Road Surface Crack Detection Method Based on Conditional Generative Adversarial Networks


 ,
,
Abstract
:1. Introduction
- The roadway surface may be captured at degree angles other than the specifically established 90-degree angle, such as 55 degrees;
- There may be glares, stains, spots, and uneven illumination from the windscreen on some images;
- There may be shadow spots, uneven illumination, and other items of asphalt that can be detected as cracks on some images;
- There are also different white blanking techniques;
- Moreover, it may also include a variety of extraneous things that are unrelated to the roadway surface itself, such as sidewalks, road markings, cars, curbs, buildings, and locations where cracks may form.
2. Preliminary
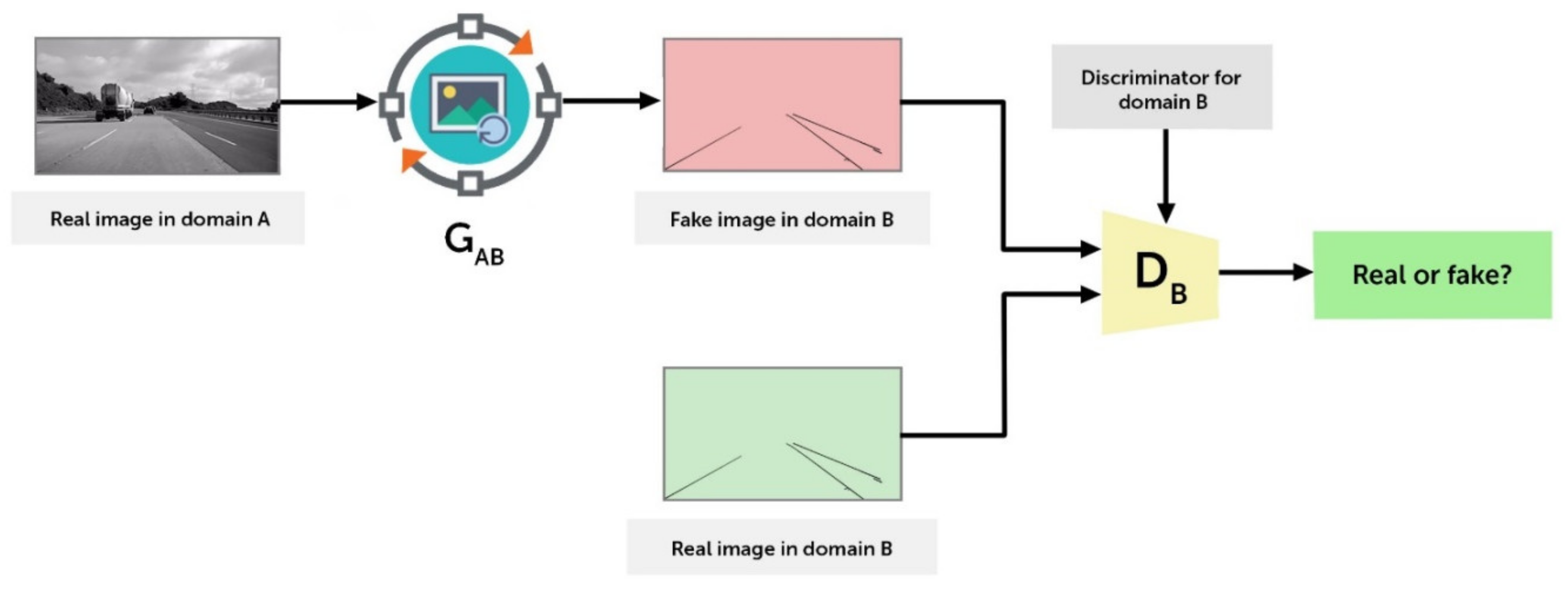
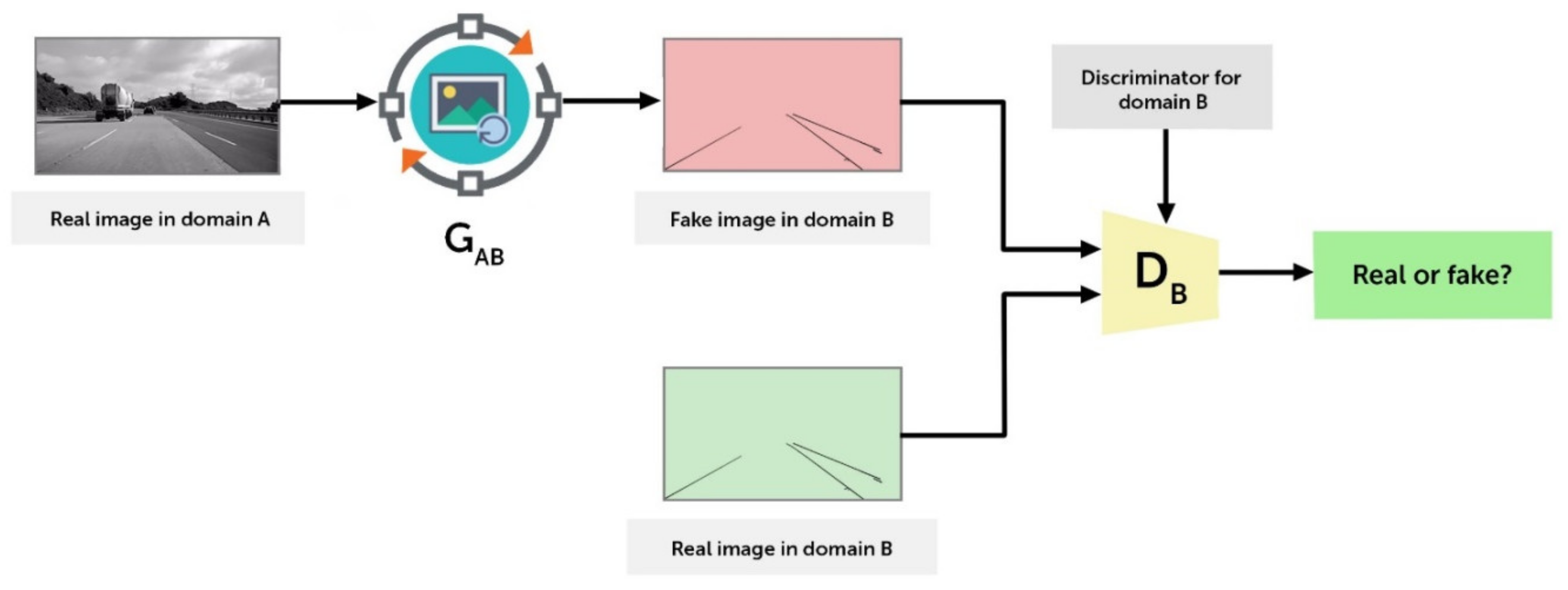
2.1. cGAN
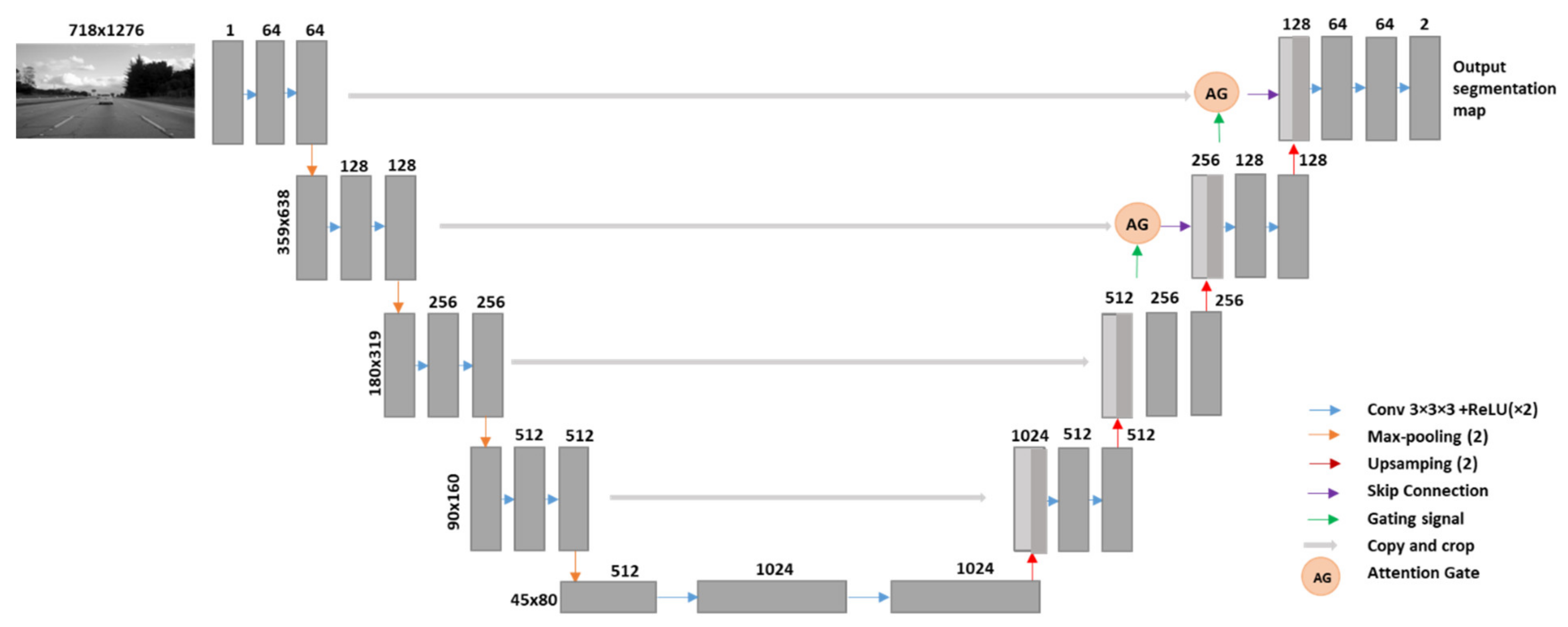
2.2. Attention Gates
3. Proposed Method
3.1. Parameter Selections
