1. Introduction
Concrete structures are now a very familiar sight due to their features and the ready availability of their materials. Concrete houses, concrete towers, concrete bridges, and numerous other structures have become a fundamental part of the modern day. Concrete has been proven to be a durable material which can withstand even extreme conditions [
1], such as fire, weather hazards, and chemical attack. An example of this can be seen in the Pantheon, which has remained in marvelous condition after almost 1900 years. Structural concrete requires reinforcing bars (rebars) to support the bending and torsional loads. Although the rebar offers superior tensile strength and is an essential part, it lowers the lifetime of concrete significantly due to rusting and crack problems. Therefore, it is essential to monitor in-service structures.
Among concrete structures, the beam is one of the most important subjects in structural health monitoring (SHM) topics, as its function is to support loading from above and to withstand compression and tension. For investigating concrete beams, visual monitoring is often used as the most basic technique; however, it cannot be efficiently performed if the location is not accessible/visible. Many studies have been proposed with different non-destructive approaches: the image processing technique [
2,
3,
4], ultrasonic [
5,
6,
7], vibration [
8,
9,
10], acoustic emission [
11,
12,
13,
14], etc. Among them, the prominence of acoustic emission (AE) techniques has increased in recent years as a solution for concrete monitoring and for general prognosis and health management (PHM) frameworks. By definition, acoustic emission is the elastic energy internally released by materials when a discontinuity appears. In comparison to other non-destructive techniques, acoustic emission testing is non-directional and little to no downtime is required during in-service testing. Moreover, this method is also superior in terms of being capable of dynamic progression tracking of the discontinuity and evaluating the significance of the deterioration in a single test. The recorded events have a now-or-never quality [
15], which means that if an event of discontinuity is not detected at the moment of its occurrence, it would not be available at any other time. However, with consistent improvements in data recording and processing, this problem can be approached with ease. The notable downside of acoustic emission testing is that it cannot detect an existing discontinuity, but given its foremost application of progression monitoring, this is not of interest, as the specimen’s initial condition should be fully investigated before performing an AE test.
Service life can be extended significantly if failure is detected and a RUL prognosis is made in an early stage and the structure is correspondingly maintained. For this purpose, multiple authors have addressed the cracking phenomenon [
16,
17,
18,
19] in ongoing studies. Along with these studies, a number of fault detection and diagnosis (FFD) techniques [
20,
21] have been proposed in recent decades with the aim of prolonging service life. While diagnosis deals with current and past faults, what we might look for in prognosis is how the accumulated faults might affect the specimen in the future. The remaining useful life (RUL), also known as the prognostic distance or lead time, is a crucial metric used in prognosis. By definition, it is the time from when the specimen is under inspection to the moment its useful life ends [
22,
23]. In general, RUL prediction methods can be roughly sorted into two different approaches: model-based and data-based.
While the model-based approach relies on establishing a mathematical model to imitate a real-life process, which can be exponentially hard with more sophisticated models, the data-based approach is centered around capturing the fault patterns with available data. Without having to investigate both the nature of the system and the fault, the second approach is significantly less complicated, and therefore more favorable in the latest studies [
24]. The data-based approach is our primary focus in this study.
With the bloom of machine learning techniques in recent years, the data-based approach has gained numerous benefits [
25] compared with the earlier days when statistical methods and principal component analysis were still state-of-the-art approaches. Recent studies concerning AE-based RUL prognosis have been presented with promising results: the authors in [
26] suggested the use of adaptive non-homogenous hidden semi Markov model to predict life of composite structures, while those in [
27] and others in [
28] respectively proposed the use of support vector machine regression and Gaussian process regression for slow speed bearings, etc. With the success of recent deep learning techniques, which have been widely adapted to many areas [
25], automatic feature extraction and direct mapping from raw input to output classes have demonstrated promising competency. Our study proposes the use of direct construction of health indicator (HI) lines from raw inputs using a deep neural network (DNN), which is fine-tuned after a stacked autoencoder (SAE) pre-train. Because the number of AE hits during a period of time, which are detected with a constant false-alarm rate (CFAR) [
11], a neural network can portray the severity of the deterioration, as it harnesses the input data labels for the training. These HI lines are then used in a long short-term memory recurrent neural network (LSTM-RNN) for HI prediction. The LSTM-RNN is utilized rather than a conventional RNN due to its ability to store and process long-term dependencies, as the data in this study can be considered a long-term time series [
25]. From the predicted HI lines, the RUL can be computed accordingly.
In order to provide a closer RUL prediction, it is essential to improve the hit detection process, which is representative of the specimen’s deterioration severity. When a specimen is fractured, its structure is altered. During a time of high AE intensity and with small test specimens, an AE event might cause more than one hit in a sensor (due to reflection, hit spit, refraction, etc.) [
29,
30] which, with the accumulation over time, can affect how the total number of hits affect the portrait of deterioration severity. There are methods proposed to address such problems, for instance, the two time-driven parameters hit definition time (HDT) and hit lockout time (HLT). However, given that these methods are hard-threshold based, they are susceptible to stochastic phenomena, which can be used to describe the concrete fracture process [
29]. Consequently, these pre-set parameters will induce errors, even with careful instrument calibration. In these cases, the implementation of a hit removal process is very important. In our study, we focus on identifying the anomalous hits that differ the most from others through one-class support vector machine (OC-SVM) [
31,
32].
