
GSS-RiskAsser: A Multi-Modal Deep-Learning Framework for Urban Gas Supply System Risk Assessment on Business Users


Abstract
:1. Introduction
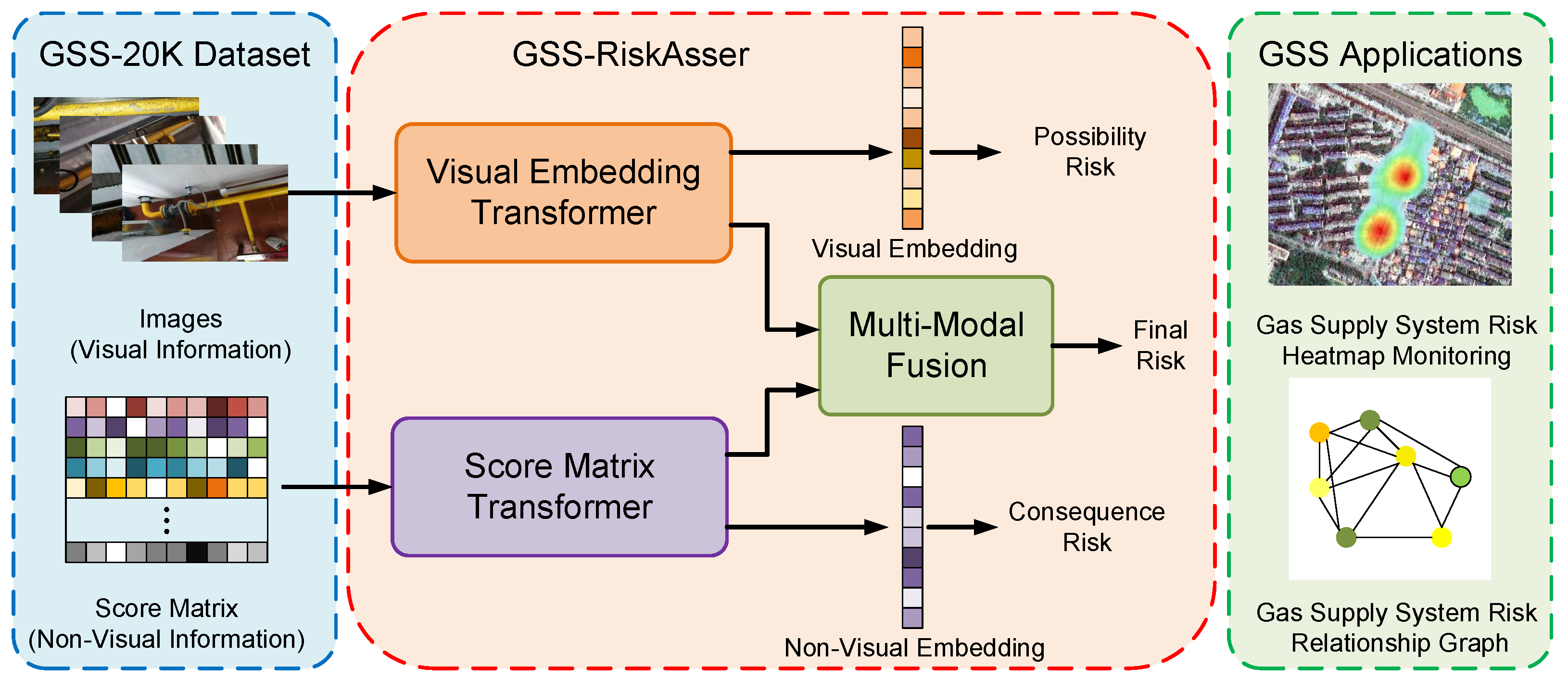
- To the best of our knowledge, we are the first to consider urban gas supply system risk assessment as a deep-learning problem. We analyze and attempt to solve the challenges when employing deep-learning techniques in this field. We re-format and define a novel task Urban Natural Gas Supply System Risk Assessment (GSS-RA). To drive the model, we publish a dataset GSS-20K that uses both image and language types of data for GSS-RA task.
- Accompanying the GSS-RA task and GSS-20K dataset, we build a practical gas supply system risk assessment system, and design a parallel transformer to process image and score matrix input for each sample. To deal with the multi-modal data problem, we propose a cross-attention mechanism into these two branches that achieves multi-modal information exchange and fusion.
- To properly evaluate our work, we employ our GSS-RiskAsser into two practical applications: Gas Supply System Risk Heatmap Monitoring and User Gas Supply System Relationship Graph. We believe that our efforts provide a feasible benchmark, which serves as a strong baseline for the GSS-RA task, and in the future could facilitate research and practical applications on city gas supply system monitoring and warning. Our dataset and code will be made publicly available.
