
Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning




Abstract
:1. Introduction
- (1)
- A more lightweight network model is designed. The model can find a better balance between precision and memory consumption. For example, the MobileNet model is in a new lightweight model structure [6]. VGG-16 network performance can be implemented with a 10-fold decrease in the calculated quantity.
- (2)
- Software optimization techniques and mathematical methods are used to trim the network, so as to reduce the network calculation and memory requirements. For example, He Yang’s team reduced the calculation amount of ILSVRC-2012 by over 40% on ResNet-50 through progressive soft-filtering pruning, with 0.14% reduced accuracy [7].
- (3)
- An hardware accelerator customized for deep learning algorithm or FPGA is used to perform the high-concurrent operations and complete the acceleration process. For example, Kang’s team won the first prize of the LPIRC competition through optimization algorithm using NVidia TX2 [8]; Ma’s team increased the reasoning speed of tiny-yolo to 20 frames using FPGA [9,10].
- (1)
- Deep learning is applied to the kitchen target detection to realize the detection of whether the workers entering the kitchen are wearing kitchen overalls. In addition, the whole system is finally deployed on low-power embedded products, which greatly reduces the cost of equipment and power consumption required for traditional deep learning target detection, so that deep learning can be applied to more use case scenarios.
- (2)
- This paper introduces the idea of software pipelining in deep learning to transform the network reasoning process from single tasks implemented step by step to different stages of multiple tasks, and thus greatly improve the utilization rate of hardware resources and the recognition speed of the system.
- (3)
- Speed matching between the anterior and posterior networks is achieved through unbalanced segmentation of the model and multithreaded optimization [13]. After the introduction of the circle buffer, it can ensure the error of a single task does not affect other tasks.
- (4)
- The goal of this scheme is to complete the intelligent processing of video data on the “edge side”. The videos of multiple cameras on the local switch can be detected through the embedded reasoning card to recognize whether the chefs correctly wear the overalls. The upper computer can display the recognition results, and set the recognition rate of the card, the threshold and the number of cameras.
2. System Scheme
2.1. Scheme Introduction
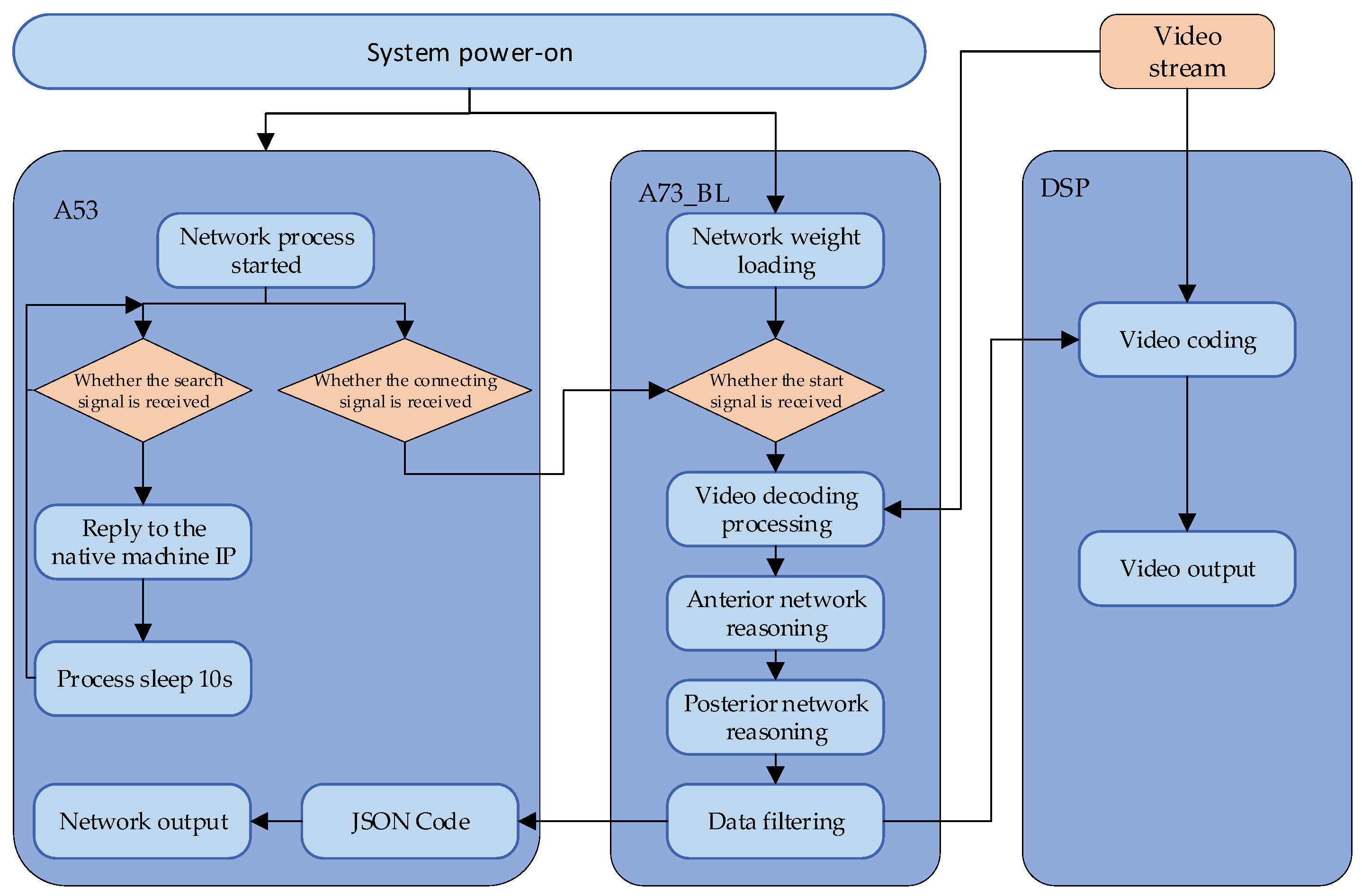
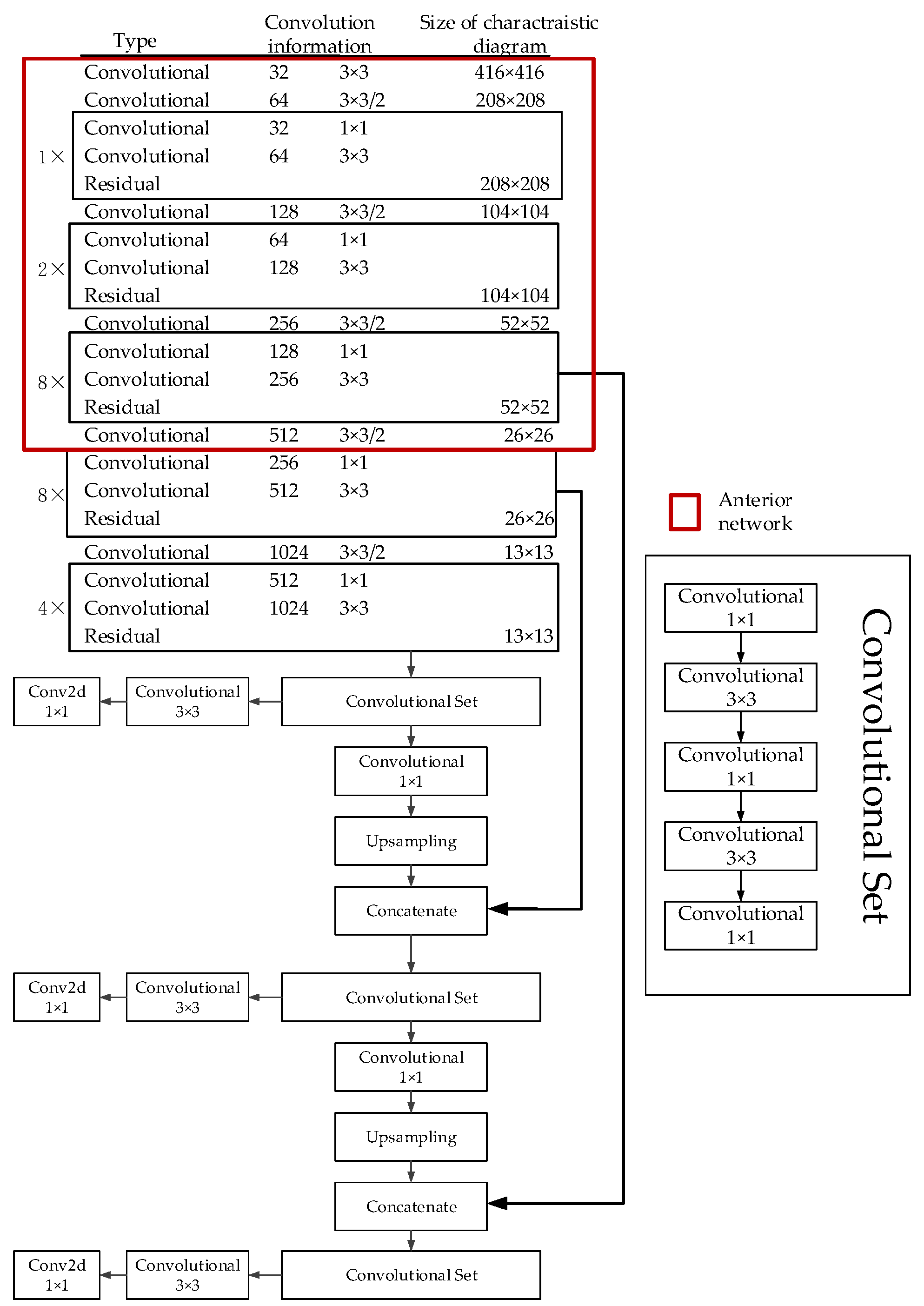
2.2. Embedded Deployment Scheme
