Robust Visual Tracking with Reliable Object Information and Kalman Filter


Abstract
1. Introduction
- We propose a new reliable online training method, which can preserve the useful first frame target information.
- We develop a Kalman filter to describe the object’s motion information, then use the trajectory information to guide the tracking process.
- We propose a reliability analysis method for tracking process. This ensures the validity of the target information in the model training process.
- Extensive experiments are conducted on several benchmark datasets. The results show the effectiveness and robustness of the proposed method. In addition, our method achieves a competitive tracking performance compared with other state-of-the-art trackers.
2. Related Work
2.1. Correlation Filter Methods
2.2. Deep Learning Methods
2.3. Temporal Stability
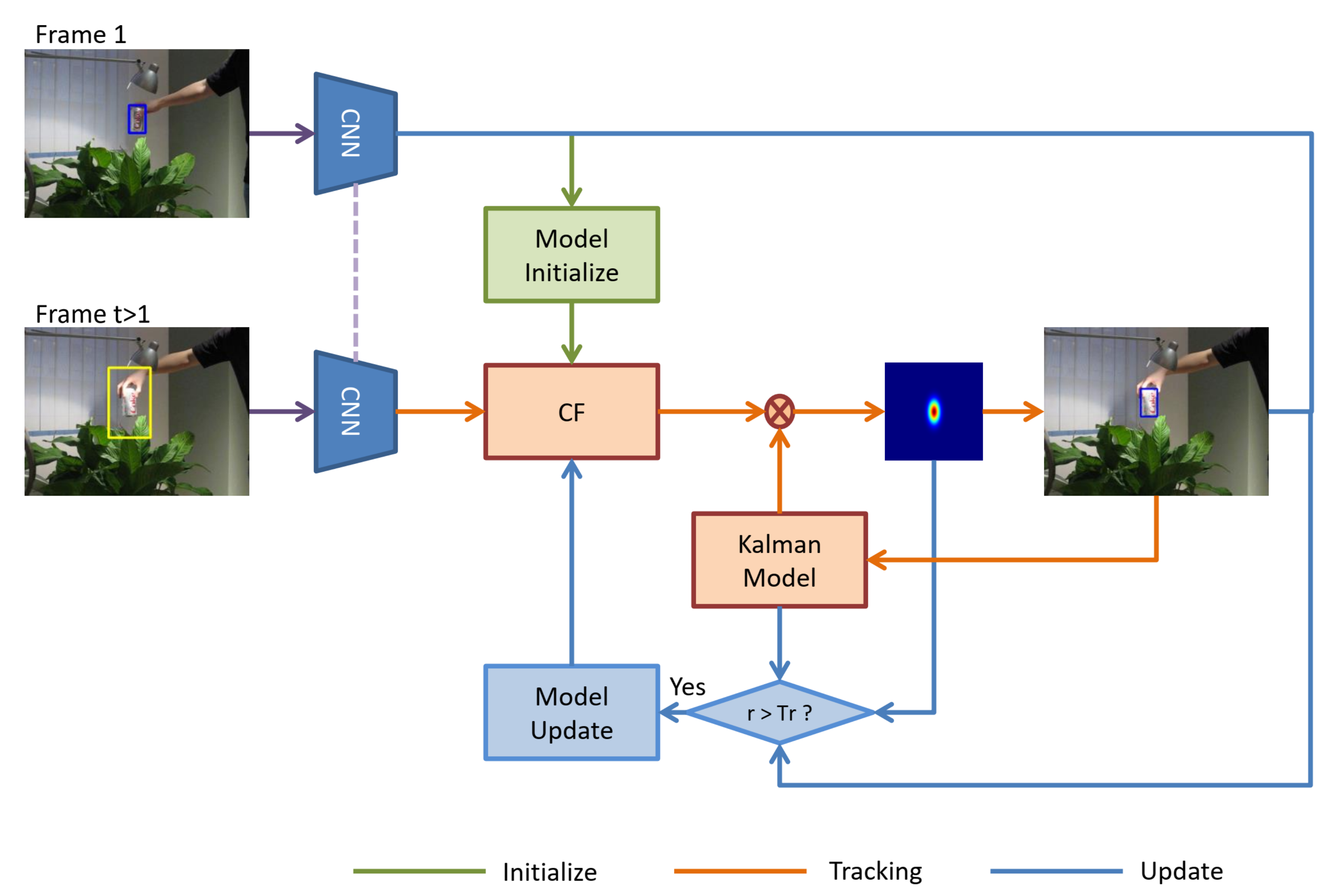
3. Proposed Method
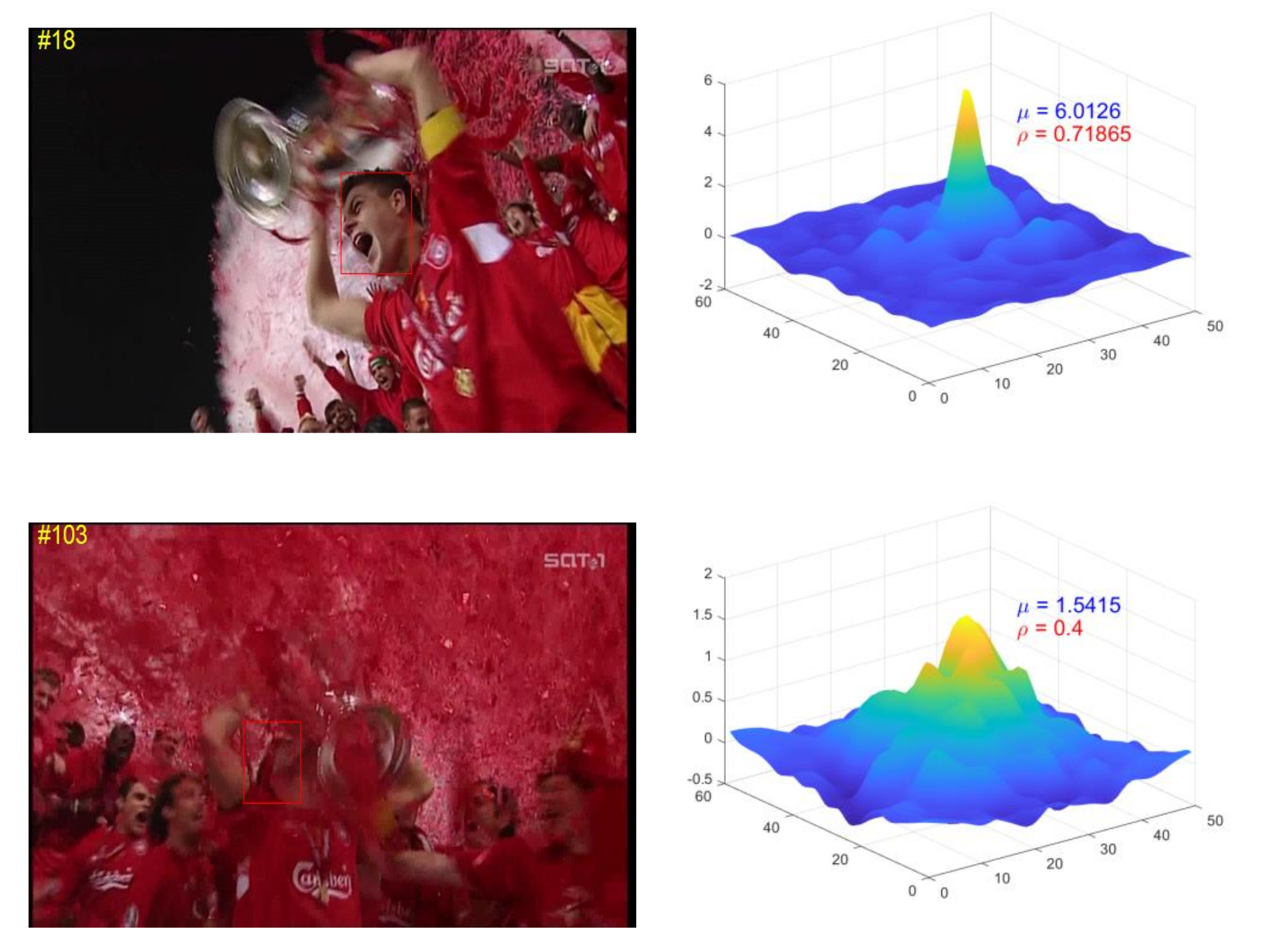
3.1. Reliability Analysis
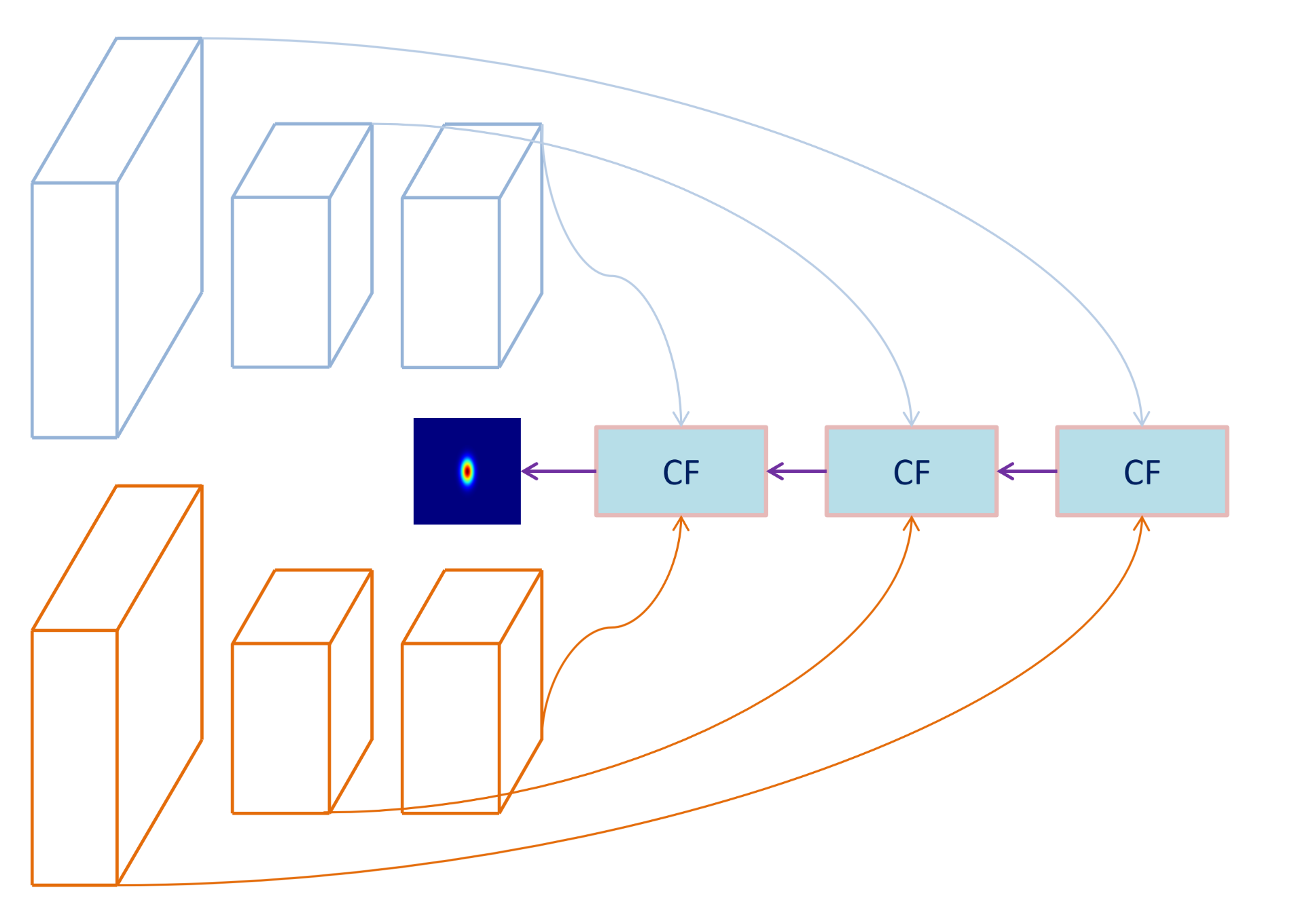
3.2. Trajectory Modeling and Kalman Filter
3.3. Reliable Online Training
3.4. Filter Update
3.5. Tracking Details
| Algorithm 1 Robust Visual Tracking with Reliable Object Information and Kalman Filter |