2. Related Work
2.1. Urban Natural Gas Risk Assessment
2.2. Deep Learning on Multi-Modal Representation
3. Problem Statement
4. Dataset
4.1. GSS Image Acquisition
4.2. GSS Score Matrix Collection
4.3. Positive Data Generation
4.4. Comparison with Other Datasets
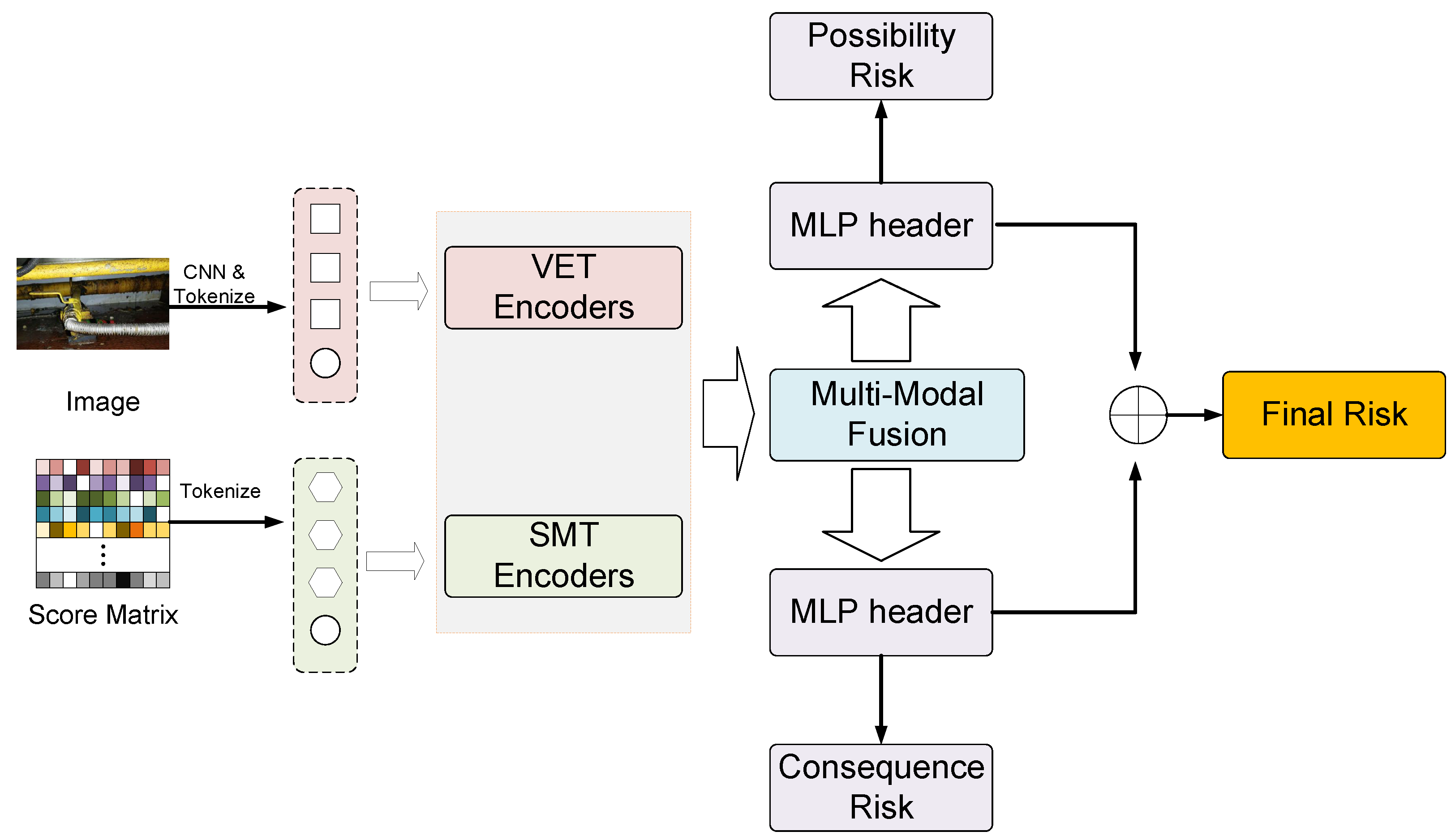
5. Method
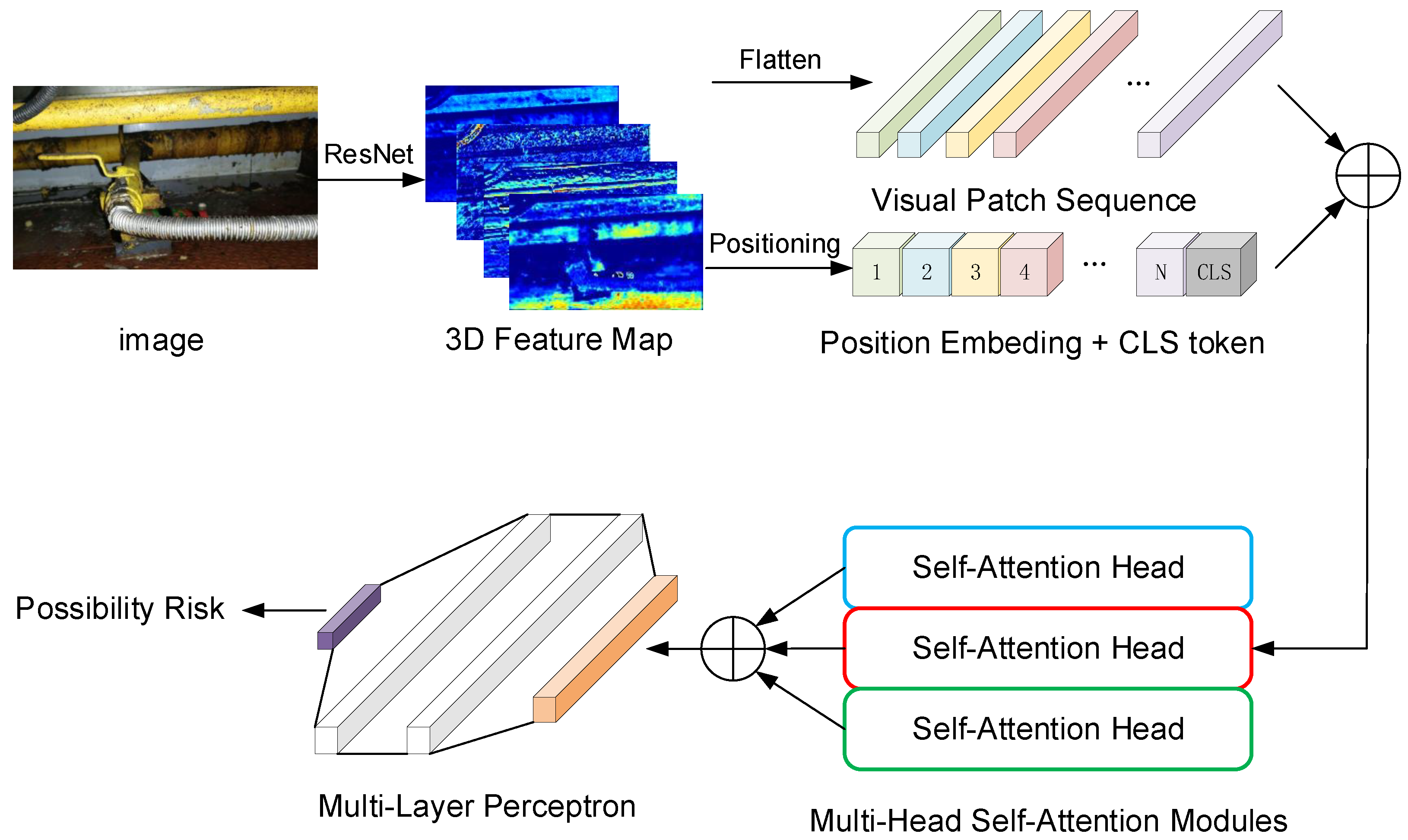
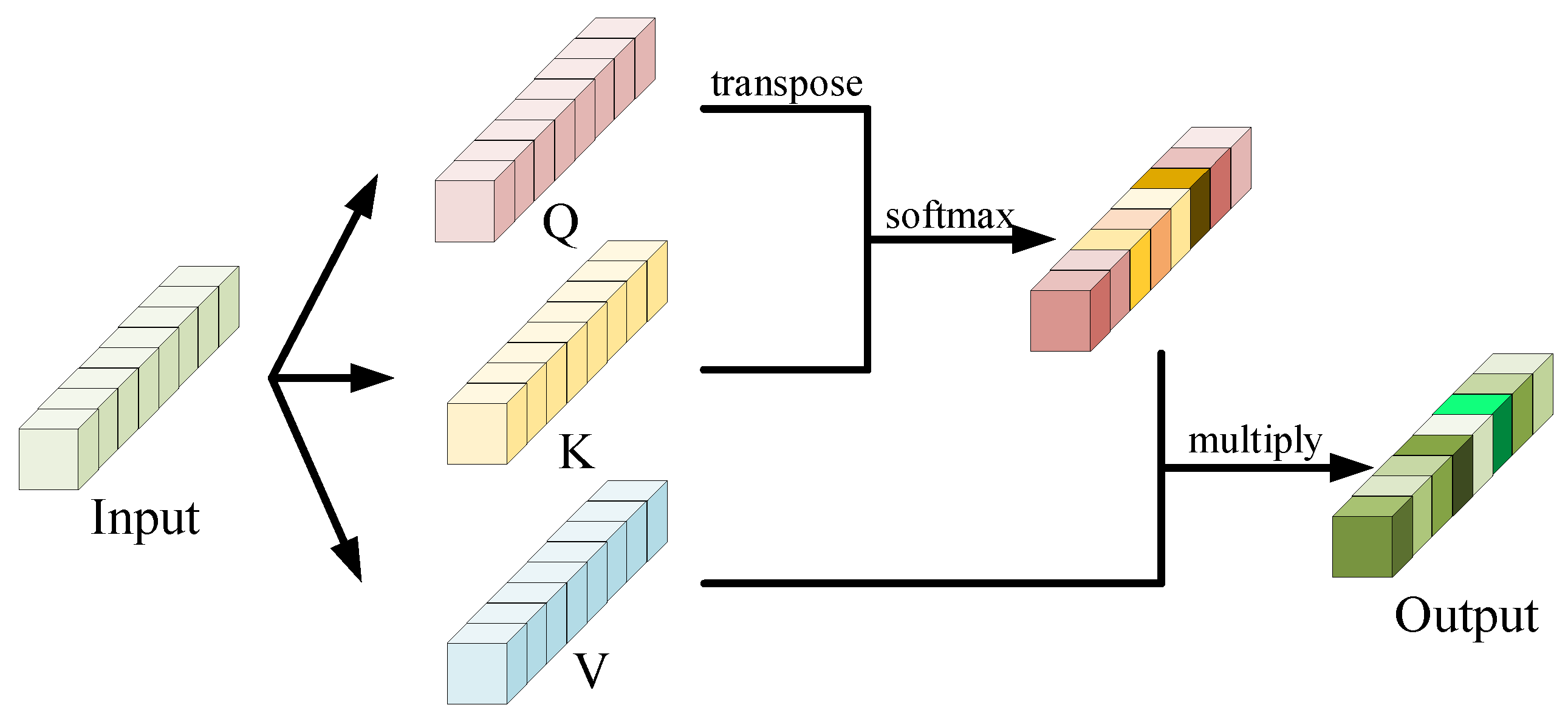
5.1. Visual Embedding Transformer (VET)
5.2. Score Matrix Transformer (SMT)
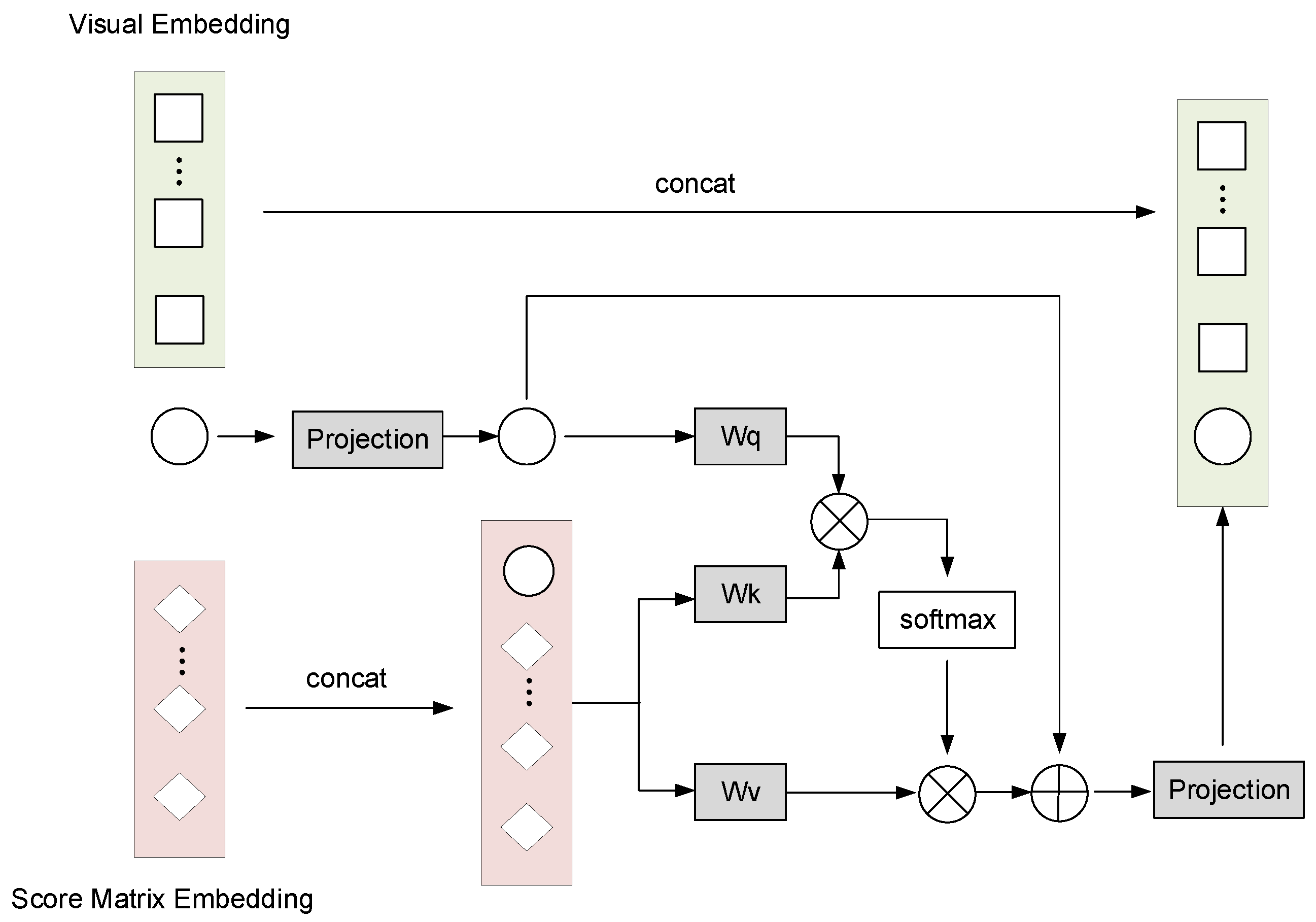
5.3. Multi-Modal Fusion (MMF)
6. Experiments
6.1. Experiment Settings
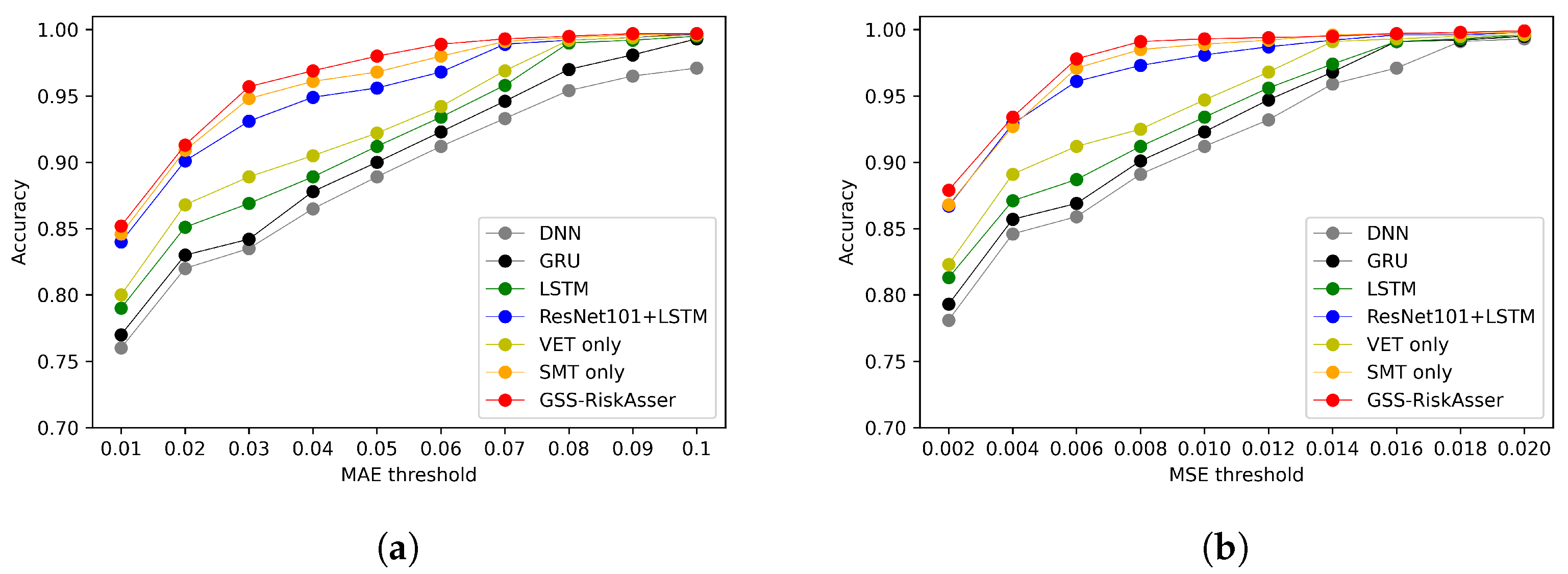
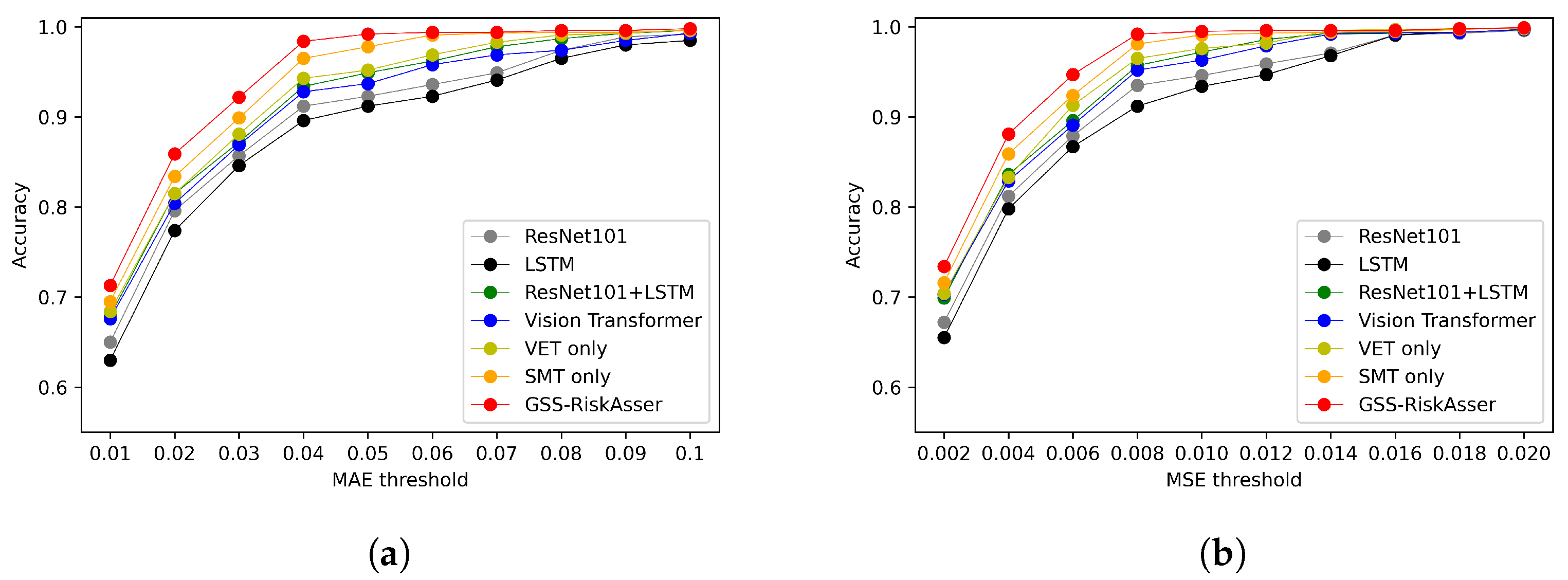
6.2. GSS-RiskAsser Performance
6.3. Ablation Studies
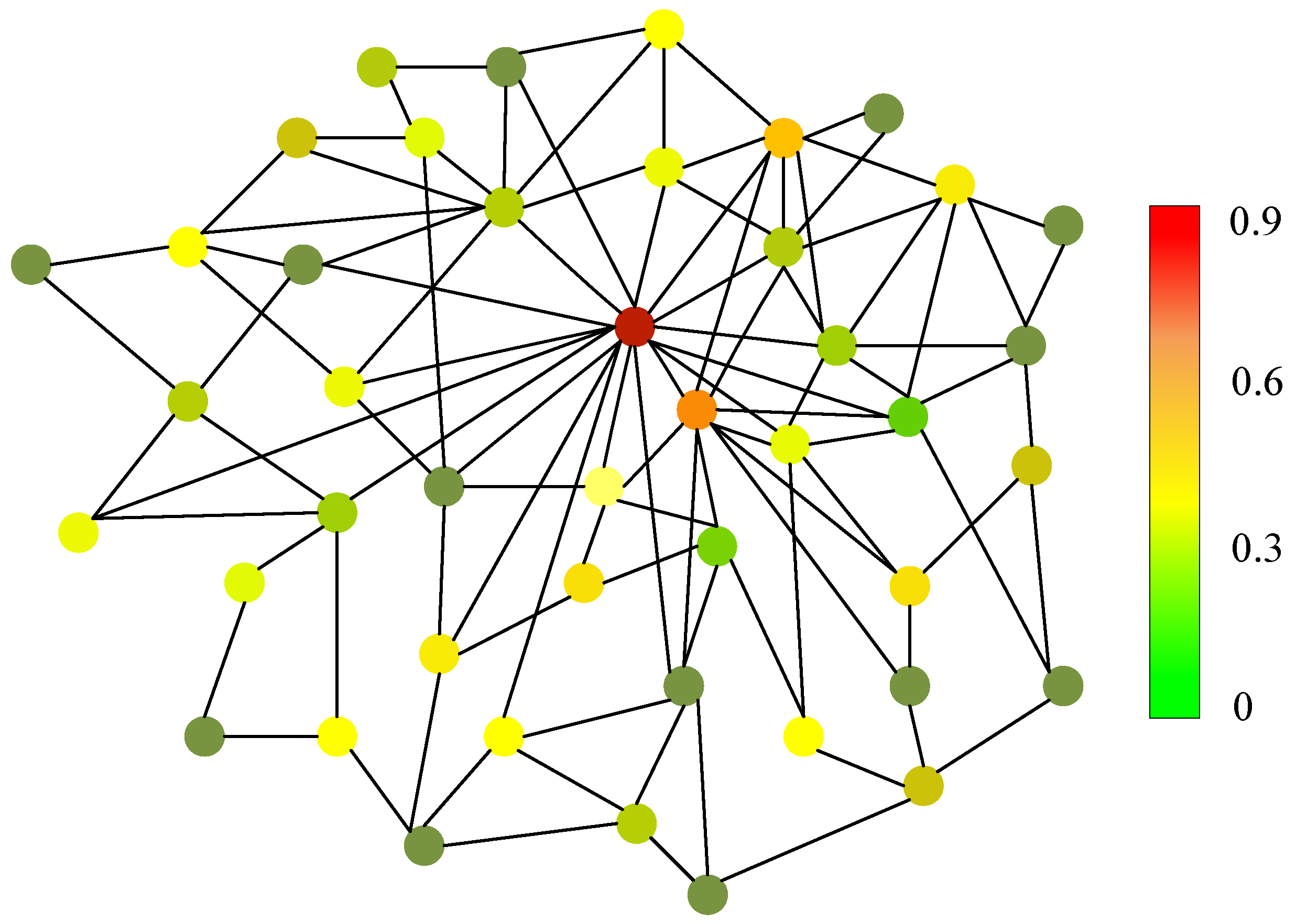
6.4. Practical Applications Using GSS-RiskAsser
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Peng, X.; Yao, D.; Liang, G.; Qin, L.; Yu, J.; He, S. Study on corrosion reliability of oil/gas pipelines based on enhanced Hamacher Operator and Bayesian Assessment. Process Saf. Environ. Prot. 2017, 111, 569–581. [Google Scholar] [CrossRef]
- Wang, W.; Shen, K.; Wang, B.; Dong, C.; Khan, F.; Wang, Q. Failure probability analysis of the urban buried gas pipelines using Bayesian networks. Process Saf. Environ. Prot. 2017, 111, 678–686. [Google Scholar] [CrossRef]
- Li, F.; Wang, W.; Xu, J.; Yi, J.; Wang, Q. Comparative study on vulnerability assessment for urban buried gas pipeline network based on SVM and ANN methods. Process Saf. Environ. Prot. 2019, 122, 23–32. [Google Scholar] [CrossRef]
- Wang, W.; Shen, K.; Yi, J.; Wang, Q. A mathematical model of crevice corrosion for buried pipeline with disbonded coatings under cathodic protection. J. Loss Prev. Process Ind. 2016, 41, 270–281. [Google Scholar] [CrossRef]
