
Lightweight Feature Enhancement Network for Single-Shot Object Detection


Abstract
1. Introduction
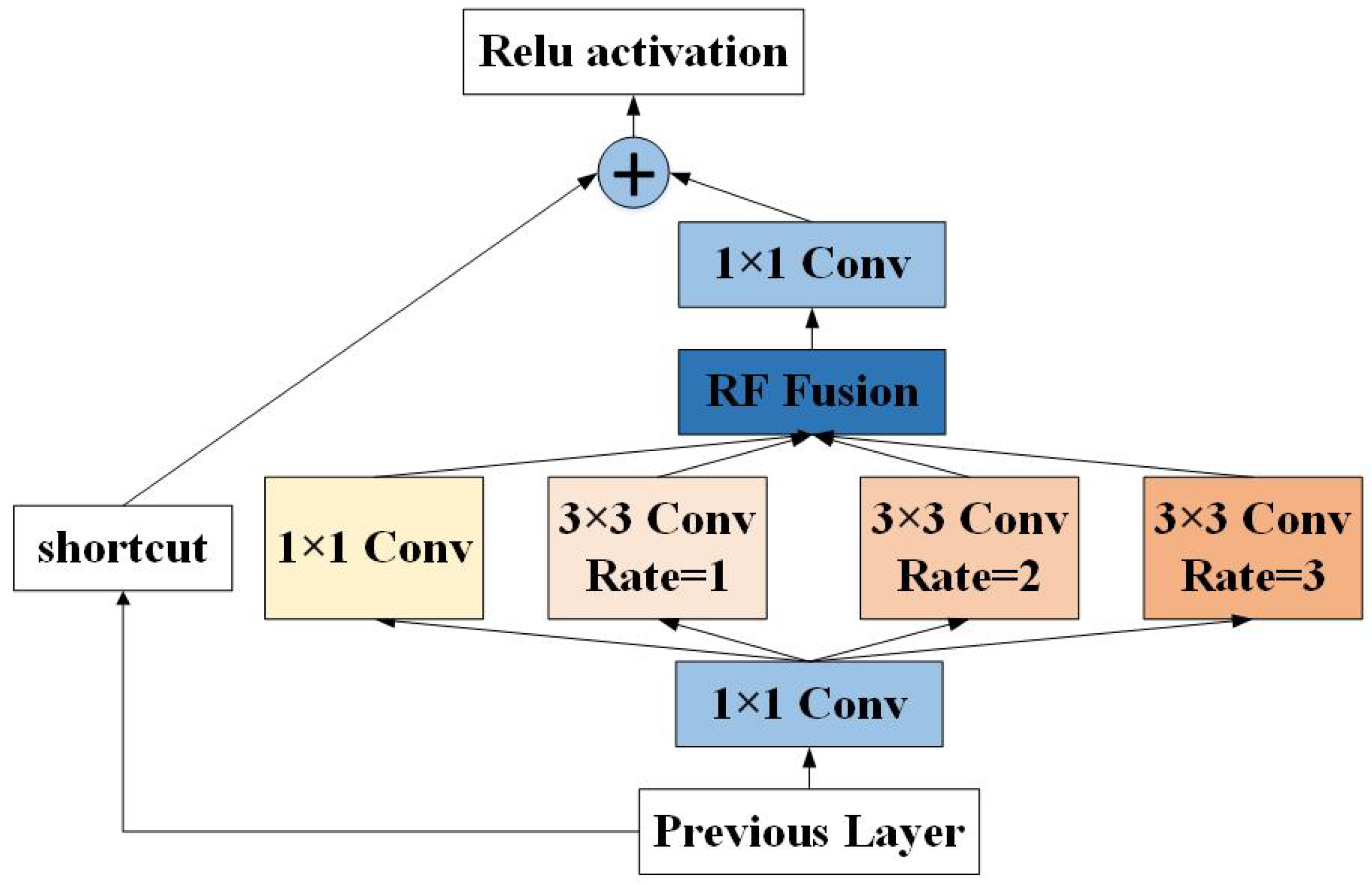
- We propose an ARFF module that adaptively learns the fusion weights of different RF branches in the RF module to enhance the model’s feature representation ability.