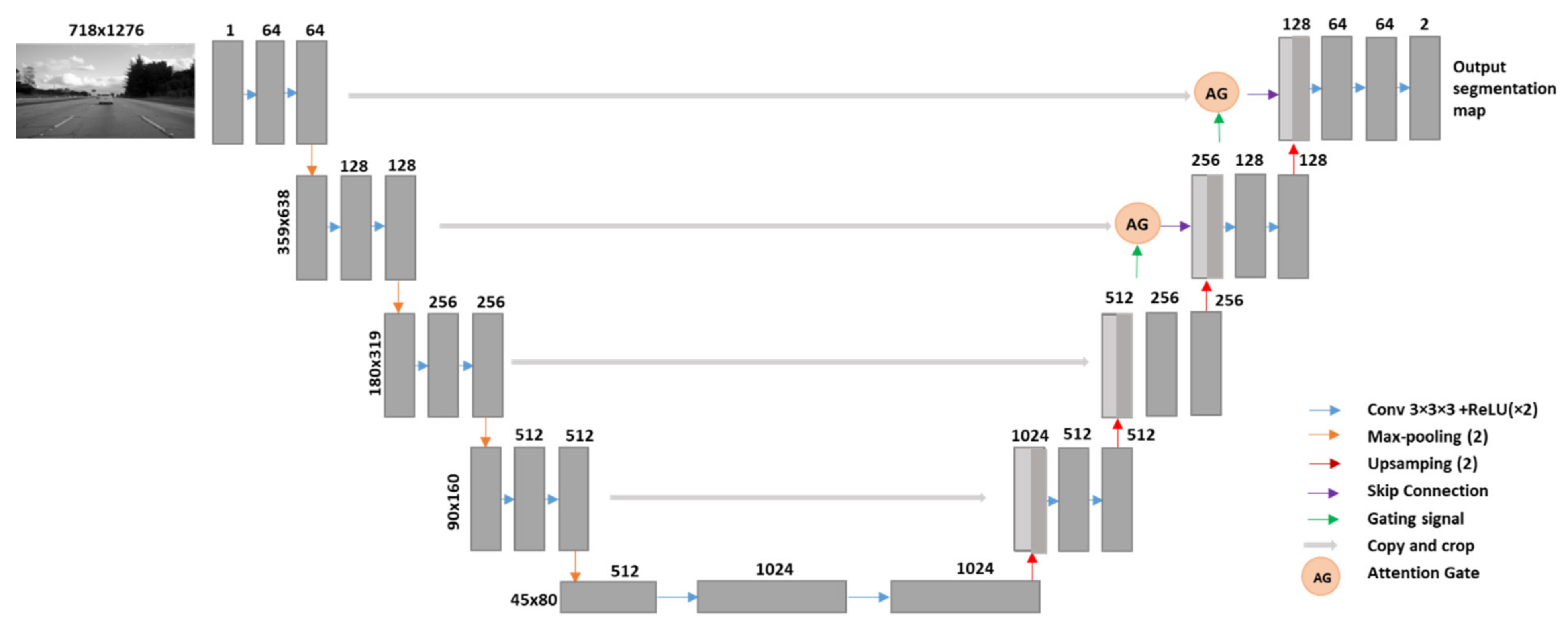
3.2. ICGA
3.2.1. The Generator
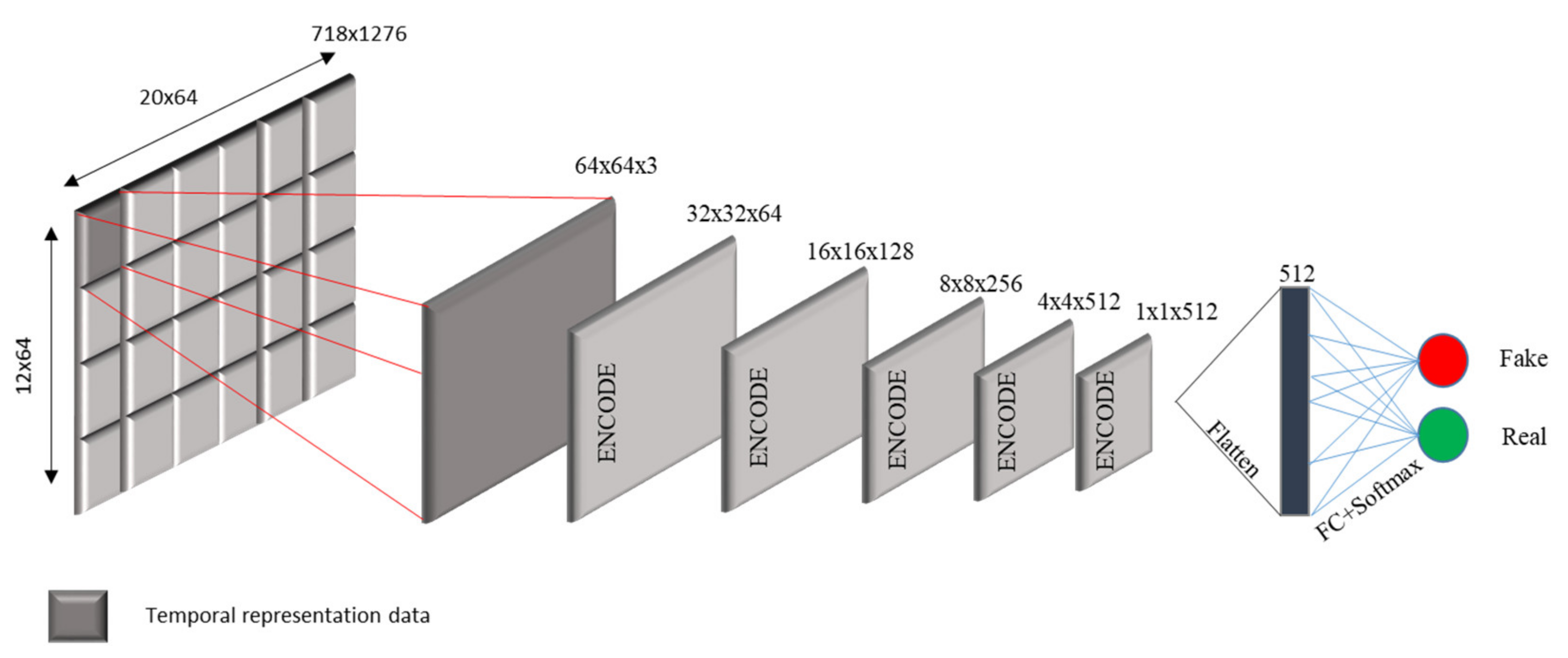
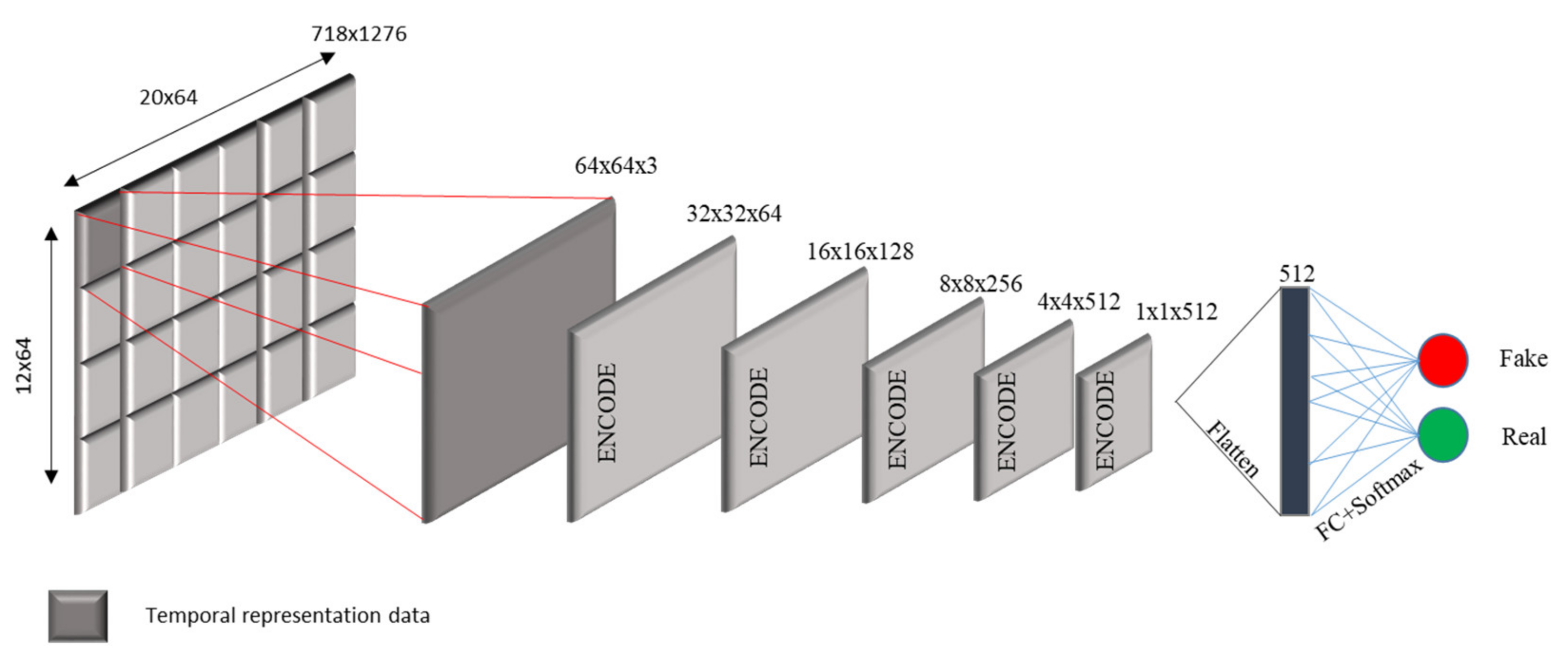
3.2.2. The Discriminator
3.2.3. ICGA Model
| Algorithm 1: Modified Algorithm Training Loop Pseudocode | |
| 1: | Draw a minibatch of samples {XAB(1),..., xAB(m)} from domain X |
| 2: | Draw a minibatch of samples {Y(1),..., y(m)} from domain Y |
| 3: | Compute the discriminator loss on real images: + |
