
Evaluation of HPC Acceleration and Interconnect Technologies for High-Throughput Data Acquisition

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Avoid dedicated network interfaces, but rather rely on standard infra- and inter-node interconnect technologies;
- Leave most of the space in the FPGA device for user acceleration, rather than using it for implementing the networking facilities;
- Follow the scaling of the interconnect technology, particularly InfiniBand, so that future performance will not be constrained by the custom FPGA implementation of the network interface.
2. Background and Key Technologies
Key Technologies
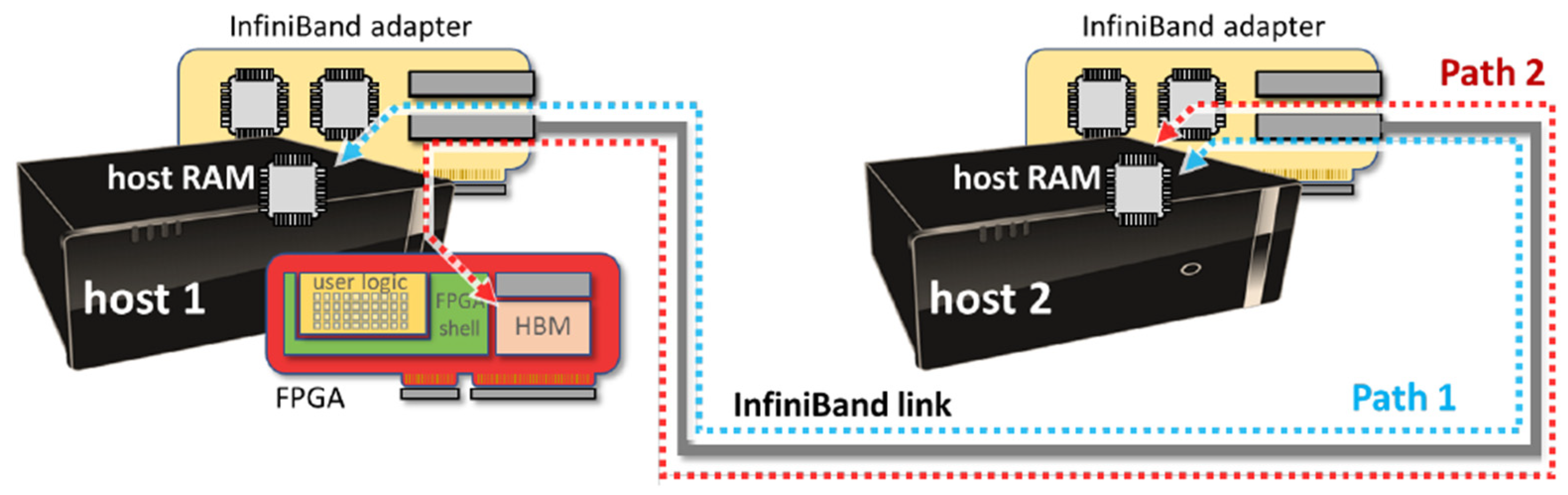
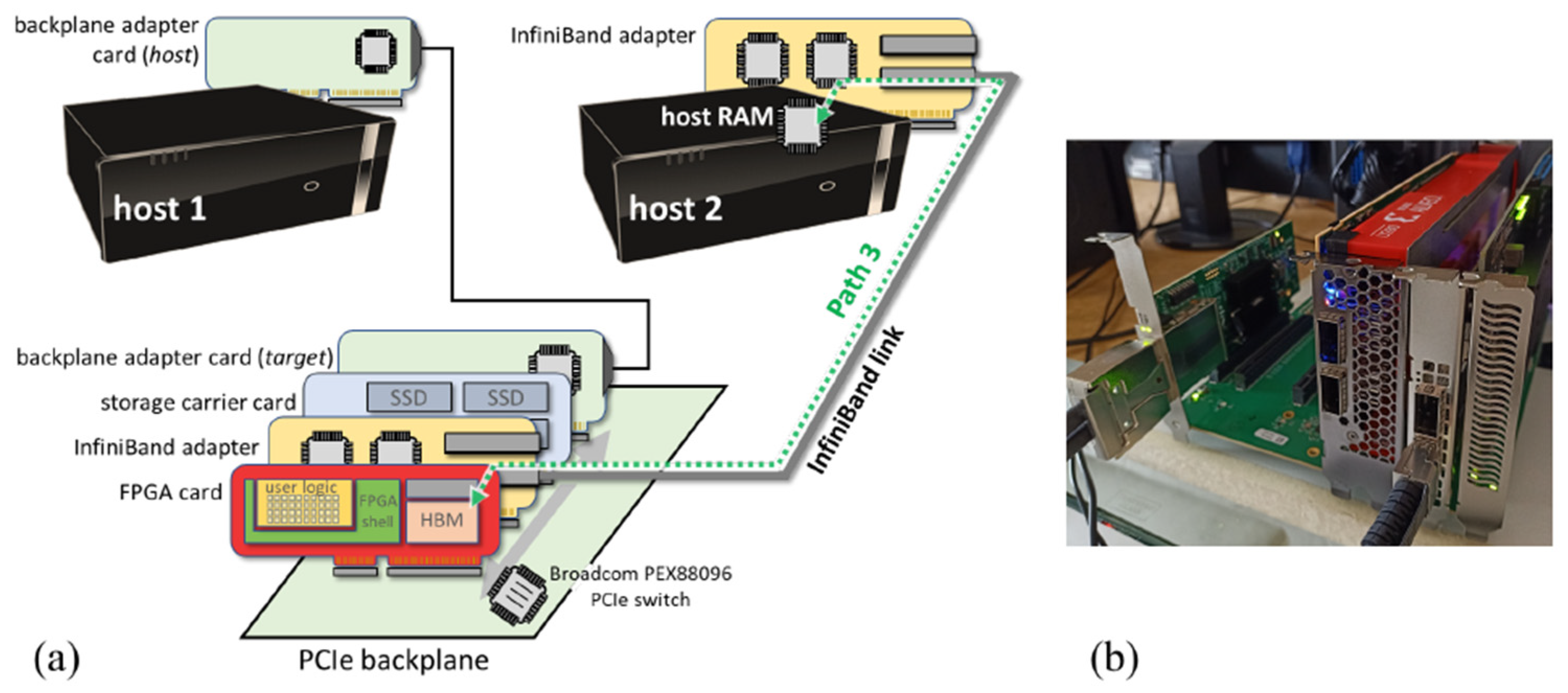
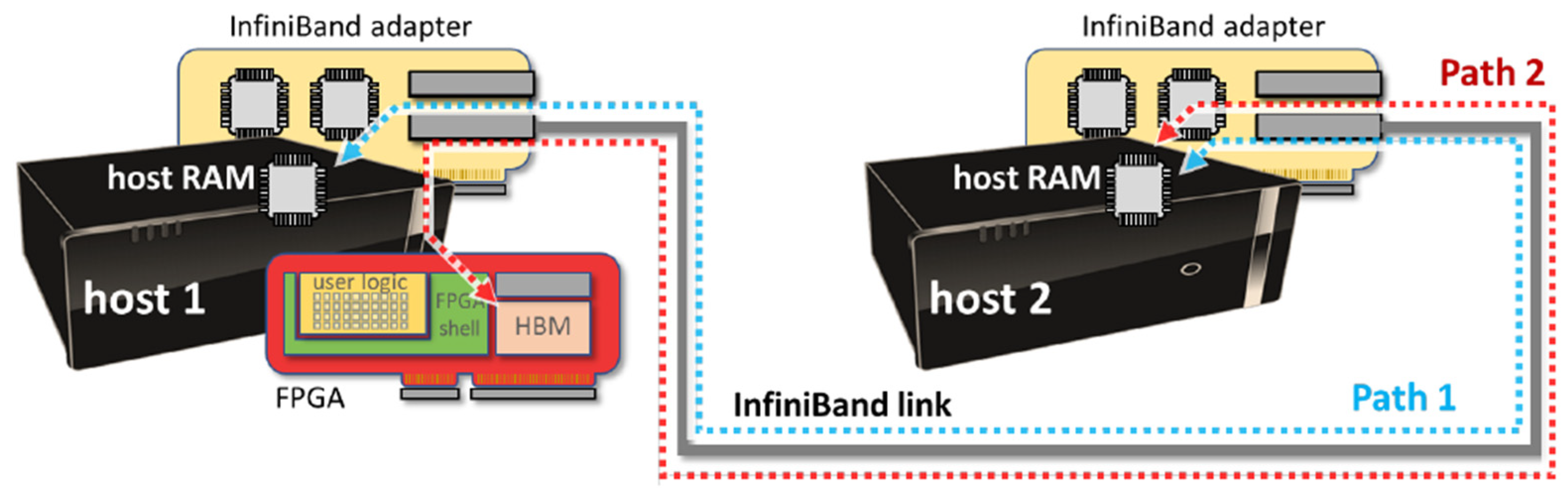
3. System Architecture
