
Complex Deep Neural Networks from Large Scale Virtual IMU Data for Effective Human Activity Recognition Using Wearables


Abstract
:1. Introduction
2. Background
2.1. Human Activity Recognition Using Wearables and Machine Learning (HAR)
2.1.1. Conventional Modeling through the Activity Recognition Chain
2.1.2. Feature Learning
2.2. Tackling the Small Data Problem in HAR
2.2.1. Data Augmentation
2.2.2. Transfer Learning and Self-Supervised Learning
2.2.3. Cross-Modality Transfer
2.3. Generating Large Scale Virtual IMU Data from Real World Videos Using IMUTube
2.3.1. Adaptive Video Selection
2.3.2. 3D Human Motion Tracking and Virtual IMU Data Extraction
3. Complex Deep Neural Networks for Human Activity Recognition
3.1. Model Overview
3.2. Adaptive Trimming of Sensor Window for Detecting Core Motion Signal
3.3. Multi-Scale, Multi-Window, Multi-View Convolutional Model
3.3.1. Non-Linear Multi-Scale Feature Representation
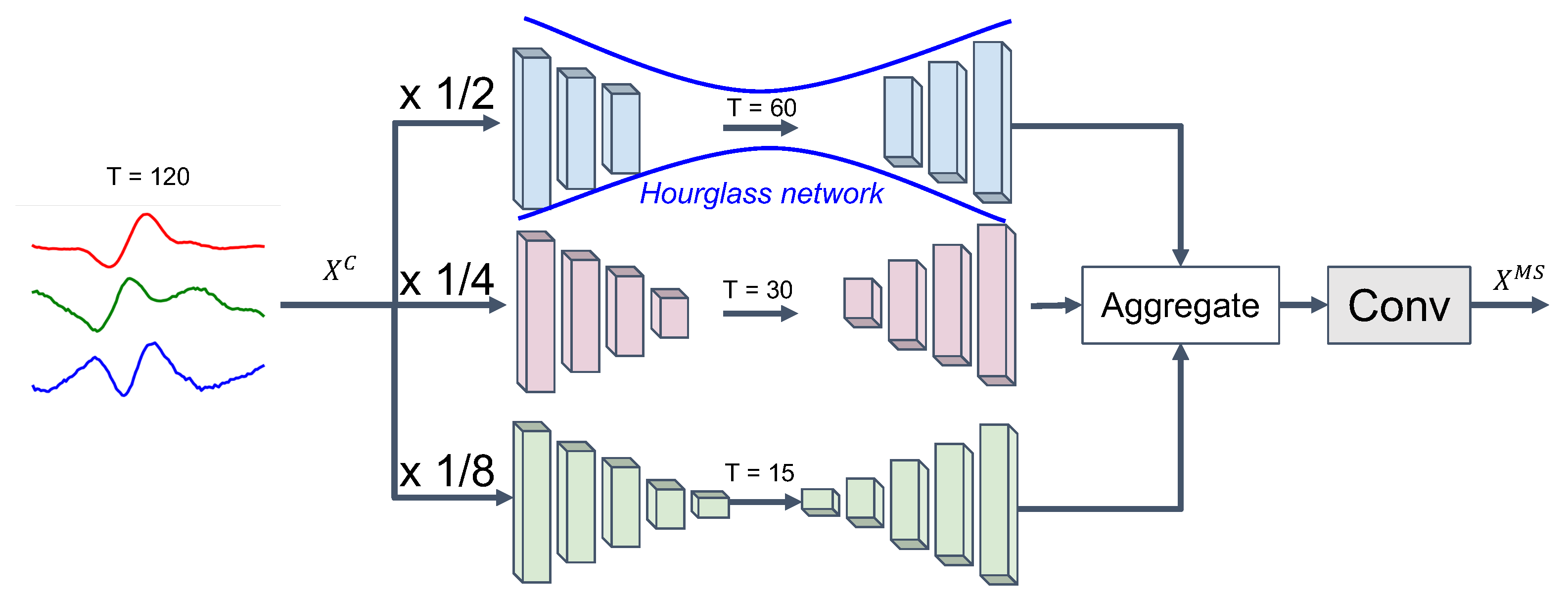
3.3.2. Multiple Kernel Window Size for Capturing Varying Motion Length
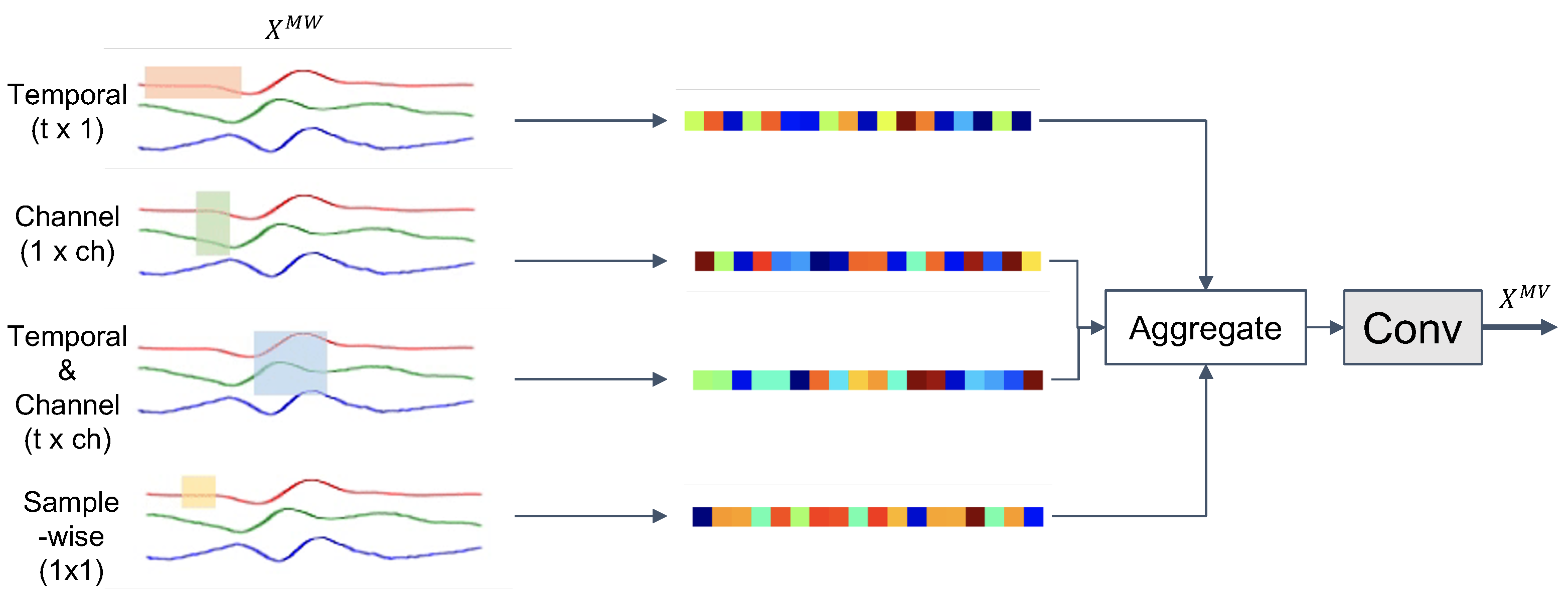
3.3.3. Multi-View Kernels for Time-Channel Representation
3.4. Full Feature Extraction Model with Skip-Connection and Temporal Aggregation
3.4.1. Composite Convolutional Layer
3.4.2. Handling Vanishing Gradients with Skip Connections
3.4.3. Temporal Aggregation with Multi-Scale Recurrent Neural Network
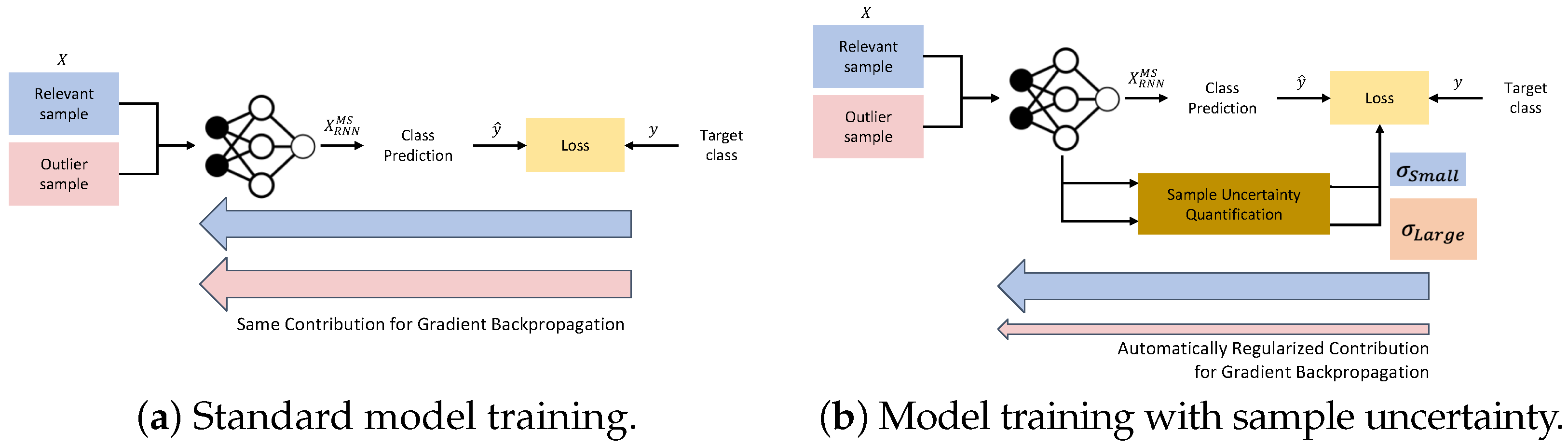
3.5. Uncertainty Modeling for Noisy Samples
4. Case Study: Analyzing Free Weight Gym Exercises
4.1. Scenario
4.2. Datasets
4.3. Evaluation Protocol
4.4. Model Hyperparameters
4.5. Results
5. Discussion
5.1. Collect Even Larger Datasets of Virtual IMU Data
5.2. Analyze Complex Activities
5.3. End-to-End Learning of Complex Model Architectures
5.4. Virtual IMU Data as Basis for Alternatives to Supervised Learning
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Y.; Jiang, F.; Gowda, M. Finger gesture tracking for interactive applications: A pilot study with sign languages. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–21. [Google Scholar] [CrossRef]
- Tchuente, F.; Baddour, N.; Lemaire, E. Classification of aggressive movements using smartwatches. Sensors 2020, 20, 6377. [Google Scholar] [CrossRef]
- Yang, S.; Gao, B.; Jiang, L.; Jin, J.; Gao, Z.; Ma, X.; Woo, W. IoT structured long-term wearable social sensing for mental wellbeing. IEEE Internet Things J. 2018, 6, 3652–3662. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, W.; Phoha, V.; Sun, W.; Jin, Z. EarEcho: Using ear canal echo for wearable authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–24. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM CSUR 2014, 46, 33. [Google Scholar] [CrossRef]
