Abstract
We propose a novel generative adversarial network (GAN)-based image denoising method that utilizes heterogeneous losses. In order to improve the restoration quality of the structural information of the generator, the heterogeneous losses, including the structural loss in addition to the conventional mean squared error (MSE)-based loss, are used to train the generator. To maximize the improvements brought on by the heterogeneous losses, the strength of the structural loss is adaptively adjusted by the discriminator for each input patch. In addition, a depth wise separable convolution-based module that utilizes the dilated convolution and symmetric skip connection is used for the proposed GAN so as to reduce the computational complexity while providing improved denoising quality compared to the convolutional neural network (CNN) denoiser. The experiments showed that the proposed method improved visual information fidelity and feature similarity index values by up to 0.027 and 0.008, respectively, compared to the existing CNN denoiser.
1. Introduction
Image denoising has been studied for several decades and studies on image denoising continue to be actively conducted due to its high utilization value in various applications. Specifically, image denoising plays an important role in improving the performance of image enhancement, feature extraction, and object recognition.
The ultimate goal of image denoising is to remove image noise while preserving structural information, such as the edges and details of a given noisy image. For structural information-preserving denoising, various denoising methods have been proposed. These conventional denoising methods can be categorized as model-based optimization methods and deep learning-based methods [1].
Model-based optimization methods [2,3,4,5,6,7,8] have been extensively studied and widely used for image denoising. The most popular model-based optimization methods are anisotropic diffusion (AD) [2], total variation (TV) [3], bilateral filter (BF) [4], non-local means filter (NLM) [5], block-matching and 3D filtering (BM3D) [6], and weighted nuclear norm minimization (WNNM) [7]. In the case of AD and TV, noise elimination is performed based on the pixel-wise similarity between the current pixel and its neighboring pixels in a given noisy image. NLM, BM3D, and WNNM restore a given noisy image by using non-local similarity (NSS) which is based on the patch-wise similarity between the current patch and the other patches in a given noisy image. These NSS-based denoising methods significantly improve the quality of image denoising compared to the pixel-similarity based methods, but the computational complexity is also greatly increased.
Recently, deep learning methods [1,9,10,11,12,13,14,15,16] using clean-noisy image pairs have been widely exploited due to the rapid development of deep learning technology. In [9], the multi-layer perceptron (MLP) for image denoising was proposed. In addition to this, various deep learning methods based on the convolutional neural network (CNN) have been proposed. The most popular CNN-based methods are denoising convolutional neural networks (DnCNN) [10], and image restoration convolutional neural networks (IRCNN) [1]. These CNN-based methods greatly enhance the performance of image denoising compared to the model-based optimization methods by using the CNN-based end-to-end transformation.
Of the existing image denoising methods, BM3D, WNNM, DnCNN, and IRCNN provide excellent performances of image denoising, but are all still limited in terms of the effective preservation of structural information, such as texture and weak edges. In addition, CNN-based methods have very high computational complexities, requiring the multiplication of several tens of thousands for the convolution processes.
In this paper, we propose a new generative adversarial network (GAN)-based denoiser to improve the quality of detail preservation by using the heterogeneous losses, consisting of the structural loss and the mean squared error (MSE)-based loss. The balance of these losses is adjusted by the gradient fidelity between the original and restored images, which is estimated by the discriminator of the GAN [17] during the training process. As a result, it is possible to maintain the quality of noise suppression while restoring the structural information to be most similar to that of the original image from the viewpoint of the discriminator. In addition, we greatly reduce the computational complexity of the proposed GAN denoiser compared to that of the existing CNN denoisers. The main contributions of this work are summarized as follows:
A new GAN denoiser is proposed to improve the restoration quality of structural information by incorporating the discriminator-based gradient fidelity, and the MSE-based loss. Specifically, unlike existing methods, the proposed discriminator uses gradient values as an input to effectively estimate the structural fidelity between the original and restored images. The balancing parameter for the gradient fidelity with the MSE-based loss is adjusted depending on the estimation result by the discriminator. This means that the balancing power for heterogeneous losses can be adjusted by considering the optimal denoising direction of the input image and it leads the best reproduction of the structural information of the original image. In addition to the heterogeneous losses, we propose a new structure of GAN denoiser that can reduce the computational complexity while providing improved denoising performance by using the capsulized depth-wise separable convolution (DSC) [18] with the dilated convolution and symmetric skip connection (DSDC) compared to the existing CNN denoisers [1,10,11].