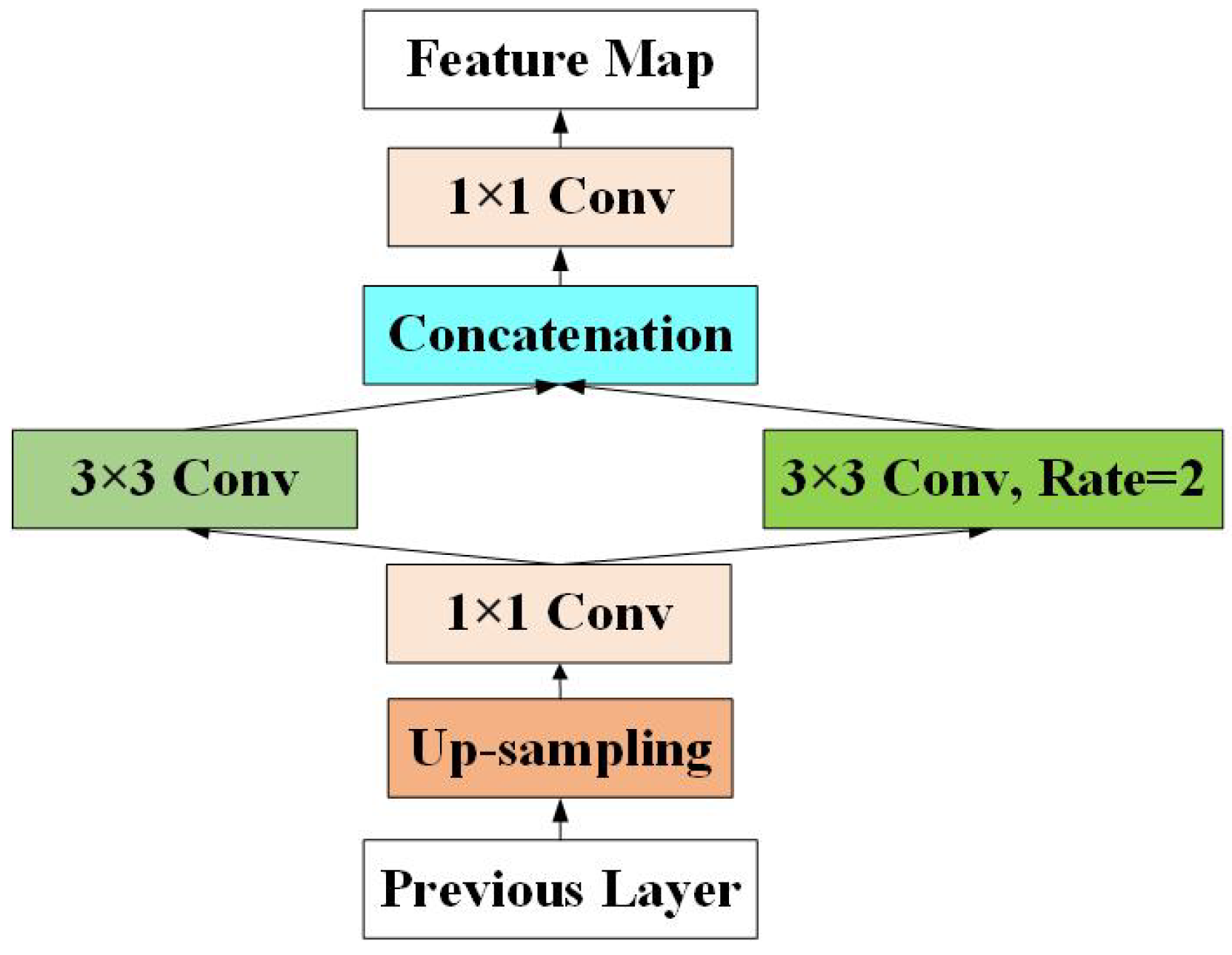
- We propose an EU module that can reduce the information loss in the up-sampling process, enhance the semantic information in the shallow layer of the feature pyramid and improve the detection performance of small objects.
