
Reinforcement Learning Approaches in Social Robotics


Abstract
1. Introduction
Overview of the Survey
- Interactive reinforcement learning: In these methods, humans are involved in the learning process either by providing reward or guidance to the agent (Section 5.1). This approach, in which the human delivers explicit or implicit feedback to the agent, is known as Interactive Reinforcement Learning (IRL).
- Intrinsically motivated methods: There are different intrinsic motivations in the literature on RL [20], however, the most frequently used approaches in social robotics depend on the robot maintaining an optimal internal state by considering both internal and external circumstances (Section 5.2).
- Task performance driven methods: In these methods, the reward the robot receives depends on either the robot’s task performance or the human interactant’s task performance, or a combination of both (Section 5.3).
2. RL in Social Robotics—Benefits and Challenges
3. Reinforcement Learning
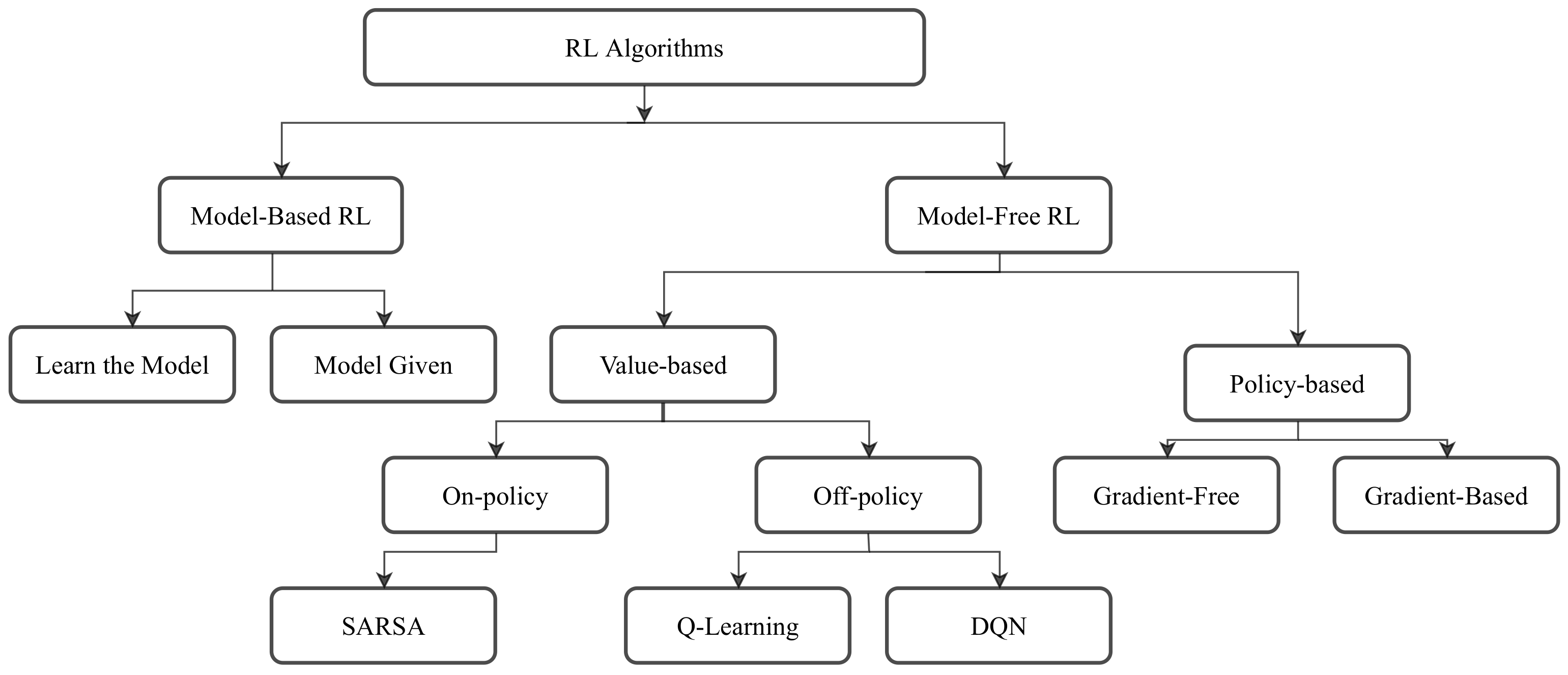
3.1. Model-Based and Model-Free Reinforcement Learning
3.2. Value-Based Methods
3.3. Policy-Based Methods
3.4. Deep Reinforcement Learning
4. Categorization of RL Approaches in Social Robotics Based on RL Type
4.1. Bandit-Based Methods
4.1.1. Additional Physical Communication Medium between the Robot and the Human
4.1.2. Verbal and Nonverbal Communication Plus an Interface
4.2. Model-Based and Model-Free Reinforcement Learning
Verbal Communication
4.3. Value-Based Methods
4.3.1. Tactile Communication
4.3.2. Additional Physical Communication Medium between the Robot and the Human
4.3.3. Verbal and Nonverbal Communication
4.3.4. Higher Level Interaction Dynamics: Engagement
4.3.5. Affective Communication: Facial Expressions
4.3.6. Verbal Communication
4.3.7. Higher Level Interaction Dynamics: Attention
4.3.8. Affective Communication
4.4. Deep Reinforcement Learning
4.4.1. Tactile Communication
4.4.2. No Communication Medium
4.4.3. Nonverbal Communication
4.5. Policy-Based Methods
Higher Level Interaction Dynamics: Comfort
5. Categorization of RL Approaches in Social Robotics Based on Reward
5.1. Interactive Reinforcement Learning
5.1.1. Explicit Feedback
5.1.2. Implicit Feedback
5.2. Methods Using Intrinsic Motivation
Homeostasis-Based Methods
5.3. Methods Driven by Task Performance
5.3.1. Human Task Performance Driven Methods
5.3.2. Robot Task Performance Driven Methods
5.3.3. Human and Robot Task Performance Driven Methods
6. Evaluation Methodologies
7. Discussion
7.1. Proposed Solutions to Real-World RL Problems
7.2. Future Outlook
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Keizer, S.; Ellen Foster, M.; Wang, Z.; Lemon, O. Machine Learning for Social Multiparty Human–Robot Interaction. ACM Trans. Interact. Intell. Syst. 2014, 4, 14:1–14:32. [Google Scholar] [CrossRef]
- de Greeff, J.; Belpaeme, T. Why robots should be social: Enhancing machine learning through social human-robot interaction. PLoS ONE 2015, 10, e0138061. [Google Scholar] [CrossRef]
