
Single Target SAR 3D Reconstruction Based on Deep Learning

 , ,
, ,
Abstract
1. Introduction
- Propose a novel 3D super-resolution network based on the architecture of UNet for reconstructing single target from three observation orbits by learning the prior distribution of targets, which to the best of our knowledge is the first attempt using a 3D super-resolution network to reconstruct a target structure and backscattering coefficient in SAR 3D imaging research;
- Comparative experiments on the performance of the proposed network using an open dataset show impressive improvement both in quality and in quantity compared with the classical compressed sensing (CS) algorithm and back-projection (BP) algorithm.
2. Materials and Methods
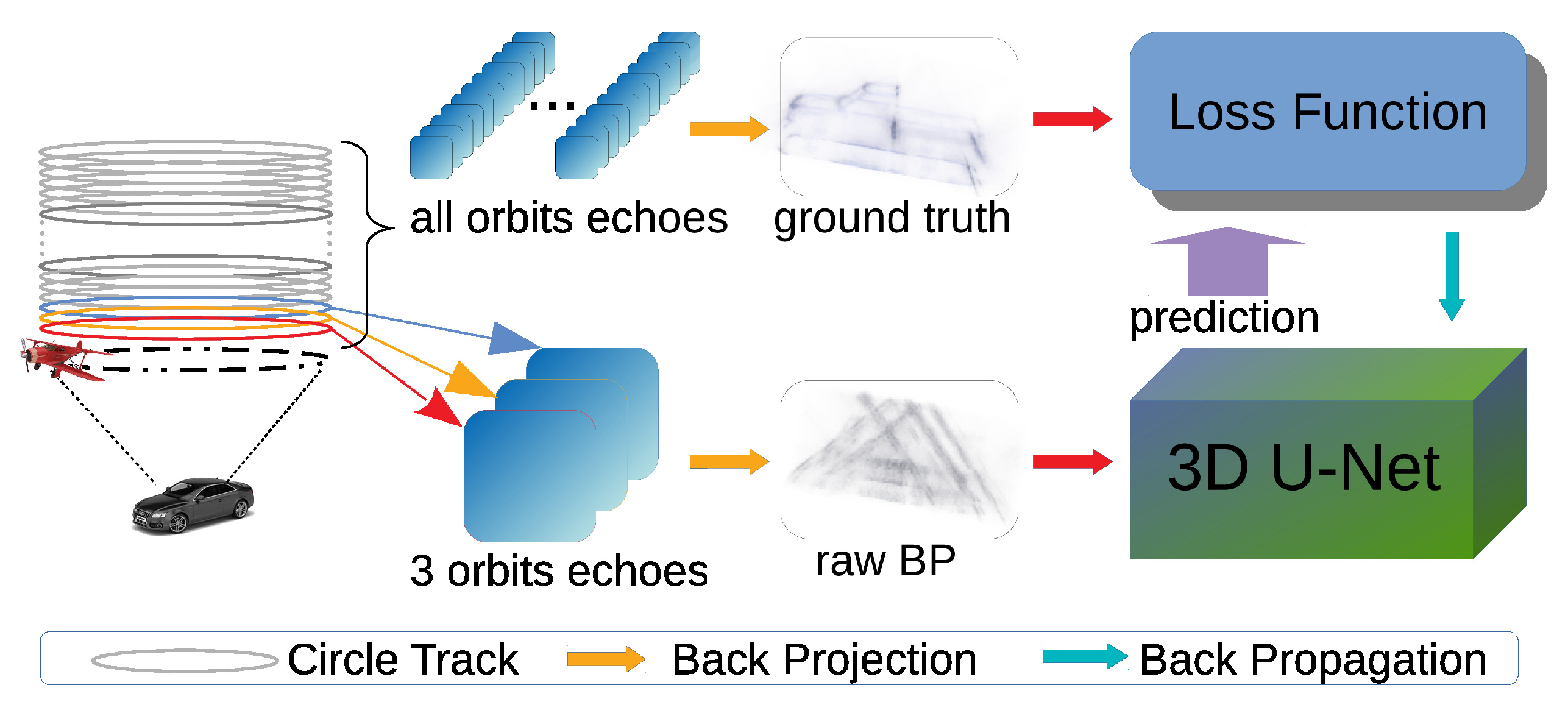
2.1. Training and Testing Procedure
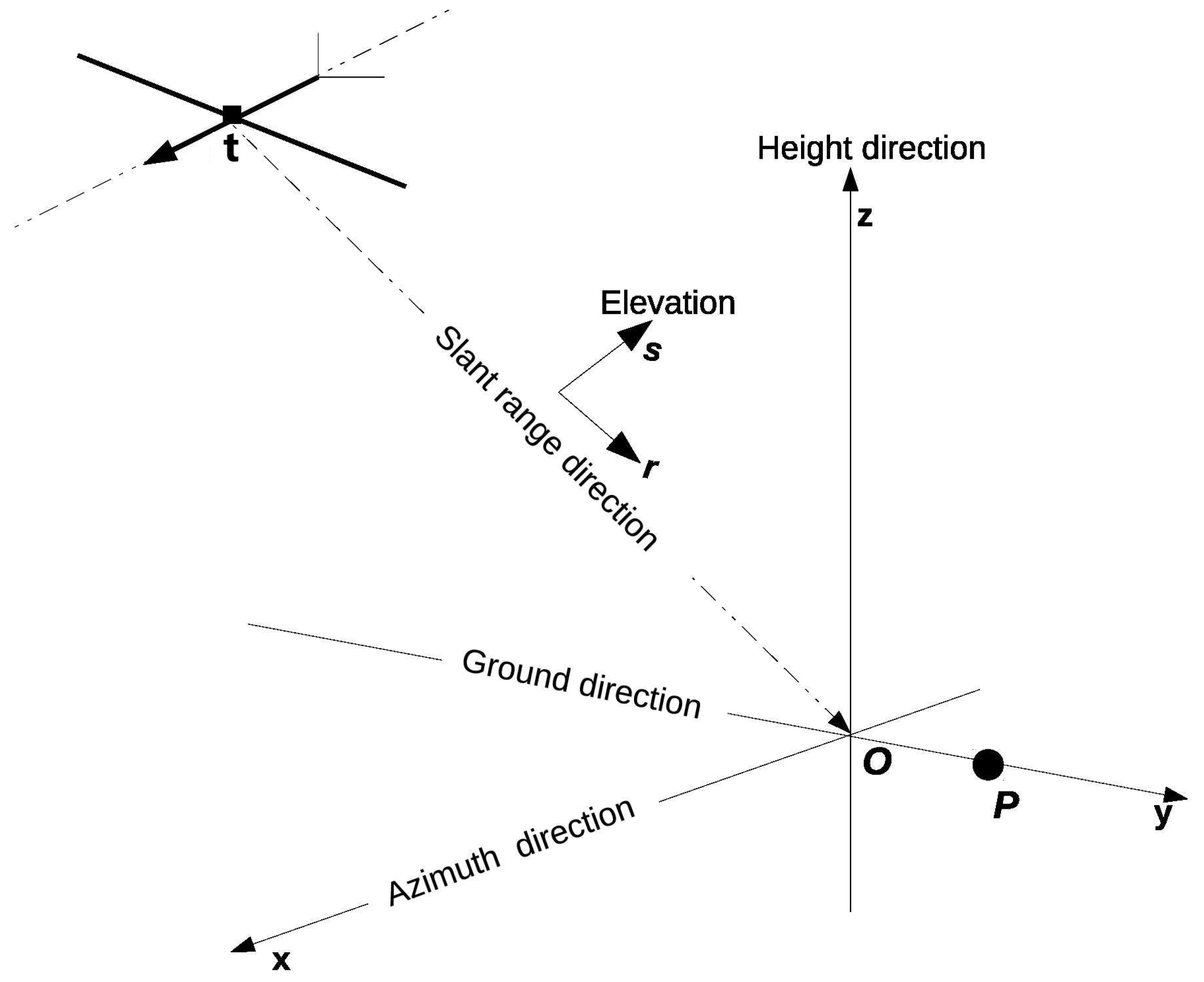
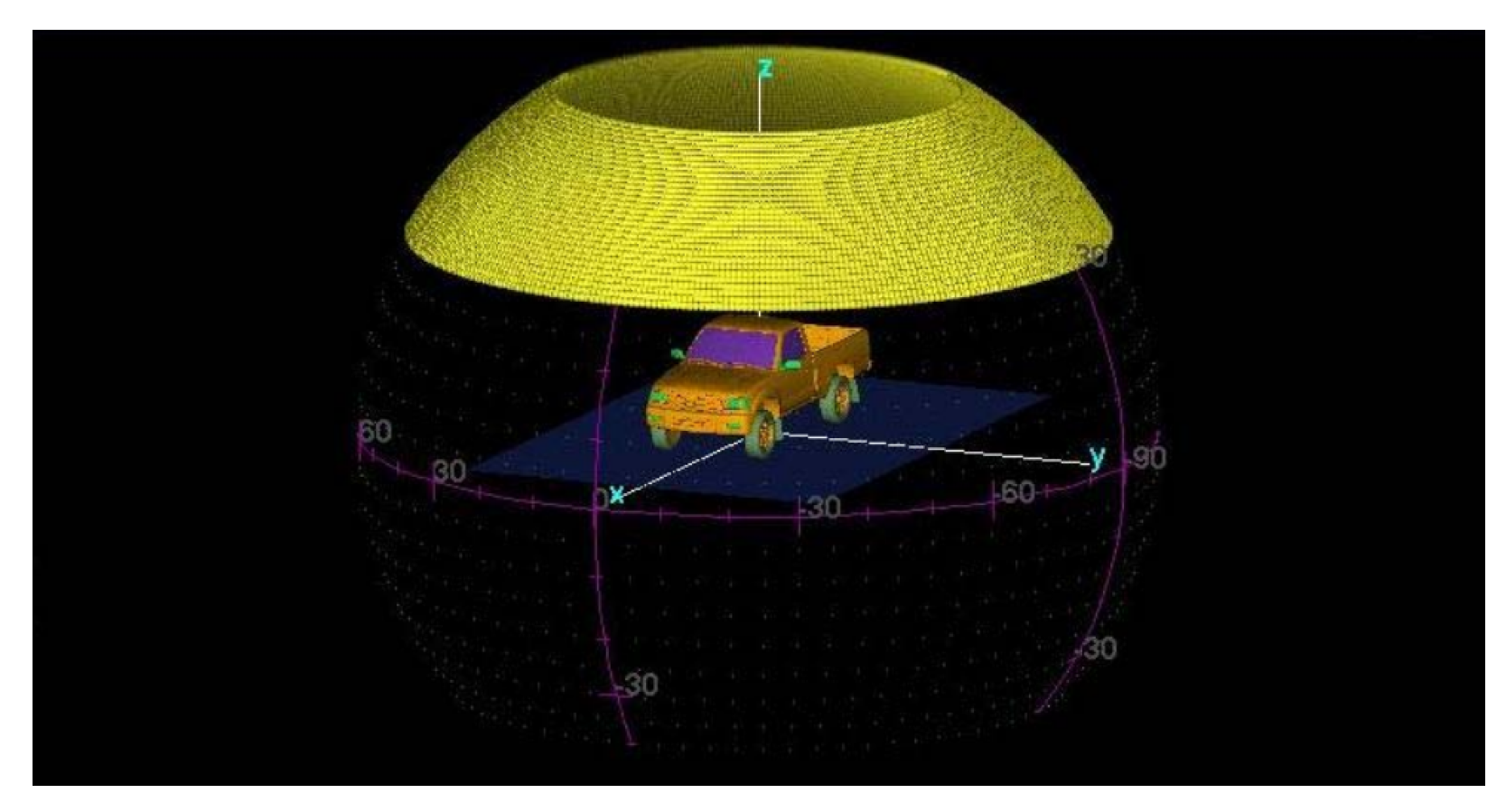
2.2. Back-Projection Principle
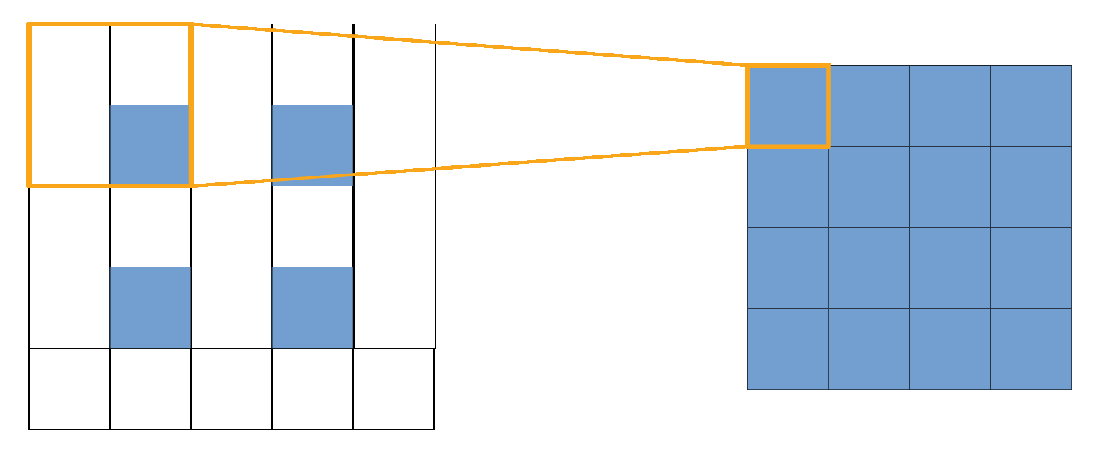
2.3. Image Generation
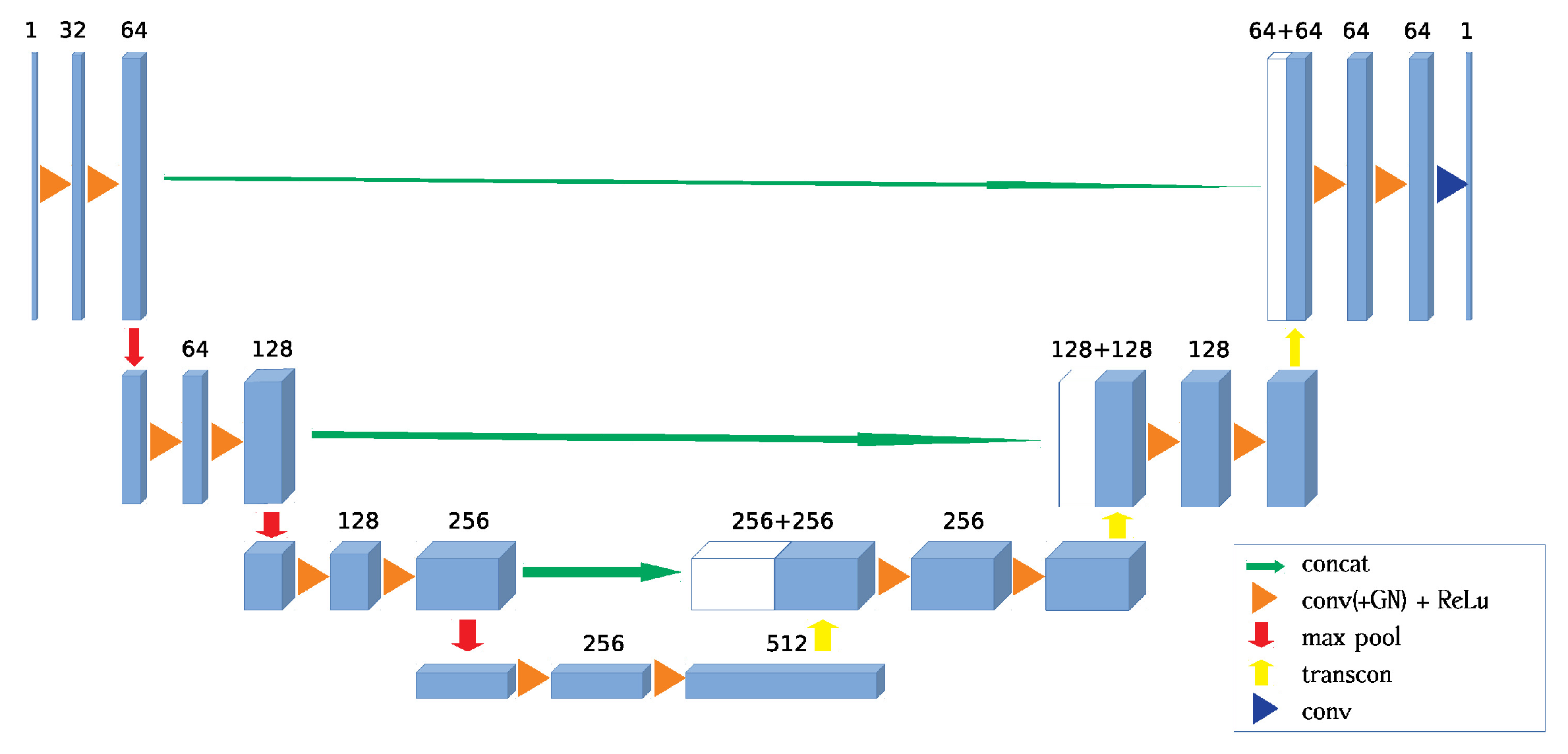
2.4. Network Architecture
2.5. Loss Function
3. Experiment
3.1. Dataset
3.2. Training Configurations
3.3. Relative Absolute Error
3.4. Comparative Experiment with Compressed Sensing Algorithm
4. Results and Discussion
4.1. Network Training
4.2. MPV Car Experiment
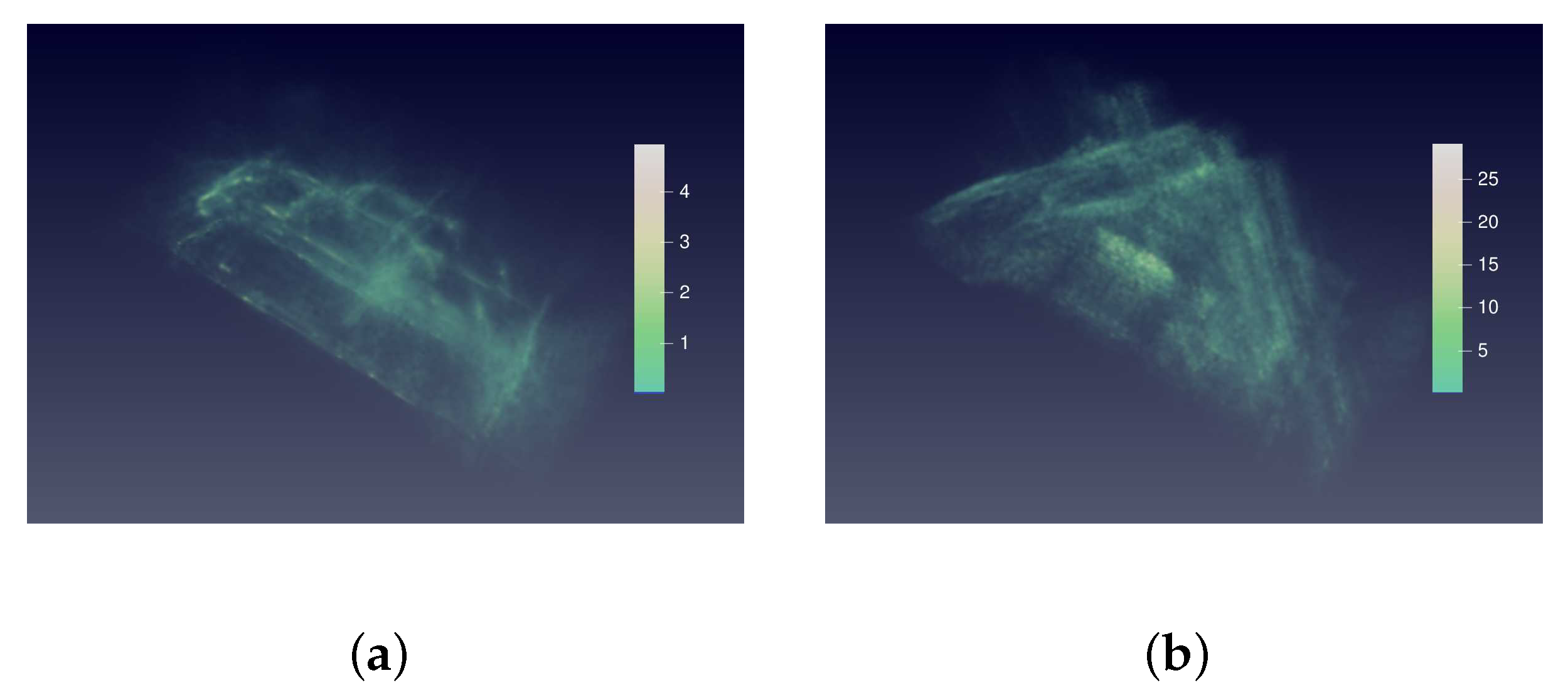
4.2.1. Quality Results
