
Joint Multimodal Embedding and Backtracking Search in Vision-and-Language Navigation



Abstract
:1. Introduction
- A novel deep neural network model, with joint multimodal embedding and backtracking search for VLN tasks.
- Rich context utilization based on a transformer-based multimodal embedding module and a temporal contextualization module.
- A backtracking-enabled greedy local search algorithm to improve the success rate and optimize the path.
- A novel global scoring method to monitor task progress by comparing the partial trajectories searched thus far with a plurality of natural language instructions.
- State-of-the-art results on the VLN task.
2. Related Works
3. Materials and Methods
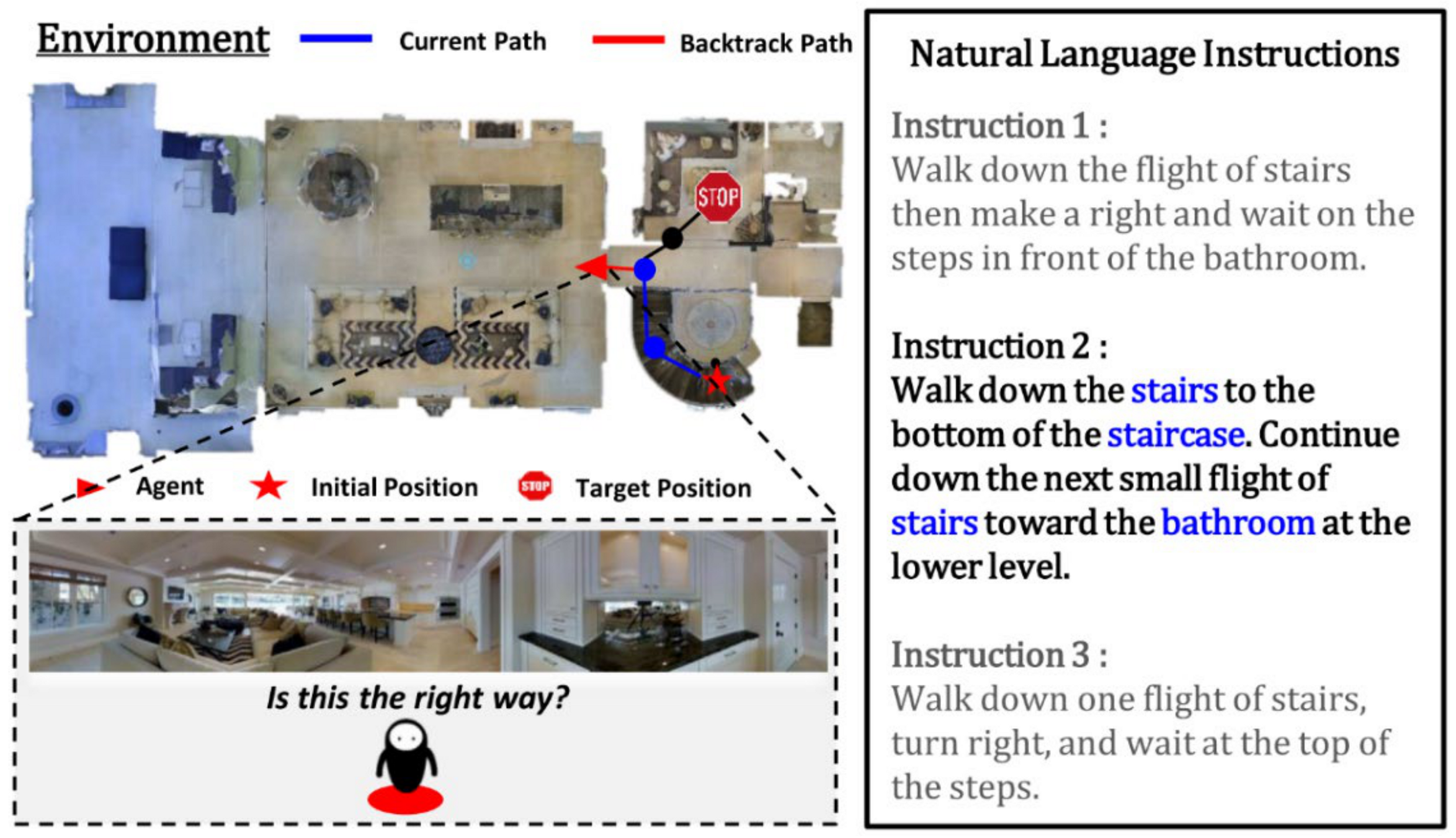
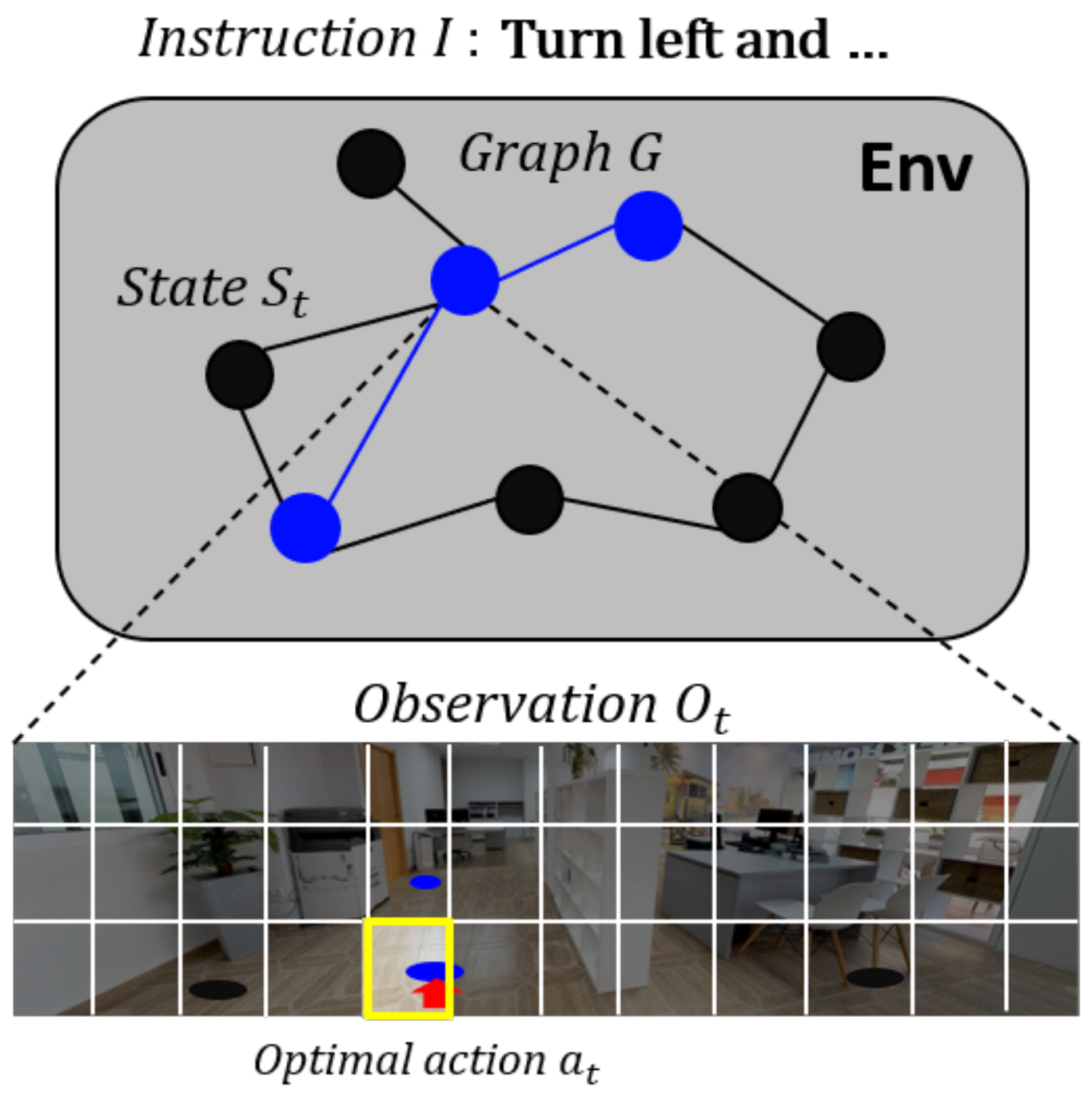
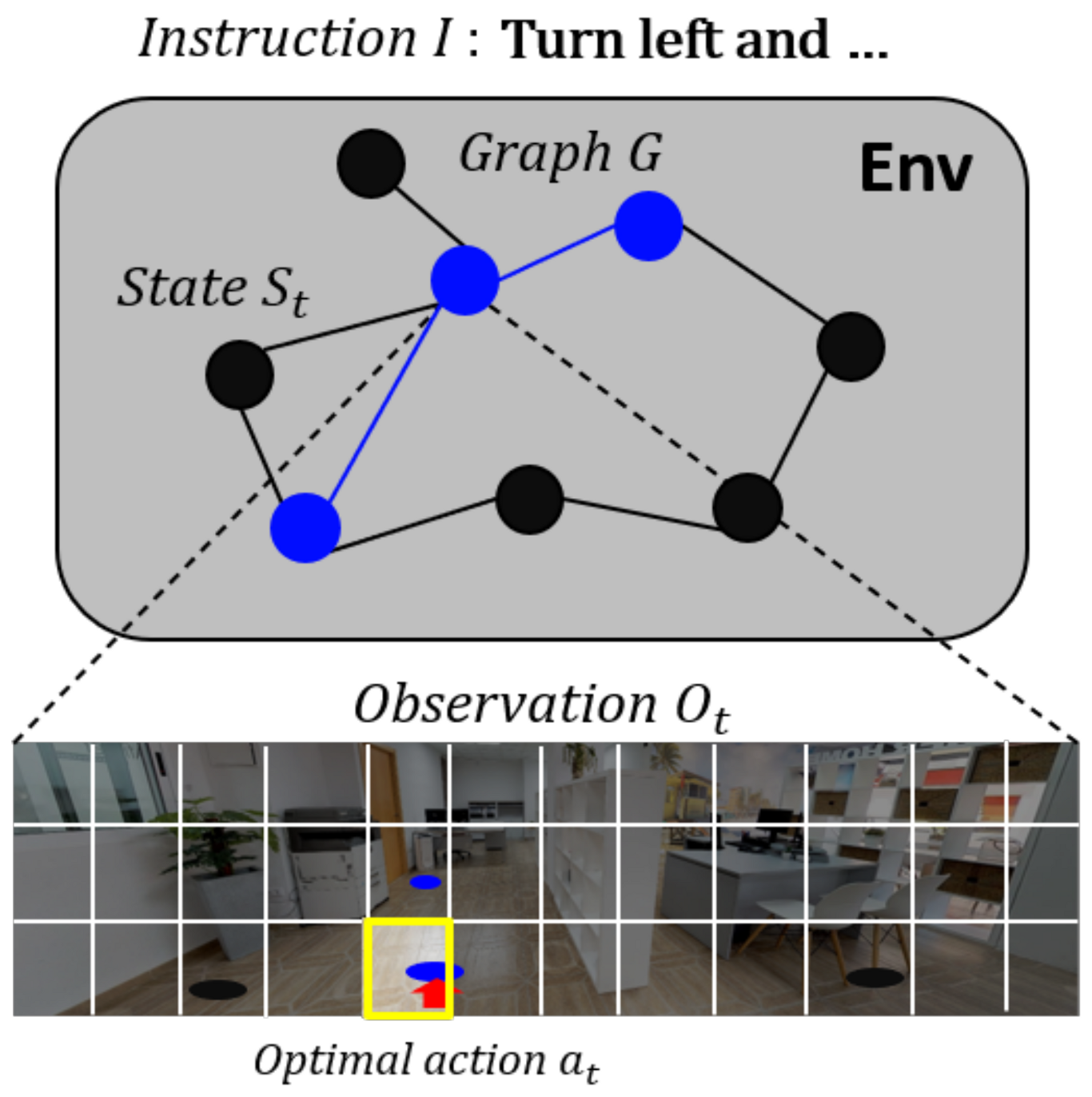
3.1. Problem Description
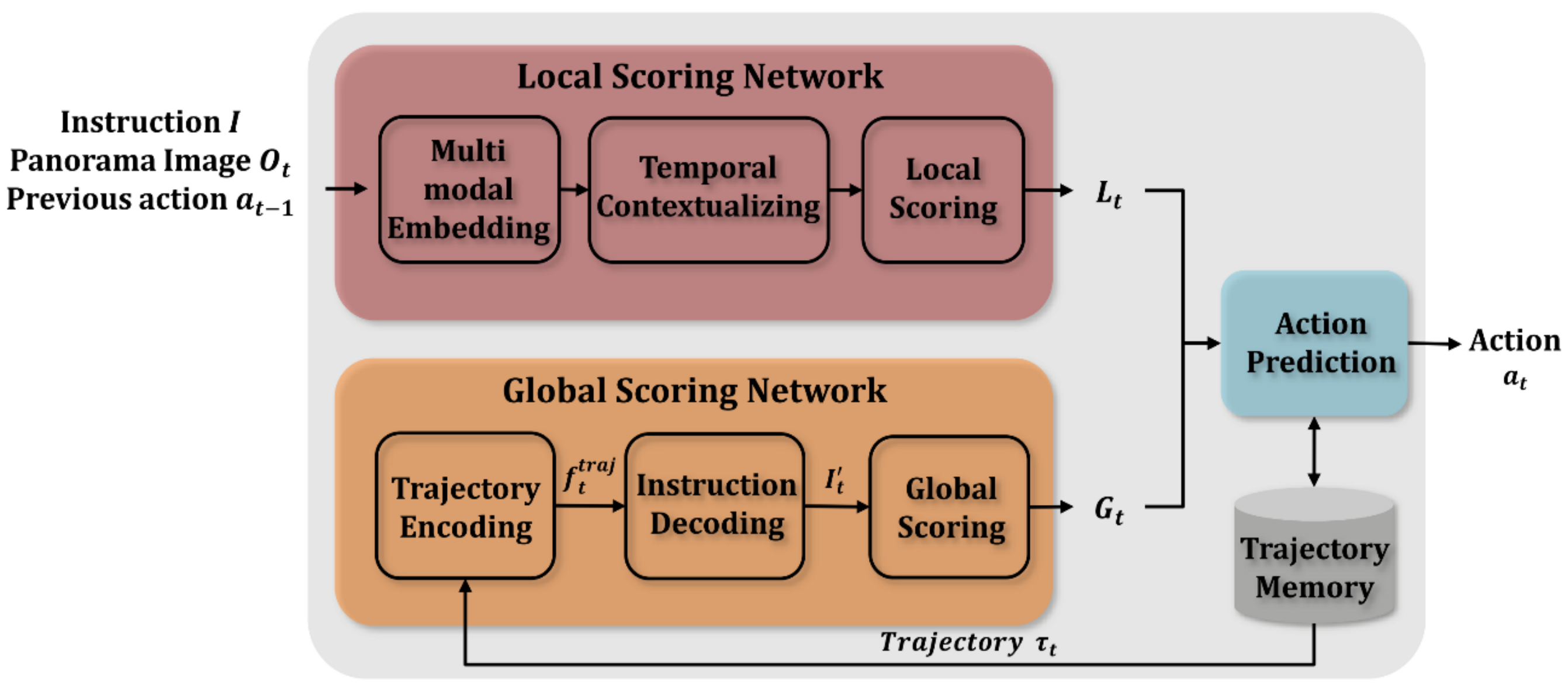
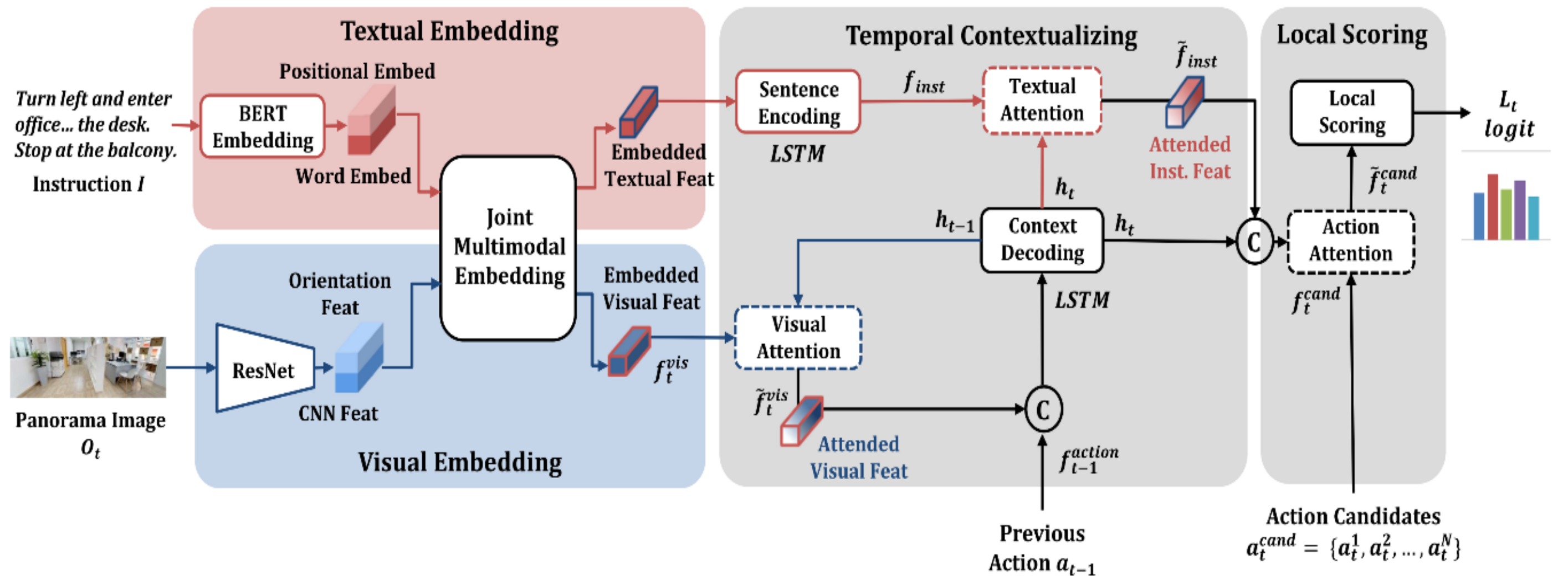
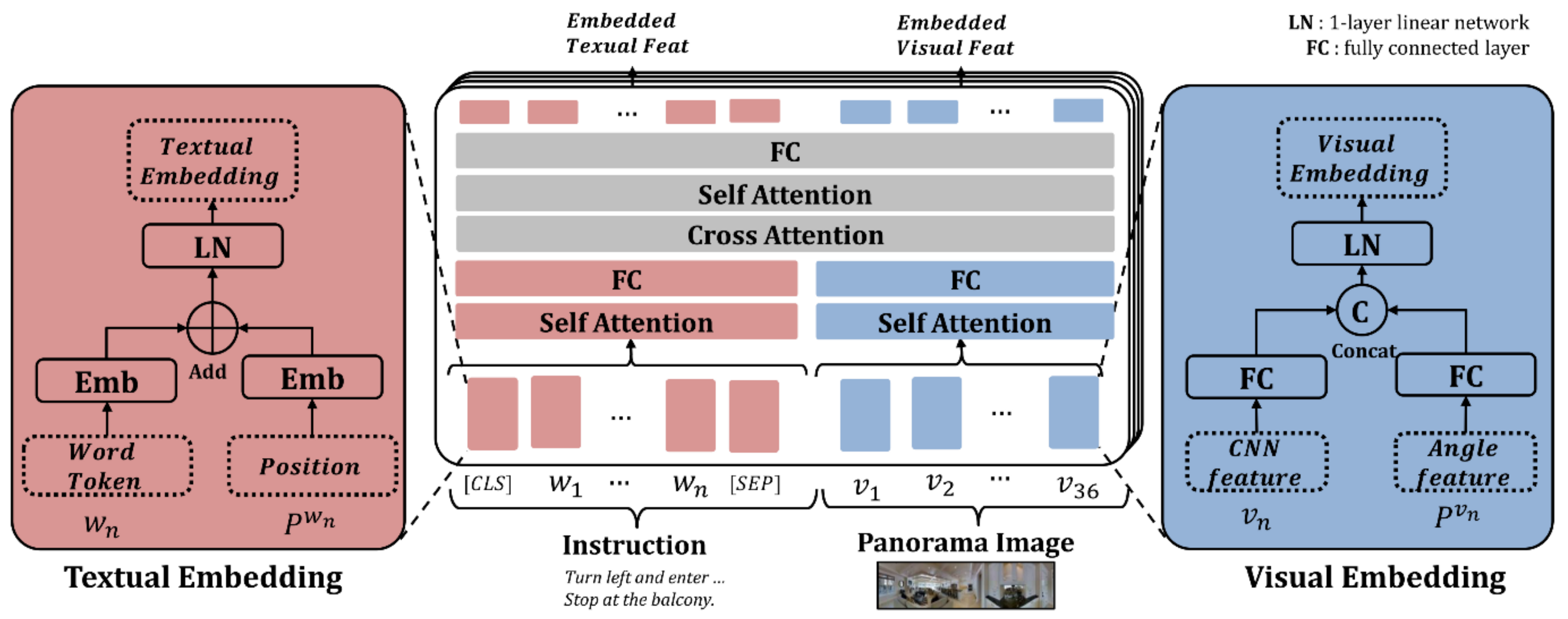
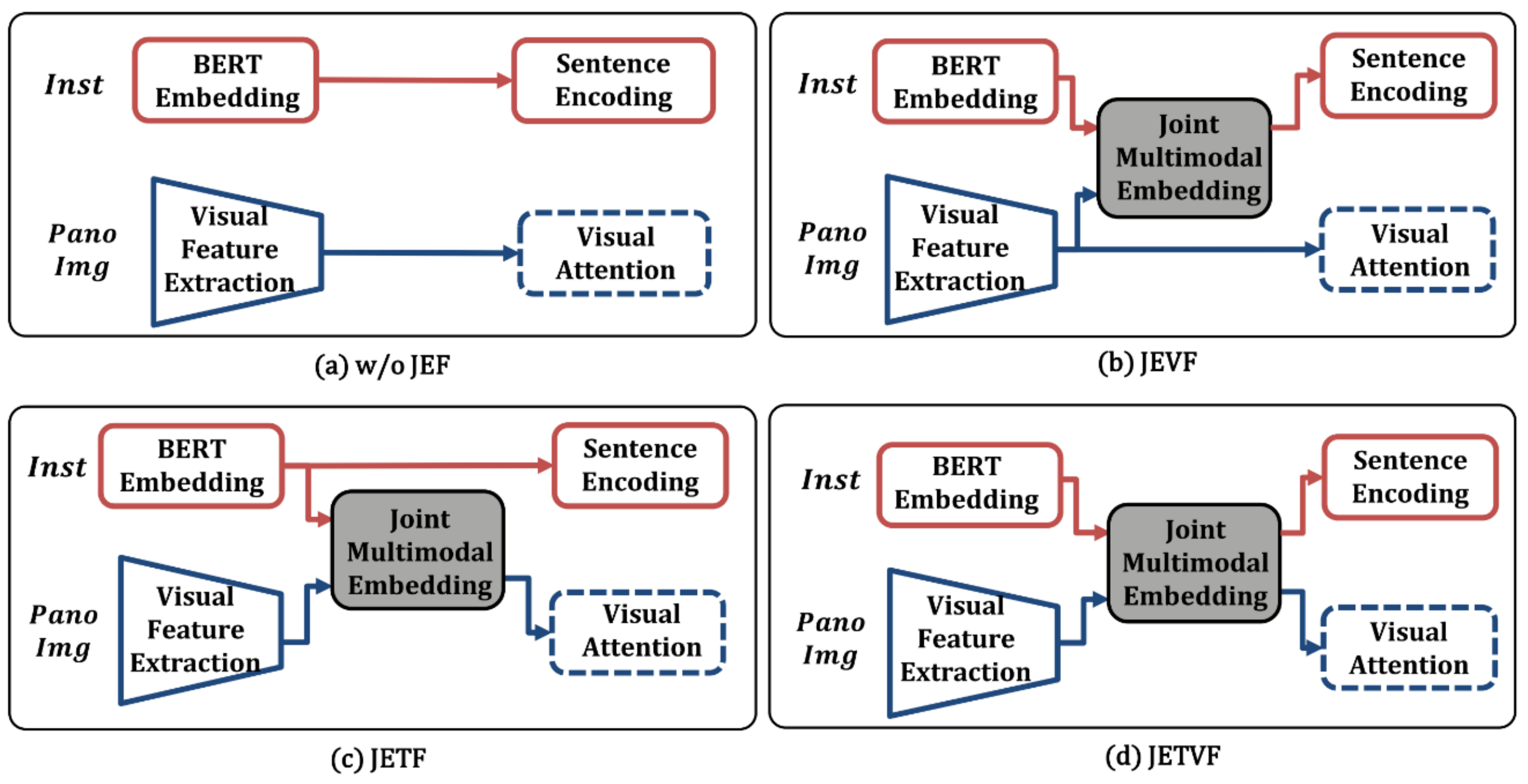
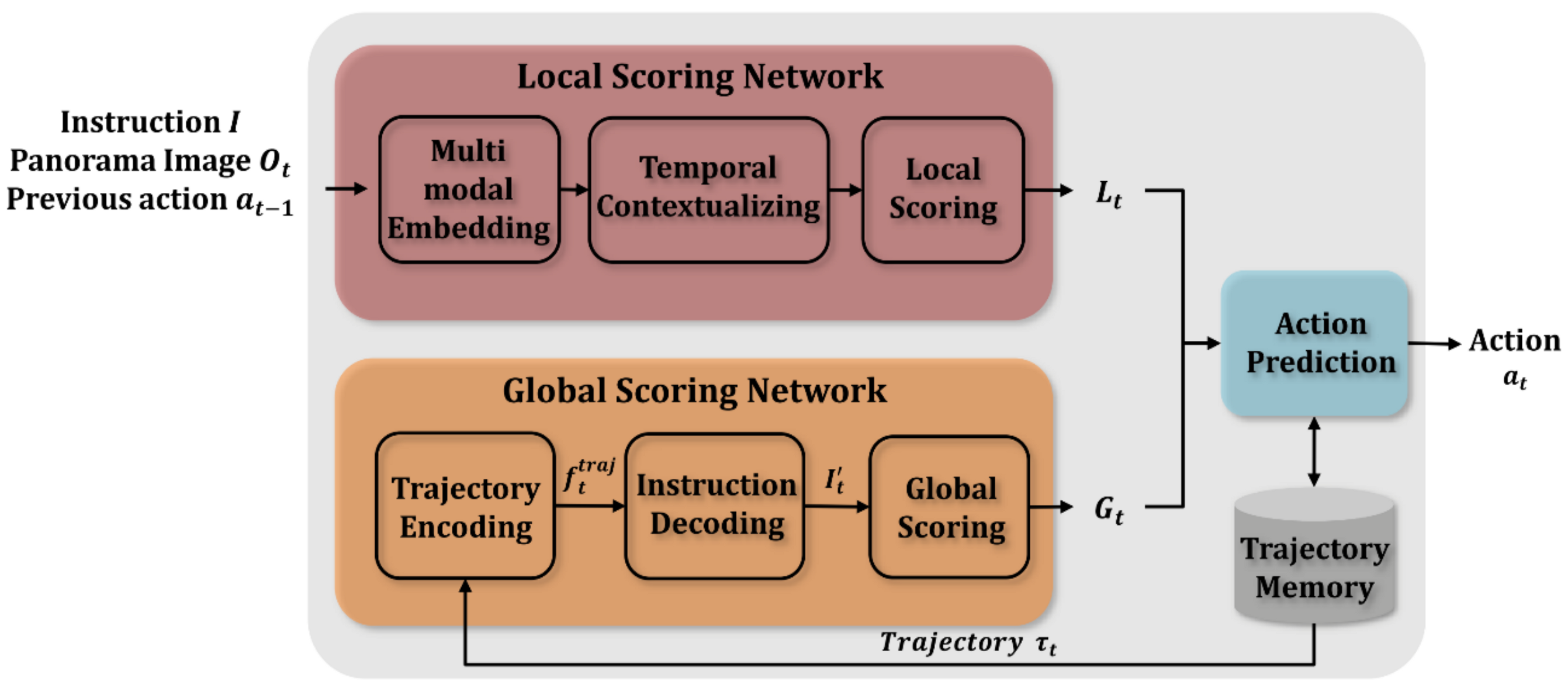
3.2. Proposed Model
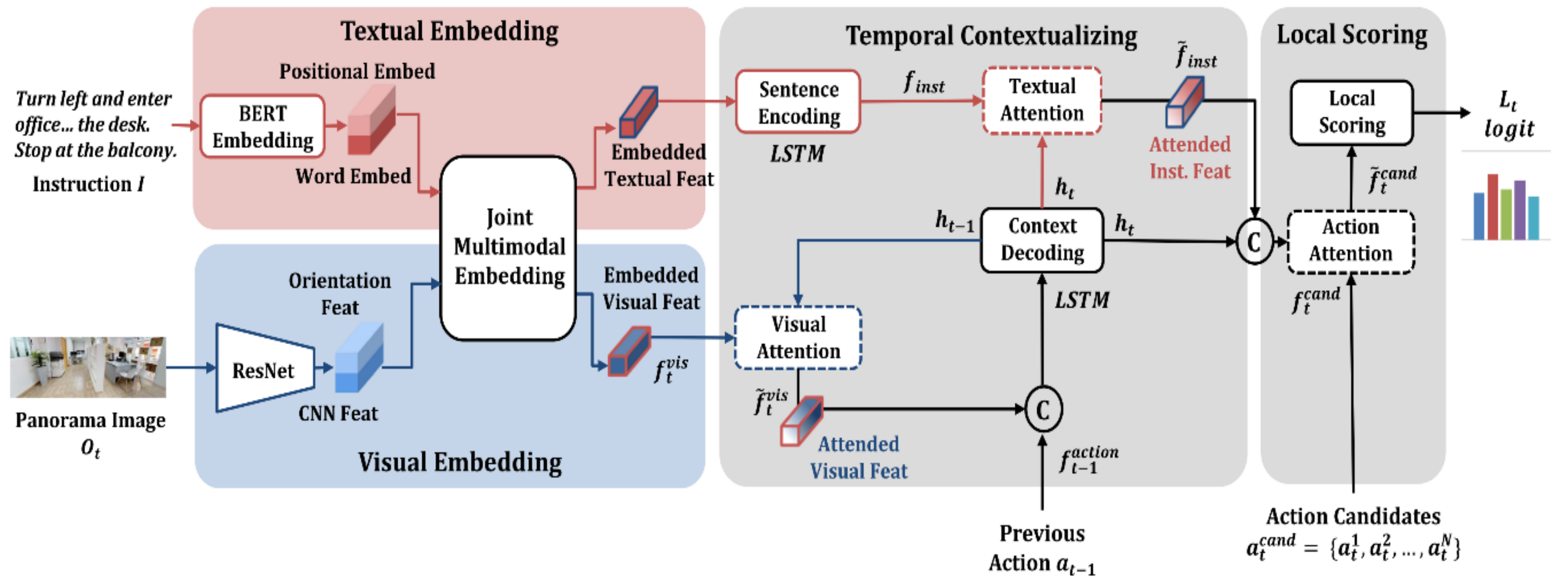
3.3. Local Scoring
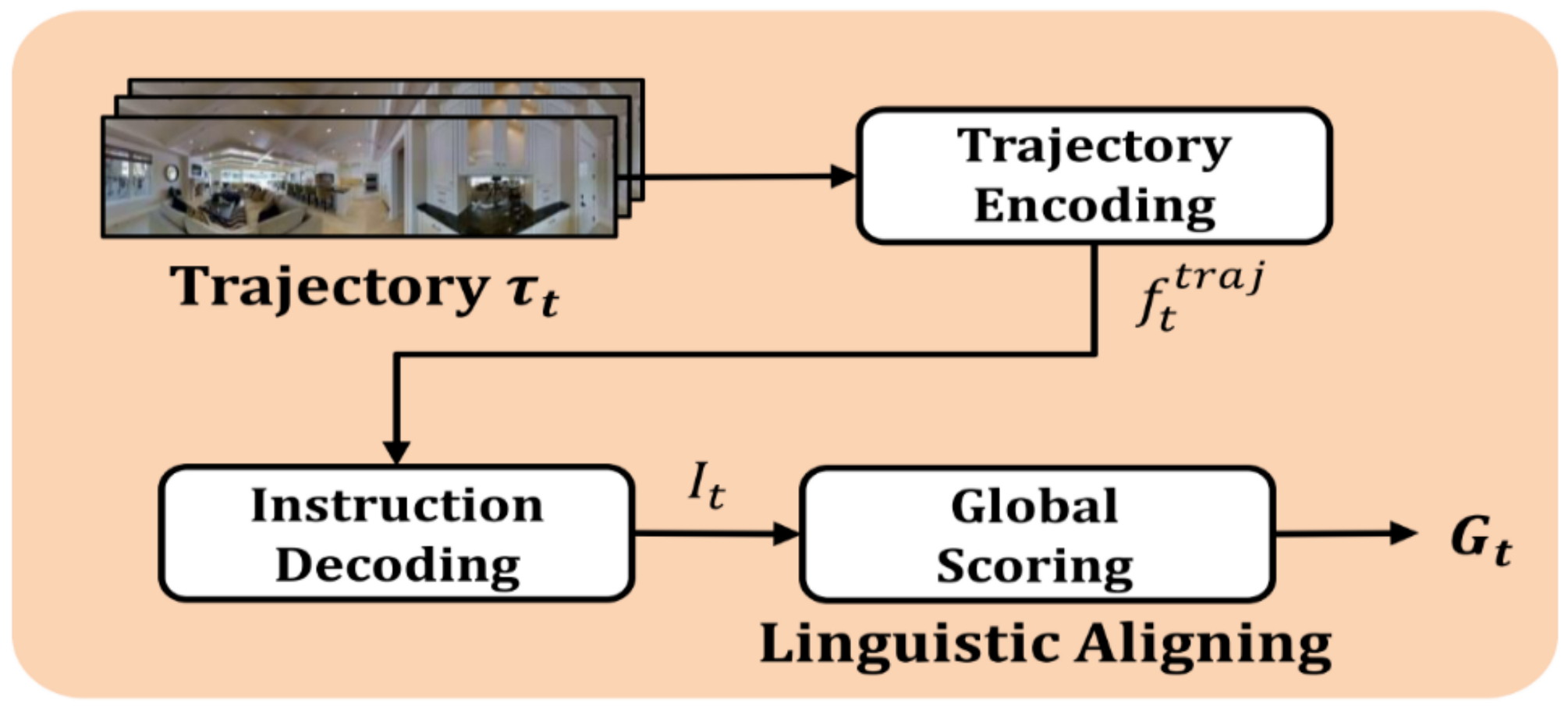
3.4. Global Scoring
3.5. Backtracking-Enabled Greedy Local Search
| Algorithm 1. Pseudocode of backtracking-enabled greedy local search (BGLS) algorithm. |