- Plötz, T.; Hammerla, N.; Olivier, P. Feature learning for activity recognition in ubiquitous computing. In Proceedings of the Twenty-Second International JOINT conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haradal, S.; Hayashi, H.; Uchida, S. Biosignal data augmentation based on generative adversarial networks. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 368–371. [Google Scholar]
- Gjoreski, M.; Kalabakov, S.; Luštrek, M.; Gams, M.; Gjoreski, H. Cross-dataset deep transfer learning for activity recognition. In Adjunct Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers; ACM: New York, NY, USA, 2019; pp. 714–718. [Google Scholar]
- Le Guennec, A.; Malinowski, S.; Tavenard, R. Data Augmentation for Time Series Classification using Convolutional Neural Networks. In Proceedings of the ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data, Porto, Portugal, 11 September 2016. [Google Scholar]
- Um, T.T.; Pfister, F.; Kulić, D. Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks. In ICMI; ACM: New York, NY, USA, 2017; pp. 216–220. [Google Scholar]
- Hoelzemann, A.; Van Laerhoven, K. Digging Deeper: Towards a Better Understanding of Transfer Learning for Human Activity Recognition. In Proceedings of the 2020 International Symposium on Wearable Computers, New York, NY, USA, 12–17 September 2020; pp. 50–54. [Google Scholar]
- Haresamudram, H.; Beedu, A.; Agrawal, V.; Grady, P.; Essa, I.; Hoffman, J.; Plötz, T. Masked reconstruction based self-supervision for human activity recognition. In Proceedings of the 2020 International Symposium on Wearable Computers, New York, NY, USA, 12–17 September 2020; pp. 45–49. [Google Scholar]
- Kwon, H.; Tong, C.; Haresamudram, H.; Gao, Y.; Abowd, G.D.; Lane, N.D.; Ploetz, T. IMUTube: Automatic extraction of virtual on-body accelerometry from video for human activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Kwon, H.; Wang, B.; Abowd, G.; Plötz, T. Approaching the Real-World: Supporting Activity Recognition Training with Virtual IMU Data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 5, 1–32. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Gowda, M. When Video meets Inertial Sensors: Zero-shot Domain Adaptation for Finger Motion Analytics with Inertial Sensors. In Proceedings of the International Conference on Internet-of-Things Design and Implementation, Charlottesville, VA, USA, 18–21 May 2021; pp. 182–194. [Google Scholar]
- Rey, V.; Hevesi, P.; Kovalenko, O.; Lukowicz, P. Let there be IMU data: Generating training data for wearable, motion sensor based activity recognition from monocular RGB videos. In Adjunct Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the ACM International Symposium on Wearable Computers; ACM: New York, NY, USA, 2019; pp. 699–708. [Google Scholar]
- Plötz, T.; Chen, C.; Abowd, G.D. Automatic Synchronization of Wearable Sensors and Video-Cameras for Ground Truth Annotation–A Practical Approach. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 100–103. [Google Scholar]