2. Materials and Methods
2.1. Overall Architecture
Figure 1 shows the overall architecture of the proposed GAN denoiser. The proposed method consists of a generator (G) and a discriminator (D), same as the conventional GAN [17]. In our work, we utilize this training approach with the heterogeneous losses, which will be described in Section 2.3.
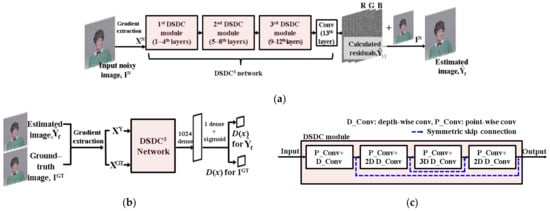
Figure 1.
Overall architecture of the proposed GAN denoiser: (a) generator, (b) discriminator, and (c) element module of the proposed method (depth-wise separable convolution using dilated convolution and symmetric skip connection (DSDC)).
As shown in Figure 1, in the proposed GAN denoiser, the G and the D have 13 convolution layers. To improve the denoising quality of the proposed network, we use multiple symmetric skip connections (DSDCs) that are the element modules of the proposed network and contain the dilated convolution–based depth-wise separable convolution (DSC) [18] and symmetric skip connection between two dilated convolutions having the same dilation size as shown in Figure 1c. The G uses the CNN structure based on an end-to-end transformation. In the case of the D, the two fully connected layers are added to the last convolution layer so that the scalar probability value indicating whether the input image is a noise-free image can be derived. For the input of the G and the D, gradients of a given input are used, as shown in [19]. The gradients are extracted from eight neighborhoods of a current pixel, and there are three kinds of color channels. Therefore, the total 24 feature channels are used as inputs for the G and the D. In the case of the G, this gradient input can increase its denoising performance [19]. In the case of the D, this can help the D estimate the fidelity of structural information between the restored and the noise-free images.
2.2. Architecture of the Proposed Network
2.2.1. Generator
The general CNN architecture that uses the end-to-end transformation is used for the G in the same way as the existing CNN denoisers [1,10]. Batch normalization (BN) [20] and the ReLU [21] are selectively applied to each layer as in shown Table 1. In this table, Conv in the 13th layer represents the general convolution operation. P_conv and D_conv represent a point-wise convolution and a depth-wise convolution, respectively.

Table 1.
The structure of a generator.
When the D_conv is applied, the dilated convolution [22] is used to increase the receptive field of convolution operation. Since each feature channel to which the D_conv is applied already contains the combined result of the previous FD1 feature maps, the dilated convolution is a very effective approach for enhancing the denoising performance. Compared to the existing networks that increase the size of the dilation in half of the entire layers and then decrease it in the rest layers [1,10,19], the proposed method uses the DSDC module to create multiple cycles that repeat the expansion and contraction of the dilation size to prevent the artifacts that may occur as the size of the dilation becomes too large. Also, the symmetric skip connection can increase the efficiency of information transfer between dilated convolutions. In our method, the number of layers, FD1, and FD2 were set to 13, 96, and 96, respectively, by considering the total number of weights for convolution and the quality of image denoising. Specifically, we determined the numbers of layers and FD1, FD2 values so that only the smaller number of parameters than existing CNNs can be used while providing a comparable to or better denoising quality than the existing CNNs [1,10,19]. Even if the number of convolution layers, FD1, and FD2, are increased, the computational complexity of the proposed method is much smaller than that of the conventional CNN denoisers [1,10] which use the general convolution process because the decrease in computational complexity by the DSC overwhelms the increase in the computational complexity by the increase in the number of layer, FD1, and FD2. In particular, the selected values of FD1 and FD2 are determined by analyzing the variations in the denoising performance against the increases in FD1 and FD2 values. The generation of each convolution layer by the DSC and Conv can be formulated as follows:
where L is an index for the convolution layer. , and biasL are the Lth resultant convolution layer and the bias for the Lth convolution, respectively. XN is the input data of the proposed network. In our work, XN is the 24 kinds of gradients of the input noisy image, as shown in [19].