4.2.2. Quantity Results
4.2.3. Comparison with CS Algorithm
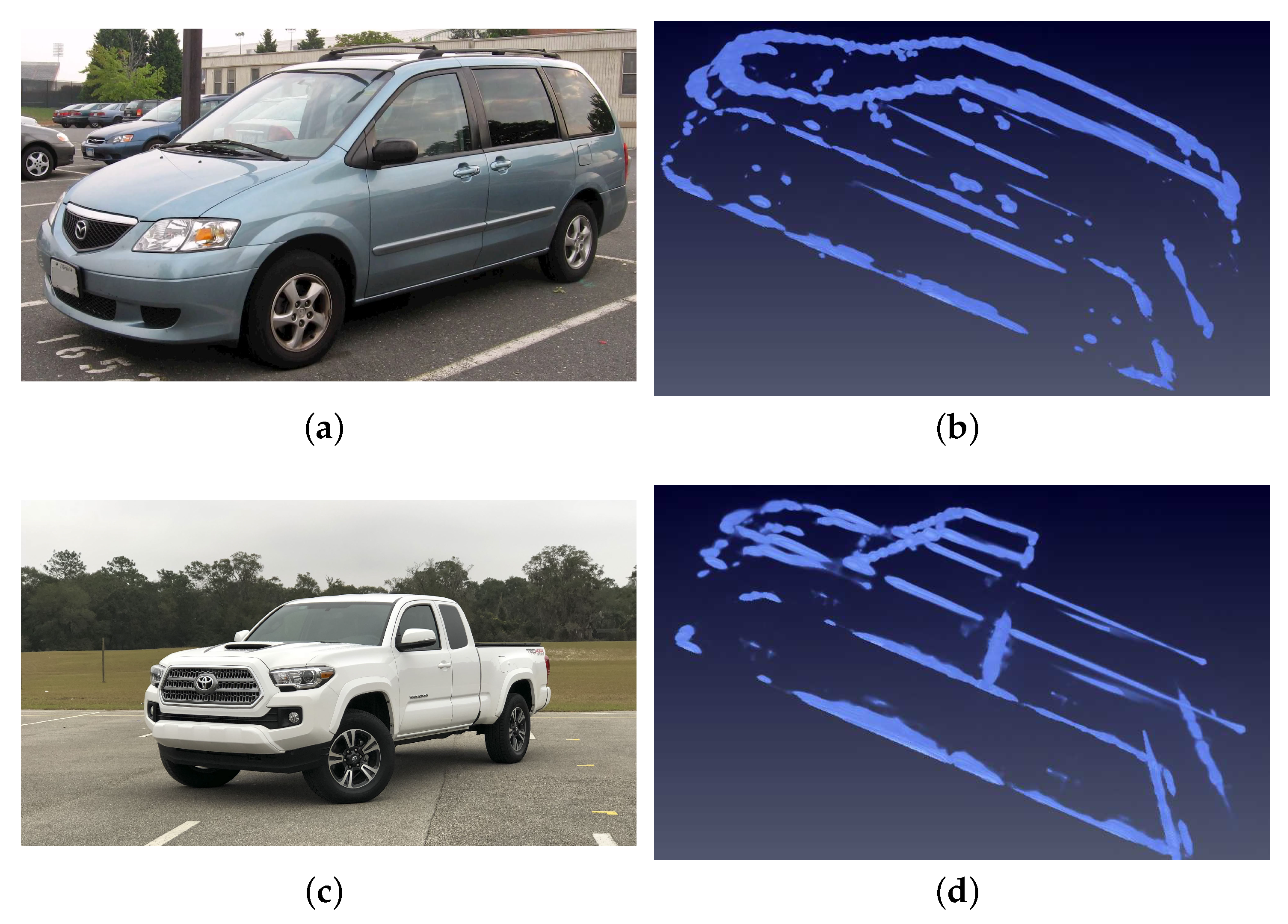
4.3. Pickup Car Experiment
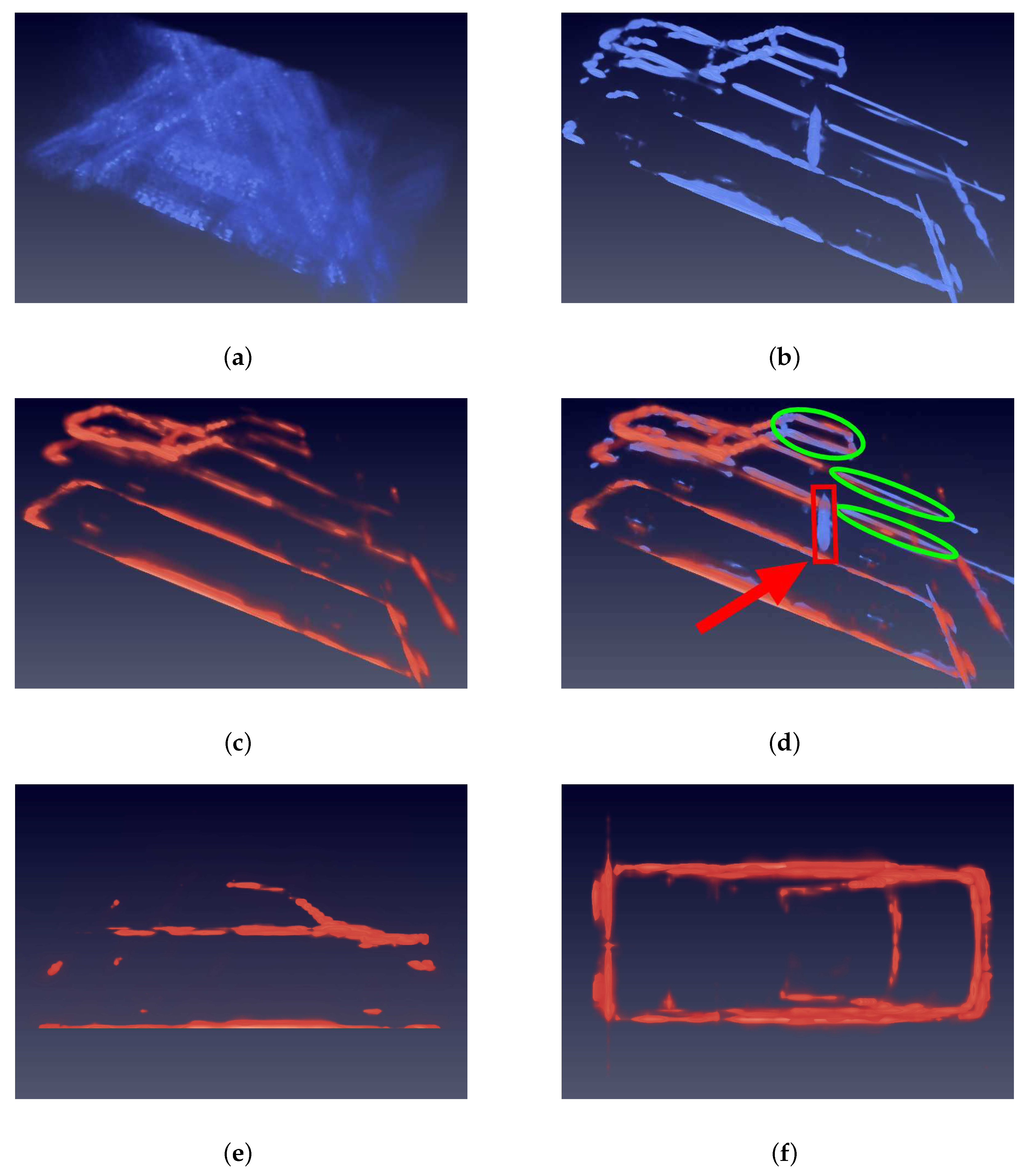
4.3.1. Quality Results
4.3.2. Quantity Results
4.3.3. Comparation with CS Algorithm
4.3.4. Comparison of Time Consumption
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.X.; Adam, N.; Bamler, R. Space-borne high resolution tomographic interferometry. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, pp. IV-869–IV-872. [Google Scholar] [CrossRef]
- Reigber, A.; Moreira, A. First demonstration of airborne SAR tomography using multibaseline L-band data. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2142–2152. [Google Scholar] [CrossRef]
- Li, X.; Liang, X.; Zhang, F.; Bu, X.; Wan, Y. A 3D Reconstruction Method of Mountain Areas for TomoSAR. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Shahzad, M.; Zhu, X.X. Automatic Detection and Reconstruction of 2-D/3-D Building Shapes From Spaceborne TomoSAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1292–1310. [Google Scholar] [CrossRef]
- Shahzad, M.; Zhu, X.X. Robust Reconstruction of Building Facades for Large Areas Using Spaceborne TomoSAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2015, 53, 752–769. [Google Scholar] [CrossRef]
