
Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification





Abstract
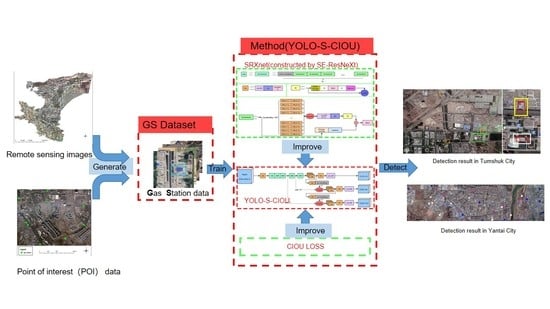
1. Introduction
2. Materials and Methods
2.1. Dataset
2.1.1. Dataset Preparation
2.1.2. Data Enhancement
2.1.3. Remote Sensing Images to Be Tested
2.2. Method
2.2.1. Structure of You Only Look Once Version 3 (YOLOv3)
2.2.2. SE-ResNeXt Network Structure
2.2.3. YOLO-S-CIOU Network Structure
2.2.4. Loss Function
2.3. Evaluation Indicators
2.4. Implement Environment and Model Training
3. Results and Discussion
3.1. Index Evaluation
- All the training and validation loss curves were reasonable, which indicates that all three networks performed well on the dataset.
- With the same loss function, the YOLO-SRXnet shows a lower training and validation loss value than YOLOv3, which indicates better performance than the traditional YOLOv3 network.
3.2. Application Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, F.; Xi, G.L.; Qing, X. Smart city planning and construction based on geographic perspectives: Some theoretical thinking. Prog. Geogr. 2015, 34, 402–409. [Google Scholar]
- Zhang, Y.M.; Gu, L.; Li, Q. Airport detection method based on global and local features. Comput. Eng. Des. 2015, 36, 2974–2978. [Google Scholar]
- Zhong, Z.X.; Wang, W. Detection of illegal buildings based on object oriented multi-feature method. Zhejiangcehui 2020, 1, 37–41. [Google Scholar]
- Yu, H.J. Applications of Spectral Location Combined Analysis and Object Scene Correlation Analysis in the Classification of Urban Building Types. Master’s Thesis, East China Normal University, Shanghai, China, 2017. [Google Scholar]
- Fan, R.S.; Chen, Y.; Xu, Q.H.; Wang, J.X. A high-resolution remote sensing image building extraction method based on deep learning. Acta Geod. Et Cartogr. Sin. 2019, 48, 34–41. [Google Scholar]
- Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors 2019, 19, 333. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wei, Y.; Wang, Q.; Chen, F.; Lu, C.; Lei, S. Mapping Post-Earthquake Landslide Susceptibility: A U-Net Like Approach. Remote Sens. 2020, 12, 2767. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colombus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative research on deep learning approaches for airplane detection from very high-resolution satellite images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef]
- Yu, D.; Zhang, N.; Zhang, B.; Guo, H.; Lu, J. Airport detection using convolutional neural network and salient feature. Bull. Surv. Mapp. 2019, 25, 44–49. [Google Scholar]
- Ma, H.J.; Liu, Y.L.; Ren, Y.H.; Yu, J.X. Detection of collapsed buildings in post-earthquake remote sensing images based on the improved yolov3. Remote Sens. 2020, 12, 44. [Google Scholar] [CrossRef]
- Chen, L.K.; Li, B.Y.; Qi, L. Research on YOLOv3 Ship Target Detection Algorithm Based on Images Saliency. Softw. Guide 2020, 19, 146–151. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. arXiv 2019, arXiv:1911.08287. [Google Scholar]
- Ji, S.P.; Wei, S.Q.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Jia, S.J.; Wang, P.; Jia, P.Y.; Hu, S.P. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Hernández-García, A.; König, P. Do deep nets really need weight decay and dropout? arXiv 2018, arXiv:1802.07042. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Xie, S.N.; Girshick, R.; Dollar, P.; Tu, Z.W.; He, K.M. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. Available online: https://www.cvfoundation.org/openaccess/content_cvpr_2015/html/Szegedy_Going_Deeper_With_2015_CVPR_paper.html (accessed on 10 January 2020).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Szegedy_Rethinking_the_Inception_CVPR_2016_paper.pdf (accessed on 10 January 2020).
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A.; Aaai. Inception-v4, inception-ResNet and the Impact of Residual Connections on Learning. In In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, X.; Li, Y.; Liu, L.; Wang, Z.; Liu, Y. Improved yolov3 target recognition algorithm with embedded senet structure. Comput. Eng. 2019, 45, 243–248. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–19 June 2019; pp. 658–666. [Google Scholar]
- Xie, M.; Liu, W.; Yang, M.; Chai, Q.; Ji, L. Remote sensing image aircraft detection supported by deep convolutional neural network. Bull. Surv. Mapp. 2019, 25, 19–23. [Google Scholar]
- Sahiner, B.; Chen, W.J.; Pezeshk, A.; Petrick, N. Comparison of two classifiers when the data sets are imbalanced: The power of the area under the precision-recall curve as the figure of merit versus the area under the roc curve. In Proceedings of the Medical Imaging 2017: Image Perception, Observer Performance, and Technology Assessment, Orlando, FL, USA, 12–13 February 2017. [Google Scholar]
- Peng, Z.; Wanhua, S. Statistical inference on recall, precision and average precision under random selection. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, Chongqing, China , 29–31 May 2012; pp. 1348–1352. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Testing Set | |
|---|---|---|---|
| Gas station | 8400 | 2100 | 2520 |
| P (%) | R (%) | F1 (%) | AP (%) | Parameter Size | |
|---|---|---|---|---|---|
| YOLOv3 | 97 | 97 | 97 | 95.39 | 61,576,343 |
| YOLO-SRXnet | 97 | 98 | 97.50 | 97.49 | 59,065,366 |
| YOLO-S-CIOU | 98 | 97 | 97.50 | 97.62 | 59,065,366 |
| Images | Model | TP | FP | TN | FN | P (%) | R (%) |
|---|---|---|---|---|---|---|---|
| WorldView data of Tumshuk City | YOLO-S-CIOU | 3 | 2 | - | 0 | 60 | 100 |
| YOLOv3 | 0 | 2 | - | 3 | 0 | 0 | |
| Google map of Yantai City | YOLO-S-CIOU | 10 | 10 | - | 8 | 50 | 55.6 |
| YOLOv3 | 1 | 9 | - | 17 | 10 | 5.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. https://doi.org/10.3390/s21041375
Gao J, Chen Y, Wei Y, Li J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors. 2021; 21(4):1375. https://doi.org/10.3390/s21041375
Chicago/Turabian StyleGao, Jinfeng, Yu Chen, Yongming Wei, and Jiannan Li. 2021. "Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification" Sensors 21, no. 4: 1375. https://doi.org/10.3390/s21041375
APA StyleGao, J., Chen, Y., Wei, Y., & Li, J. (2021). Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors, 21(4), 1375. https://doi.org/10.3390/s21041375