Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors



Abstract
1. Introduction
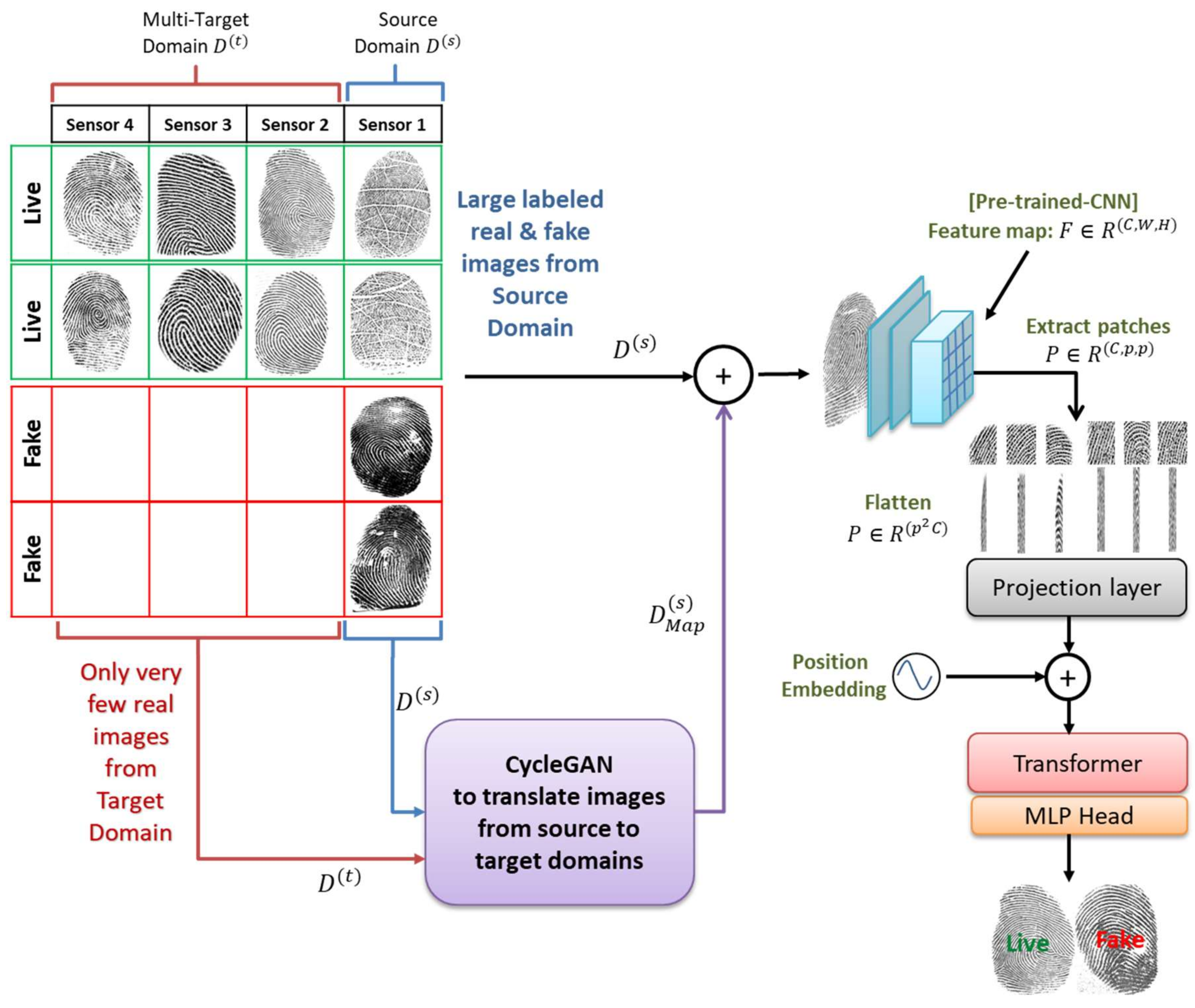
2. Proposed Methodology
2.1. Backbone CNN
2.2. Transformer Encoder
2.3. Classification Layer
2.4. Domain Conversion with GAN
| Algorithm 1 |
| Input: Source images , Target images Output: fingerprint class, i.e., live or fake.
|
3. Experimental Results
3.1. Dataset Description
3.2. Dataset Preprocessing
3.3. Experiment Setup and Performance Metrics
- Accuracy: rate of correctly classified live and fake fingerprints.