| BGLS() |
| 1: |
| 2: if () then return |
| 3: () |
| 4: if () then |
| 5: |
| 6: ) |
| 7: |
| 8: return |
| 9: end if |
| 10: for each possible action at state do |
| 11: |
| 12: end for |
| 13: |
| 14: |
| 15: ) |
| 16: |
| 17: return |
4. Experiments
4.1. Dataset and Model Training
4.2. Experiments
4.3. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Agrawal, A.; Lu, J.; Antol, S.; Mitchell, M.; Zitnick, C.L.; Parikh, D.; Batra, D. VQA: Visual question answering. Int. J. Comput. Vis. 2017, 123, 4–31. [Google Scholar] [CrossRef]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Moura, J.M.F.; Parikh, D.; Batra, D. Visual dialog. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1242–1256. [Google Scholar] [CrossRef] [PubMed]
- Das, A.; Datta, S.; Gkioxari, G.; Lee, S.; Parikh, D.; Batra, D. Embodied Question Answering. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2054–2063. [Google Scholar]
- Gordon, D.; Kembhavi, A.; Rastegari, M.; Redmon, J.; Fox, D.; Farhadi, A. IQA: Visual question answering in interactive environments. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4089–4098. [Google Scholar]
- Thomason, J.; Murray, M.; Cakmak, M.; Zettlemoyer, L. Vision-and-dialog navigation. In Proceedings of the International Conference Robot. Learning (CoRL), Osaka, Japan, 30 October–1 November 2019; pp. 394–406. [Google Scholar]