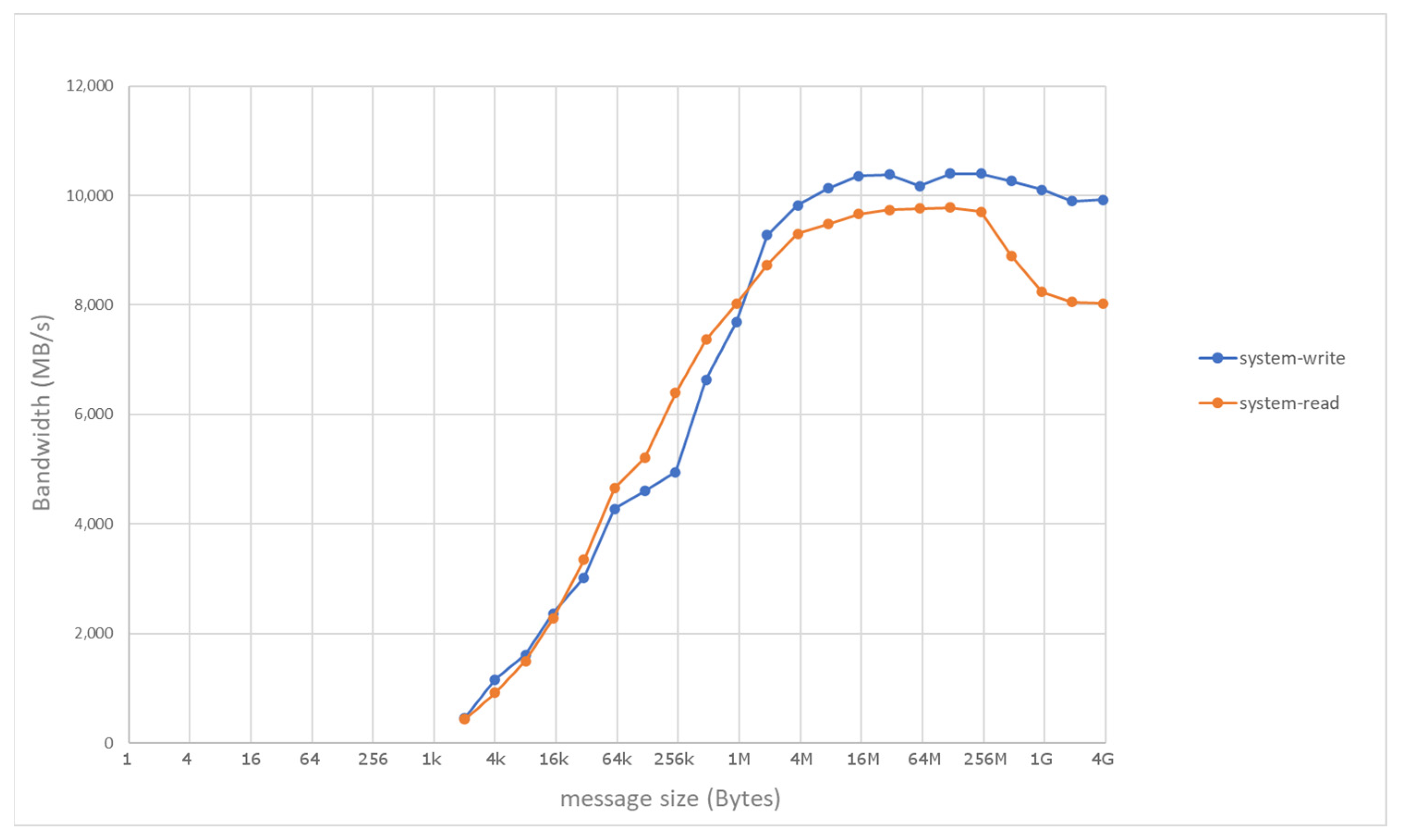
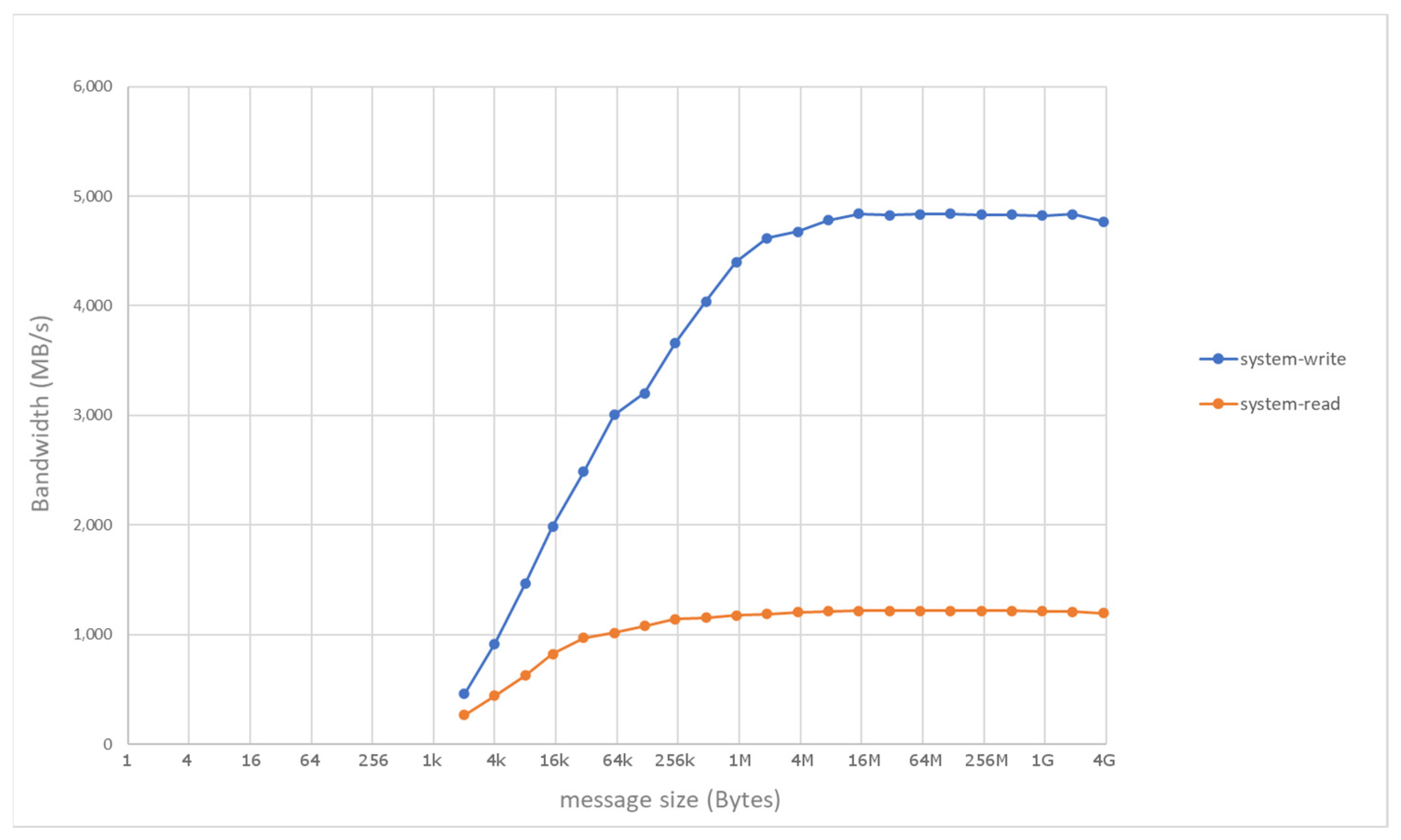
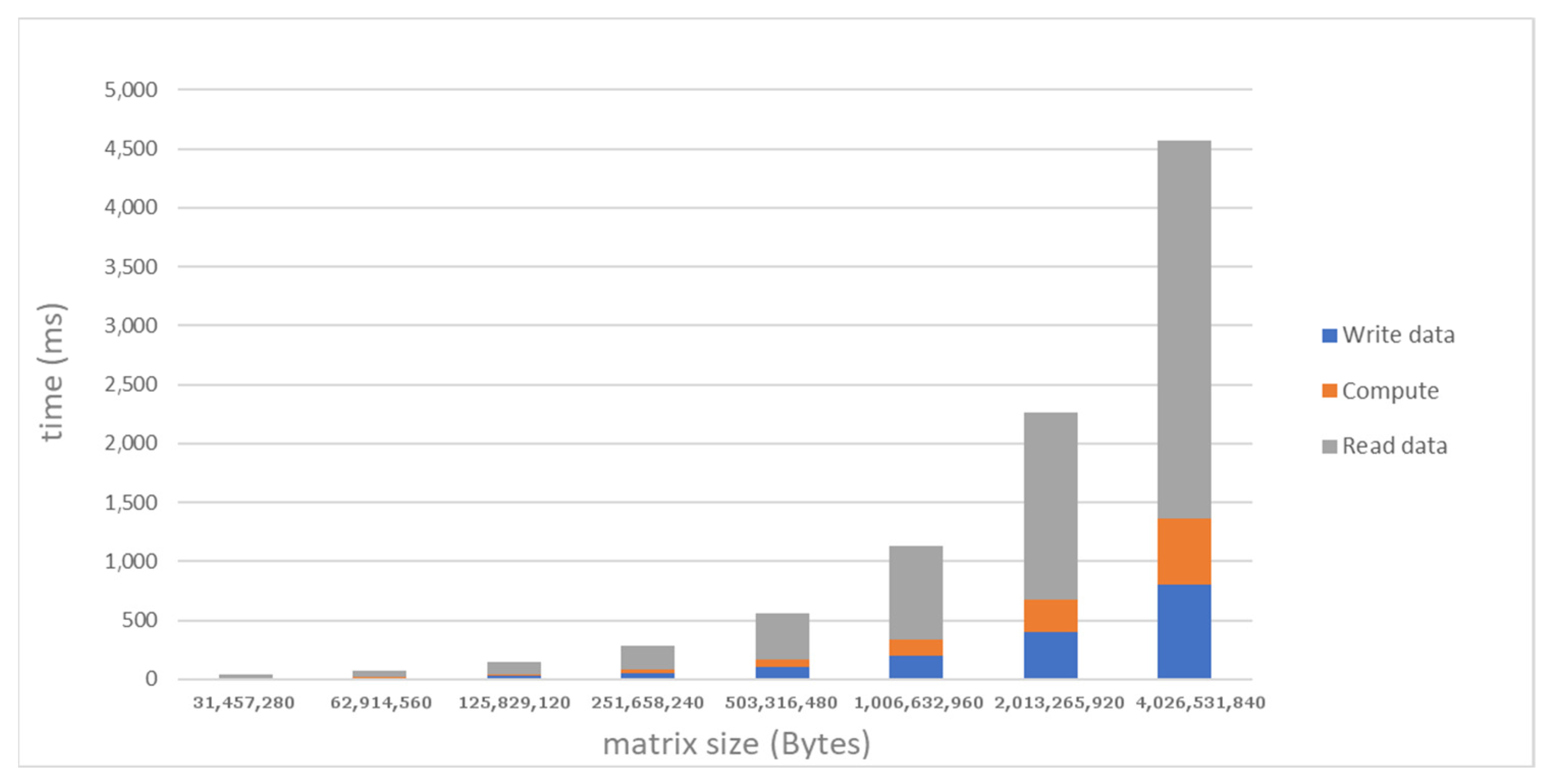
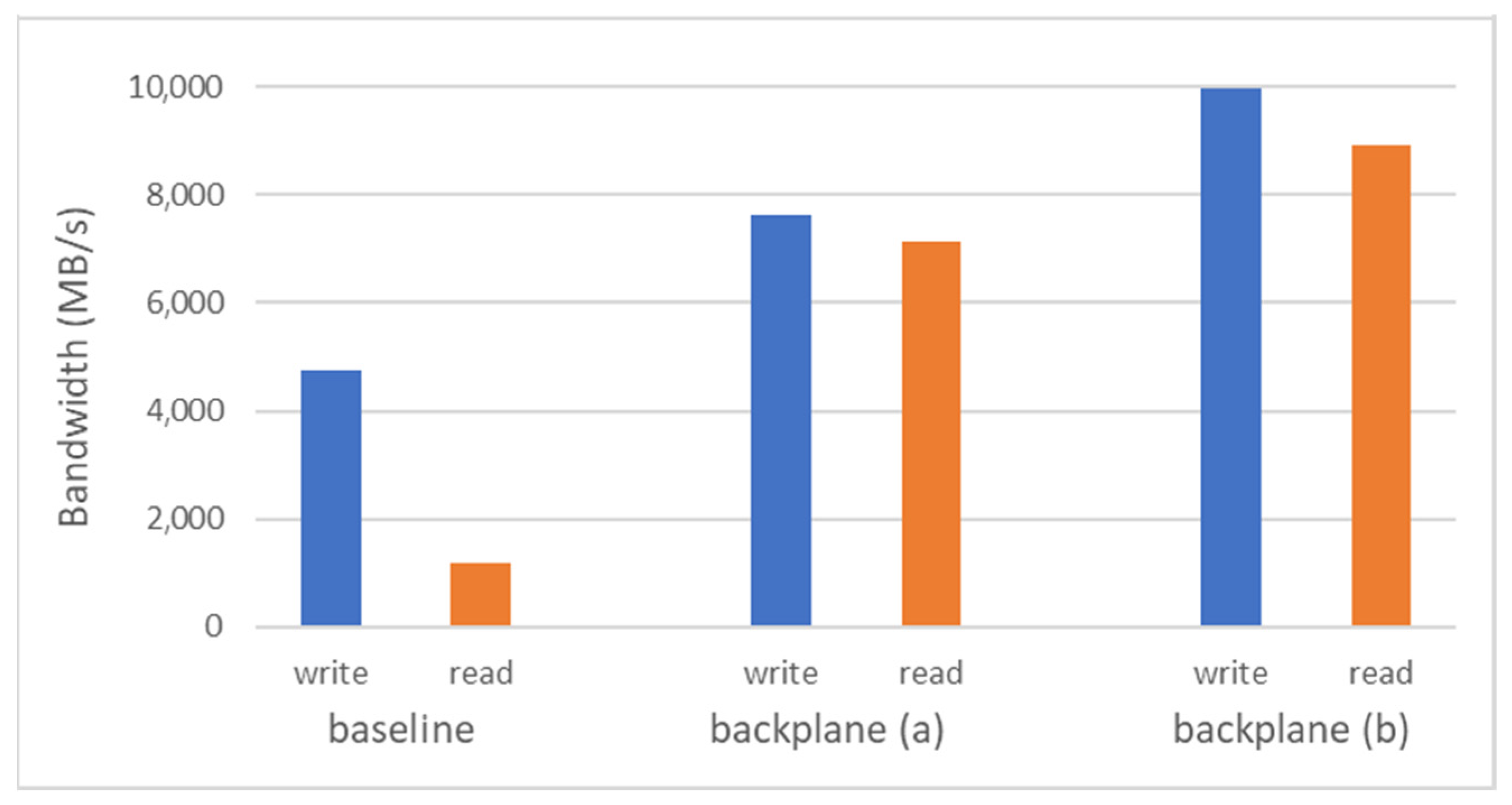
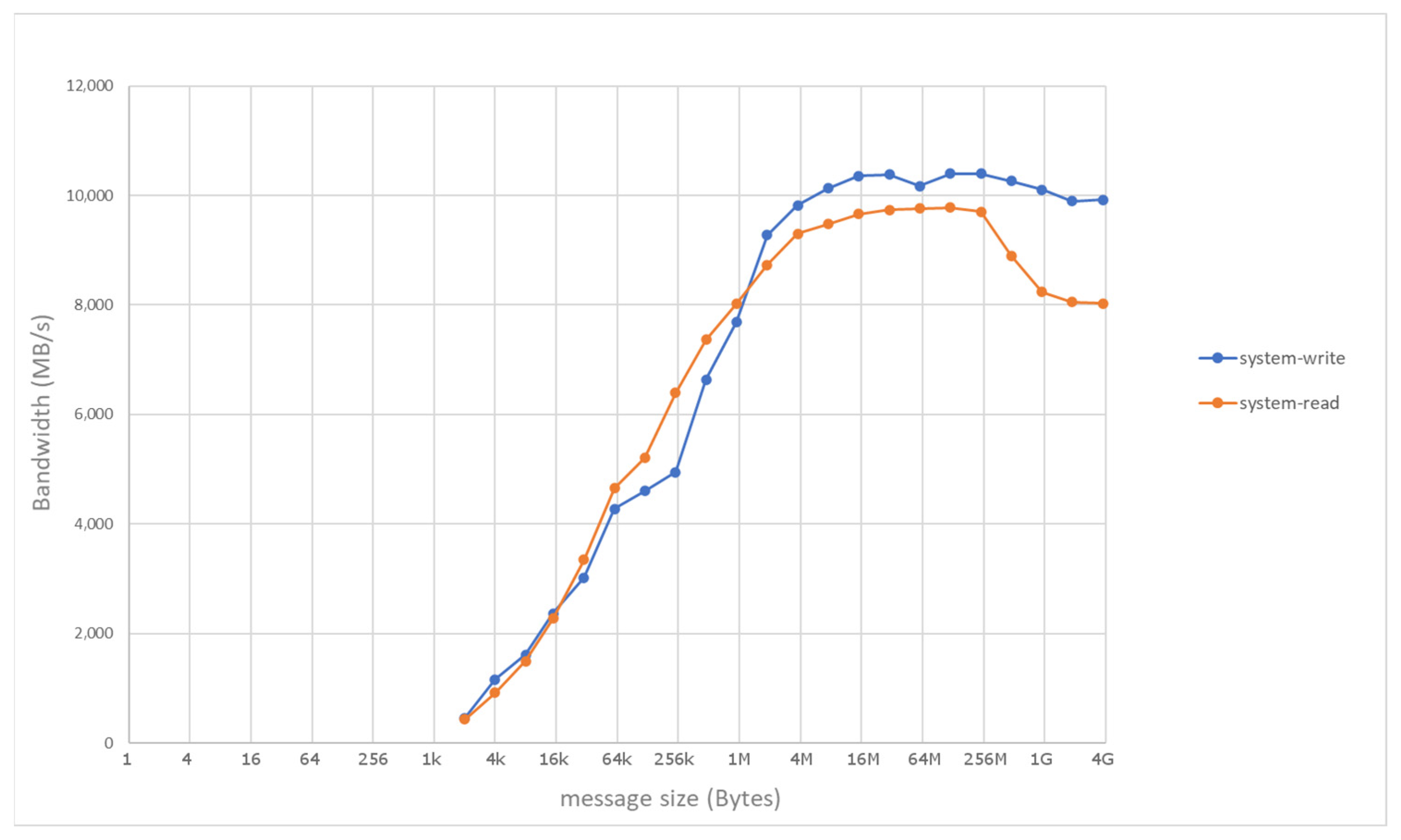
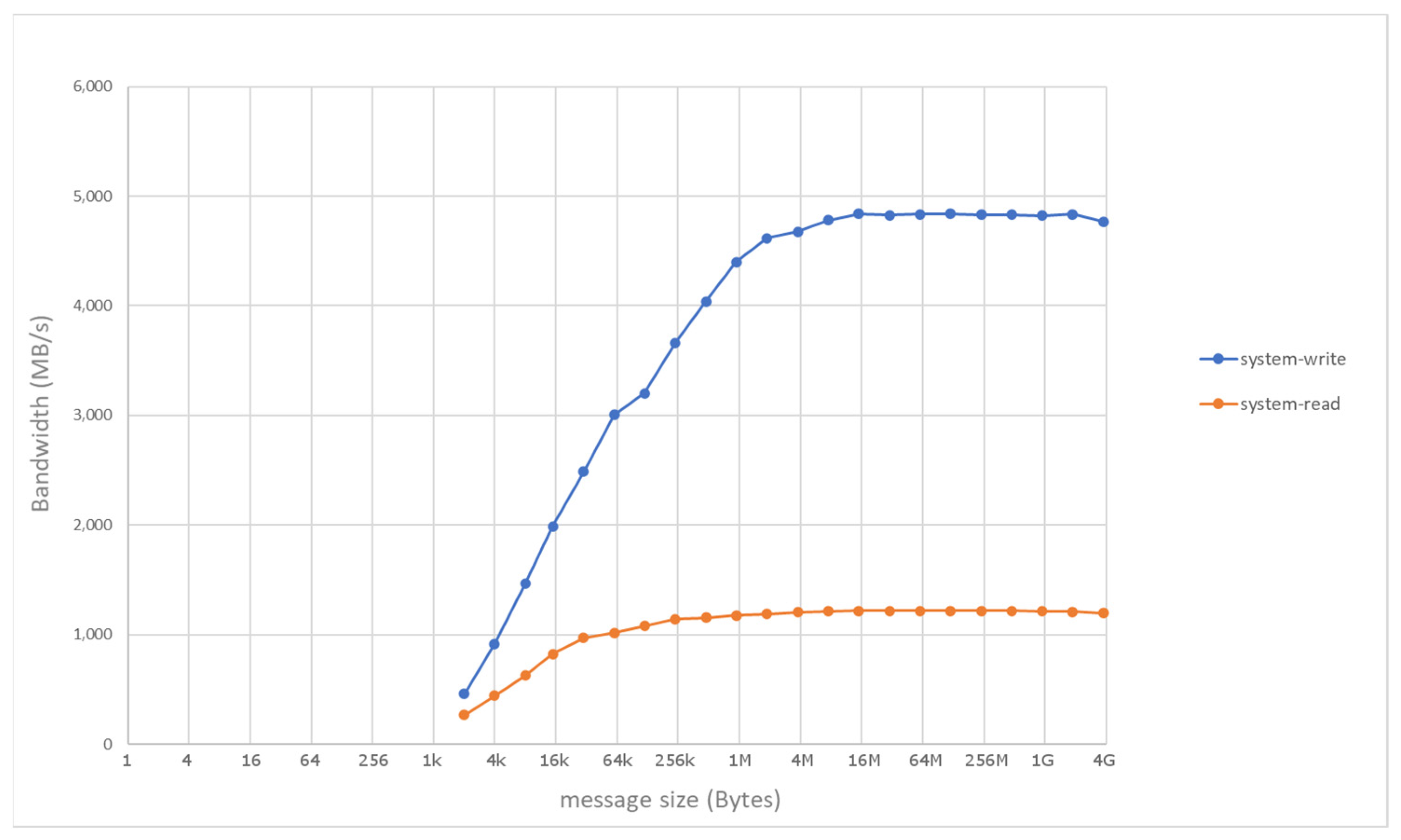
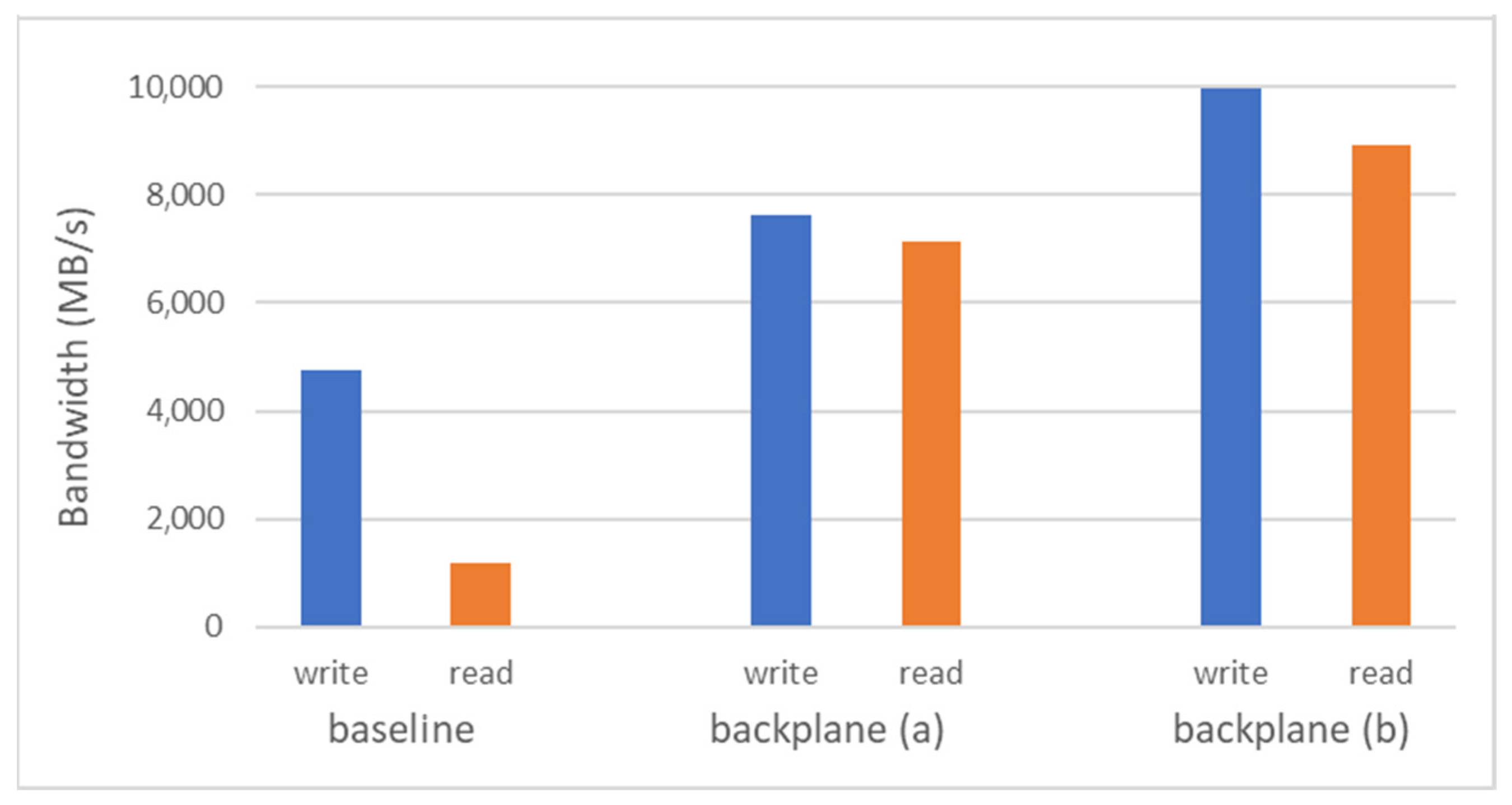
4. Evaluation
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lonardo, A.; Ameli, F.; Ammendola, R.; Biagioni, A.; CottaRamusino, A.; Fiorini, M.; Frezza, O.; Lamanna, G.; LoCicero, F.; Martinelli, M.; et al. A FPGA-based Network Interface Card with GPUDirect enabling real-time GPU computing in HEP experiments. In Proceedings of the GPU Computing in High-Energy Physics (GPUHEP2014), Pisa, Italy, 10–12 September 2014; pp. 86–91. [Google Scholar]
