
Sky and Ground Segmentation in the Navigation Visions of the Planetary Rovers




Abstract
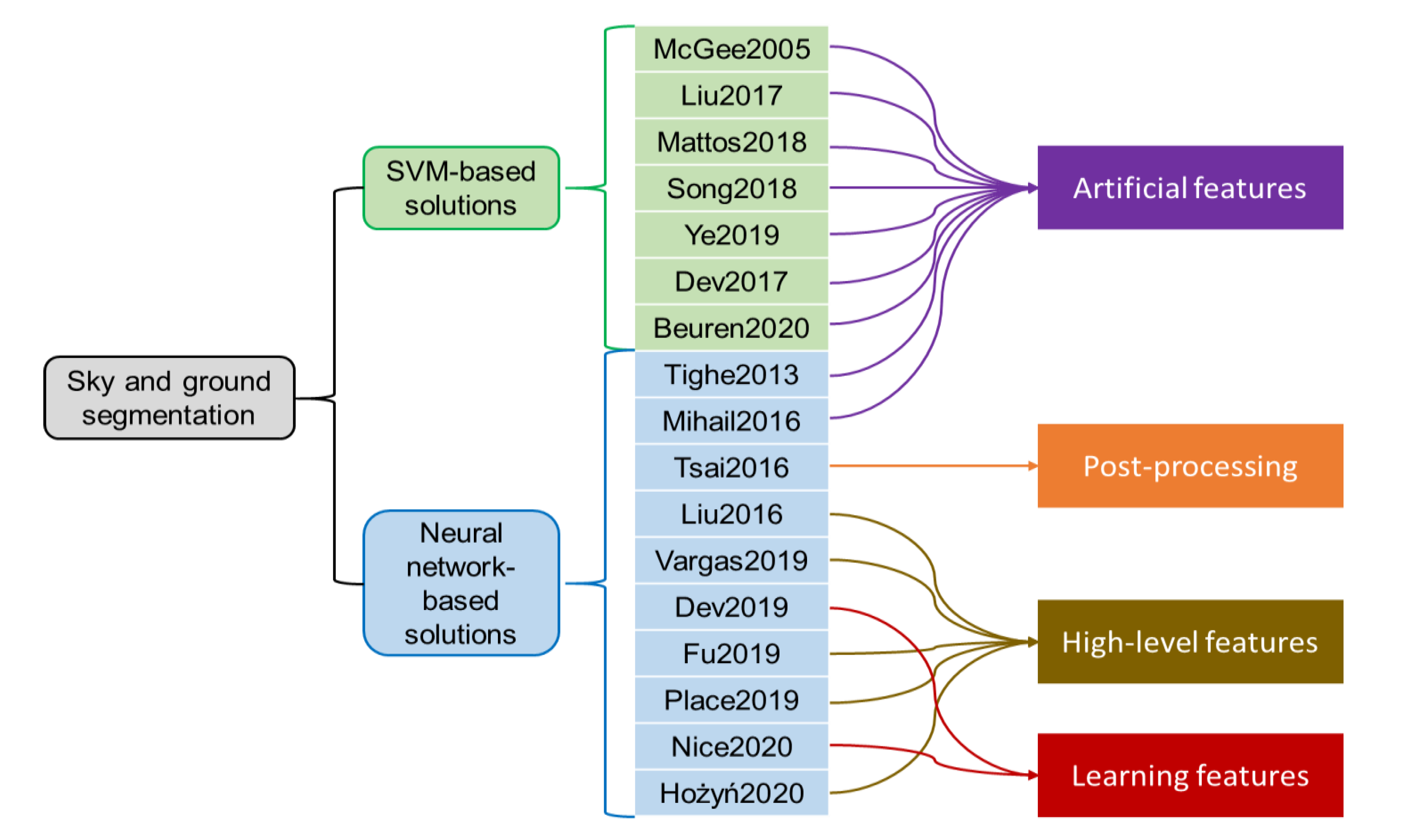
:1. Introduction
- (1)
- This research appears to be the first successful E2E and real-time solution for the navigation visions of the planetary rover.
- (2)
- The sky and ground segmentation network has achieved the best results in seven metrics on the open benchmark (the Skyfinder dataset) compared to the state-of-the-art.
