A Mixed-Perception Approach for Safe Human–Robot Collaboration in Industrial Automation



 and
and 
Abstract
1. Introduction
- It is not possible to differentiate between people and other objects that enter the workspace of the cobot. Therefore, the speed is always reduced regardless of the object.
- It is also not possible to differentiate whether an interaction with the robot should really take place or not; this also always forces a maximum reduction in speed.
1.1. Human Action Recognition (HAR)
1.2. Contact Type Detection
2. Material and Methods
2.1. Mixed Perception Terminology and Design
- A human entering the shared workspace (Passing)
- A human observing its tasks when he/she is near to the robot and wants to supervise the robot task (Observation)
- A dangerous situation when the human is not in a proper situation to do collaboration or observation, which can threaten human safety (Dangerous Observation)
- A human interaction when the human is close to robot and doing the collaboration (Interaction).
2.2. Robotic Platform
2.3. Camera Systems
2.4. Standard Robot Collision Detection
2.5. Deep Learning Approach
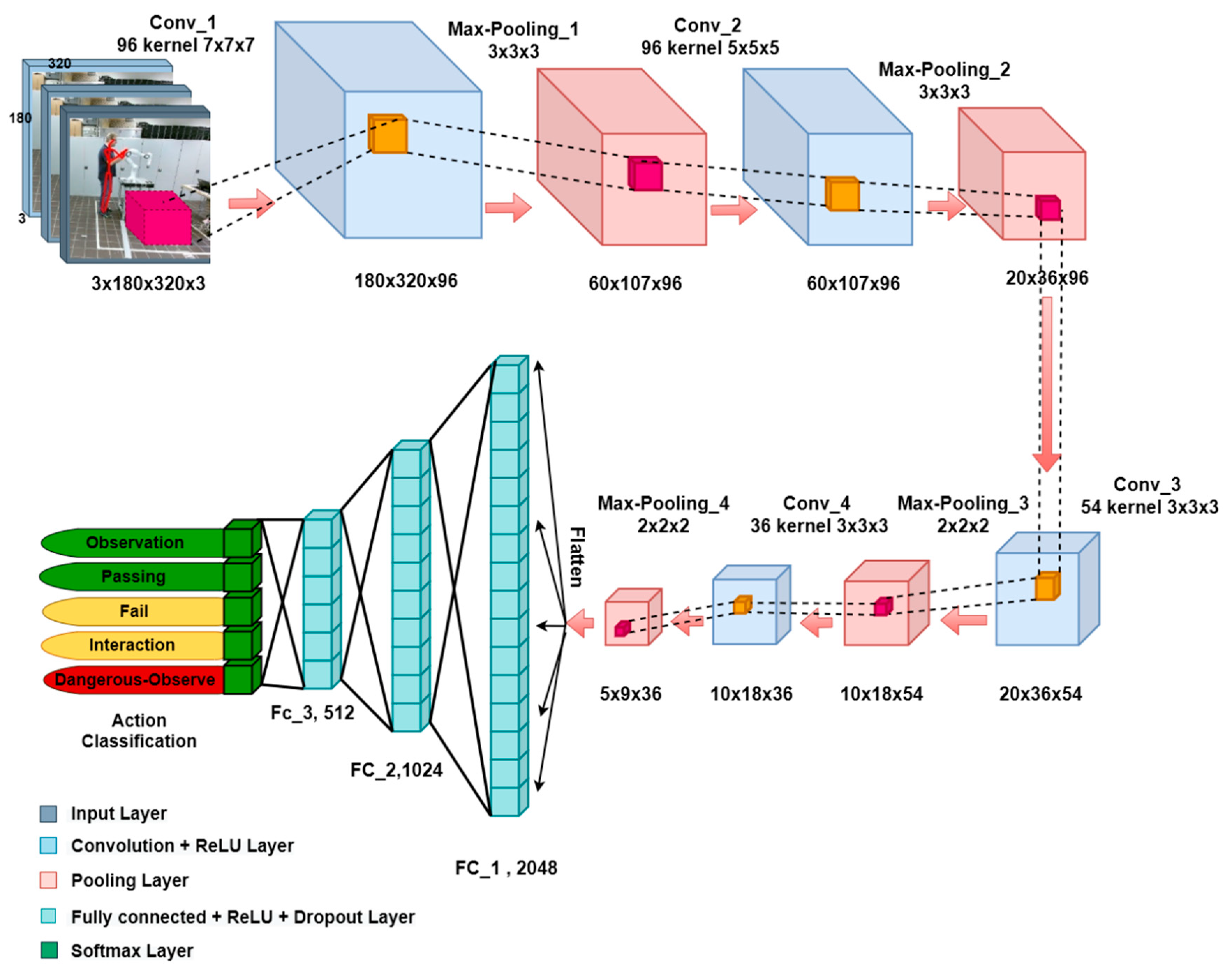
2.5.1. Human Action Recognition Network
- Passing: a human operator occasionally needs to enter the robot’s workspace, which is specified due to the fix position of the robot but without any intention to actively intervene the task execution of the robot.