| Input: Initial target position Output: Estimated target position and updated correlation filters
|
4. Experiments
4.1. Evaluation Criteria and Parameter Setting
4.2. Ablation Experiments
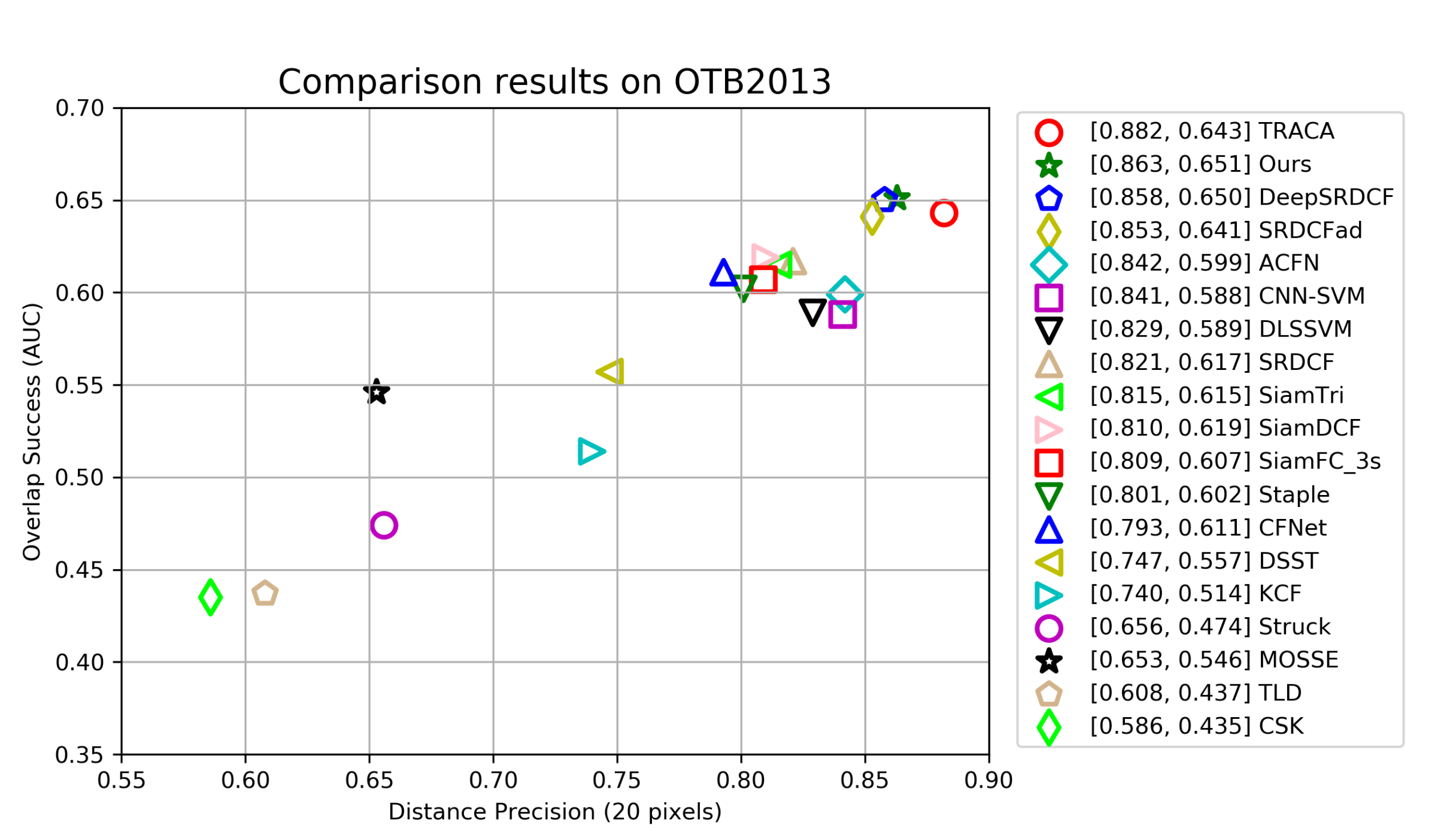
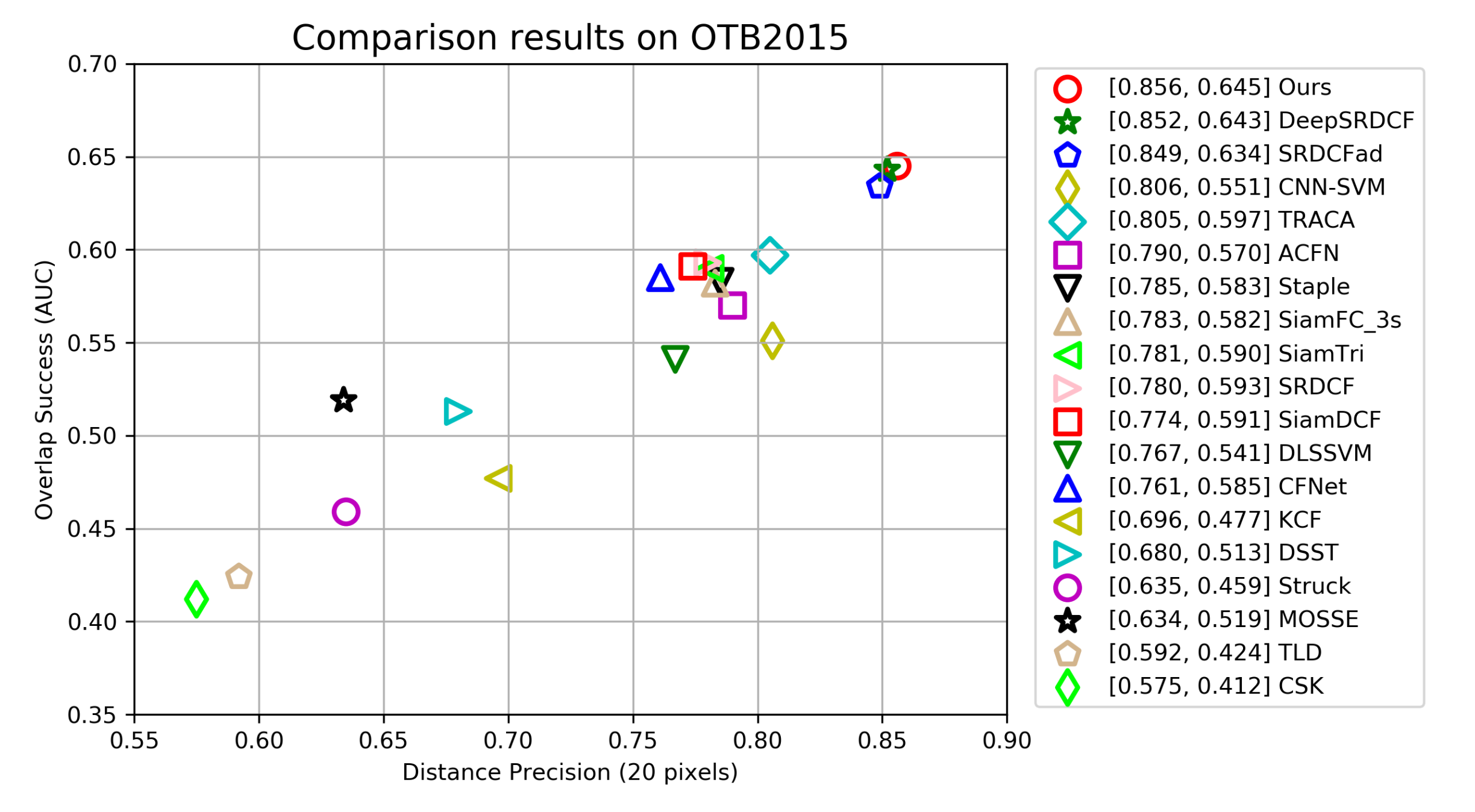
4.3. Comparison with Other Trackers
4.4. Quantitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bouchrika, I.; Carter, J.N.; Nixon, M.S. Towards automated visual surveillance using gait for identity recognition and tracking across multiple non-intersecting cameras. Multimed. Tools Appl. 2016, 75, 1201–1221. [Google Scholar] [CrossRef]
- Lien, J.; Olson, E.M.; Amihood, P.M.; Poupyrev, I. RF-Based Micro-Motion Tracking for Gesture Tracking and Recognition. U.S. Patent No. 10,241.581, 26 March 2019. [Google Scholar]
- Tokekar, P.; Isler, V.; Franchi, A. Multi-target visual tracking with aerial robots. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3067–3072. [Google Scholar]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Smeulders, A.W.M.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed]
- Alper, Y.; Omar, J.; Mubarak, S. Object tracking: A survey. ACM Comput. Surv. 2006, 38, B1–B45. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 4310–4318. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 3074–3082. