
Research on Efficient Reinforcement Learning for Adaptive Frequency-Agility Radar

Abstract
:1. Introduction
2. Reinforcement Learning Modeling Based on Radar System
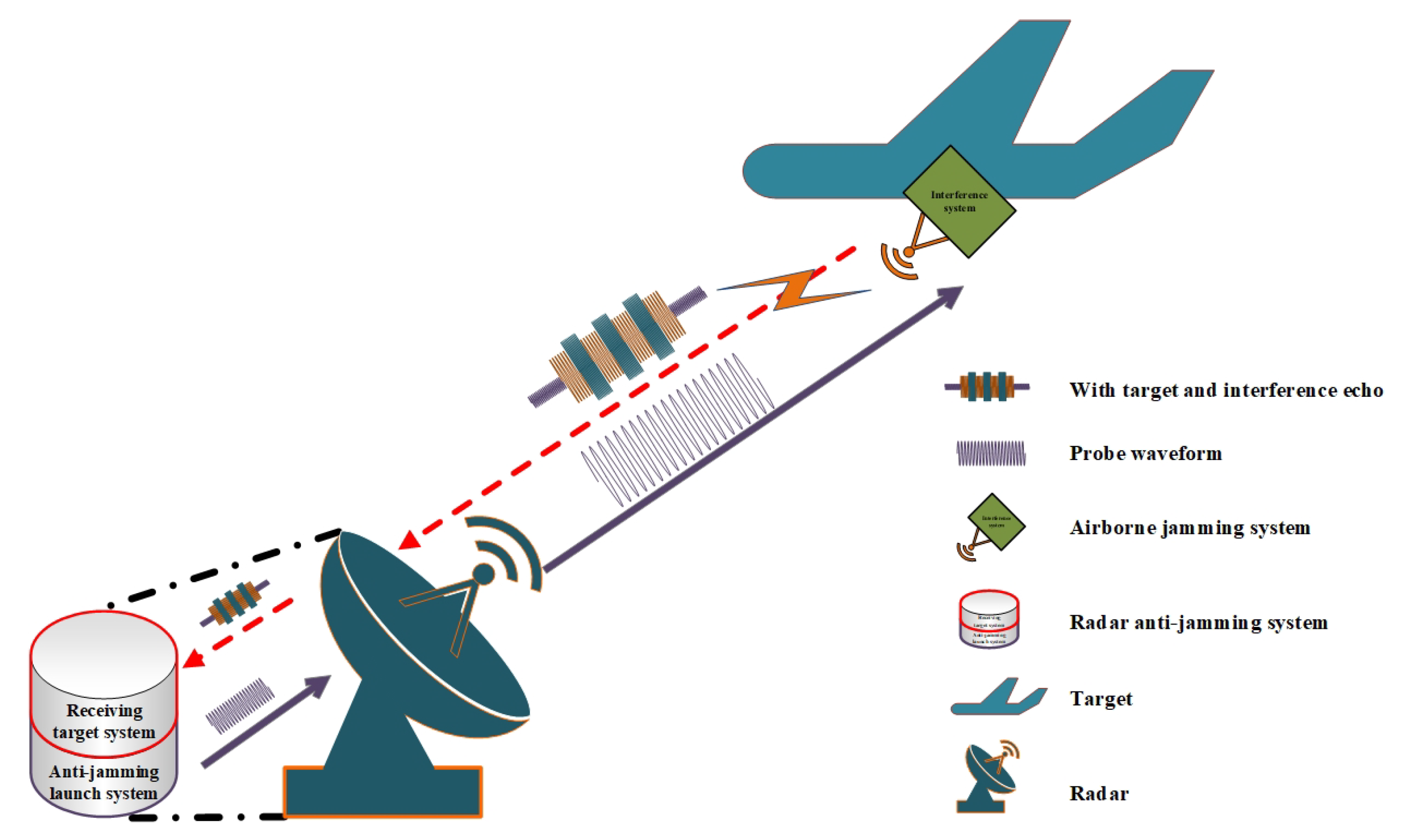
2.1. Radar Countermeasure System Model
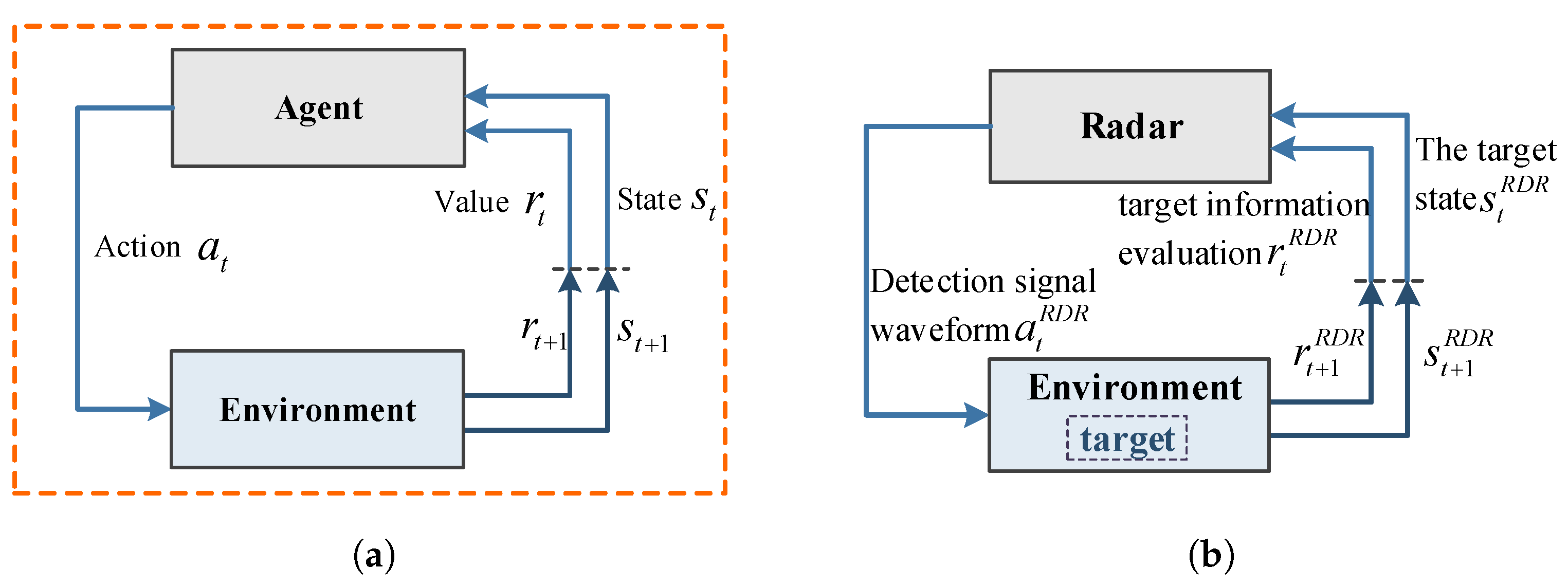
2.2. Reinforcement Learning Model for Single Radar System
2.3. Reinforcement Learning Modeling for Radar-Jammer System
2.4. Markov Game Inference Applicable to Radar-Jammer System Environment
- 2 refers to the number of agents in the radar-jammer system, including the radar and the jammer;
- s = {} indicates the joint state of the radar-jammer system model, indicates the current state of the radar side, and indicates the state of the jammer;
- represents the action set of the radar, and represents the action set of the jammer;
- T represents the transfer function, which represents the probability of the radar side taking action and the jammer taking action under the current state and then transferring to the next state;
- represents the reward function of radar; represents the reward function of jammer. Among them, the radar side and the jammer side have independent reward function R. Different agents can switch from the same state to different rewards.
