
Multi-Objective Optimization of Energy Saving and Throughput in Heterogeneous Networks Using Deep Reinforcement Learning


Abstract
:1. Introduction
- There has not been notable research on an energy efficient multi-hop routing algorithm using DRL for an mmWave backhaul mesh of a dense HetNet;
- The DRL-based algorithm can be considered to find a Pareto front solution for the dual-objective optimization of energy saving and throughput maximization in the HetNet.
- We propose a PPO-based online algorithm for the bi-objective problem of energy minimization and throughput maximization;
- We propose an integrated framework based on the PPO algorithm and OLS to find the Pareto front of the two objectives;
- We demonstrate the feasibility of the proposed online solution based on DRL in a HetNet environment.
2. Related Works
3. Deep Reinforcement Learning (DRL)
3.1. Deep Q-Learning
3.2. Policy Gradient and Actor-Critic
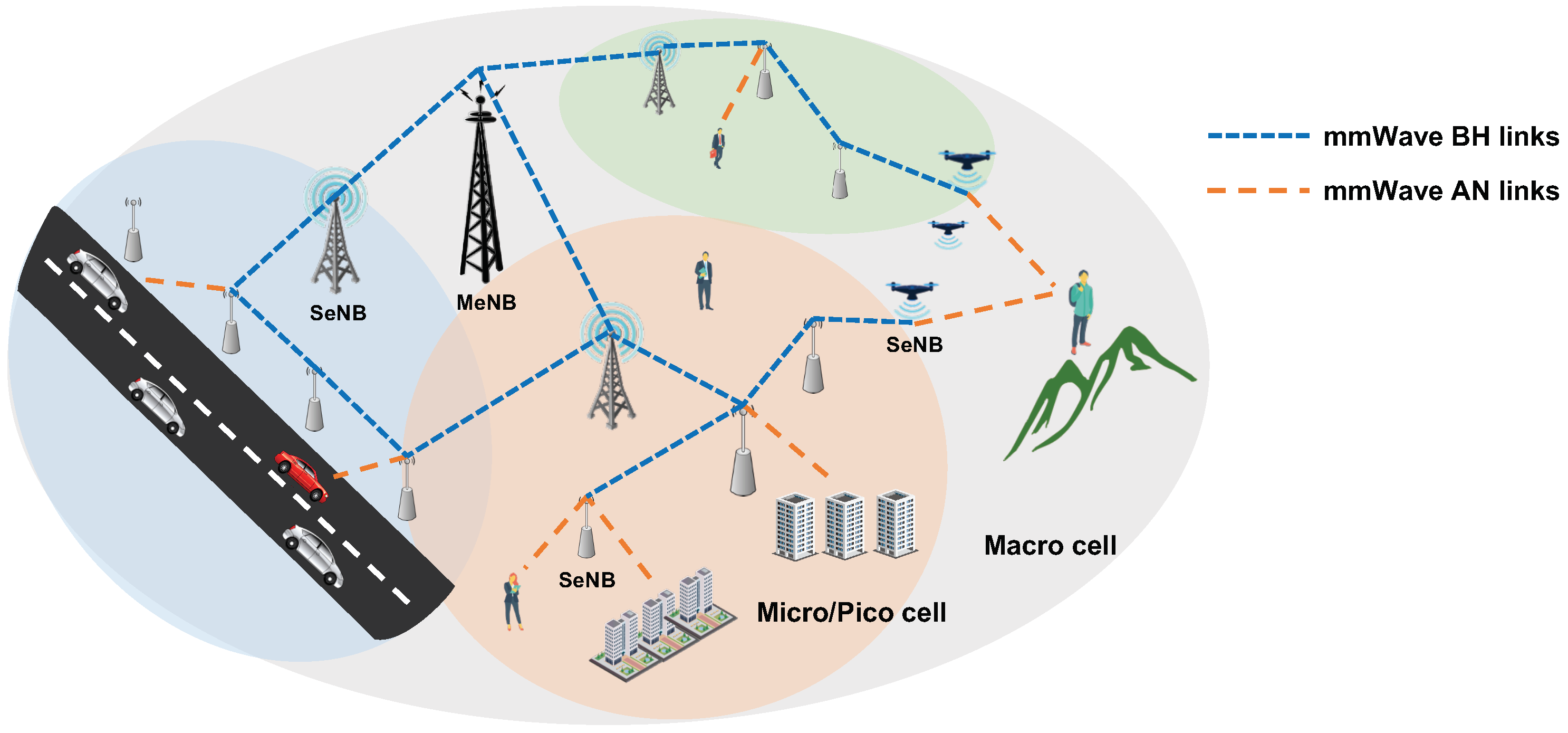
4. System Model
4.1. Energy Consumption Model
4.1.1. AN Energy Consumption
4.1.2. BN Energy Consumption
4.2. Switch On and Off Model
4.3. Multi-Hop Routing Model
4.4. Link Capacity and Scheduling Model
4.5. Dual Objective Function
5. Deep Multi-Objective Reinforcement Learning in mmWave HetNet
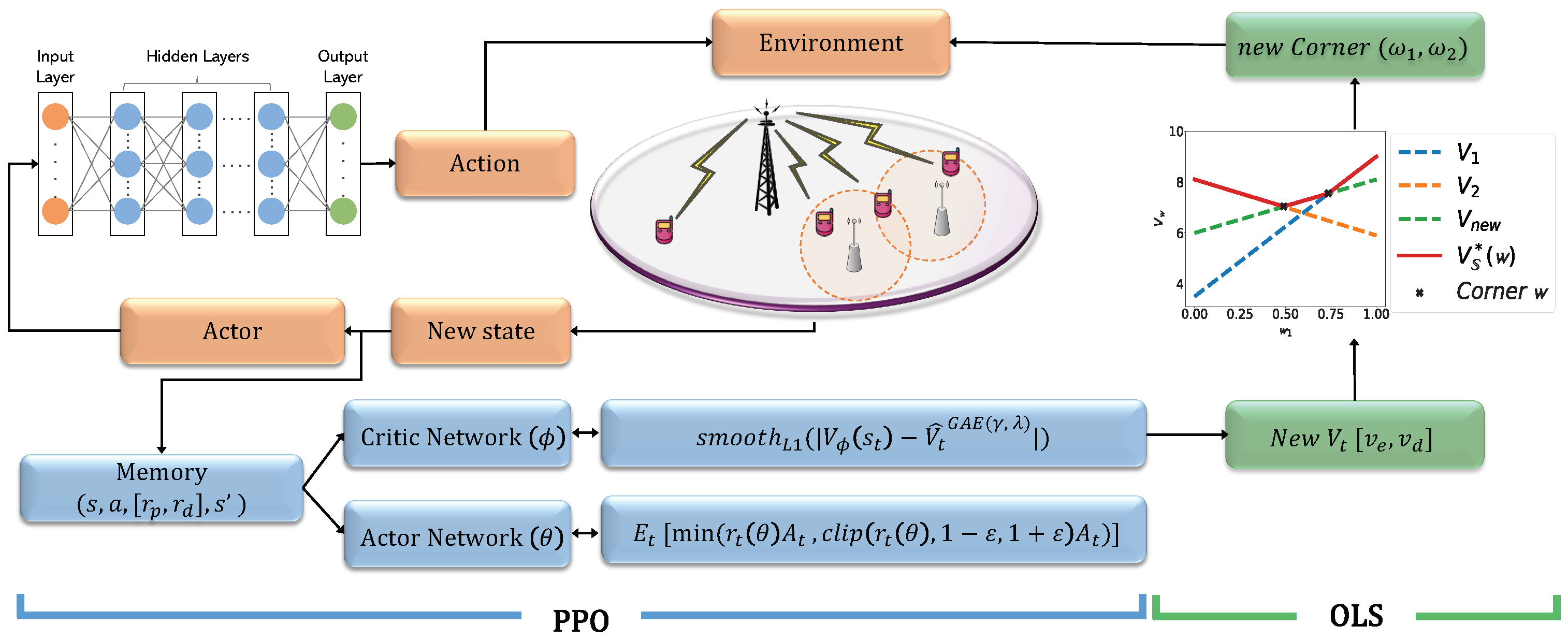
5.1. Proximal Policy Optimization
5.2. MDP of mmWave-Backhaul HetNets
- State S: the state in the HetNet MDP is denoted by a traffic matrix that represents traffic load at access and backhaul links, which eventually determines throughput and energy consumption. In particular, we define a single representative state for all access links of a certain eNB instead of the individual state to reduce state information, since the AN energy consumption from transmission power, , is calculated by aggregated RBs of all associated users as shown in Equation (4). Accordingly, the vector size of the state space is . We define the environment state, , with , as below:where the index e of each link is given by the environment at the beginning of the learning phase;