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the European Conference on Computer Vision (ECCV Workshops), Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference (BMVC), University of Nottinghan, Nottinghan, UK, 1–5 September 2014. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional features for correlation filter based visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV Workshops), Santiago, Chile, 11–18 December 2015; pp. 621–629. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-aware correlation filter tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Bibi, A.; Mueller, M.; Ghanem, B. Target response adaptation for correlation filter tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 419–433. [Google Scholar]
- Xia, H.; Zhang, Y.; Yang, M.; Zhao, Y. Visual Tracking via Deep Feature Fusion and Correlation Filters. Sensors 2020, 20, 3370. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. ECO: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 FPS with deep regression networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 749–765. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1420–1429. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV Workshops), Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4586–4595. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4277–4286. [Google Scholar]
- Kim, Y.; Shin, J.; Park, H.; Paik, J. Real-Time Visual Tracking with Variational Structure Attention Network. Sensors 2019, 19, 4904. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Xing, Q.; Ma, Z. HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter. Sensors 2020, 20, 2137. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Ling, H. SANet: Structure-Aware Network for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Honolulu, HI, USA, 21–26 July 2017; pp. 2217–2224. [Google Scholar]
- Choi, J.; Jin Chang, H.; Yun, S.; Fischer, T.; Demiris, Y.; Young Choi, J. Attentional correlation filter network for adaptive visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4807–4816. [Google Scholar]
- Yang, T.; Chan, A.B. Learning Dynamic Memory Networks for Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 153–169. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Fontainebleau Resort, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Dong, H.; Ma, W.; Wu, Y.; Gong, M.; Jiao, L. Local Descriptor Learning for Change Detection in Synthetic Aperture Radar Images via Convolutional Neural Networks. IEEE Access 2018, 7, 15389–15403. