
Rolling Bearing Incipient Fault Diagnosis Method Based on Improved Transfer Learning with Hybrid Feature Extraction



Abstract
:1. Introduction
2. Preliminaries and Methods
2.1. Domain Adaptation Algorithm CORAL
| Algorithm 1 CORAL for Unsupervised Domain Adaptation |
| Input: Data of Source Domain , Data of Target Domain |
| Output: Data of Adjusted Source |
| = |
| = |
| = |
| = |
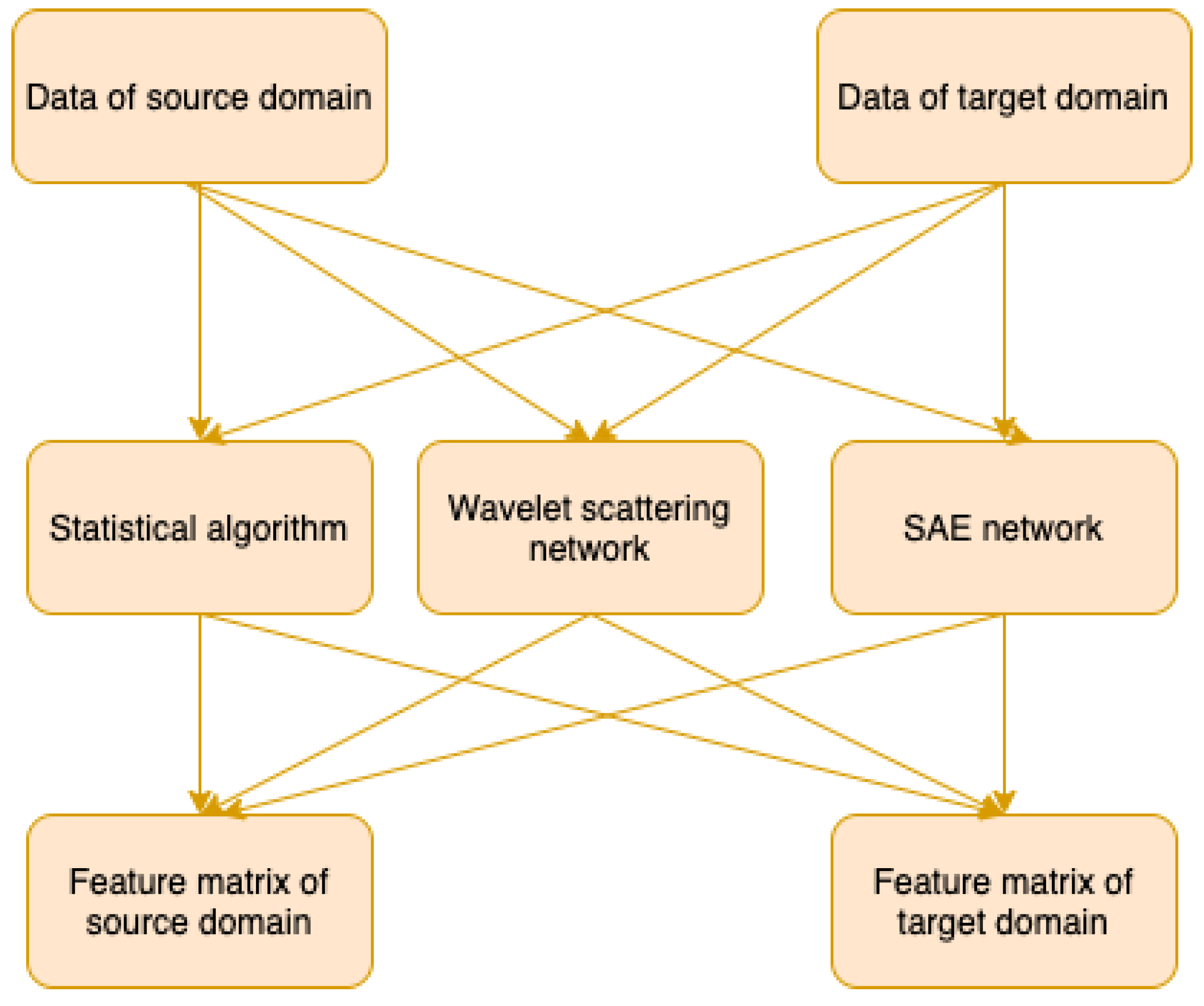
2.2. Feature Extraction
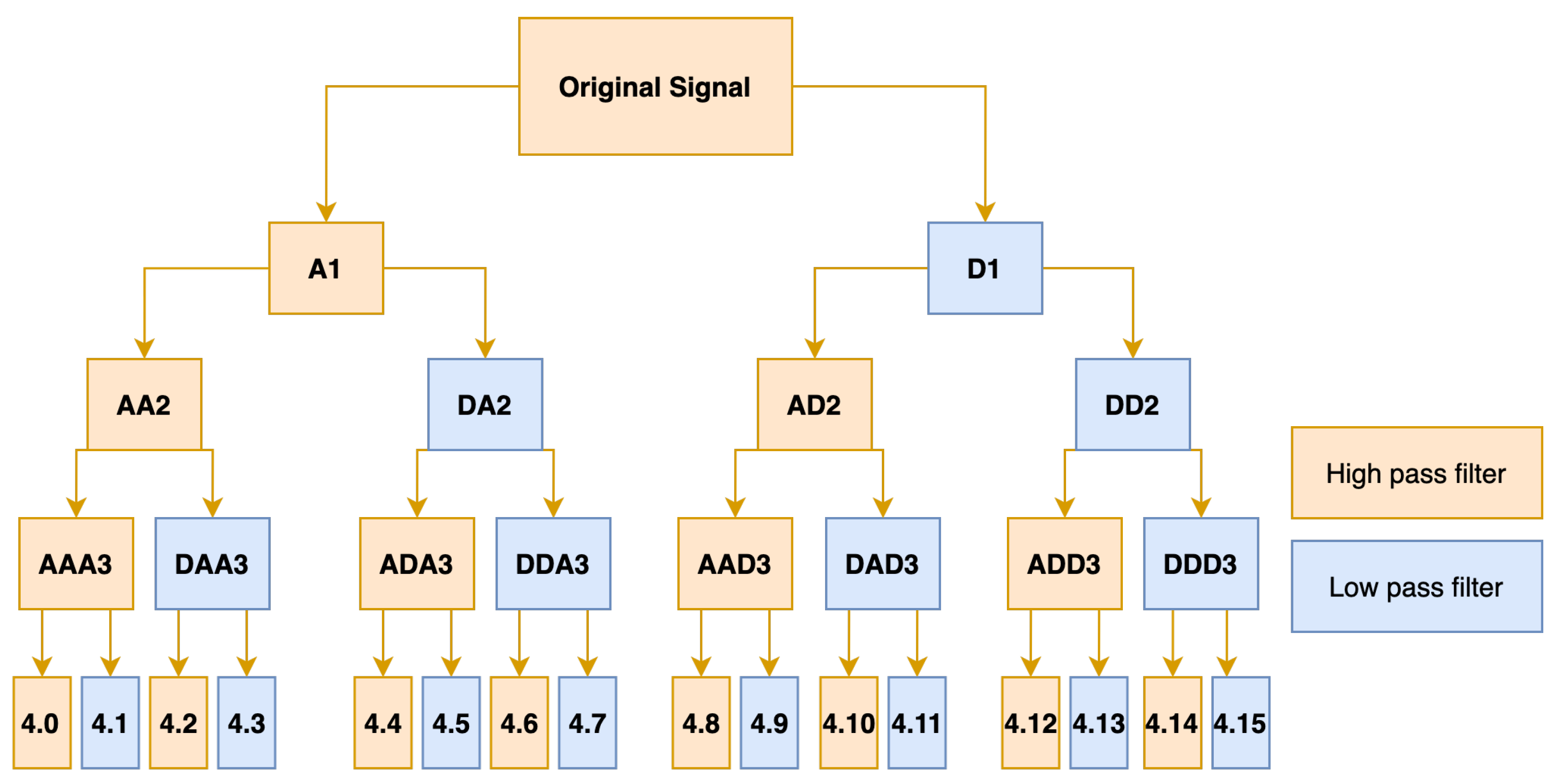
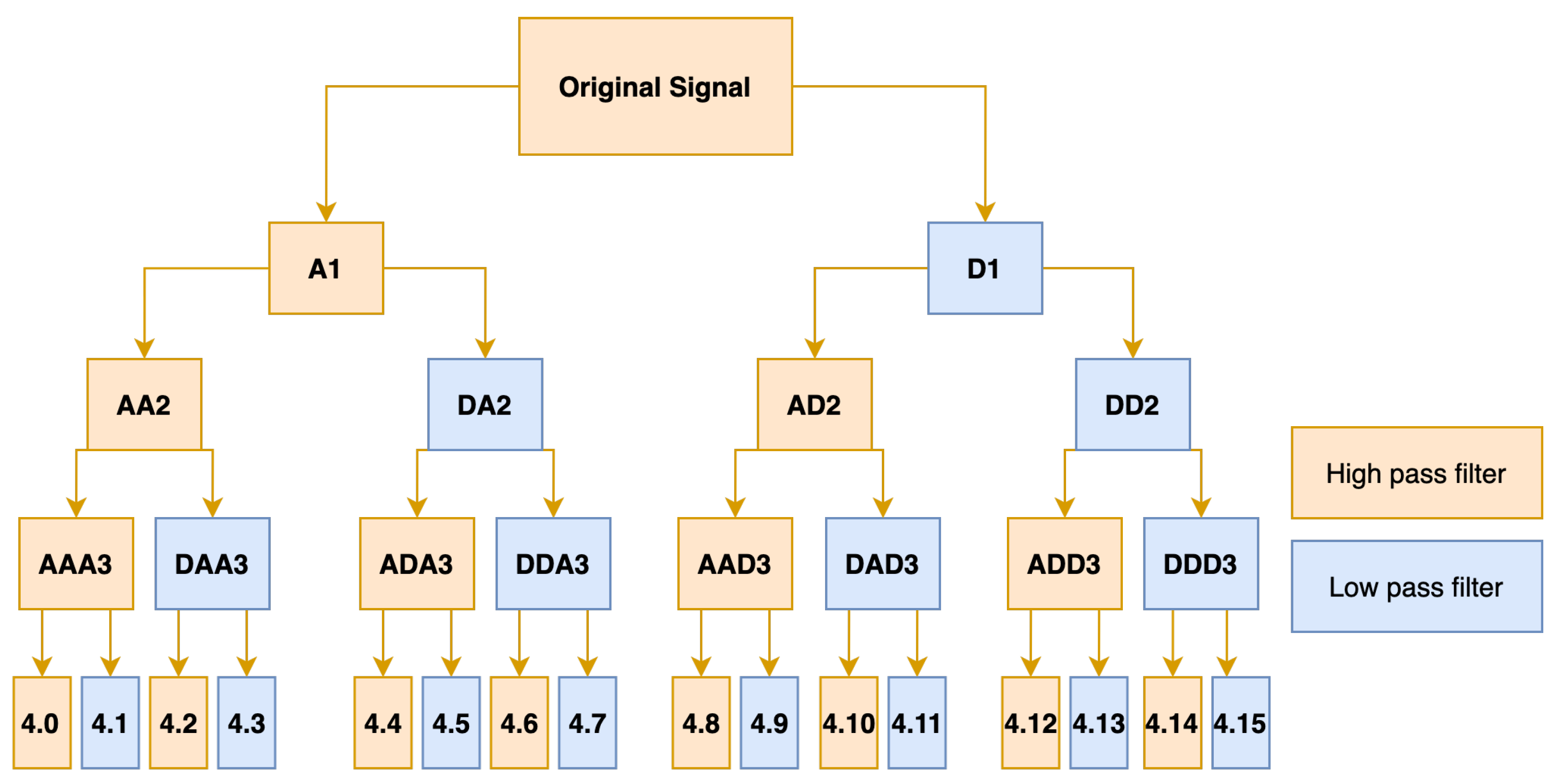
2.2.1. Time and Frequency Domain Analysis
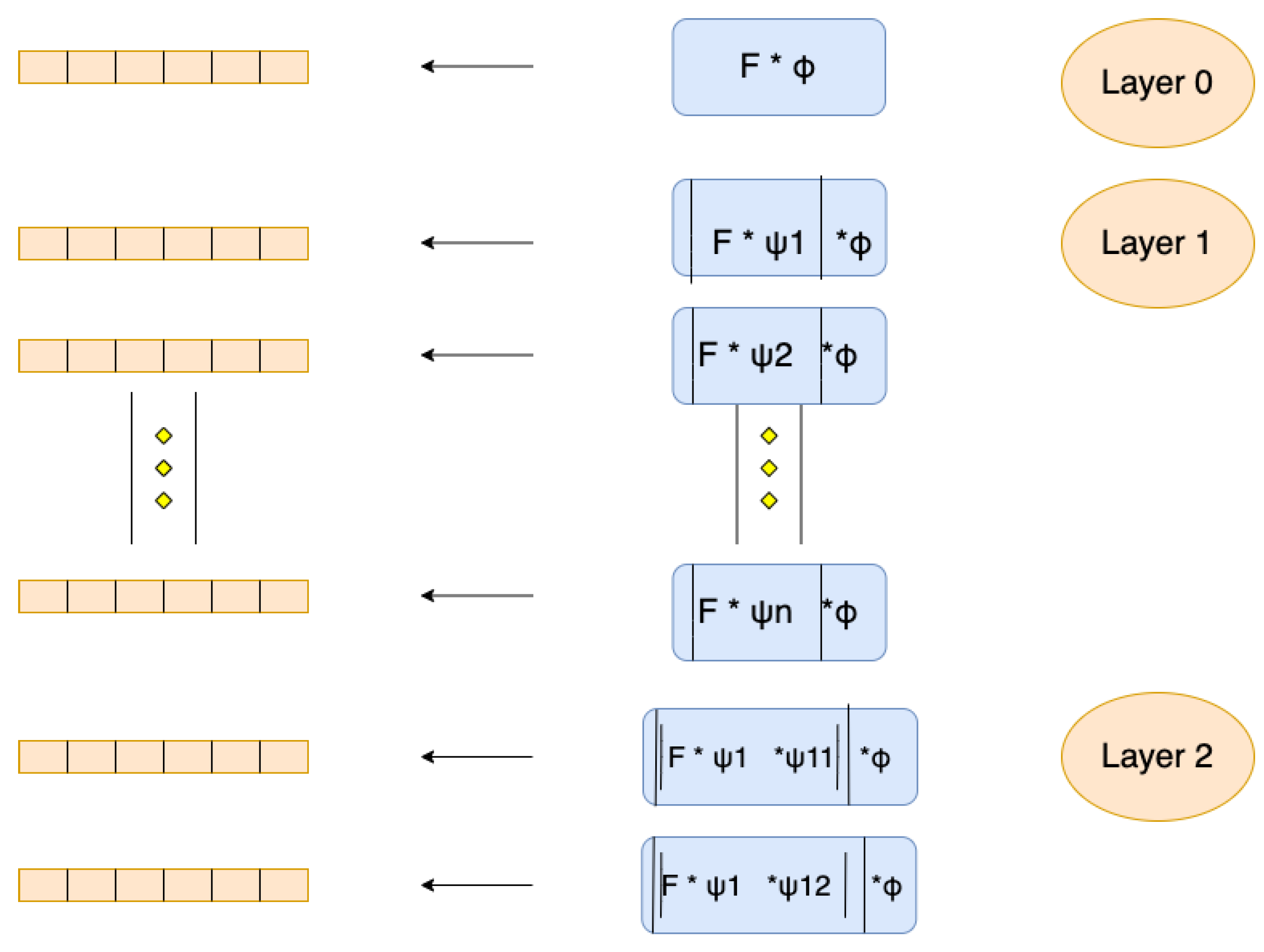
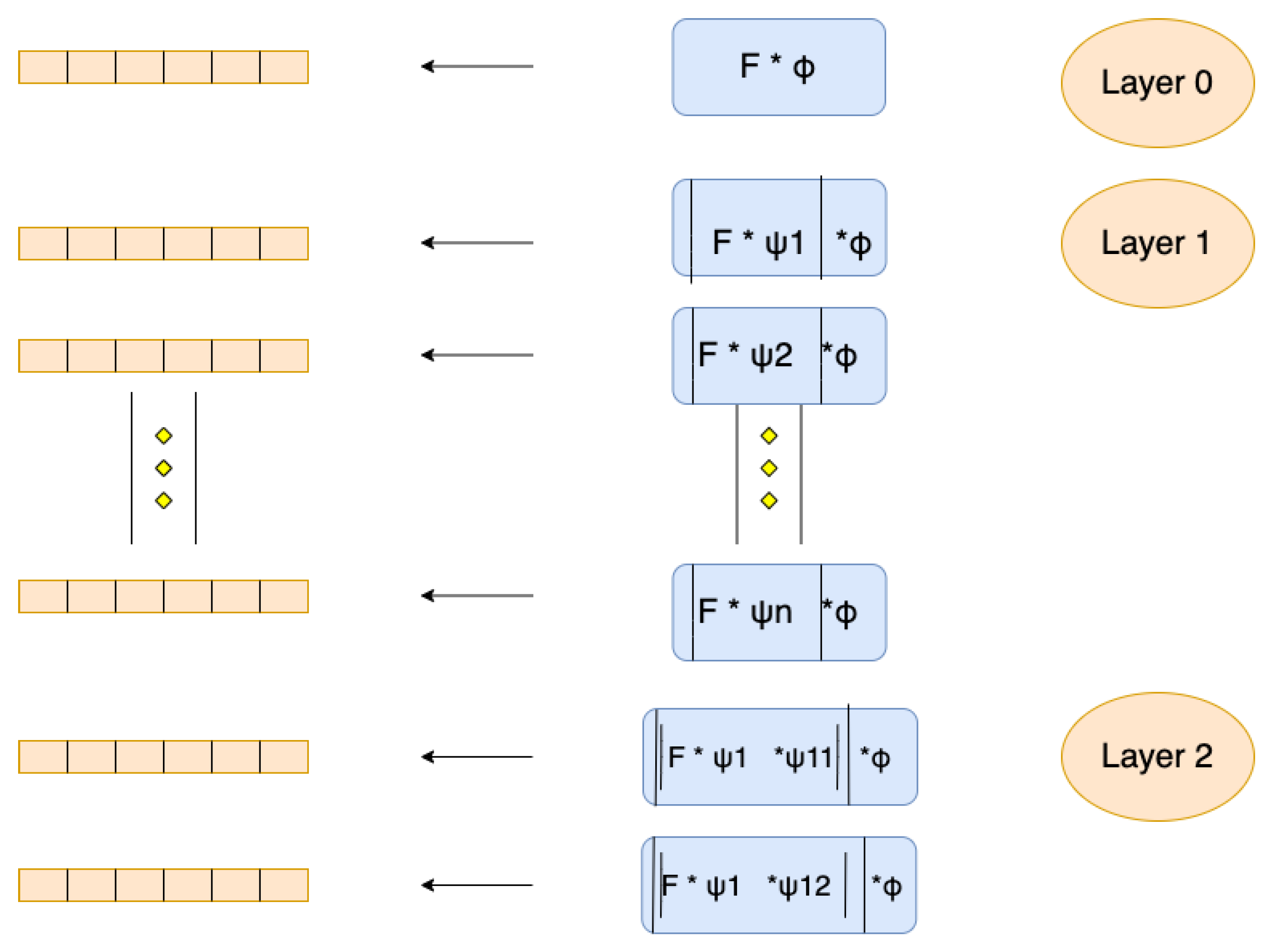
2.2.2. Wavelet Scattering Network
2.2.3. Stacked Auto-Encoder Network
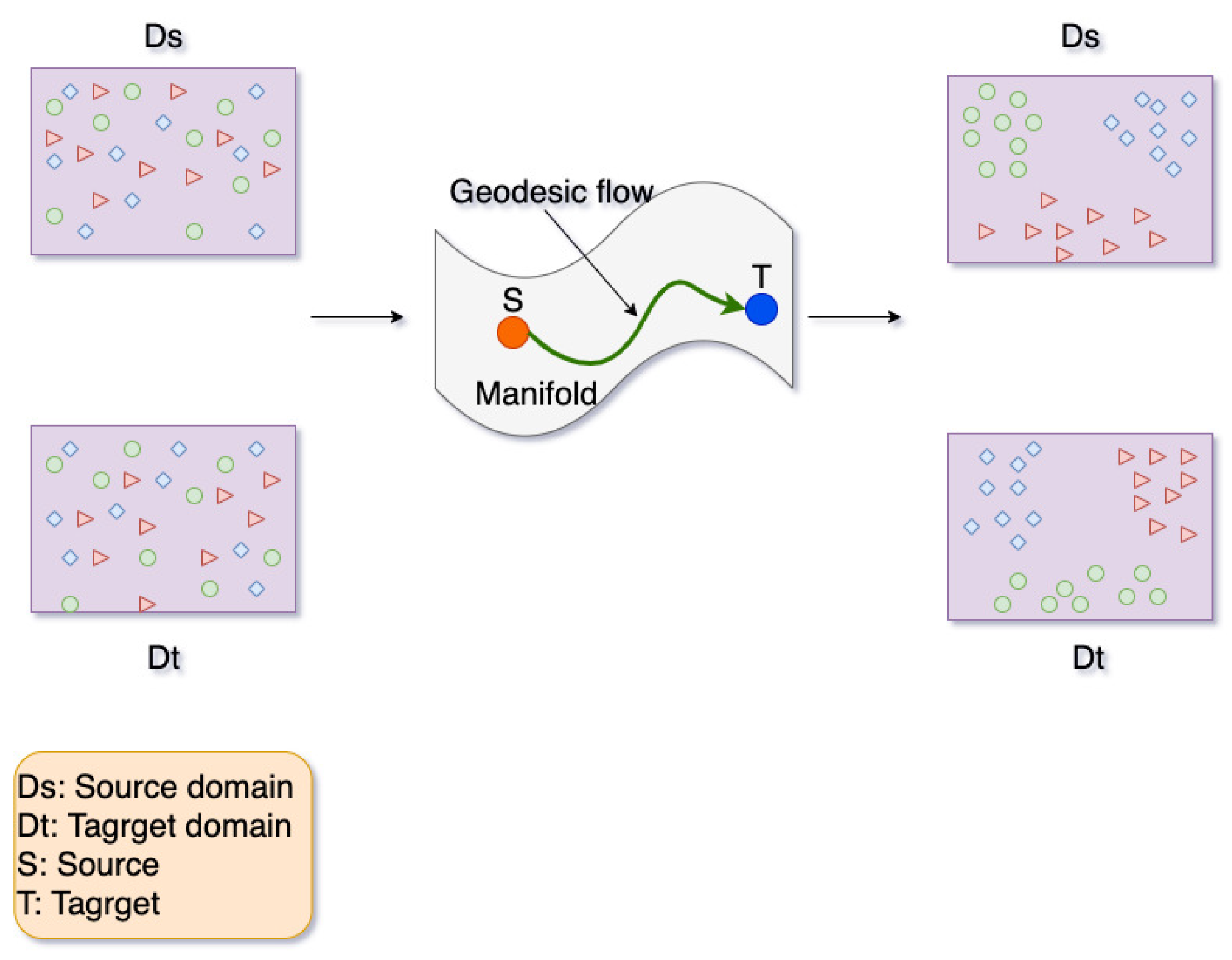
2.3. Geodesic Flow Kernel
2.4. K Nearest Neighbor Classification
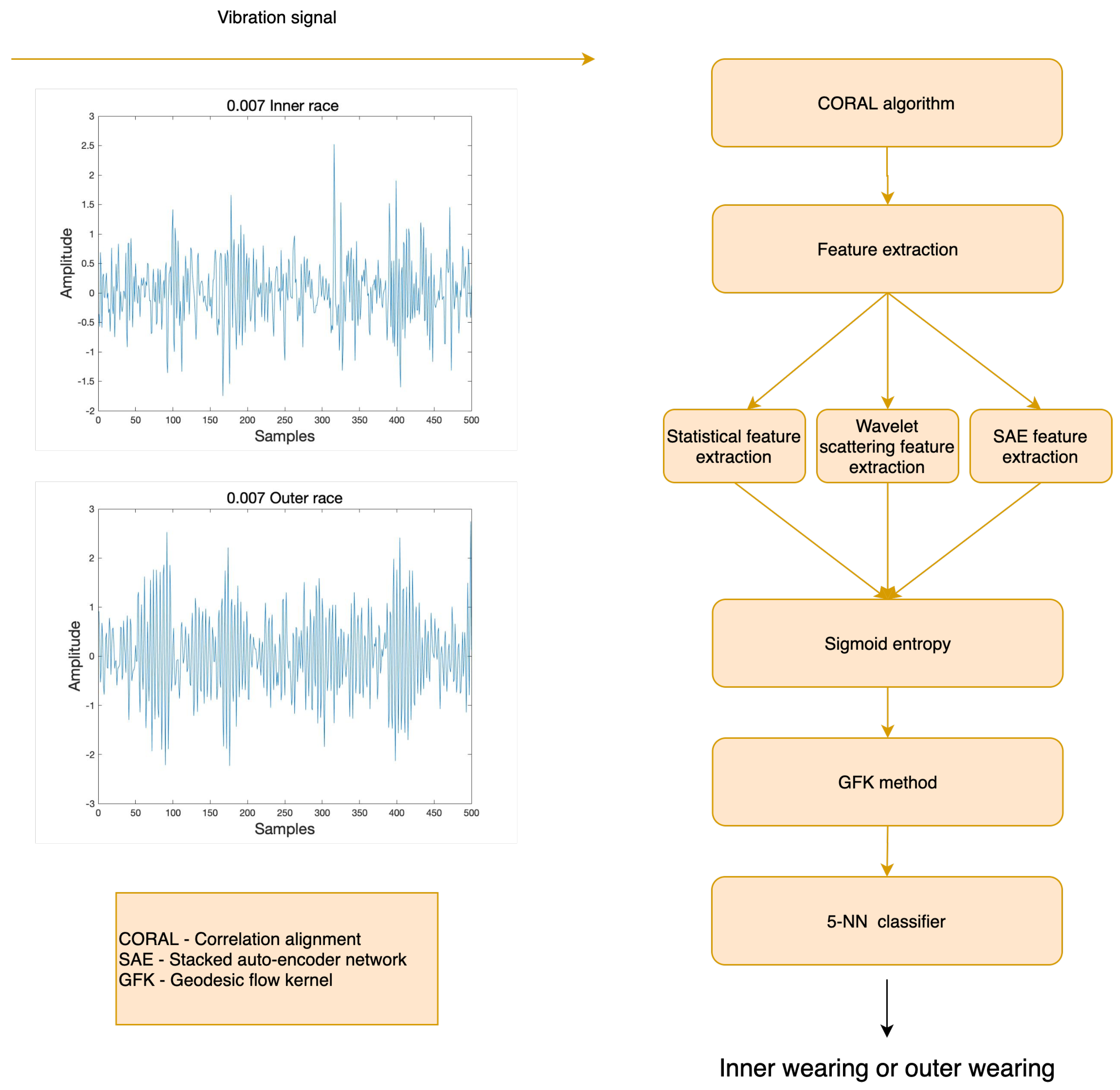
3. Experiments and Results
