
How to Represent Paintings: A Painting Classification Using Artistic Comments



Abstract
1. Introduction
- We propose a novel graph neural network method for art classification that uses features extracted from textual comments about art. In addition, on this basis, we propose a multitask learning model (MTL) to solve the different tasks using one model. This approach encourages the models to find common elements (and hence the context) between the different tasks. A comparison shows that our proposed approach performs state-of-the-art compared with traditional benchmarks that apply vision-based and text-based methods to classify art.
- Our method performs word embedding and creates labels using the dimension that has the highest value. The mean of the label is the same as the painting label; thus, by extracting the top 10 words that had higher values in each category, we find that the extracted words are highly correlated descriptions of labels.
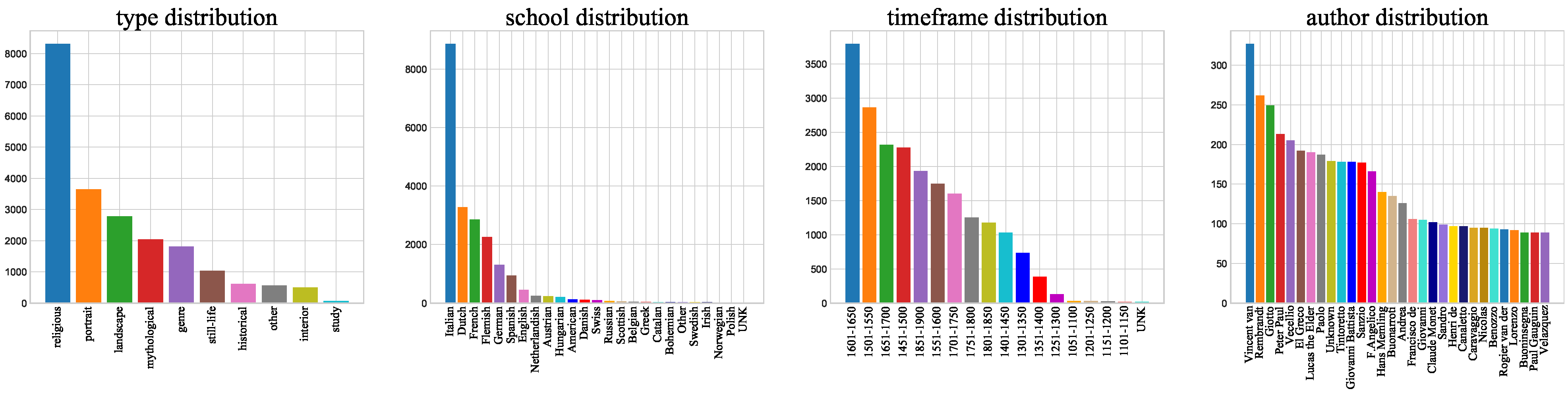