- (3)
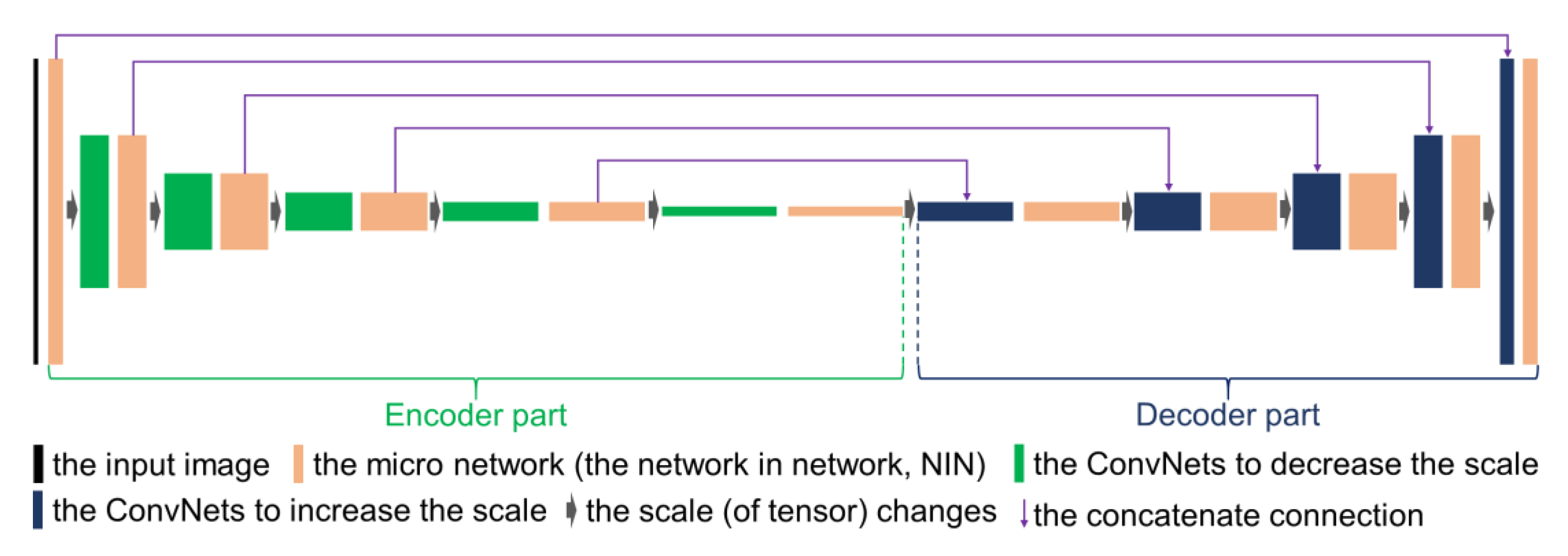
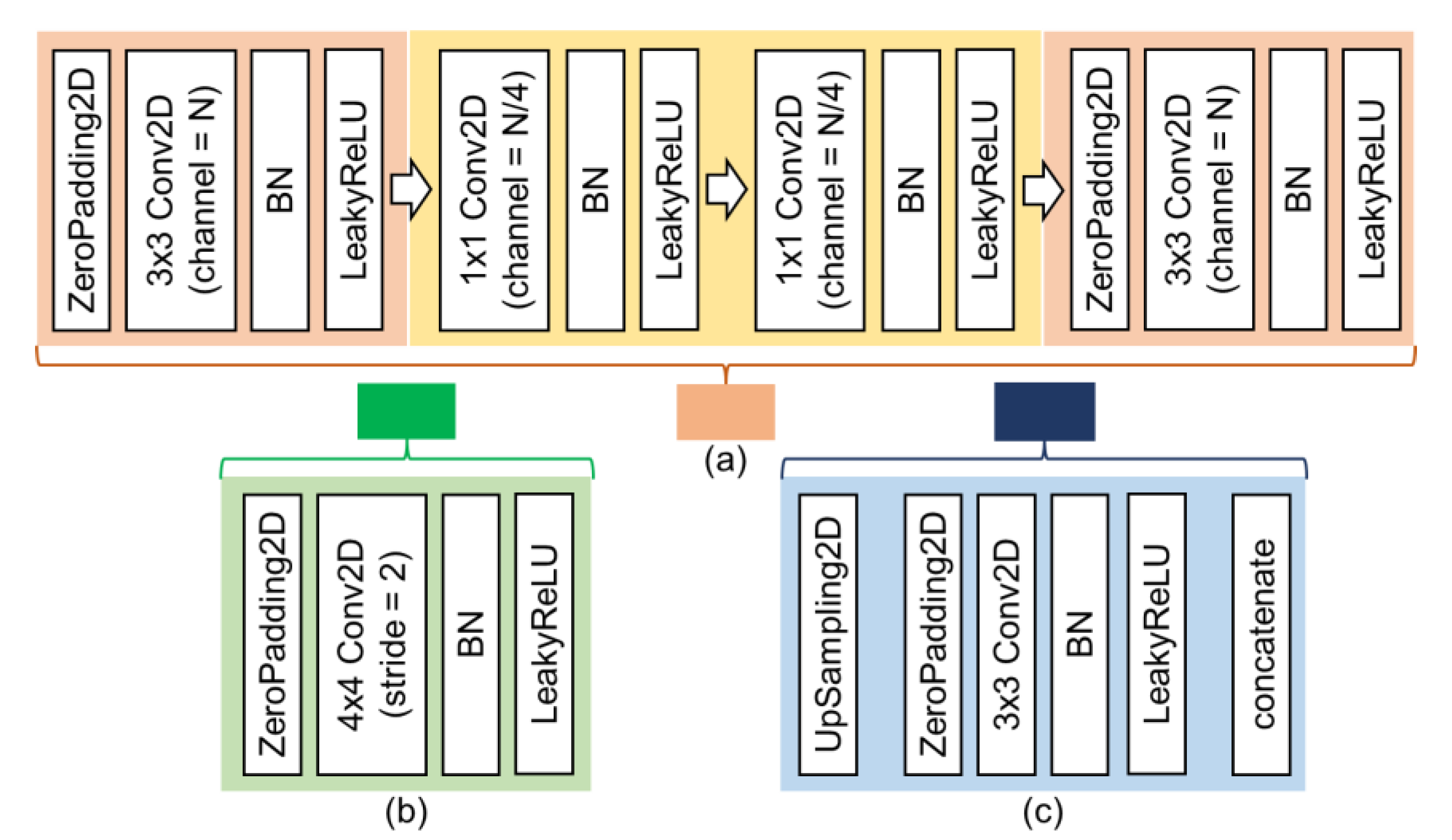
- This research designs a new sky and ground segmentation neural network (network in U-shaped network (NI-U-Net)) for the sky and ground segmentation.