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Lukežic, A.; Vojír, T.; Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Zajc, L.C.; Hager, G.; Eldesokey, A.; et al. The visual object tracking vot2016 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV Workshops), Amsterdam, The Netherlands, 8–16 October 2016; pp. 777–823. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Zajc, L.C.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision Workshops—(ECCV Workshops), Munich, Germany, 8–14 September 2018; pp. 3–53. [Google Scholar]
- Vedaldi, A.; Lenc, K. MatConvNet: Convolutional Neural Networks for MATLAB. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, October 2015; pp. 689–692. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed]
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured output tracking with kernels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1401–1409. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. DCFNet: Discriminant correlation filters network for visual tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Dong, X.; Shen, J. Triplet loss in siamese network for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Ning, J.; Yang, J.; Jiang, S.; Zhang, L.; Yang, M.-H. Object tracking via dual linear structured svm and explicit feature map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4266–4274. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Adaptive decontamination of the training set: A unified formulation for discriminative visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1430–1438. [Google Scholar]
- Choi, J.; Jin Chang, H.; Fischer, T.; Yun, S.; Lee, K.; Jeong, J.; Demiris, Y.; Young Choi, J. Context-aware deep feature compression for high-speed visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 479–488. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline + All | Baseline + RA | Baseline + OT | Baseline + KF | Baseline | |
|---|---|---|---|---|---|
| Illumination Variation | 0.848 | 0.823 | 0.813 | 0.796 | 0.786 |
| Occlusion | 0.831 | 0.801 | 0.796 | 0.775 | 0.771 |
| Fast Motion | 0.763 | 0.742 | 0.741 | 0.726 | 0.706 |
| Background Clutters | 0.856 | 0.836 | 0.824 | 0.819 | 0.786 |
| Out-of-Plane Rotation | 0.828 | 0.811 | 0.795 | 0.791 | 0.782 |
| Deformation | 0.852 | 0.831 | 0.825 | 0.814 | 0.805 |
| In-Plane Rotation | 0.830 | 0.822 | 0.814 | 0.807 | 0.789 |
| Low Resolution | 0.798 | 0.776 | 0.765 | 0.758 | 0.737 |
| Scale Variation | 0.817 | 0.801 | 0.796 | 0.785 | 0.754 |
| Motion Blur | 0.788 | 0.765 | 0.753 | 0.750 | 0.736 |
| Out-of-View | 0.721 | 0.709 | 0.691 | 0.679 | 0.667 |