- Average Classification Error (ACE):
3.3.1. Experiment 1: Full Supervised Classification
3.3.2. Experiment 2: Generalization Ability
3.3.3. Experiment 3: Cross-Sensor Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint Spoof Detection Using Minutiae-Based Local Patches. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 581–589. [Google Scholar]
- International Standards Organization. ISO/IEC 30107-1:2016, Information Technology-Biometric Presentation Attack Detection-Part 1: Framework; International Standards Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Schuckers, S. Presentations and Attacks, and Spoofs, Oh My. Image Vis. Comput. 2016, 55, 26–30. [Google Scholar] [CrossRef]
- Chugh, T.; Jain, A.K. Fingerprint Spoof Generalization. arXiv 2019, arXiv:1912.02710. [Google Scholar]
- Drahanský, M.; Dolezel, M.; Vana, J.; Brezinova, E.; Yim, J.; Shim, K. New Optical Methods for Liveness Detection on Fingers. BioMed Res. Int. 2013. [Google Scholar] [CrossRef]
- Hengfoss, C.; Kulcke, A.; Mull, G.; Edler, C.; Püschel, K.; Jopp, E. Dynamic Liveness and Forgeries Detection of the Finger Surface on the Basis of Spectroscopy in the 400–1650 Nm Region. Forensic Sci. Int. 2011, 212, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Barrero, M.; Kolberg, J.; Busch, C. Towards Fingerprint Presentation Attack Detection Based on Short Wave Infrared Imaging and Spectral Signatures. In Proceedings of the Norwegian Information Security Conference (NISK), Svalbard, Norway, 18–20 September 2018. [Google Scholar]
- Ghiani, L.; Marcialis, G.L.; Roli, F. Fingerprint Liveness Detection by Local Phase Quantization. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 537–540. [Google Scholar]
- Nikam, S.B.; Agarwal, S. Texture and Wavelet-Based Spoof Fingerprint Detection for Fingerprint Biometric Systems. In Proceedings of the 2008 First International Conference on Emerging Trends in Engineering and Technology, Maharashtra, India, 16–18 July 2008; pp. 675–680. [Google Scholar]
- Xia, Z.; Yuan, C.; Lv, R.; Sun, X.; Xiong, N.N.; Shi, Y.-Q. A Novel Weber Local Binary Descriptor for Fingerprint Liveness Detection. IEEE Trans. Syst. ManCybern. Syst. 2018, 50, 1–11. [Google Scholar] [CrossRef]
- Nogueira, R.F.; de Alencar Lotufo, R.; Campos Machado, R. Fingerprint Liveness Detection Using Convolutional Neural Networks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1206–1213. [Google Scholar] [CrossRef]
- Nguyen, T.H.B.; Park, E.; Cui, X.; Nguyen, V.H.; Kim, H. FPADnet: Small and Efficient Convolutional Neural Network for Presentation Attack Detection. Sensors 2018, 18, 2532. [Google Scholar] [CrossRef]
- Park, E.; Cui, X.; Nguyen, T.H.B.; Kim, H. Presentation Attack Detection Using a Tiny Fully Convolutional Network. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3016–3025. [Google Scholar] [CrossRef]
- Kim, H.; Cui, X.; Kim, M.-G.; Nguyen, T.H.B. Fingerprint Generation and Presentation Attack Detection Using Deep Neural Networks. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 375–378. [Google Scholar]
- Jomaa, M.R.; Mathkour, H.; Bazi, Y.; Islam, M.S. End-to-End Deep Learning Fusion of Fingerprint and Electrocardiogram Signals for Presentation Attack Detection. Sensors 2020, 20, 2085. [Google Scholar] [CrossRef]
- González-Soler, L.J.; Gomez-Barrero, M.; Chang, L.; Pérez-Suárez, A.; Busch, C. Fingerprint Presentation Attack Detection Based on Local Features Encoding for Unknown Attacks. arXiv 2019, arXiv:1908.10163. [Google Scholar]