- (4)
- This research proposes a conservative annotation method correlated with the conservative cross-entropy () and conservative accuracy (for the weak supervision. The results indicate that the conservative annotation method can achieve superior performance with limited manual intervention, and the annotation speed is about one to two minutes per image.
- (5)
- This research further transfers the pre-trained NI-U-Net into the navigation vision of the planetary rovers through transfer learning and weak supervision, forming an E2E sky and ground segmentation framework that meets real-time requirements.
2. Methods
2.1. Datasets
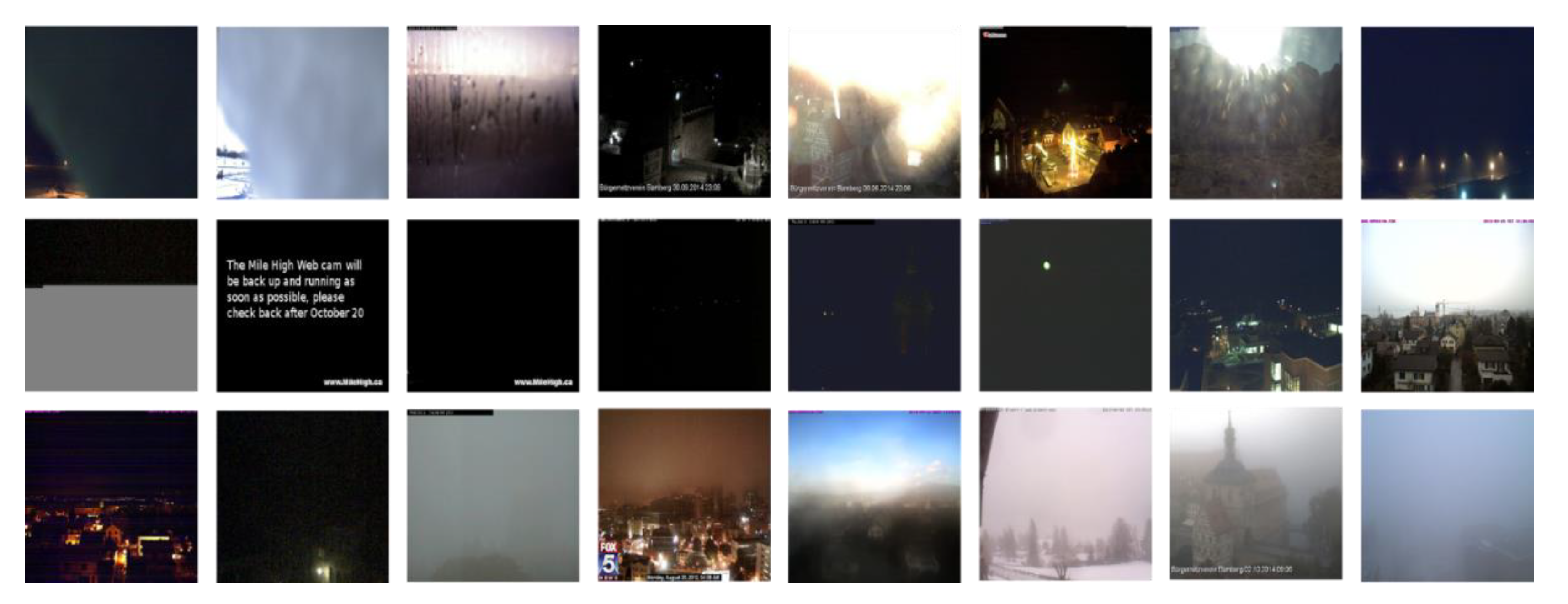
2.1.1. The Skyfinder Dataset
2.1.2. The Katwijk Beach Planetary Rover Dataset
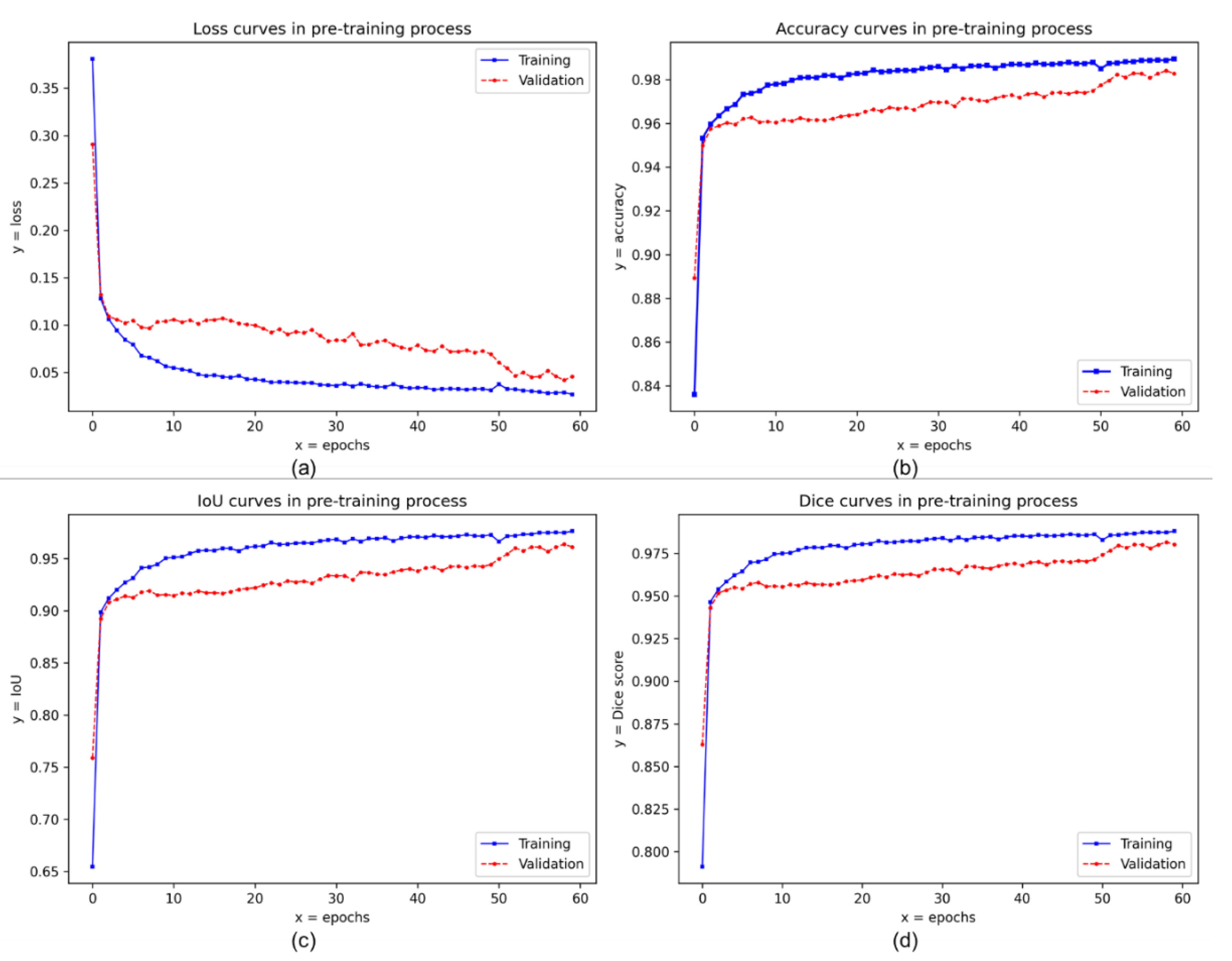
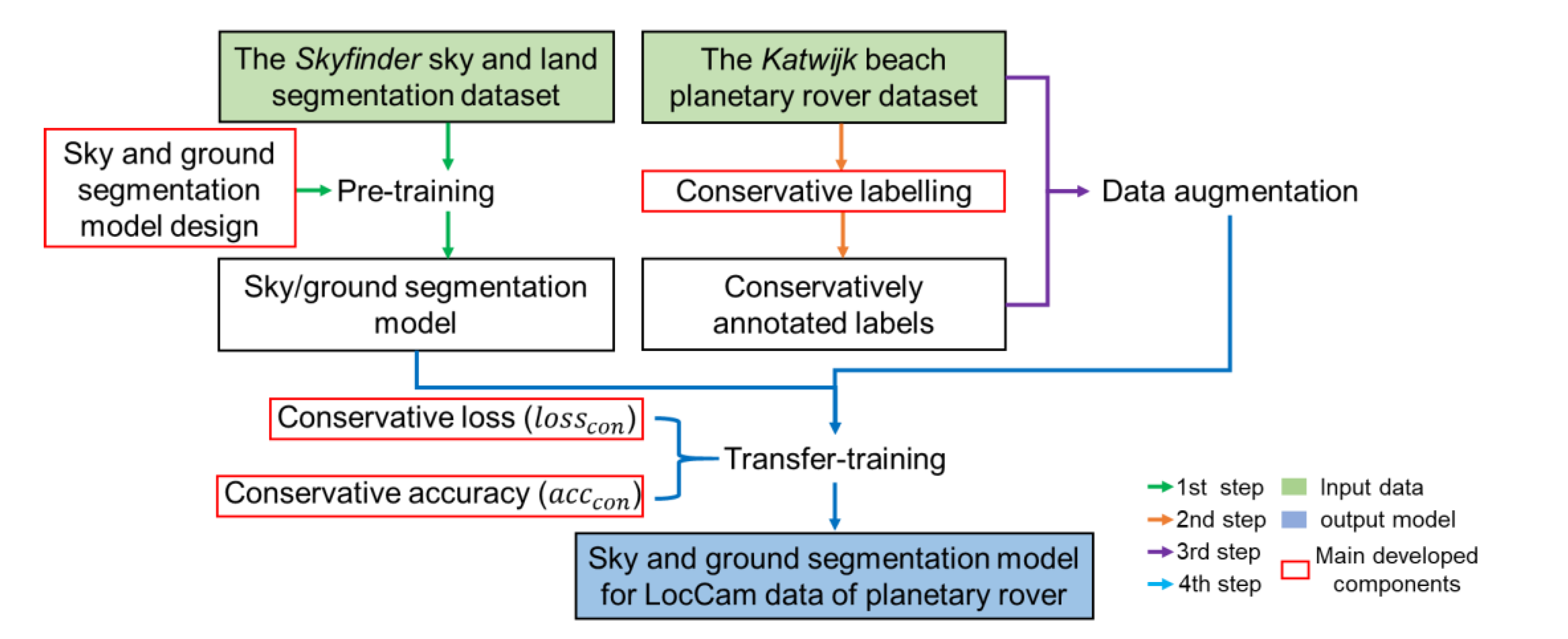
2.2. Pre-Training Process: Sky and Ground Segmentation Network
2.3. Conservative Annotation Strategy
