
CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method


Abstract
:1. Introduction
- A novel encrypted traffic classification model called CBD is designed. It combines a Convolutional Neural Network (CNN) and Bidirectional Encoder Representation from Transformers (BERT) to automatically learn the features of traffic data from the packet level and flow level to achieve the encrypted traffic classification for applications.
- A general pre-training method suitable for the field of encrypted traffic analysis is proposed. For unlabeled data, this method proposes two tasks of identifying ciphertext packets and identifying continuous flows, to deepen the model’s understanding and learning of encrypted traffic data.
- The CBD model has achieved good results when encrypting traffic classification. In addition, the performence of the CBD model has obvious advantages compared with other methods.
2. Related Work
2.1. Applications of Deep Learning
2.2. Applications of Transfer Learning
2.3. Applications of Transformer Model
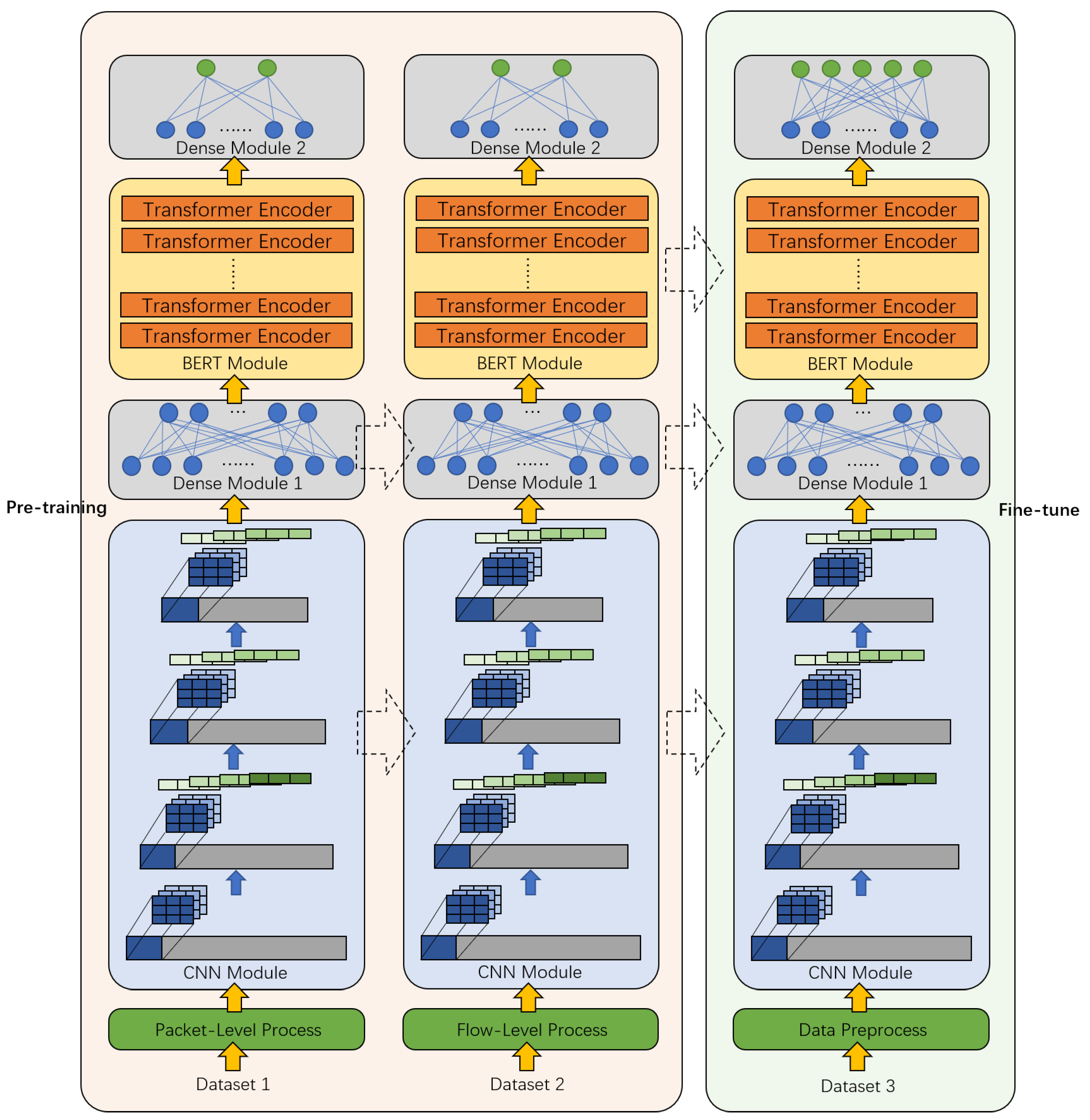
3. Model Structure
3.1. Data Preprocess
| Algorithm 1 Preprocessing Algorithm. |
|
3.2. CNN Module
3.3. BERT Module
3.4. Dense Module