- Action A: the agent action is routing and association of user flows, which actually decides a set of binary variables, as discussed in Equations (16) and (17). However, such discrete action space grows exponentially by the number of the links, in which convergence of the learning algorithm is rarely guaranteed and large memory is required for computation. Instead, we consider a weight matrix () of all links for all user flows, with which each flow finds a path using a link-state routing algorithm (e.g., the Dijikstra algorithm). Accordingly, the space complexity decreases from to . All actions for the links can be defined as below:Unfortunately, such a shortest path algorithm leads most of users to select a MeNB’s AN link as a single-hop path; cumulative weights along a multi-hop path are mostly higher than for a single hop. This prevents the DRL algorithm from exploring actions of multi-hop routing that may offer reward gain by increasing user throughput, , more than the cost of energy consumption, .Therefore, we limit the number of user flows for the MeNB in the routing algorithm that admits the user flows to the MeNB only if the MeNB has available RBs, . Otherwise, users find multi-hop paths through SeNBs in the algorithm;
- Reward R: the reward is given by the objective function of Equation (21). Thus, we change the minimization objective to maximization by multiplying Equation (21) by . For normalization, the sum rate of all UE flows and corresponding eNB energy consumption are divided by the sum of the maximum data rate and maximum energy consumption. Subsequently, the reward can be written in Equation (31) aswhere and represent and , respectively.
5.3. PPO-Based DRL for HetNet Optimization
| Algorithm 1 Proposed PPO Solution for mmWave HetNet |
|
5.4. Multi-Objective Deep Reinforcement Learning
| Algorithm 2 PPO-Based Deep Optimistic Linear Support |
|
6. Experiment
