
HARTH: A Human Activity Recognition Dataset for Machine Learning

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Related Work
2.1. Public Har Datasets
2.2. Human Activity Recognition Approaches
3. Methods
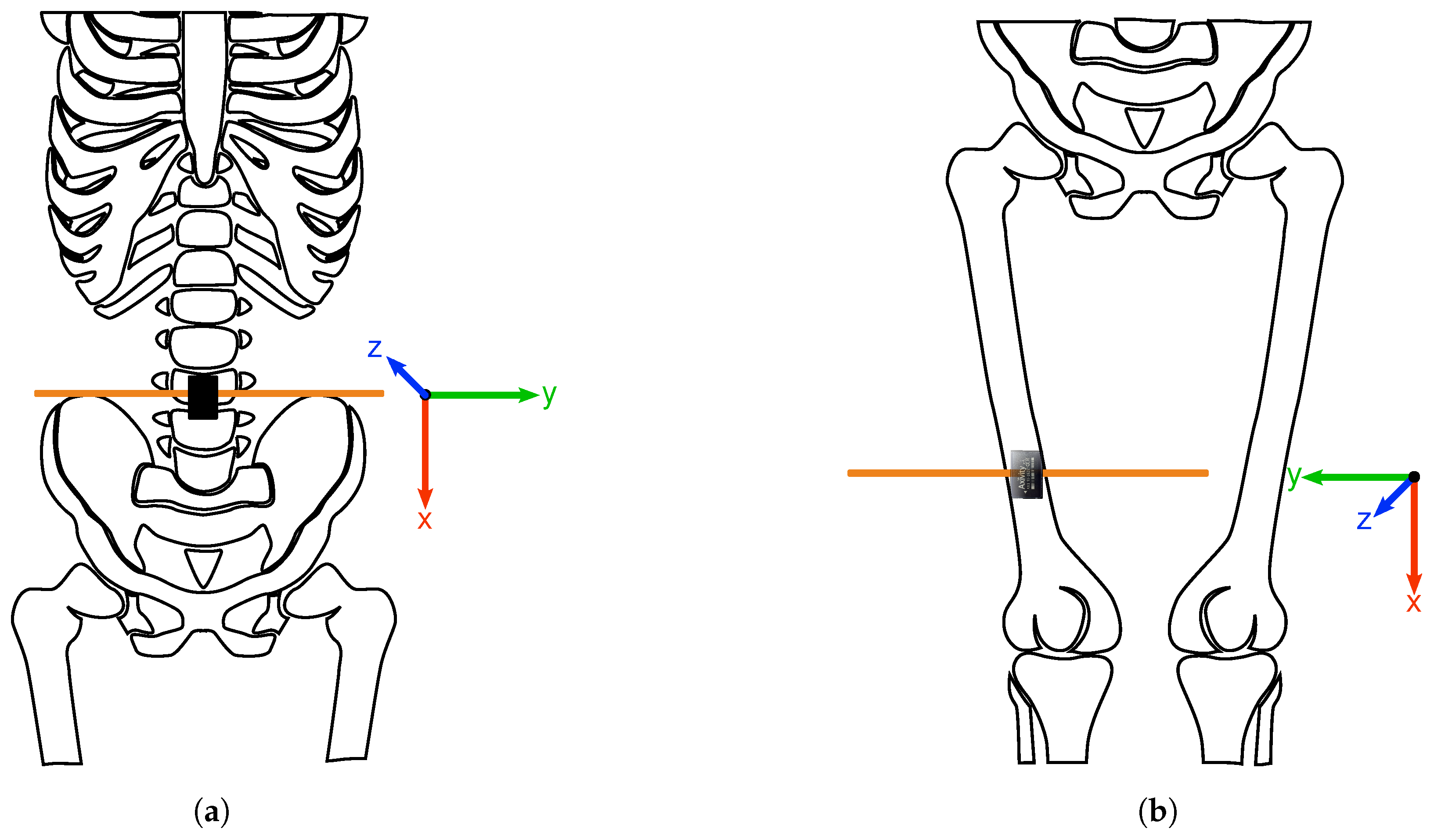
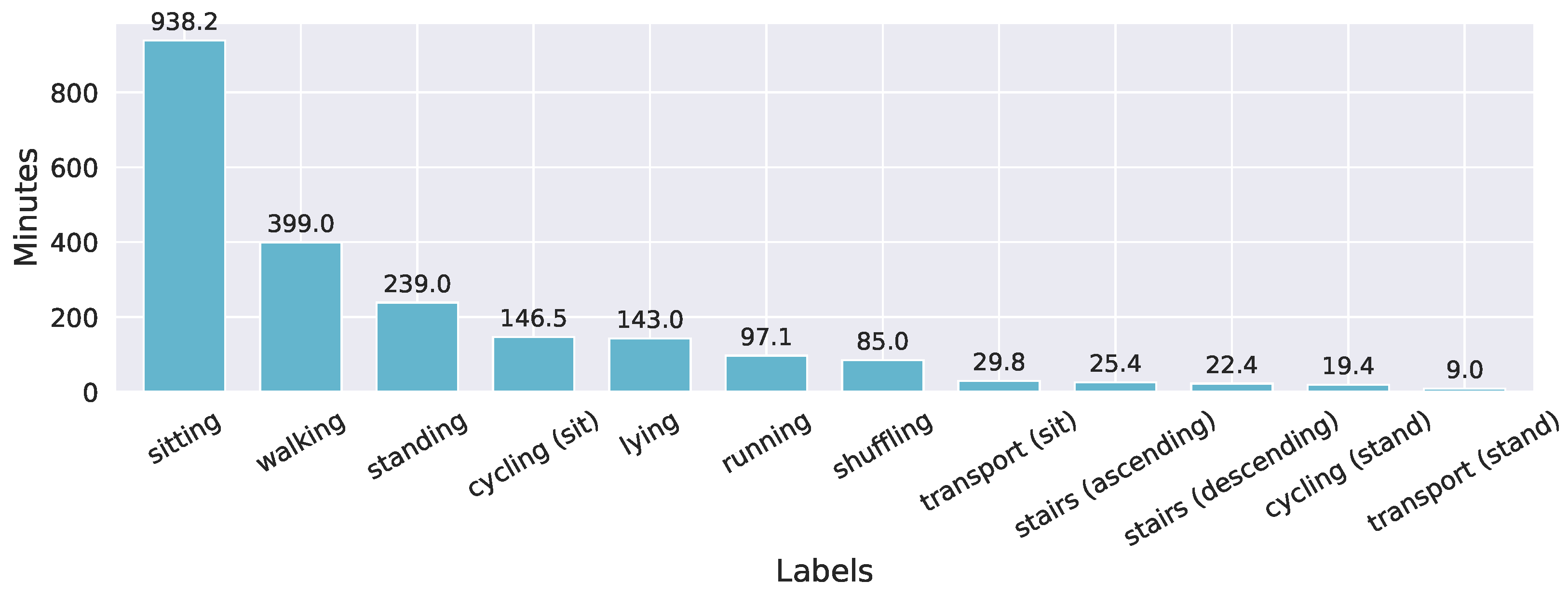
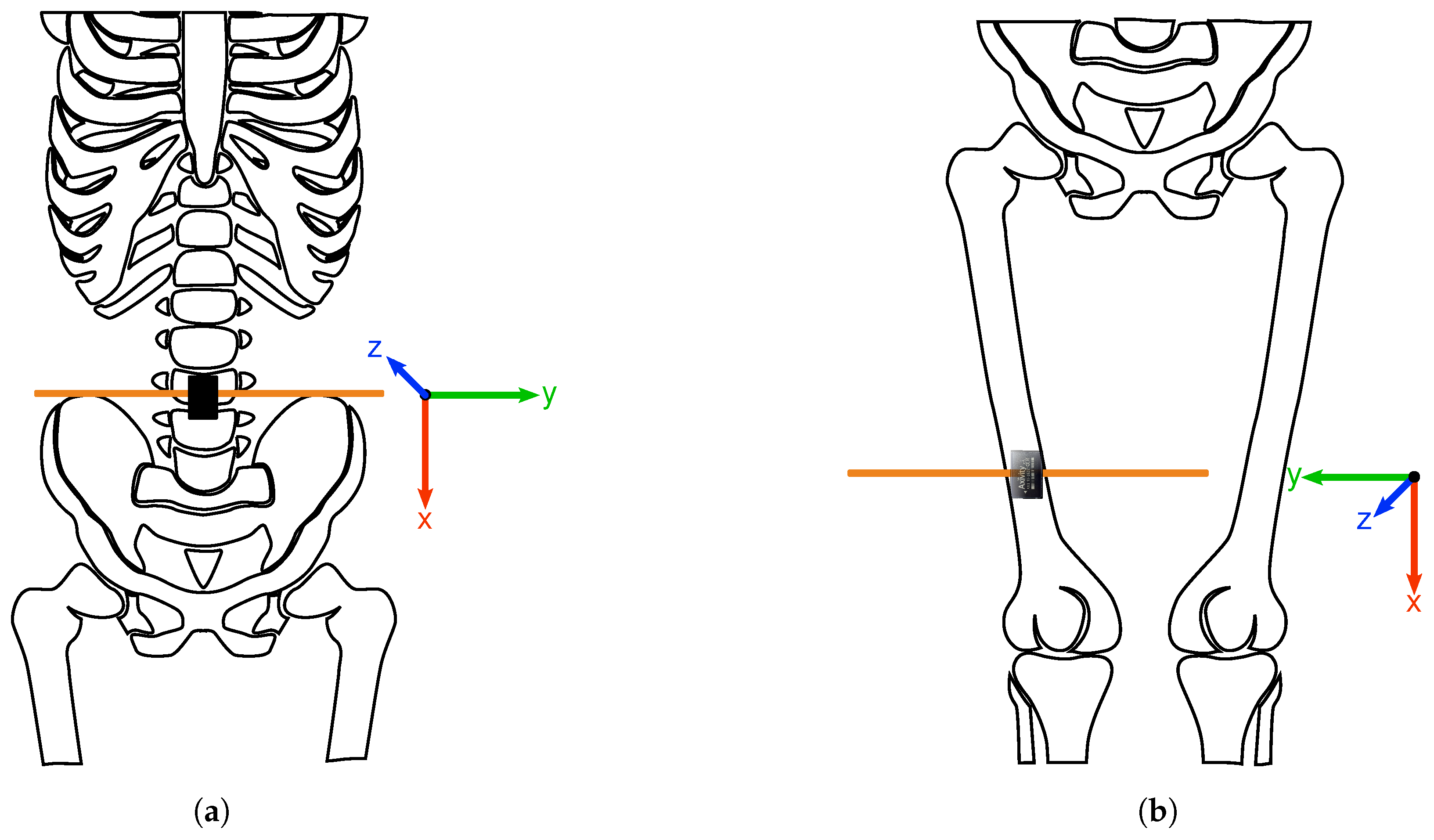
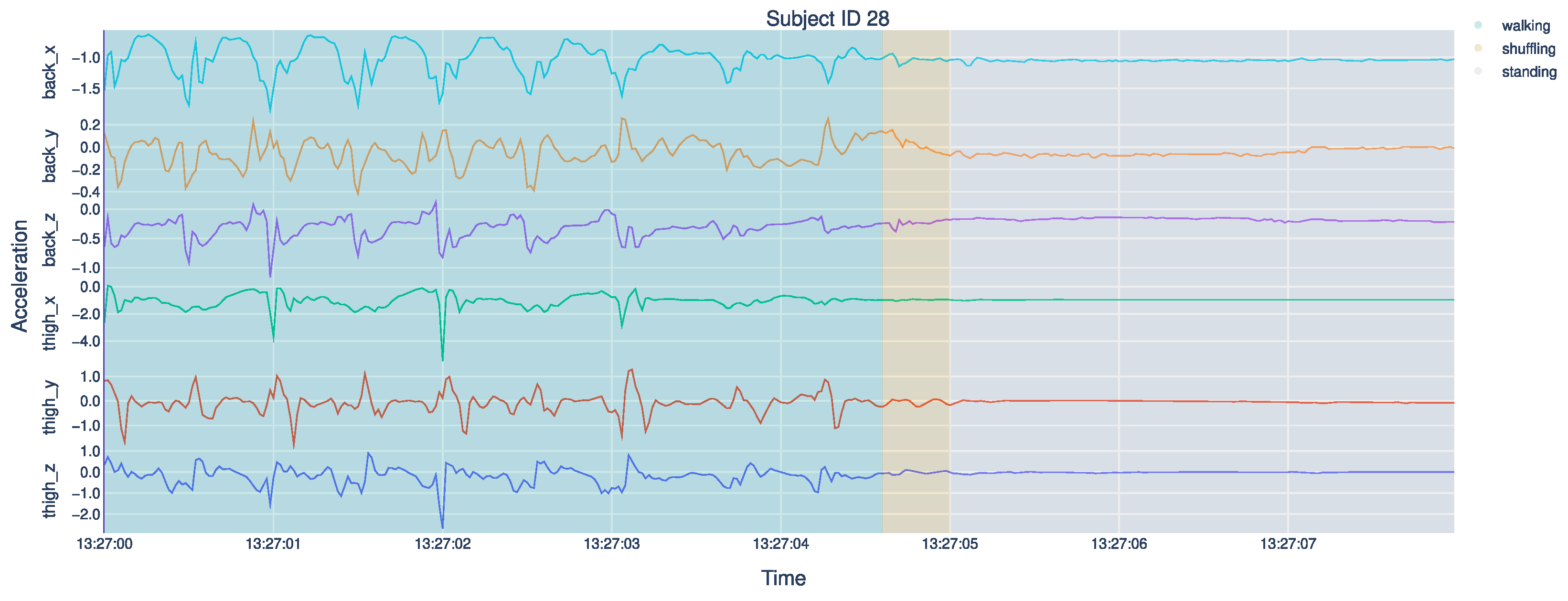
3.1. Human Activity Recognition Trondheim Dataset
3.2. Human Activity Recognition Models
3.2.1. K-Nearest Neighbors
3.2.2. Support Vector Machine
3.2.3. Random Forest
3.2.4. Extreme Gradient Boost
3.2.5. Bidirectional Long Short-Term Memory
3.2.6. Convolutional Neural Network
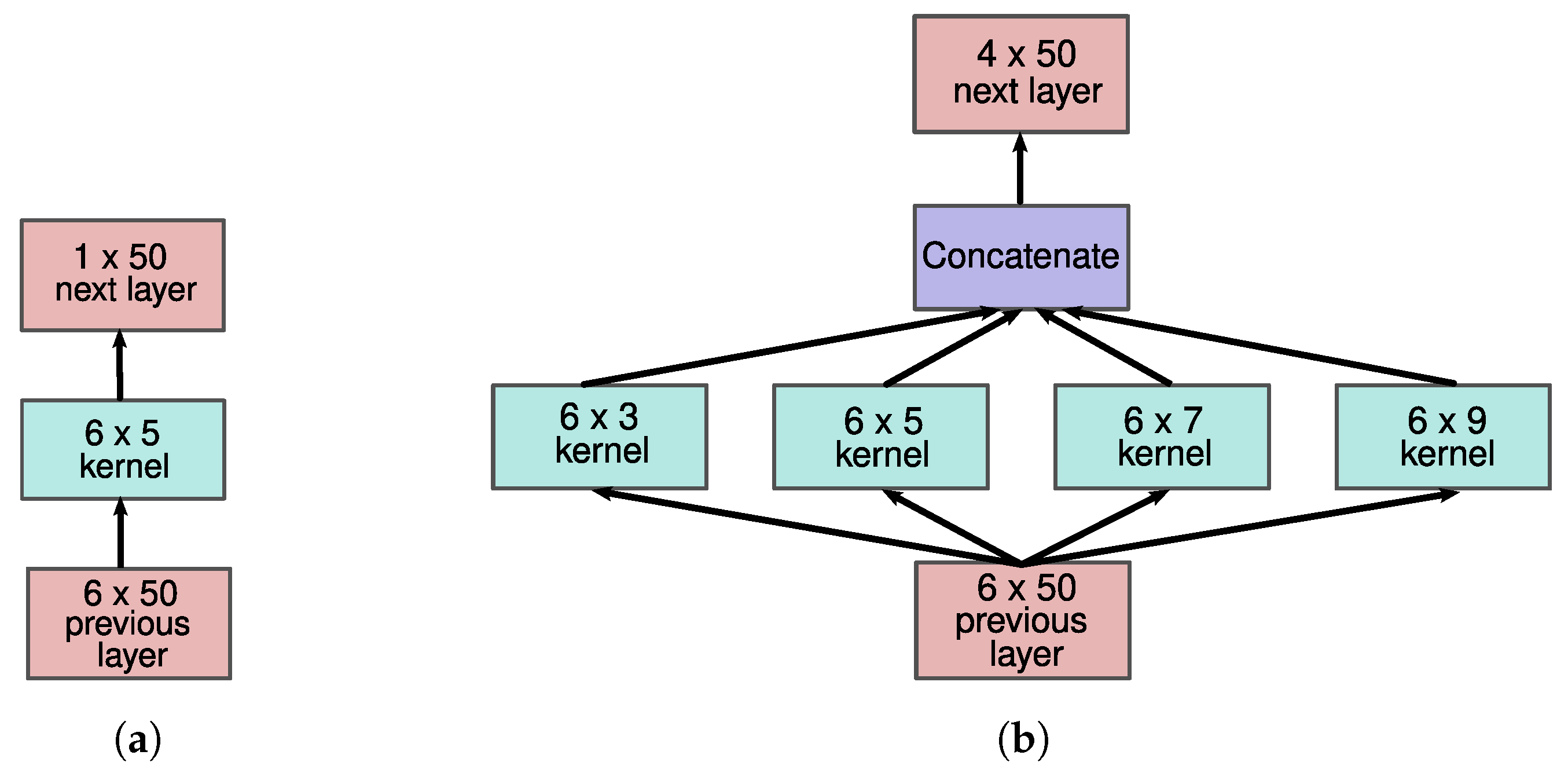
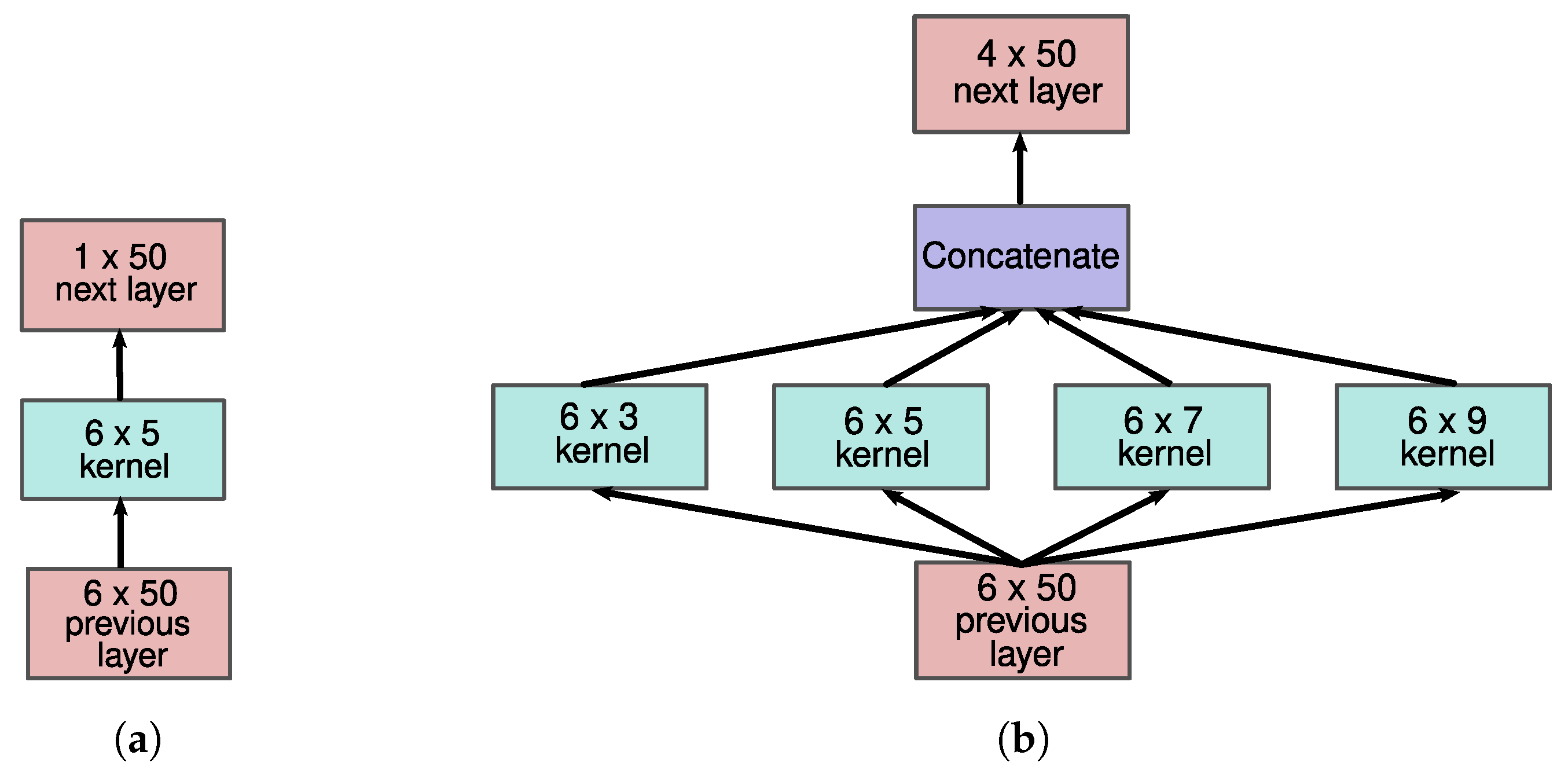
3.2.7. Multi-Resolution CNN
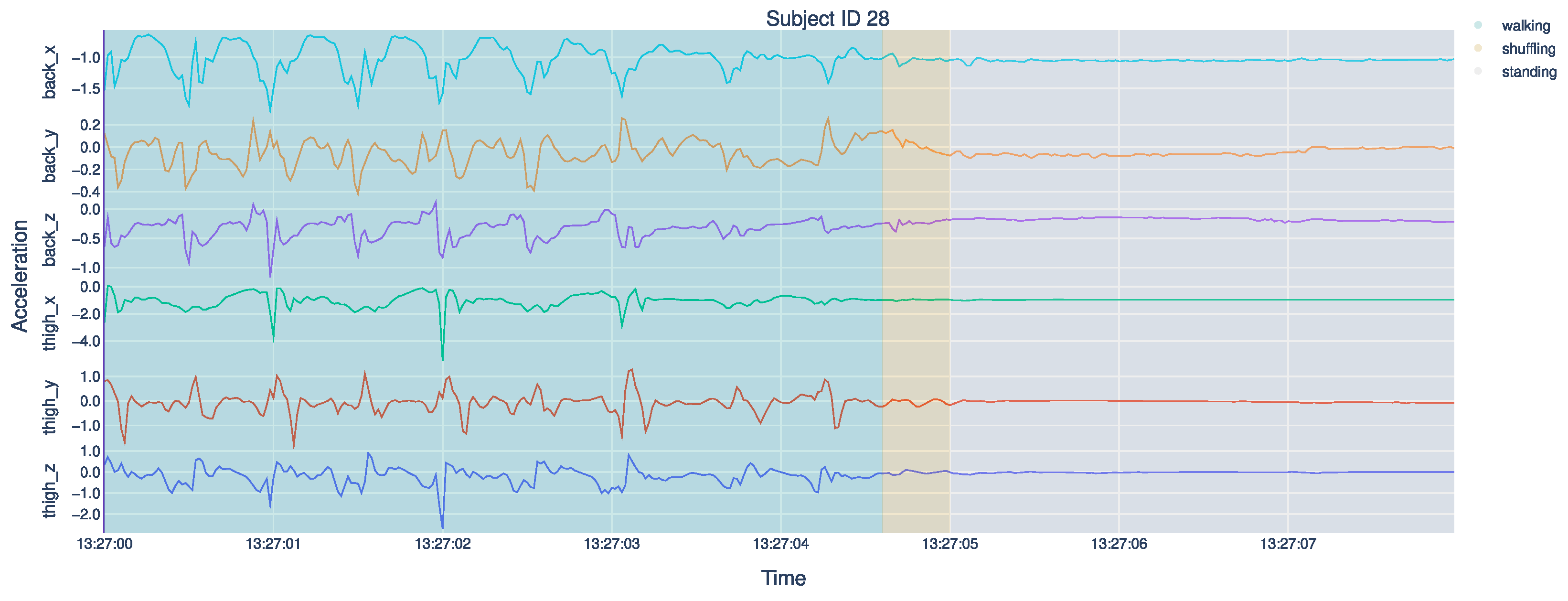
3.3. Preprocessing
4. Experiments and Results
4.1. Hyperparameter Optimization
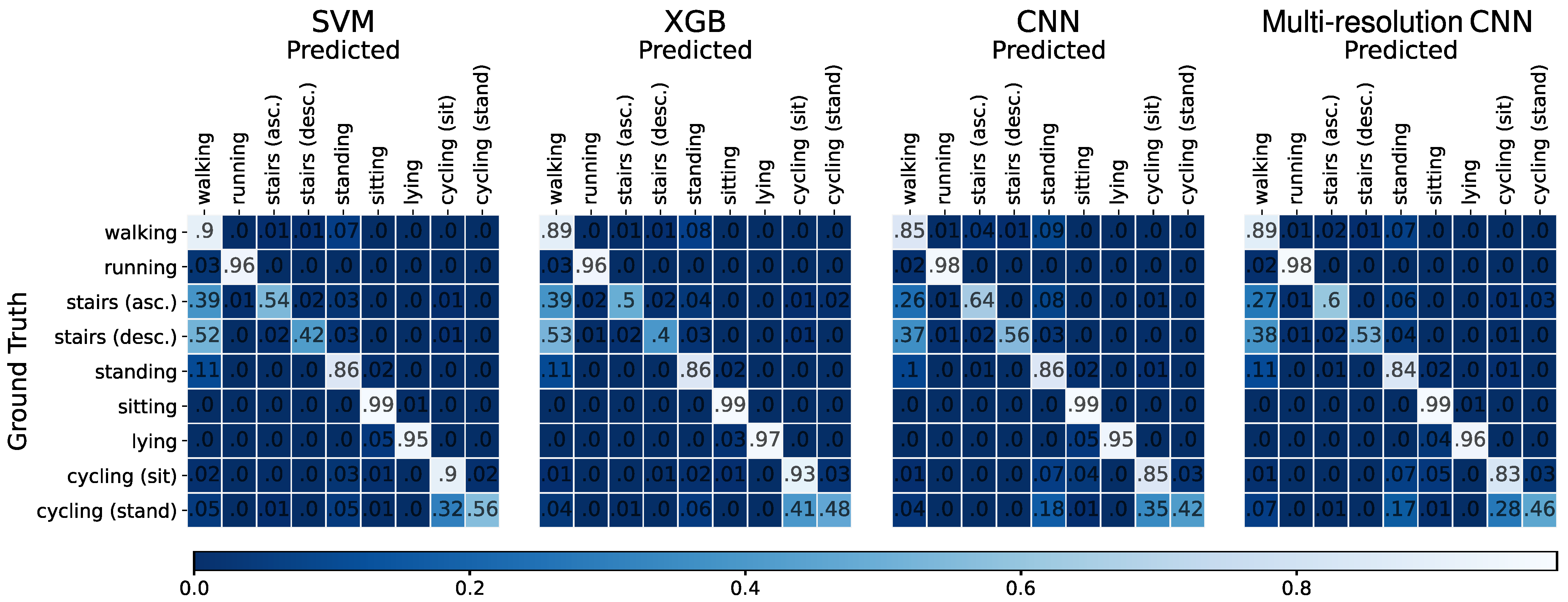
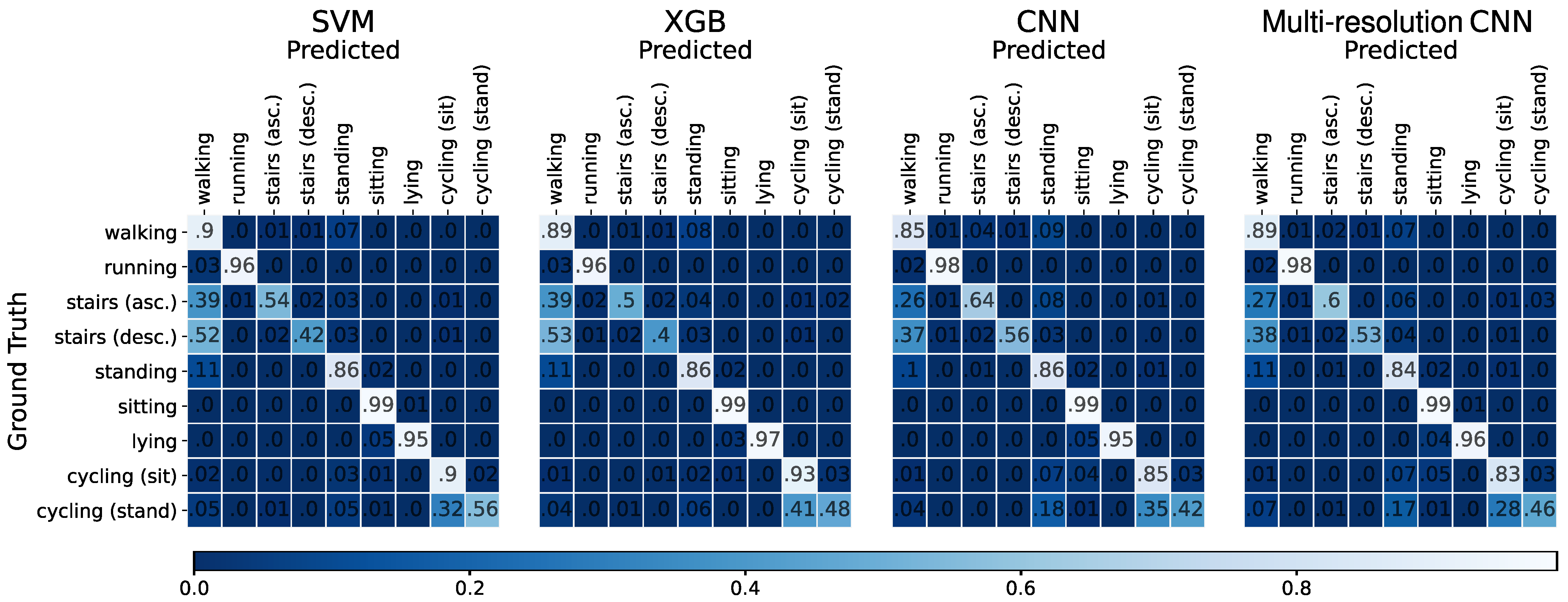
4.2. Leave-One-Subject-Out Cross-Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Definition |
|---|---|
| Sitting | When the person’s buttocks is on the seat of the chair, bed, or floor. Sitting can include some movement in the upper body and legs; this should not be tagged as a separate transition. Adjustment of sitting position is allowed. |
| Standing | Upright, feet supporting the person’s body weight, with no feet movement, otherwise this could be shuffling/walking. Movement of upper body and arms is allowed. If feet position is equal before and after upper body movement, standing can be inferred. Without being able to see the feet, if upper body and surroundings indicate no feet movement, standing can be inferred. |
| Lying | The person lies either on the stomach, on the back, or on the right/left shoulder. Movement of arms, feet, and head is allowed. |