- Hemminghaus, J.; Kopp, S. Towards Adaptive Social Behavior Generation for Assistive Robots Using Reinforcement Learning. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction (HRI 2017), Vienna, Austria, 6–9 March 2017; pp. 332–340. [Google Scholar] [CrossRef]
- Ritschel, H.; Seiderer, A.; Janowski, K.; Wagner, S.; André, E. Adaptive linguistic style for an assistive robotic health companion based on explicit human feedback. In Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; pp. 247–255. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, UK, 1998; Volume 2. [Google Scholar]
- Barto, A.G.; Sutton, R.S.; Watkins, C. Learning and Sequential Decision Making; University of Massachusetts Amherst: Amherst, MA, USA, 1989. [Google Scholar]
- Fong, T.; Nourbakhsh, I.; Dautenhahn, K. A survey of socially interactive robots. Robot. Auton. Syst. 2003, 42, 143–166. [Google Scholar] [CrossRef]
- Breazeal, C. Toward sociable robots. Robot. Auton. Syst. 2003, 42, 167–175. [Google Scholar] [CrossRef]
- Duffy, B.R. Anthropomorphism and the social robot. Robot. Auton. Syst. 2003, 42, 177–190. [Google Scholar] [CrossRef]
- Bartneck, C.; Forlizzi, J. A design-centred framework for social human-robot interaction. In Proceedings of the 13th IEEE International Workshop on Robot and Human Interactive Communication (RO-MAN 2004), Kurashiki, Japan, 20–22 September 2004; pp. 591–594. [Google Scholar]
- Hegel, F.; Muhl, C.; Wrede, B.; Hielscher-Fastabend, M.; Sagerer, G. Understanding social robots. In Proceedings of the 2009 Second International Conferences on Advances in Computer-Human Interactions, Cancun, Mexico, 1–7 February 2009; pp. 169–174. [Google Scholar]
- Yan, H.; Ang, M.H.; Poo, A.N. A survey on perception methods for human–robot interaction in social robots. Int. J. Soc. Robot. 2014, 6, 85–119. [Google Scholar] [CrossRef]
- Maroto-Gómez, M.; Castro-González, Á.; Castillo, J.; Malfaz, M.; Salichs, M. A bio-inspired motivational decision making system for social robots based on the perception of the user. Sensors 2018, 18, 2691. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Kormushev, P.; Calinon, S.; Caldwell, D. Reinforcement learning in robotics: Applications and real-world challenges. Robotics 2013, 2, 122–148. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Neumann, G.; Peters, J. A survey on policy search for robotics. Found. Trends® Robot. 2013, 2, 388–403. [Google Scholar]
- Garcıa, J.; Fernández, F. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Bhagat, S.; Banerjee, H.; Ho Tse, Z.T.; Ren, H. Deep reinforcement learning for soft, flexible robots: Brief review with impending challenges. Robotics 2019, 8, 4. [Google Scholar] [CrossRef]
- Oudeyer, P.Y.; Kaplan, F. How can we define intrinsic motivation. In Proceedings of the 8th International Conference on Epigenetic Robotics: Modeling Cognitive Development in Robotic Systems, Brighton, UK, 30–31 July 2008; pp. 93–101. [Google Scholar]
- Thomaz, A.; Hoffman, G.; Cakmak, M. Computational human-robot interaction. Found. Trends Robot. 2016, 4, 105–223. [Google Scholar]
- Thomaz, A.L.; Breazeal, C.; Barto, A.G.; Picard, R. Socially Guided Machine Learning. 2006. Available online: https://scholarworks.umass.edu/cs_faculty_pubs/183 (accessed on 2 February 2020).