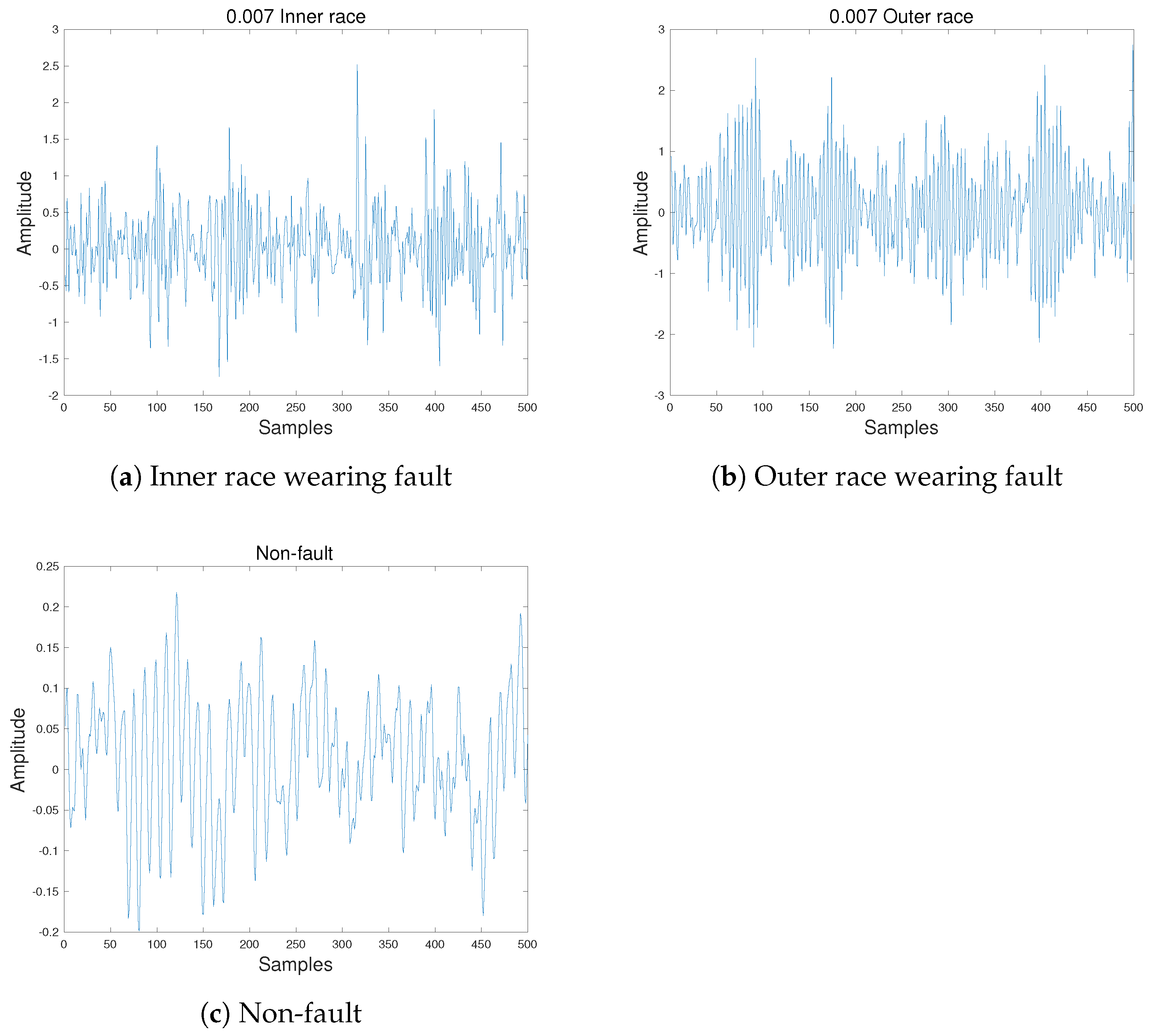
3.1. Data Description
3.2. Experiment Results and Analysis
- (a)
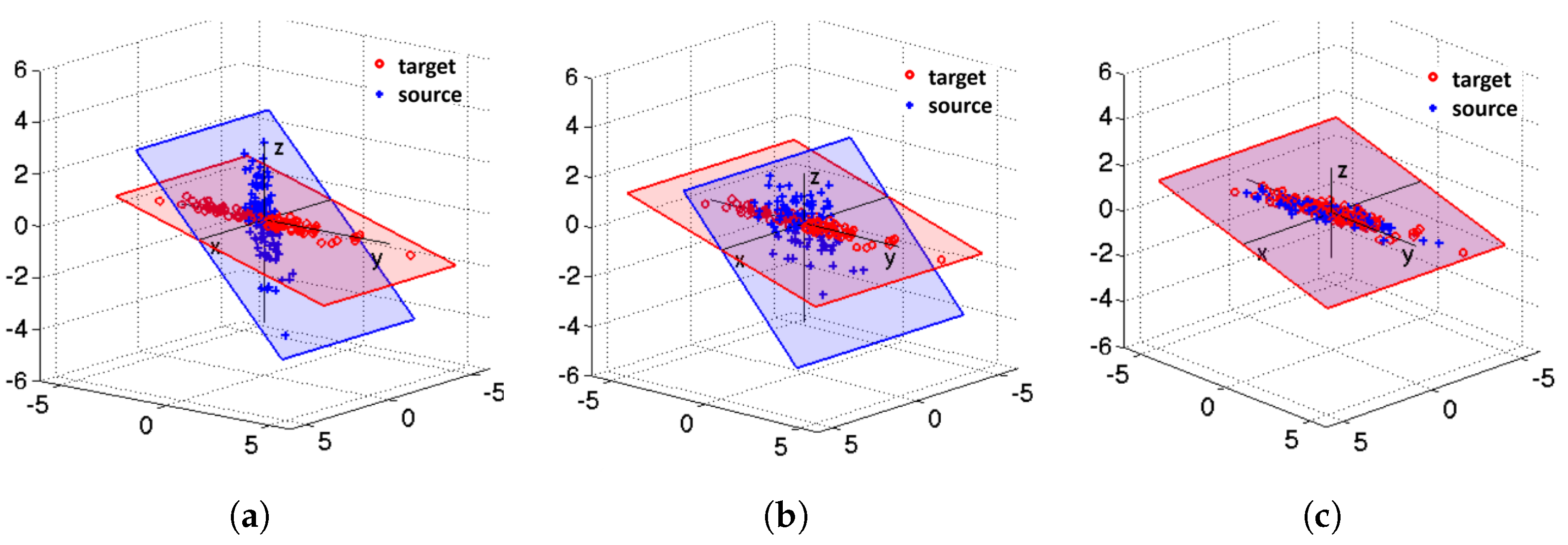
- Effect of Domain Adaptation
- (b)
- Effect of Feature Extraction
- (c)
- Effect of Sigmoid Entropy
- (d)
- Effect of Neighbor Number
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, L.; Yao, B.; Peng, Z.; Guan, Y. Fault Diagnosis of Roller Bearings Based on a Wavelet Neural Network and Manifold Learning. Appl. Sci. 2017, 7, 158–164. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Wang, Z. Design of Power Transformer Fault Diagnosis Model Based on Support Vector Machine. In Proceedings of the 2009 International Symposium on Intelligent Ubiquitous Computing and Education, Chengdu, China, 15–16 May 2009; Wuhan University of Technology: Wuhan, China, 2009; pp. 137–140. [Google Scholar]