- Anderson, J.; Borga, A.; Boterenbrood, H.; Chen, H.; Chen, K.; Drake, G.; Francis, D.; Gorini, B.; Lanni, F.; Miotto, G.L.; et al. FELIX: A High-throughput network approach for interfacing to front end electronics for ATLAS upgrades. J. Phys. Conf. Ser. 2015, 664, 082050. [Google Scholar] [CrossRef] [Green Version]
- Schumacher, J.; Plessl, C.; Vandelli, W. High-Throughput and Low-Latency Network Communication with NetIO. J. Phys. Conf. Ser. 2017, 898, 082003. [Google Scholar] [CrossRef] [Green Version]
- Lenkiewicz, P.; Broekema, P.C.; Metzler, B. Energy-efficient data transfers in radio astronomy with software UDP RDMA. Future Gener. Comput. Syst. 2018, 79, 215–224. [Google Scholar] [CrossRef]
- Perret, D.; Laine, M.; Bernard, J.; Gratadour, D.; Sevin, A. Bridging FPGA and GPU technologies for AO real-time control. Adapt. Opt. Syst. V 2016, 9909, 99094M. [Google Scholar] [CrossRef]
- Mansour, W.; Janvier, N.; Fajardo, P. FPGA Implementation of RDMA-Based Data Acquisition System over 100-Gb Ethernet. IEEE Trans. Nucl. Sci. 2019, 66, 1138–1143. [Google Scholar] [CrossRef]
- Mansour, W.; Biv, R.; Ponchut, C.; Ponsard, R.; Janvier, N.; Fajardo, P. FPGA-Based Real-Time Image Manipulation and Advanced Data Acquisition for 2-D-XRAY Detectors. IEEE Trans. Nucl. Sci. 2021, 68, 1927–1932. [Google Scholar] [CrossRef]
- Leonarski, F.; Mozzanica, A.; Bruckner, M.; Lopez-Cuenca, C.; Redford, S.; Sala, L.; Babic, A.; Billich, H.; Bunk, O.; Schmitt, B.; et al. JUNGFRAU detector for brighter X-ray sources: Solutions for IT and data science challenges in macromolecular crystallography. Struct. Dyn. 2020, 7, 014305. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahoo, S.; Chaddha, N.; Sahoo, S.; Biswas, N.; Roy, A.; Das, M.; Pal, S. FPGA-based multi-channel data acquisition system for Superheated Emulsion Detectors. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 2021, 1009, 165457. [Google Scholar] [CrossRef]
- Schelten, N.; Steinert, F.; Schulte, A.; Stabernack, B. A High-Throughput, Resource-Efficient Implementation of the RoCEv2 Remote DMA Protocol for Network-Attached Hardware Accelerators. In Proceedings of the 2020 International Conference on Field-Programmable Technology (ICFPT), Maui, HI, USA, 9–11 December 2020; pp. 241–249. [Google Scholar] [CrossRef]
- Lant, J.; Navaridas, J.; Lujan, M.; Goodacre, J. Toward FPGA-Based HPC: Advancing interconnect technologies. IEEE Micro 2020, 40, 25–34. [Google Scholar] [CrossRef]
- Weerasinghe, J.; Abel, F.; Hagleitner, C.; Herkersdorf, A. Disaggregated FPGAs: Network performance comparison against bare-metal servers, virtual machines and linux containers. In Proceedings of the International Conference on Cloud Computing Technology and Science (CloudCom), Luxembourg, 12–16 December 2016; pp. 9–17. [Google Scholar] [CrossRef]
- Association, I.T. InfiniBand Roadmap—Advancing InfiniBand. Available online: https://www.infinibandta.org/infiniband-roadmap/ (accessed on 21 November 2021).
- Supermicro. Supermicro SuperServer 1029GQ-TNRT. Available online: https://www.supermicro.com/products/system/1U/1029/SYS-1029GQTNRT.cfm (accessed on 20 September 2021).
- Mellanox. ConnectX-5 IBA HCA. Available online: http://www.mellanox.com/page/products_dyn?product_family=258&mtag=connectx_5_vpi_card (accessed on 21 November 2021).