, , and WL are the weight sets for Lth P_conv, D_conv, and Conv, respectively, and BN is the batch normalization operator. In addition to this convolution operation, symmetric skip connection is used as in Figure 1c. For the training of the proposed network, residual learning [23] that trains the network to convert a given input data to the residual between a training input data and its ground-truth data, which denotes image noise is used. Hence, the final restored image by the G can be calculated by:
where IN and are the noisy and final restored images, respectively. is the final result of the G and denotes the negative value of image noise.
2.2.2. Discriminator
In the general GAN [17], the following adversarial min-max problem is used for training:
where IGT and IN are a ground-truth image and an input noisy image, respectively. Ptrain and PG are the data distributions of the ground-truth image and resultant image by the G. D (·) denotes the output of the D, which indicates the probability that the current input is the ground-truth. The G(IN) denotes the output of the G for a given noisy image, thus, it is the restored image from a noisy image by the G. Therefore, the D is trained so that D(IGT) is close to 1 and so that D(G(IN)) is close to 0.
We utilize this training process of the general GAN for the training of the proposed method. The general CNN denoiser [1,10] is trained using MSE between the ground-truth and restored images. In this case, some small structural information, such as weak edges or texture, can be lost because the training is performed only in the direction of reducing MSE of the entire image. We alleviate this problem by incorporating MSE and the gradient-based structural loss that can be adjusted by the result of the D. In the proposed method, the D uses the gradients of a given ground-truth image (XGT) and the gradients of the restored images (XY) as an input as shown in Figure 1b so that it can estimate the restoration quality of gradient information of the G. (IGT and G(IN) in Equation (3) is changed to XGT and XY, respectively.) For example, a high D(XGT) and a low D(XY) indicate that the performance of gradient information restoration of the G is lower than the classification accuracy of the D. For this case, the strength of structural loss is increased for the training of the G, while in the opposite case, MSE-based loss is increased for the training of the G. Through this training strategy, the proposed GAN reproduces the structural information most similar to that of the ground-truth image while maintaining the quality of noise suppression in smooth regions. This loss function and training process used for the proposed method will be described in detail in Section 2.3.
Table 2 shows the structure of the proposed D. The D is composed of 13 convolution layers as in G, and BN and ReLU are applied between the two consecutive convolution layers. After the 13th convolution layer, two dense layers are connected. Finally, the sigmoid activation function is applied to extract the scalar probability value that the input image is the original noise-free image. Because the G is intended to deduce the original pixel value from a noisy input patch, whereas the D is intended to determine the probability that the input patch is the original patch, we consider that the problem difficulty of the G is higher than that of the D. Hence, we set the size of the future channel of the D (FD1 and FD2) to 1/3 that of the G, so that we can balance the performances between the G and the D.
Table 2.
The structure of a discriminator.
2.3. GAN-Based Heterogeneous Losses Function
The GAN-based denoiser is described in Section 2.2.2. In the general GAN, training for G and D is performed using the results of G and D as described in Equation (3). For the proposed D, the training is performed in the same way as the training of the general GAN by maximizing loss described in Equation (3). For the proposed G, the training using Equation (3) can also be applied. However, this training approach is not suitable for the G (CNN denoiser) that transforms a given noisy image to a denoised image in an end-to-end manner. This is because the purpose of the GAN is to understand or learn an intended context of a given image and reproduce the intended context, not to accurately restore each pixel value. Hence, we propose a new heterogeneous losses function, which consists of MSE-based loss (Lossresidual), GAN loss (LossGAN), and structural loss (Lossstruct). Lossstruct is calculated from the fidelity of structural information between the original image and restored image by the G, which is estimated by the D. These are used as an auxiliary loss to Lossresidual in order to improve the preservation quality of structural information while also increasing the overall performance of noise suppression during the training process in a stable manner as follows:
where i and NT denote the index for training patch pairs and the total number of training patch pairs, respectively. L is the final loss value for the training. Lossresidual denotes the residual loss, that is, MSE between the resultant image by the G and the ground-truth data. In our work that utilizes the residual learning, the target data of the training is the residual (difference) of an input noisy image and a noise-free image, which represents the negative value of image noise. LossGAN is the general GAN loss denoted in Equation (3). Lossstruct denotes the structural loss, that is, the dissimilarity between the gradients of a noise-free image and a resultant image by the G. α is the balancing factor for Lossstruct, which can be controlled by the results of the proposed GAN. In our method, α indicates the inverse fidelity of structural information between the original image and the produced image by the G. The α value was determined as the value obtained by dividing the output of the D for the gradient values of IGT and the output D for the gradient values of resultant image by G. More specifically, the meaning of the value α can be said to be an index that evaluates how well the generator has preserved structural information after denoising from the point of view of a discriminator. Therefore, as the difficulty of restoring structural information increases, the α value increases, and the Lossstruct is more reflected in the update of the convolution coefficient than the Lossresidual. This value will be explained in detail in a later paragraph.