- Wang, D.; Tse, P.W.; Tsui, K.L. An enhanced Kurtogram method for fault diagnosis of rolling element bearings. Mech. Syst. Signal Process. 2013, 35, 176–199. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, L.; Li, X.; Wang, H. A Method of Fault Diagnosis for Rotary Equipment Based on Deep Learning. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 958–962. [Google Scholar] [CrossRef]
- Wan, Z.; Yang, R.; Huang, M.; Zeng, N.; Liu, X. A review on transfer learning in EEG signal analysis. Neurocomputing 2021, 421, 1–14. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Wan, Z.; Yang, R.; Huang, M. Deep transfer learning-based fault diagnosis for gearbox under complex working conditions. Shock Vib. 2020, 2020, 8884179. [Google Scholar] [CrossRef]
- Lu, N.; Xiao, H.; Sun, Y.; Han, M.; Wang, Y. A new method for intelligent fault diagnosis of machines based on unsupervised domain adaptation. Neurocomputing 2020, 427, 296–309. [Google Scholar] [CrossRef]
- Li, K.; Xiong, M.; Li, F.; Su, L.; Wu, J. A novel fault diagnosis algorithm for rotating machinery based on a sparsity and neighborhood preserving deep extreme learning machine. Neurocomputing 2019, 350, 261–270. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Saidi, L.; Ali, J.B.; Fnaiech, F. Bi-spectrum based-EMD applied to the non-stationary vibration signals for bearing faults diagnosis. ISA Trans. 2015, 53, 1650–1660. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.; Feng, J.; Saenko, K. Correlation Alignment for Unsupervised Domain Adaptation. In Domain Adaptation in Computer Vision Applications; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 999–1006. [Google Scholar] [CrossRef]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydeny, Australia, 2–8 December 2013; pp. 2960–2967. [Google Scholar] [CrossRef] [Green Version]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.Q.; Huang, D.S.; Sun, B.Y. Human