3.5. Pre-Training of Unlabeled Data
3.6. Model Transfer and Fine-Tune
4. Experiment
4.1. Experimental Settings
4.2. Evaluation Metrics
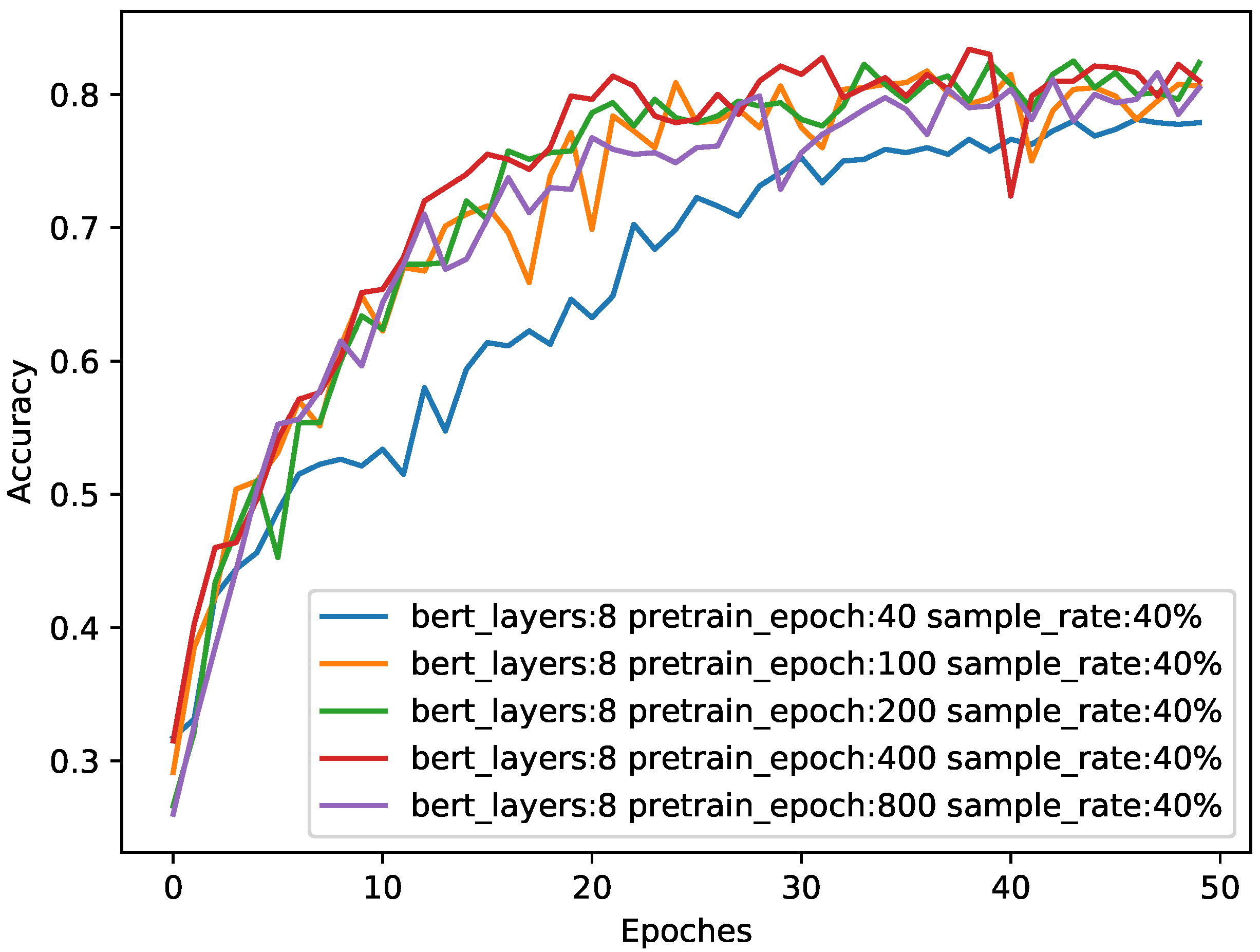
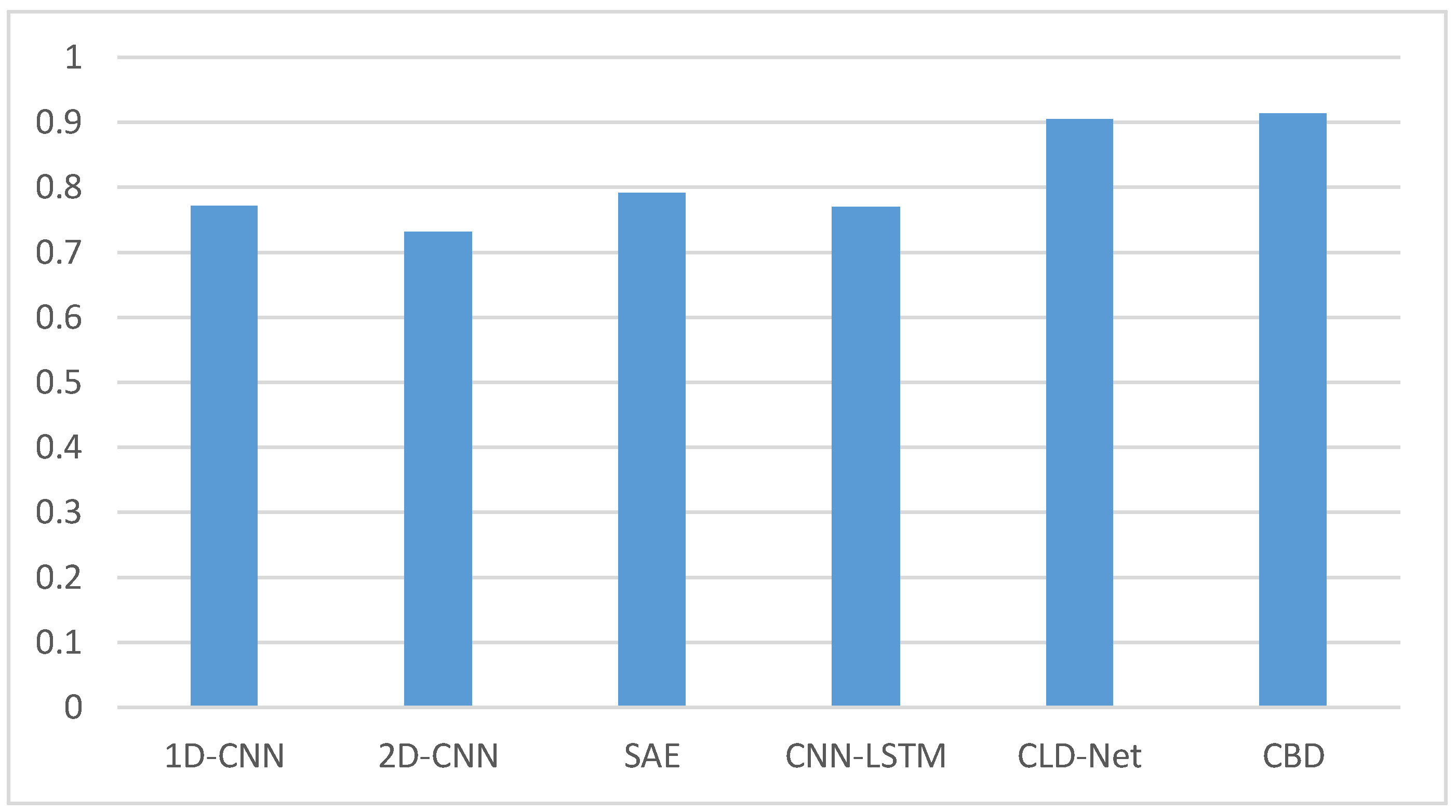
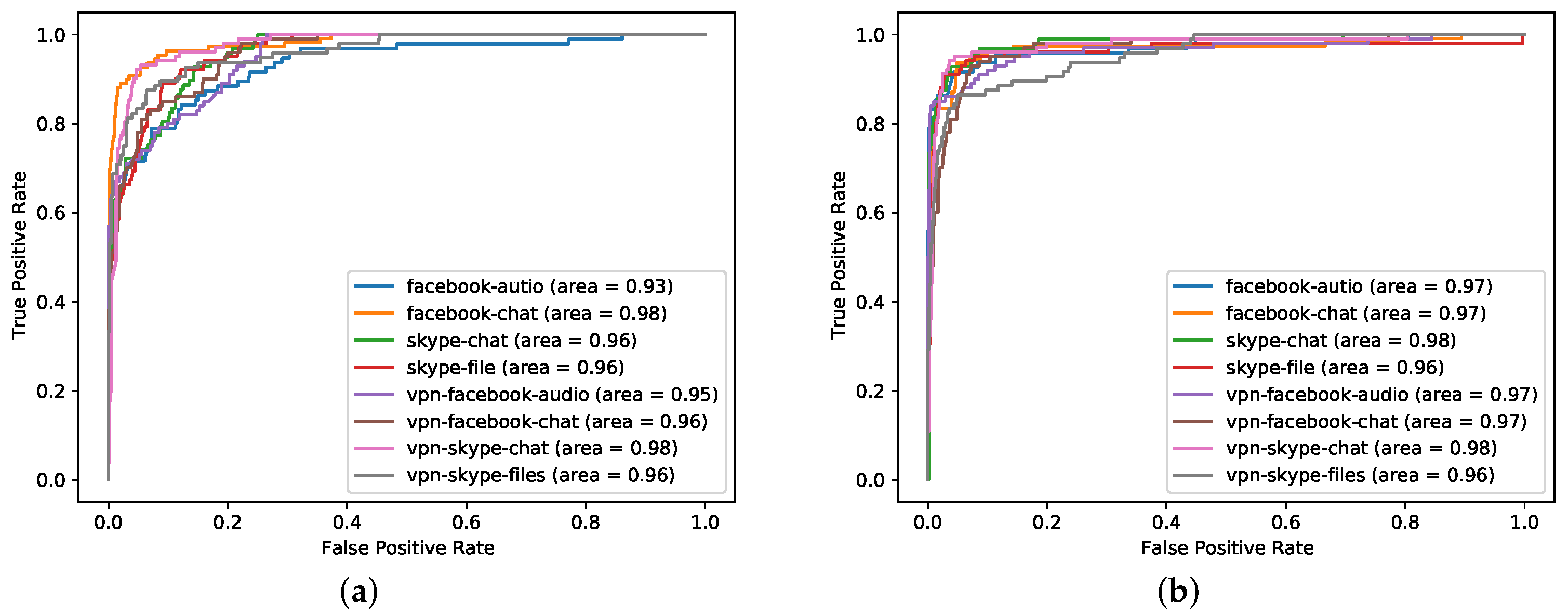
4.3. Experimental Results
- 1.
- Sample Size = 20% or 0.2 (200 samples are randomly selected from each class of data to form a new dataset);
- 2.