- Holzinger, A.; Plass, M.; Holzinger, K.; Crişan, G.C.; Pintea, C.M.; Palade, V. Towards interactive Machine Learning (iML): Applying ant colony algorithms to solve the traveling salesman problem with the human-in-the-loop approach. In Proceedings of the International Conference on Availability, Reliability, and Security (ARES 2016), Salzburg, Austria, 31 August–2 September 2016; pp. 81–95. [Google Scholar]
- Knox, W.B.; Stone, P. Reinforcement learning from simultaneous human and MDP reward. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems (AAMAS ’12), Valencia, Spain, 4–8 June 2012; pp. 475–482. [Google Scholar]
- Isbell, C.; Shelton, C.R.; Kearns, M.; Singh, S.; Stone, P. A social reinforcement learning agent. In Proceedings of the Fifth International Conference on Autonomous Agents, (AGENTS ’01), Montreal, QC, Canada, 28 May–1 June 2001; pp. 377–384. [Google Scholar]
- Suay, H.B.; Chernova, S. Effect of human guidance and state space size on interactive reinforcement learning. In Proceedings of the 20th IEEE International Workshop on Robot and Human Communication (RO-MAN 2011), Atlanta, GA, USA, 31 July–3 August 2011; pp. 1–6. [Google Scholar]
- Thomaz, A.L.; Hoffman, G.; Breazeal, C. Reinforcement learning with human teachers: Understanding how people want to teach robots. In Proceedings of the 15th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2006), Hatfield, UK, 6–8 September 2006; pp. 352–357. [Google Scholar]
- Thomaz, A.L.; Breazeal, C. Experiments in socially guided exploration: Lessons learned in building robots that learn with and without human teachers. Connect. Sci. 2008, 20, 91–110. [Google Scholar] [CrossRef]
- Knox, W.B.; Stone, P.; Breazeal, C. Training a Robot via Human Feedback: A Case Study. In Social Robotics; Herrmann, G., Pearson, M.J., Lenz, A., Bremner, P., Spiers, A., Leonards, U., Eds.; Springer International Publishing: Cham, Switzerland, 2013; pp. 460–470. [Google Scholar]
- Suay, H.B.; Toris, R.; Chernova, S. A Practical Comparison of Three Robot Learning from Demonstration Algorithm. Int. J. Soc. Robot. 2012, 4, 319–330. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Asymmetric Interpretations of Positive and Negative Human Feedback for a Social Learning Agent. In Proceedings of the 16th IEEE International Symposium Robot and Human Interactive Communication (RO-MAN 2007), Jeju, Korea, 26–29 August 2007; pp. 720–725. [Google Scholar] [CrossRef]
- Patompak, P.; Jeong, S.; Nilkhamhang, I.; Chong, N.Y. Learning Proxemics for Personalized Human–Robot Social Interaction. Int. J. Soc. Robot. 2019, 12, 267–280. [Google Scholar] [CrossRef]
- Chan, J.; Nejat, G. Social Intelligence for a Robot Engaging People in Cognitive Training Activities. Int. J. Adv. Robot. Syst. 2012, 9. [Google Scholar] [CrossRef]
- Pérula-Martínez, R.; Castro-Gonzalez, A.; Malfaz, M.; Alonso-Martín, F.; Salichs, M.A. Bioinspired decision-making for a socially interactive robot. Cogn. Syst. Res. 2019, 54, 287–301. [Google Scholar] [CrossRef]
- Cuayáhuitl, H. A data-efficient deep learning approach for deployable multimodal social robots. Neurocomputing 2019, 396, 587–598. [Google Scholar] [CrossRef]
- Qureshi, A.H.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Robot gains social intelligence through multimodal deep reinforcement learning. In Proceedings of the 16th IEEE-RAS International Conference on Humanoid Robots, Humanoids, Cancun, Mexico, 15–17 November 2016; pp. 745–751. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, T. Taxonomy of Reinforcement Learning Algorithms. In Deep Reinforcement Learning: Fundamentals, Research and Applications; Dong, H., Ding, Z., Zhang, S., Eds.; Springer: Singapore, 2020; pp. 125–133. [Google Scholar] [CrossRef]
- Bellman, R. On the theory of dynamic programming. Proc. Natl. Acad. Sci. USA 1952, 38, 716. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. 1989. Available online: http://www.cs.rhul.ac.uk/~chrisw/new_thesis.pdf (accessed on 7 December 2019).