- Interaction: a human operator wants to actively intervene the robot’s task execution, which can be the case due to correct a Tool Center Point (TCP) path or to help the robot if it gets stuck.
- Observation: the robot is working on its own and a human operator is about to observe and check the working process from within the robot’s workspace.
- Dangerous Observation: the robot is working on its own and a human operator is about to observe the working process. Due to the proximity of exposed body parts (head and upper extremities) to the robot in the shared workspace, there is a high potential of life-threatening injury in case of a collision.
- Fail: one or all system cameras are not able to detect the human operator in the workspace due to occlusion by the robot itself or other artefacts in the working area.
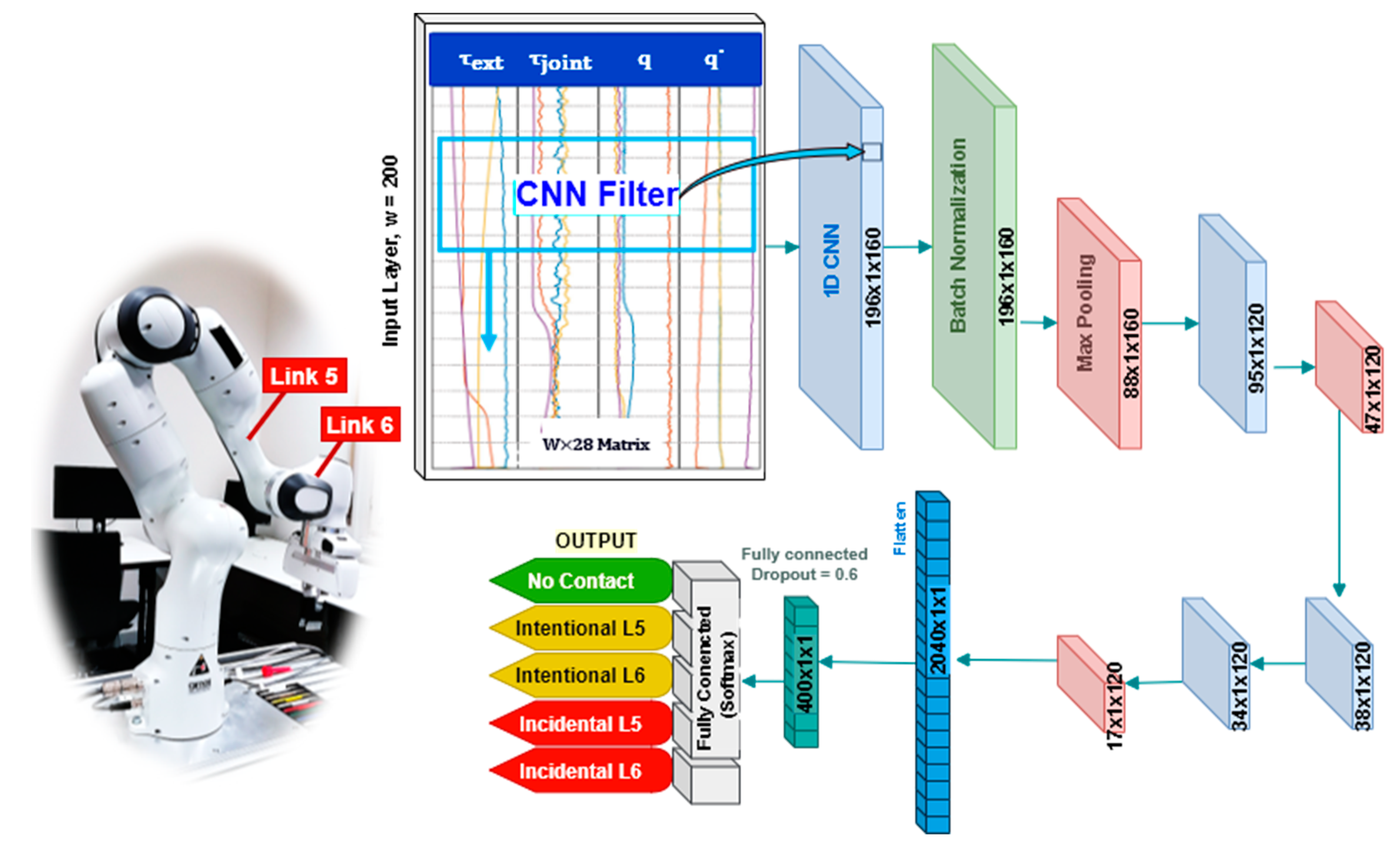
2.5.2. Contact Detection Network
- No-Contact: no contact is detected within the specified sensitivity.
- Intentional_Link5: an intentional contact at robot link 5 is detected.