| Walking | Locomotion towards a destination with one stride or more, (one step with both feet, where one foot is placed at the other side of the other). Walking could occur in all directions. Walking along a curved line is allowed. |
| Running | Locomotion towards a destination, with at least two steps where both feet leave the ground during each stride. Running can be inferred when trunk moves forward is in a constant upward-downward motion with at least two steps. Running along a curved line is allowed. |
| Stairs (asc./desc.) | Start: Heel-off of the foot that will land on the first step of the stairs. End: When the heel-strike of the last foot is placed on flat ground. If both feet rests at the same step with no feet movement, standing should be inferred. |
| Shuffling | Stepping in place by non-cyclical and non-directional movement of the feet. Includes turning on the spot with feet movement not as part of walking bout. Without being able to see the feet, if movement of the upper body and surroundings indicate non-directional feet movement, shuffling can be inferred. |
| Cycling (sitting) | Pedaling while the buttocks is placed at the seat. Cycling starts at first pedaling, or when the bike is moving while one/both feet are on the pedal(s). Cycling ends when the first foot is in contact with the ground. If one/both feet are placed on the pedal(s), the buttocks is placed at the seat, with no pedaling and the bike is standing still, this should be tagged as sitting. |
| Cycling (standing) | Standing with both feet on the pedals, while riding a bike. Cycling (standing) starts when the buttocks leave the seat, and ends when the buttocks is placed on the seat. |
| Transport (sitting) | When sitting in a bus/car/train among others. |