- Gosavi, A. Boundedness of iterates in Q-learning. Syst. Control Lett. 2006, 55, 347–349. [Google Scholar] [CrossRef]
- Sigaud, O.; Stulp, F. Policy search in continuous action domains: An overview. Neural Netw. 2019, 113, 28–40. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schneider, S.; Kummert, F. Exploring embodiment and dueling bandit learning for preference adaptation in human-robot interaction. In Proceedings of the 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2017), Lisbon, Portugal, 28 August–1 September 2017; pp. 1325–1331. [Google Scholar]
- Leite, I.; Pereira, A.; Castellano, G.; Mascarenhas, S.; Martinho, C.; Paiva, A. Modelling empathy in social robotic companions. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization (UMAP 2011), Girona, Spain, 11–15 July 2011; pp. 135–147. [Google Scholar]
- Ritschel, H.; Seiderer, A.; Janowski, K.; Aslan, I.; André, E. Drink-o-mender: An adaptive robotic drink adviser. In Proceedings of the 3rd International Workshop on Multisensory Approaches to Human-Food Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 1–8. [Google Scholar]
- Gao, Y.; Barendregt, W.; Obaid, M.; Castellano, G. When robot personalisation does not help: Insights from a robot-supported learning study. In Proceedings of the 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2018), Nanjing, China, 27–31 August 2018; pp. 705–712. [Google Scholar]
- Bubeck, S.; Cesa-Bianchi, N. Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems. Found. Trends® Mach. Learn. 2012, 5, 1–122. [Google Scholar] [CrossRef]
- Tseng, S.H.; Liu, F.C.; Fu, L.C. Active Learning on Service Providing Model: Adjustment of Robot Behaviors Through Human Feedback. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 701–711. [Google Scholar] [CrossRef]
- Martins, G.S.; Al Tair, H.; Santos, L.; Dias, J. αPOMDP: POMDP-based user-adaptive decision-making for social robots. Pattern Recognit. Lett. 2019, 118, 94–103. [Google Scholar] [CrossRef]
- Wiewiora, E. Reward Shaping. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 863–865. [Google Scholar]
- Barraquand, R.; Crowley, J.L. Learning Polite Behavior with Situation Models. In Proceedings of the 3rd ACM/IEEE International Conference on Human Robot Interaction (HRI 2008), Amsterdam, The Netherlands, 12–15 March 2008; pp. 209–216. [Google Scholar] [CrossRef]
- Yang, C.; Lu, M.; Tseng, S.; Fu, L. A companion robot for daily care of elders based on homeostasis. In Proceedings of the 56th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE 2017), Kanazawa, Japan, 19–22 September 2017; pp. 1401–1406. [Google Scholar] [CrossRef]
- Zarinbal, M.; Mohebi, A.; Mosalli, H.; Haratinik, R.; Jabalameli, Z.; Bayatmakou, F. A New Social Robot for Interactive Query-Based Summarization: Scientific Document Summarization. In Proceedings of the International Conference on Interactive Collaborative Robotics (ICR 2019), Istanbul, Turkey, 20–25 August 2019; pp. 330–340. [Google Scholar]
- Addo, I.D.; Ahamed, S.I. Applying affective feedback to reinforcement learning in ZOEI, a comic humanoid robot. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2014), Edinburgh, UK, 25–29 August 2014; pp. 423–428. [Google Scholar]
- Chiang, Y.S.; Chu, T.S.; Lim, C.; Wu, T.Y.; Tseng, S.H.; Fu, L.C. Personalizing robot behavior for interruption in social human-robot interaction. In Proceedings of the 2014 IEEE International Workshop on Advanced Robotics and its Social Impacts (ARSO 2014), Evanston, IL, USA, 11–13 September 2014; pp. 44–49. [Google Scholar] [CrossRef]
- Ritschel, H.; Baur, T.; André, E. Adapting a Robot’s linguistic style based on socially-aware reinforcement learning. In Proceedings of the 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2017), Lisbon, Portugal, 28 August–1 September 2017; pp. 378–384. [Google Scholar] [CrossRef]
- Park, H.W.; Grover, I.; Spaulding, S.; Gomez, L.; Breazeal, C. A model-free affective reinforcement learning approach to personalization of an autonomous social robot companion for early literacy education. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 687–694. [Google Scholar]
- Weber, K.; Ritschel, H.; Aslan, I.; Lingenfelser, F.; André, E. How to Shape the Humor of a Robot—Social Behavior Adaptation Based on Reinforcement Learning. In Proceedings of the International Conference on Multimodal Interaction, ICMI 2018, Boulder, CO, USA, 16–20 October 2018; pp. 154–162. [Google Scholar] [CrossRef]
- Papaioannou, I.; Dondrup, C.; Novikova, J.; Lemon, O. Hybrid chat and task dialogue for more engaging hri using reinforcement learning. In Proceedings of the 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN 2017), Lisbon, Portugal, 28 August–1 September 2017; pp. 593–598. [Google Scholar]