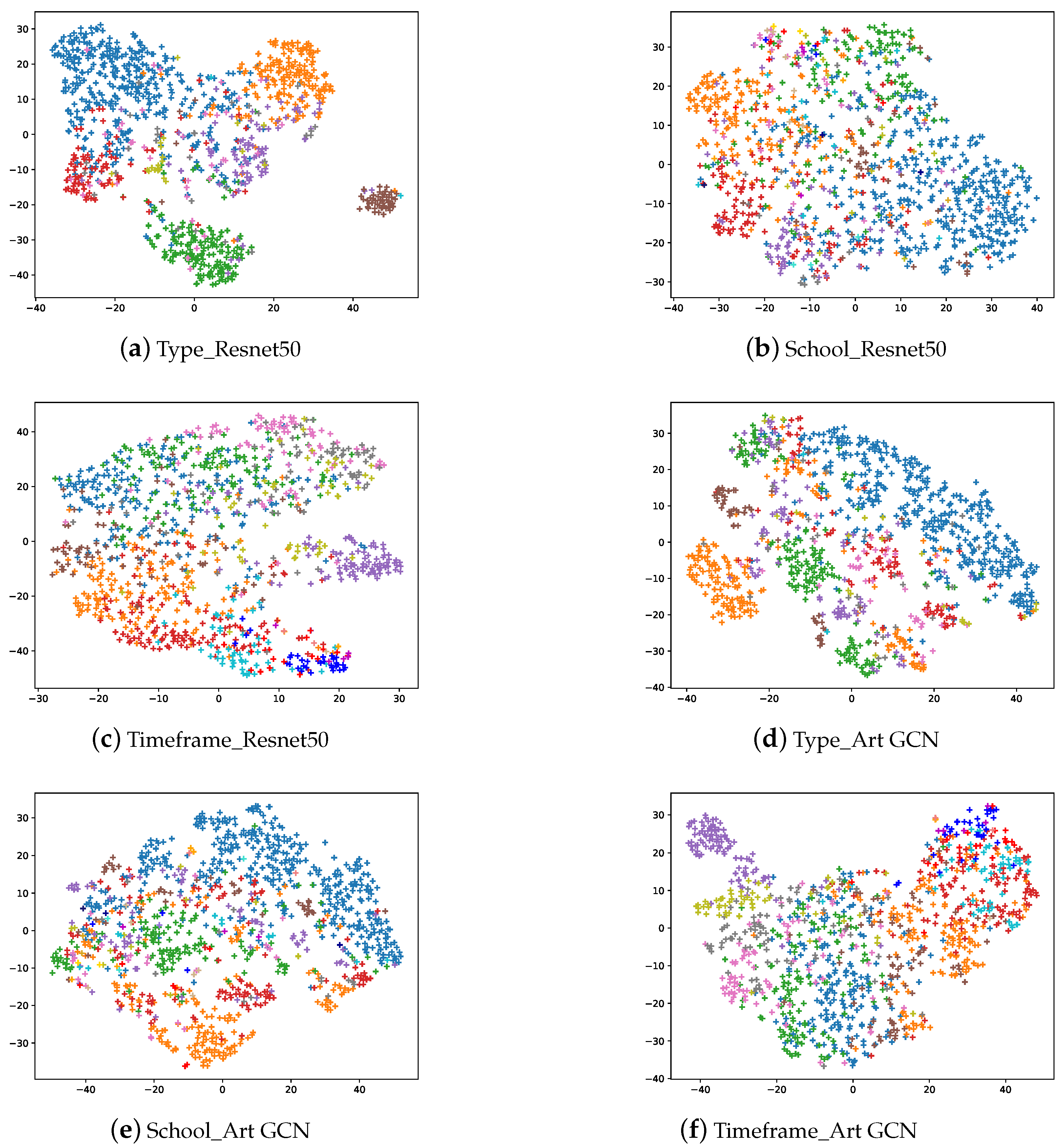
- We analyze the SemArt dataset, including the class distribution. We create visualizations to analyze the results of the art classification for different tasks using ResNet50 and ArtGCN models. Overall, the classification effect improves when using ArtGCN—but not for all specific categories. These 2 methods include using the pixels of the painting itself (ResNet50) and art comments (ArtGCN). Here, we compare two ways of representing paintings using neural networks.
- Based on the trained classification models, we develop a painting retrieval system and find that both methods achieve good performance. An analysis of the retrieval results further illuminates the differences in how the 2 models with different input sources work.
2. Related Work
2.1. Art Classification
2.2. Text Classification
2.3. Graph Neural Networks
3. Datasets
3.1. Data Analysis
4. Method
- Nodes representing artistic comments represented as TF-IDF weighted bag of words.
- Nodes that correspond to unique words.