- Incidental_Link5: a collision at robot link 5 is detected.
- Intentional_Link6: an intentional contact at robot link 6 is detected.
- Incidental_Link6: a collision at robot link 6 is detected.
2.6. Data Collection
2.6.1. Human Action Recognition
2.6.2. Contact Detection
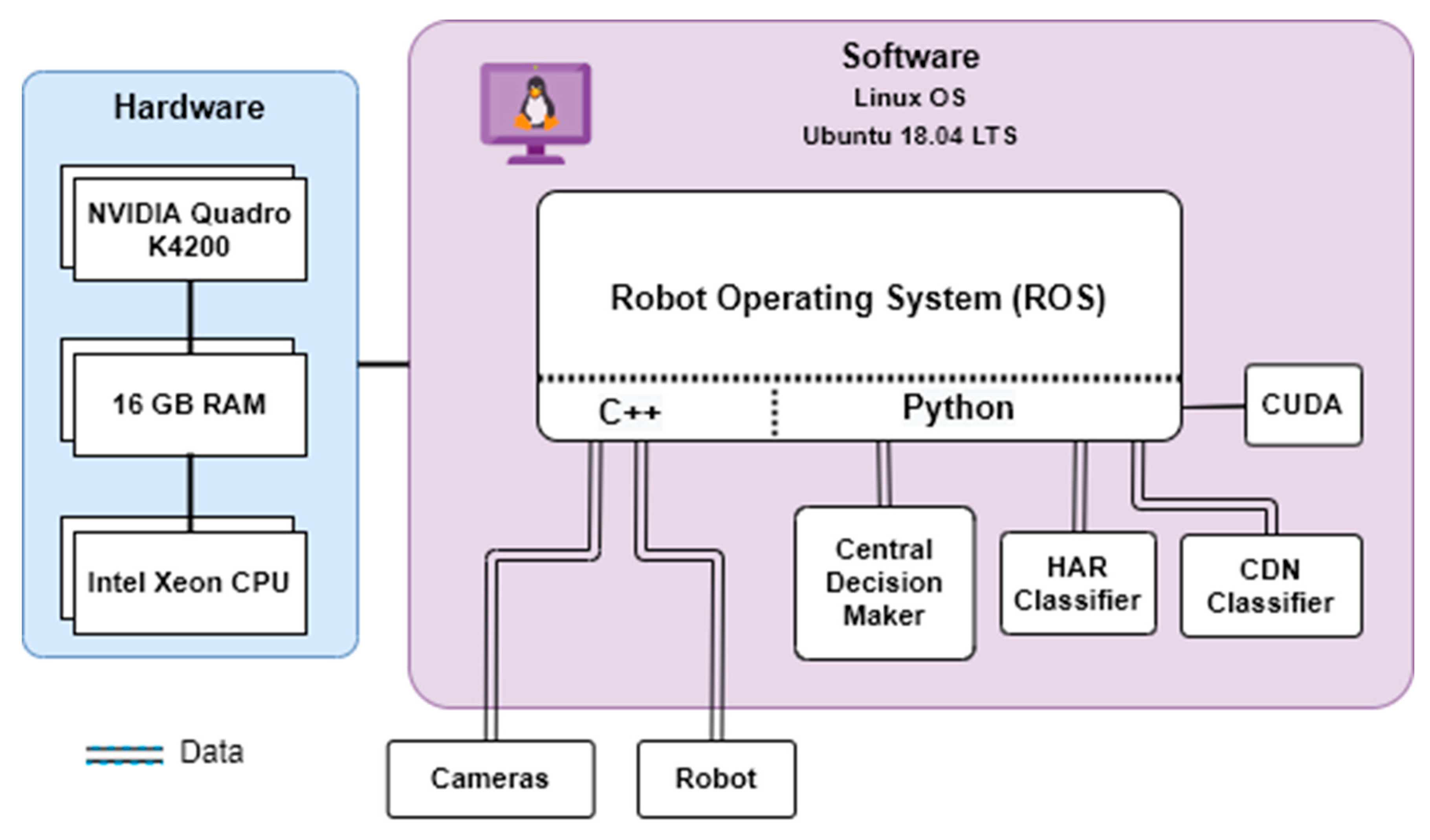
2.7. Training Hardware and API Setup
2.8. Real Time Interface
3. Results
3.1. Dataset
3.2. Comparison between Networks
3.2.1. Human Action Recognition
3.2.2. Contact Detection
3.2.3. Mixed Perception Safety Monitoring
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Robla-Gomez, S.; Becerra, V.M.; Llata, J.R.; Gonzalez-Sarabia, E.; Torre-Ferrero, C.; Perez-Oria, J. Working Together: A Review on Safe Human–Robot Collaboration in Industrial Environments. IEEE Access 2017, 5, 26754–26773. [Google Scholar] [CrossRef]
- Nikolakis, N.; Maratos, V.; Makris, S. A cyber physical system (CPS) approach for safe human–robot collaboration in a shared workplace. Robot. Comput. Integr. Manuf. 2019, 56, 233–243. [Google Scholar] [CrossRef]
- Villani, V.; Pini, F.; Leali, F.; Secchi, C. Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications. Mechatronics 2018, 55, 248–266. [Google Scholar] [CrossRef]
- Safety Fence Systems—F.EE Partner Für Automation. Available online: https://www.fee.de/en/automation-robotics/safety-fence-systems.html (accessed on 7 October 2020).