- Orrù, G.; Casula, R.; Tuveri, P.; Bazzoni, C.; Dessalvi, G.; Micheletto, M.; Ghiani, L.; Marcialis, G.L. LivDet in Action–Fingerprint Liveness Detection Competition 2019. arXiv 2019, arXiv:1905.00639. [Google Scholar]
- Engelsma, J.J.; Jain, A.K. Generalizing Fingerprint Spoof Detector: Learning a One-Class Classifier. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Huang, X.; Liu, M.-Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation. arXiv 2018, arXiv:1804.04732. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. arXiv 2017, arXiv:1703.05192. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Aguirre, H.; Tanaka, K. ArtGAN: Artwork Synthesis with Conditional Categorical GANs. arXiv 2017, arXiv:1702.03410. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv 2017, arXiv:1612.03242. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. arXiv 2017, arXiv:1609.04802. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4396–4405. [Google Scholar]
- Cai, J.; Han, H.; Shan, S.; Chen, X. FCSR-GAN: Joint Face Completion and Super-Resolution via Multi-Task Learning. arXiv 2019, arXiv:1911.01045. [Google Scholar] [CrossRef]
- Lutz, S.; Amplianitis, K.; Smolic, A. AlphaGAN: Generative Adversarial Networks for Natural Image Matting. arXiv 2018, arXiv:1807.10088. [Google Scholar]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef]
- Kim, H.-K.; Yoo, K.-Y.; Park, J.H.; Jung, H.-Y. Asymmetric Encoder-Decoder Structured FCN Based LiDAR to Color Image Generation. Sensors 2019, 19, 4818. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised Representation Learning for Remote Sensing Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef]
- He, Z.; Liu, H.; Wang, Y.; Hu, J. Generative Adversarial Networks-Based Semi-Supervised Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1042. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; AlHichri, H.; AlRahhal, M.M.; Ammour, N.; Alajlan, N. Siamese-GAN: Learning Invariant Representations for Aerial Vehicle Image Categorization. Remote Sens. 2018, 10, 351. [Google Scholar] [CrossRef]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. arXiv 2018, arXiv:1703.00848. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Mura, V.; Ghiani, L.; Marcialis, G.L.; Roli, F.; Yambay, D.A.; Schuckers, S.A. LivDet 2015 Fingerprint Liveness Detection Competition 2015. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–6. [Google Scholar]
- Standard, I. Information Technology–Biometric Presentation Attack Detection–Part 3: Testing and Reporting; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. arXiv 2019, arXiv:1905.04899. [Google Scholar]
- Zhang, Y.; Shi, D.; Zhan, X.; Cao, D.; Zhu, K.; Li, Z. Slim-ResCNN: A Deep Residual Convolutional Neural Network for Fingerprint Liveness Detection. IEEE Access 2019, 7, 91476–91487. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. arXiv 2017, arXiv:1611.04076. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Model | Resolution (dpi) | Image Size (px) | # of Training (Live/Spoof) | # of Testing (Live/Spoof) |
|---|---|---|---|---|---|
| Green Bit | DactyScan26 | 500 | 500 × 500 | 1000/1000 | 1000/1500 |
| Biometrika | HiScan-PRO | 1000 | 1000 × 1000 | 1000/1000 | 1000/1500 |
| Digital Persona | U.are.U 5160 | 500 | 252 × 324 | 1000/1000 | 1000/1500 |
| Crossmatch | L Scan Guardian | 500 | 640 × 480 | 1500/1500 | 1500/1448 |
| Sensor | Spoof Material Used in Training | Spoof Material Used in Testing |
|---|---|---|
| Green Bit | Ecoflex, gelatin, latex, and wood glue | Ecoflex, gelatin, latex, wood glue, liquid Ecoflex, and RTV |