- Moro, C.; Nejat, G.; Mihailidis, A. Learning and Personalizing Socially Assistive Robot Behaviors to Aid with Activities of Daily Living. ACM Trans. Hum. Robot. Interact. 2018, 7. [Google Scholar] [CrossRef]
- Nejat, G.; Ficocelli, M. Can I be of assistance? The intelligence behind an assistive robot. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation (ICRA 2008), Pasadena, CA, USA, 19–23 May 2008; pp. 3564–3569. [Google Scholar]
- Da Silva, R.R.; Francelin Romero, R.A. Modelling Shared Attention Through Relational Reinforcement Learning. J. Intell. Robot. Syst. 2012, 66, 167–182. [Google Scholar] [CrossRef]
- Castro-González, Á.; Malfaz, M.; Gorostiza, J.F.; Salichs, M.A. Learning behaviors by an autonomous social robot with motivations. Cybern. Syst. 2014, 45, 568–598. [Google Scholar] [CrossRef]
- Castro-González, Á.; Malfaz, M.; Salichs, M.A. An autonomous social robot in fear. IEEE Trans. Auton. Ment. Dev. 2013, 5, 135–151. [Google Scholar] [CrossRef]
- Castro-González, Á.; Malfaz, M.; Salichs, M.A. Learning the Selection of Actions for an Autonomous Social Robot by Reinforcement Learning Based on Motivations. Int. J. Soc. Robot. 2011, 3, 427–441. [Google Scholar] [CrossRef]
- Chen, L.; Wu, M.; Zhou, M.; She, J.; Dong, F.; Hirota, K. Information-Driven Multirobot Behavior Adaptation to Emotional Intention in Human–Robot Interaction. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 647–658. [Google Scholar] [CrossRef]
- Gordon, G.; Spaulding, S.; Westlund, J.K.; Lee, J.J.; Plummer, L.; Martinez, M.; Das, M.; Breazeal, C. Affective personalization of a social robot tutor for children’s second language skills. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Gamborino, E.; Fu, L.C. Interactive Reinforcement Learning based Assistive Robot for the Emotional Support of Children. In Proceedings of the 18th International Conference on Control Automation and Systems (ICCAS 2018), Pyeong Chang, Korea, 17–20 October 2018; pp. 708–713. [Google Scholar]
- Ranatunga, I.; Rajruangrabin, J.; Popa, D.O.; Makedon, F. Enhanced Therapeutic Interactivity Using Social Robot Zeno. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA 2011), Crete, Greece, 25–27 May 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Chan, J.; Nejat, G. Minimizing task-induced stress in cognitively stimulating activities using an intelligent socially assistive robot. In Proceedings of the 20th International Symposium on Robot and Human Interactive Communication (RO-MAN 2011), Atlanta, GA, USA, 31 July–3 August 2011; pp. 296–301. [Google Scholar]
- Chan, J.; Nejat, G. A learning-based control architecture for an assistive robot providing social engagement during cognitively stimulating activities. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3928–3933. [Google Scholar]
- Qureshi, A.H.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Show, attend and interact: Perceivable human-robot social interaction through neural attention Q-network. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2017), Singapore, 29 May–3 June 2017; pp. 1639–1645. [Google Scholar]
- Qureshi, A.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Intrinsically motivated reinforcement learning for human–robot interaction in the real-world. Neural Netw. 2018, 107, 23–33. [Google Scholar] [CrossRef] [PubMed]
- Thomaz, A.; Breazeal, C. Adding guidance to interactive reinforcement learning. In Proceedings of the 20th Conference on Artificial Intelligence (AAAI 2006), Boston, MA, USA, 16–20 July 2006. [Google Scholar]
- Loftin, R.; Peng, B.; MacGlashan, J.; Littman, M.L.; Taylor, M.E.; Huang, J.; Roberts, D.L. Learning behaviors via human-delivered discrete feedback: Modeling implicit feedback strategies to speed up learning. Auton. Agents Multi Agent Syst. 2016, 30, 30–59. [Google Scholar] [CrossRef]
- Wagner, J.; Lingenfelser, F.; Baur, T.; Damian, I.; Kistler, F.; André, E. The social signal interpretation (SSI) framework: Multimodal signal processing and recognition in real-time. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 831–834. [Google Scholar]
- McDuff, D.; Mahmoud, A.; Mavadati, M.; Amr, M.; Turcot, J.; Kaliouby, R.E. AFFDEX SDK: A cross-platform real-time multi-face expression recognition toolkit. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3723–3726. [Google Scholar]
- Chen, L.F.; Liu, Z.T.; Dong, F.Y.; Yamazaki, Y.; Wu, M.; Hirota, K. Adapting multi-robot behavior to communication atmosphere in humans-robots interaction using fuzzy production rule based friend-Q learning. J. Adv. Comput. Intell. Intell. Inform. 2013, 17, 291–301. [Google Scholar] [CrossRef]
- Schwartz, A. A Reinforcement Learning Method for Maximizing Undiscounted Rewards. In Proceedings of the 10th International Conference on Machine Learning (ICML 1993), Amherst, MA, USA, 27–29 June 1993; Volume 298, pp. 298–305. [Google Scholar]