| 4: | Compute the discriminator loss on fake images: + |
| 5: | Update the PatchGAN discriminator |
| 6: | Apply Attention to the Generator ) |
| 7: | Compute the B → A generator loss: |
| 8: | Compute the A → B generator loss: |
| 9: | Update the generator |
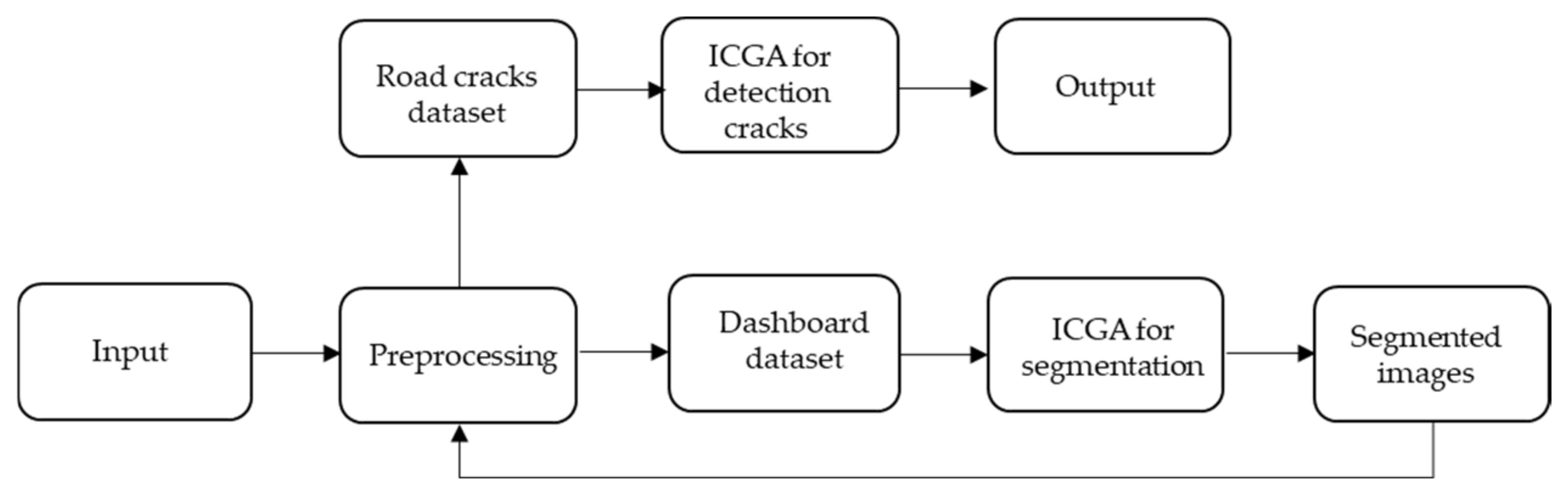
3.3. Method Steps for the Road Surface Crack Detection
- (1)
- The first stage entails preparing the dashboard image dataset.
- (2)
- The second stage is road segmentation, which involves removing extraneous items from images using the ICGA method. We train our model to remove unwanted items from the images, such as scenery, construction, walkways, etc., as described in Section 3.2. As a result, we obtain a new dataset, which we called Roadway cracks.
- (3)
- The third stage is image pre-processing for the processing of the new Roadway cracks dataset. It contains image resolution transformation and channel configuration.
- (4)
- In the fourth stage, we apply the ICGA method to detect cracks on the newly segmented dataset.
4. Results
4.1. Experiment Preparation
4.1.1. Dataset Description
4.1.2. Experimental Environment
- Linux based system: Ubuntu 20.04;
- PyTorch platform with CUDA based video cards 4X 1080 TI;
- A GPU video memory of 11 Gb;
- CPU: Intel(R) Xeon(R) Silver 4114 CPU @ 2.2 Hz;
- Server model: DELL PowerEdge T640 tower server;
- 32 GB memory, 10 TB hard drive, and 320 GB solid state drive;
- The programming software was Python 3.