5. Experiments
5.1. Hyperparameter Selection
5.2. Baselines
6. Results and Discussion
6.1. Results
6.2. Word Embedding
6.3. Interpreting the Classification Results
6.4. Painting Retrieval
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sandoval, C.; Pirogova, E.; Lech, M. Two-Stage Deep Learning Approach to the Classification of Fine-Art Paintings. IEEE Access 2019, 7, 41770–41781. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. Fine-Tuning Convolutional Neural Networks for Fine Art Classification. Expert Syst. Appl. 2018, 114, 107–118. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. A Deep Learning Perspective on Beauty, Sentiment, and Remembrance of Art. IEEE Access 2019, 7, 73694–73710. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. Learning the Principles of Art History with Convolutional Neural Networks. Pattern Recognit. Lett. 2020, 129, 56–62. [Google Scholar] [CrossRef]
- Huckle, N.; Garcia, N.; Nakashima, Y. Demographic Influences on Contemporary Art with Unsupervised Style Embeddings. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 126–142. [Google Scholar]
- Chen, L.; Yang, J. Recognizing the Style of Visual Arts via Adaptive Cross-Layer Correlation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2459–2467. [Google Scholar]
- Wynen, D.; Schmid, C.; Mairal, J. Unsupervised Learning of Artistic Styles with Archetypal Style Analysis. arXiv 2018, arXiv:1805.11155. [Google Scholar]
- Falomir, Z.; Museros, L.; Sanz, I.; Gonzalez-Abril, L. Categorizing Paintings in Art Styles Based on Qualitative Color Descriptors, Quantitative Global Features and Machine Learning (QArt-Learn). Expert Syst. Appl. 2018, 97, 83–94. [Google Scholar] [CrossRef]
- Ma, D.; Gao, F.; Bai, Y.; Lou, Y.; Wang, S.; Huang, T.; Duan, L.Y. From Part to Whole: Who Is behind the Painting? In Proceedings of the 25th ACM International Conference on Multimedia, Sliema, Malta, 3–7 April 2017; pp. 1174–1182. [Google Scholar]
- Mao, H.; Cheung, M.; She, J. Deepart: Learning Joint Representations of Visual Arts. In Proceedings of the 25th ACM International Conference on Multimedia, Sliema, Malta, 3–7 April 2017; pp. 1183–1191. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. Ceci n’est Pas Une Pipe: A Deep Convolutional Network for Fine-Art Paintings Classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: New York, NY, USA, 2016; pp. 3703–3707. [Google Scholar]
- Garcia, N.; Ye, C.; Liu, Z.; Hu, Q.; Otani, M.; Chu, C.; Nakashima, Y.; Mitamura, T. A Dataset and Baselines for Visual Question Answering on Art. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 92–108. [Google Scholar]
- Sheng, S.; Moens, M.F. Generating Captions for Images of Ancient Artworks. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2478–2486. [Google Scholar]
- Baraldi, L.; Cornia, M.; Grana, C.; Cucchiara, R. Aligning Text and Document Illustrations: Towards Visually Explainable Digital Humanities. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: New York, NY, USA, 2018; pp. 1097–1102. [Google Scholar]
- Shamir, L.; Macura, T.; Orlov, N.; Eckley, D.M.; Goldberg, I.G. Impressionism, Expressionism, Surrealism: Automated Recognition of Painters and Schools of Art. ACM Trans. Appl. Percept. 2010, 7, 1–17. [Google Scholar]
- Arora, R.S.; Elgammal, A. Towards Automated Classification of Fine-Art Painting Style: A Comparative Study. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; IEEE: Nork, NY, USA, 2012; pp. 3541–3544. [Google Scholar]
- Agarwal, S.; Karnick, H.; Pant, N.; Patel, U. Genre and Style Based Painting Classification. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; IEEE: Nork, NY, USA, 2015; pp. 588–594. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Nork, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Strezoski, G.; Worring, M. Omniart: A Large-Scale Artistic Benchmark. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–21. [Google Scholar]
- Seguin, B.; Striolo, C.; Kaplan, F. Visual Link Retrieval in a Database of Paintings. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 753–767. [Google Scholar]
