only. J. Hum. Comput. Interact. (IJHCI) 2011, 2, 1–9. [Google Scholar]
- Chang, P.H.; Park, H.S. Development of a robotic arm for handicapped people: A task-oriented design approach. Auton. Robot. 2003, 15, 81–92. [Google Scholar] [CrossRef]
- Ali, S.; Madariaga, M.G.; McGeary, D.C.; Pruehsner, W.R.; Enderle, J.D. The Assistive Robotic Arm. In Proceedings of the 33rd Annual Northeast Bioengineering Conference, Stony Brook, NY, USA, 10–11 March 2007; pp. 291–292. [Google Scholar]
- Groothuis, S.S.; Stramigioli, S.; Carloni, R. Lending a helping hand: Toward novel assistive robotic arms. IEEE Robot. Autom. Mag. 2013, 20, 20–29. [Google Scholar] [CrossRef]
- Zanella; Mason, F.; Pluchino, P.; Cisotto, G.; Orso, V.; Gamberini, L. Internet of Things for Elderly and Fragile People. arXiv 2020, arXiv:2006.05709. [Google Scholar]
- Cisotto, G.; Casarin, E.; Tomasin, S. Requirements and Enablers of Advanced Healthcare Services over Future Cellular Systems. IEEE Commun. Mag. 2020, 58, 76–81. [Google Scholar] [CrossRef]
- Sharma, R.; Pavlovic, V.I.; Huang, T.S. Toward multimodal human-computer interface. Proc. IEEE 1998, 86, 853–869. [Google Scholar] [CrossRef]
- Raisamo, R. Multimodal Human-Computer Interaction: A Constructive and Empirical Study; Tampere University Press: Tampere, Finland, 1999; p. 85. [Google Scholar]
- Gyurian, N.; Drozd, I.; Rozinaj, G. Multimodal interface for smart home. In Proceedings of the International Symposium ELMAR, Zadar, Croatia, 12–14 September 2016; pp. 283–286. [Google Scholar] [CrossRef]
- Jeon, Y.; Ahn, H. A multimodal ubiquitous interface system using smart phone for human-robot interaction. In Proceedings of the 8th Interna-tional Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Incheon, Korea, 23–26 November 2011; pp. 764–767. [Google Scholar] [CrossRef]
- Maimon-Mor, R.O.; Fernandez-Quesada, J.; Zito, G.A.; Konnaris, C.; Dziemian, S.; Faisal, A.A. Towards free 3D end-point control for robotic-assisted human reaching using binocular eye tracking. In Proceedings of the International Conference on Rehabilitation Robotics (ICORR), London, UK, 17–20 July 2017; pp. 1049–1054. [Google Scholar] [CrossRef]
- Tostado, P.M.; Abbott, W.W.; Faisal, A.A. 3D gaze cursor: Continuous calibration and end-point grasp control of robotic actuators. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3295–3300. [Google Scholar] [CrossRef]
- Mtshali, P.; Khubisa, F. A Smart Home Appliance Control System for Physically Disabled People. In Proceedings of the Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 6–8 March 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Këpuska, V.; Bohouta, G. Next-generation of virtual personal assistants (Microsoft Cortana, Apple Siri, Amazon Alexa and Google Home). In Proceedings of the IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 99–103. [Google Scholar] [CrossRef]
- Nasr, M.; Karray, F.; Quintana, Y. Human Machine Interaction Platform for Home Care Support System. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 4210–4215. [Google Scholar] [CrossRef]
- Elleuch, H.; Wali, A.; Alimi, A.M. Smart Tablet Monitoring by a Real-Time Head Movement and Eye Gestures Recognition Sys-tem. In Proceedings of the International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 August 2014; pp. 393–398. [Google Scholar] [CrossRef]
- Topal, C.; Gunal, S.; Koçdeviren, O.; Doğan, A.; Gerek, Ö.N. A Low-Computational Approach on Gaze Estimation With Eye Touch System. IEEE Trans. Cybern. 2014, 44, 228–239. [Google Scholar] [CrossRef] [PubMed]
- Noronha, B.; Dziemian, S.; Zito, G.A.; Konnaris, C.; Faisal, A.A. Wink to grasp: Comparing eye, voice and EMG gesture control of grasp with soft-robotic gloves. In Proceedings of the International Conference on Rehabilitation Robotics (ICORR), London, UK, 17–20 July 2017; pp. 1043–1048. [Google Scholar]