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rappaport, T.S.; Sun, S.; Mayzus, R.; Zhao, H.; Azar, Y.; Wang, K.; Wong, G.N.; Schulz, J.K.; Samimi, M.; Gutierrez, F. Millimeter wave mobile communications for 5G cellular: It will work! Access IEEE 2013, 1, 335–349. [Google Scholar] [CrossRef]
- Sun, S.; MacCartney, G.R.; Samimi, M.K.; Nie, S.; Rappaport, T.S. Millimeter wave multi-beam antenna combining for 5G cellular link improvement in New York City. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 5468–5473. [Google Scholar]
- Maccartney, G.R.; Rappaport, T.S. 73 GHz millimeter wave propagation measurements for outdoor urban mobile and backhaul communications in New York City. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 4862–4867. [Google Scholar]
- Dehos, C.; González, J.L.; De Domenico, A.; Ktenas, D.; Dussopt, L. Millimeter-wave access and backhauling: The solution to the exponential data traffic increase in 5G mobile communications systems? Commun. Mag. IEEE 2014, 52, 88–95. [Google Scholar] [CrossRef]
- Wang, P.; Li, Y.; Song, L.; Vucetic, B. Multi-gigabit millimeter wave wireless communications for 5G: From fixed access to cellular networks. Commun. Mag. IEEE 2015, 53, 168–178. [Google Scholar] [CrossRef]
- Taori, R.; Sridharan, A. Point-to-multipoint in-band mmwave backhaul for 5G networks. IEEE Commun. Mag. 2015, 53, 195–201. [Google Scholar] [CrossRef]
- Zhu, Y.; Niu, Y.; Li, J.; Wu, D.O.; Li, Y.; Jin, D. QoS-Aware Scheduling for Small Cell Millimeter Wave Mesh Backhaul. Available online: https://ieeexplore.ieee.org/document/7511065 (accessed on 10 October 2021).
- Nakamura, M.; Tran, G.K.; Sakaguchi, K. Interference Management for Millimeter-Wave Mesh Backhaul Networks. Available online: https://ieeexplore.ieee.org/document/8651725 (accessed on 10 October 2021).
- Zola, E.; Kassler, A.J.; Kim, W. Joint User Association and Energy Aware Routing for Green Small Cell Mmwave Backhaul Networks. Available online: https://ieeexplore.ieee.org/document/7925706 (accessed on 10 October 2021).