4.2. Evaluation Metric
4.3. Experiments on Road Segmentation and Cracks Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdellatif, M.; Peel, H.; Cohn, A.G. Pavement Crack Detection from Hyperspectral Images Using a Novel Asphalt Crack Index. Remote Sens. 2020, 12, 3084. [Google Scholar] [CrossRef]
- Oh, H.; Garrick, N.; Achenie, L. Segmentation Algorithm Using Iterative Clipping for Processing Noisy Pavement Images. In Proceedings of the Imaging Technologies: Techniques and Applications in Civil Engineering, Second International Conference, Davos, Switzerland, 25–30 May 1997; pp. 138–147. [Google Scholar]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic Crack Detection from Pavement Images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Roli, F. Measure of Texture Anisotropy for Crack Detection on Textured Surfaces. Electron. Lett. 1996, 1274–1275. [Google Scholar] [CrossRef]
- Nguyen, T.S.; Begot, S.; Duculty, F.; Avila, M. Free-Form Anisotropy: A New Method for Crack Detection on Pavement Surface Images. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1069–1072. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic Crack Detection and Classification Method for Subway Tunnel Safety Monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Zhang, D.; Li, Q.; Chen, Y.; Cao, M.; He, L.; Zhang, B. An Efficient and Reliable Coarse-to-Fine Approach for Asphalt Pavement Crack Detection. Image Vis. Comput. 2017, 57, 130–146. [Google Scholar] [CrossRef]
- Yu, Y.; Rashidi, M.; Samali, B.; Yousefi, A.M.; Wang, W. Multi-Image-Feature-Based Hierarchical Concrete Crack Identification Framework Using Optimized Svm Multi-Classifiers and d–s Fusion Algorithm for Bridge Structures. Remote Sens. 2021, 13, 240. [Google Scholar] [CrossRef]
- Dong, C.; Li, L.; Yan, J.; Zhang, Z.; Pan, H.; Catbas, F.N. Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network. Sensors 2021, 21, 4135. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Li, H.; Song, D.; Liu, Y.; Li, B. Automatic Pavement Crack Detection by Multi-Scale Image Fusion. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2025–2036. [Google Scholar] [CrossRef]
- Sobol, B.V.; Soloviev, A.N.; Vasiliev, P.V.; Podkolzina, L.A. Deep Convolution Neural Network Model in Problem of Crack Segmentation on Asphalt Images. Vestn. Don State Tech. Univ. 2019, 19, 63–73. [Google Scholar] [CrossRef]
- Park, S.; Bang, S.; Kim, H.; Kim, H. Patch-Based Crack Detection in Black Box Road Images Using Deep Learning. In Proceedings of the ISARC 2018—35th International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018; pp. 2–5. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. CrackIT—An Image Processing Toolbox for Crack Detection and Characterization. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 798–802. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A Deep Hierarchical Feature Learning Architecture for Crack Segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An Integrated Approach to Automatic Pixel-Level Crack Detection and Quantification of Asphalt Pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Feng, X.; Xiao, L.; Li, W.; Pei, L.; Sun, Z.; Ma, Z.; Shen, H.; Ju, H. Pavement Crack Detection and Segmentation Method Based on Improved Deep Learning Fusion Model. Math. Probl. Eng. 2020, 2020, 8515213. [Google Scholar] [CrossRef]
- Haghighat, A.K.; Ravichandra-Mouli, V.; Chakraborty, P.; Esfandiari, Y.; Arabi, S.; Sharma, A. Applications of Deep Learning in Intelligent Transportation Systems. J. Big Data Anal. Transp. 2020, 2, 115–145. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H. Da CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1306–1319. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Jay, F.; Renou, J.-P.; Voinnet, O.; Navarro, L. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks Jun-Yan. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 183–202. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Cao, J.; Li, X.; You, J. Improvement of Residual Attention Network for Image Classification. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11935LNCS, pp. 529–539. [Google Scholar] [CrossRef]