- PILZ Safety Sensors PSEN. Available online: https://www.pilz.com/en-INT/products/sensor-technology (accessed on 7 October 2020).
- Safe Camera System SafetyEYE—Pilz INT. Available online: https://www.pilz.com/en-INT/eshop/00106002207042/SafetyEYE-Safe-camera-system (accessed on 7 October 2020).
- Virtual Fence. Available online: https://www.densorobotics-europe.com/product-overview/products/robotics-functions/virtual-fence (accessed on 7 October 2020).
- Losey, D.P.; McDonald, C.G.; Battaglia, E.; O’Malley, M.K. A Review of Intent Detection, Arbitration, and Communication Aspects of Shared Control for Physical Human–Robot Interaction. Appl. Mech. Rev. 2018, 70. [Google Scholar] [CrossRef]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Otim, T.; Díez, L.E.; Bahillo, A.; Lopez-Iturri, P.; Falcone, F. Effects of the Body Wearable Sensor Position on the UWB Localization Accuracy. Electronics 2019, 8, 1351. [Google Scholar] [CrossRef]
- Moschetti, A.; Cavallo, F.; Esposito, D.; Penders, J.; Di Nuovo, A. Wearable sensors for human–robot walking together. Robotics 2019, 8, 38. [Google Scholar] [CrossRef]
- Otim, T.; Díez, L.E.; Bahillo, A.; Lopez-Iturri, P.; Falcone, F. A Comparison of Human Body Wearable Sensor Positions for UWB-based Indoor Localization. In Proceedings of the 10th International Conference Indoor Positioning Indoor Navigat, Piza, Italy, 30 September 2019; pp. 165–171. [Google Scholar]
- Rosati, S.; Balestra, G.; Knaflitz, M. Comparison of different sets of features for human activity recognition by wearable sensors. Sensors 2018, 18, 4189. [Google Scholar] [CrossRef]
- Xu, Z.; Zhao, J.; Yu, Y.; Zeng, H. Improved 1D-CNNs for behavior recognition using wearable sensor network. Comput. Commun. 2020, 151, 165–171. [Google Scholar] [CrossRef]
- Xia, C.; Sugiura, Y. Wearable Accelerometer Optimal Positions for Human Motion Recognition. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 19–20. [Google Scholar]
- Qian, H.; Mao, Y.; Xiang, W.; Wang, Z. Recognition of human activities using SVM multi-class classifier. Pattern Recognit. Lett. 2010, 31, 100–111. [Google Scholar] [CrossRef]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef]
- Manosha Chathuramali, K.G.; Rodrigo, R. Faster human activity recognition with SVM. In Proceedings of the International Conference on Advances in ICT for Emerging Regions (ICTer2012), Colombo, Sri Lanka, 12–15 December 2012; pp. 197–203. [Google Scholar]
- Sharma, S.; Modi, S.; Rana, P.S.; Bhattacharya, J. Hand gesture recognition using Gaussian threshold and different SVM kernels. In Proceedings of the Communications in Computer and Information Science, Dehradun, India, 20–21 April 2018; pp. 138–147. [Google Scholar]
- Berg, J.; Reckordt, T.; Richter, C.; Reinhart, G. Action recognition in assembly for human–robot-cooperation using hidden Markov Models. Procedia CIRP 2018, 76, 205–210. [Google Scholar] [CrossRef]
- Le, H.; Thuc, U.; Ke, S.-R.; Hwang, J.-N.; Tuan, P.V.; Chau, T.N. Quasi-periodic action recognition from monocular videos via 3D human models and cyclic HMMs. In Proceedings of the 2012 International Conference on Advanced Technologies for Communications, Hanoi, Vietnam, 10–12 October 2012; pp. 110–113. [Google Scholar]
- Hasan, H.; Abdul-Kareem, S. Static hand gesture recognition using neural networks. Artif. Intell. Rev. 2014, 41, 147–181. [Google Scholar] [CrossRef]
- Cho, W.H.; Kim, S.K.; Park, S.Y. Human action recognition using hybrid method of hidden Markov model and Dirichlet process Gaussian mixture model. Adv. Sci. Lett. 2017, 23, 1652–1655. [Google Scholar] [CrossRef]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Wang, P.; Liu, H.; Wang, L.; Gao, R.X. Deep learning-based human motion recognition for predictive context-aware human–robot collaboration. CIRP Ann. Manuf. Technol. 2018, 67, 17–20. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action Recognition in Video Sequences using Deep Bi-Directional LSTM with CNN Features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Zhao, Y.; Man, K.L.; Smith, J.; Siddique, K.; Guan, S.U. Improved two-stream model for human action recognition. Eurasip J. Image Video Process. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Gao, J.; Yang, Z.; Sun, C.; Chen, K.; Nevatia, R. TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3648–3656. [Google Scholar]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. Comput. Vis. Image Underst. 2018, 171, 118–139. [Google Scholar] [CrossRef]