- Jaber, M.; Imran, M.A.; Tafazolli, R.; Tukmanov, A. 5G backhaul challenges and emerging research directions: A survey. IEEE Access 2016, 4, 1743–1766. [Google Scholar] [CrossRef] [Green Version]
- Correia, L.M.; Zeller, D.; Blume, O.; Ferling, D.; Jading, Y.; Gódor, I.; Auer, G.; Van Der Perre, L. Challenges and enabling technologies for energy aware mobile radio networks. IEEE Commun. Mag. 2010, 48, 66–72. [Google Scholar] [CrossRef]
- Ashraf, I.; Boccardi, F.; Ho, L. Sleep mode techniques for small cell deployments. IEEE Commun. Mag. 2011, 49, 72–79. [Google Scholar] [CrossRef]
- Soh, Y.S.; Quek, T.Q.; Kountouris, M.; Shin, H. Energy efficient heterogeneous cellular networks. IEEE J. Sel. Areas Commun. 2013, 31, 840–850. [Google Scholar] [CrossRef]
- Suárez, L.; Nuaymi, L.; Bonnin, J.M. Energy-efficient BS switching-off and cell topology management for macro/femto environments. Comput. Netw. 2015, 78, 182–201. [Google Scholar] [CrossRef]
- Liu, C.; Pan, Z.; Liu, N.; You, X. A Novel Energy Saving Strategy for LTE HetNet. Available online: https://ieeexplore.ieee.org/document/6096845 (accessed on 10 October 2021).
- Bhaumik, S.; Narlikar, G.; Chattopadhyay, S.; Kanugovi, S. Breathe to Stay Cool: ADJUSTING Cell Sizes to Reduce Energy Consumption. Available online: https://dl.acm.org/doi/10.1145/1851290.1851300 (accessed on 10 October 2021).
- Chen, L.; Yu, F.R.; Ji, H.; Rong, B.; Li, X.; Leung, V.C. Green full-duplex self-backhaul and energy harvesting small cell networks with massive MIMO. IEEE J. Sel. Areas Commun. 2016, 34, 3709–3724. [Google Scholar] [CrossRef]
- Mesodiakaki, A.; Adelantado, F.; Alonso, L.; Di Renzo, M.; Verikoukis, C. Energy-and spectrum-efficient user association in millimeter-wave backhaul small-cell networks. IEEE Trans. Veh. Technol. 2016, 66, 1810–1821. [Google Scholar] [CrossRef] [Green Version]
- Hao, W.; Zeng, M.; Chu, Z.; Yang, S.; Sun, G. Energy-efficient resource allocation for mmWave massive MIMO HetNets with wireless backhaul. IEEE Access 2017, 6, 2457–2471. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. Available online: http://proceedings.mlr.press/v32/silver14.pdf (accessed on 10 October 2021).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. Available online: https://arxiv.org/abs/1502.05477 (accessed on 10 October 2021).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Available online: https://arxiv.org/abs/1801.01290 (accessed on 10 October 2021).
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access in wireless networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 257–265. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Lu, Z.; Gursoy, M.C.; Velipasalar, S. Actor-Critic Deep Reinforcement Learning for Dynamic Multichannel Access. Available online: https://ieeexplore.ieee.org/document/8646405 (accessed on 10 October 2021).
- Zhong, C.; Lu, Z.; Gursoy, M.C.; Velipasalar, S. A deep actor-critic reinforcement learning framework for dynamic multichannel access. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1125–1139. [Google Scholar] [CrossRef] [Green Version]
- Naparstek, O.; Cohen, K. Deep Multi-User Reinforcement Learning for Dynamic Spectrum Access in Multichannel Wireless Networks. Available online: https://arxiv.org/abs/1704.02613 (accessed on 10 October 2021).
- Naparstek, O.; Cohen, K. Deep multi-user reinforcement learning for distributed dynamic spectrum access. IEEE Trans. Wirel. Commun. 2018, 18, 310–323. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, W.; Wang, C.X.; Sun, J.; Liu, Y. Deep reinforcement learning for dynamic spectrum sensing and aggregation in multi-channel wireless networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 464–475. [Google Scholar] [CrossRef]
- Liu, S.; Wu, J.; He, J. Dynamic Multichannel Sensing in Cognitive Radio: Hierarchical Reinforcement Learning. IEEE Access 2021, 9, 25473–25481. [Google Scholar] [CrossRef]
- He, Y.; Yu, F.R.; Zhao, N.; Yin, H.; Boukerche, A. Deep Reinforcement Learning (DRL)-Based Resource Management in Softwaredefined and Virtualized Vehicular Ad Hoc Networks. Available online: https://www.semanticscholar.org/paper/Deep-Reinforcement-Learning-(DRL)-based-Resource-in-He-Yu/e1d5360a49ee5269298a54c49d171661ffc245d6 (accessed on 10 October 2021).