- Chu, W.T.; Wu, Y.L. Image Style Classification Based on Learnt Deep Correlation Features. IEEE Trans. Multimed. 2018, 20, 2491–2502. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-Level Convolutional Networks for Text Classification. arXiv 2015, arXiv:1509.01626. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations from Tree-Structured Long Short-Term Memory Networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Luo, Y. Recurrent Neural Networks for Classifying Relations in Clinical Notes. J. Biomed. Inform. 2017, 72, 85–95. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. NIPS. 2017. Available online: https://arxiv.org/pdf/1706.03762.pdf (accessed on 15 February 2021).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Tu, M.; Wang, G.; Huang, J.; Tang, Y.; He, X.; Zhou, B. Multi-Hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs. arXiv 2019, arXiv:1905.07374. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-End Deep Learning Architecture for Graph Classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ying, Z.; You, J.; Morris, C.; Ren, X.; Hamilton, W.; Leskovec, J. Hierarchical Graph Representation Learning with Differentiable Pooling. arXiv 2018, arXiv:1806.08804. [Google Scholar]
- Cangea, C.; Veličković, P.; Jovanović, N.; Kipf, T.; Liò, P. Towards Sparse Hierarchical Graph Classifiers. arXiv 2018, arXiv:1811.01287. [Google Scholar]
- Bianchi, F.M.; Grattarola, D.; Alippi, C.; Livi, L. Graph Neural Networks with Convolutional Arma Filters. arXiv 2019, arXiv:1901.01343. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. arXiv 2018, arXiv:1809.05679. [Google Scholar]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor Graph Convolutional Networks for Text Classification. AAAI 2020, 34, 8409–8416. [Google Scholar]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3444–3450. [Google Scholar] [CrossRef]
- Garcia, N.; Vogiatzis, G. How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Khan, F.S.; Beigpour, S.; Van de Weijer, J.; Felsberg, M. Painting-91: A Large Scale Database for Computational Painting Categorization. Mach. Vis. Appl. 2014, 25, 1385–1397. [Google Scholar]
- Karayev, S.; Trentacoste, M.; Han, H.; Agarwala, A.; Darrell, T.; Hertzmann, A.; Winnemoeller, H. Recognizing Image Style. arXiv 2013, arXiv:1311.3715. [Google Scholar]
- Bianco, S.; Mazzini, D.; Napoletano, P.; Schettini, R. Multitask Painting Categorization by Deep Multibranch Neural Network. Expert Syst. Appl. 2019, 135, 90–101. [Google Scholar]
- Zhou, K.; Dong, Y.; Lee, W.S.; Hooi, B.; Xu, H.; Feng, J. Effective Training Strategies for Deep Graph Neural Networks. arXiv 2020, arXiv:2006.07107. [Google Scholar]
- Zhao, L.; Akoglu, L. Pairnorm: Tackling Oversmoothing in Gnns. arXiv 2019, arXiv:1909.12223. [Google Scholar]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards Deep Graph Convolutional Networks on Node Classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Garcia, N.; Renoust, B.; Nakashima, Y. Context-Aware Embeddings for Automatic Art Analysis. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 25–33. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 427–431. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Chen, J.; Ma, T.; Xiao, C. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling. arXiv 2018, arXiv:1801.10247. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Paintings | # Words | # Nodes | # Average Length | # Classes | |
|---|---|---|---|---|---|---|
| train | 19,244 | - | - | - | 11 | TYPE |
| val | 1069 | - | - | - | 25 | SCHOOL |
| test | 1069 | - | - | - | 18 | TIMEFRAME |
| total | 21,382 | 17,944 | 39,326 | 59.27 | 350 | AUTHOR |
| # Region | # Model | # TYPE | # SCHOOL | # TIMEFRAME | # AUTHOR | # AVE |
|---|---|---|---|---|---|---|
| cv | resnet50 [47] | 0.787 | 0.636 | 0.592 | 0.557 | 0.643 |
| resnet101 [47] | 0.771 | 0.655 | 0.591 | 0.519 | 0.634 | |
| resnet152 [47] | 0.806 | 0.644 | 0.615 | 0.546 | 0.653 | |