The following contributions are proposed in this study:
A novel hit removal process is proposed using OC-SVM for a better portrait of deterioration process, which has not been investigated in other studies to the best of the authors’ knowledge.
The construction of HI lines from raw data through a SAE-DNN with AE hits detected with the CFAR as the training label.
RUL prediction based on the LSTM-RNN which outputs HI prediction from the lines constructed in an offline process.
The arrangement of the following sections is as follows:
Section 2 provides the experimental setup along with a description of the dataset; the methodology is discussed in detail in
Section 3;
Section 4 shows the results of our method, with discussion, which is followed by concluding remarks, along with a discussion of future research directions, provided in
Section 5.
3. Methodology
Prior to the description of the methodology, we need to clarify some definitions. An AE event is the release of elastic energy when the subject undergoes deformation. A hit can be considered as the way a transducer (in this circumstance, an AE sensor) perceives the event from its point of view. In this paper, we will discuss events and hits only from AE view, hence from here, an AE event is referred to as “an event” only, just as “a hit” represents the term of an AE hit.
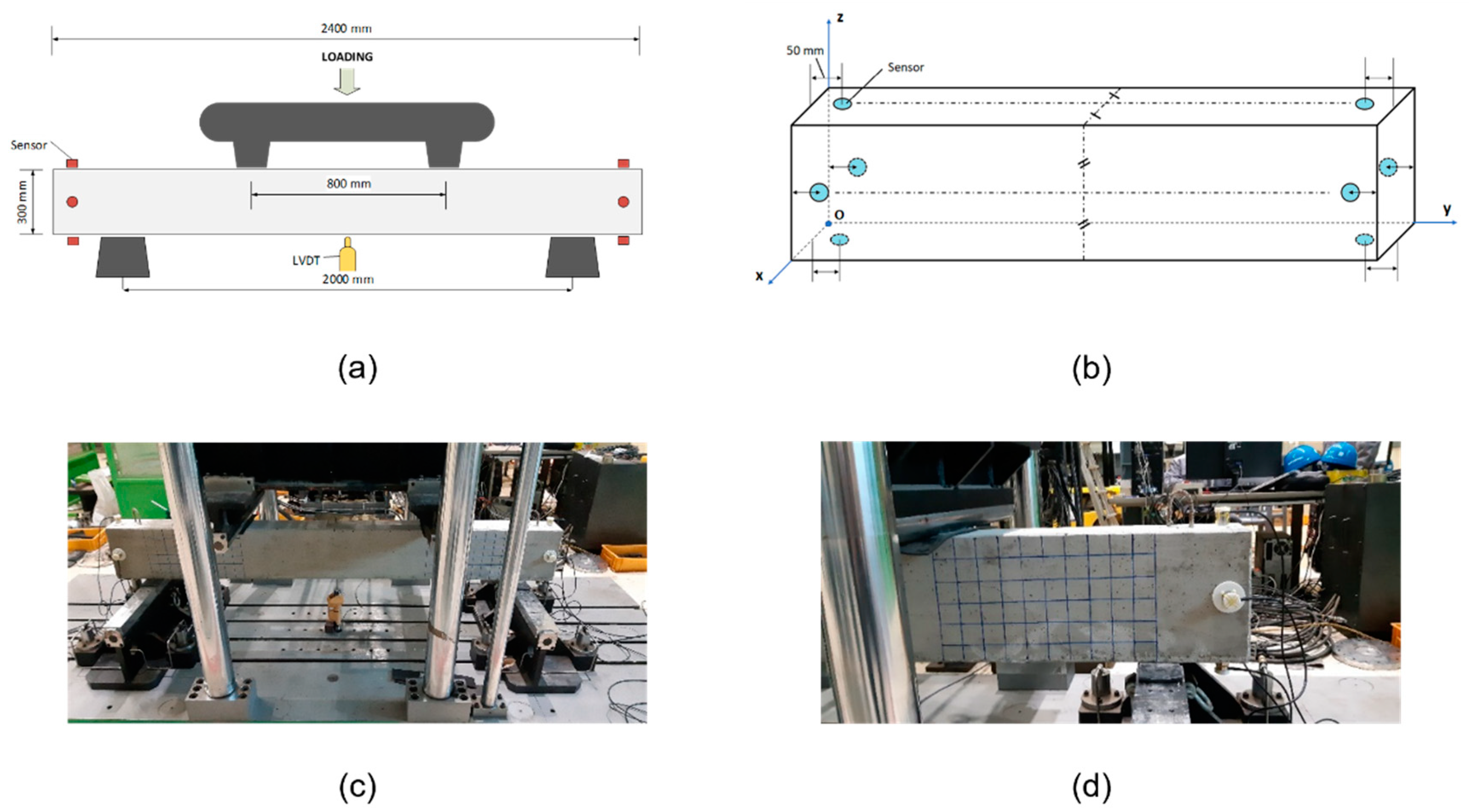
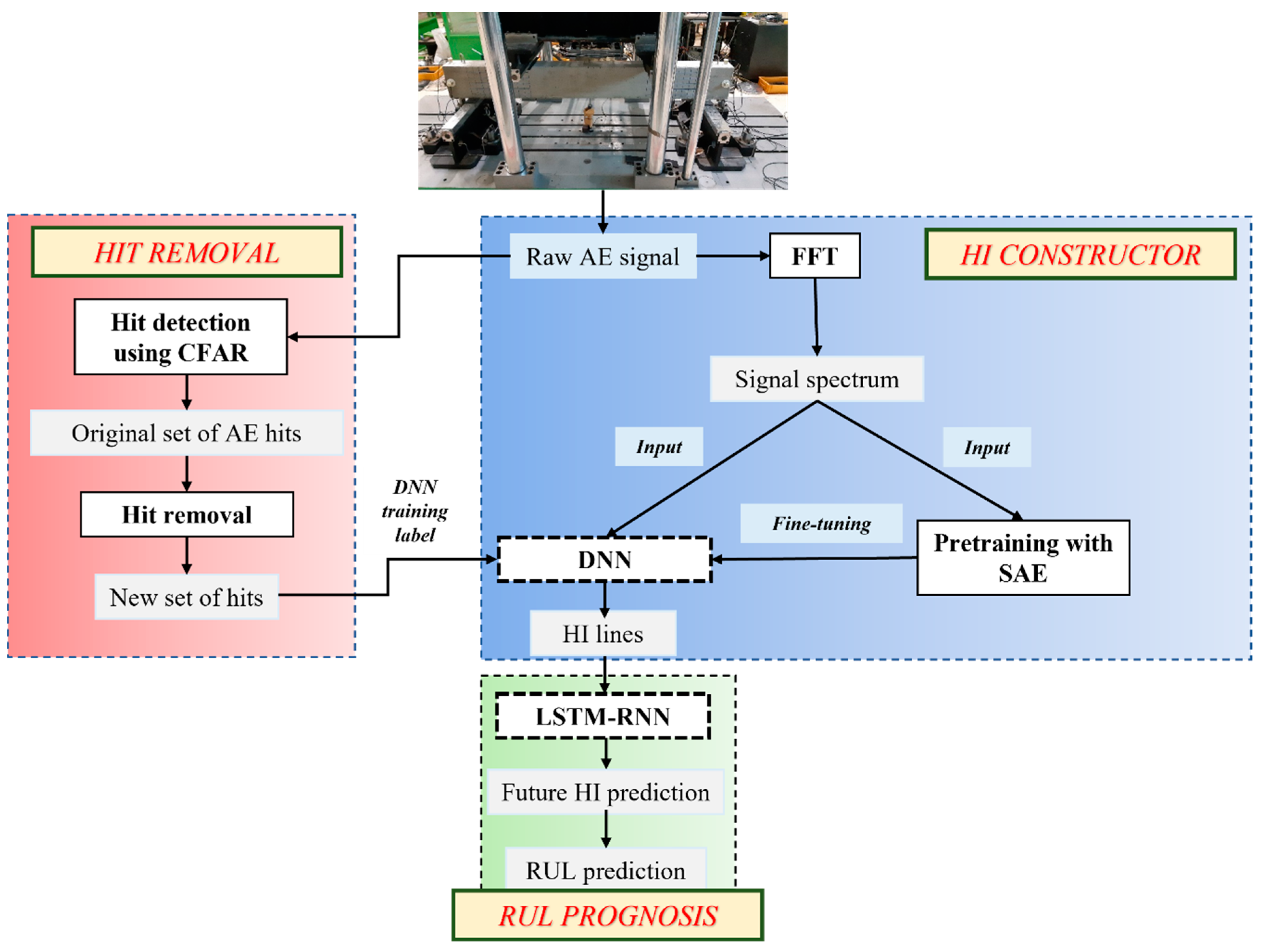
The general framework of our proposed approach is shown in
Figure 3.
3.1. Hit Detection Using CFAR
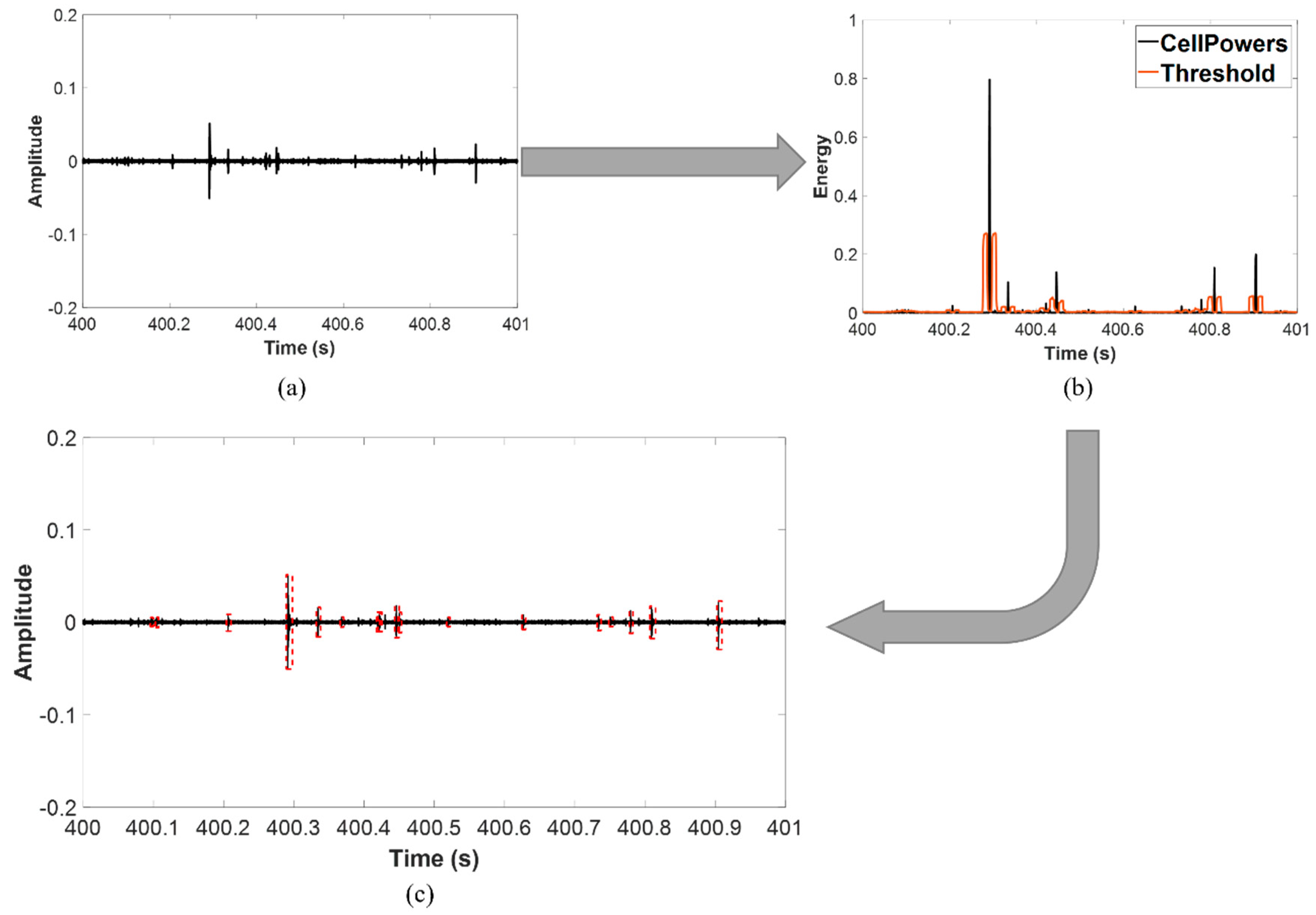
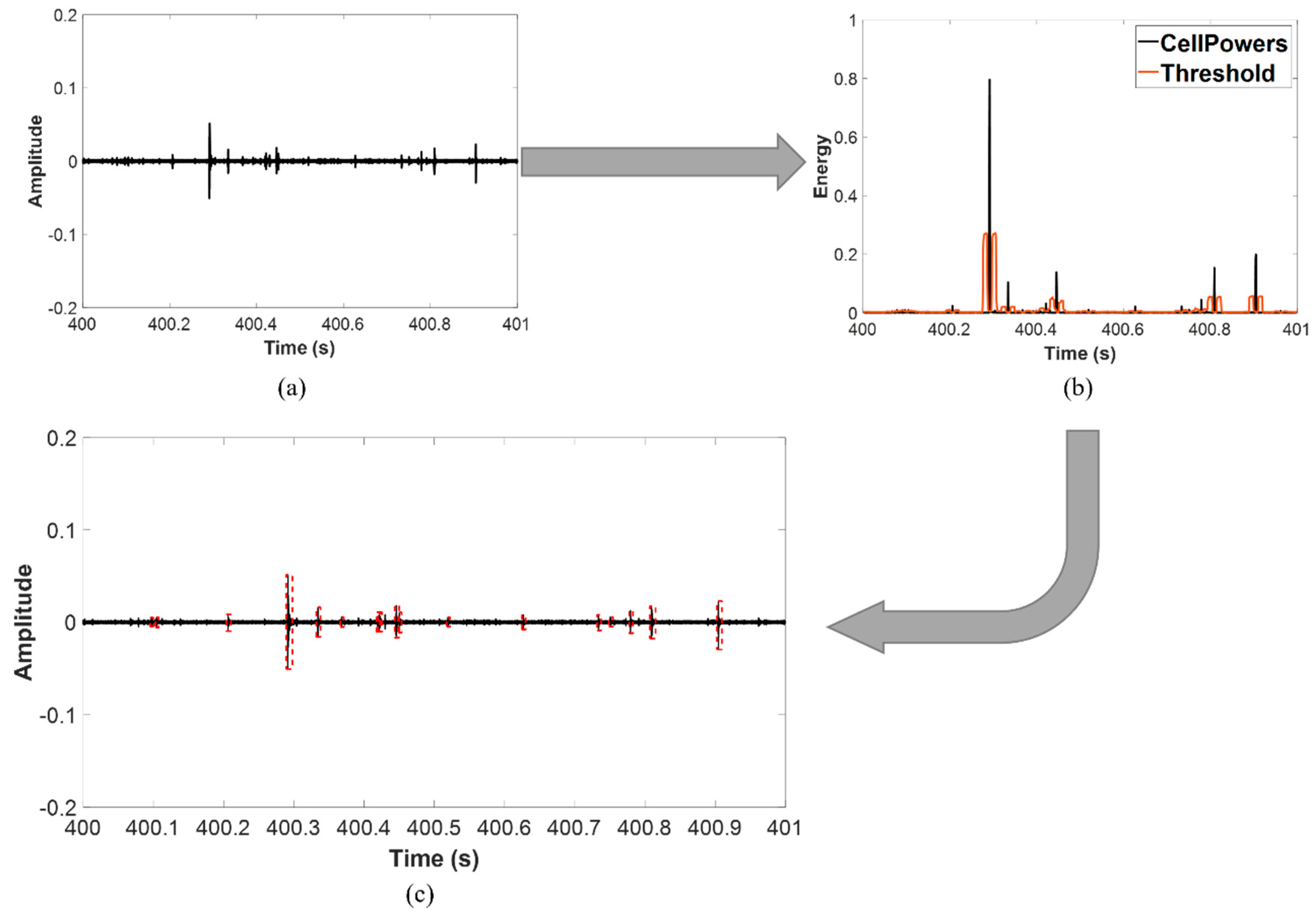
The process starts with hit extraction from data, which is done using the average constant false alarm rate (CFAR). The CFAR is an algorithm first introduced for target detection in radar systems. Due to its ability to solve real-life problems in which the noise is usually colored and its variance is often unknown, CFAR can be imported to various applications, one of which is hit detection.
