
Visual Attention and Color Cues for 6D Pose Estimation on Occluded Scenarios Using RGB-D Data


Abstract
:1. Introduction
2. Method
2.1. The Point Pair Features Voting Approach
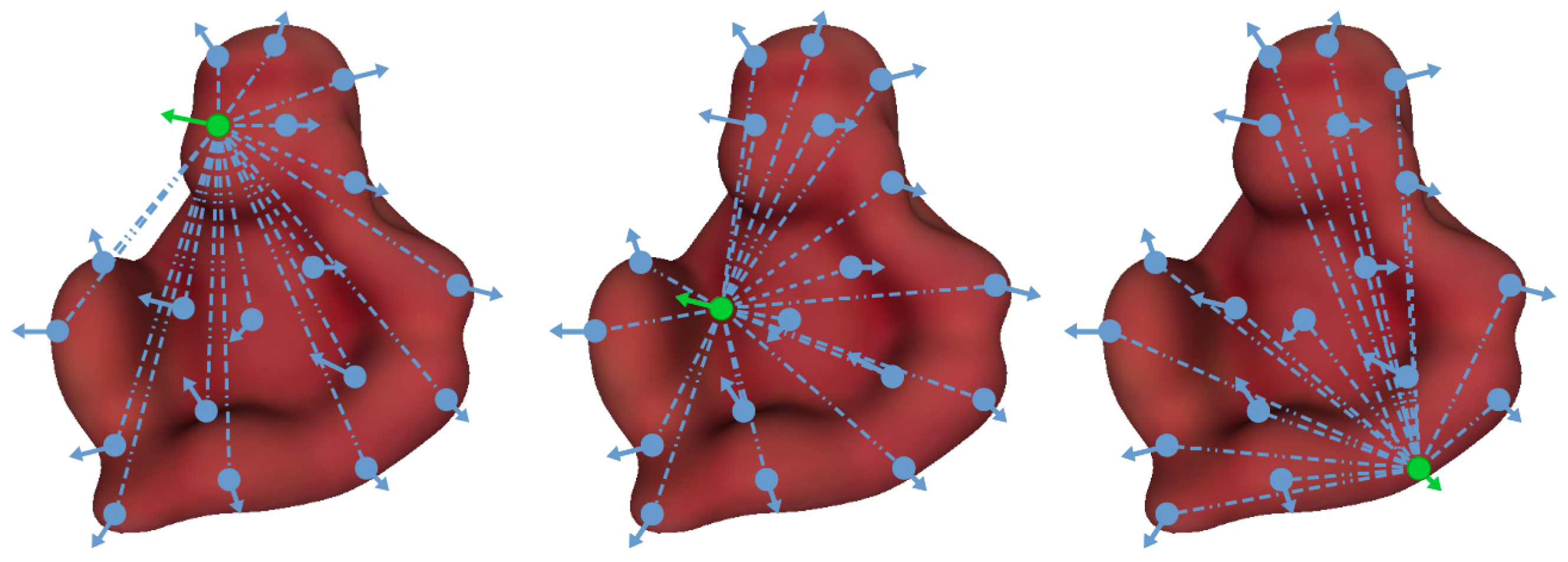
2.2. Attention-Based Matching Using Color Cues
2.3. Color-Weighted PPF Matching
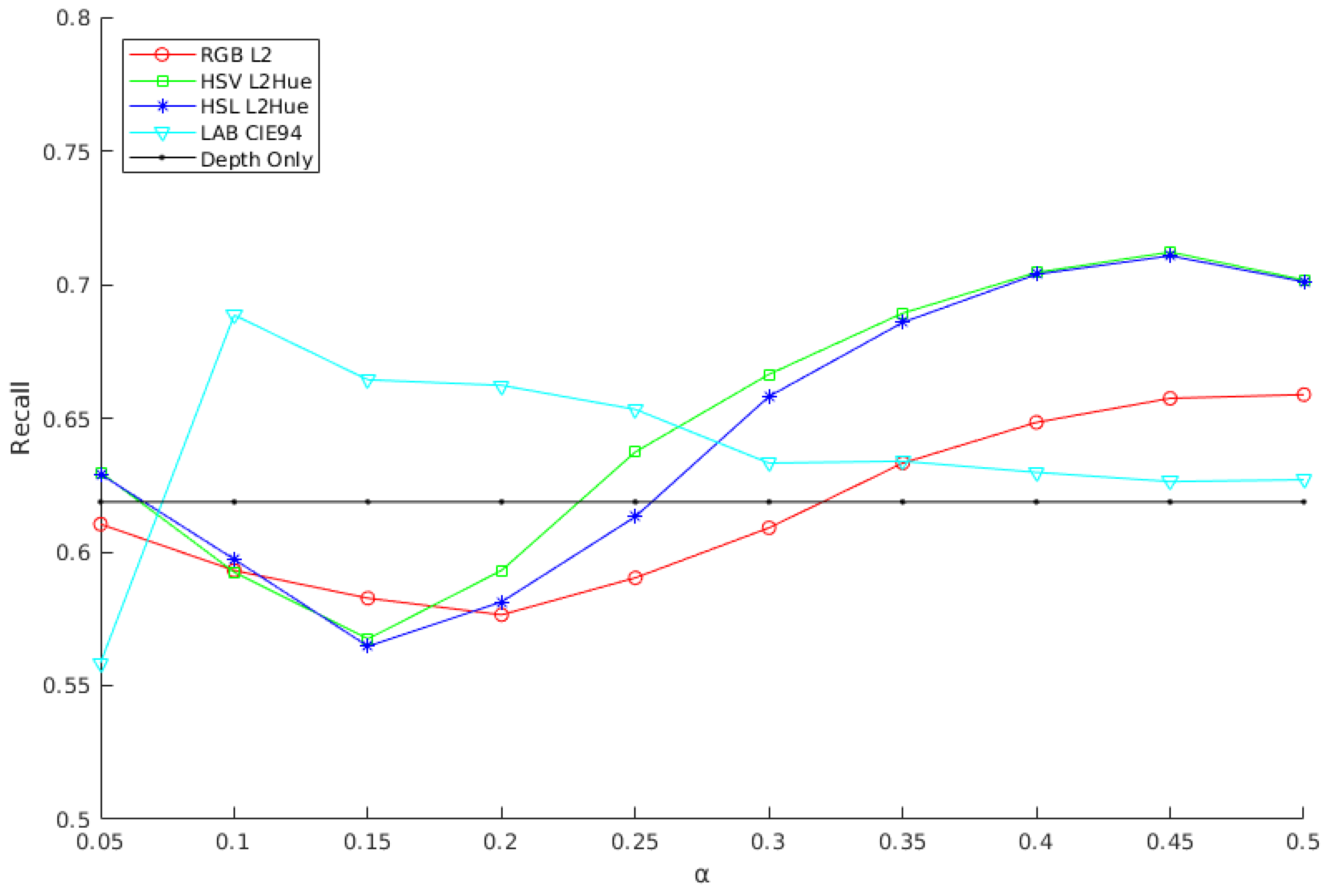
2.4. Color Models and Distance
2.5. Precomputing Color Weights
3. Results
3.1. Datasets and Evaluation Metric
3.2. LM-O: Performance and Parameter Configuration
3.3. LM-O: State-of-the-Art Comparison
3.4. TUD-L: Robustness under Illumination Changes
3.5. IC-MI/IC-BIN: Performance on Multiple Instances
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Buchholz, D. Bin-Picking—5 Decades of Research. In Bin-Picking. Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2016; Volume 44, pp. 3–12. [Google Scholar]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1530–1538. [Google Scholar]
- Liu, H.; Cong, Y.; Yang, C.; Tang, Y. Efficient 3D object recognition via geometric information preservation. Pattern Recognit. 2019, 92, 135–145. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Marton, Z.C.; Durner, M.; Triebel, R. Augmented autoencoders: Implicit 3D orientation learning for 6D object detection. Int. J. Comput. Vis. 2020, 128, 714–729. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, Z.; Zhang, H. Out-of-region keypoint localization for 6D pose estimation. Image Vis. Comput. 2020, 93, 103854. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D Object Recognition in Cluttered Scenes with Local Surface Features: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar] [CrossRef] [PubMed]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the Viewpoint Feature Histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique Signatures of Histograms for Local Surface Description. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 356–369. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Zhao, H.; Tang, M.; Ding, H. HoPPF: A novel local surface descriptor for 3D object recognition. Pattern Recognit. 2020, 103, 107272. [Google Scholar] [CrossRef]