| mtl-resnet50 | 0.790 | 0.667 | 0.616 | 0.526 | 0.650 | |
| kgm-resnet50 [48] | 0.815 | 0.671 | 0.613 | 0.615 | 0.679 | |
| nlp | TF-IDF+LR | 0.772 | 0.688 | 0.480 | 0.097 | 0.509 |
| fastText [49] | 0.787 | 0.757 | 0.665 | 0.498 | 0.677 | |
| fastText (bigrams) | 0.804 | 0.774 | 0.634 | 0.453 | 0.666 | |
| RoBERTa [50] | 0.815 | 0.783 | 0.545 | 0.465 | 0.652 | |
| mtl-ArtGCN | 0.815 | 0.783 | 0.707 | 0.686 | 0.748 | |
| ArtGCN | 0.826 | 0.788 | 0.717 | 0.702 | 0.758 |
| Religious | Portrait | Landscape | Mythological | Genre | Still-Life | Historical | Other |
|---|---|---|---|---|---|---|---|
| saints | portrait | estuary | bacchus | bambocciata | porcelain | battle | painting |
| triptych | sitter | ruisdael | scorpio | singerie | nots | alexander | , |
| mary | portraits | views | aquarius | ceruti | shrimps | fleet | ’s |
| virgin | camus | coastal | capricorn | bamboccio | blackberries | brutus | artist |
| angels | portraitist | moored | pisces | steen | blooms | army | painted |
| madonna | hertel | boats | ovid | lhermitte | hazelnuts | war | one |
| altenburg | sitters | waterfalls | ariadne | singeries | tulips | defeated | \( |
| altarpiece | dihau | topographical | sagittarius | laer | grapes | naval | \) |
| polyptych | countess | hobbema | goddess | metsu | figs | king | painter |
| deposition | morbilli | fishing | pan | mieris | medlars | havana | paintings |
| Italian | Dutch | French | Flemish | German | Spanish | English | Netherlandish |
|---|---|---|---|---|---|---|---|
| chapels | leiden | fran | bruges | cranach | juan | british | bosch |
| pezzoli | nieuwe | ch | rubens | halle | zquez | sickert | bruegel |
| petrvs | rembrandt | fragonard | brueghel | herlin | vel | groom | haywain |
| petronio | bredius | boucher | memling | nuremberg | carlos | stubbs | hell |
| esther | kerk | le | snyders | holbein | alonso | maitland | geertgen |
| mariotti | hals | courbet | eyck | luther | vicente | starr | aertsen |
| pesaro | hague | ois | pourbus | heyday | las | wright | devils |
| evangelist | haarlem | bruyas | balen | secession | bautista | 1st | bouts |
| florentine | hooch | lautrec | neeffs | liebermann | retablo | gainsborough | obverse |
| peruzzi | dutch | oudry | rubens’ | friedrich | caj | sidney | sins |
| 1601–1650 | 1501–1550 | 1651–1700 | 1451–1500 | 1851–1900 | 1551–1600 | 1701–1750 | 1751–1800 |
|---|---|---|---|---|---|---|---|
| poussin | rer | 1660s | ghirlandaio | brittany | arcimboldo | ricci | pulcinella |
| barberini | leo | vermeer | piero | parisian | zelotti | rosalba | reynolds |
| vel | capricorn | hooch | botticelli | ferenczy | sofonisba | ballroom | nemi |
| manfredi | scorpio | carre | mantegna | fattori | tintoretto | watteau | 1773 |
| caravaggism | aquarius | terborch | memling | poster | el | pellegrini | wright |
| 1640 | begat | 1670s | bellini | cassatt | grandi | lancret | 1777 |
| ribera | 1525 | dou | roberti | boldini | zuccaro | tiepolo | volaire |
| hals | gossart | maes | tura | fantin | greco | crespi | 1768 |
| 1635 | raphael | steen | cossa | pouldu | veronese | carriera | zianigo |
| haarlem | sagittarius | deventer | signorelli | nabis | dell’albergo | boucher | gherardini |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Zhou, D.; Qiu, X.; Jiang, W. How to Represent Paintings: A Painting Classification Using Artistic Comments. Sensors 2021, 21, 1940. https://doi.org/10.3390/s21061940
Zhao W, Zhou D, Qiu X, Jiang W. How to Represent Paintings: A Painting Classification Using Artistic Comments. Sensors. 2021; 21(6):1940. https://doi.org/10.3390/s21061940
Chicago/Turabian StyleZhao, Wentao, Dalin Zhou, Xinguo Qiu, and Wei Jiang. 2021. "How to Represent Paintings: A Painting Classification Using Artistic Comments" Sensors 21, no. 6: 1940. https://doi.org/10.3390/s21061940
APA StyleZhao, W., Zhou, D., Qiu, X., & Jiang, W. (2021). How to Represent Paintings: A Painting Classification Using Artistic Comments. Sensors, 21(6), 1940. https://doi.org/10.3390/s21061940