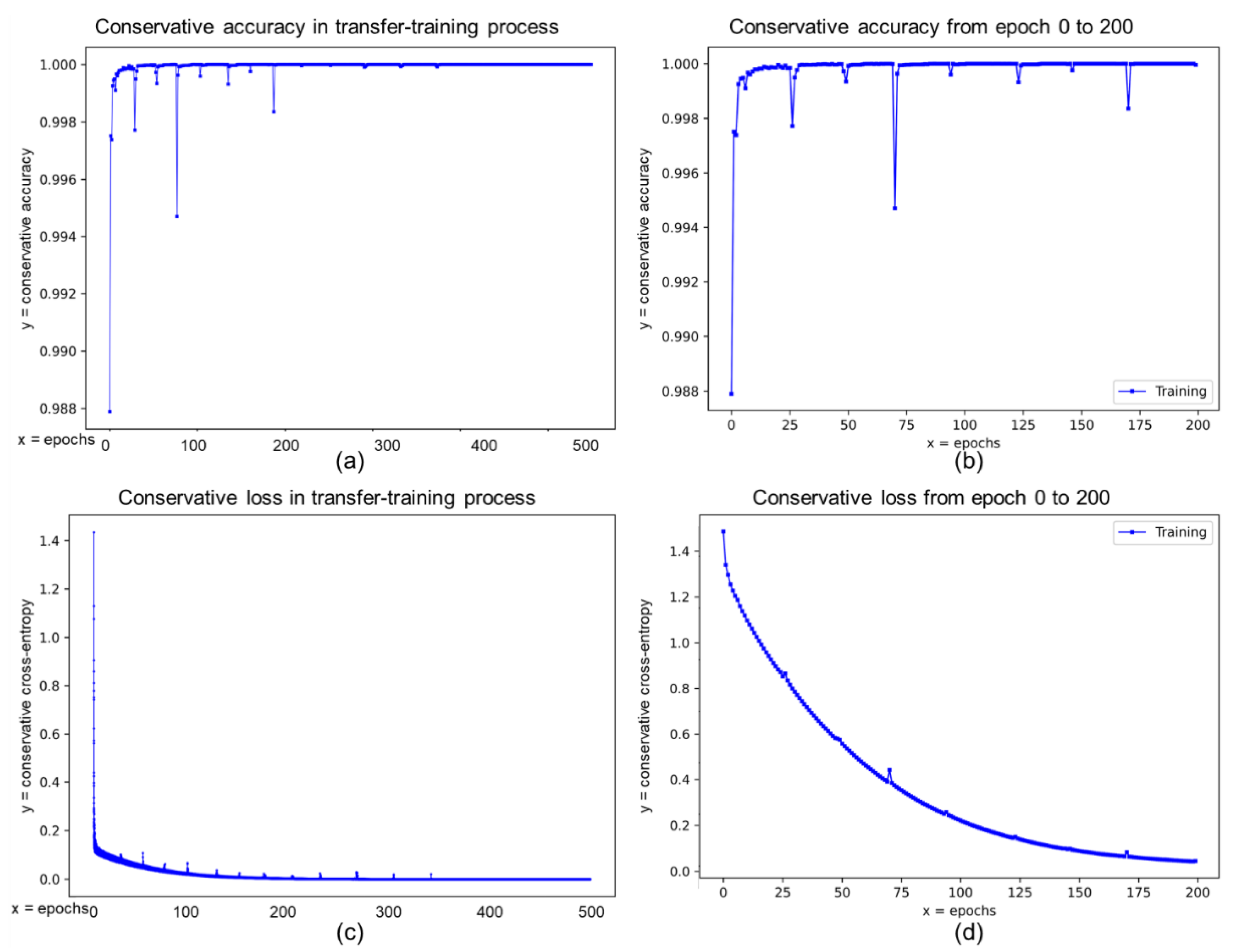
2.4. Transfer Training Process: Sky and Ground Segmentation Network for the Navigation Visions of Planetary Rover
- (1)
- The sky and ground segmentation network inputs a batch of images and outputs a prediction (), while the corresponding conservative label is . The can be divided into the sky, ground, and unannotated pixels using two thresholds ( and ). (Notably, all and subscripts indicate sky and ground.)