- Guo, J.; Xing, X.; Quan, W.; Yan, D.M.; Gu, Q.; Liu, Y.; Zhang, X. Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud. IEEE Trans. Image Process. 2021, 30, 5072–5084. [Google Scholar] [CrossRef]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3D object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Karon Beach, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [Green Version]
- Kehl, W.; Milletari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep Learning of Local RGB-D Patches for 3DObject Detection and 6D Pose Estimation. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 205–220. [Google Scholar]
- Tong, X.; Li, R.; Ge, L.; Zhao, L.; Wang, K. A New Edge Patch with Rotation Invariance for Object Detection and Pose Estimation. Sensors 2020, 20, 887. [Google Scholar] [CrossRef] [Green Version]
- Tejani, A.; Tang, D.; Kouskouridas, R.; Kim, T.K. Latent-Class Hough Forests for 3D Object Detection and Pose Estimation. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 462–477. [Google Scholar]
- Hodan, T.; Michel, F.; Brachmann, E.; Kehl, W.; GlentBuch, A.; Kraft, D.; Drost, B.; Vidal, J.; Ihrke, S.; Zabulis, X.; et al. BOP: Benchmark for 6D Object Pose Estimation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 19–35. [Google Scholar]
- Vidal, J.; Lin, C.Y.; Lladó, X.; Martí, R. A Method for 6D Pose Estimation of Free-Form Rigid Objects Using Point Pair Features on Range Data. Sensors 2018, 18, 2678. [Google Scholar] [CrossRef] [Green Version]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. In Computer Vision—ACCV 2012; Lee, K.M., Matsushita, Y., Rehg, J.M., Hu, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 548–562. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D Object Pose Estimation Using 3D Object Coordinates. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 536–551. [Google Scholar]
- Theeuwes, J. Top–down and bottom–up control of visual selection. Acta Psychol. 2010, 135, 77–99. [Google Scholar] [CrossRef] [PubMed]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Fisher, R. Object-based visual attention for computer vision. Artif. Intell. 2003, 146, 77–123. [Google Scholar] [CrossRef] [Green Version]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD Salient Object Detection via Deep Fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef]