| Baseline + All | Baseline + RA | Baseline + OT | Baseline + KF | Baseline | |
|---|---|---|---|---|---|
| lllumination Variation | 0.603 | 0.582 | 0.579 | 0.564 | 0.556 |
| Occlusion | 0.598 | 0.581 | 0.572 | 0.552 | 0.539 |
| Fast Motion | 0.573 | 0.558 | 0.546 | 0.530 | 0.524 |
| Background Clutters | 0.628 | 0.612 | 0.609 | 0.597 | 0.583 |
| Out-of-Plane Rotation | 0.615 | 0.592 | 0.583 | 0.572 | 0.551 |
| Deformation | 0.606 | 0.586 | 0.574 | 0.559 | 0.531 |
| In-Plane Rotation | 0.624 | 0.608 | 0.582 | 0.583 | 0.568 |
| Low Resolution | 0.542 | 0.521 | 0.516 | 0.503 | 0.496 |
| Scale Variation | 0.581 | 0.571 | 0.559 | 0.542 | 0.532 |
| Motion Blur | 0.599 | 0.583 | 0.577 | 0.552 | 0.548 |
| Out-of-View | 0.532 | 0.519 | 0.503 | 0.498 | 0.482 |
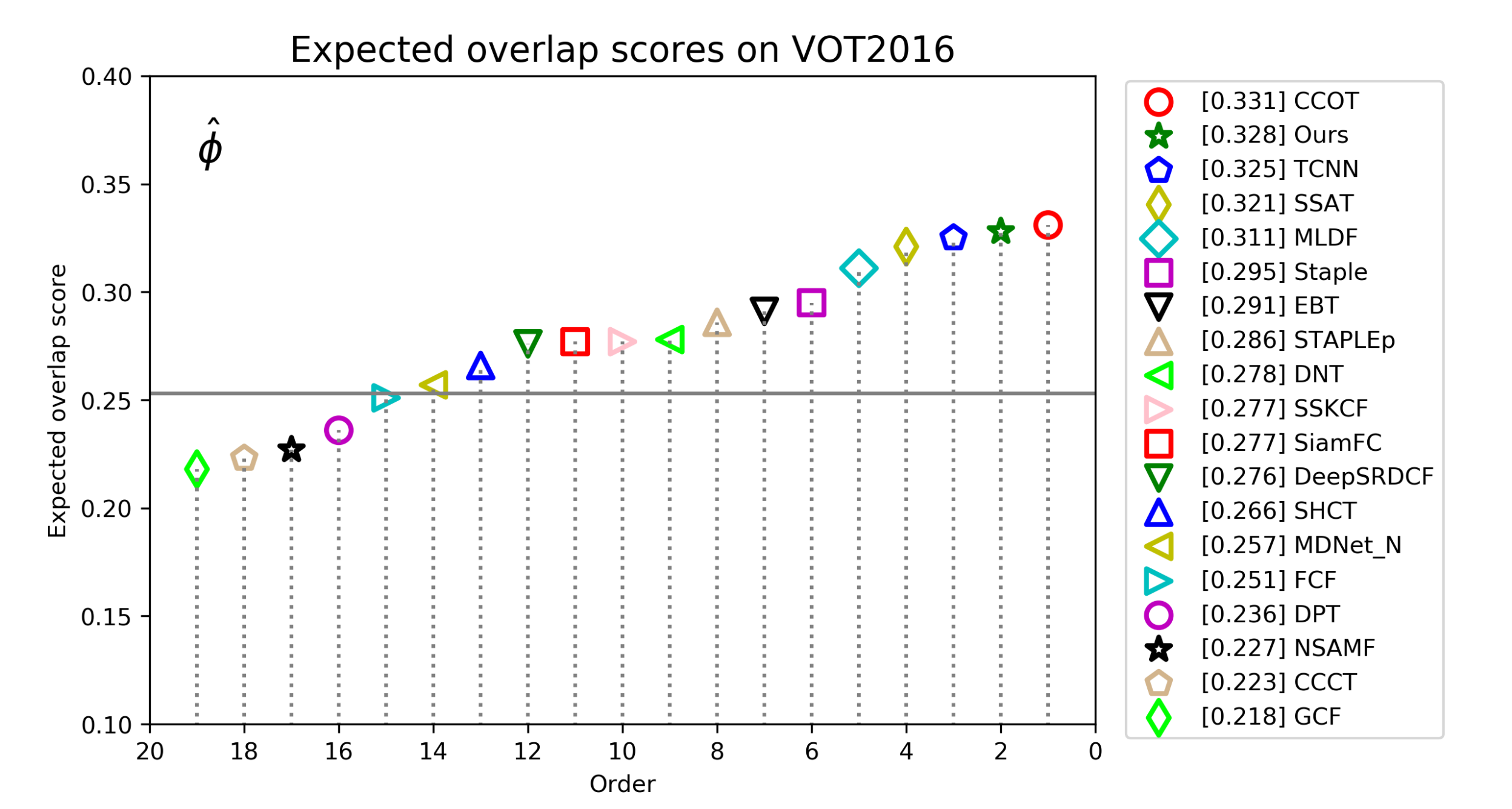
| Ours | CCOT | TCNN | SSAT | MLDF | Staple | EBT | STAPLEp | DNT | SSKCF | SiamFC | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| EAO↑ | 0.328 | 0.331 | 0.325 | 0.321 | 0.311 | 0.295 | 0.291 | 0.286 | 0.278 | 0.277 | 0.277 |
| Accuracy↑ | 0.552 | 0.539 | 0.554 | 0.577 | 0.490 | 0.544 | 0.465 | 0.557 | 0.515 | 0.547 | 0.549 |
| Robust↓ | 0.230 | 0.238 | 0.268 | 0.291 | 0.233 | 0.378 | 0.252 | 0.368 | 0.329 | 0.373 | 0.382 |
