
SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi



Abstract
:1. Introduction
- We carefully analyze the existing data sets and methods proposed for WiFi based human activity recognition and identify the issues. We observe that the public data sets generally have insufficient data and the records are pre-processed insufficiently.
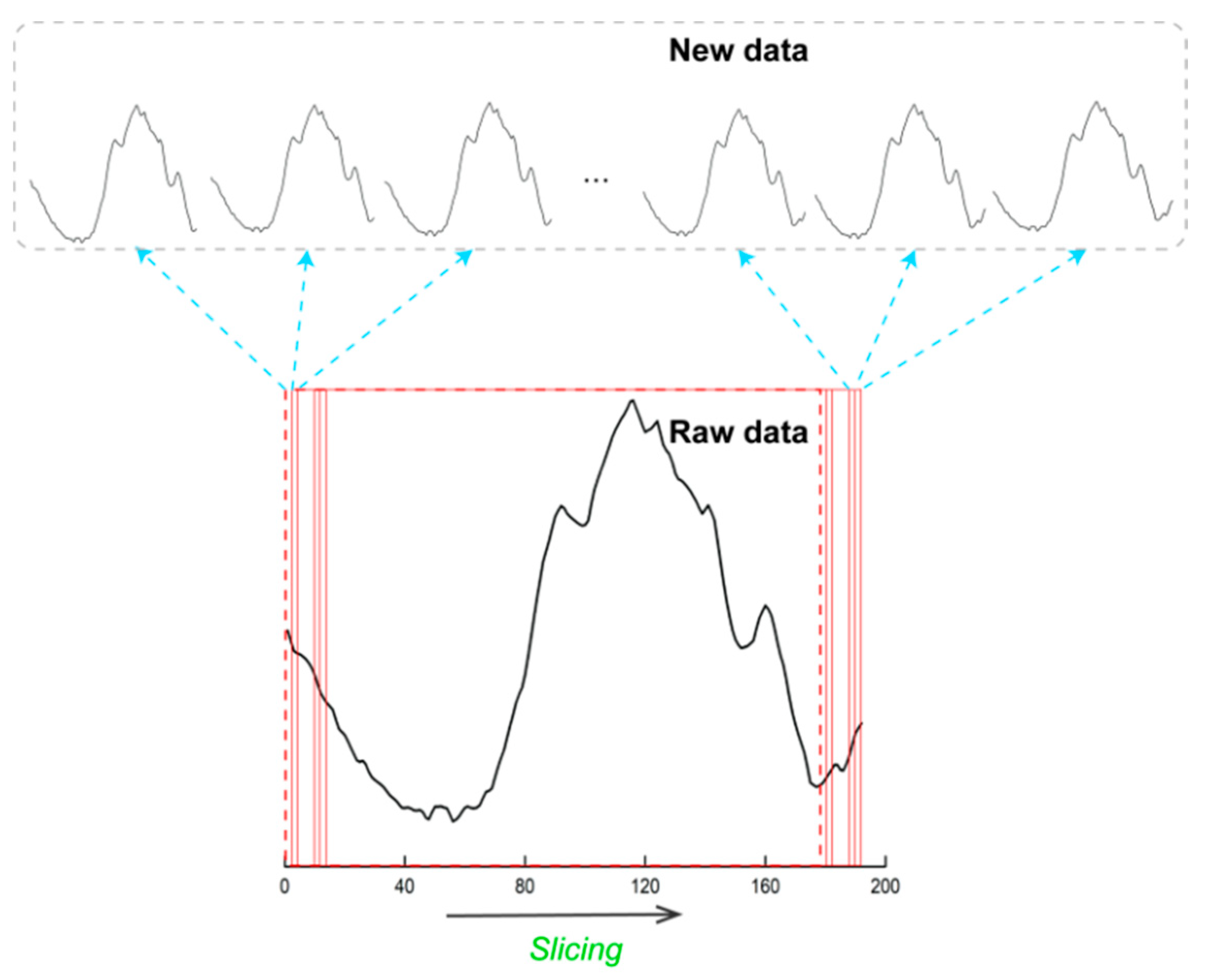
- Considering the existing problems, we first present a window slicing method for CSI data. By slicing on the original data, the size of data set increases. We perform experiments on the existing data sets to verify the effectiveness of the proposed method.
- We present a WiFi based activity recognition data set named CSIGe. Furthermore, we perform experiments on CSIGe to verify the effectiveness of the proposed window slicing method.