- Potapova, E.; Zillich, M.; Vincze, M. Survey of recent advances in 3D visual attention for robotics. Int. J. Robot. Res. 2017, 36, 1159–1176. [Google Scholar] [CrossRef]
- Li, X.; Zhao, L.; Wei, L.; Yang, M.; Wu, F.; Zhuang, Y.; Ling, H.; Wang, J. DeepSaliency: Multi-Task Deep Neural Network Model for Salient Object Detection. IEEE Trans. Image Process. 2016, 25, 3919–3930. [Google Scholar] [CrossRef] [Green Version]
- Bramão, I.; Reis, A.; Petersson, K.M.; Faísca, L. The role of color information on object recognition: A review and meta-analysis. Acta Psychol. 2011, 138, 244–253. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- van de Sande, K.; Gevers, T.; Snoek, C. Evaluating Color Descriptors for Object and Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Stefano, L.D. A combined texture-shape descriptor for enhanced 3D feature matching. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 809–812. [Google Scholar]
- Wang, W.; Chen, L.; Liu, Z.; Kühnlenz, K.; Burschka, D. Textured/textureless object recognition and pose estimation using RGB-D image. J. Real Image Process. 2015, 10, 667–682. [Google Scholar] [CrossRef] [Green Version]
- Drost, B.; Ilic, S. 3D Object Detection and Localization Using Multimodal Point Pair Features. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 9–16. [Google Scholar]
- Choi, C.; Christensen, H.I. RGB-D object pose estimation in unstructured environments. Robot. Auton. Syst. 2016, 75, 595–613. [Google Scholar] [CrossRef]
- Kiforenko, L.; Drost, B.; Tombari, F.; Krüger, N.; Buch, A.G. A performance evaluation of point pair features. Comput. Vis. Image Underst. 2018, 166, 66–80. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Rajkumar, N.; Konolige, K. Going Further with Point Pair Features. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 834–848. [Google Scholar]
- Choi, C.; Christensen, H.I. 3D pose estimation of daily objects using an RGB-D camera. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 3342–3349. [Google Scholar]
- Plataniotis, K.N.; Venetsanopoulos, A.N. Color Image Processing and Applications; Springer Science & Business Media: Cham, Switzerland, 2013. [Google Scholar]