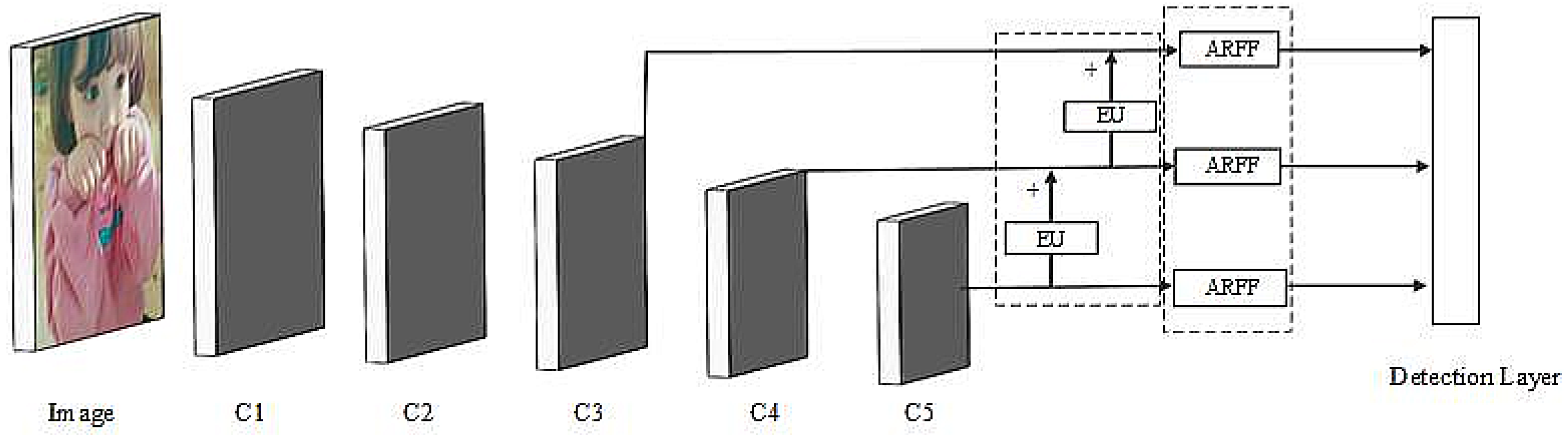
- We integrate the ARFF and EU modules on top of YOLO v3 to build a lightweight object detector that achieves the development of advanced, very deep detectors while maintaining real-time speed.