- Pinto, J.; Varum, H.; Bentes, I.; Agarwal, J. A theory of vulnerability of water pipe network (TVWPN). Water Resour. Manag. 2010, 24, 4237–4254. [Google Scholar] [CrossRef]
- Lanzano, G.; Salzano, E.; De Magistris, F.S.; Fabbrocino, G. Seismic vulnerability of gas and liquid buried pipelines. J. Loss Prev. Process Ind. 2014, 28, 72–78. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, G.; Li, J.; Diao, C. Risk assessment along the gas pipelines and its application in urban planning. Land Use Policy 2014, 38, 233–238. [Google Scholar] [CrossRef]
- Liu, D.; Zhou, W.; He, S. Risk assessment for urban gas transmission and distribution system using fuzzy comprehensive evaluation method. J. Pipeline Syst. Eng. Pract. 2018, 9, 04017038. [Google Scholar] [CrossRef]
- Jo, Y.; Park, K.; Kim, H.; Kim, J.; Kim, J.; Ko, J. A quantitative risk analysis method for the natural gas pipeline network. Trans. Inf. Commun. Technol 2010, 43, 195–203. [Google Scholar]
- Hao, M.; You, Q.; Yue, Z. Risk analysis of urban gas pipeline network based on improved bow-tie model. IOP Conference Series: Earth and Environmental Science. IOP Publ. 2017, 93, 012059. [Google Scholar]
- Li, S.; Cheng, C.; Pu, G.; Chen, B. QRA-Grid: Quantitative risk analysis and grid-based pre-warning model for urban natural gas pipeline. ISPRS Int. J. Geo-Inf. 2019, 8, 122. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.X.; Wang, S.M. Research and application of gas pipeline safety planning based on quantitative risk analysis. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 240–246. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Liu, L.; Xie, C.; Wang, R.; Yang, P.; Sudirman, S.; Zhang, J.; Li, R.; Wang, F. Deep learning based automatic multi-class wild pest monitoring approach using hybrid global and local activated features. IEEE Trans. Ind. Inform. 