- Gu, Y.; Ye, X.; Sheng, W.; Ou, Y.; Li, Y. Multiple stream deep learning model for human action recognition. Image Vis. Comput. 2020, 93, 103818. [Google Scholar] [CrossRef]
- Srihari, D.; Kishore, P.V.V.; Kiran Kumar, E.; Anil Kumar, D.; Teja, M.; Kumar, K.; Prasad, M.V.D.; Raghava Prasad, C. A four-stream ConvNet based on spatial and depth flow for human action classification using RGB-D data. Multimed. Tools Appl. 2020, 79, 11723–11746. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2018, 11205 LNCS, 106–121. [Google Scholar] [CrossRef]
- Cheng, J. Skeleton-Based Action Recognition with Directed Graph Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7912–7921. [Google Scholar]
- Trăscău, M.; Nan, M.; Florea, A.M. Spatio-temporal features in action recognition using 3D skeletal joints. Sensors 2019, 19, 423. [Google Scholar] [CrossRef]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Proceedings of the 2nd International Workshop on Human Behavior Understanding (HBU), Amsterdam, The Netherlands, 16 November 2011; pp. 29–39. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Latah, M. Human action recognition using support vector machines and 3D convolutional neural networks. Int. J. Adv. Intell. Inform. 2017, 3, 47–55. [Google Scholar] [CrossRef]
- Almaadeed, N.; Elharrouss, O.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A Novel Approach for Robust Multi Human Action Detection and Recognition based on 3-Dimentional Convolutional Neural Networks. arXiv 2019, arXiv:1907.11272. [Google Scholar]
- Arunnehru, J.; Chamundeeswari, G.; Bharathi, S.P. Human Action Recognition using 3D Convolutional Neural Networks with 3D Motion Cuboids in Surveillance Videos. Procedia Comput. Sci. 2018, 133, 471–477. [Google Scholar] [CrossRef]
- Asghari-Esfeden, S.; Io, S.; Sznaier, M.; Camps, O. Dynamic Motion Representation for Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 2–5 March 2020; pp. 557–566. [Google Scholar]
- Fan, H.; Luo, C.; Zeng, C.; Ferianc, M.; Que, Z.; Liu, S.; Niu, X.; Luk, W. F-E3D: FPGA-based acceleration of an efficient 3D convolutional neural network for human action recognition. In Proceedings of the 2019 IEEE 30th International Conference on Application-specific Systems, Architectures and Processors (ASAP), New York, NY, USA, 15–17 July 2019; pp. 1–8. [Google Scholar]
- Recognition of Human Actions. Available online: https://www.csc.kth.se/cvap/actions/ (accessed on 8 October 2020).
- Hoang, V.D.; Hoang, D.H.; Hieu, C.L. Action recognition based on sequential 2D-CNN for surveillance systems. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3225–3230. [Google Scholar]
- Kim, J.H.; Won, C.S. Action Recognition in Videos Using Pre-Trained 2D Convolutional Neural Networks. IEEE Access 2020, 8, 60179–60188. [Google Scholar] [CrossRef]
- Singh, I.; Zhu, X.; Greenspan, M. Multi-Modal Fusion With Observation Points For Skeleton Action Recognition. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), IEEE, Abu Dhabi, UAE, 25–28 October 2020; pp. 1781–1785. [Google Scholar]
- Weng, J.; Luo, D.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Jiang, X.; Yuan, J. Temporal Distinct Representation Learning for Action Recognition. arXiv 2020, arXiv:2007.07626. [Google Scholar]
- Akkaladevi, S.C.; Heindl, C. Action recognition for human robot interaction in industrial applications. In Proceedings of the 2015 IEEE International Conference on Computer Graphics, Vision and Information Security (CGVIS), Bhubaneswar, India, 2–3 November 2015; pp. 94–99. [Google Scholar]