As shown in this equation, the Lossresidual is calculated by using MSE between results by the G and the residual (IGT − IN) image. The Lossresidual plays a key role in improving the overall performance of noise suppression in a stable manner during the training process. However, as mentioned before, some weak structural information, such as texture or weak edges, can be lost because the training of the G is performed in order to improve the overall pixel-wise similarity between the IGT and the restored image by the G. In order to alleviate this, Lossstruct and LossGAN are added to Lossresidual. LossGAN is defined as follows:
where XGT and XY are the gradient values of IGT and , as shown in Figure 2, respectively. In addition to LossGAN, Lossstruct is defined as follows:
where Dir indicates the direction of gradient values. λ is the offset value and was empirically set to 32. ND was set to 24 because gradients on eight neighborhoods of the current pixel in three color channels were used. Considering that the gradient of a given image is the most basic and important information used to derive structural information, Lossstruct can effectively reflect the loss of structural information. Figure 3 shows example results of the normalized Lossresidual and Lossstruct of training patches. As shown in this figure, compared with the energy distribution of Lossresidual, the energy distribution of Lossstruct is concentrated in the texture or edge areas, having a relatively high amount of structural information in a training patch.
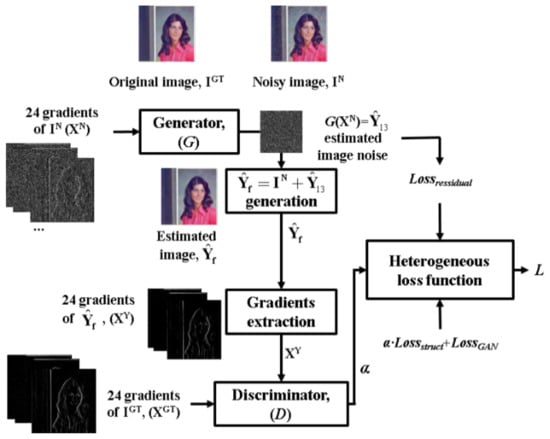
Figure 2.
The proposed GAN-based training model using the gradient fidelity-based heterogeneous loss function.

Figure 3.
Examples of Lossresidual and Lossstruct: 1st row: original patches, 2nd row: resultant patches by the G, 3rd row: normalized Lossresiduals, 4th row: normalized Lossstructs.
Therefore, if the balance between Lossresidual and Lossstruct can be adjusted depending on the characteristics of the patch, the qualities of noise suppression and the preservation of structural information can be maximized. Hence, we tried to set the ideal training direction using α as the balancing value. To estimate the characteristics of the patch, we utilized the result of D as shown in Equation (4). As mentioned in Section 2.2.2, the D provides two probabilities (D(XGT), D(XY)) ranging from 0 to 1. These values represent the fidelity of structural information between IGT and , that are the original patch and restored patch by the G. By using these probabilities, α can be defined as follows:
where κ is the scaling factor and was set to 3 through the extensive experiments. In our method, 1 in numerator and denominator is the offset value. If the value of D(XGT(i)) is large and the value of D(XY(i)) is small, this indicates that it is easy to distinguish the XGT(i) from the XY(i) from the viewpoint of the D. In other words, the restoration result of the gradients information by the G for the corresponding ith input training pair is not accurate, indicating that the G provides a restored image that has a low fidelity of structural information with respect to XGT. In this case, α is increased (to be closed to κ × ((1 + 1)/(0 + 1)) = κ × 2) so as to increase the strength of Lossstruct. As a result, the training is concentrated on improving the fidelity of the structural information. In the opposite case, the accuracy of gradient restoration of the G is high, which leads to a decrease in α (to be closed to κ × ((0.5 + 1)/(0.5 + 1)) = κ × 1). In this case, the training is focused on smoothing-based noise suppression. Consequently, the strength of Lossstruct can be continuously updated depending on the fidelity between the gradient of the IGT and , and this fidelity can be estimated by the D. The patch including a texture region with high energy is generally more difficult to restore than the patch including a smooth region or a region having clear boundaries, thus, it is likely to have a low fidelity of structural information (as it is easy to be smoothed). These characteristics are well reflected by α value. Figure 4 shows examples of IGT and paired with their α values. As shown in this figure, the patches with relatively low energy (Figure 4a), including unclear boundaries, have low α values, thus the loss function with a strong Lossresidual value is used for training. For this case, the strong noise suppression is performed. For the patches with clear boundaries (Figure 4b), a moderate strength of Lossstruct is used for training. Finally, for the patches with texture areas (Figure 4c), a high α value is applied and a strong Lossstruct is used for training. Hence, the texture region that is easy to be smoothed by a denoiser can be effectively preserved. The utilization effectiveness of the α for improving the preservation quality of structural information will be analyzed in the experimental results.