| Biometrika | ||
| Digital Persona | ||
| Crossmatch | Play-Doh, Body Double, and Ecoflex | Play-Doh, Body Double, Ecoflex, OOMOO, and Gelatin |
| Algorithm | Green Bit | Biometrika | Digital Persona | Crossmatch | Average |
|---|---|---|---|---|---|
| Nogueira (first place winner) [38] | 95.40 | 94.36 | 93.72 | 98.10 | 95.40 |
| Unina (second place winner) [38] | 95.80 | 95.20 | 85.44 | 96.00 | 93.11 |
| Zhang et al. [41] | 97.81 | 97.02 | 95.42 | 97.01 | 96.82 |
| M. Jomaa et al. [15] | 94.68 | 95.12 | 91.96 | 97.29 | 94.87 |
| Proposed network [no-augmentation, ] | 96.72 | 95.44 | 94.76 | 98.30 | 96.31 |
| Proposed network [simple augmentation, ] * | 98.44 | 97.68 | 96.36 | 98.33 | 97.70 |
| Proposed network [cutmix augmentation, ] | 97.48 | 97.64 | 94.40 | 99.01 | 97.13 |
| Proposed network [simple augmentation, = 4] | 97.00 | 95.84 | 91.11 | 98.50 | 95.61 |
| Sensor in Testing | Green Bit | Biometrika | Digital Persona | Crossmatch | Average | |
|---|---|---|---|---|---|---|
| Sensor in Training | ||||||
| Green Bit | Acc | 97.56 | 83.68 | 66.60 | 63.97 | 77.95 |
| ACE | 2.23 | 20.20 | 41.75 | 35.47 | 24.91 | |
| Biometrika | Acc | 80.12 | 94.80 | 87.28 | 57.86 | 80.02 |
| ACE | 16.76 | 4.70 | 12.33 | 42.81 | 19.15 | |
| Digital Persona | Acc | 52.40 | 70.36 | 91.00 | 60.31 | 68.52 |
| ACE | 39.78 | 25.13 | 8.00 | 40.36 | 28.32 | |
| Crossmatch | Acc | 70.76 | 70.04 | 50.32 | 97.79 | 72.23 |
| ACE | 26.90 | 29.08 | 44.86 | 2.17 | 25.75 |
| Sensor in Testing | Green Bit | Biometrika | Digital Persona | Crossmatch | Average | |
|---|---|---|---|---|---|---|
| Sensor in Training | ||||||
| Green Bit | Acc | 91.20 | 81.20 | 76.96 | 83.12 | |
| ACE | 10.20 | 23.21 | 23.06 | 18.82 | ||
| Biometrika | Acc | 89.52 | 86.72 | 69.77 | 82.00 | |
| ACE | 9.81 | 15.30 | 30.62 | 18.58 | ||
| Digital Persona | Acc | 85.36 | 84.96 | 69.02 | 79.78 | |
| ACE | 13.05 | 14.28 | 31.36 | 19.56 | ||
| Crossmatch | Acc | 80.04 | 76.24 | 60.70 | 72.33 | |
| ACE | 17.43 | 22.61 | 35.51 | 25.18 |
| Sensor in Testing | Green Bit | Biometrika | Digital Persona | Crossmatch | Average | |
|---|---|---|---|---|---|---|
| Sensor in Training | ||||||
| Green Bit | No-GAN | 83.68 | 66.60 | 63.97 | 71.42 | |
| GAN | 91.20 | 81.20 | 76.96 | 83.12 | ||
| LSGAN | 90.52 | 80.16 | 72.62 | 81.10 | ||
| Biometrika | No-GAN | 80.12 | 87.28 | 57.86 | 75.09 | |
| GAN | 89.52 | 86.72 | 69.77 | 82.00 | ||
| LSGAN | 92.76 | 88.08 | 66.55 | 82.46 | ||
| Digital Persona | No-GAN | 52.40 | 70.36 | 60.31 | 61.02 | |
| GAN | 85.36 | 84.96 | 69.02 | 79.78 | ||
| LSGAN | 85.88 | 83.20 | 69.17 | 79.42 | ||
| Crossmatch | No-GAN | 70.76 | 70.04 | 50.32 | 63.71 | |
| GAN | 80.04 | 76.24 | 60.70 | 72.33 | ||
| LSGAN | 80.10 | 75.78 | 61.00 | 72.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sandouka, S.B.; Bazi, Y.; Alajlan, N. Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors. Sensors 2021, 21, 699. https://doi.org/10.3390/s21030699
Sandouka SB, Bazi Y, Alajlan N. Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors. Sensors. 2021; 21(3):699. https://doi.org/10.3390/s21030699
Chicago/Turabian StyleSandouka, Soha B., Yakoub Bazi, and Naif Alajlan. 2021. "Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors" Sensors 21, no. 3: 699. https://doi.org/10.3390/s21030699
APA StyleSandouka, S. B., Bazi, Y., & Alajlan, N. (2021). Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors. Sensors, 21(3), 699. https://doi.org/10.3390/s21030699