- Roitberg, A.; Perzylo, A.; Somani, N.; Giuliani, M.; Rickert, M.; Knoll, A. Human activity recognition in the context of industrial human–robot interaction. In Proceedings of the 2014 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Chiang Mai, Thailand, 9–12 December 2014. [Google Scholar] [CrossRef]
- Olatunji, I.E. Human Activity Recognition for Mobile Robot. J. Phys. Conf. Ser. 2018, 1069, 4–7. [Google Scholar] [CrossRef]
- Duckworth, P.; Hogg, D.C.; Cohn, A.G. Unsupervised human activity analysis for intelligent mobile robots. Artif. Intell. 2019, 270, 67–92. [Google Scholar] [CrossRef]
- Cao, P.; Gan, Y.; Dai, X. Model-based sensorless robot collision detection under model uncertainties with a fast dynamics identification. Int. J. Adv. Robot. Syst. 2019, 16, 172988141985371. [Google Scholar] [CrossRef]
- Haddadin, S.; Albu-Schaffer, A.; De Luca, A.; Hirzinger, G. Collision Detection and Reaction: A Contribution to Safe Physical Human–Robot Interaction. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, Nice, France, 22–26 September 2008; pp. 3356–3363. [Google Scholar]
- de Luca, A.; Mattone, R. Sensorless Robot Collision Detection and Hybrid Force/Motion Control. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, IEEE, Barcelona, Spain, 18–22 April 2005; pp. 999–1004. [Google Scholar]
- Xiao, J.; Zhang, Q.; Hong, Y.; Wang, G.; Zeng, F. Collision detection algorithm for collaborative robots considering joint friction. Int. J. Adv. Robot. Syst. 2018, 15. [Google Scholar] [CrossRef]
- Cao, P.; Gan, Y.; Dai, X. Finite-Time Disturbance Observer for Robotic Manipulators. Sensors 2019, 19, 1943. [Google Scholar] [CrossRef]
- Luca, A.; Albu-Schaffer, A.; Haddadin, S.; Hirzinger, G. Collision Detection and Safe Reaction with the DLR-III Lightweight Manipulator Arm. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, Beijing, China, 9–15 October 2006; pp. 1623–1630. [Google Scholar]
- Ren, T.; Dong, Y.; Wu, D.; Chen, K. Collision detection and identification for robot manipulators based on extended state observer. Control Eng. Pract. 2018, 79, 144–153. [Google Scholar] [CrossRef]
- Min, F.; Wang, G.; Liu, N. Collision Detection and Identification on Robot Manipulators Based on Vibration Analysis. Sensors 2019, 19, 1080. [Google Scholar] [CrossRef]
- Haddadin, S. Towards Safe Robots: Approaching Asimov’s 1st Law; Springer: Berlin/Heidelberg, Germany, 2014; ISBN 9783642403088. [Google Scholar] [CrossRef]
- Haddadin, S.; De Luca, A.; Albu-Schaffer, A. Robot Collisions: A Survey on Detection, Isolation, and Identification. IEEE Trans. Robot. 2017, 33, 1292–1312. [Google Scholar] [CrossRef]
- Sharkawy, A.-N.; Koustoumpardis, P.N.; Aspragathos, N. Neural Network Design for Manipulator Collision Detection Based Only on the Joint Position Sensors. Robotica 2019, 1–19. [Google Scholar] [CrossRef]
- Sharkawy, A.-N.; Koustoumpardis, P.N.; Aspragathos, N. Human–robot collisions detection for safe human–robot interaction using one multi-input–output neural network. Soft Comput. 2019, 1–33. [Google Scholar] [CrossRef]
- Liu, Z.; Hao, J. Intention Recognition in Physical Human–Robot Interaction Based on Radial Basis Function Neural Network. Available online: https://www.hindawi.com/journals/jr/2019/4141269/ (accessed on 8 June 2020).
- Heo, Y.J.; Kim, D.; Lee, W.; Kim, H.; Park, J.; Chung, W.K. Collision Detection for Industrial Collaborative Robots: A Deep Learning Approach. IEEE Robot. Autom. Lett. 2019, 4, 740–746. [Google Scholar] [CrossRef]
- El Dine, K.M.; Sanchez, J.; Ramón, J.A.C.; Mezouar, Y.; Fauroux, J.-C. Force-Torque Sensor Disturbance Observer Using Deep Learning; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Pham, C.; Nguyen-Thai, S.; Tran-Quang, H.; Tran, S.; Vu, H.; Tran, T.H.; Le, T.L. SensCapsNet: Deep Neural Network for Non-Obtrusive Sensing Based Human Activity Recognition. IEEE Access 2020, 8, 86934–86946. [Google Scholar] [CrossRef]
- Gao, X.; Shi, M.; Song, X.; Zhang, C.; Zhang, H. Recurrent neural networks for real-time prediction of TBM operating parameters. Autom. Constr. 2019, 98, 225–235. [Google Scholar] [CrossRef]