2. Preliminary
2.1. RSSI and CSI
2.2. The Survey of Public Data Sets for WiFi Based Activity Recognition
3. Methods
3.1. Window Slicing
3.2. Data Collection
3.2.1. Hardware
3.2.2. Environment Settings
- The Room1 is a 10 × 13 m room. There are three desks with the size of 5 × 2 m in Room1. There are three windows on the right side of the room. The transmitter(Tx) and receiver(Rx) are separated by 2.6 m.
- The Room2 is a 10 × 4 m room. There are two desks in Room2, the size of the desk on the left is 3 × 1 m and the size of right desk is 7 × 2 m. There is a window on the right side of the room. The distance between transmitter(Tx) and receiver(Rx) is 2.6 m.
3.2.3. Activity Types
4. Experiments
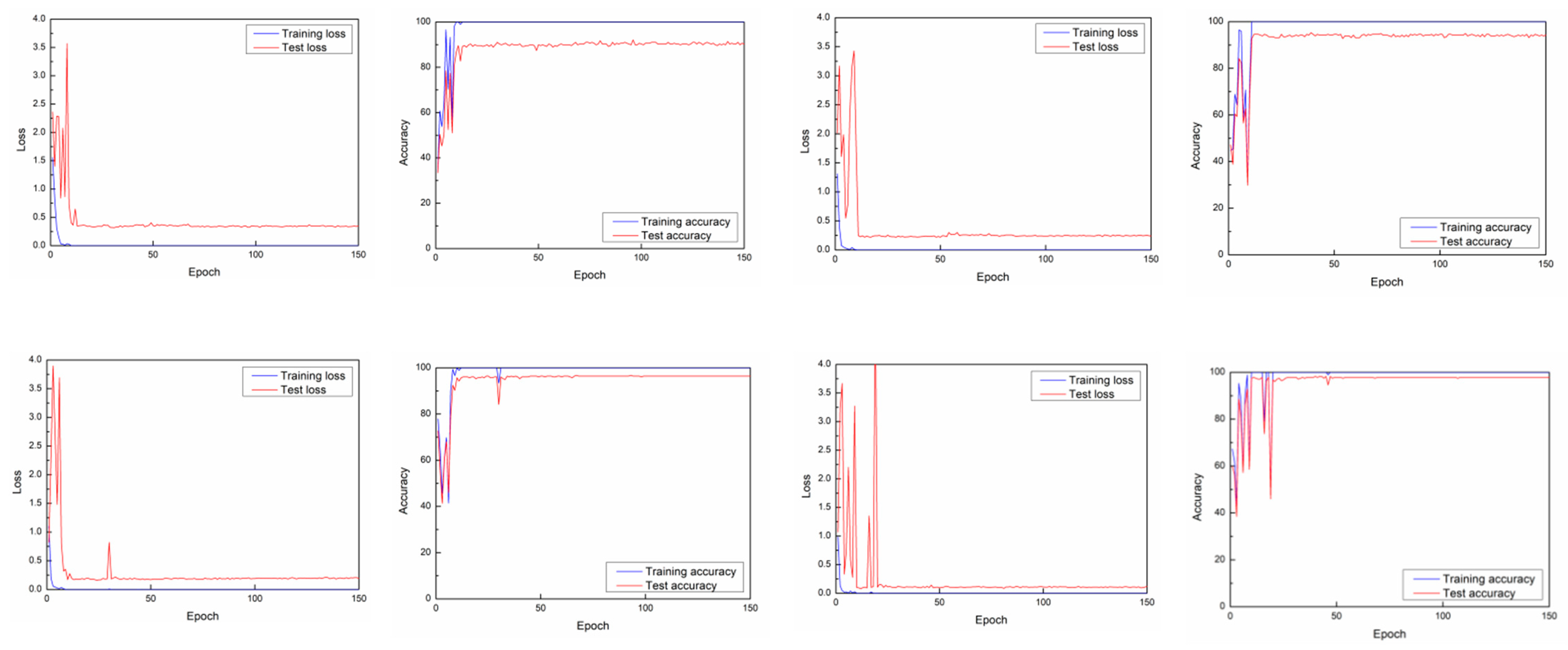
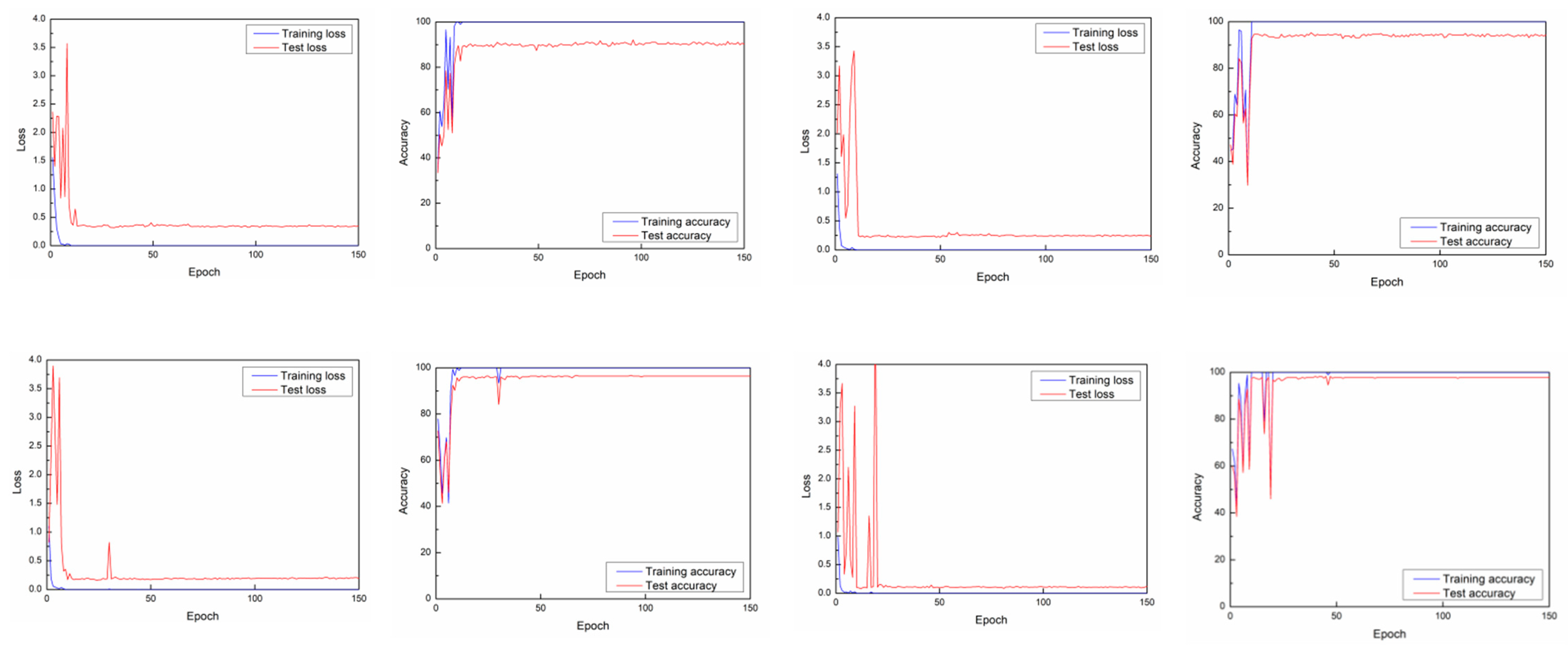
4.1. Window Slicing on ARIL
4.2. Data Collection and Processing
4.3. Window Slicing on CSIGe
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mihanpour, A.; Rashti, M.J.; Alavi, S.E. Human Action Recognition in Video Using DB-LSTM and ResNet. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 133–138. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A Real-Time Human Action Recognition System Using Depth and Inertial Sensor Fusion. IEEE Sens. J. 2016, 16, 773–781. [Google Scholar] [CrossRef]
- Nandy, A.; Saha, J.; Chowdhury, C.; Singh, K. Detailed Human Activity Recognition Using Wearable Sensor and Smartphones. In Proceedings of the 2019 International Conference on Opto-Electronics and Applied Optics (Optronix), Kolkata, India, 18–20 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sang, H.; Zhao, Z.; He, D.J.I.A. Two-Level Attention Model Based Video Action Recognition Network. IEEE Access 2019, 7, 118388–118401. [Google Scholar] [CrossRef]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; De Munari, I. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor localization via channel response. ACM Comput. Surv. (CSUR) 2013, 46, 25. [Google Scholar] [CrossRef]
- Chang, J.; Lee, K.; Lin, K.C.; Hsu, W. WiFi action recognition via vision-based methods. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2782–2786. [Google Scholar]
- Koike-Akino, T.; Wang, P.; Pajovic, M.; Sun, H.; Orlik, P. Fingerprinting-Based Indoor Localization with Commercial MMWave WiFi: A Deep Learning Approach. IEEE Access 2020. [Google Scholar] [CrossRef]