- Qi, Y.; Wu, Q.; Anderson, P.; Wang, X.; Wang, W.-Y.; Shen, C.; van den Henglel, A. REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Online. 14–19 June 2020; pp. 9982–9991. [Google Scholar]
- Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Sünderhauf, N.; Reid, I.; Gould, S.; van den Hengel, A. Vision-and-language navigation: Interpreting visually grounded navigation instructions in real environments. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; Volume 2. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Nießner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D data in indoor environments. In Proceedings of the International Conference 3D. Vision 2017, Qingdao, China, 10–12 October 2017; p. 5. [Google Scholar]
- Fried, D.; Hu, R.; Cirik, V.; Rohrbach, A.; Andreas, J.; Morency, L.-P.; Berg-Kirkpatrick, T.; Saenko, K.; Klein, D.; Darrell, T. Speaker–follower models for vision-and-language navigation. arXiv 2018, arXiv:1806.02724. [Google Scholar]
- Ma, C.; Lu, J.; Wu, Z.; AlRegib, G.; Kira, Z.; Socher, R.; Xiong, C. Self-monitoring navigation agent via auxiliary progress estimation. In Proceedings of the International Conference Learning Representation. (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Qi, Y.; Pan, Z.; Zhang, S.; van den Hengel, A.; Wu, Q. Object-and-Action Aware Model for Visual Language Navigation. In Proceedings of the Europa Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hong, Y.; Rodriguez -O, C.; Qi, Y.; Wu, Q.; Gould, S. Language and Visual Entity Relationship Graph for Agent Navigation. arXiv 2020, arXiv:2010.09304. [Google Scholar]
- Ma, C.; Wu, Z.; AlRegib, G.; Xiong, C.; Kira, Z. The regretful agent: Heuristic-aided navigation through progress estimation. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ke, L.; Li, X.; Bisk, Y.; Holtzman, A.; Gan, Z.; Liu, J.; Gao, J.; Choi, Y.; Srinvasa, S. Tactical rewind: Self-correction via backtracking in vision-and-language navigation. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Tan, H.; Yu, L.; Bansal, M. Learning to navigate unseen environments: Back translation with environmental dropout. In Proceedings of the International Conference North. American Chapter of the Association for Computational Linguistic s (NAACL), Minnesota, MI, USA, 2–7 June 2019; pp. 2610–2621. [Google Scholar]
- Jain, V.; Magalhaes, G.; Ku, A.; Vaswani, A.; Ie, E.; Baldridge, J. Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3674–3683. [Google Scholar]