3. An Improved RL Framework for Radar-Jammer System
3.1. Improved RL Framework
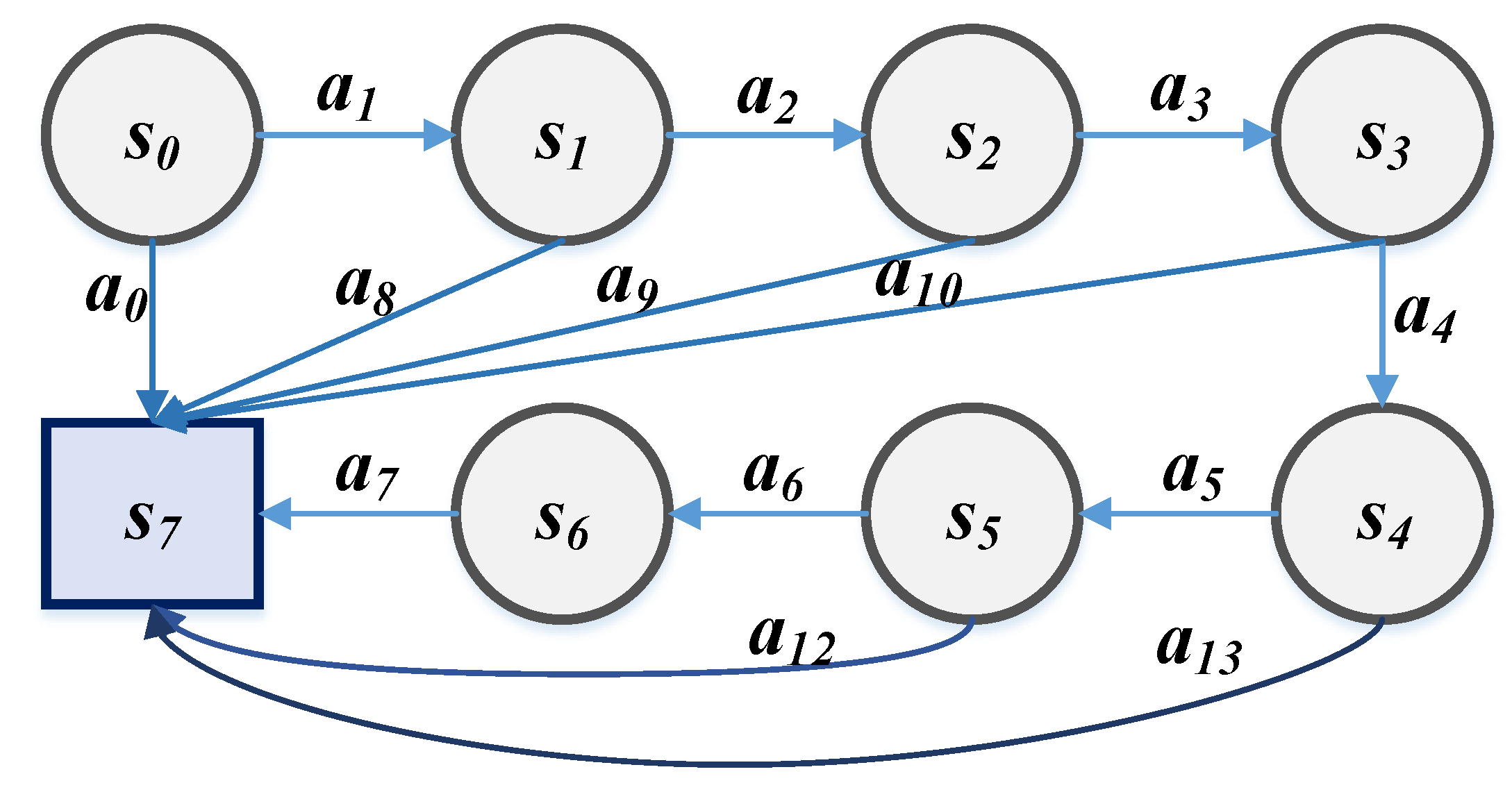
3.2. Bellman Equation in Frequency-Agility Scenario
4. Experiments
4.1. Setup
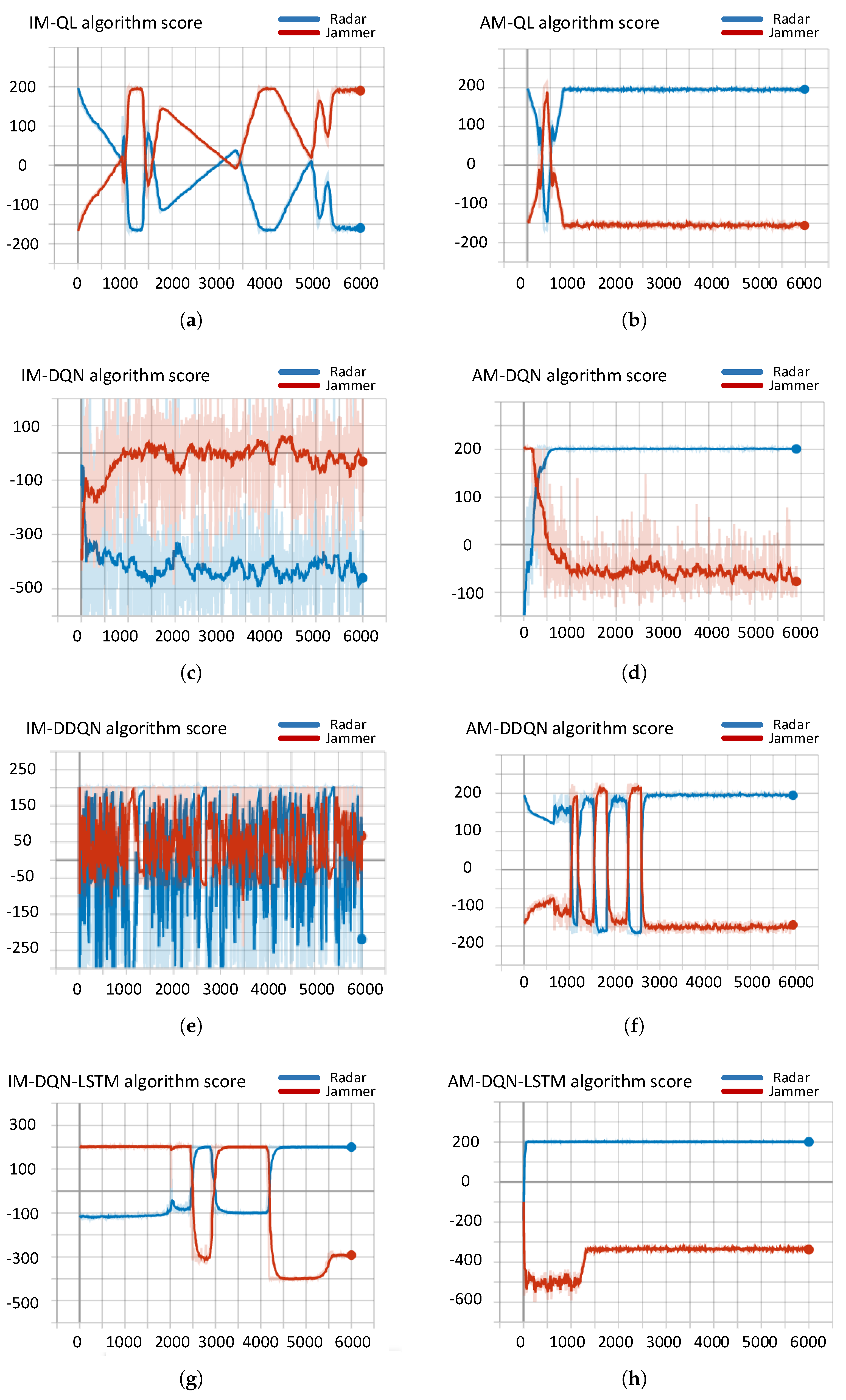
- QL (Q-learning) [18]: Q-learning (QL) is a classic reinforcement learning algorithm, which can efficiently uses guided experience replay sampling to update the strategy, and selects the action that can get the most benefit based on the Q value.
- DQN (deep Q-network) [21]: Deep Q-learning replaces the regular Q-table with a neural network. Rather than mapping a state-action pair to a q-value, a neural network maps input states to (action, Q-value) pairs. DQN algorithm relies on limited discrete empirical data storage memory and complete observation information, effectively solving the “dimension disaster” of reinforcement learning.
- DDQN (double deep Q-network) [24]: DDQN is an optimization of the DQN algorithm, using two independent Q-value estimators, each of which is used to update the other. Using these independent estimators, an unbiased Q-value estimation can be performed on actions selected using the opposite estimator. Therefore, the update can be separated from the biased estimate in this way to avoid maximizing bias.
- DQN+LSTM (deep Q-network + long-short term memory) [25]: DQN+LSTM is proposed to solve two problems of DQN: (1) The memory for storing empirical data is limited. (2) Need complete observation information. DQN+LSTM replaces the fully connected layer in DQN with an LSTM network. In the case of changes in observation quality, it has stronger adaptability.