- Islam, M.T.; Nirjon, S. Wi-Fringe: Leveraging Text Semantics in WiFi CSI-Based Device-Free Named Gesture Recognition. arXiv 2019, arXiv:1908.06803. [Google Scholar]
- Ma, Y.; Zhou, G.; Wang, S.; Zhao, H.; Jung, W. SignFi: Sign Language Recognition Using WiFi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 23. [Google Scholar] [CrossRef]
- Dang, X.; Cao, Y.; Hao, Z.; Liu, Y. WiGId: Indoor Group Identification with CSI-Based Random Forest. Sensors 2020, 20, 4607. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Zhang, F.; Wu, C.; Wang, B.; Liu, K.J.R. A WiFi-Based Passive Fall Detection System. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1723–1727. [Google Scholar]
- Li, Q.; Li, M.; Ke, X.; Kong, W.; Yang, L.; Tang, Z.; Chen, X.; Fang, D. WisDriver:A WiFi and Smartphone Sensing System for Safely Driving. In Proceedings of the 2019 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2019; pp. 1–6. [Google Scholar]
- Han, C.; Wu, K.; Wang, Y.; Ni, L. WiFall: Device-Free Fall Detection by Wireless Networks. IEEE Trans. Mob. Comput. 2014, 16, 271–279. [Google Scholar]
- Nakamura, T.; Bouazizi, M.; Yamamoto, K.; Ohtsuki, T. Wi-Fi-CSI-based Fall Detection by Spectrogram Analysis with CNN. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI Based Passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2019, 18, 2714–2724. [Google Scholar] [CrossRef]
- Zou, H.; Zhou, Y.; Yang, J.; Gu, W.; Xie, L.; Spanos, C. Multiple Kernel Representation Learning for WiFi-Based Human Activity Recognition. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 268–274. [Google Scholar] [CrossRef]
- Zhang, L.; Ruan, X.; Wang, J. WiVi: A Ubiquitous Violence Detection System with Commercial WiFi Devices. IEEE Access 2020, 8, 6662–6672. [Google Scholar] [CrossRef]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless Fine-Grained Gesture Recognition Uses Channel State Information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Zhang, Y.; Qian, K.; Zhang, G.; Liu, Y.; Wu, C.; Yang, Z. Zero-Effort Cross-Domain Gesture Recognition with Wi-Fi. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Korea, 17–21 June 2019; pp. 313–325. [Google Scholar]
- Alazrai, R.; Awad, A.; Alsaify, B.A.; Hababeh, M.; Daoud, M.I. A dataset for Wi-Fi-based human-to-human interaction recognition. Data Brief 2020, 31, 105668. [Google Scholar] [CrossRef] [PubMed]
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6. [Google Scholar] [CrossRef]