2020, 17, 7589–7598. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Z.; Li, F.; Xie, C.; Ren, T.; Chen, J.; Liu, L. A deep learning framework for driving behavior identification on in-vehicle CAN-BUS sensor data. Sensors 2019, 19, 1356. [Google Scholar] [CrossRef] [Green Version]
- Han, Z.Y.; Weng, W.G. Comparison study on qualitative and quantitative risk assessment methods for urban natural gas pipeline network. J. Hazard. Mater. 2011, 189, 509–518. [Google Scholar] [CrossRef]
- Jamshidi, A.; Yazdani-Chamzini, A.; Yakhchali, S.H.; Khaleghi, S. Developing a new fuzzy inference system for pipeline risk assessment. J. Loss Prev. Process Ind. 2013, 26, 197–208. [Google Scholar] [CrossRef]
- Lu, J.; Wang, Y.N.; Zheng, Y.Y.; Li, J.C. Inspection and assessment of urban gas pipeline based on risk analysis. Applied Mechanics and Materials. Trans. Tech. Publ. 2014, 501, 2386–2391. [Google Scholar]
- Azari, P.; Karimi, M. Extracting spatial patterns of urban gas pipeline risk considering social and structural parameters of urban blocks. J. Nat. Gas Sci. Eng. 2018, 55, 16–29. [Google Scholar] [CrossRef]
- Zhang, Y.; Weng, W. Bayesian network model for buried gas pipeline failure analysis caused by corrosion and external interference. Reliab. Eng. Syst. Saf. 2020, 203, 107089. [Google Scholar] [CrossRef]
- Wang, Z.; Li, S. Data-driven risk assessment on urban pipeline network based on a cluster model. Reliab. Eng. Syst. Saf. 2020, 196, 106781. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; Baltrušaitis, T.; Morency, L.P. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 770–778. [Google Scholar]