- Sushmit, S.; Haque, F.M.; Shahriar, M.; Bhuiyan, S.A.M.; Sarkar, M.A.R. Design of a gesture controlled robotic gripper arm using neural networks. In Proceedings of the IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 248–251. [Google Scholar] [CrossRef]
- Fall, C.L.; Quevillon, F.; Blouin, M.; Latour, S.; Campeau-Lecours, A.; Gosselin, C.; Gosselin, B. A Multimodal Adaptive Wireless Control Interface for People with Upper-Body Disabilities. IEEE Trans. Biomed. Circ. Syst. 2018, 12, 564–575. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.; Kim, D.; Seo, Y. Controlling Mobile Robot Using IMU and EMG Sensor-Based Gesture Recognition. In Proceedings of the Ninth International Conference on Broadband and Wireless Computing, Communication and Applications, Guangdong, China, 8–10 November 2014; pp. 554–557. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, X.; Zhong, Z.; Zhang, Y. ROS-based UAV control using hand gesture recognition. In Proceedings of the 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 6795–6799. [Google Scholar] [CrossRef]
- Lamb, K.; Madhe, S. Hand gesture recognition based bed position control for disabled patients. In Proceedings of the Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; pp. 170–174. [Google Scholar] [CrossRef]
- Ransalu, S.; Kumarawadu, S. A robust vision-based hand gesture recognition system for appliance control in smart homes. In Proceedings of the IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC 2012), Hong Kong, China, 12–15 August 2012; pp. 760–763. [Google Scholar] [CrossRef]
- Handosa, M.; Gracanin, D.; Elmongui, H.G.; Ciambrone, A. Painting with light: Gesture based light control in architectural set-tings. In Proceedings of the IEEE Symposium on 3D User Interfaces (3DUI), Los Angeles, CA, USA, 18–19 March 2017; pp. 249–250. [Google Scholar] [CrossRef]
- Czuszynski, K.; Ruminski, J. Towards Contactless, Hand Gestures-Based Control of Devices. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3298–3303. [Google Scholar] [CrossRef]
- Petersen, N.; Stricker, D. Continuous natural user interface: Reducing the gap between real and digital world. In Proceedings of the 2009 IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 23–26. [Google Scholar]
- Kassem, I.S.; Evinger, C. Asymmetry of blinking. Investig. Ophthalmol. Vis. Sci. 2006, 47, 195–201. [Google Scholar] [CrossRef] [PubMed]
- Coşar, S.; Fernandez-Carmona, M.; Agrigoroaie, R.; Pages, J.; Ferland, F.; Zhao, F.; Yue, S.; Bellotto, N.; Tapus, A. ENRICHME: Perception and Interaction of an Assistive Robot for the Elderly at Home. Int. J. Soc. Robot. 2020, 12, 779–805. [Google Scholar] [CrossRef]
- Araujo, J.M.; Zhang, G.; Hansen, J.P.P.; Puthusserypady, S. Exploring Eye-Gaze Wheelchair Control. In ACM Symposium on Eye Tracking Research and Applications (ETRA ’20 Adjunct); Association for Computing Machinery: New York, NY, USA, 2020; Volume 16, pp. 1–8. [Google Scholar] [CrossRef]
- Rubí, S.; Jesús, N.; Gondim, L.; Paulo, R. IoMT Platform for Pervasive Healthcare Data Aggregation, Processing, and Sharing Based on OneM2M and OpenEHR. Sensors 2019, 19, 4283. [Google Scholar] [CrossRef] [PubMed]
- Rincon, J.A.; Guerra-Ojeda, S.; Carrascosa, C.; Julian, V. An IoT and Fog Computing-Based Monitoring System for Cardio-vascular Patients with Automatic ECG Classification Using Deep Neural Networks. Sensors 2020, 20, 7353. [Google Scholar] [CrossRef] [PubMed]