Figure 4.
Examples of original (left) patches and resultant patches (right) by G with α values. (noise level: σn = 25) (a) α < = κ × 1.100 (b) κ × 1.100 ≤ α < κ × 1.600 (c) κ × 1.600 ≤ α.
3. Simulation Results
Simulations for testing were performed with widely-used color testing sets, which are Kodak, misc1 (CIPR_M), and Cannon datasets (CIPR_C) from the CIPR image databases (CIPR) [24]. In addition, images captured from the IEC62087 (IEC) [25], football sequences [26], and CBSD68 dataset that is the color version of the grayscale BSD68 dataset were also used as test image sets. For the image noise model, additive white Gaussian noise (AWGN) with typical values of 15, 25, and 35 σns was used [1,10,19,27].
The color versions of NLM (NLMC) [5], block-matching, and 3D filtering (BM3DC) [6], which are popular image denoising methods, were used as benchmark methods. The weighted nuclear norm minimization (WNNM) [7] and Multi-channel WNNM (MCWNNM) [8] which are the recent state-of-the-art image denoising methods were also used as a benchmark method. All of these methods were simulated using publicly available MATLAB code. Other benchmark methods were the color versions of MLP [9], DnCNNC [10], IRCNNC [1], and MemNetC [11] which are recent CNN denoisers. For the generation of denoised results of MLP, DnCNNC, and IRCNNC, we used the already trained parameters provided by publicly available MATLAB code. For the case of MemNetC, we trained the model by using same environments with the proposed method. The training environments will be described below.
An Adam solver [28] was used for the training of parameters in the proposed CNN denoiser. The initial step size for each iteration of training was set to 3 × 10−2, and the step size was decreased to 9/10 for every 2000 iterations. The training was terminated when the loss function defined in Equation (4) no longer decreased. For the training images, we used a total of 4000 images, of which 500 were selected from the Berkeley Segmentation Dataset [29], 3000 were selected from the ImageNet database (3000 of the front images out of a total of 5500 images in ILSVRC2017 Object detection test dataset) [30], and 500 were selected from the Waterloo Exploration Database [31] (500 of the front images out of a total of 4744 images). The size of the training patch was set to 70 × 70 pixels considering the receptive field of our method, and training patches were randomly cropped from the four corners and centers of the training images. The mini-batch size for each iteration was set to 20. The proposed method was implemented using the tensor flow [32].
The performances of the proposed method with the five benchmark methods were evaluated in two ways: First, the qualities of image denoising were compared using the PSNR, structural similarity index (SSIM) [33], visual information fidelity (VIF) [34], and feature similarity index (FSIM) [35] values. Although PSNR is the most widely used objective evaluation method for image quality, it is limited in evaluating the loss of small structural information or perceptual image quality, because it is calculated by considering only the squared difference between the original pixel value and the resulting pixel value. In order to alleviate this, SSIM, which can consider the similarity of structural information between the resultant and ground-truth images, is proposed. However, SSIM is also based on MSE [36], so the difference of pixel values can dominate its resulting value rather than the fidelity of structural information for some images. Therefore, we added VIF and FSIM, which are widely used for various image processing applications [37,38,39,40,41,42,43,44] to the PSNR and SSIM as the image quality evaluation metric to accurately evaluate the quality of structural information preservation. VIF, which is based on image information fidelity measures the similarity between images by the amount of information that can be extracted by the brain from a given image. The value of VIF is equal to 1 when the resultant image is a copy of the ground-truth image. FSIM provides the feature similarity index by measuring the similarity of low-level features between resultant and ground-truth images. By using VIF and FSIM, we could more accurately evaluate the improvements obtained through the usage of GAN-based heterogeneous losses.