Since the recorded signal is one-dimensional, the model for the CFAR can be seen in
Figure 4.
The training cells are protected by the leading and lagging guard cells, which prevent signal components from leaking into them. When a given cell is required to be checked, the noise power is then estimated from its neighboring cells. The threshold for this cell under test (CUT) can be then calculated as follows:
where
is the threshold factor and
is the estimated power of the noise. In this study, cell averaging of the CFAR [
33] was implemented, therefore, the estimated power of the noise and the threshold factor can be achieved through the following calculations:
where
is the number of training cells,
is the sample in each training cell and Pfa is the desired false alarm rate. The desired false alarm rate should be chosen with precaution, because it affects the number of detected hits and the number of false alarms. With a higher
, it is expected that more hits are registered, however, at the expense of a high rate of false hits. This is the opposite with a lower
. Given this observation, it is of the utmost importance to choose a proper value of the
. In this report, the
was set to 1% and each 1-s-long signal was segmented into 2000 cells for processing. The number of training and guard cells for each side of the CUT are both 10. The idea is that when the CUT’s power is higher than the threshold, the algorithm deduces that there is at least one target included in this region.
3.2. Hit Removal Process with OC-SVM
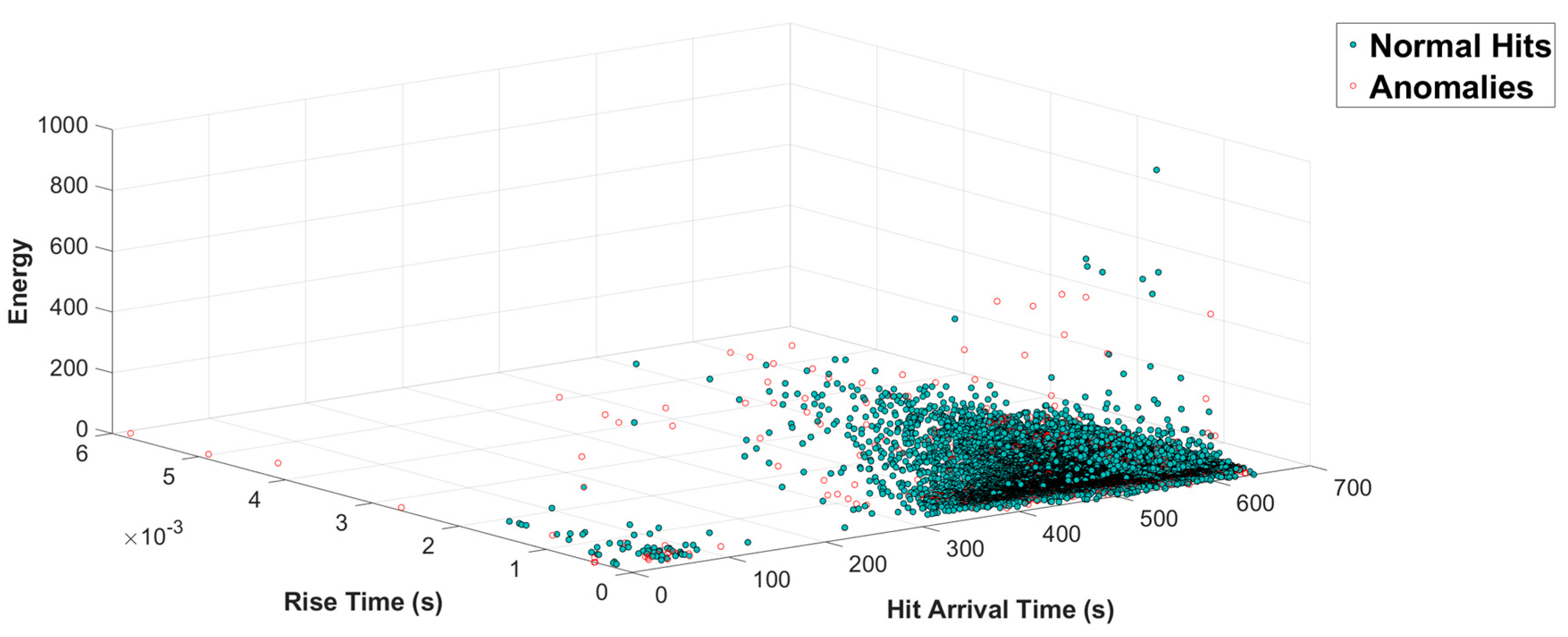
As mentioned previously, a hit is the way a sensor “sees” an AE event. Typically, at a sensor, only one direct hit can be achieved from its original event. However, in reality, more than one hit can be registered for the same event due to reflection, hit split, refraction, etc., especially when the specimen is small in size and damaged to a certain degree. In our test, the specimens undergo intense AE activity during the second phase of loading. With the progression of cracks, they no longer retain their original acoustic profile due to both external and internal damage. During this period, the number of hits is especially high. The number of non-direct hits through reflection and refraction is also expected to be significant in such a circumstance. Therefore, in order to get the most accurate number of hits to portray the deterioration, a process of hit removal is essential. Compared to the direct hit from a same source, the non-direct one(s) are delayed in time and less significant in amplitude. This, however, is yet to be distinguished with hits recorded from a more distant source. Therefore, to remove the unwanted hits without having to sacrifice the hits originating from distant events, we focus only on the ones that are very different from the rest (anomalies). Through this process, the DNN can learn to construct HI lines closer to the actual specimen state.