- (2)
- This research calculates the number of sky () and ground () pixels in , while the and refer to sky and ground pixel ratio in , respectively.
- (3)
- This research produces a and , where has all conservative annotated sky pixels with value one and others with value zero, where has all conservative annotated ground pixels with value one and others with value zero.
- (4)
- This research conducts the pointwise multiplications between and to achieve the filtered conservative sky pixel prediction (see “” in Equation (21)), which only remains the predictions at the exact locations of the conservatively annotated sky pixels.
- (5)
- This research uses value one to pointwise-subtract the (the “” in Equation (21)) because the situation of sky and ground should be opposite. This research conducts a similar process (as step (4)) to achieve a filtered conservative ground pixel prediction (see “” in Equation (21)).
- (6)
- This research generates the and to indicate the annotated sky and ground pixels only. The has sky pixels with value one and others with zero. The has ground pixels with value one and others with zero.
- (7)
- This research calls the function (Equation (19)) with the input of step (4) and step (6) to achieve the conservative sky cross-entropy. This research calls the function (Equation (19)) with the input of step (5) and step (6) to achieve the conservative ground cross-entropy. This research further adds a weight parameter “” to balance the two cross-entropies.
- (8)
- Equation (22) calls the function (Equation (20)) with the input of step (4) and step (6) to achieve the conservative sky accuracy. Equation (22) calls the function (Equation (20)) with the input of step (5) and step (6) to achieve the conservative ground accuracy.
3. Results and Discussion
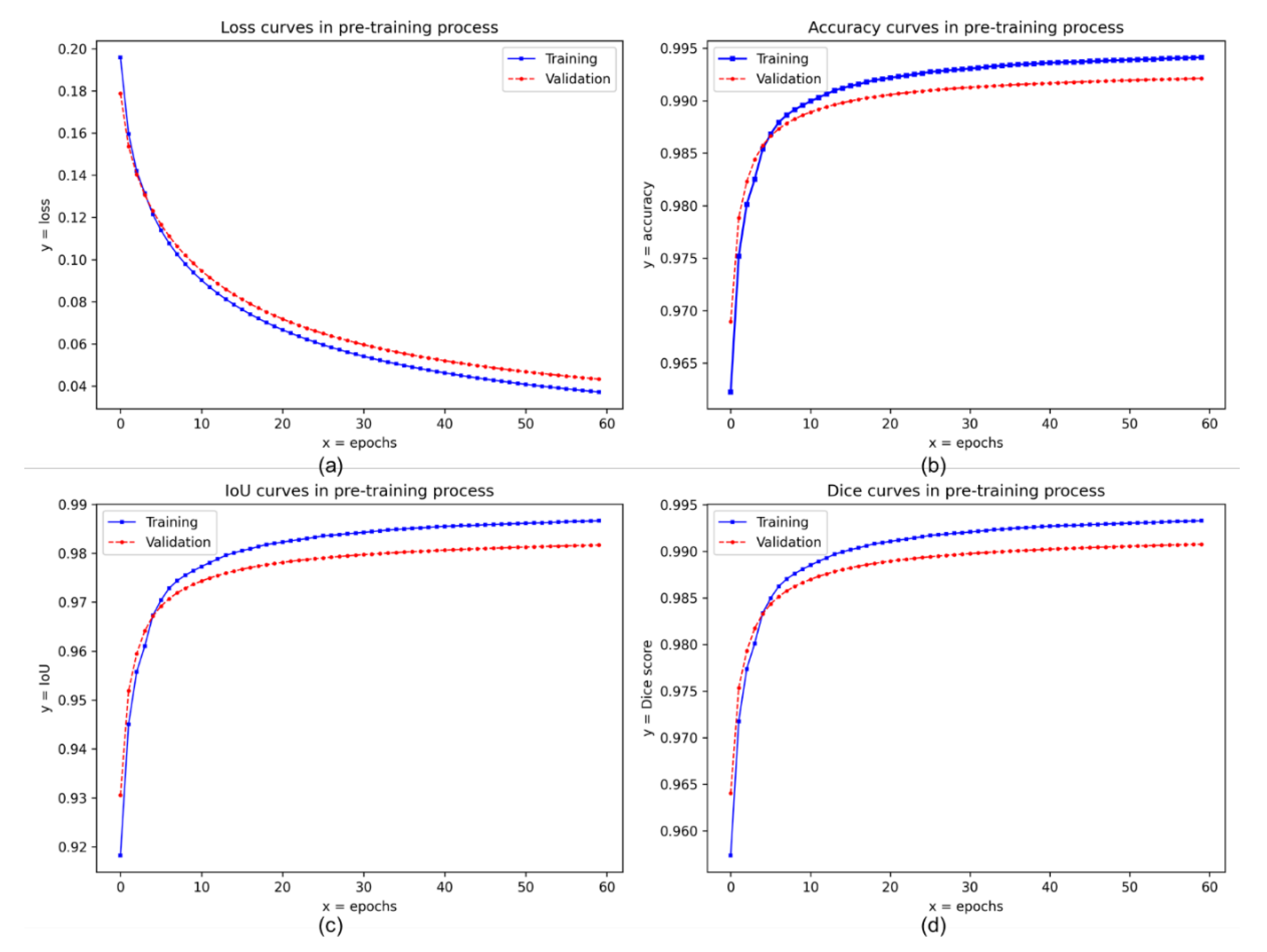
3.1. Pre-Trained Results in the Skyfinder Dataset
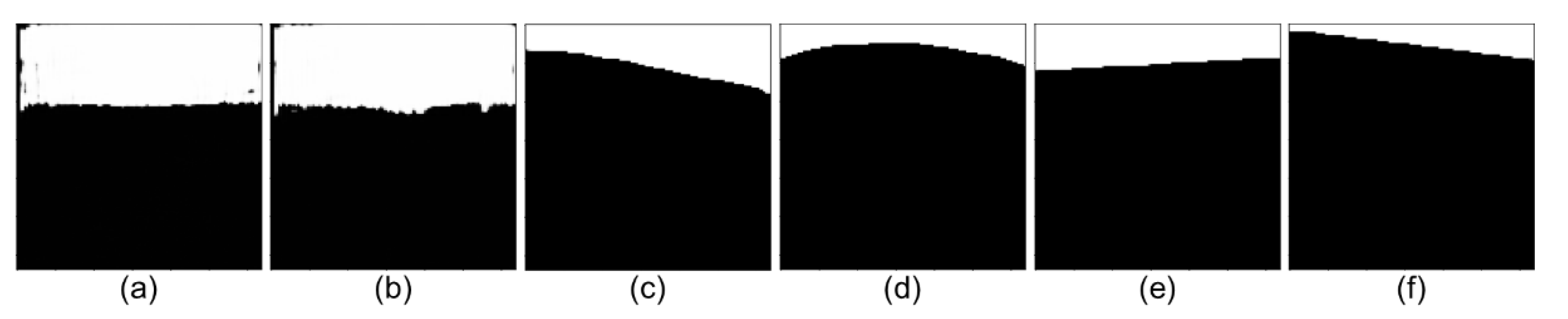
3.2. Intermedia Results of Using Pre-Trained Network in the Katwijk Dataset
- (1)
- The pre-trained network has generally found the sky and ground area (the black and white predictions approximately gathered at corresponding image region).