3.1. Comparisons of Denoising Quality
Table 3 shows the PSNR, SSIM, VIF, and FSIM values for the five benchmark methods and the two kinds of proposed methods, which are Pro_w/o_D (DSDC3) and Pro_wtih_D. The Pro_w/o_D (DSDC3) is the proposed G which uses the three DSDCs as shown in Figure 1a and does not use the D and Lossstruct during training, and the Pro_wtih_D is the proposed G which uses the D with Lossstruct during training. As shown in this table, except the MemNetC which requires the tremendous computational complexity, the Pro_w/o_D provided the best PSNR and SSIM values for most noise levels and image sets while using a much smaller number of convolution weights than the DnCNNC and IRCNNC. (The comparison of computational complexity will be analyzed in detail in Section 3.2). This demonstrated that the proposed DSDC3 network, which has a cascade structure of the three DSDCs, is a very effective convolution approach to image denoising. The MemNetC provided slightly higher denoising quality than the proposed DSDC3 network, but it has a much higher computational complexity. For the fair comparison, we compared the proposed method with the MemNetC by increasing the number of DSDC. Table 4 shows the PSNR and SSIM values of the proposed DSDC5 network (Pro_w/o_D_DSDC5) that uses the five DSDCs, and MemNetC. As shown in this table, the proposed method provided slightly higher or comparable denoising quality while it still has a much smaller computational complexity than the MemNetC, which will be analyzed in a later paragraph.
Table 3.
PSNRs, SSIMs, VIFs, and FSIMs of the benchmark and proposed methods.
Table 4.
PSNR and SSIM values of the MemNetC and the proposed method using the increased number of DSDCs (DSDC5 network).
In the Pro_w/o_D, since only the Lossresidual was used for the loss function, there was a problem in that some weak structural information could not be effectively preserved. Compared to the Pro_w/o_D, the Pro_wtih_D that uses Lossstruct in addition to Lossresidual, and the D provided slightly lower PSNR and SSIM values, but provided higher VIF and FSIM values that more accurately estimated the fidelity of structural information between the ground-truth and resultant images. To evaluate the utilization effectiveness of the α, we compared the denoising performances of the Pro_wtih_D that adjusts α value by using the results of the D as in Equation (8) and Pro_wtih_D without α that fixes the value of α to 1. As shown in Table 5, the Pro_wtih_D without α provided lower VIF and FSIM values that indicate the quality of structural information preservation than those of the Pro_wtih_D. This is because the D-based α-value adjustment allows training to be performed in the direction optimized for the characteristics of the input training data and the G.
Table 5.
PSNRs, SSIMs, VIFs, and FSIMs of the Pro_wtih_D and Pro_wtih_D without α in Equation (8).
Figure 5 and Figure 6 showed the resultant images by the benchmark methods, the Pro_w/o_D, and the Pro_wtih_D for noise level, σn = 35. Figure 5 showed resultant images by the benchmark methods, the Pro_w/o_D, and the Pro_wtih_D. As in Figure 5, the deep learning-based methods provided the better qualities of noise elimination. Among the deep learning-based methods, the Pro_wtih_D most effectively preserved the small details that are spread throughout the statue face. In addition, the Pro_wtih_D showed an outstanding result in the preservation of rough textures around metal ball. In Figure 6, the Pro_wtih_D showed the best quality of detail preservation in animal’s tail and the ear compared with the benchmark methods. This is because the training of the Pro_wtih_D was performed in order to best reproduce the structural information of the restored image by the G as close as possible to the noise-free image by adjusting the strength of Lossstruct depending on the result of the D.

Figure 5.
Denoised results of the benchmark and proposed methods for AWGN (noise level: σn = 35). (a) Original image (cropped from 4th (1st row), 15th (2nd row) and 22th (3rd row) images in Kodak image set) (b) Noisy image, (c) Image by NLMC, (d) Image by BM3DC, (e) Image by WNNM, (f) Image by DnCNNC, (g) Image by IRCNNC, (h) Image by MemNetC, (i) Image by the proposed method without D (Pro_w/o_D (DSDC3)), and (j) Image by the proposed method with D (Pro_wtih_D (DSDC3)).

Figure 6.