face recognition based on multi-features using neural networks committee. Pattern Recognit. Lett. 2004, 25, 1351–1358. [Google Scholar] [CrossRef]
- Sun, L.; Chen, J.; Xie, K.; Gu, T. Deep and shallow features fusion based on deep convolutional neural network for speech emotion recognition. Int. J. Speech Technol. 2018, 21, 1–10. [Google Scholar] [CrossRef]
- Han, B.; Ji, S.; Wang, J.; Bao, H.; Jiang, X. An intelligent diagnosis framework for roller bearing fault under speed fluctuation condition. Neurocomputing 2021, 420, 171–180. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wang, Y. An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 2018, 310, 213–222. [Google Scholar] [CrossRef]
- Ali, H.; Azalan, M.S.Z.; Zaidi, A.F.A.; Amran, T.S.T.; Ahmad, M.R.; Elshaikh, M. Feature extraction based on empirical mode decomposition for shapes recognition of buried objects by ground penetrating radar. J. Phys. Conf. Ser. 2021, 1878, 13–20. [Google Scholar] [CrossRef]
- Tang, J.; Liu, Z.; Zhang, J.; Wu, Z.; Chai, T.; Yu, W. Kernel latent features adaptive extraction and selection method for multi-component non-stationary signal of industrial mechanical device. Neurocomputing 2016, 427, 296–309. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. Fault diagnosis based on novel hybrid intelligent model. Chin. J. Mech. Eng. 2008, 44, 112–117. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Wang, K. Fault diagnosis and prognosis using wavelet packet decomposition, fourier transform and artificial neural network. J. Intell. Manuf. 2013, 24, 1213–1227. [Google Scholar] [CrossRef]
- Mallat, S. Group invariant scattering. Commun. Pure Appl. Math. 2012, 65, 1331–1398. [Google Scholar] [CrossRef] [Green Version]