- Shi, W.; Li, J.; Wu, H.; Zhou, C.; Cheng, N.; Shen, X. Drone-cell trajectory planning and resource allocation for highly mobile networks: A hierarchical DRL approach. IEEE Internet Things J. 2020, 8, 9800–9813. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Shen, R.; Xu, Y.; Zheng, F.C. DRL-based energy-efficient resource allocation frameworks for uplink NOMA systems. IEEE Internet Things J. 2020, 7, 7279–7294. [Google Scholar] [CrossRef]
- Ahsan, W.; Yi, W.; Qin, Z.; Liu, Y.; Nallanathan, A. Resource allocation in uplink NOMA-IoT networks: A reinforcement-learning approach. IEEE Trans. Wirel. Commun. 2021, 20, 5083–5098. [Google Scholar] [CrossRef]
- Rahimi, A.M.; Ziaeddini, A.; Gonglee, S. A novel approach to efficient resource allocation in load-balanced cellular networks using hierarchical DRL. J. Ambient. Intell. Humaniz. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Ali, R.; Shahin, N.; Zikria, Y.B.; Kim, B.S.; Kim, S.W. Deep reinforcement learning paradigm for performance optimization of channel observation–based MAC protocols in dense WLANs. IEEE Access 2018, 7, 3500–3511. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, T.; Liew, S.C. Deep-reinforcement learning multiple access for heterogeneous wireless networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef] [Green Version]
- Al-Tam, F.; Correia, N.; Rodriguez, J. Learn to Schedule (LEASCH): A Deep reinforcement learning approach for radio resource scheduling in the 5G MAC layer. IEEE Access 2020, 8, 108088–108101. [Google Scholar] [CrossRef]
- Nisioti, E.; Thomos, N. Robust coordinated reinforcement learning for MAC design in sensor networks. IEEE J. Sel. Areas Commun. 2019, 37, 2211–2224. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, B.; Xin, Q.; Su, J.; Ou, W. DRL-ER: An Intelligent Energy-aware Routing Protocol with Guaranteed Delay Bounds in Satellite Mega-constellations. IEEE Trans. Netw. Sci. Eng. 2020. [Google Scholar] [CrossRef]
- El Amine, A.; Dini, P.; Nuaymi, L. Reinforcement Learning for Delay-Constrained Energy-Aware Small Cells with Multi-Sleeping Control. Available online: https://ieeexplore.ieee.org/document/9145431 (accessed on 10 October 2021).
- Asuhaimi, F.A.; Bu, S.; Klaine, P.V.; Imran, M.A. Channel access and power control for energy-efficient delay-aware heterogeneous cellular networks for smart grid communications using deep reinforcement learning. IEEE Access 2019, 7, 133474–133484. [Google Scholar] [CrossRef]
- Hsieh, C.K.; Chan, K.L.; Chien, F.T. Energy-efficient power allocation and user association in heterogeneous networks with deep reinforcement learning. Appl. Sci. 2021, 11, 4135. [Google Scholar] [CrossRef]
- Roijers, D.M.; Vamplew, P.; Whiteson, S.; Dazeley, R. A survey of multi-objective sequential decision-making. J. Artif. Intell. Res. 2013, 48, 67–113. [Google Scholar] [CrossRef] [Green Version]
- Mossalam, H.; Assael, Y.M.; Roijers, D.M.; Whiteson, S. Multi-objective deep reinforcement learning. arXiv 2016, arXiv:1610.02707. [Google Scholar]
- Dong, P.; Zhang, H.; Li, G.Y.; Gaspar, I.S.; NaderiAlizadeh, N. Deep CNN-based channel estimation for mmWave massive MIMO systems. IEEE J. Sel. Top. Signal Process. 2019, 13, 989–1000. [Google Scholar] [CrossRef] [Green Version]
- Lin, B.; Wang, X.; Yuan, W.; Wu, N. A novel OFDM autoencoder featuring CNN-based channel estimation for internet of vessels. IEEE Internet Things J. 2020, 7, 7601–7611. [Google Scholar] [CrossRef]