| EFO↑ | 10.16 | 0.507 | 1.049 | 0.475 | 1.483 | 11.14 | 3.011 | 44.77 | 1.127 | 29.15 | 5.444 |
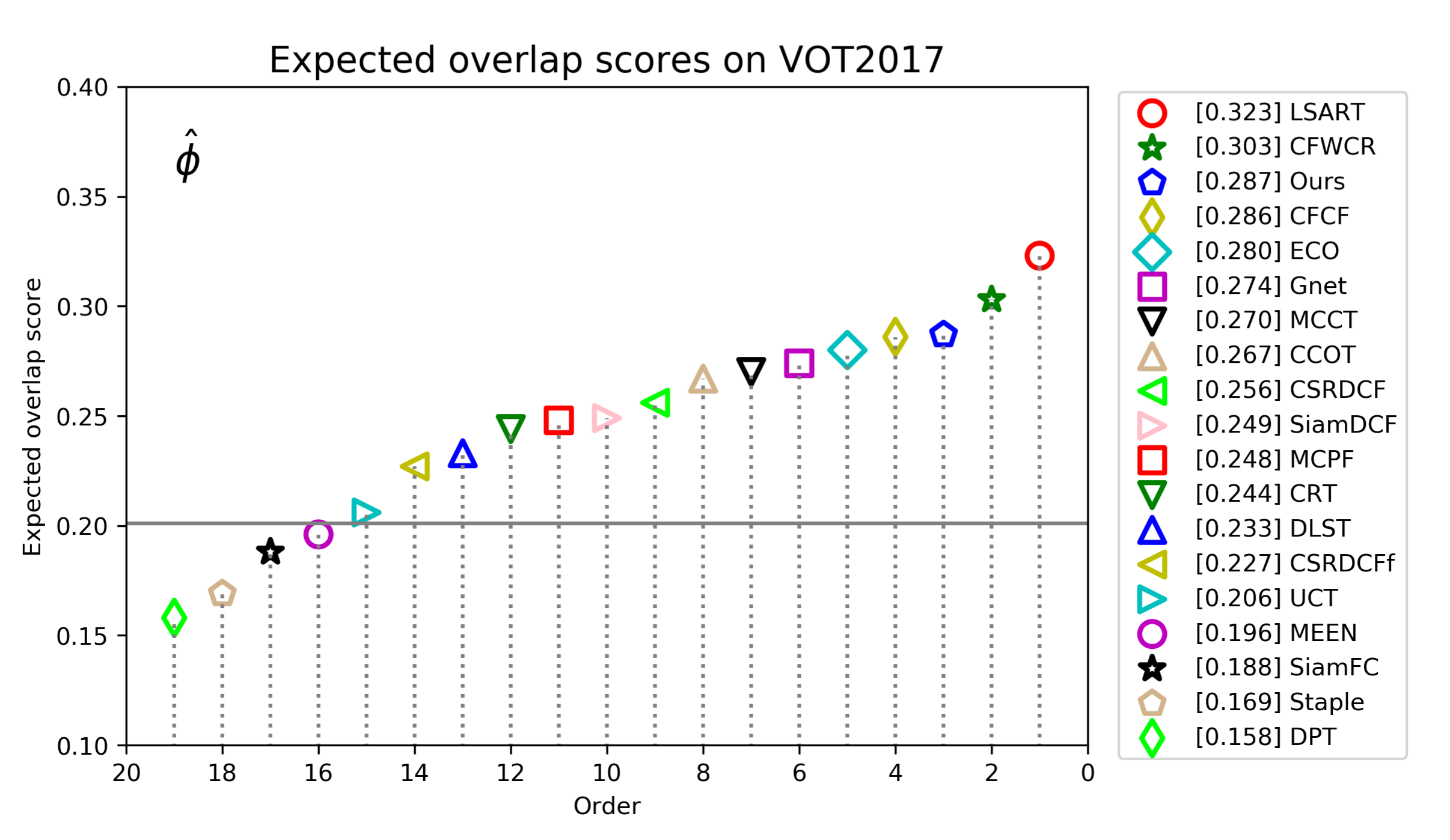
| Ours | LSART | CFWCR | CFCF | ECO | Gnet | MCCT | CCOT | CSRDCF | SiamDCF | MCPF | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| EAO↑ | 0.287 | 0.323 | 0.303 | 0.286 | 0.280 | 0.274 | 0.270 | 0.267 | 0.256 | 0.249 | 0.248 |
| A↑ | 0.486 | 0.493 | 0.484 | 0.509 | 0.483 | 0.502 | 0.525 | 0.494 | 0.491 | 0.500 | 0.510 |
| R↓ | 0.273 | 0.218 | 0.267 | 0.281 | 0.276 | 0.276 | 0.323 | 0.318 | 0.356 | 0.473 | 0.427 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, W.; Yan, D. Robust Visual Tracking with Reliable Object Information and Kalman Filter. Sensors 2021, 21, 889. https://doi.org/10.3390/s21030889
Chen H, Zhang W, Yan D. Robust Visual Tracking with Reliable Object Information and Kalman Filter. Sensors. 2021; 21(3):889. https://doi.org/10.3390/s21030889
Chicago/Turabian StyleChen, Hang, Weiguo Zhang, and Danghui Yan. 2021. "Robust Visual Tracking with Reliable Object Information and Kalman Filter" Sensors 21, no. 3: 889. https://doi.org/10.3390/s21030889
APA StyleChen, H., Zhang, W., & Yan, D. (2021). Robust Visual Tracking with Reliable Object Information and Kalman Filter. Sensors, 21(3), 889. https://doi.org/10.3390/s21030889