
A Robust Thermal Infrared Vehicle and Pedestrian Detection Method in Complex Scenes


Abstract
1. Introduction
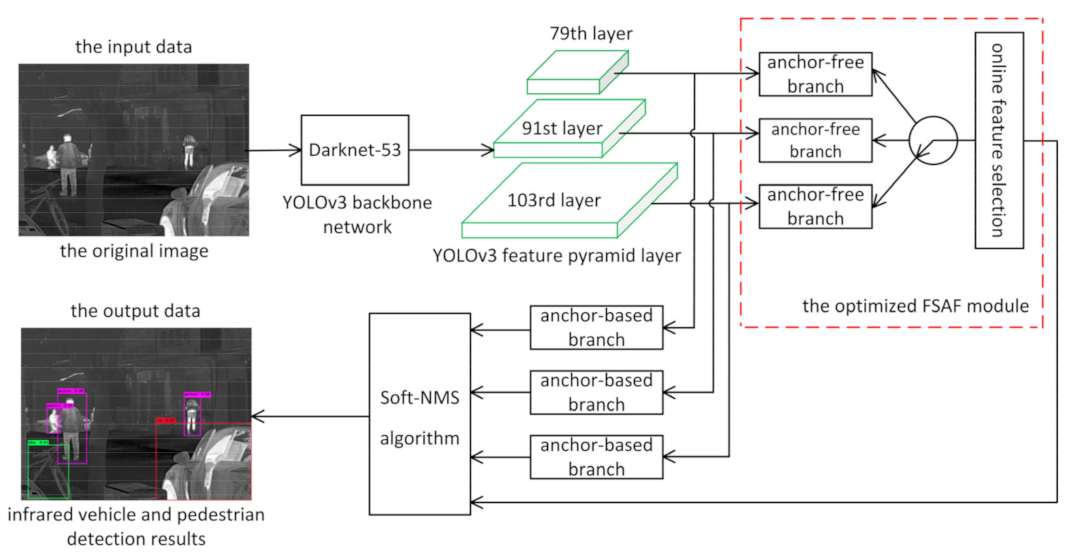
2. Algorithm Process
2.1. The FSAF Module
2.2. The Optimized FSAF Module
2.2.1. Adopting CIoU Loss
2.2.2. The Weight Parameter
2.3. Improved Detector Network Architecture
2.4. Employing Soft-NMS Algorithm
3. Experiments and Discussion
3.1. The Infrared Image Dataset
3.2. Experiment Details
3.3. Ablation Studies
3.4. Comparison to Other Infrared Object Detectors
3.5. Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Suard, F.; Rakotomamonjy, A.; Bensrhair, A.; Broggi, A. Pedestrian Detection using Infrared images and Histograms of Oriented Gradients. In Proceedings of the 2006 IEEE Intelligent Vehicles Symposium, Tokyo, Japan, 13–15 June 2006; pp. 206–212. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A.; Fascioli, T.; Graf, G.; Meinecke, M. Pedestrian detection for driver assistance using multiresolution infrared vision. IEEE Trans. Veh. Technol. 2004, 53, 1666–1678. [Google Scholar] [CrossRef]
- Dai, C.; Zheng, Y.; Li, X. Pedestrian detection and tracking in infrared imagery using shape and appearance. Comput. Vis. Image Underst. 2007, 106, 288–299. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, B.; Nevatia, R. Pedestrian detection in infrared images based on local shape features. In Proceeding of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 16–20 June 2007; pp. 1–8. [Google Scholar]
- Fardi, B.; Schuenert, U.; Wanielik, G. Shape and motion-based pedestrian detection in infrared images: A multi sensor approach. Proceeding of the IEEE Intelligent Vehicles Symposium, Toronto, ON, Canada, 17–20 September 2000; IEEE: Piscataway, NJ, USA, 2005; pp. 18–23. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Pisctaway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscatway, NJ, USA, 2017; Volume 39, pp. 1137–1149. [Google Scholar] [CrossRef]
- Shi, Y.I.; Yan, N.; Yang, Y.; Zhang, K. Nighttime Target Recognition Method Based on Infrared Thermal Imaging and YOLOv3. Infrared Technol. 2019, 41, 970–975. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, X.; Zhu, X. Vehicle Detection in the Aerial Infrared Images via an Improved Yolov3 Network. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; IEEE: Pisactaway, NJ, USA, 2019; pp. 372–376. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R. Feature Pyramid Networks for Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2017; pp. 936–944. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the National Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; IEEE: Piscatway, NJ, USA, 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5562–5570. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R. Focal Loss for Dense Object Detection. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2999–3007. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 2016 ACM on Multimedia Conference, Amsterdam, UK, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 315–323. [Google Scholar]
- Neubeck, A.; van Gool, L. Efficient non-maximum suppression. Proceeding of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 850–855. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Eslami, S.M.; van Gool, L. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6517–6525. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. arXiv 2017, arXiv:1711.10398. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Online Feature Selection Loss | mAP (%) | |
|---|---|---|---|---|
| FSAF | DarkNet-53 | 66.1 | ||
| Ours | DarkNet-53 | 0.25 | 52.3 | |
| 0.40 | 63.1 | |||
| 0.50 | 66.1 | |||
| 0.60 | 68.5 | |||
| 0.75 | 52.7 | |||
| 68.3 | ||||
| 0.25 | 54.4 | |||
| 0.40 | 64.6 | |||
| 0.50 | 68.3 | |||
| 0.60 | 70.7 | |||
| 0.75 | 54.9 |
| Method | Anchor-Based Branches | Anchor-Free Branches | CIoU Loss | Soft-NMS | mAP (%) |
|---|---|---|---|---|---|
| YOLOv3 | √ √ √ | √ √ | √ | 65.8 66.9 68.1 | |
| Ours | √ √ √ | √ √ √ | √ √ | √ | 67.9 70.7 72.2 |
| Method | Backbone | mAP (%) | FPS |
|---|---|---|---|
| Two-stage: | |||
| Faster R-CNN | ResNet-101 [31] | 64.1 | 2 |
| One-stage: | |||
| YOLOv2 | DarkNet-19 [29] | 54.1 | 40 |
| SSD513 | ResNet-101 | 59.6 | 8 |
| DSSD513 | ResNet-101 | 62.5 | 6 |
| YOLOv3 | Darknet-53 [17] | 65.8 | 20 |
| Ours (AB+AF) | Darknet-53 | 72.2 | 18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Su, H.; Zeng, C.; Li, X. A Robust Thermal Infrared Vehicle and Pedestrian Detection Method in Complex Scenes. Sensors 2021, 21, 1240. https://doi.org/10.3390/s21041240
Liu Y, Su H, Zeng C, Li X. A Robust Thermal Infrared Vehicle and Pedestrian Detection Method in Complex Scenes. Sensors. 2021; 21(4):1240. https://doi.org/10.3390/s21041240
Chicago/Turabian StyleLiu, Yang, Hailong Su, Cao Zeng, and Xiaoli Li. 2021. "A Robust Thermal Infrared Vehicle and Pedestrian Detection Method in Complex Scenes" Sensors 21, no. 4: 1240. https://doi.org/10.3390/s21041240
APA StyleLiu, Y., Su, H., Zeng, C., & Li, X. (2021). A Robust Thermal Infrared Vehicle and Pedestrian Detection Method in Complex Scenes. Sensors, 21(4), 1240. https://doi.org/10.3390/s21041240