- Jiang, P.; Wen, C.K.; Jin, S.; Li, G.Y. Dual CNN based Channel Estimation for MIMO-OFDM Systems. IEEE Trans. Commun. 2021, 69, 5859–5872. [Google Scholar] [CrossRef]
- Zheng, S.; Qi, P.; Chen, S.; Yang, X. Fusion methods for CNN-based automatic modulation classification. IEEE Access 2019, 7, 66496–66504. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Pham, Q.V.; Kim, D.S. MCNet: An efficient CNN architecture for robust automatic modulation classification. IEEE Commun. Lett. 2020, 24, 811–815. [Google Scholar] [CrossRef]
- Hermawan, A.P.; Ginanjar, R.R.; Kim, D.S.; Lee, J.M. CNN-based automatic modulation classification for beyond 5G communications. IEEE Commun. Lett. 2020, 24, 1038–1041. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1222–1228. [Google Scholar]
- Kim, J.; Kim, J.; Kim, H.; Shim, M.; Choi, E. CNN-based network intrusion detection against denial-of-service attacks. Electronics 2020, 9, 916. [Google Scholar] [CrossRef]
- Riyaz, B.; Ganapathy, S. A deep learning approach for effective intrusion detection in wireless networks using CNN. Soft Comput. 2020, 24, 17265–17278. [Google Scholar] [CrossRef]
- Azizjon, M.; Jumabek, A.; Kim, W. 1D CNN Based Network Intrusion Detection with Normalization on Imbalanced Data. Available online: https://ieeexplore.ieee.org/document/9064976 (accessed on 10 October 2021).
- Zhao, N.; Liang, Y.C.; Niyato, D.; Pei, Y.; Wu, M.; Jiang, Y. Deep reinforcement learning for user association and resource allocation in heterogeneous cellular networks. IEEE Trans. Wirel. Commun. 2019, 18, 5141–5152. [Google Scholar] [CrossRef]
- Zhang, Q.; Liang, Y.C.; Poor, H.V. Intelligent user association for symbiotic radio networks using deep reinforcement learning. IEEE Trans. Wirel. Commun. 2020, 19, 4535–4548. [Google Scholar] [CrossRef] [Green Version]
- Ding, H.; Zhao, F.; Tian, J.; Li, D.; Zhang, H. A deep reinforcement learning for user association and power control in heterogeneous networks. Ad Hoc Netw. 2020, 102, 102069. [Google Scholar] [CrossRef]
- Du, Z.; Deng, Y.; Guo, W.; Nallanathan, A.; Wu, Q. Green Deep Reinforcement Learning for Radio Resource Management: Architecture, Algorithm Compression, and Challenges. IEEE Veh. Technol. Mag. 2020, 16, 29–39. [Google Scholar] [CrossRef]
- Dai, Y.; Zhang, K.; Maharjan, S.; Zhang, Y. Edge intelligence for energy-efficient computation offloading and resource allocation in 5G beyond. IEEE Trans. Veh. Technol. 2020, 69, 12175–12186. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Available online: https://proceedings.neurips.cc/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf (accessed on 10 October 2021).
- Auer, G.; Giannini, V.; Desset, C.; Godor, I.; Skillermark, P.; Olsson, M.; Imran, M.A.; Sabella, D.; Gonzalez, M.J.; Blume, O.; et al. How much energy is needed to run a wireless network? IEEE Wirel. Commun. 2011, 18, 40–49. [Google Scholar] [CrossRef]
- 36.814. Evolved Universal Terrestrial Radio Access (E-UTRA); Further Advancements for E-UTRA Physical Layer Aspects. Available online: https://www.scirp.org/(S(czeh2tfqyw2orz553k1w0r45))/reference/ReferencesPapers.aspx?ReferenceID=998750 (accessed on 10 October 2021).
- Mesodiakaki, A.; Adelantado, F.; Antonopoulos, A.; Kartsakli, E.; Alonso, L.; Verikoukis, C. Energy Impact of Outdoor Small Cell Backhaul in Green Heterogeneous Networks. Available online: https://ieeexplore.ieee.org/document/7033196?arnumber=7033196 (accessed on 10 October 2021).