| Transport (standing) | When standing in a bus/train among others. Movement of feet while standing is allowed and should not be tagged separately. |
References
- Kohl, H.W.; Craig, C.L.; Lambert, E.V.; Inoue, S.; Alkandari, J.R.; Leetongin, G.; Kahlmeier, S.; Lancet Physical Activity Series Working Group. The pandemic of physical inactivity: Global action for public health. Lancet 2012, 380, 294–305. [Google Scholar] [CrossRef] [Green Version]
- Lee, I.M.; Shiroma, E.J.; Lobelo, F.; Puska, P.; Blair, S.N.; Katzmarzyk, P.T.; Lancet Physical Activity Series Working Group. Effect of physical inactivity on major non-communicable diseases worldwide: An analysis of burden of disease and life expectancy. Lancet 2012, 380, 219–229. [Google Scholar] [CrossRef] [Green Version]
- Pedersen, S.J.; Kitic, C.M.; Bird, M.L.; Mainsbridge, C.P.; Cooley, P.D. Is self-reporting workplace activity worthwhile? Validity and reliability of occupational sitting and physical activity questionnaire in desk-based workers. BMC Public Health 2016, 16, 836. [Google Scholar] [CrossRef] [Green Version]
- Gupta, N.; Christiansen, C.S.; Hanisch, C.; Bay, H.; Burr, H.; Holtermann, A. Is questionnaire-based sitting time inaccurate and can it be improved? A cross-sectional investigation using accelerometer-based sitting time. BMJ Open 2017, 7, e013251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Troiano, R.P.; Berrigan, D.; Dodd, K.W.; Mâsse, L.C.; Tilert, T.; Mcdowell, M. Physical Activity in the United States Measured by Accelerometer. Med. Sci. Sport. Exerc. 2008, 40, 181–188. [Google Scholar] [CrossRef] [PubMed]
- Arvidsson, D.; Fridolfsson, J.; Börjesson, M. Measurement of physical activity in clinical practice using accelerometers. J. Intern. Med. 2019, 286, 137–153. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Lee, J.; Choi, J. Activity Recognition Based on RFID Object Usage for Smart Mobile Devices. J. Comput. Sci. Technol. 2011, 26, 239–246. [Google Scholar] [CrossRef]