- Kwon, H.; Abowd, G.; Plötz, T. Adding structural characteristics to distribution-based accelerometer representations for activity recognition using wearables. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; pp. 72–75. [Google Scholar]
- Nyan, M.N.; Tay, F.E.H.; Seah, K.H.W.; Sitoh, Y.Y. Classification of gait patterns in the time–frequency domain. J. Biomech. 2006, 39, 2647–2656. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Ambikairajah, E.; Lovell, N.H.; Celler, B.G. Accelerometry based classification of walking patterns using time-frequency analysis. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; pp. 4899–4902. [Google Scholar]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges, and Opportunities. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Varamin, A.; Abbasnejad, E.; Shi, Q.; Ranasinghe, D.; Rezatofighi, H. Deep auto-set: A deep auto-encoder-set network for activity recognition using wearables. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, New York, NY, USA, 5–7 November 2018; pp. 246–253. [Google Scholar]
- Haresamudram, H.; Anderson, D.; Plötz, T. On the role of features in human activity recognition. In Proceedings of the 2019 International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 78–88. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1533–1540. [Google Scholar]
- Morales, F.; Roggen, D. Deep convolutional feature transfer across mobile activity recognition domains, sensor modalities and locations. In Proceedings of the 2016 ACM International Symposium on Wearable Computers, Heidelberg, Germany, 12–16 September 2016; pp. 92–99. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bevilacqua, A.; MacDonald, K.; Rangarej, A.; Widjaya, V.; Caulfield, B.; Kechadi, T. Human activity recognition with convolutional neural networks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2018; pp. 541–552. [Google Scholar]
- Bächlin, M.; Plotnik, M.; Tröster, G. Wearable assistant for Parkinson’s disease patients with the freezing of gait symptom. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 436–446. [Google Scholar] [CrossRef] [PubMed]
- Scholl, P.M.; Wille, M.; Van Laerhoven, K. Wearables in the wet lab: A laboratory system for capturing and guiding experiments. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 589–599. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P. Data augmentation using synthetic data for time series classification with deep residual networks. arXiv 2018, arXiv:1808.02455. [Google Scholar]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Yao, S.; Zhao, Y.; Shao, H.; Zhang, C.; Zhang, A.; Hu, S.; Liu, D.; Liu, S.; Su, L.; Abdelzaher, T. Sensegan: Enabling deep learning for internet of things with a semi-supervised framework. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-cgan: Conditional generative adversarial network for data augmentation in noisy time series with irregular sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Hu, D.; Zheng, V.; Yang, Q. Cross-domain activity recognition via transfer learning. Pervasive Mob. Comput. 2011, 7, 344–358. [Google Scholar] [CrossRef]