- Vielzeuf, V.; Lechervy, A.; Pateux, S.; Jurie, F. Centralnet: A multilayer approach for multimodal fusion. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Pérez-Rúa, J.M.; Vielzeuf, V.; Pateux, S.; Baccouche, M.; Jurie, F. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 6966–6975. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Perez-Rua, J.M.; Baccouche, M.; Pateux, S. Efficient progressive neural architecture search. arXiv 2018, arXiv:1808.00391. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–8 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Zhu, Y.; Groth, O.; Bernstein, M.; Fei-Fei, L. Visual7w: Grounded question answering in images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4995–5004. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 21–29. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 6077–6086. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. arXiv 2019, arXiv:1908.02265. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Wang, R.; Liu, L.; Xie, C.; Yang, P.; Li, R.; Zhou, M. AgriPest: A Large-Scale Domain-Specific Benchmark Dataset for Practical Agricultural Pest Detection in the Wild. Sensors 2021, 21, 1601. [Google Scholar] [CrossRef]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 6904–6913. [Google Scholar]
- Wu, X.; Zhan, C.; Lai, Y.K.; Cheng, M.M.; Yang, J. Ip102: A large-scale benchmark dataset for insect pest recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October 27–2 November 2019; pp. 8787–8796. [Google Scholar]
- Zhang, Y.; Liu, M.; Yang, Y.; Guo, Y.; Zhang, H. A Unified Light Framework for Real-time Fault Detection of Freight Train Images. IEEE Trans. Ind. Informatics 2021, 17, 7423–7432. [Google Scholar] [CrossRef]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Type | Value Intervals | Description | |||
|---|---|---|---|---|---|
| I | II | III | IV | ||