- Sample Size = 40% or 0.4 (400 samples are randomly selected from each class of data to form a new dataset);
- 3.
- Sample Size = 60% or 0.6 (600 samples are randomly selected from each class of data to form a new dataset);
- 4.
- Sample Size = 80% or 0.8 (800 samples are randomly selected from each type of data to form a new dataset).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z. The Applications of Deep Learning on Traffic Identification. BlackHat USA 2015, 24, 1–10. [Google Scholar]
- Höchst, J.; Baumgärtner, L.; Hollick, M.; Freisleben, B. Unsupervised Traffic Flow Classification Using a Neural Autoencoder. In Proceedings of the 2017 IEEE 42nd Conference on Local Computer Networks (LCN), Singapore, 9–12 October 2017; pp. 523–526. [Google Scholar]
- Li, R.; Xiao, X.; Ni, S.; Zheng, H.; Xia, S. Byte Segment Neural Network for Network Traffic Classification. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–10. [Google Scholar]
- Marín, G.; Casas, P.; Capdehourat, G. Deep in the Dark—Deep Learning-Based Malware Traffic Detection without Expert Knowledge. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 23 May 2019; pp. 34–42. [Google Scholar]
- Pacheco, F.; Exposito, E.; Gineste, M. A framework to classify heterogeneous Internet traffic with Machine Learning and Deep Learning techniques for satellite communications. Comput. Netw. 2020, 173, 107213. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Toward effective mobile encrypted traffic classification through deep learning. Neurocomputing 2020, 409, 306–315. [Google Scholar] [CrossRef]
- Hu, X.; Gu, C.; Wei, F. CLD-Net: A Network Combining CNN and LSTM for Internet Encrypted Traffic Classification. Secur. Commun. Netw. 2021, 2021, 5518460. [Google Scholar] [CrossRef]
- Lashkari, A.; Draper-Gil, G.; Mamun, M.; Ghorbani, A. Characterization of Encrypted and VPN Traffic Using Time-Related Features. In Proceedings of the International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016. [Google Scholar]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 297–315. [Google Scholar] [CrossRef]
- Taheri, S.; Salem, M.; Yuan, J. Leveraging Image Representation of Network Traffic Data and Transfer Learning in Botnet Detection. Big Data Cogn. Comput. 2018, 2, 37. [Google Scholar] [CrossRef] [Green Version]
- Garcia, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. J. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- Sun, G.; Liang, L.; Chen, T.; Xiao, F.; Lang, F. Network traffic classification based on transfer learning. Comput. Electr. Eng. 2018, 69, 920–927. [Google Scholar] [CrossRef]
- Liu, X.; You, J.; Wu, Y.; Li, T.; Li, L.; Zhang, Z.; Ge, J. Attention-based bidirectional GRU networks for efficient HTTPS traffic classification. J. Inf. Sci. Eng. 2020, 541, 297–315. [Google Scholar] [CrossRef]
- Hu, X.; Gu, C.; Chen, Y.; Wei, F. tCLD-Net: A Transfer Learning Internet Encrypted Traffic Classification Scheme Based on Convolution Neural Network and Long Short-Term Memory Network. In Proceedings of the 2021 International Conference on Communications, Computing, Cybersecurity, and Informatics (CCCI), Beijing, China, 15–17 October 2021; pp. 1–5. [Google Scholar]
- Wang, C.; Dani, J.; Li, X.; Jia, X.; Wang, B. Adaptive Fingerprinting: Website Fingerprinting over Few Encrypted Traffic. In Proceedings of the 11th ACM Conference on Data and Application Security and Privacy, Virtual Event, 26–28 April 2021. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar]