- Yang, K.; Wang, X.; Quddus, M.; Yu, R. Predicting Real-Time Crash Risk on Urban Expressways Using Recurrent Neural Network. In Proceedings of the Transportation Research Board 98th Annual Meeting, Washington, DC, USA, 13–17 January 2019. [Google Scholar]
- Masood, S.; Srivastava, A.; Thuwal, H.C.; Ahmad, M. Real-Time Sign Language Gesture (Word) Recognition from Video Sequences Using CNN and RNN; Springer: Singapore, 2018; pp. 623–632. [Google Scholar]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently Recurrent Neural Network (IndRNN): Building a Longer and Deeper RNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5457–5466. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-Time Action Recognition with Enhanced Motion Vector CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2718–2726. [Google Scholar]
- Jin, C.-B.; Li, S.; Do, T.D.; Kim, H. Real-Time Human Action Recognition Using CNN Over Temporal Images for Static Video Surveillance Cameras; Springer: Cham, Switzerland, 2015; pp. 330–339. [Google Scholar]
- Pathak, D.; El-Sharkawy, M. Architecturally Compressed CNN: An Embedded Realtime Classifier (NXP Bluebox2.0 with RTMaps). In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0331–0336. [Google Scholar]
- Birjandi, S.A.B.; Kuhn, J.; Haddadin, S. Observer-Extended Direct Method for Collision Monitoring in Robot Manipulators Using Proprioception and IMU Sensing. IEEE Robot. Autom. Lett. 2020, 5, 954–961. [Google Scholar] [CrossRef]
- BaradaranBirjandi, S.A.; Haddadin, S. Model-Adaptive High-Speed Collision Detection for Serial-Chain Robot Manipulators. IEEE Robot. Autom. Lett. 2020. [Google Scholar] [CrossRef]
- Ullah, I.; Hussain, M.; Qazi, E.-H.; Aboalsamh, H. An automated system for epilepsy detection using EEG brain signals based on deep learning approach. Expert Syst. Appl. 2018, 107, 61–71. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests Tin Kam Ho Perceptron training. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Quebec, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Kinect for Windows v2. Available online: https://docs.depthkit.tv/docs/kinect-for-windows-v2 (accessed on 10 March 2020).
- Kim, C.; Yun, S.; Jung, S.W.; Won, C.S. Color and depth image correspondence for Kinect v2. Adv. Multimed. Ubiquitous Eng. 2015, 352, 111–116. [Google Scholar] [CrossRef]
- Rezayati, M.; van de Venn, H.W. Collision Detection in Physical Human Robot Interaction. Mendeley Data 2020, V1. [Google Scholar] [CrossRef]
- Cirillo, A.; Cirillo, P.; De Maria, G.; Natale, C.; Pirozzi, S. A Distributed Tactile Sensor for Intuitive Human–Robot Interfacing. J. Sens. 2017. [Google Scholar] [CrossRef]
- Khoramshahi, M.; Billard, A. A dynamical system approach to task-adaptation in physical human–robot interaction. Auton. Robots 2019, 43, 927–946. [Google Scholar] [CrossRef]
- Xiong, G.L.; Chen, H.C.; Xiong, P.W.; Liang, F.Y. Cartesian Impedance Control for Physical Human–Robot Interaction Using Virtual Decomposition Control Approach. Iran. J. Sci. Technol. Trans. Mech. Eng. 2019, 43, 983–994. [Google Scholar] [CrossRef]
- Johannsmeier, L.; Gerchow, M.; Haddadin, S. A Framework for Robot Manipulation: Skill Formalism, Meta Learning and Adaptive Control. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5844–5850. [Google Scholar]
- Yang, C.; Zeng, C.; Liang, P.; Li, Z.; Li, R.; Su, C.Y. Interface Design of a Physical Human–Robot Interaction System for Human Impedance Adaptive Skill Transfer. IEEE Trans. Autom. Sci. Eng. 2018, 15, 329–340. [Google Scholar] [CrossRef]
- Weistroffer, V.; Paljic, A.; Callebert, L.; Fuchs, P. A Methodology to Assess the Acceptability of Human–Robot Collaboration Using Virtual Reality. In Proceedings of the 19th ACM Symposium on Virtual Reality Software and Technology, Singapore, 6 October 2013; pp. 39–48. [Google Scholar]
- ISO/TS 15066:2016. Robots and Robotic Devices—Collaborative Robots; International Organization for Standardization: Geneva, Switzerland, 2016. [Google Scholar]