- Twomey, N.; Diethe, T.; Fafoutis, X.; Elsts, A.; McConville, R.; Flach, P.; Craddock, I. A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics 2018, 5, 27. [Google Scholar] [CrossRef] [Green Version]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human Activity Recognition Using Inertial, Physiological and Environmental Sensors: A Comprehensive Survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef]
- Fullerton, E.; Heller, B.; Munoz-Organero, M. Recognizing Human Activity in Free-Living Using Multiple Body-Worn Accelerometers. IEEE Sensors J. 2017, 17, 5290–5297. [Google Scholar] [CrossRef] [Green Version]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Stewart, T.; Narayanan, A.; Hedayatrad, L.; Neville, J.; Mackay, L.; Duncan, S. A Dual-Accelerometer System for Classifying Physical Activity in Children and Adults. Med. Sci. Sport. Exerc. 2018, 50, 2595–2602. [Google Scholar] [CrossRef]
- Narayanan, A.; Stewart, T.; Mackay, L. A Dual-Accelerometer System for Detecting Human Movement in a Free-living Environment. Med. Sci. Sport. Exerc. 2020, 52, 252–258. [Google Scholar] [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A new dataset for human activity recognition using acceleration data from smartphones. arXiv 2017, arXiv:1611.07688. [Google Scholar] [CrossRef] [Green Version]
- Reiss, A.; Stricker, D. Creating and benchmarking a new dataset for physical activity monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments—PETRA’12, Heraklion, Greece, 6–8 June 2012; p. 1. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Lockhart, J.W.; Weiss, G.M. Limitations with activity recognition methodology & data sets. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 747–756. [Google Scholar] [CrossRef]