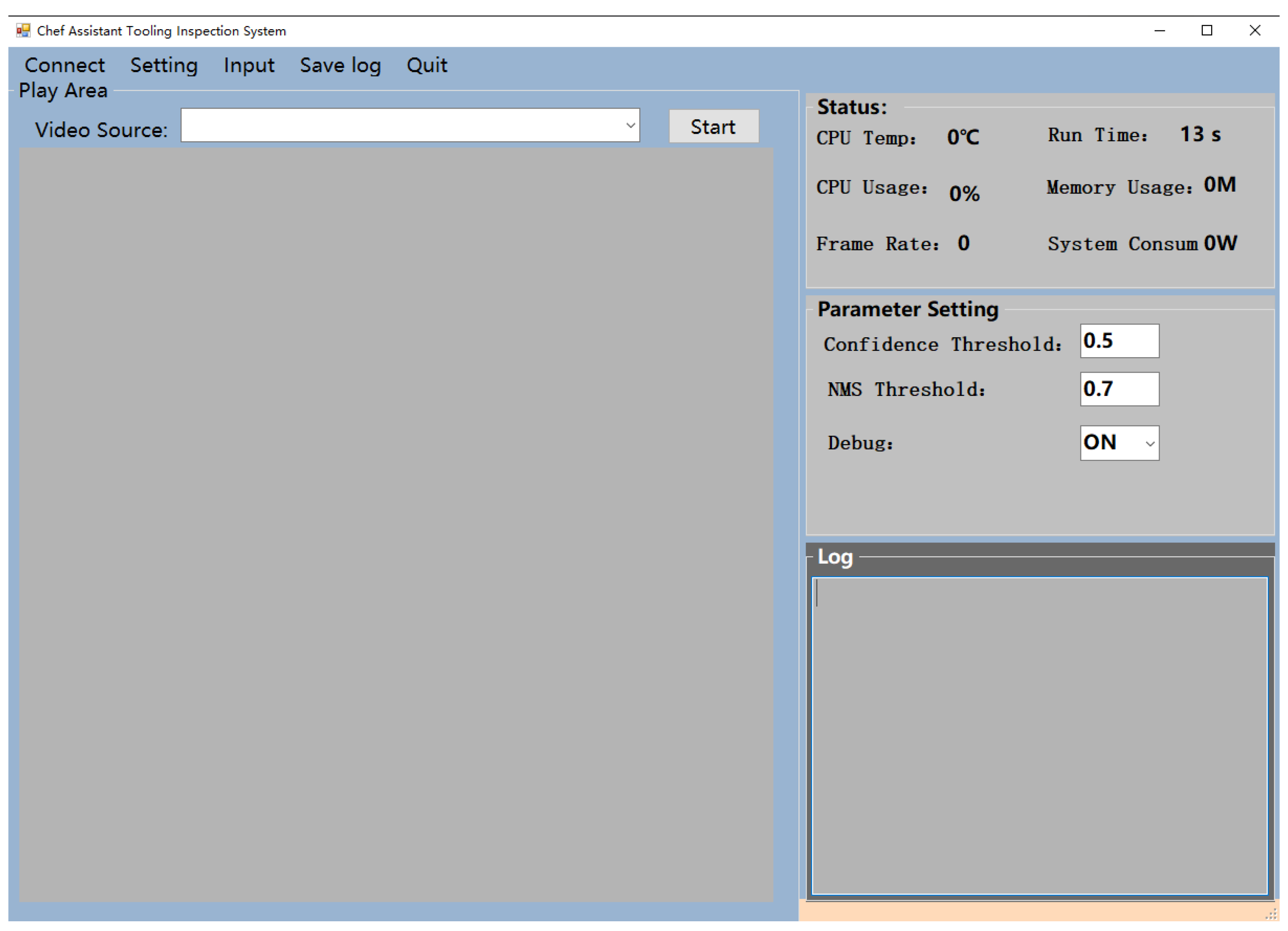
2.3. Interface of Console Software
3. Core Acceleration Method
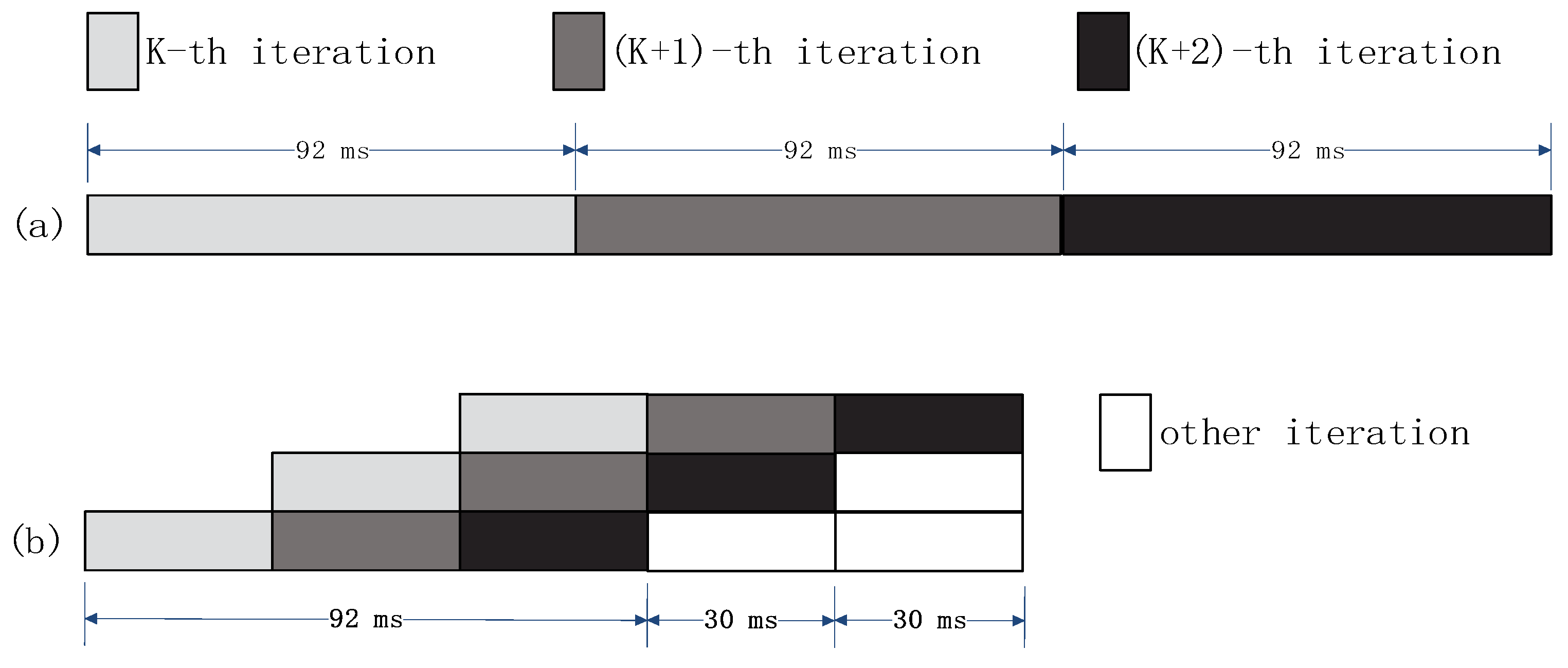
3.1. Introduction of Pipelining Technology
- (1)
- It greatly improves the utilization rate of hardware resources, and realizes the parallel execution of multiple tasks of different stages at the same time;
- (2)
- Although pipelining operates multiple network data at the same time, the network only needs to load once, which greatly reduces the memory occupation compared with traditional multi-operators. This is very important for embedded devices;
- (3)
- Pipelining with a buffer zone can effectively reduce the processor’s idle time through reasonable task distribution, without additional multi-process time consumption;
- (4)
- Pipelining is more conducive to protecting the relationship between frames before and after pictures. The order of data processed is synchronized, without additional thread synchronization tools.
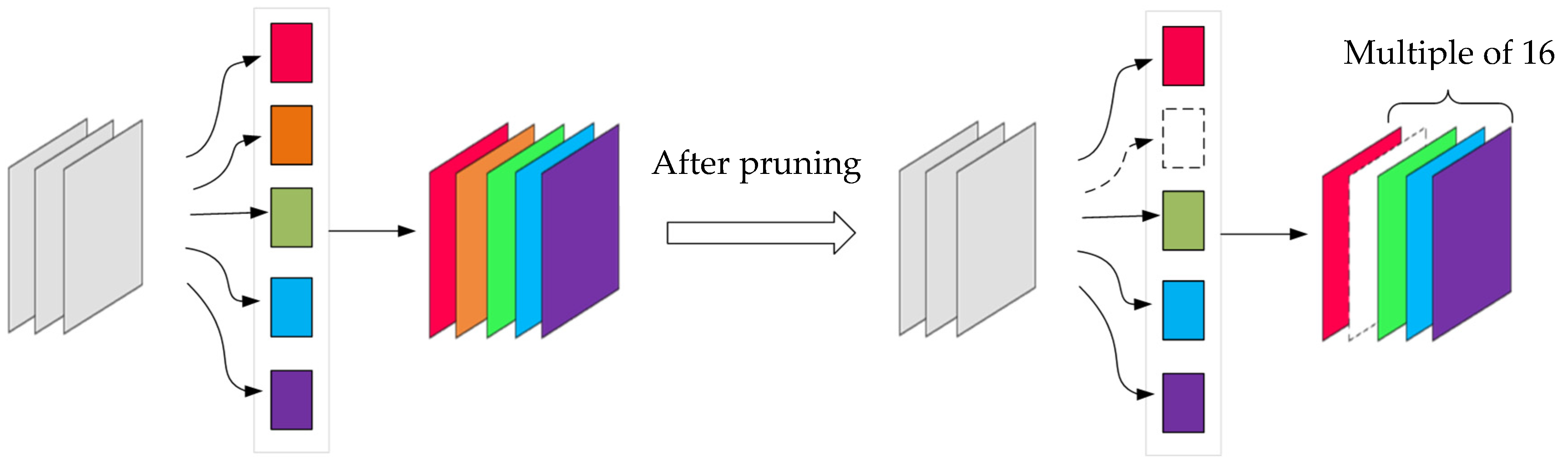
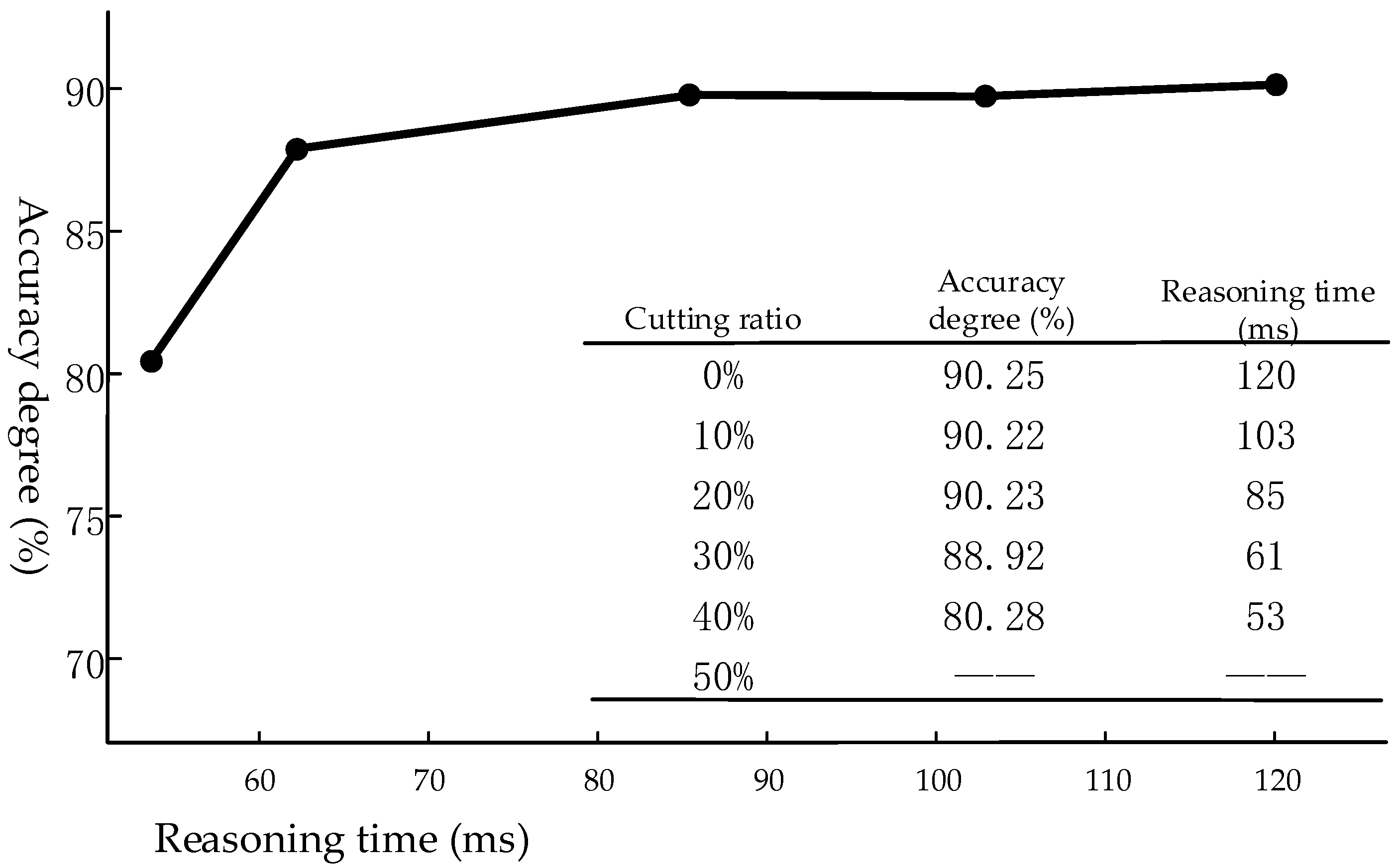
3.2. Network Cutting
3.3. Model Segmentation and Quantization
3.4. Fixed-Point Data Flow
| Algorithm 1 Data filtering and calculation |