- Weiß, M.; Fornaro, G.; Reale, D. Multi scatterer detection within tomographic SAR using a compressive sensing approach. In Proceedings of the 2015 3rd International Workshop on Compressed Sensing Theory and its Applications to Radar, Sonar and Remote Sensing (CoSeRa), Pisa, Italy, 17–19 June 2015; pp. 11–15. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, B.; Xu, H. Analysis of the effect of sparsity on the performance of SAR imaging based on CS theory. In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2016; pp. 384–388. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. Super-resolution of sparse reconstruction for tomographic SAR imaging—Demonstration with real data. In Proceedings of the 9th European Conference on Synthetic Aperture Radar, Nuremberg, Germany, 23–26 April 2012; pp. 215–218. [Google Scholar]
- Wei, S.; Zhang, X.; Shi, J. Sparse array SAR 3-D imaging using compressed sensing. In Proceedings of the IET International Radar Conference 2013, Xi’an, China, 14–16 April 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Bao, Q.; Peng, X.; Wang, Z.; Lin, Y.; Hong, W. DLSLA 3-D SAR Imaging Based on Reweighted Gridless Sparse Recovery Method. IEEE Geosci. Remote Sens. Lett. 2016, 13, 841–845. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, Y. SAR imaging with frequency band gaps based on sparse regularization. In Proceedings of the IET International Radar Conference 2015, Hangzhou, China, 14–16 