- de Almeida Mendes, M.; da Silva, I.C.M.; Ramires, V.V.; Reichert, F.F.; Martins, R.C.; Tomasi, E. Calibration of raw accelerometer data to measure physical activity: A systematic review. Gait Posture 2018, 61, 98–110. [Google Scholar] [CrossRef]
- Ahmadi, M.N.; Brookes, D.; Chowdhury, A.; Pavey, T.; Trost, S.G. Free-living Evaluation of Laboratory-based Activity Classifiers in Preschoolers. Med. Sci. Sport. Exerc. 2020, 52, 1227–1234. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, M.N.; Pavey, T.G.; Trost, S.G. Machine Learning Models for Classifying Physical Activity in Free-Living Preschool Children. Sensors 2020, 20, 4364. [Google Scholar] [CrossRef]
- Cuba Gyllensten, I.; Bonomi, A. Identifying Types of Physical Activity With a Single Accelerometer: Evaluating Laboratory-trained Algorithms in Daily Life. IEEE Trans. Biomed. Eng. 2011, 58, 2656–2663. [Google Scholar] [CrossRef] [PubMed]
- Cleland, I.; Kikhia, B.; Nugent, C.; Boytsov, A.; Hallberg, J.; Synnes, K.; McClean, S.; Finlay, D. Optimal placement of accelerometers for the detection of everyday activities. Sensors 2013, 13, 9183–9200. [Google Scholar] [CrossRef] [Green Version]
- Olguín, D.O.; Pentland, A. Human activity recognition: Accuracy across common locations for wearable sensors. In Proceedings of the IEEE 10th International Symposium on Wearable Computers, Montreaux, Switzerland, 11–14 October 2006; pp. 11–13. [Google Scholar]
- Garcia-Gonzalez, D.; Rivero, D.; Fernandez-Blanco, E.; Luaces, M.R. A Public Domain Dataset for Real-Life Human Activity Recognition Using Smartphone Sensors. Sensors 2020, 20, 2200. [Google Scholar] [CrossRef] [Green Version]