- Wang, X.; Xiong, W.; Wang, H.; Wang, W.Y. Look before you leap: Bridging model-free and model-based reinforcement learning for planned-ahead vision-and-language navigation. Lecture Notes in Computer Science. In Proceedings of the Europa Conference Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 38–55. [Google Scholar]
- Wang, X.; Huang, Q.; Celikyilmax, A.; Gao, J.; Shen, D.; Wang, Y.-F.; Wang, W.-Y.; Zhang, L. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Landi, F.; Baraldi, L.; Cornia, M.; Corsini, M.; Cucchiara, R. Perceive, Transform., and Act.: Multi-modal Attention Networks for Vision-and-Language Navigation. arXiv 2019, arXiv:1911.12377. [Google Scholar]
- Hao, W.; Li, C.; Li, X.; Carin, L.; Gao, J. Towards learning a generic agent for vision-and-language navigation via pre-training. In Proceedings of the IEEE Conference Computer Vision Patt. Recogn. (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Majumdar, A.; Shviastava, A.; Lee, S.; Anderson, P.; Parikh, D.; Batra, D. Improving vision-and-language navigation with image-text pairs from the Web. In Proceedings of the Europa Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, L.-H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. VILBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the Thirty-Third conference Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 13–23. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VILBERT: Pre-training of generic visual linguistic representations. In Proceedings of the International Conference Learning Representation. (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Chen, Y.-C.; Li, L.; Yu, L.; Kholy, A.-E.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Universal Image-TExt Representation Learning. arXiv 2019, arXiv:1909.11740. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
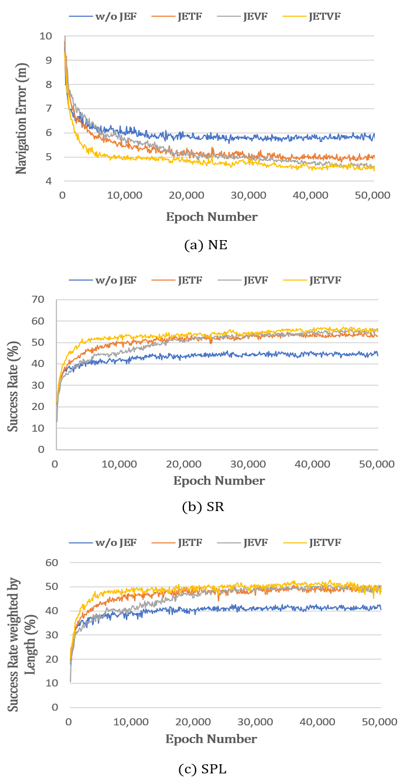
| Embedding Features | Val-Seen | Val-Unseen | ||||
|---|---|---|---|---|---|---|
| SR | SPL | NE | SR | SPL | NE | |
| w/o JEF | 62.0 | 59.0 | 4.0 | 52.0 | 48.0 | 5.2 |
| JEVF | 66.0 | 61.6 | 3.6 | 56.5 | 50.0 | 4.5 |
| JETF | 66.5 | 62.9 | 3.6 | 55.4 | 50.9 | 4.7 |
| JETVF | 67.9 | 63.9 | 3.6 | 58.7 | 53.5 | 4.4 |
| Temporal Contextualization | Val-Seen | Val-Unseen | ||||
|---|---|---|---|---|---|---|
| SR | SPL | NE | SR | SPL | NE | |
| AvCM | 67.9 | 64.1 | 3.4 | 58.5 | 51.8 | 4.4 |
| AtCM | 64.8 | 60.3 | 3.6 | 53.6 | 49.9 | 4.8 |
| AvtAM | 67.9 | 63.9 | 3.6 | 58.7 | 53.5 | 4.4 |
| No. | Global Scoring | Val-Unseen | ||
|---|---|---|---|---|
| SR | SPL | NE | ||
| 1 | LD with single instruction | 54.1 | 48.9 | 4.6 |