2. Related Works
2.1. Object Detection
2.2. Receptive Field
3. Methods
3.1. Adaptive Receptive Field Fusion
3.2. Enhanced Up-Sampling
3.3. ARFF-EU Network Detection Architecture
4. Experiments
4.1. The Datasets
4.2. Training Settings
4.3. Pascal VOC
4.4. Ablation Study
4.4.1. Adaptive Receptive Field Fusion
4.4.2. Enhanced Up-Sampling
4.4.3. ARFF-EU Object Detector
4.5. Microsoft COCO

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | FPS | GPU | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|---|
| Two-stage Detectors: | |||||||||
| Faster w FPN | ResNet-101-FPN | 11.0 | V100 | 39.8 | 61.3 | 43.3 | 22.9 | 43.3 | 52.6 |
| Mask R-CNN | ResNext-101-FPN | 6.5 | V100 | 41.4 | 63.4 | 45.2 | 24.5 | 44.9 | 51.8 |
| Cascade R-CNN | ResNet-101-FPN | 9.6 | V100 | 42.8 | 62.1 | 46.3 | 23.7 | 45.5 | 55.2 |
| SNIPER | ResNet-101 | 5.0 | V100 | 46.1 | 67.0 | 52.6 | 29.6 | 48.9 | 58.1 |
| One-stage Detectors: | |||||||||
| SSD512 | VGG | 22 | Titan X | 28.8 | 48.5 | 30.3 | - | - | - |
| RFB Net512 | VGG | 33 | Titan X | 33.8 | 54.2 | 35.9 | 16.2 | 37.1 | 47.4 |
| CornerNet-511 | Hourglass-104 | 5 | Titan X | 40.5 | 56.5 | 43.1 | 19.4 | 42.7 | 53.9 |
| YOLO v3 @416 | Darknet-53 | 45.8 | 2080Ti | 31.0 | - | - | - | - | - |
| Baseline416 | Darknet-53 | 40.8 | 2080Ti | 37.2 | 58.1 | 40.2 | 18.7 | 40.3 | 52.6 |
| EU416 | Darknet-53 | 40.0 | 2080Ti | 39.6 | 59.6 | 43.0 | 22.2 | 42.6 | 54.7 |
| ARFF416 | Darknet-53 | 37.2 | 2080Ti | 40.3 | 60.5 | 44.0 | 21.5 | 43.9 | 56.2 |
| ARFF-EU @416 | Darknet-53 | 36.6 | 2080Ti | 41.2 | 61.6 | 44.8 | 24.1 | 44.4 | 50.8 |
| RetinaNet800 | ResNet-101-FPN | 9.3 | V100 | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| FCOS-800 | ResNet-101-FPN | 13.5 | V100 | 41.0 | 60.7 | 44.1 | 24.0 | 44.1 | 51.0 |
| YOLO v3 @608 | Darknet-53 | 40.6 | 2080Ti | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| Baseline608 | Darknet-53 | 37.1 | 2080Ti | 39.0 | 60.4 | 42.3 | 23.2 | 41.7 | 50.8 |
| EU608 | Darknet-53 | 36.8 | 2080Ti | 41.0 | 61.5 | 44.6 | 26.0 | 43.7 | 51.2 |
| ARFF608 | Darknet-53 | 34.2 | 2080Ti | 41.7 | 61.8 | 45.6 | 25.4 | 44.7 | 52.6 |
| ARFF-EU @608 | Darknet-53 | 33.7 | 2080Ti | 42.5 | 62.4 | 45.7 | 26.2 | 44.8 | 52.9 |
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kang, K.; Ouyang, W.; Li, H.; Wang, X. Object detection from video tubelets with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 817–825. [Google Scholar]
- Satzoda, R.K.; Trivedi, M.M. Overtaking & receding vehicle detection for driver assistance and naturalistic driving studies. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 697–702. [Google Scholar]
- Li, L.J.; Socher, R.; Fei-Fei, L. Towards total scene understanding: Classification, annotation and segmentation in an automatic framework. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2036–2043. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Ying, J.C.; Li, C.Y.; Wu, G.W.; Li, J.X.; Chen, W.J.; Yang, D.L. A deep learning approach to sensory navigation device for blind guidance. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 1195–1200. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Marindra, A.M.J.; Tian, G.Y. Chipless RFID sensor for corrosion characterization based on frequency selective surface and feature fusion. Smart Mater. Struct. 2020, 29, 125010. [Google Scholar] [CrossRef]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Zhuang, S.; Wang, P.; Jiang, B.; Wang, G.; Wang, C. A single shot framework with multi-scale feature fusion for geospatial object detection. Remote Sens. 2019, 11, 594. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Sun, F.; Kong, T.; Huang, W.; Tan, C.; Fang, B.; Liu, H. Feature pyramid reconfiguration with consistent loss for object detection. IEEE Trans. Image Process. 2019, 28, 5041–5051. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Luo, P.; Wang, Z. Receptive field enrichment network for pedestrian detection. In Proceedings of the 2019 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 23–25 August 2019; Volume 11321, p. 113211K. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017 2017; pp. 764–773. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Bell, S.; Lawrence Zitnick, C.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 483–499. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, G.; Wang, K.; Lin, L. Adaptively connected neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1781–1790. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of freebies for training object detection neural networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. Sniper: Efficient multi-scale training. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 9310–9320. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]






| Method | Backbone | Dataset | FPS | GPU | mAP(%) | Input Size |
|---|---|---|---|---|---|---|
| Two-stage Detectors: | ||||||
| Faster R-CNN | VGG | 07+12 | 7 | Titan X | 73.2 | |
| R-FCN | ResNet-101 | 07+12 | 12 | Titan X | 79.5 | |
| CoupleNet | ResNet-101 | 07+12 | 9.8 | Titan X | 81.7 | |
| One-stage Detectors: | ||||||
| SSD512 | VGG | 07+12 | 19 | Titan X | 78.5 | |
| SSD513 | ResNet-101 | 07+12 | 7.5 | Titan X | 81.1 | |
| FSSD512 | VGG | 07+12 | 35.7 | 1080Ti | 80.9 | |
| DSSD513 | ResNet-101 | 07+12 | 5.5 | Titan X | 81.5 | |
| YOLO v3 | Darknet-53 | 07+12 | - | 2080Ti | 79.4 | |
| RFB Net608* | Darknet-53 | 07+12 | 38 | 2080Ti | 83.0 | |
| Baseline416 | Darknet-53 | 07+12 | 48.9 | 2080Ti | 82.0 | |
| EU416 | Darknet-53 | 07+12 | 48.0 | 2080Ti | 82.4 | |
| ARFF416 | Darknet-53 | 07+12 | 42.8 | 2080Ti | 82.7 | |
| ARFF+EU @416 | Darknet-53 | 07+12 | 41.1 | 2080Ti | 83.0 | |
| Baseline608 | Darknet-53 | 07+12 | 44.6 | 2080Ti | 82.6 | |
| EU608 | Darknet-53 | 07+12 | 43.8 | 2080Ti | 82.9 | |
| ARFF608 | Darknet-53 | 07+12 | 38.5 | 2080Ti | 83.3 | |
| ARFF+EU @608 | Darknet-53 | 07+12 | 37.5 | 2080Ti | 83.6 |
| Baseline608 | RFB Net608* | ARFF608 | EU608 | ARFF-EU @608 | ||
|---|---|---|---|---|---|---|
| +RFB | 🗸 | |||||
| +Multi-branch RF | 🗸 | 🗸 | ||||
| +RF Fusion (ARFF) | 🗸 | 🗸 | ||||
| +EU | 🗸 | 🗸 | ||||
| mAP (%) | 82.6 | 83.0 | 82.9 | 83.3 | 82.9 | 83.6 |
| FPS | 44.6 | 38 | 42 | 38.5 | 43.8 | 37.5 |
| Architecture | VOC 2007 Test Set mAP (%) |
|---|---|
| ARFF608 | 83.3 |
| RFB Net608* | 83.0 |
| RFB | 80.1 |
| Inception | 78.4 |
| Deformable CNN | 79.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, P.; Liu, F. Lightweight Feature Enhancement Network for Single-Shot Object Detection. Sensors 2021, 21, 1066. https://doi.org/10.3390/s21041066
Jia P, Liu F. Lightweight Feature Enhancement Network for Single-Shot Object Detection. Sensors. 2021; 21(4):1066. https://doi.org/10.3390/s21041066
Chicago/Turabian StyleJia, Peng, and Fuxiang Liu. 2021. "Lightweight Feature Enhancement Network for Single-Shot Object Detection" Sensors 21, no. 4: 1066. https://doi.org/10.3390/s21041066
APA StyleJia, P., & Liu, F. (2021). Lightweight Feature Enhancement Network for Single-Shot Object Detection. Sensors, 21(4), 1066. https://doi.org/10.3390/s21041066