| Indoor gas supply system | [0, 0.4) | [0.4, 0.6) | [0.6, 0.8) | [0.8, 1) | The integrity and corrosion of the indoor gas equipment |
| Gas equipment connection pipe | [0, 0.3) | [0.3, 0.5) | [0.5, 0.7) | [0.7, 0.9) | Material, length and other status of the gas equipment |
| Habits and skills of using gas | [0, 0.4) | [0.4, 0.6) | [0.6, 0.8) | [0.8, 1) | Whether gas users have been trained and standardized |
| Number of gas equipment | [0, 0.3) | [0.3, 0.5) | [0.5, 0.7) | [0.7, 0.9) | The number of gas equipment of the user |
| Gas equipment quality | [0, 0.3) | [0.3, 0.5) | [0.5, 0.7) | [0.7, 0.9) | Years of gas equipment, is there a flameout protection device, etc |
| Environment of the gas equipment | [0, 0.2) | [0.2, 0.4) | [0.4, 0.6) | [0.6, 1) | Sanitation, ventilation and other conditions of the gas equipment |
| Gas use-side management | [0, 0.3) | [0.3, 0.5) | [0.5, 0.7) | [0.7, 0.9) | formulated management rules and regular inspection |
| Gas supply-side management | [0, 0.2) | [0.2, 0.4) | [0.4, 0.6) | [0.6, 1) | Frequency of gas company safety inspections |
| Factor Type | Value Intervals | Description | |||
|---|---|---|---|---|---|
| I | II | III | IV | ||
| Distance from the accident point | [0, 0.4) | [0.4, 0.6) | [0.6, 0.8) | [0.8, 1) | Distance of the rescue point from the accident occurrence point |
| Gas safety facilities | [0, 0.4) | [0.4, 0.6) | [0.6, 0.8) | [0.8, 1) | Setting of the gas leakage alarm and the emergency cut-off valve |
| Gas-use environment | [0, 0.6) | [0.6, 0.7) | [0.7, 0.8) | [0.8, 0.9) | Indoor ventilation conditions, the opening of doors and windows |
| Gas user type | [0, 0.4) | [0.4, 0.6) | [0.6, 0.8) | [0.8, 1) | kind of users, hotels, schools, hospitals and so on |
| Dataset | Task | #Samples | Multi-Modal Information | Drive for Deep Learning | Hierarchical Validation |