4.2. Results and Analyss
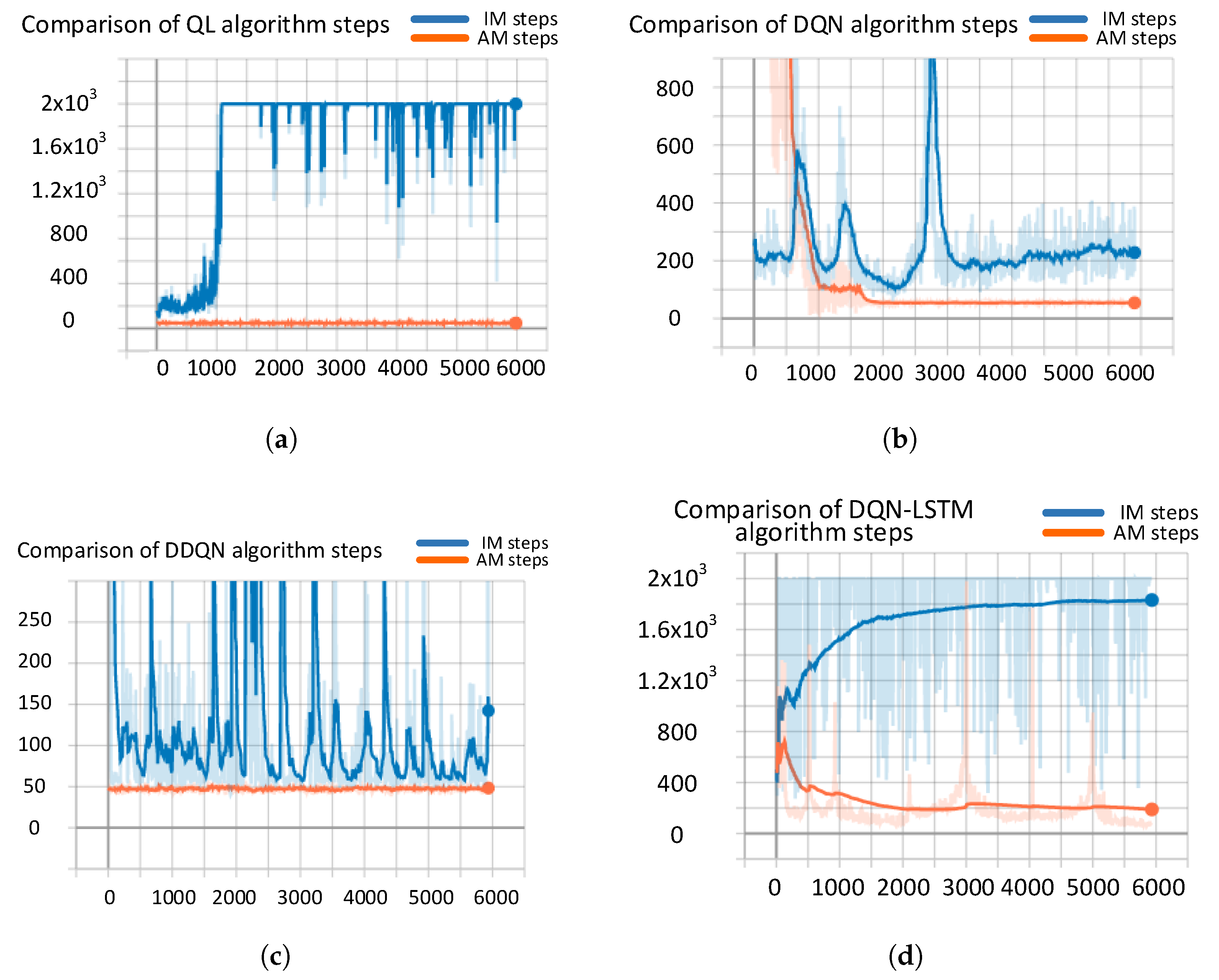
4.2.1. Convergence Analysis
4.2.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Peng, J.; Xie, Z.; Zhang, Y. Optimal jamming frequency selection for cognitive jammer based on reinforcement learning. In Proceedings of the 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), Weihai, China, 28–30 September 2019; pp. 39–43. [Google Scholar]
- Wang, Y.; Zhang, T.; Xu, L.; Tian, T.; Kong, L.; Yang, X. Model-free reinforcement learning based multi-stage smart noise jamming. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar]
- Shang, Z.; Liu, T. Present situation and trend of precision guidance technology and its intelligence. In Proceedings of the LIDAR Imaging Detection and Target Recognition 2017, Changchun, China, 23–25 July 2017; p. 1060540. [Google Scholar]
- Carotenuto, V.; De Maio, A.; Orlando, D.; Pallotta, L. Adaptive radar detection using two sets of training data. IEEE Trans. Sign. Process. 2017, 66, 1791–1801. [Google Scholar] [CrossRef]
- Young, J.R.; Narayanan, R.M.; Jenkins, D.M. Modified transmitted reference technique for multi-resolution radar timing and synchronization. In Proceedings of the Radar Sensor Technology XXIII, Baltimore, MD, USA, 14–18 April 2019; Volume 11003, p. 110031A. [Google Scholar]
- Haykin, S. Cognitive radar: A way of the future. IEEE Sign. Process. Mag. 2006, 23, 30–40. [Google Scholar] [CrossRef]
- Edelman, G.M. Second Nature: Brain Science and Human Knowledge; Yale University Press: New Haven, CT, USA, 2006. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach. 2002. Available online: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/27702.pdf (accessed on 1 January 2020).