The support vector machine (SVM) was first introduced in 1992 by Vapnik V.N. et al. [
33] and quickly became one of the most popular machine learning methods. Primarily, the SVM handles classification tasks using multidimensional-space hyperplanes for the separation of different classes. The reason behind its popularity and its great power with nonlinear separable data is the kernel trick. The kernel trick, in short, can make a non-linear problem into a linear one by projecting it to a higher dimension where it is linearly solvable.
As a natural extension of SVM, the purpose of one-class SVM (OC-SVM) fundamentally revolves around class separation, but the change is that the separation is harnessed to differentiate the “suspicious” observations (anomalies) from the rest of the data. This algorithm focuses on two aspects: 1—the estimation of a probability distribution function that is more likely to include the majority of data than the rest; 2—the decision rule which ensures the largest possible margin during the separation of these observations.
The original OC-SVM version by Schölkopf et al. [
31] utilizes the kernel trick to capture regions in the input space where the probability density of the data points resides in a binary function and returns +1 in such a region, whereas −1 is returned for the rest. The quadratic programming minimization function of OC-SVM is not too much different from that of the original SVM:
which is subject to:
with
being the slack variables that allow data points to be within the margin,
C as the penalty parameter which characterizes the trade-off between the number of data points within the margin and how big the margin is.
The decision function is achieved after solving this minimization problem with Lagrange multipliers:
Instead of the planar approach used by the original SVM, Tax and Duin‘s OC-SVM (SVDD) [
32] focuses on a spherical approach. What can be obtained from this approach is a spherical boundary, which is characterized by a center A and a radius R. This approach’s minimization problem is as follows:
which is subject to:
Again, by using Lagrange multipliers, it can be simplified as follows:
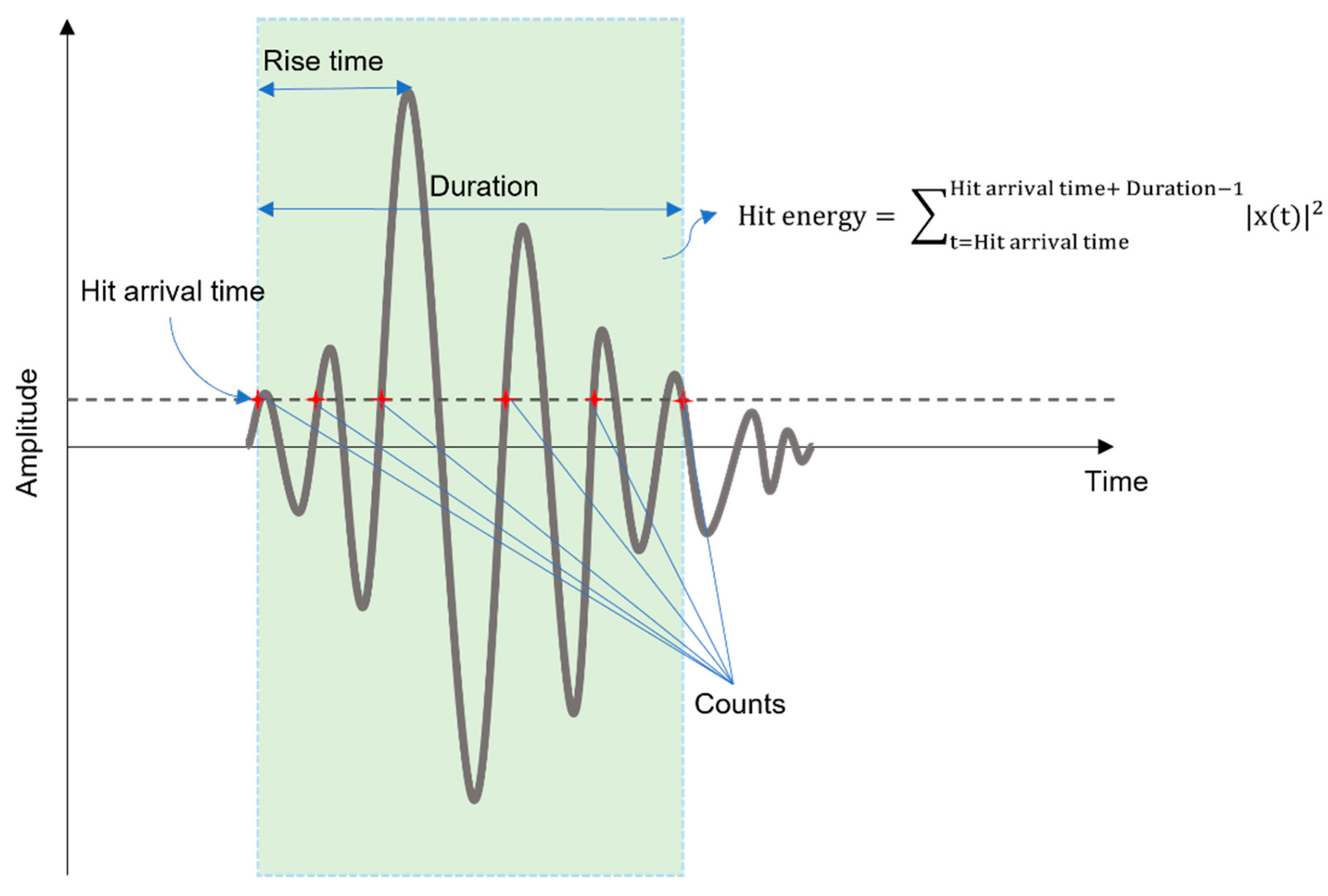
In our study, the version of OC-SVM proposed by Tax and Duin is utilized along with the Radial Basis Function (RBF) kernel. The data of channels 5 to 8 from the three tests’ second phase are utilized for the training as one class. The trained OC-SVM is then utilized to seek for anomalies in the remaining set of data, which is later utilized as the training label for the DNN, which is to be discussed in the following section. Our OC-SVM considers hit arrival time, duration, hit energy, rise time of the hit, and hit counts for the process of anomaly detection. These characteristics of a hit are illustrated in
Figure 5.