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. Sparse reconstrcution techniques for SAR tomography. In Proceedings of the 2011 17th International Conference on Digital Signal Processing (DSP), Corfu, Greece, 6–8 July 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Xiao Xiang, Z.; Bamler, R. Compressive sensing for high resolution differential SAR tomography—The SL1MMER algorithm. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 17–20. [Google Scholar] [CrossRef]
- Austin, C.D.; Ertin, E.; Moses, R.L. Sparse Signal Methods for 3-D Radar Imaging. IEEE J. Sel. Top. Signal Process. 2011, 5, 408–423. [Google Scholar] [CrossRef]
- Austin, C.D.; Ertin, E.; Moses, R.L. Sparse multipass 3D SAR imaging: Applications to the GOTCHA data set. Proc. Spie Int. Soc. Opt. 2009, 7337, 733703. [Google Scholar]
- Ertin, E.; Austin, C.D.; Sharma, S.; Moses, R.L.; Potter, L.C. GOTCHA experience report: Three-dimensional SAR imaging with complete circular apertures. In Proceedings of the Proceedings of Spie the International Society for Optical Engineering, Orlando, FL, USA, 10–11 April 2007. [Google Scholar]
- Austin, C.D.; Moses, R.L. Wie-Angle Sarse 3D Synthetic Aerture Radar Imaging for Nonlinear Flight Paths. In Proceedings of the 2008 IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 16–18 July 2010. [Google Scholar]