- McDonald, R.; Roderick, E. Colour Physics for Industry; Society of Dyers and Colourists: Bradford, UK, 1987. [Google Scholar]
- Doumanoglou, A.; Kouskouridas, R.; Malassiotis, S.; Kim, T.K. Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mercier, J.P.; Mitash, C.; Giguère, P.; Boularias, A. Learning Object Localization and 6D Pose Estimation from Simulation and Weakly Labeled Real Images. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3500–3506. [Google Scholar]
- Mitash, C.; Boularias, A.; Bekris, K. Physics-based scene-level reasoning for object pose estimation in clutter. Int. J. Robot. Res. 2019. [Google Scholar] [CrossRef]
- Vidal, J.; Lin, C.; Martí, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 23–26 April 2018; pp. 405–409. [Google Scholar]
- MVTec HALCON. Available online: https://www.mvtec.com/halcon/ (accessed on 5 November 2021).
- Brachmann, E.; Michel, F.; Krull, A.; Yang, M.Y.; Gumhold, S.; Rother, C. Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3364–3372. [Google Scholar]
- Hodaň, T.; Zabulis, X.; Lourakis, M.; Obdržálek, Š.; Matas, J. Detection and fine 3D pose estimation of texture-less objects in RGB-D images. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4421–4428. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 1 | 5 | 6 | 8 | 9 | 10 | 11 | 12 | Avg. | Stdev | All |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours - HSV | 69 | 89 | 56 | 89 | 84 | 50 | 50 | 73 | 70 | 17 | 71 |
| Tong-20 [17] | 60 | 75 | 47 | 80 | 71 | 35 | 55 | 74 | 62 | 16 | - |
| Vidal-18b [20] | 66 | 84 | 48 | 76 | 72 | 43 | 34 | 62 | 61 | 17 | 62 |
| Mercier-MS-ICP-19 [42] | - | - | - | - | - | - | - | - | - | - | 62 |
| SL-MCTS-19 [43] | 50 | 71 | 43 | 68 | 72 | 46 | 33 | 66 | 57 | 15 | 60 |
| Vidal-18a [44] | 66 | 81 | 46 | 65 | 73 | 43 | 26 | 64 | 58 | 18 | 59 |
| MCTS-19 [43] | 48 | 59 | 35 | 78 | 71 | 48 | 32 | 65 | 55 | 17 | 58 |
| Drost-10-edge [45] | 47 | 82 | 46 | 75 | 42 | 44 | 36 | 57 | 54 | 17 | 55 |
| Drost-10 [11,45] | 62 | 75 | 39 | 70 | 57 | 46 | 26 | 57 | 54 | 16 | 55 |
| Mercier-MS-19 [42] | - | - | - | - | - | - | - | - | - | - | 55 |