- Chen, Y.; Gu, Y.; Jiang, X.; Wang, J. Ocean: A new opportunistic computing model for wearable activity recognition. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 33–36. [Google Scholar]
- Saeed, A.; Ozcelebi, T.; Lukkien, J. Multi-task self-supervised learning for human activity detection. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Saeed, A.; Salim, F.; Ozcelebi, T.; Lukkien, J. Federated Self-Supervised Learning of Multisensor Representations for Embedded Intelligence. IEEE Internet Things J. 2020, 8, 1030–1040. [Google Scholar] [CrossRef]
- Haresamudram, H.; Essa, I.; Plötz, T. Contrastive predictive coding for human activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–26. [Google Scholar] [CrossRef]
- Kang, C.; Jung, H.; Lee, Y. Towards Machine Learning with Zero Real-World Data. In Proceedings of the ACM Workshop on Wearable Systems and Applications, Seoul, Korea, 17–21 June 2019; pp. 41–46. [Google Scholar]
- Haas, J.K. A History of the Unity Game Engine; Worcester Polytechnic Institute: Worcester, MA, USA, 2014. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.; Pons-Moll, G.; Black, M. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5442–5451. [Google Scholar]
- Lab, C.M.G. Carnegie Mellon Motion Capture Database. Available online: http://mocap.cs.cmu.edu/ (accessed on 10 December 2021).
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Berkeley mhad: A comprehensive multimodal human action database. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 53–60. [Google Scholar]
- Xiao, F.; Pei, L.; Chu, L.; Zou, D.; Yu, W.; Zhu, Y.; Li, T. A Deep Learning Method for Complex Human Activity Recognition Using Virtual Wearable Sensors. arXiv 2020, arXiv:2003.01874. [Google Scholar]
- Takeda, S.; Okita, T.; Lago, P.; Inoue, S. A multi-sensor setting activity recognition simulation tool. In Proceedings of the ACM International Joint Conference and International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1444–1448. [Google Scholar]
- Cao, Z.; Hidalgo Martinez, G.; Simon, T.; Wei, S.; Sheikh, Y.A. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, S.H.; Li, R.; Dong, X.; Rosin, P.; Cai, Z.; Han, X.; Yang, D.; Huang, H.; Hu, S.M. Pose2seg: Detection free human instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 889–898. [Google Scholar]
- He, H.; Zhang, J.; Zhang, Q.; Tao, D. Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liu, L.; Zhang, J.; He, R.; Liu, Y.; Wang, Y.; Tai, Y.; Luo, D.; Wang, C.; Li, J.; Huang, F. Learning by Analogy: Reliable Supervision from Transformations for Unsupervised Optical Flow Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7753–7762. [Google Scholar]