- Xilinx. SmartSSD Computational Storage Drive, Installation and User Guide-UG1382 (v1.2). Available online: https://www.xilinx.com/applications/data-center/computational-storage/smartssd.html (accessed on 21 November 2021).
- Du, C.; Yamaguchi, Y. High-level synthesis design for stencil computations on FPGA with high bandwidth memory. Electronics 2020, 9, 1275. [Google Scholar] [CrossRef]
- Kalia, A.; Kaminsky, M.; Andersen, D.G. Design guidelines for high performance RDMA systems. In Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC 2016), Denver, CO, USA, 22–24 June 2016; pp. 437–450. [Google Scholar]
- Supermicro. Supermicro SuperServer 1029GQ-TXRT. Available online: https://www.supermicro.com/products/system/1U/1029/SYS-1029GQTXRT.cfm (accessed on 20 September 2021).


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cilardo, A. Evaluation of HPC Acceleration and Interconnect Technologies for High-Throughput Data Acquisition. Sensors 2021, 21, 7759. https://doi.org/10.3390/s21227759
Cilardo A. Evaluation of HPC Acceleration and Interconnect Technologies for High-Throughput Data Acquisition. Sensors. 2021; 21(22):7759. https://doi.org/10.3390/s21227759
Chicago/Turabian StyleCilardo, Alessandro. 2021. "Evaluation of HPC Acceleration and Interconnect Technologies for High-Throughput Data Acquisition" Sensors 21, no. 22: 7759. https://doi.org/10.3390/s21227759
APA StyleCilardo, A. (2021). Evaluation of HPC Acceleration and Interconnect Technologies for High-Throughput Data Acquisition. Sensors, 21(22), 7759. https://doi.org/10.3390/s21227759