- Case Western Reserve University Bearing Data Center Website. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 16 November 2021).
- Wang, B.; Lei, Y.; Li, N.; Li, N. A hybrid prognostics approach for estimating remaining useful life of rolling element bearings. IEEE Trans. Reliab. 2018, 69, 401–412. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Domain | Target Domain | |
|---|---|---|
| Working Conditions | 1797 | 2250 |
| Sample Numbers | 600 | 900 |
| Vibration Signals in Each Sample | 500 | 500 |
| Fault Type | inner race and outer race wearing | Unknown |
| Label | 1 and 2 | None |
| Approach | Source Samples | Target Samples | Accuracy |
|---|---|---|---|
| Without sigmoid entropy | 600 | 900 | 75.44% |
| Without GFK | 600 | 900 | 79.90% |
| KNN with K = 1 | 600 | 900 | 86.00% |
| Statistical Feature only | 600 | 900 | 92.00% |
| GFK approach | 600 | 900 | 60.17% |
| Proposed Approach | 600 | 900 | 95.56% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Yang, R.; Huang, M. Rolling Bearing Incipient Fault Diagnosis Method Based on Improved Transfer Learning with Hybrid Feature Extraction. Sensors 2021, 21, 7894. https://doi.org/10.3390/s21237894
Yang Z, Yang R, Huang M. Rolling Bearing Incipient Fault Diagnosis Method Based on Improved Transfer Learning with Hybrid Feature Extraction. Sensors. 2021; 21(23):7894. https://doi.org/10.3390/s21237894
Chicago/Turabian StyleYang, Zhengni, Rui Yang, and Mengjie Huang. 2021. "Rolling Bearing Incipient Fault Diagnosis Method Based on Improved Transfer Learning with Hybrid Feature Extraction" Sensors 21, no. 23: 7894. https://doi.org/10.3390/s21237894
APA StyleYang, Z., Yang, R., & Huang, M. (2021). Rolling Bearing Incipient Fault Diagnosis Method Based on Improved Transfer Learning with Hybrid Feature Extraction. Sensors, 21(23), 7894. https://doi.org/10.3390/s21237894