3.3. HI Constructor Using SAE-DNN
In order to get the HI lines that are later utilized for the RUL prediction, the process initiates with the construction of the DNN which outputs these curves. The DNN is designed so that it takes in the signal spectrum and outputs the HI in the range of [0, 1]. At the start, fast Fourier transform (FFT) is applied to each one-second segment of the signal, which returns 2.5 × 106 data points. However, since that number is undesirably large, the spectrum is divided into 2000 equal bands, each with an approximated energy that is calculated through the root mean square (RMS). This vector of size 2000 is fed to the stacked autoencoder (SAE) for the pre-training purpose. The encoder has three dense layers with diminishing sizes from 1000 to 200 to 10 with Xavier initialization and an exponential linear unit (ELU) activation function that are then utilized to process these data. Afterward, the decoder with three size-increasing dense layers from 200 to 1000 to 2000 takes in the encoder’s output for the reconstruction. The SAE’s regularization can be improved by adding dropout layers with a rate of 0.1 preceding the dense layers. Unlabeled signal spectra are harnessed as both inputs and outputs for SAE training along with Adam optimization and the fractions of masked zero at 0.1.
Following the training of the SAE, the encoder’s layers are reused as hidden layers in our DNN model, which also includes a logistic regression layer at the top. Fine-tuning is then performed in a supervised manner with an output size of one regarding the normalized number of AE hits in the range of [0, 1]. Since the number of hits represent how much damage the specimen takes at a moment, these values of normalized AE hit number can be considered the health indicator. The learning ability of high-level features from low-level ones of the SAE model is preserved by freezing the reused layers during DNN training, along with early stopping and checkpoint techniques to achieve the best parameters.
3.4. RUL Prognosis Using LSTM-RNN
Previously, the problem of vanishing and exploding gradients in RNN training had been a major problem. However, with the birth of LSTM, came a solution, especially for temporal sequences and long-range dependency models. What makes LSTM superior to the conventional RNN is the introduction of different gates and components, such as hidden units and memory cells, which allow the model to retain and process the information stored for a long time.
There are a total number of three main types of gates for LSTM: the input gate, forget gate, and output gate. The general idea of these gates is that they regulate the flow of information through storing, writing, and reading via gate opening or closing.
The forget gate
’s role is to determine whether to keep or dispose a piece of information. The current input
and hidden state
are fed to a logistic activation function, whose output represents the necessity of the information. The result
equal to 0 indicates that the information is not needed and the gate is hence closed while it being 1 shows the opposite. Later,
is utilized for an element-wise multiplication operation. Overall, the forget gate’s calculation is performed as follows:
Subsequently, the evaluation of the new information is conducted before determining whether to store it in the internal state. The current input
and previous hidden state
are once again fed to a sigmoid activation function to achieve
and then to a tanh function afterward to output
. This tanh layer, which can sometimes be referred to as an “input modulation gate”, constructs a candidate state vector
. The role of the input gate is to find the supplementation for the long-term state
from
.
and
are achieved as follows:
Following the calculations in Equations (8)–(10), the current state is computed from the previous internal state
as follows:
Thereupon, the output gate
decides which parts of the long-term state can be read and output through evaluation. The remaining state values are acquired by passing the internal state
through a tanh layer and then by multiplication with the output of the sigmoid gate, which is computed by the equation below:
with:
where
and
are the layer’s weight and bias, respectively.
Each data stream, which is a sequence of values along with time steps, can be considered a univariate time series. Each stream is utilized to train the RUL-predictor LSTM with segments of size 50. The segments are achieved by sliding a 50-value-long window with a step of 1 along the series. The model is adjusted such that it has to make a forecast at every time step rather than just the final one, which allows the loss to contain a term for every time step. This enables more error gradients to flow through the model, which leads to both faster training and stabilization at the same time [
25]. When the data is assigned to a certain point in time, the predicted time step at the last moment is used as the 50th value in the next window for further computation.