- Zhu, X.X.; Bamler, R. Super-Resolution Power and Robustness of Compressive Sensing for Spectral Estimation With Application to Spaceborne Tomographic SAR. IEEE Trans. Geosci. Remote Sens. 2012, 50, 247–258. [Google Scholar] [CrossRef]
- Wang, P.; Liu, M.; Wang, Z.; Zhao, X.; Chen, H. 3-D imaging of spaceborne distributed SAR based on phase preserving compressive sensing. In Proceedings of the IET International Radar Conference 2015, Hangzhou, China, 14–16 October 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Liang, L.; Guo, H.; Li, X. Three-Dimensional Structural Parameter Inversion of Buildings by Distributed Compressive Sensing-Based Polarimetric SAR Tomography Using a Small Number of Baselines. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4218–4230. [Google Scholar] [CrossRef]
- Farhadi, M.; Jie, C. Distributed compressive sensing for multi-baseline circular SAR image formation. In Proceedings of the 2017 IEEE International Conference on Imaging Systems and Techniques (IST), Beijing, China, 18–20 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Li, L.; Li, D. Sparse Array SAR 3D Imaging for Continuous Scene Based on Compressed Sensing. J. Electron. Inf. Technol. 2014, 36, 2166. [Google Scholar] [CrossRef]
- Kragh, T.J.; Kharbouch, A.A. Monotonic Iterative Algorithms for SAR Image Restoration. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 645–648. [Google Scholar]