Denoised results of the benchmark and proposed methods for AWGN (noise level: σn = 35). (a) Original image with two enlarged patches (cropped from 20th image in CBSD68 image set) (b) Noisy image, (c) Image by NLMC, (d) Image by BM3DC, (e) Image by WNNM, (f) Image by DnCNNC, (g) Image by IRCNNC, (h) Image by MemNetC, (i) Image by the proposed method without D (Pro_w/o_D (DSDC3)), and (j) Image by the proposed method with D (Pro_wtih_D (DSDC3)).
3.2. Comparisons of Computational Complexity
As shown in Section 3.1, of the benchmark methods, DnCNNC, IRCNNC, and MemNetC which are CNN-based denoisers, showed improved quality of denoising results than the other benchmark methods. In addition, the proposed method (Pro_w/o_D and Pro_wtih_D) is also a CNN denoiser. Thus, among the benchmark methods, we compared the computational complexities of the proposed method with DnCNNC, IRCNNC, and MemNetC. The Pro_w/o_D and the Pro_wtih_D have the same number of weights for their networks, since the use of the D is only applied during the training. This indicates that the computational complexity of the proposed G is equal to the computational complexity of the proposed method.
Since addition and subtraction operations require a very small amount of hardware resources compared to multiplication, the number of multiplications for convolution operations dominantly determines the computational complexity of the entire network. Hence, we compared the number of multiplications for each method for the comparison of the computational complexities of the benchmark and proposed methods, as shown in Table 6. As shown in this table, the proposed method (DSDC3) greatly reduced the number of multiplications to 20.96% and 62.12% compared to the DnCNNC and IRCNNC, respectively, while providing higher PSNR and SSIM values for the various test image sets and noise levels. Compared with the MemNetC, the number of multiplications of the proposed methods using DSDC3 and DSDC5 are 2.34% and 3.96% of the MemNetC. In addition to the comparison of the number of multiplications, we compared the processing times (CTs) of the benchmark and the proposed methods. The CTs of each method were measured by using tensorflow on a PC with an Intel I7 7700 processor at 3.60 GHz, 16 GB DDR3s, and an Nvidia Titan X (Pascal) GPU. As shown in Table 7, although the proposed method (DSDC3) has fewer number of multiplications than the DnCNNC and IRCNNC, the CT of the proposed method was slightly larger than the DnCNNC and IRCNNC. This is due to the fact that the proposed method has more convolution stages (because of DSC) in situations where each convolution layer was completely parallelized. However, the number of multiplications has the biggest effect on the cost for the HW implementation. Hence, the reduced number of multiplications of the proposed method could be an advantage in hardware design or CPU-based processing systems. In addition, the proposed method provided a noticeable improvement in denoising performance over the DnCNNC and IRCNNC. Compared with the MemNetC, the proposed method showed a much lower CT while providing the better or comparable denoising performance. This reduction of computational complexity of CNN can enhance the feasibility of CNN implementation in mobile applications and can increase energy efficiency.
Table 6.
Comparison of the number of multiplications.
Table 7.
Comparison of the processing time per pixel (CT).
4. Conclusions
In this paper, we proposed a novel GAN denoiser that uses heterogeneous losses, consisting of MSE-based loss and structural loss, for its training in order to improve the quality of detail preservation while maintaining the quality of noise suppression. In addition, a DSC-based module that utilizes the dilated convolution and symmetric skip connection was used for the proposed GAN denoiser in order to greatly reduce the computational complexity of the proposed network while maintaining or slightly increasing the denoising performance. In the proposed method, training was carried out so as to improve the quality of detail preservation using the GAN structure. By adjusting the strength of the proposed structural loss depending on the gradient fidelity between the original and restored images, which is calculated by the discriminator, we could reproduce the structural information most similar to that of the original image while maintaining the quality of noise suppression in smooth regions.
The advantages of the proposed method were verified on various test images and by noise levels. The proposed method showed the best denoising quality by providing various image quality indexes that were superior to those of the benchmark methods while greatly reducing the computational complexity.