- Wen, X.; Chen, H.; Hong, Q. Human Assembly Task Recognition in Human–Robot Collaboration based on 3D CNN. In Proceedings of the 2019 IEEE 9th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Suzhou, China, 29 July–2 August 2019; pp. 1230–1234. [Google Scholar]
- Liu, H.; Wang, L. Gesture recognition for human–robot collaboration: A review. Int. J. Ind. Ergon. 2018, 68, 355–367. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2018, arXiv:1812.08008. [Google Scholar] [CrossRef]
- Fang, H.-S.; Xie, S.; Tai, Y.-W.; Lu, C.; Jiao Tong University, S.; YouTu, T. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2380–7504. [Google Scholar]
- Robertini, N.; Bernard, F.; Xu, W.; Theobalt, C. Illumination-invariant robust multiview 3d human motion capture. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1661–1670. [Google Scholar]
- Anvaripour, M.; Saif, M. Collision detection for human–robot interaction in an industrial setting using force myography and a deep learning approach. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2149–2154. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | 2D | 3D | ||
|---|---|---|---|---|
| Precision | Recall | Precision | Recall | |
| Observation | 0.99 | 0.99 | 1.00 | 1.00 |
| Interaction | 1.00 | 1.00 | 1.00 | 1.00 |
| Passing | 1.00 | 1.00 | 1.00 | 1.00 |
| Fail | 1.00 | 1.00 | 1.00 | 1.00 |
| Dangerous Observation | 0.98 | 0.96 | 0.98 | 0.99 |
| Accuracy | 0.9956 | 0.9972 | ||
| Network | 2D | 3D | |||||||||
| Observation | Interaction | Passing | Fail | Dangerous Observation | Observation | Interaction | Passing | Fail | Dangerous Observation | ||
| True Labels | Observation | 3696 | 7 | 2 | 0 | 5 | 3751 | 6 | 2 | 1 | 7 |
| Interaction | 13 | 4130 | 0 | 0 | 1 | 8 | 4030 | 0 | 0 | 0 | |
| Passing | 2 | 0 | 1145 | 0 | 0 | 1 | 0 | 1160 | 0 | 0 | |
| Fail | 0 | 0 | 0 | 593 | 0 | 0 | 0 | 0 | 588 | 0 | |
| Dangerous Observation | 12 | 1 | 0 | 0 | 313 | 2 | 0 | 0 | 0 | 359 | |
| w | 100 | 200 | 300 | 100 | 200 | 300 |
|---|---|---|---|---|---|---|
| Precision | Recall | |||||
| No-Contact | 0.94 | 0.99 | 0.98 | 0.94 | 1.00 | 1.00 |
| Intentional_Link5 | 0.74 | 0.91 | 0.89 | 0.84 | 0.91 | 0.84 |
| Intentional_Link6 | 0.68 | 0.97 | 0.91 | 0.64 | 0.90 | 0.91 |
| Incidental_Link5 | 0.61 | 0.89 | 0.83 | 0.61 | 0.93 | 0.89 |
| Incidental_Link6 | 0.69 | 0.96 | 0.96 | 0.57 | 0.96 | 0.93 |
| Accuracy | 0.78 | 0.96 | 0.93 | |||
| Window Size | 100 | 200 | 300 | |||||||||||||
| No-Contact | Intentional_Link5 | Intentional_Link6 | Incidental_Link5 | Incidental_Link6on | No-Contact | Intentional_Link5 | Intentional_Link6 | Incidental_Link5 | Incidental_Link6 | No-Contact | Intentional_Link5 | Intentional_Link6 | Incidental_Link5 | Incidental_Link6 | ||
| True Labels | No-Contact | 166 | 0 | 9 | 0 | 1 | 242 | 0 | 3 | 0 | 1 | 167 | 0 | 3 | 0 | 0 |
| Intentional_Link5 | 0 | 86 | 12 | 19 | 0 | 0 | 93 | 4 | 4 | 1 | 0 | 86 | 5 | 5 | 1 | |
| Intentional_Link6 | 8 | 1 | 59 | 2 | 17 | 0 | 3 | 83 | 0 | 0 | 0 | 5 | 84 | 0 | 3 | |
| Incidental_Link5 | 0 | 15 | 1 | 33 | 5 | 0 | 6 | 0 | 50 | 0 | 0 | 10 | 0 | 48 | 0 | |
| Incidental_Link6 | 3 | 0 | 11 | 0 | 31 | 0 | 0 | 2 | 0 | 52 | 0 | 1 | 0 | 1 | 50 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadi Amin, F.; Rezayati, M.; van de Venn, H.W.; Karimpour, H. A Mixed-Perception Approach for Safe Human–Robot Collaboration in Industrial Automation. Sensors 2020, 20, 6347. https://doi.org/10.3390/s20216347
Mohammadi Amin F, Rezayati M, van de Venn HW, Karimpour H. A Mixed-Perception Approach for Safe Human–Robot Collaboration in Industrial Automation. Sensors. 2020; 20(21):6347. https://doi.org/10.3390/s20216347
Chicago/Turabian StyleMohammadi Amin, Fatemeh, Maryam Rezayati, Hans Wernher van de Venn, and Hossein Karimpour. 2020. "A Mixed-Perception Approach for Safe Human–Robot Collaboration in Industrial Automation" Sensors 20, no. 21: 6347. https://doi.org/10.3390/s20216347
APA StyleMohammadi Amin, F., Rezayati, M., van de Venn, H. W., & Karimpour, H. (2020). A Mixed-Perception Approach for Safe Human–Robot Collaboration in Industrial Automation. Sensors, 20(21), 6347. https://doi.org/10.3390/s20216347