- Ichino, H.; Kaji, K.; Sakurada, K.; Hiroi, K.; Kawaguchi, N. HASC-PAC2016: Large scale human pedestrian activity corpus and its baseline recognition. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 705–714. [Google Scholar]
- Lockhart, J.W.; Weiss, G.M.; Xue, J.C.; Gallagher, S.T.; Grosner, A.B.; Pulickal, T.T. Design considerations for the WISDM smart phone-based sensor mining architecture. In Proceedings of the Fifth International Workshop on Knowledge Discovery from Sensor Data, San Diego, CA, USA, 21 August 2011; pp. 25–33. [Google Scholar] [CrossRef] [Green Version]
- Weiss, G.; Lockhart, J. The Impact of Personalization on Smartphone-Based Activity Recognition. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Sztyler, T.; Carmona, J.; Völker, J.; Stuckenschmidt, H. Self-tracking Reloaded: Applying Process Mining to Personalized Health Care from Labeled Sensor Data. In Transactions on Petri Nets and Other Models of Concurrency XI; Koutny, M., Desel, J., Kleijn, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 160–180. [Google Scholar] [CrossRef] [Green Version]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing Detailed Human Context in the Wild from Smartphones and Smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Carpineti, C.; Lomonaco, V.; Bedogni, L.; Felice, M.D.; Bononi, L. Custom Dual Transportation Mode Detection By Smartphone Devices Exploiting Sensor Diversity. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 367–372. [Google Scholar] [CrossRef] [Green Version]
- Wold, T.; Skaugvoll, S.A.E. Ensemble Classifier Managing Uncertainty in Accelerometer Data within HAR Systems. Ph.D. Thesis, Norwegian University of Science and Technology’s, Trondheim, Norway, 2019. [Google Scholar]
- About HUNT-The Nord-Trøndelag Health Study-NTNU. Available online: https://www.ntnu.edu/hunt/about-hunt (accessed on 16 November 2021).