Author Contributions
Conceptualization S.I.C., and S.-J.K.; methodology, S.I.C., and S.-J.K.; software, S.I.C. and J.H.P.; validation, S.I.C., J.H.P., and S.-J.K.; formal analysis, S.I.C., and S.-J.K.; investigation, S.I.C., and S.-J.K.; resources, S.I.C., and S.-J.K.; data curation, S.I.C., J.H.P., and S.-J.K.; writing—original draft preparation, S.I.C., and S.-J.K.; writing—review and editing, S.I.C., J.H.P., and S.-J.K.; visualization, S.I.C. and J.H.P.; supervision, S.-J.K.; project administration, S.I.C.; funding acquisition, S.I.C. and S.-J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP; Ministry of Science, ICT & Future Planning) (No. 2020R1C1C1009662 and NRF-2020×1A3A1093880).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2808–2817. [Google Scholar]
- Perona, P.; Malik, J. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Bombay, India, 4–7 January 1998; pp. 839–846. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 2862–2869. [Google Scholar]
- Xu, J.; Zhang, L.; Zhang, D.; Feng, X. Multi-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1105–1113. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 2392–2399. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1712–1722. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 3155–3164. [Google Scholar]
- Yin, J.; Chen, B.; Li, Y. Highly Accurate Image Reconstruction for Multimodal Noise Suppression Using Semisupervised Learning on Big Data. IEEE Trans. Multimed. 2018, 20, 3045–3056. [Google Scholar] [CrossRef]
- Hou, X.; Luo, H.; Liu, J.; Xu, B.; Sun, K.; Gong, Y.; Liu, B.; Qiu, G. Learning Deep Image Priors for Blind Image Denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; pp. 1738–1747. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mehdi, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Polytechnique University, Palaiseau, France, 2014. [Google Scholar]
- Cho, S.I.; Kang, S.-J. Gradient Prior-aided CNN Denoiser with Separable Convolution-based Optimization of Feature Dimension. IEEE Trans. Multimed. 2019, 21, 484–493. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Lake Tahoe, NV, USA, 2012. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 20 June–1 July 2016; pp. 770–778. [Google Scholar]
- CIPR Database. Available online: http://www.cipr.rpi.edu/resource/stills/index.html (accessed on 19 January 2021).
- Jones, K. Methods of measurement for the power consumption of audio, video and related equipment. In ENERGY STAR Program. Requirements for Displays; ENERGY STAR Program Requirements for Displays: Washington, DC, USA, 2008. [Google Scholar]
- Football Sequences. Available online: http://media.xiph.org/video/derf/ (accessed on 19 January 2021).
- Cho, S.I.; Kang, S.-J. Geodesic path-based diffusion acceleration for image denoising. IEEE Trans. Multimed. 2018, 20, 1738–1750. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Fowlkes, C.C.; Martin, D.R.; Malik, J. Local figure–ground cues are valid for natural images. J. Vis. 2007, 7, 1–9. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2017, 26, 1004–1016. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Li, T.H.; Li, Z.; Han, T.Y.; Rahardja, S.; Yeo, C. A perceptually relevant MSE-based image quality. IEEE Trans. Image Process. 2013, 22, 4447–4459. [Google Scholar]
- Shao, L.; Yan, R.; Li, X.; Liu, Y. From heuristic optimization to dictionary learning: A review and comprehensive comparison of image denoising algorithms. IEEE Trans. Cybern. 2014, 44, 1001–1013. [Google Scholar] [CrossRef]
- Kang, L.-W.; Lin, C.-W.; Fu, Y.-H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans. Image Process. 2012, 21, 1742–1755. [Google Scholar] [CrossRef]
- Huang, T.-H. Enhancement of Backlight-Scaled Images. IEEE Trans. Image Process. 2013, 22, 4587–4597. [Google Scholar] [CrossRef]
- Li, S.; Kang, X. Fast multi-exposure image fusion with median filter and recursive filter. IEEE Trans. Consum. Electron. 2012, 58, 626–632. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Zhang, J.; Dai, Q. CCR: Clustering and collaborative representation for fast single image super-resolution. IEEE Trans. Multimed. 2016, 18, 405–417. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, X.; Chen, C.; Lu, T.; Wang, Z.; Ma, J. Single image super-resolution via locally regularized anchored neighborhood regression and nonlocal means. IEEE Trans. Multimed. 2017, 19, 15–26. [Google Scholar] [CrossRef]
- Du, B.; Zhang, M.; Zhang, L.; Hu, R.; Tao, D. PLTD: Patch-based low-rank tensor decomposition for hyperspectral images. IEEE Trans. Multimed. 2017, 19, 67–79. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Xiong, R.; Ma, S.; Gao, W.; Sun, H. Image interpolation via regularized local linear regression. IEEE Trans. Image Process. 2011, 20, 3455–3469. [Google Scholar] [PubMed]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).