| 1: tensor parseYolov3Feature(Tensor features, conf_threshold) 2: conf_threshold = anti_sigmoid(conf_threshold) << 12 3: for feature in features do 4: confidence = feature.data[c] 5: if (feature.confidence >= conf_threshold) then 6: (tx, ty, tw, th, tc) = feature.data[(x, y, w, h, c)] * 1.0f/4096 7: (x, y, w, h) = computers_box(tx, ty, tw, th) 8: Class_confidences[i] = feature.data[conf] * 1.0/4096 9: Softmax(class_confidences) 10: box = (class, confindences, x, y, w, h) 11: Boxes.push_back(box) 12: return Boxes |
3.5. Multithreaded Optimization
3.5.1. Shared Memory in the Critical Zone
3.5.2. Introduction of a Circle Buffer
4. Experiments
4.1. Experimental Environment Preparation
4.2. Dataset Used for the Experiment
4.3. Network Result Validation
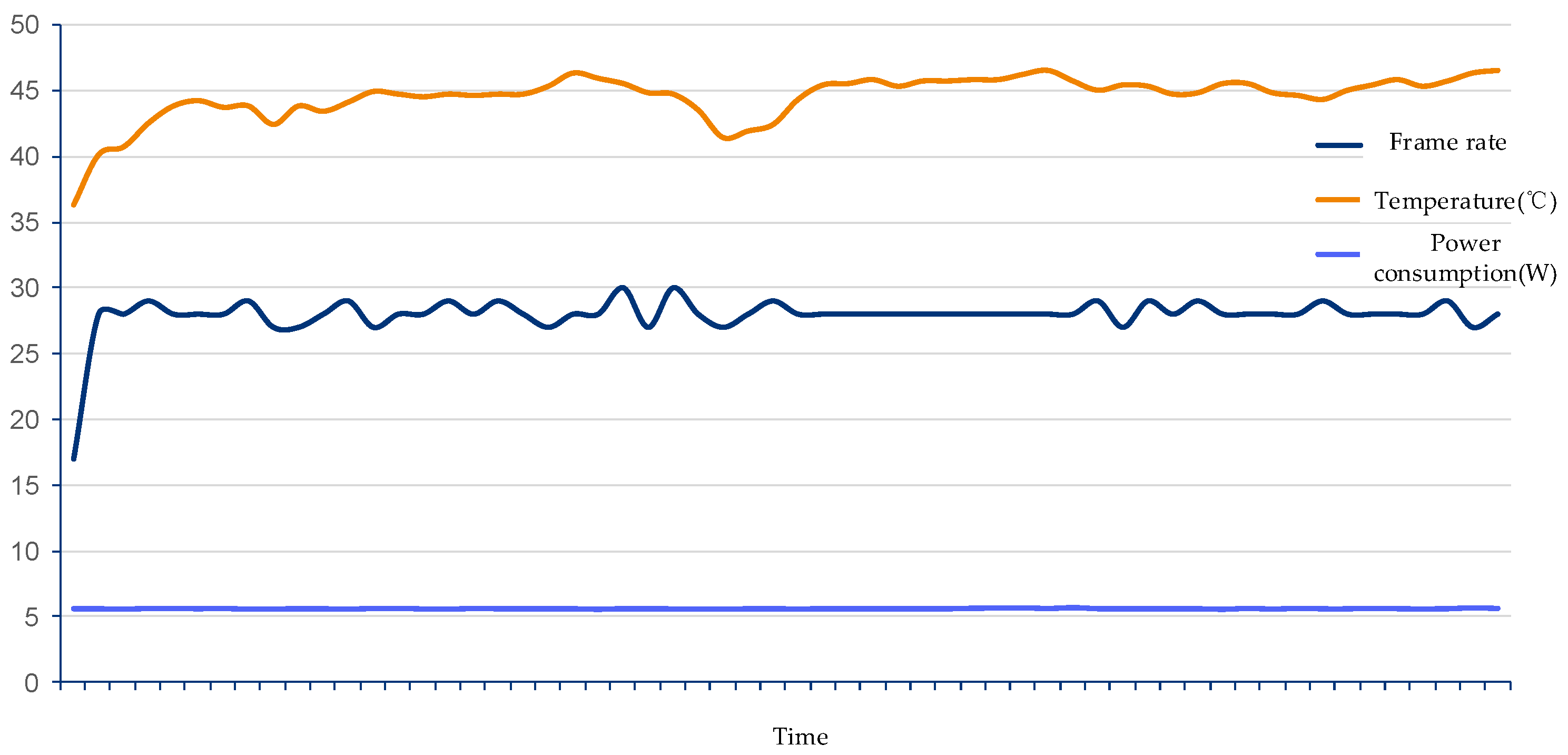
4.4. Reasoning Speed and Stability Test
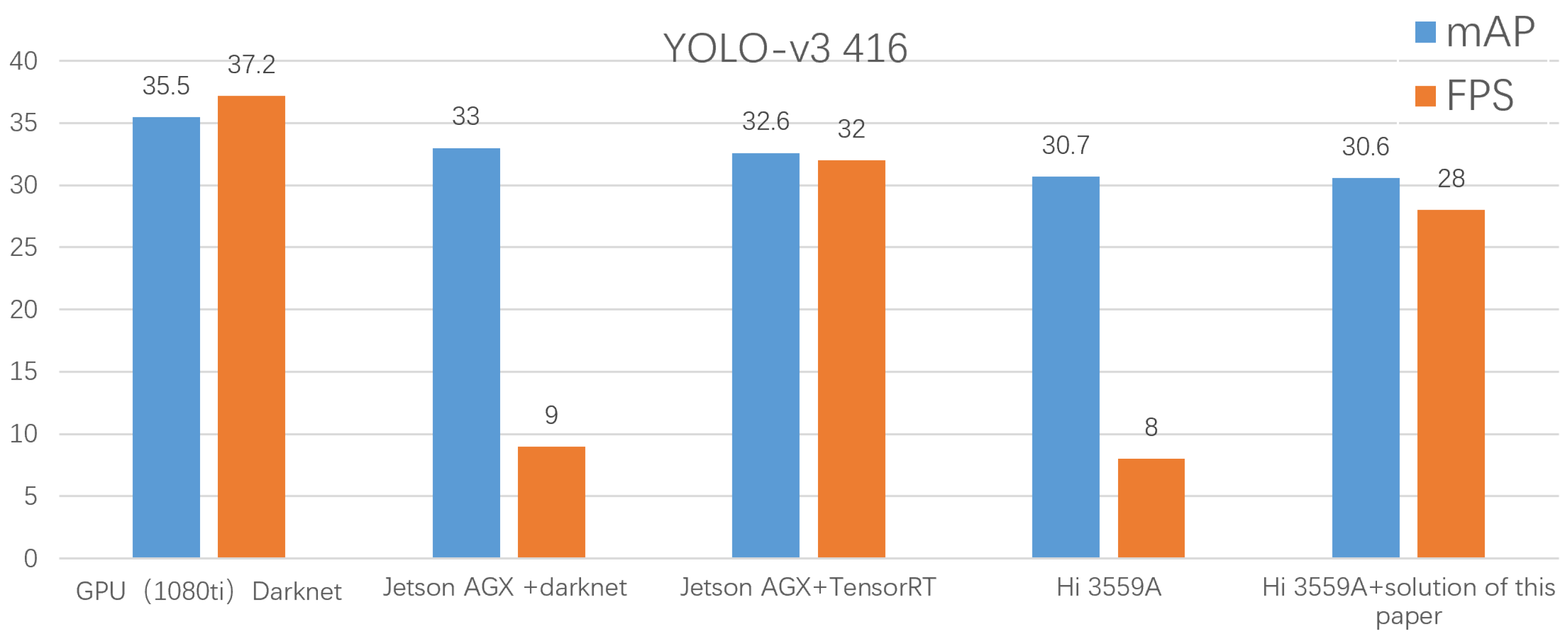
4.5. Results Comparison and Analysis
4.6. On-Site Deployment Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Food Safety. Available online: https://www.who.int/news-room/fact-sheets/detail/food-safety (accessed on 19 November 2021).
- Chen, X.Z.; Chang, C.M.; Yu, C.W.; Chen, Y.L. A Real-Time Vehicle Detection System under Various Bad Weather Conditions Based on a Deep Learning Model without Retraining. Sensors 2020, 20, 5731. [Google Scholar] [CrossRef]