- Bu, F.; He, J.; Li, H.; Fu, Q. Radar seeker anti-jamming performance prediction and evaluation method based on the improved grey wolf optimizer algorithm and support vector machine. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology (ICET), Chengdu, China, 8–12 May 2020; pp. 704–710. [Google Scholar]
- Chu, Z.; Xiao, N.; Liang, J. Jamming effect evaluation method based on radar behavior recognition. J. Phys. Conf. Ser. 2020, 1629, 012001. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Liu, M.; Qi, H.; Wang, J.; Liu, L. Design of intelligent anti-jamming system based on neural network algorithm. Comput. Meas. Control 2018, 26, 155–159. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3/E; Pearson Education India: Chennai, India, 2010. [Google Scholar]
- Deligiannis, A.; Lambotharan, S. A bayesian game theoretic framework for resource allocation in multistatic radar networks. In Proceedings of the 2017 IEEE Radar Conference (RadarConf), Seattle, WA, USA, 8–12 May 2017; pp. 0546–0551. [Google Scholar]
- Garnaev, A.; Petropulu, A.; Trappe, W.; Poor, H.V. A power control problem for a dual communication-radar system facing a jamming threat. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Li, H.; Han, Z. Dogfight in spectrum: Combating primary user emulation attacks in cognitive radio systems, part i: Known channel statistics. IEEE Trans. Wirel. Commun. 2010, 9, 3566–3577. [Google Scholar] [CrossRef]
- Wu, B. Hierarchical macro strategy model for moba game ai. Proc. AAAI Conf. Artif. Intell. 2019, 33, 1206–1213. [Google Scholar] [CrossRef] [Green Version]
- Qiang, X.; Weigang, Z.; Xin, J. Research on method of intelligent radar confrontation based on reinforcement learning. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 471–475. [Google Scholar]
- Watkins, C.J.; Dayan, P. Technical note: Q-learning. Mach. Learn. 1992, 6, 279–292. [Google Scholar] [CrossRef]
- Melo, F.S. Convergence of q-Learning: A Simple Proof; Institute of Systems and Robotics: Lisbon, Portugal, 2001. [Google Scholar]
- Li, K.; Jiu, B.; Liu, H. Deep q-network based anti-jamming strategy design for frequency agile radar. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–5. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Aref, M.A.; Jayaweera, S.K. Spectrum-agile cognitive interference avoidance through deep reinforcement learning. In Proceedings of the International Conference on Cognitive Radio Oriented Wireless Networks, Poznan, Poland, 11–12 June 2019; pp. 218–231. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. Proc. AAAI Conf. Artif. Intell. 2016, 30, 2094–2100. [Google Scholar]
- Ak, S.; Brüggenwirth, S. Avoiding jammers: A reinforcement learning approach. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 321–326. [Google Scholar]
- Olah, C. Understanding LSTM Networks. 2015. Available online: https://web.stanford.edu/class/cs379c/archive/2018/class_messages_listing/content/Artificial_Neural_Network_Technology_Tutorials/OlahLSTM-NEURAL-NETWORK-TUTORIAL-15.pdf (accessed on 1 November 2019).