- Al-khafajiy, M.; Webster, L.; Baker, T.; Waraich, A. Towards fog driven IoT healthcare: Challenges and framework of fog computing in healthcare. In Proceedings of the 2nd International Conference on Future Networks and Distributed Systems (ICFNDS ’18). Association for Computing Machinery, New York, NY, USA, 26–27 June 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Pietrabissa, G.; Zoppis, I.; Mauri, G.; Ghiretti, R.; Giusti, E.M.; Cattivelli, R.; Spatola, C.; Manzoni, G.M.; Castelnuovo, G. System of Nudge Theory-Based ICT Applications for Older Citizens: The SENIOR Project. In Pervasive Computing Paradigms for Mental Health; Cipresso, P., Serino, S., Villani, D., Eds.; MindCare 2019; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2019; Volume 288. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Repetitions | Accuracy | Repeatability |
|---|---|---|---|
| 1 | 10 | <4 mm | <5 mm |
| 2 | 9 | <5 mm | <6 mm |
| Tries/Subjects | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 166 | 151 | 299 | 123 | 106 |
| 2 | 199 | 118 | 522 | 122 | 135 |
| 3 | 181 | 91 | 600 | 78 | 136 |
| 4 | 131 | 92 | 417 | 121 | 105 |
| 5 | 135 | 77 | 375 | 77 | 104 |
| 6 | 147 | 77 | 282 | 120 | 124 |
| 7 | 198 | 137 | 284 | 122 | 121 |
| 8 | 152 | 91 | 408 | 168 | 120 |
| 9 | 151 | 105 | 550 | 106 | 105 |
| 10 | 136 | 136 | 409 | 80 | 104 |
| Mean (ms) | 159.6 | 107.5 | 414.6 | 111.7 | 116.0 |
| STD (ms) | 25.4 | 26.5 | 112.5 | 28.0 | 12.9 |
| Tries/Subjects | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 120 | 150 | 286 | 119 | 226 |
| 2 | 149 | 151 | 386 | 121 | 210 |
| 3 | 104 | 136 | 100 | 135 | 256 |
| 4 | 120 | 180 | 161 | 154 | 240 |
| 5 | 104 | 160 | 289 | 116 | 241 |
| 6 | 121 | 150 | 316 | 116 | 285 |
| 7 | 135 | 148 | 281 | 190 | 255 |
| 8 | 89 | 147 | 151 | 160 | 255 |
| 9 | 91 | 163 | 243 | 146 | 210 |
| 10 | 149 | 151 | 314 | 161 | 285 |
| Mean (ms) | 118.2 | 153.6 | 252.7 | 141.8 | 246.3 |
| STD (ms) | 20.5 | 11.2 | 84.2 | 23.5 | 25.2 |
| Device/Distance (m) | 5 | 4.5 | 4 | 3.5 | 3 | 2.5 | 2 | 1.5 | 1 | 0.5 |
|---|---|---|---|---|---|---|---|---|---|---|
| Glasses AR Epson Moverio BT-200 | NO | NO | NO | NO | NO | NO | NO | NO | YES | YES |
| Huawei HONOR 8 | NO | NO | NO | NO | NO | NO | NO | YES | YES | YES |
| BQ E5 | NO | NO | NO | NO | NO | NO | NO | YES | YES | YES |
| Samsung Galaxy S7 | NO | NO | NO | NO | NO | NO | NO | YES | YES | YES |
| Huawei P9 | NO | NO | NO | NO | NO | NO | NO | YES | YES | YES |
| Device/Distance (m) | 5 | 4.5 | 4 | 3.5 | 3 | 2.5 | 2 | 1.5 | 1 | 0.5 |
|---|---|---|---|---|---|---|---|---|---|---|
| Glasses AR Epson Moverio BT-200 | NO | NO | NO | YES | YES | YES | YES | YES | YES | YES |
| Huawei HONOR 8 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| BQ E5 | NO | NO | YES | YES | YES | YES | YES | YES | YES | YES |
| Samsung Galaxy S7 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| Huawei P9 | NO | YES | YES | YES | YES | YES | YES | YES | YES | YES |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brunete, A.; Gambao, E.; Hernando, M.; Cedazo, R. Smart Assistive Architecture for the Integration of IoT Devices, Robotic Systems, and Multimodal Interfaces in Healthcare Environments. Sensors 2021, 21, 2212. https://doi.org/10.3390/s21062212
Brunete A, Gambao E, Hernando M, Cedazo R. Smart Assistive Architecture for the Integration of IoT Devices, Robotic Systems, and Multimodal Interfaces in Healthcare Environments. Sensors. 2021; 21(6):2212. https://doi.org/10.3390/s21062212
Chicago/Turabian StyleBrunete, Alberto, Ernesto Gambao, Miguel Hernando, and Raquel Cedazo. 2021. "Smart Assistive Architecture for the Integration of IoT Devices, Robotic Systems, and Multimodal Interfaces in Healthcare Environments" Sensors 21, no. 6: 2212. https://doi.org/10.3390/s21062212
APA StyleBrunete, A., Gambao, E., Hernando, M., & Cedazo, R. (2021). Smart Assistive Architecture for the Integration of IoT Devices, Robotic Systems, and Multimodal Interfaces in Healthcare Environments. Sensors, 21(6), 2212. https://doi.org/10.3390/s21062212