In our model, the input layer is followed by two hidden LSTM layers of size 20. The dense output layer of size 1 harnesses a linear activation function. Both early stopping and checkpoints are similarly utilized during training, as with the previous DNN construction.
5. Conclusions
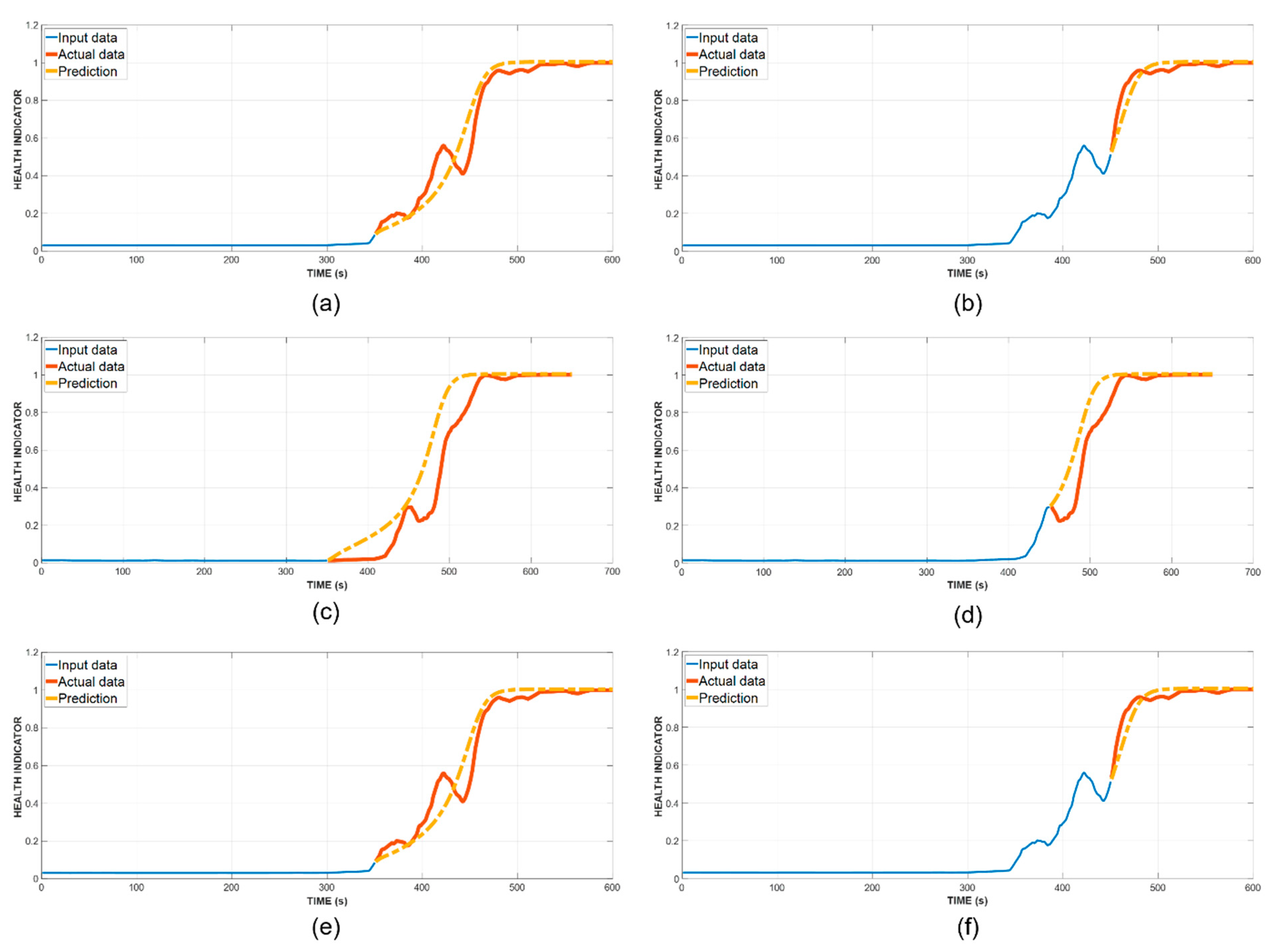
In this paper, we presented a scheme of remaining useful life (RUL) prognosis from raw acoustic emission (AE) signals. From the raw signals, a health indicator (HI) constructor based on deep neural network pretrained and fine-tuned with stacked autoencoder (SAE-DNN), whose training is performed with AE hits as the label. We also proposed that the AE hits utilized for DNN training are processed through a hit removal process in advance, which filters out the ones that stray the furthest from the other hits. With the aforementioned process, the DNN can construct better HI lines which later are a vital part of RUL prediction.
After the DNN constructs HI lines from raw AE data, these lines are fed into the long short-term memory recurrent neural network (LSTM-RNN) for prognosis. To verify the validity of our method, we performed two RUL estimations for each of the three tests at the passing of the 350th and 450th s, with regard to the fact that they mark the start of micro and macro fractures, respectively. The results obtained from the proposed method show significant improvement over the reference methods, such as gated recurrent unit recurrent neural network (GRU-RNN) and recurrent neural network (RNN). Furthermore, a performance comparison is made between the proposed scheme and a similar scheme without the hit removal process, which also indicates notable amelioration in RUL prediction.
For upcoming studies, this method can be further extended to other concrete structures such as walls, buildings, etc. Other approaches to RUL prognosis instead of an LSTM-RNN are also considered for future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}