- Joel, A.; Stergios, I. A Direct Least-Squares (DLS) method for PnP. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Vankadari, M.; Garg, S.; Majumder, A.; Kumar, S.; Behera, A. Unsupervised monocular depth estimation for night-time images using adversarial domain feature adaptation. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 443–459. [Google Scholar]
- Gordon, A.; Li, H.; Jonschkowski, R.; Angelova, A. Depth from Videos in the Wild: Unsupervised Monocular Depth Learning From Unknown Cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Park, J.; Zhou, Q.; Koltun, V. Colored Point Cloud Registration Revisited. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 143–152. [Google Scholar]
- Community, B.O. Blender—A 3D Modelling and Rendering Package; Blender Foundation, Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Young, A.; Ling, M.; Arvind, D. IMUSim: A simulation environment for inertial sensing algorithm design and evaluation. In Proceedings of the International Conference on Information Processing in Sensor Networks (IPSN), Chicago, IL, USA, 12–14 April 2011; pp. 199–210. [Google Scholar]
- Conover, W.; Iman, R. Rank transformations as a bridge between parametric and nonparametric statistics. Am. Stat. 1981, 35, 124–129. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 8–22 June 2012. [Google Scholar]
- Koskimäki, H.; Siirtola, P.; Röning, J. Myogym: Introducing an open gym data set for activity recognition collected using myo armband. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 537–546. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Li, P.; Lin, Y.; Schultz-Fellenz, E. Contextual hourglass network for semantic segmentation of high resolution aerial imagery. arXiv 2018, arXiv:1810.12813. [Google Scholar]
- Oñoro-Rubio, D.; Niepert, M. Contextual Hourglass Networks for Segmentation and Density Estimation. arXiv 2018, arXiv:1806.04009. [Google Scholar]
- Tudor-Locke, C.; Craig, C.; Beets, M.; Belton, S.; Cardon, G.; Duncan, S.; Hatano, Y.; Lubans, D.; Olds, T.; Raustorp, A.; et al. How many steps/day are enough? for children and adolescents. Int. J. Behav. Nutr. Phys. Act. 2011, 8, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tudor-Locke, C.; Craig, C.; Brown, W.; Clemes, S.; De Cocker, K.; Giles-Corti, B.; Hatano, Y.; Inoue, S.; Matsudo, S.; Mutrie, N.; et al. How many steps/day are enough? For adults. Int. J. Behav. Nutr. Phys. Act. 2011, 8, 1–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bassett, D.; Toth, L.; LaMunion, S.; Crouter, S. Step counting: A review of measurement considerations and health-related applications. Sport. Med. 2017, 47, 1303–1315. [Google Scholar] [CrossRef] [Green Version]