- Amin, M.S.; Yasir, S.M.; Ahn, H. Recognition of Pashto Handwritten Characters Based on Deep Learning. Sensors 2020, 20, 5884. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Y.; Sheng, Q.; Chen, K.; Huang, J. A High-Robust Automatic Reading Algorithm of Pointer Meters Based on Text Detection. Sensors 2020, 20, 5946. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized Convolutional Neural Networks for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar]
- He, Y.; Dong, X.; Kang, G.; Fu, Y.; Yan, C.; Yang, Y. Asymptotic Soft Filter Pruning for Deep Convolutional Neural Networks. IEEE Trans. Cybern. 2020, 8, 11041–11051. [Google Scholar] [CrossRef] [Green Version]
- Kang, D.; Kang, D.; Kang, J.; Yoo, S.; Ha, S. Joint optimization of speed, accuracy, and energy for embedded image recognition systems. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 715–720. [Google Scholar]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A Real-Time Object Detection Method for Constrained Environments. IEEE Access 2020, 8, 1935–1944. [Google Scholar] [CrossRef]
- Ma, J.; Chen, L.; Gao, Z. Hardware implementation and optimization of tiny-YOLO network. Commun. Comput. Inf. Sci. 2018, 815, 224–234. [Google Scholar]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, M.; Chen, D.; Lee, H.; Ngiam, J.; Le, Q.; Wu, Y.; et al. GPipe: Efficient training of giant neural networks using pipeline parallelism. In Proceedings of the Vanco 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 103–112. [Google Scholar]