- Mahadevan, S. Average reward reinforcement learning: Foundations, algorithms, and empirical results. Mach. Learn. 1996, 22, 159–195. [Google Scholar] [CrossRef]
- Mavridis, N. A review of verbal and non-verbal human–robot interactive communication. Robot. Auton. Syst. 2015, 63, 22–35. [Google Scholar] [CrossRef]
- Da Silva, R.R.; Policastro, C.A.; Romero, R.A. Relational reinforcement learning applied to shared attention. In Proceedings of the 2009 International Joint Conference on Neural Networks (IJCNN 2009), Atlanta, GA, USA, 14–19 June 2009; pp. 2943–2949. [Google Scholar]
- Dietterich, T.G. Hierarchical reinforcement learning with the MAXQ value function decomposition. J. Artif. Intell. Res. 2000, 13, 227–303. [Google Scholar] [CrossRef]
- Lathuilière, S.; Massé, B.; Mesejo, P.; Horaud, R. Deep Reinforcement Learning for Audio-Visual Gaze Control. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2018), Madrid, Spain, 1–5 October 2018; pp. 1555–1562. [Google Scholar]
- Lathuilière, S.; Massé, B.; Mesejo, P.; Horaud, R. Neural network based reinforcement learning for audio–visual gaze control in human–robot interaction. Pattern Recognit. Lett. 2019, 118, 61–71. [Google Scholar] [CrossRef]
- Churamani, N.; Barros, P.; Strahl, E.; Wermter, S. Learning Empathy-Driven Emotion Expressions using Affective Modulations. In Proceedings of the International Joint Conference on Neural Networks (IJCNN 2018), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Breazeal, C. Role of expressive behaviour for robots that learn from people. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3527–3538. [Google Scholar] [CrossRef]
- Mitsunaga, N.; Smith, C.; Kanda, T.; Ishiguro, H.; Hagita, N. Robot behavior adaptation for human-robot interaction based on policy gradient reinforcement learning. J. Robot. Soc. Jpn. 2006, 24, 820–829. [Google Scholar] [CrossRef]
- Mitsunaga, N.; Smith, C.; Kanda, T.; Ishiguro, H.; Hagita, N. Adapting robot behavior for human–robot interaction. IEEE Trans. Robot. 2008, 24, 911–916. [Google Scholar] [CrossRef]
- Tapus, A.; Ţăpuş, C.; Matarić, M.J. User—Robot personality matching and assistive robot behavior adaptation for post-stroke rehabilitation therapy. Intell. Serv. Robot. 2008, 1, 169. [Google Scholar] [CrossRef]
- Knox, W.B.; Stone, P. Interactively shaping agents via human reinforcement: The TAMER framework. In Proceedings of the 5th International Conference on Knowledge Capture, Redondo Beach, CA, USA, 1–4 September 2009; pp. 9–16. [Google Scholar]
- Celemin, C.; Ruiz-del Solar, J. An interactive framework for learning continuous actions policies based on corrective feedback. J. Intell. Robot. Syst. 2019, 95, 77–97. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Teachable robots: Understanding human teaching behavior to build more effective robot learners. Artif. Intell. 2008, 172, 716–737. [Google Scholar] [CrossRef]
- Li, G.; Gomez, R.; Nakamura, K.; He, B. Human-centered reinforcement learning: A survey. IEEE Trans. Hum. Mach. Syst. 2019, 49, 337–349. [Google Scholar] [CrossRef]
- Knox, W.B.; Stone, P. Framing reinforcement learning from human reward: Reward positivity, temporal discounting, episodicity, and performance. Artif. Intell. 2015, 225, 24–50. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Reinforcement Learning with Human Teachers: Evidence of Feedback and Guidance with Implications for Learning Performance. In Proceedings of the 21st National Conference on Artificial intelligence (AAAI 2006), Boston, MA, USA, 16–20 July 2006; Volume 6, pp. 1000–1005. [Google Scholar]
- Schmidt, A. Implicit human computer interaction through context. Pers. Technol. 2000, 4, 191–199. [Google Scholar] [CrossRef]
- Grüneberg, P.; Suzuki, K. A lesson from subjective computing: Autonomous self-referentiality and social interaction as conditions for subjectivity. In Proceedings of the AISB/IACAP World Congress 2012: Computational Philosophy, Part of Alan Turing Year, Birmingham, UK, 2–6 July 2012; pp. 18–28. [Google Scholar]
- Grüneberg, P.; Suzuki, K. An approach to subjective computing: A robot that learns from interaction with humans. IEEE Trans. Auton. Ment. Dev. 2013, 6, 5–18. [Google Scholar] [CrossRef]
- Ramachandran, A.; Sebo, S.S.; Scassellati, B. Personalized Robot Tutoring using the Assistive Tutor POMDP (AT-POMDP). In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI 2019), Honolulu, HI, USA, 27 January–1 February 2019; pp. 8050–8057. [Google Scholar]
- Lerner, J.S.; Li, Y.; Valdesolo, P.; Kassam, K.S. Emotion and decision making. Annu. Rev. Psychol. 2015, 66, 799–823. [Google Scholar] [CrossRef]
- Moerland, T.M.; Broekens, J.; Jonker, C.M. Emotion in reinforcement learning agents and robots: A survey. Mach. Learn. 2018, 107, 443–480. [Google Scholar] [CrossRef]