- Baz-Valle, E.; Fontes-Villalba, M.; Santos-Concejero, J. Total number of sets as a training volume quantification method for muscle hypertrophy: A systematic review. J. Strength Cond. Res. 2021, 35, 870–878. [Google Scholar] [CrossRef] [PubMed]
- Schoenfeld, B.; Ogborn, D.; Krieger, J. Effect of repetition duration during resistance training on muscle hypertrophy: A systematic review and meta-analysis. Sport. Med. 2015, 45, 577–585. [Google Scholar] [CrossRef]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (Bigcomp), Jeju, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Sena, J.; Barreto, J.; Caetano, C.; Cramer, G.; Schwartz, W.R. Human activity recognition based on smartphone and wearable sensors using multiscale DCNN ensemble. Neurocomputing 2021, 444, 226–243. [Google Scholar] [CrossRef]
- Lin, T.; RoyChowdhury, A.; Maji, S. Bilinear cnn models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Bai, L.; Yao, L.; Wang, X.; Kanhere, S.; Guo, B.; Yu, Z. Adversarial multi-view networks for activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–22. [Google Scholar] [CrossRef]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies. In A Field Guide to Dynamical Recurrent Networks; Kremer, S.C., Kolen, J.F., Eds.; IEEE Press: Piscataway, NJ, USA, 2001; pp. 237–243. [Google Scholar]
- Goh, G.; Hodas, N.; Vishnu, A. Deep learning for computational chemistry. J. Comput. Chem. 2017, 38, 1291–1307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lu, R.; Duan, Z.; Zhang, C. Multi-scale recurrent neural network for sound event detection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 131–135. [Google Scholar]
- Chung, J.; Ahn, S.; Bengio, Y. Hierarchical multiscale recurrent neural networks. arXiv 2016, arXiv:1609.01704. [Google Scholar]
- Kádár, A.; Côté, M.; Chrupała, G.; Alishahi, A. Revisiting the hierarchical multiscale lstm. arXiv 2018, arXiv:1807.03595. [Google Scholar]
- Hu, N.; Englebienne, G.; Kröse, B. Learning to Recognize Human Activities Using Soft Labels. TPAMI 2017, 39, 1973–1984. [Google Scholar] [CrossRef]
- Kwon, H.; Abowd, G.; Plötz, T. Handling annotation uncertainty in human activity recognition. In Proceedings of the 23rd International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 109–117. [Google Scholar]
- Nasir, M.; Baucom, B.; Narayanan, S. Redundancy analysis of behavioral coding for couples therapy and improved estimation of behavior from noisy annotations. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 1886–1890. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Wilson, E. Probable inference, the law of succession, and statistical inference. J. Am. Stat. Assoc. 1927, 22, 209–212. [Google Scholar] [CrossRef]
- Rolnick, D.; Veit, A.; Belongie, S.; Shavit, N. Deep learning is robust to massive label noise. arXiv 2017, arXiv:1705.10694. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural Architecture Search: A Survey. J. Mach. Learn. Res. 2019, 20, 1–21. [Google Scholar]