- Wei, H.; Yu, J.; Yu, H.; Qin, M.; Gao, G.R. Software Pipelining for Stream Programs on Resource Constrained Multicore Architectures. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 2338–2350. [Google Scholar] [CrossRef]
- Li, T.; Dong, Q.; Wang, Y.; Gong, X.; Yang, Y. Dual buffer rotation four-stage pipeline for CPU–GPU cooperative computing. Soft Comput. 2019, 23, 859–869. [Google Scholar] [CrossRef]
- Chen, W.; Wilson, J.; Tyree, S.; Weinberger, K.; Chen, Y. Compressing neural networks with the hashing trick. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2285–2294. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantification: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Cattaneo, D.; di Bello, A.; Cherubin, S.; Terraneo, F.; Agosta, G. Embedded Operating System Optimization through Floating to Fixed Point Compiler Transformation. In Proceedings of the 2018 21st Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 172–176. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. Lect. Notes Comput. Sci. 2014, 8693, 740–755. [Google Scholar]
- Mushtaq, H.; Al-Ars, Z.; Bertels, K. DetLock: Portable and Efficient Deterministic Execution for Shared Memory Multicore Systems. In Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 721–730. [Google Scholar]
- Gowanlock, M.; Blair, D.M.; Pankratius, V. Optimizing Parallel Clustering Throughput in Shared Memory. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2595–2607. [Google Scholar] [CrossRef]
- Koo, Y.; You, C.; Kim, S. OpenCL-Darknet: An OpenCL Implementation for Object Detection. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 January 2018; pp. 631–634. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Network Layers | Number of Parameters | Calculated Quantity (GFLOPS) | Reasoning Time | |
|---|---|---|---|---|
| Anterior network | 78 | 3,201,760 | 12.29 | 32~36 |
| Posterior network | 141 | 58,746,624 | 20.64 | 34~40 |
| Name | Version No. |
|---|---|
| CPU Model | Intel core i7-6850k |
| GPU model | GTX1080Ti ×3 |
| Memory capacity | 64 GB |
| System version | Ubuntu 18.04.5 LTS |
| CUDA | 9.1.85 |
| cud | 7.6.5 |
| cafe | 1.0.0 |
| Hyper-Parameter | Value |
|---|---|
| batch | 96 |
| subdivisions | 16 |
| decay | 0.0005 |
| max_batches | 62,000 |
| learning_rate | 0.001 |
| policy | Steps |
| steps | 45,000, 50,000, 55,000 |
| Deployment Scheme | Memory Consumption (MB) | Frame Rate (FPS/s) | Precision (mAP) | Overall Power Consumption of the System (W) |
|---|---|---|---|---|
| Official solutions | 81.3 | 8.9 | 50.31% | 5.0 |
| Double-threaded synchronization | 166.1 | 17.5 | 50.6% | 5.5 |
| Queuing scheme | 83.4 | 27.6 | 50.8% | 5.5 |
| Server deployment (Titan-X) | 250 | 32 | 51.2% | —— |