- Cui, Z.; Chen, W. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Wang, F.; Feng, J.; Zhao, Y.; Zhang, X.; Zhang, S.; Han, J. Joint Activity Recognition and Indoor Localization with WiFi Fingerprints. IEEE Access 2019, 7. [Google Scholar] [CrossRef]
- Guo, L.; Guo, S.; Wang, L.; Lin, C.; Liu, J.; Lu, B.; Fang, J.; Liu, Z.; Shan, Z.; Yang, J. Wiar: A Public Dataset for Wifi-Based Activity Recognition. IEEE Access 2019, 7, 154935–154945. [Google Scholar] [CrossRef]
- Kaemarungsi, K. Distribution of WLAN received signal strength indication for indoor location determination. In Proceedings of the 2006 1st International Symposium on Wireless Pervasive Computing, Catalunya, Spain, 16–18 January 2006. [Google Scholar]
- Pires, R.P.; Wanner, L.F.; Frohlich, A.A. An efficient calibration method for RSSI-based location algorithms. In Proceedings of the 2008 6th IEEE International Conference on Industrial Informatics, Daejeon, Korea, 13–16 July 2008; pp. 1183–1188. [Google Scholar]
- Paul, A.S.; Wan, E.A. RSSI-Based Indoor Localization and Tracking Using Sigma-Point Kalman Smoothers. IEEE J. Sel. Top. Signal Process. 2009, 3, 860–873. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Chen, Y.; Gruteser, M.; Yang, J.; Liu, H. E-eyes: Device-free location-oriented activity identification using fine-grained WiFi signatures. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7 September 2014; pp. 617–628. [Google Scholar]
- Li, H.; Yang, W.; Wang, J.; Xu, Y.; Huang, L. WiFinger: Talk to your smart devices with finger-grained gesture. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016. [Google Scholar]
- Ali, K.; Liu, A.X.; Wang, W.; Shahzad, M. Keystroke Recognition Using WiFi Signals. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015; pp. 90–102. [Google Scholar]
- Hoang, M.K.; Schmalenstroeer, J.; Drueke, C.; Vu, D.H.T.; Haeb-Umbach, R. A hidden Markov model for indoor user tracking based on WiFi fingerprinting and step detection. In Proceedings of the 21st European Signal Processing Conference (EUSIPCO 2013), Marrakech, Morocco, 9–13 September 2013; pp. 1–5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Z.; Li, J.; Ma, S.; Ren, H. Speech Emotion Recognition Based on Residual Neural Network with Different Classifiers. In Proceedings of the 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 186–190. [Google Scholar]