| 2 | DTW with single instruction | 54.7 | 49.2 | 4.6 |
| 3 | LD with triple instructions | 57.1 | 49.7 | 4.5 |
| 4 | DTW with triple instructions | 59.0 | 51.6 | 4.5 |
| Search | Val-Seen | Val-Unseen | ||||||
|---|---|---|---|---|---|---|---|---|
| SR | SPL | NE | TL | SR | SPL | NE | TL | |
| Greedy | 67.9 | 63.9 | 3.6 | 12.1 | 58.7 | 53.5 | 4.4 | 13.1 |
| Beam (K = 10) | 70.3 | 0.01 | 5.2 | 457.9 | 61.5 | 0.01 | 5.2 | 409.1 |
| Beam (K = 20) | 76.6 | 0.01 | 4.5 | 771.2 | 62.6 | 0.01 | 4.6 | 688.3 |
| Beam (K = 30) | 79.2 | 0.01 | 4.2 | 1122.9 | 72.9 | 0.01 | 4.5 | 1015.2 |
| BGLS | 70.1 | 64.1 | 3.2 | 13.5 | 59.0 | 51.6 | 4.4 | 15.1 |
| Model | Val-Seen | Val-Unseen | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SR | SPL | NE | SR | SPL | NE | SR | SPL | NE | |
| Random [7] | 15.9 | - | 9.5 | 16.0 | - | 9.2 | 13.0 | 12.0 | 9.8 |
| T-Forcing [7] | 27.4 | - | 8.0 | 19.6 | - | 8.6 | - | - | - |
| S-Forcing [7] | 38.6 | - | 6.0 | 21.8 | - | 7.8 | 20.0 | 18.0 | 7.8 |
| Speaker-Follower [9] | 66.0 | - | 3.4 | 36.0 | - | 6.6 | 35.0 | 28.0 | 6.6 |
| RCM [18] | 67.0 | - | 3.4 | 43.0 | - | 5.9 | 43.0 | 35.0 | 6.0 |
| Self-monitoring [10] | 67.0 | 58.0 | 3.2 | 45.0 | 32.0 | 5.5 | 48.0 | 32.0 | 6.0 |
| Regretful [10] | 69.0 | 63.0 | 3.2 | 50.0 | 41.0 | 5.3 | 48.0 | 40.0 | 5.7 |