- gTSC0020, gAPZ0039, gRSC0016, gRSC0015, gTSC0023, gAPZ0042. Technical Report, Gotmic. 2017. Available online: www.gotmic.se (accessed on 10 October 2021).
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. Available online: https://arxiv.org/abs/1802.09477 (accessed on 10 October 2021).
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Areas of DRL Studies on Wireless Communications |
|---|---|
| [26,27,28,29,30,31,32] | Cognitive radio and dynamic wireless channel selection increase spectral efficiency, which is typically a combinatoric problem of matching channels to nodes. Using DRL, agents can learn the optimal policy from the degree of interference as a reward for every action of channel selection. |
| [38,39,40,41] | The wireless link layer provides a media access scheme for multiple users which is realized in a MAC protocol. Several studies design the wireless MAC protocol based on the DRL algorithm, in which DRL agents learn an optimal transmission policy from the reward of contention resolution at a particular channel state. |
| [59,60,61] | A user association or handover algorithm for a serving base station affects throughput and QoS of each user. The DRL algorithm enables UEs to select an optimal base station based on past experience. |
| [33,34,35,36,37] | Wireless networks have various resources to be scheduled, such as radio block, channels, sequence codes, power, time slots, etc. Many of the scheduling problems have non-convex feasible set and user mobility, which makes the problems intractable. The DRL agents learn an optimal scheduling policy repeatedly from resource utilization against a chosen allocation. |
| [42,43,44,62,63] | Energy and power consumption is critical, especially for green wireless networking, mobile edge cloud networks and UAV networks. The DRL algorithm explores possible policies based on the reward of energy saving while guaranteeing throughput constraint. |
| Symbol | Description | |
|---|---|---|
| Bandwidth for a RB | P | |
| Maximum capacity of link (i,j) | P | |
| Maximum AN capacity of eNB i | P | |
| Total energy consumption at node i | V | |
| Flow of UE u on link (i,j) | V | |
| Indicator if UE u uses link (i,j) | V | |
| Set of interference links | P | |
| Set of links | P | |
| Set of AN links | P | |
| Set of BH links | P | |
| Set of eNB | P | |
| Set of Macro eNB (MeNB) | P | |
| Set of Small eNB (SeNB) | P | |
| Set of UE | P | |
| Number of antennas (MIMO) for UE u at eNB i | P | |
| Number of RBs at node i | P | |
| Static power at node i | P | |
| User demand data rate u | V |
| MeNB-AN | SeNB-AN | BH Link | |
|---|---|---|---|
| Frequency band (GHz) | 2 | 2.6 | 60 |
| Available BW (MHz) | 20 (= 0.18 ) | 20 (= 0.18 ) | 1000 (10 × 100 MHz) |
| Antenna gain (dBi) (, ) | <15 | <15 | 36 |
| 4 (MIMO 4 × 4) | 4 (MIMO 4 × 4) | 1 for each active BH link | |
| (W) | 130 | 6.8 | 3.9 |
| (W) | 20 | 0.13 | 0.224 |
| 4.7 | 4.0 | not used | |
| Distance-dep. Path Loss | [68] | [68] | Equations (6)–(11) in [69] |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 0.8 | 0.8 | ||
| Trajectory size | 1024 | Batch size | 32 |
| K epoch | 10 | Clipping range | 0.2 |
| Learning rate of actor | 1 × | Learning rate of critic | 1 × |
| Network initialization | HE | Optimization method |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, K.; Kim, W. Multi-Objective Optimization of Energy Saving and Throughput in Heterogeneous Networks Using Deep Reinforcement Learning. Sensors 2021, 21, 7925. https://doi.org/10.3390/s21237925
Ryu K, Kim W. Multi-Objective Optimization of Energy Saving and Throughput in Heterogeneous Networks Using Deep Reinforcement Learning. Sensors. 2021; 21(23):7925. https://doi.org/10.3390/s21237925
Chicago/Turabian StyleRyu, Kyungho, and Wooseong Kim. 2021. "Multi-Objective Optimization of Energy Saving and Throughput in Heterogeneous Networks Using Deep Reinforcement Learning" Sensors 21, no. 23: 7925. https://doi.org/10.3390/s21237925
APA StyleRyu, K., & Kim, W. (2021). Multi-Objective Optimization of Energy Saving and Throughput in Heterogeneous Networks Using Deep Reinforcement Learning. Sensors, 21(23), 7925. https://doi.org/10.3390/s21237925