- Ryan, R.M.; Deci, E.L. Intrinsic and extrinsic motivations: Classic definitions and new directions. Contemp. Educ. Psychol. 2000, 25, 54–67. [Google Scholar] [CrossRef] [PubMed]
- Oudeyer, P.Y.; Kaplan, F. What is intrinsic motivation? A typology of computational approaches. Front. Neurorobot. 2009, 1, 6. [Google Scholar] [CrossRef] [PubMed]
- Chentanez, N.; Barto, A.G.; Singh, S.P. Intrinsically motivated reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2004), Vancouver, BC, Canada, 13–18 December 2004; pp. 1281–1288. [Google Scholar]
- Malfaz, M.; Castro-González, Á.; Barber, R.; Salichs, M.A. A biologically inspired architecture for an autonomous and social robot. IEEE Trans. Auton. Ment. Dev. 2011, 3, 232–246. [Google Scholar] [CrossRef]
- Cannon, W.B. The Wisdom of the Body; W.W. Norton & Company, Inc.: New York, NY, USA, 1939. [Google Scholar]
- Berridge, K.C. Motivation concepts in behavioral neuroscience. Physiol. Behav. 2004, 81, 179–209. [Google Scholar] [CrossRef]
- Sim, D.Y.Y.; Loo, C.K. Extensive assessment and evaluation methodologies on assistive social robots for modelling human–robot interaction–A review. Inf. Sci. 2015, 301, 305–344. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Mankowitz, D.; Hester, T. Challenges of real-world reinforcement learning. arXiv 2019, arXiv:1904.12901. [Google Scholar]
- Lockerd, A.; Breazeal, C. Tutelage and socially guided robot learning. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2004), Sendai, Japan, 28 September–2 October 2004; Volume 4, pp. 3475–3480. [Google Scholar]
- Liu, L.; Li, B.; Chen, I.M.; Goh, T.J.; Sung, M. Interactive robots as social partner for communication care. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2014), Hong Kong, China, 31 May–7 June 2014; pp. 2231–2236. [Google Scholar]
- Bai, C.; Liu, P.; Zhao, W.; Tang, X. Guided goal generation for hindsight multi-goal reinforcement learning. Neurocomputing 2019, 359, 353–367. [Google Scholar] [CrossRef]
- Hao, M.; Cao, W.; Liu, Z.; Wu, M.; Yuan, Y. Emotion Regulation Based on Multi-objective Weighted Reinforcement Learning for Human-robot Interaction. In Proceedings of the 12th Asian Control Conference (ASCC 2019), Kitakyushu-shi, Japan, 9–12 June 2019; pp. 1402–1406. [Google Scholar]
- Roijers, D.M.; Vamplew, P.; Whiteson, S.; Dazeley, R. A Survey of Multi-objective Sequential Decision-making. J. Artif. Intell. Res. 2013, 48, 67–113. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Huang, C.; Sheng, Q.Z.; Wang, X. Intent Recognition in Smart Living through Deep Recurrent Neural Networks. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 748–758. [Google Scholar]
- Hafner, D.; Lillicrap, T.; Fischer, I.; Villegas, R.; Ha, D.; Lee, H.; Davidson, J. Learning Latent Dynamics for Planning from Pixels. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; pp. 2555–2565. [Google Scholar]
- Kostavelis, I.; Giakoumis, D.; Malassiotis, S.; Tzovaras, D. A POMDP Design Framework for Decision Making in Assistive Robots. In Proceedings of the International Conference on Human-Computer Interaction (HCI 2017), Vancouver, BC, Canada, 9–14 July 2017; pp. 467–479. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep Recurrent Q-Learning for Partially Observable MDPs. In Proceedings of the 2015 AAAI Fall Symposium on Sequential Decision Making for Intelligent Agents (AAAI-SDMIA15), Arlington, VA, USA, 12–14 November 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Subcategory | Type of RL | Reward | Social Robot |
|---|---|---|---|---|
| Barraquand et al. [52] | Explicit feedback | Q-learning | User provides reward by using robot’s tactile sensors | Aibo |
| Suay et al. [26,30] | Explicit feedback | Q-learning | Human teacher delivers reward or guidance through a GUI | Nao |
| Knox et al. [29] | Explicit feedback | TAMER | Human teacher provides reward by using a remote | Nexi |
| Yang et al. [53] | Explicit feedback | Q-learning | User gives reward by touching robot’s tactile sensors | Pepper |
| Schneider et al. [44] | Explicit feedback | Dueling bandit | User provides feedback through a button | Nao |
| Churamani et al. [87] | Explicit feedback | DDPG | User gives reward whether robot’s expression is appropriate to affective context of dialogue | Nico |
| Tseng et al. [49] | Explicit feedback | Modified R-Max | User provides reward through a software | ARIO |
| Gamborino et al. [69] | Explicit feedback | SARSA | User’s transition between bad and good mood state | RoBoHoN |
| Ritschel et al. [4] | Explicit feedback | k-armed bandit | User gives reward via buttons | Reeti |
| Patompak et al. [32] | Implicit feedback | R-learning | Verbal reward by the user based on robot’s social distance | Pepper |
| Thomaz et al. [31] | Implicit feedback | Q-learning | Human teacher provides reward or guidance | Leonardo |