- Skapis. Available online: https://www.hjart-lungfonden.se/ (accessed on 16 November 2021).
- WG3 • DE-PASS|COST ACTION CA19101. Available online: https://depass.eu/working-groups/wg3/ (accessed on 16 November 2021).
- Jepsen, R.; Egholm, C.L.; Brodersen, J.; Simonsen, E.; Grarup, J.; Cyron, A.; Ellervik, C.; Rasmussen, K. Lolland-Falster Health Study: Study protocol for a household-based prospective cohort study. Scand. J. Public Health 2020, 48, 382–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gjoreski, H.; Ciliberto, M.; Morales, F.J.O.; Roggen, D.; Mekki, S.; Valentin, S. A Versatile Annotated Dataset for Multimodal Locomotion Analytics with Mobile Devices. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; pp. 1–2. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Gjoreski, H.; Ciliberto, M.; Mekki, S.; Valentin, S.; Roggen, D. Enabling Reproducible Research in Sensor-Based Transportation Mode Recognition With the Sussex-Huawei Dataset. IEEE Access 2019, 7, 10870–10891. [Google Scholar] [CrossRef]
- Herrera-Alcántara, O.; Barrera-Animas, A.Y.; González-Mendoza, M.; Castro-Espinoza, F. Monitoring Student Activities with Smartwatches: On the Academic Performance Enhancement. Sensors 2019, 19, 1605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kawaguchi, N.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Inoue, S.; Kawahara, Y.; Sumi, Y.; Nishio, N. HASC Challenge: Gathering large scale human activity corpus for the real-world activity understandings. In Proceedings of the 2nd Augmented Human International Conference, Tokyo, Japan, 13 March 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Kawaguchi, N.; Yang, Y.; Yang, T.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Inoue, S.; Kawahara, Y.; et al. HASC2011corpus: Towards the common ground of human activity recognition. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 571–572. [Google Scholar] [CrossRef] [Green Version]
- Kawaguchi, N.; Watanabe, H.; Yang, T.; Ogawa, N.; Iwasaki, Y.; Kaji, K.; Terada, T.; Murao, K.; Hada, H.; Inoue, S.; et al. HASC2012corpus: Large Scale Human Activity Corpus and Its Application. In Proceedings of the Second International Workshop of Mobile Sensing: From Smartphones and Wearables to Big Data, Beijing, China, 16–20 April 2012; pp. 10–14. [Google Scholar]
- Kaji, K.; Watanabe, H.; Ban, R.; Kawaguchi, N. HASC-IPSC: Indoor pedestrian sensing corpus with a balance of gender and age for indoor positioning and floor-plan generation researches. In Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013; pp. 605–610. [Google Scholar] [CrossRef]
- Elhattab, A.; Uddin, N.; OBrien, E. Extraction of Bridge Fundamental Frequencies Utilizing a Smartphone MEMS Accelerometer. Sensors 2019, 19, 3143. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. Human Activity Recognition via an Accelerometer-Enabled-Smartphone Using Kernel Discriminant Analysis. In Proceedings of the 5th International Conference on Future Information Technology, Busan, Korea, 21–23 May 2010; pp. 1–6, ISSN 2159-7014. [Google Scholar] [CrossRef]
- Axivity. Available online: https://axivity.com/ (accessed on 16 November 2021).