- Komodakis, N.; Gidaris, S. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Misra, I.; Zitnick, C.L.; Hebert, M. Shuffle and learn: Unsupervised learning using temporal order verification. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 527–544. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Muscle Group | Posture | One-Arm, Both or Alternate |
|---|---|---|---|
| One-Arm Dumbbell Row | Middle Back | Bent Over | One-arm |
| Incline Dumbbell Flyes | Chest | Seated inclined | Both |
| Incline Dumbbell Press | Chest | Seated inclined | Both |
| Dumbbell Flyes | Chest | On back | Both |
| Tricep Dumbbell Kickback | Triceps | Bent Over | One-arm |
| Dumbbell Alternate Bicep Curl | Biceps | Standing | Alternate |
| Incline Hammer Curl | Biceps | Seated inclined | Both |
| Concentration Curl | Biceps | Seated | One-arm |
| Hammer Curl | Biceps | Standing | Alternate |
| Side Lateral Raise | Shoulders | Standing | Both |
| Front Dumbbell Raise | Shoulders | Standing | Alternate |
| Seated Dumbbell Shoulder Press | Shoulders | Seated | Both |
| Lying Rear Delt Raise | Shoulders | On stomach | Both |
| Model | Number of Parameters | Training Data | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Real IMU | Real + Virtual IMU | |||||||||
| ConvNet | 106,054 | 5.7% | ||||||||
| DeepConvLSTM | 394,189 | 19.7% | ||||||||
| Proposed | ||||||||||
| AT | MS | MW | MV | AX | RNN | UL | ||||
| ✔ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | 1,239,519 | 8.3% | ||
| ✔ | ✔ | ✕ | ✕ | ✕ | ✕ | ✕ | 1,335,519 | 8.1% | ||
| ✔ | ✔ | ✔ | ✕ | ✕ | ✕ | ✕ | 10,855,199 | 9.0% | ||
| ✔ | ✔ | ✔ | ✔ | ✕ | ✕ | ✕ | 42,727,455 | 10.6% | ||
| ✔ | ✔ | ✔ | ✔ | ✔ | ✕ | ✕ | 42,933,599 | 13.1% | ||
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✕ | 112,810,015 | 11.8% | ||
| ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 116,473,632 | 10.4% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, H.; Abowd, G.D.; Plötz, T. Complex Deep Neural Networks from Large Scale Virtual IMU Data for Effective Human Activity Recognition Using Wearables. Sensors 2021, 21, 8337. https://doi.org/10.3390/s21248337
Kwon H, Abowd GD, Plötz T. Complex Deep Neural Networks from Large Scale Virtual IMU Data for Effective Human Activity Recognition Using Wearables. Sensors. 2021; 21(24):8337. https://doi.org/10.3390/s21248337
Chicago/Turabian StyleKwon, Hyeokhyen, Gregory D. Abowd, and Thomas Plötz. 2021. "Complex Deep Neural Networks from Large Scale Virtual IMU Data for Effective Human Activity Recognition Using Wearables" Sensors 21, no. 24: 8337. https://doi.org/10.3390/s21248337
APA StyleKwon, H., Abowd, G. D., & Plötz, T. (2021). Complex Deep Neural Networks from Large Scale Virtual IMU Data for Effective Human Activity Recognition Using Wearables. Sensors, 21(24), 8337. https://doi.org/10.3390/s21248337