| Thomaz et al. [28] | Implicit feedback | Q-learning | Human teacher provides guidance through speech or gestures | Leonardo |
| Gruneberg et al. [100,101] | Implicit feedback | Not specified | Human teacher’s smile and frown | Nao |
| Addo et al. [55] | Implicit feedback | Q-learning | Verbal reward of the user | Nao |
| Zarinbal et al. [54] | Implicit feedback | Q-learning | Human teacher’s facial expressions | Nao |
| Mitsunaga et al. [90,91] | Implicit feedback | PGRL | Discomfort signals of the user | Robovie II |
| Leite et al. [45] | Implicit feedback | Multi-armed bandit | User’s affective cues and task-related features | iCat |
| Chiang et al. [56] | Implicit feedback | Q-learning | Numerical values based on attention and engagement levels of the user | ARIO |
| Gordon et al. [68] | Implicit feedback | SARSA | Weighted sum of facial valence and engagement | Tega |
| Ritschel et al. [57] | Implicit feedback | Q-learning | Change in user engagement | Reeti |
| Weber et al. [59] | Implicit feedback | Q-learning | Vocal laughter and visual smiles | Reeti |
| Park et al. [58] | Implicit feedback | Q-learning | Weighted sum of engagement and learning | Tega |
| Ramachandran et al. [102] | Implicit feedback | POMDP | Engagement level of the user | Nao |
| Martins et al. [50] | Implicit feedback | Model-based RL and POMDP | The robot’s actions’ impact on the user | GrowMu |
| Reference | Subcategory | Type of RL | Reward | Social Robot |
|---|---|---|---|---|
| Malfaz et al. [108] | Homeostasis based | Q-learning | Wellbeing of the robot | Maggie |
| Castro-Gonzalez et al. [64,65,66] | Homeostasis based | Object Q-learning | Variation of robot’s wellbeing | Maggie |
| Maroto et al. [13] | Homeostasis based | Q-learning | Maximization of robot’s well-being | Mini |
| Perula et al. [34] | Homeostasis based | Q-learning | Well-being of the robot | Mini |
| Da Silva et al. [63] | - | Economic TG | Generated on the basis of internal state estimate | Robotic head |
| Qureshi et al. [74] | - | DQN | Prediction error of an action conditional prediction network | Pepper |
| Reference | Subcategory | Type of RL | Reward | Social Robot |
|---|---|---|---|---|
| Tapus et al. [92] | Human task performance | PGRL | User performance | Pioneer 2-DX |
| Gao et al. [47] | Human task performance | Multi-arm bandit | User task performance and user’s verbal feedback | Pepper |
| Chan et al. [71,72] | Human and robot task performance | MAXQ | Success of the robot’s actions in helping or improving user’s affect and task performance | Brian 2.0 |
| Chan et al. [33] | Human and robot task performance | MAXQ | Task performance of human and robot | Brian 2.0 |
| Moro et al. [61] | Human and robot task performance | Q-learning | Numerical numbers based on robot’s performance on user’s activity state | Casper |
| Nejat et al. [62] | Robot task performance | Q-learning | User provides verbal feedback | Brian |
| Ranatunga et al. [70] | Robot task performance | TD() | Head and eye kinematic scheme of the robot | Zeno |
| Keizer et al. [1] | Robot task performance | Monte-Carlo control | The robot’s performance as a bartender | iCat |
| Qureshi et al. [36] | Robot task performance | Multimodal DQN | Numerical values based on robot’s handshake success | Pepper |
| Papaioannou et al. [60] | Robot task performance | Q-learning | Task completion of the robot | Pepper |
| Qureshi et al. [73] | Robot task performance | MDARQN | Numerical values based on robot’s handshaking success | Pepper |
| Hemminghaus et al. [3] | Robot task performance | Q-learning | Robot’s task performance and execution cost of the robot’s action | Furhat |
| Chen et al. [67] | Robot task performance | Q-learning | Numerical values based on correctly completed tasks | Mobile robots |
| Ritschel et al. [46] | Robot task performance | n-armed bandit | Robot’s performance at convincing user to select healthy drink | Reeti |
| Lathuiliere et al. [85,86] | Robot task performance | DQN | Number of observed faces and presence of speech sources in the visual field | Nao |
| Cuayahuitl [35] | Robot task performance | DQN | Numerical values based on robot’s performance in the game | Pepper |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akalin, N.; Loutfi, A. Reinforcement Learning Approaches in Social Robotics. Sensors 2021, 21, 1292. https://doi.org/10.3390/s21041292
Akalin N, Loutfi A. Reinforcement Learning Approaches in Social Robotics. Sensors. 2021; 21(4):1292. https://doi.org/10.3390/s21041292
Chicago/Turabian StyleAkalin, Neziha, and Amy Loutfi. 2021. "Reinforcement Learning Approaches in Social Robotics" Sensors 21, no. 4: 1292. https://doi.org/10.3390/s21041292
APA StyleAkalin, N., & Loutfi, A. (2021). Reinforcement Learning Approaches in Social Robotics. Sensors, 21(4), 1292. https://doi.org/10.3390/s21041292