| Camera No. | Identification Error (pcs) | Mislabeling | False Detection | Missed Detection | Accuracy Rate |
|---|---|---|---|---|---|
| SXSZBG006 | 0 | 0 | 0 | 0 | 100.00% |
| SXSZBG10 | 0 | 0 | 0 | 41 | 95.90% |
| SXSZBLDJD001 | 0 | 0 | 0 | 0 | 100.00% |
| SXSMHGJD004 | 0 | 0 | 0 | 19 | 98.10% |
| SXXHDJD003 | 0 | 0 | 0 | 23 | 97.70% |
| SXSZGXDJD001 | 4 | 0 | 0 | 0 | 99.60% |
| SXKYMD004 | 0 | 0 | 0 | 11 | 98.90% |
| SXKJJD002 | 8 | 0 | 0 | 9 | 98.30% |
| SXSZYHBG003 | 9 | 0 | 0 | 21 | 97.00% |
| HZCZZX001 | 0 | 0 | 0 | 26 | 97.40% |
| Total | 21 | 0 | 0 | 150 | 98.29% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, Q.; Sheng, H.; Gao, P.; Li, Z.; Yin, H. Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning. Sensors 2021, 21, 8069. https://doi.org/10.3390/s21238069
Sheng Q, Sheng H, Gao P, Li Z, Yin H. Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning. Sensors. 2021; 21(23):8069. https://doi.org/10.3390/s21238069
Chicago/Turabian StyleSheng, Qinghua, Haixiang Sheng, Peng Gao, Zhu Li, and Haibing Yin. 2021. "Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning" Sensors 21, no. 23: 8069. https://doi.org/10.3390/s21238069
APA StyleSheng, Q., Sheng, H., Gao, P., Li, Z., & Yin, H. (2021). Real-Time Detection of Cook Assistant Overalls Based on Embedded Reasoning. Sensors, 21(23), 8069. https://doi.org/10.3390/s21238069