- Sirinam, P.; Mathews, N.; Rahman, M.; Wright, M. Triplet Fingerprinting: More Practical and Portable Website Fingerprinting with N-shot Learning. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Bikmukhamedo, R.; Nadeev, A. Generative transformer framework for network traffic generation and classification. T-Comm-Telecommun. Transp. 2020, 14, 11. [Google Scholar] [CrossRef]
- Wang, H.; Li, W. DDosTC: A Transformer-Based Network Attack Detection Hybrid Mechanism in SDN. Sensors 2021, 21, 5047. [Google Scholar] [CrossRef] [PubMed]
- Sharafaldin, I.; Lashkari, A.; Hakak, S.; Ghorbani, A. Developing Realistic Distributed Denial of Service (DDoS) Attack Dataset and Taxonomy. In Proceedings of the IEEE 53rd International Carnahan Conference on Security Technology, Chennai, India, 1–3 October 2019. [Google Scholar]
- Kozik, R.; Pawlicki, M.; Choraś, M. A new method of hybrid time window embedding with transformer-based traffic data classification in IoT-networked environment. Pattern Anal. Appl. 2021, 24, 1441–1449. [Google Scholar] [CrossRef]
- Garcia, S.; Parmisano, A.; Erquiaga, M. IoT-23: A labeled dataset with malicious and benign IoT network traffic (Version 1.0.0) [Data set]. Zenodo 2020. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- He, H.; Yang, Z.; Chen, X. PERT: Payload Encoding Representation from Transformer for Encrypted Traffic Classification. In Proceedings of the 2020 ITU Kaleidoscope: Industry-Driven Digital Transformation (ITU K), Online, 7–11 December 2020; pp. 1–8. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encrypted Application Traffic Classes | VPN | vpn-facebook-chat | |
| vpn-facebook-audio | |||
| Skype | vpn-skype-chat | ||
| vpn-skype-file | |||
| nonVPN | facebook-chat | ||
| facebook-audio | |||
| Skype | skype-chat | ||
| skype-file |
| Models | 4-Layer BERT | 6-Layer BERT | 8-Layer BERT | 10-Layer BERT | 12-Layer BERT | |
|---|---|---|---|---|---|---|
| Metrics | ||||||
| Accuracy | 0.8163 | 0.82 | 0.8388 | 0.8263 | 0.7788 | |
| macro-F1-score | 0.8147 | 0.8197 | 0.8397 | 0.8242 | 0.7793 | |
| macro-Precision | 0.8161 | 0.8225 | 0.8449 | 0.8321 | 0.7924 | |
| macro-Recall | 0.8150 | 0.8192 | 0.8381 | 0.8239 | 0.7769 | |
| Epochs | 40 | 100 | 200 | 400 | 800 | |
|---|---|---|---|---|---|---|
| Metrics | ||||||
| Accuracy | 0.8062 | 0.8175 | 0.8388 | 0.8338 | 0.8163 | |
| macro-F1-score | 0.8042 | 0.8160 | 0.8397 | 0.8341 | 0.8146 | |
| macro-Precision | 0.8127 | 0.8184 | 0.8449 | 0.8370 | 0.8170 | |
| macro-Recall | 0.8053 | 0.8161 | 0.8381 | 0.8335 | 0.8149 | |
| Models | CBD | EBD | |
|---|---|---|---|
| Metrics | |||
| Accuracy | 0.8388 | 0.5462 | |
| macro-F1-score | 0.8397 | 0.5372 | |
| macro-Precision | 0.8449 | 0.5693 | |
| macro-Recall | 0.8381 | 0.5512 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Gu, C.; Chen, Y.; Wei, F. CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method. Sensors 2021, 21, 8231. https://doi.org/10.3390/s21248231
Hu X, Gu C, Chen Y, Wei F. CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method. Sensors. 2021; 21(24):8231. https://doi.org/10.3390/s21248231
Chicago/Turabian StyleHu, Xinyi, Chunxiang Gu, Yihang Chen, and Fushan Wei. 2021. "CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method" Sensors 21, no. 24: 8231. https://doi.org/10.3390/s21248231
APA StyleHu, X., Gu, C., Chen, Y., & Wei, F. (2021). CBD: A Deep-Learning-Based Scheme for Encrypted Traffic Classification with a General Pre-Training Method. Sensors, 21(24), 8231. https://doi.org/10.3390/s21248231