| Env-Dropout [15] | 62.0 | 59.0 | 4.0 | 52.0 | 48.0 | 5.2 | 51.5 | 47.0 | 5.2 |
| OAAM [11] | 65.0 | 62.0 | - | 54.0 | 50.0 | - | 53.0 | 50.0 | - |
| LVERG [12] | 67.0 | 70.0 | 3.47 | 57.0 | 53.0 | 4.7 | 55.0 | 52.0 | 4.7 |
| PREVALENT [20] | 67.8 | 64.8 | 3.6 | 57.6 | 52.2 | 4.6 | 54.0 | 51.0 | 5.3 |
| Tactical-Rewind [14] | 70.0 | 4.0 | 3.1 | 63.0 | 2.0 | 4.0 | 61.0 | 3.0 | 4.3 |
| JMEBS (Greedy) | 67.9 | 63.9 | 3.6 | 58.7 | 53.5 | 4.4 | 52.1 | 47.4 | 5.4 |
| JMEBS (BGLS) | 70.1 | 64.1 | 3.2 | 59.0 | 51.6 | 4.4 | 55.7 | 51.8 | 5.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, J.; Kim, I. Joint Multimodal Embedding and Backtracking Search in Vision-and-Language Navigation. Sensors 2021, 21, 1012. https://doi.org/10.3390/s21031012
Hwang J, Kim I. Joint Multimodal Embedding and Backtracking Search in Vision-and-Language Navigation. Sensors. 2021; 21(3):1012. https://doi.org/10.3390/s21031012
Chicago/Turabian StyleHwang, Jisu, and Incheol Kim. 2021. "Joint Multimodal Embedding and Backtracking Search in Vision-and-Language Navigation" Sensors 21, no. 3: 1012. https://doi.org/10.3390/s21031012
APA StyleHwang, J., & Kim, I. (2021). Joint Multimodal Embedding and Backtracking Search in Vision-and-Language Navigation. Sensors, 21(3), 1012. https://doi.org/10.3390/s21031012