- Jetley, S.; Lord, N.A.; Lee, N.; Torr, P.H.S. Learn to Pay Attention. In Proceedings of the 6th International Conference on Learning Representations. (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–14. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5999–6009. [Google Scholar]
- Huang, Z.; Zhao, Y.; Liu, Y.; Song, G. GCAUNet: A Group Cross-Channel Attention Residual UNet for Slice Based Brain Tumor Segmentation. Biomed. Signal Process. Control 2021, 70, 102958. [Google Scholar] [CrossRef]
- Tsai, Y.-C.; Chatterjee, A. Comprehensive, Quantitative Crack Detection Algorithm Performance Evaluation System. J. Comput. Civ. Eng. 2017, 31, 04017047. [Google Scholar] [CrossRef]
- Ren, M.; Zemel, R.S. End-to-End Instance Segmentation with Recurrent Attention. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 293–301. [Google Scholar] [CrossRef] [Green Version]
- Khanh, T.L.B.; Dao, D.P.; Ho, N.H.; Yang, H.J.; Baek, E.T.; Lee, G.; Kim, S.H.; Yoo, S.B. Enhancing U-Net with Spatial-Channel Attention Gate for Abnormal Tissue Segmentation in Medical Imaging. Appl. Sci. 2020, 10, 5729. [Google Scholar] [CrossRef]
- Zhao, B.; Feng, J.; Wu, X.; Yan, S. A Survey on Deep Learning-Based Fine-Grained Object Classification and Semantic Segmentation. Int. J. Autom. Comput. 2017, 14, 119–135. [Google Scholar] [CrossRef]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked Attention Networks for Image Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Shen, T.; Jiang, J.; Zhou, T.; Pan, S.; Long, G.; Zhang, C. Disan: Directional Self-Attention Network for RnN/CNN-Free Language Understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5446–5455. [Google Scholar]
- Behrendt, K.; Soussan, R. Unsupervised Labeled Lane Markers Using Maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW 2019), Seoul, Korea, 27–28 October 2019; pp. 832–839. [Google Scholar] [CrossRef]
- Derczynski, L. Complementarity, F-Score, and NLP Evaluation. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–28 May 2016; pp. 261–266. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PPV | TPR | F1 | HD-Score |
|---|---|---|---|---|
| Pix2pix cGAN | 89.24% | 95.04% | 91.07% | 92 |
| ICGA | 89.33% | 95.06% | 92.01% | 94 |
| Methods | PPV | TPR | F1 | HD-Score |
|---|---|---|---|---|
| CrackForest | 23.21% | 77.03% | 5.07% | 47 |
| FCN-VGG | 0.00% | 0.00% | N/A | N/A |
| DeepCrack-1 | 46.03% | 76.04% | 44.32 | 53 |
| DeepCrack-2 | 0.00% | 0.00% | N/A | N/A |
| Pix2pix cGAN | 73.04% | 79.07% | 83.01% | 82 |
| CrackGAN | 79.34% | 72.27% | 76.31 | 67 |
| ICGA | 88.03% | 90.06% | 85.01% | 94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kyslytsyna, A.; Xia, K.; Kislitsyn, A.; Abd El Kader, I.; Wu, Y. Road Surface Crack Detection Method Based on Conditional Generative Adversarial Networks. Sensors 2021, 21, 7405. https://doi.org/10.3390/s21217405
Kyslytsyna A, Xia K, Kislitsyn A, Abd El Kader I, Wu Y. Road Surface Crack Detection Method Based on Conditional Generative Adversarial Networks. Sensors. 2021; 21(21):7405. https://doi.org/10.3390/s21217405
Chicago/Turabian StyleKyslytsyna, Anastasiia, Kewen Xia, Artem Kislitsyn, Isselmou Abd El Kader, and Youxi Wu. 2021. "Road Surface Crack Detection Method Based on Conditional Generative Adversarial Networks" Sensors 21, no. 21: 7405. https://doi.org/10.3390/s21217405
APA StyleKyslytsyna, A., Xia, K., Kislitsyn, A., Abd El Kader, I., & Wu, Y. (2021). Road Surface Crack Detection Method Based on Conditional Generative Adversarial Networks. Sensors, 21(21), 7405. https://doi.org/10.3390/s21217405