| Brachmann-16 [46] | 64 | 65 | 44 | 68 | 71 | 3 | 32 | 61 | 51 | 24 | 52 |
| Hodan-15 [47] | 54 | 66 | 40 | 26 | 73 | 37 | 44 | 68 | 51 | 17 | 51 |
| Method | 1 | 2 | 3 | Avg. | Stdev |
|---|---|---|---|---|---|
| Ours - HSV | 92 | 94 | 91 | 92 | 2 |
| Vidal-18b [20] | 88 | 93 | 92 | 91 | 3 |
| Vidal-18a [44] | 79 | 88 | 74 | 80 | 7 |
| Drost-10-edge [45] | 85 | 88 | 90 | 87 | 3 |
| Drost-10 [11,45] | 73 | 90 | 74 | 79 | 10 |
| Brachmann-16 [46] | 81 | 95 | 91 | 89 | 7 |
| Hodan-15 [47] | 27 | 63 | 48 | 46 | 18 |
| Method | 1 | 2 | 3 | 4 | 5 | 6 | Avg. | Stdev |
|---|---|---|---|---|---|---|---|---|
| Ours - HSV | 98 | 100 | 100 | 100 | 100 | 98 | 99.3 | 1.0 |
| Vidal-18b [20] | 94 | 100 | 100 | 100 | 100 | 98 | 98.7 | 2.4 |
| Vidal-18a [44] | 80 | 100 | 100 | 98 | 100 | 94 | 95.3 | 7.9 |
| Hodan-15 [47] | 100 | 100 | 100 | 74 | 98 | 100 | 95.3 | 10.5 |
| Drost-10 [11,45] | 76 | 100 | 98 | 100 | 96 | 96 | 94.3 | 9.2 |
| Drost-10-edge [45] | 78 | 100 | 100 | 100 | 90 | 96 | 94.0 | 8.8 |
| Brachmann-16 [46] | 42 | 98 | 70 | 88 | 64 | 78 | 73.3 | 19.6 |
| Method | 2 | 4 | Avg. |
|---|---|---|---|
| Ours - HSV | 100 | 95 | 97.5 |
| Vidal-18b [20] | 100 | 95 | 97.5 |
| Vidal-18a [44] | 100 | 93 | 96.5 |
| Drost-10-edge [45] | 100 | 94 | 92.0 |
| Hodan-15 [47] | 100 | 81 | 90.5 |
| Drost-10 [11,45] | 100 | 74 | 87.0 |
| Brachmann-16 [46] | 84 | 29 | 56.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vidal, J.; Lin, C.-Y.; Martí, R. Visual Attention and Color Cues for 6D Pose Estimation on Occluded Scenarios Using RGB-D Data. Sensors 2021, 21, 8090. https://doi.org/10.3390/s21238090
Vidal J, Lin C-Y, Martí R. Visual Attention and Color Cues for 6D Pose Estimation on Occluded Scenarios Using RGB-D Data. Sensors. 2021; 21(23):8090. https://doi.org/10.3390/s21238090
Chicago/Turabian StyleVidal, Joel, Chyi-Yeu Lin, and Robert Martí. 2021. "Visual Attention and Color Cues for 6D Pose Estimation on Occluded Scenarios Using RGB-D Data" Sensors 21, no. 23: 8090. https://doi.org/10.3390/s21238090
APA StyleVidal, J., Lin, C.-Y., & Martí, R. (2021). Visual Attention and Color Cues for 6D Pose Estimation on Occluded Scenarios Using RGB-D Data. Sensors, 21(23), 8090. https://doi.org/10.3390/s21238090