|---|---|---|---|---|---|
| ImageNet [13] | Image Classification | >10,000 K | - | ✓ | - |
| MS COCO [39] | Object Detection | 123 K | - | ✓ | |
| VQAv2 [41] | Visual Question Answering | 400 K | ✓ | ✓ | - |
| IP102 [42] | Pest Recognition | 75 K | - | ✓ | ✓ |
| Zhang et al. [43] | Train Fault Detection | 3.8 K | - | ✓ | - |
| Wang and Li [21] | Risk Assessment | 0.7 K | - | - | - |
| Li et al. [3] | Risk Assessment | 2 K | - | - | ✓ |
| GSS-20K (Ours) | GSS-RA | 20K | ✓ | ✓ | ✓ |
| Method | Possibility Risk | Consequence Risk | Final Risk | |||
|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | |
| Single-Modal Methods | ||||||
| DNN | - | - | 0.067 | 0.013 | 0.081 | 0.026 |
| ResNet50 [22] | 0.086 | 0.019 | - | - | 0.069 | 0.012 |
| ResNet101 [22] | 0.085 | 0.017 | - | - | 0.067 | 0.013 |
| GRU [44] | - | - | 0.065 | 0.012 | 0.078 | 0.020 |
| LSTM [33] | - | - | 0.066 | 0.012 | 0.076 | 0.019 |
| Vision Transformer [32] | 0.085 | 0.016 | - | - | 0.066 | 0.012 |
| Multi-Modal Methods | ||||||
| ResNet50 [22] + GRU [44] | 0.078 | 0.017 | 0.060 | 0.010 | 0.062 | 0.011 |
| ResNet50 [22] + LSTM [33] | 0.078 | 0.017 | 0.062 | 0.011 | 0.063 | 0.011 |
| ResNet101 [22] + DNN | 0.076 | 0.016 | 0.063 | 0.011 | 0.072 | 0.012 |
| ResNet101 [22] + GRU [44] | 0.074 | 0.015 | 0.058 | 0.009 | 0.054 | 0.008 |
| ResNet101 [22] + LSTM [33] | 0.069 | 0.013 | 0.052 | 0.008 | 0.048 | 0.006 |
| Our Methods | ||||||
| VET only | 0.063 | 0.011 | 0.061 | 0.010 | 0.047 | 0.006 |
| SMT only | 0.072 | 0.015 | 0.045 | 0.006 | 0.042 | 0.004 |
| GSS-RiskAsser | 0.054 | 0.009 | 0.040 | 0.003 | 0.036 | 0.003 |
| Method | M | K | L | MAE | ||
|---|---|---|---|---|---|---|
| Possibility Risk | Consequence Risk | Final Risk | ||||
| GSS-RiskAsser | 2 | 1 | 1 | 0.065 | 0.051 | 0.048 |