- Anderson, T. The Theory and Practice of Online Learning; Athabasca University Press: Athabasca, AB, Canada, 2008. [Google Scholar]
- Laskin, M.; Lee, K.; Stooke, A.; Pinto, L.; Abbeel, P.; Srinivas, A. Reinforcement learning with augmented data. arXiv 2020, arXiv:2004.14990. [Google Scholar]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269, 115036. [Google Scholar] [CrossRef]
- Kostrikov, I.; Yarats, D.; Fergus, R. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. arXiv 2020, arXiv:2004.13649. [Google Scholar]
- Van Otterlo, M.; Wiering, M. Reinforcement learning and markov decision processes. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar]
- Whitehead, S.D.; Lin, L.-J. Reinforcement learning of non-markov decision processes. Artif. Intell. 1995, 73, 271–306. [Google Scholar] [CrossRef] [Green Version]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Pardhasaradhi, A.; Kumar, R.R. Signal jamming and its modern applications. Int. J. Sci. Res. 2013, 2, 429–431. [Google Scholar]
- Peiqiang, W.; Zhang, J. Analysis and countermeasures of radar radio frequency-screen signal. Aerosp. Electron. Warf. 2013, 29, 47–50. [Google Scholar]
- Jin, L.; Zhan, L.; Xiao, J.; Shen, Y. A syn-aim jamming algorithm against concatenated code. J. Telem. Track. Command 2014, 35, 37–42. [Google Scholar]
- Zhang, L.; She, C. Research into the anti-spot-jamming performance of terminal guidance radar based on random frequency hopping. Shipboard Electron. Countermeas. 2020, 43, 17–19+24. [Google Scholar]
- Dayan, P.; Daw, N.D. Decision theory, reinforcement learning, and the brain. Cognit. Affect. Behav. Neurosci. 2008, 8, 429–453. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Jiu, B.; Liu, H.; Liang, S. Reinforcement learning based anti-jamming frequency hopping strategies design for cognitive radar. In Proceedings of the 2018 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; pp. 1–5. [Google Scholar]
- Kozy, M.; Yu, J.; Buehrer, R.M.; Martone, A.; Sherbondy, K. Applying deep-q networks to target tracking to improve cognitive radar. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 2–26 April 2019; pp. 1–6. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RL Parameters | Radar System Parameters |
|---|---|
| Agent | Radar. |
| Environment | Target environment. |
| State | The status of the detected target , which contains target speed, angle and distance information. |
| Action | Frequency agile anti-jamming cover pulse and tracking signal source emitted by radar , which contains radar amplitude A, pulse width and pulse repetition period (PRF) . |
| Reward | Obtain target information accuracy evaluation . |
| RL Parameters | Radar System Radar Side’s Parameters |
|---|---|
| Agent | Radar. |
| Environment | Target and jamming radar environment. |
| State | Status of detected targets with interference information , which contains target speed , angle and distance d information, target error rate . |
| Action | Frequency agile anti-jamming cover pulse and tracking signal source emitted by radar , which contains radar amplitude A, pulse width and pulse repetition period (PRF) . |
| Reward | Obtain target information accuracy assessment and whether the jamming signal locks the cover pulse . |
| () | () | |
| () | () |
| Radar initial state, which is the first radar echo signal, is described by target error rate , . | |
| – | Radar intermediate state, . |
| Radar final state, . |
| Target Error Rate | Radar’s Rewards | Jammer’s Reward |
|---|---|---|
| +5 | −4 | |
| +4 | −2 | |
| +1 | −1 | |
| others | −4 | +3 |
| Mode | Convergence Time (Time/) | Single-Round Decision Time After Convergence (Time/) | 6000 Rounds Total Running Time (Time/) | MSE | |
|---|---|---|---|---|---|
| Before Convergence | After Convergence | ||||
| IM_QL [18] | 837,581.728 | ||||
| AM_QL | 18,122.910 | ||||
| IM_DQN [21] | 1,083,521.021 | ||||
| AM_DQN | 159,102.375 | ||||
| IM_DDQN [24] | 106,707.731 | ||||
| AM_DDQN | |||||
| IM_DDQN+LSTM [25] | 2,550,491.971 | ||||
| AM_DQN+LSTM | 283,561.026 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Dong, S. Research on Efficient Reinforcement Learning for Adaptive Frequency-Agility Radar. Sensors 2021, 21, 7931. https://doi.org/10.3390/s21237931
Li X, Dong S. Research on Efficient Reinforcement Learning for Adaptive Frequency-Agility Radar. Sensors. 2021; 21(23):7931. https://doi.org/10.3390/s21237931
Chicago/Turabian StyleLi, Xinzhi, and Shengbo Dong. 2021. "Research on Efficient Reinforcement Learning for Adaptive Frequency-Agility Radar" Sensors 21, no. 23: 7931. https://doi.org/10.3390/s21237931
APA StyleLi, X., & Dong, S. (2021). Research on Efficient Reinforcement Learning for Adaptive Frequency-Agility Radar. Sensors, 21(23), 7931. https://doi.org/10.3390/s21237931