- Fogler, R.; Hostetler, L.D.; Hush, D.R. SAR clutter suppression using probability density skewness. IEEE Trans. Aerosp. Electron. Syst. 1994, 30, 622–626. [Google Scholar] [CrossRef]
- Porgès, T.; Delabbaye, J.; Enderli, C.; Favier, G. Probability distribution mixture model for detection of targets in high-resolution SAR images. In Proceedings of the 2009 International Radar Conference “Surveillance for a Safer World” (RADAR 2009), Bordeaux, France, 12–16 October 2009; pp. 1–5. [Google Scholar]
- Pu, L.; Zhang, X.; Shi, J.; Wei, S. Adaptive Filtering for 3D SAR Data based on Dynamic Gaussian Threshold. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–5. [Google Scholar]
- D’Hondt, O.; Lš®pez-Martšªnez, C.; Guillaso, S.; Hellwich, O. Impact of non-local filtering on 3D reconstruction from tomographic SAR data. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2476–2479. [Google Scholar]
- Chen, C.; Zhang, X. A new super-resolution 3D-SAR imaging method based on MUSIC algorithm. In Proceedings of the 2011 IEEE RadarCon (RADAR), Kansas City, MO, USA, 23–27 May 2011; pp. 525–529. [Google Scholar]
- Shi, Y.; Zhu, X.; Bamler, R. Nonlocal Compressive Sensing-Based SAR Tomography. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3015–3024. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, Y.; Zhu, X.X.; Bamler, R. Large-Scale Urban Mapping using Small Stack Multi-baseline TanDEM-X Interferograms. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Shi, Y.; Bamler, R.; Wang, Y.; Zhu, X.X. SAR Tomography at the Limit: Building Height Reconstruction Using Only 3–5 TanDEM-X Bistatic Interferograms. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8026–8037. [Google Scholar] [CrossRef]
- Li, L.; Wang, L.G.; Teixeira, F.L.; Liu, C.; Nehorai, A.; Cui, T.J. DeepNIS: Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. IEEE Trans. Antennas Propag. 2019, 67, 1819–1825. [Google Scholar] [CrossRef]
- Zhou, S.; Li, Y.; Zhang, F.; Chen, L.; Bu, X. Automatic Reconstruction of 3-D Building Structures for TomoSAR Using Neural Networks. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 424–432. [Google Scholar]
- Peng, L.; Qiu, X.; Ding, C.; Tie, W. Generating 3d Point Clouds from a Single SAR Image Using 3D Reconstruction Network. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3685–3688. [Google Scholar]
- Chen, J.; Peng, L.; Qiu, X.; Ding, C.; Wu, Y. A 3D building reconstruction method for SAR images based on deep neural network. Sci. Sin. Inform. 2019, 49, 1606–1625. [Google Scholar] [CrossRef]
- Wei, S.; Zhou, L.; Zhang, X.; Shi, J. Fast back-projection autofocus for linear array SAR 3-D imaging via maximum sharpness. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 525–530. [Google Scholar] [CrossRef]