- Zou, H.; Yang, J.; Das, H.P.; Liu, H.; Spanos, C.J. WiFi and Vision Multimodal Learning for Accurate and Robust Device-Free Human Activity Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set Name | Year | Activity Types | No. of Actors | No. of Scenarios | Total Instances |
|---|---|---|---|---|---|
| Wih2h [21] | 2020 | 12 | 40 pairs | 1 | 4800 |
| WiAR [25] | 2019 | 16 | 10 | 3 | 4800 |
| Widar3.0 [20] | 2019 | 16 | 16 | 3 | 17,000 |
| ARIL [24] | 2019 | 6 | 1 | 1 | 1394 |
| Signfi [10] | 2018 | 276 | 5 | 2 | 8280 |
| Window Size | 192 | 180 | 170 | 160 | 150 |
|---|---|---|---|---|---|
| ResNet1D-[1,1,1,1] | 88.13% | 90.29% | 92.45% | 96.76% | 97.12% |
| ResNet1D-[1,1,1,1]+ | 88.49% | 90.65% | 93.88% | 95.32% | 96.04% |
| Window Size | 192 | 180 | 170 | 160 | 150 |
|---|---|---|---|---|---|
| ResNet1D-[1,1,1,1] | 88.13% | 93.17% | 94.24% | 96.76% | 97.12% |
| ResNet1D-[1,1,1,1]+ | 88.49% | 93.88% | 94.96% | 96.4% | 96.4% |
| Location 1 in Room1 | Location 2 in Room1 | Location3 in Room1 | Location 4 in Room2 | Location 5 in Room2 | |
|---|---|---|---|---|---|
| Volunteer 1 | 113 | 114 | 116 | 112 | 114 |
| Volunteer 2 | 114 | 99 | 114 | 114 | 114 |
| Volunteer 3 | 115 | 113 | 115 | 115 | 116 |
| Volunteer 4 | 116 | 114 | 115 | 115 | 114 |
| Volunteer 5 | 115 | 115 | 114 | 114 | 114 |
| Slicing | 0:1800 | 0:1790 | 1:1791 | 2:1792 | 3:1793 | 4:1794 | 5:1795 | 6:1796 | 7:1797 | 8:1798 | 9:1799 | 10:1800 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Room1 | 76.25% | 77.13% | 80.94% | 81.52% | 82.4% | 83.58% | 85.04% | 85.63% | 86.22% | 86.22% | 87.1% | 87.98% |
| Room2 | 78.17% | 79.91% | 80.79% | 80.79% | 81.66% | 81.66% | 82.53% | 82.97% | 83.41% | 83.84% | 83.84% | 84.28% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Yin, K.; Tang, C. SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi. Sensors 2021, 21, 2181. https://doi.org/10.3390/s21062181
Li J, Yin K, Tang C. SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi. Sensors. 2021; 21(6):2181. https://doi.org/10.3390/s21062181
Chicago/Turabian StyleLi, Junyan, Kang Yin, and Chengpei Tang. 2021. "SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi" Sensors 21, no. 6: 2181. https://doi.org/10.3390/s21062181
APA StyleLi, J., Yin, K., & Tang, C. (2021). SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi. Sensors, 21(6), 2181. https://doi.org/10.3390/s21062181