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In Pervasive Computing; Lecture Notes in Computer Science; Ferscha, A., Mattern, F., Eds.; Springer: Berlin, Heidelberg, 2004; pp. 1–17. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Scholten, H.; Havinga, P.J.M.; Incel, O.D. Towards detection of bad habits by fusing smartphone and smartwatch sensors. In Proceedings of the IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), St. Louis, MO, USA, 23–27 March 2015; pp. 591–596. [Google Scholar] [CrossRef]
- Gao, L.; Bourke, A.K.; Nelson, J. Evaluation of accelerometer based multi-sensor versus single-sensor activity recognition systems. Med. Eng. Phys. 2014, 36, 779–785. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Baños, O.; Damas, M.; Pomares, H.; Rojas, I.; Tóth, M.A.; Amft, O. A benchmark dataset to evaluate sensor displacement in activity recognition. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 1026–1035. [Google Scholar] [CrossRef]
- Maurer, U.; Smailagic, A.; Siewiorek, D.; Deisher, M. Activity recognition and monitoring using multiple sensors on different body positions. International Workshop on Wearable and Implantable Body Sensor Networks (BSN’06), Cambridge, MA, USA, 3–5 April 2006; pp. 4–116, ISSN 2376-8894. [Google Scholar] [CrossRef]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Proceedings of the SBIA 2012: 21th Brazilian Symposium on Artificial Intelligence, Curitiba, Brazil, 20–25 October 2012; pp. 52–61. [Google Scholar] [CrossRef] [Green Version]
- Zubair, M.; Song, K.; Yoon, C. Human activity recognition using wearable accelerometer sensors. In Proceedings of the IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 26–28 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Gupta, R.; Gupta, A.; Aswal, R. Time-CNN and Stacked LSTM for Posture Classification. In Proceedings of the International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–5, ISSN 2329-7190. [Google Scholar] [CrossRef]
- Atallah, L.; Lo, B.; King, R.; Yang, G.Z. Sensor Positioning for Activity Recognition Using Wearable Accelerometers. IEEE Trans. Biomed. Circuits Syst. 2011, 5, 320–329. [Google Scholar] [CrossRef]
- Chawathe, S.S. Recognizing Human Falls and Routine Activities Using Accelerometers. In Proceedings of the IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 120–126. [Google Scholar] [CrossRef]
- Cheng, L.; Guan, Y.; Zhu, K.; Li, Y. Recognition of human activities using machine learning methods with wearable sensors. In Proceedings of the IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Cheng, L.; Li, Y.; Guan, Y. Human activity recognition based on compressed sensing. In Proceedings of the IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Dehghani, A.; Sarbishei, O.; Glatard, T.; Shihab, E. A Quantitative Comparison of Overlapping and Non-Overlapping Sliding Windows for Human Activity Recognition Using Inertial Sensors. Sensors 2019, 19, 5026. [Google Scholar] [CrossRef] [Green Version]
- Guiry, J.J.; van de Ven, P.; Nelson, J. Classification techniques for smartphone based activity detection. In Proceedings of the IEEE 11th International Conference on Cybernetic Intelligent Systems (CIS), Limerick, Ireland, 23–24 August 2012; pp. 154–158. [Google Scholar] [CrossRef]
- Awais, M.; Chiari, L.; Ihlen, E.A.F.; Helbostad, J.L.; Palmerini, L. Physical Activity Classification for Elderly People in Free-Living Conditions. IEEE J. Biomed. Health Inform. 2019, 23, 197–207. [Google Scholar] [CrossRef]
- GoPro, I. Available online: https://gopro.com/ (accessed on 16 November 2021).
- Kipp, M. ANVIL: The Video Annotation Research Tool; Oxford University Press: Oxford, UK, 2014; pp. 420–436. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J. Discriminatory Analysis—Nonparametric Discrimination: Consistency Properties; Technical Report; University of California: Berkeley, CA, USA, 1951. [Google Scholar]
- Dudani, S.A. The Distance-Weighted k-Nearest-Neighbor Rule. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 325–327. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 2047–2052. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Yu, S.; Qin, L. Human Activity Recognition with Smartphone Inertial Sensors Using Bidir-LSTM Networks. In Proceedings of the 3rd International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Huhhot, China, 14–16 September 2018; pp. 219–224. [Google Scholar] [CrossRef]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Google-Books-ID:omivDQAAQBAJ. [Google Scholar]
- Nonis, F.; Barbiero, P.; Cirrincione, G.; Olivetti, E.C.; Marcolin, F.; Vezzetti, E. Understanding Abstraction in Deep CNN: An Application on Facial Emotion Recognition. In Progresses in Artificial Intelligence and Neural Systems; Esposito, A., Faundez-Zanuy, M., Morabito, F.C., Pasero, E., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2021; pp. 281–290. [Google Scholar] [CrossRef]
- Pham, C.; Nguyen-Thai, S.; Tran-Quang, H.; Tran, S.; Vu, H.; Tran, T.H.; Le, T.L. SensCapsNet: Deep Neural Network for Non-Obtrusive Sensing Based Human Activity Recognition. IEEE Access 2020, 8, 86934–86946. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Karantonis, D.; Narayanan, M.; Mathie, M.; Lovell, N.; Celler, B. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window size impact in human activity recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Finizola, J.S.; Targino, J.M.; Teodoro, F.G.S.; de Moraes Lima, C.A. A Comparative Study Between Deep Learning and Traditional Machine Learning Techniques for Facial Biometric Recognition. Advances in Artificial Intelligence–IBERAMIA 2018; Lecture Notes in Computer Science; Simari, G.R., Fermé, E., Gutiérrez Segura, F., Rodríguez Melquiades, J.A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 217–228. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. On the Personalization of Classification Models for Human Activity Recognition. IEEE Access 2020, 8, 32066–32079. [Google Scholar] [CrossRef]


| Name | #Labels | #PAs | #Subjects | #Accelero. | Sensor Type | Annotation |
|---|---|---|---|---|---|---|
| Real-life-HAR [24] | 4 | 2 | 19 | 1 | Smartphone | User |
| SHL [36,37] | 8 | 5 | 3 | 4 | Smartphone | User and expert |
| HASC-PAC2016 [25] | 6 | 6 | 81 | 1 | Smartphone | User |
| WISDMv2.0 [26,27] | 6 | 6 | 225 | 1 | Smartphone | User |
| DailyLog [28] | 19 | 7 | 7 | 2 | Smartphone & Smartwatch | User |
| ExtraSensory [29] | 51 | 8 | 60 | 2 | Smartphone & Smartwatch | User |
| TMD [30] | 5 | 3 | 13 | 1 | Smartphone | User |
| SDL [38] | 10 | 4 | 8 | 1 | Smartwatch | User |
| HARTH (ours) | 12 | 9 | 22 | 2 | Axivity AX3 | Human experts |
| k-NN | SVM | RF | XGB | BiLSTM | CNN | mCNN | |
|---|---|---|---|---|---|---|---|
| Recall | |||||||
| Precision | |||||||
| F1-score |
| k-NN | SVM | RF | XGB | BiLSTM | CNN | mCNN | |
|---|---|---|---|---|---|---|---|
| Recall | |||||||
| Precision | |||||||
| F1-score |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Logacjov, A.; Bach, K.; Kongsvold, A.; Bårdstu, H.B.; Mork, P.J. HARTH: A Human Activity Recognition Dataset for Machine Learning. Sensors 2021, 21, 7853. https://doi.org/10.3390/s21237853
Logacjov A, Bach K, Kongsvold A, Bårdstu HB, Mork PJ. HARTH: A Human Activity Recognition Dataset for Machine Learning. Sensors. 2021; 21(23):7853. https://doi.org/10.3390/s21237853
Chicago/Turabian StyleLogacjov, Aleksej, Kerstin Bach, Atle Kongsvold, Hilde Bremseth Bårdstu, and Paul Jarle Mork. 2021. "HARTH: A Human Activity Recognition Dataset for Machine Learning" Sensors 21, no. 23: 7853. https://doi.org/10.3390/s21237853
APA StyleLogacjov, A., Bach, K., Kongsvold, A., Bårdstu, H. B., & Mork, P. J. (2021). HARTH: A Human Activity Recognition Dataset for Machine Learning. Sensors, 21(23), 7853. https://doi.org/10.3390/s21237853