- Lee, J.S. Speckle analysis and smoothing of synthetic aperture radar images. Comput. Graph. Image Process. 1981, 17, 24–32. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| p-norm | 1 |
| sparsity penalty () | |
| space resolution | 0.05 m |
| subaperture window | 5 degree |
| x extents | 3.0 m |
| y extents | 1.5 m |
| z extents | 2.0 m |
| rand seed | 10 |
| outer loop tolerance | 0.1 |
| CG loop tolerance | 0.0001 |
| Algorithm | Time Consumption |
|---|---|
| Back-projection | 8–10 min |
| Compressed sencing | 40–50 min |
| Proposed | 0.15–0.20 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Guo, J.; Zhang, Y.; Hu, Y.; Ding, C.; Wu, Y. Single Target SAR 3D Reconstruction Based on Deep Learning. Sensors 2021, 21, 964. https://doi.org/10.3390/s21030964
Wang S, Guo J, Zhang Y, Hu Y, Ding C, Wu Y. Single Target SAR 3D Reconstruction Based on Deep Learning. Sensors. 2021; 21(3):964. https://doi.org/10.3390/s21030964
Chicago/Turabian StyleWang, Shihong, Jiayi Guo, Yueting Zhang, Yuxin Hu, Chibiao Ding, and Yirong Wu. 2021. "Single Target SAR 3D Reconstruction Based on Deep Learning" Sensors 21, no. 3: 964. https://doi.org/10.3390/s21030964
APA StyleWang, S., Guo, J., Zhang, Y., Hu, Y., Ding, C., & Wu, Y. (2021). Single Target SAR 3D Reconstruction Based on Deep Learning. Sensors, 21(3), 964. https://doi.org/10.3390/s21030964