| 3 | 1 | 1 | 0.061 | 0.047 | 0.043 | |
| 4 | 1 | 1 | 0.058 | 0.043 | 0.040 | |
| 4 | 2 | 1 | 0.055 | 0.042 | 0.038 | |
| 4 | 1 | 2 | 0.054 | 0.040 | 0.036 | |
| 4 | 2 | 2 | 0.056 | 0.041 | 0.038 | |
| Method | Fusion | MAE | ||
|---|---|---|---|---|
| Possibility Risk | Consequence Risk | Final Risk | ||
| GSS-RiskAsser | ConcatFusion | 0.065 | 0.051 | 0.047 |
| SumFusion | 0.063 | 0.049 | 0.046 | |
| Single-level Cross-Attention | 0.057 | 0.043 | 0.040 | |
| Mingle-level Cross-Attention | 0.054 | 0.040 | 0.036 | |
| Method | Image Size | Patch Size | MAE | ||
|---|---|---|---|---|---|
| Possibility Risk | Consequence Risk | Final Risk | |||
| GSS-RiskAsser | 8 | 0.067 | 0.049 | 0.046 | |
| 12 | 0.064 | 0.048 | 0.044 | ||
| 12 | 0.059 | 0.044 | 0.038 | ||
| 16 | 0.058 | 0.043 | 0.039 | ||
| 12 | 0.055 | 0.039 | 0.038 | ||
| 16 | 0.054 | 0.040 | 0.036 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Song, L.; Liu, L.; Zhou, L. GSS-RiskAsser: A Multi-Modal Deep-Learning Framework for Urban Gas Supply System Risk Assessment on Business Users. Sensors 2021, 21, 7010. https://doi.org/10.3390/s21217010
Li X, Song L, Liu L, Zhou L. GSS-RiskAsser: A Multi-Modal Deep-Learning Framework for Urban Gas Supply System Risk Assessment on Business Users. Sensors. 2021; 21(21):7010. https://doi.org/10.3390/s21217010
Chicago/Turabian StyleLi, Xuefei, Liangtu Song, Liu Liu, and Linli Zhou. 2021. "GSS-RiskAsser: A Multi-Modal Deep-Learning Framework for Urban Gas Supply System Risk Assessment on Business Users" Sensors 21, no. 21: 7010. https://doi.org/10.3390/s21217010
APA StyleLi, X., Song, L., Liu, L., & Zhou, L. (2021). GSS-RiskAsser: A Multi-Modal Deep-Learning Framework for Urban Gas Supply System Risk Assessment on Business Users. Sensors, 21(21), 7010. https://doi.org/10.3390/s21217010