- (2)
- The pre-trained network also roughly identified the skyline between sky and ground (a shallow trace at the top of the image region).
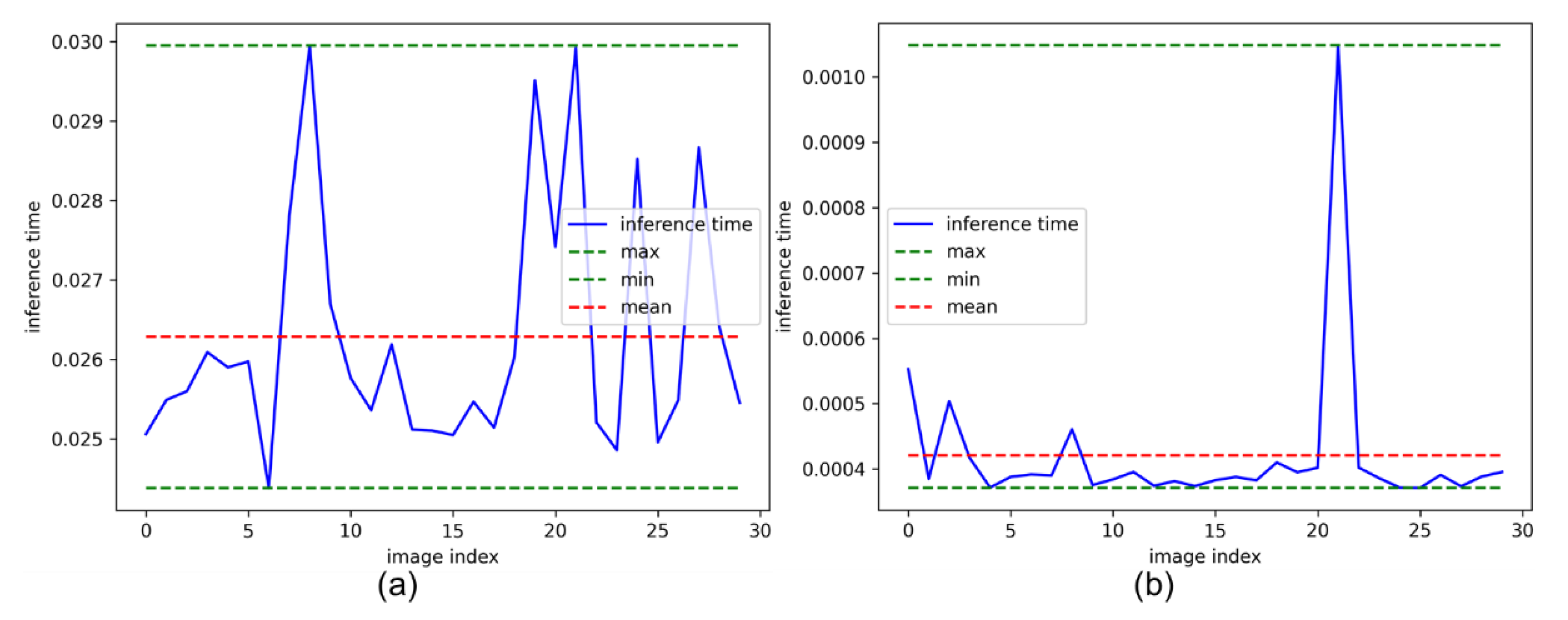
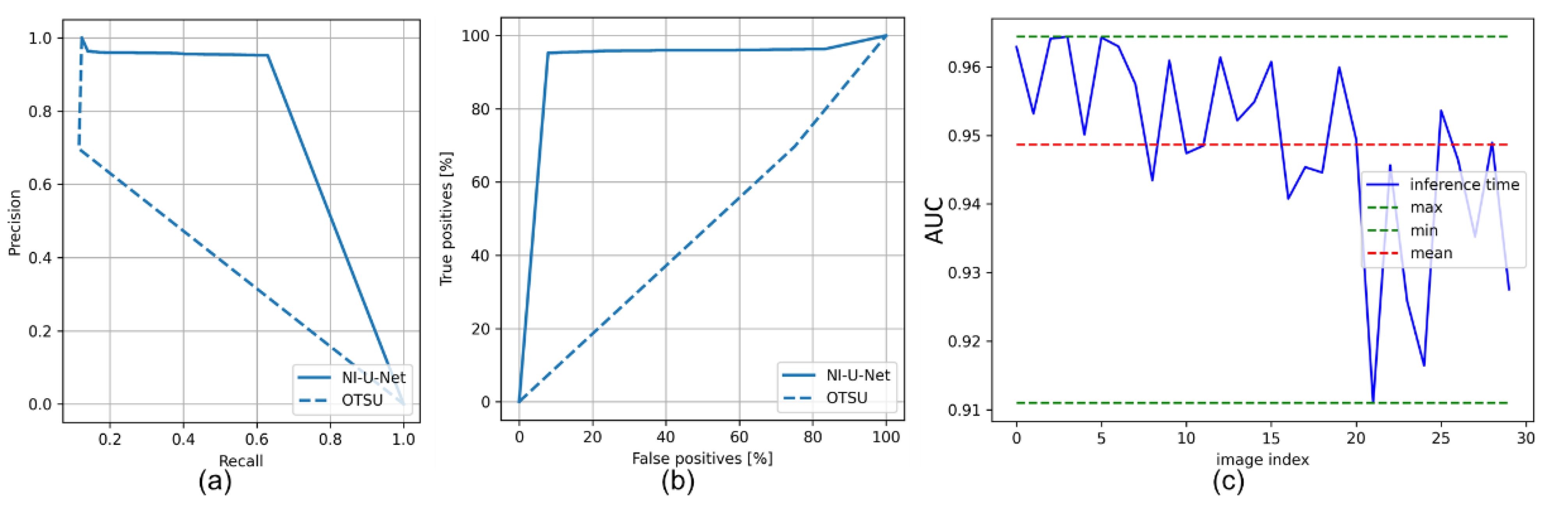
3.3. Final Results in the Katwijk Beach Planetary Rover Dataset
4. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1 Conservative loss and accuracy in once gradient descent | |||
| Input: | |||
| Output: | |||
| 1 | Initialization: | ||
| 2 | Constant: = 0; | ||
| 3 | Array: = 0; | ||
| 4 | for do | ||
| 5 |  | ||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 | |||
| 11 | |||
| 12 | |||
| 13 | |||
| 14 | |||
| 15 | ; | ||
| 16 | ; | ||
| 17 | ; | ||
| 18 | ; | ||
| 19 | ; | ||
| 20 | ; | ||
| 21 | ; | ||
| 22 | ; | ||
| 23 | ; | ||
| 24 | ; | ||
| 25 | ; | ||
| 26 | ; | ||
| 27 | ; | ||
| 28 | ; | ||





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | Real-Time Property | Computing Power Property |
|---|---|---|
| McGee2005 | 320~720 ms | PC104 stack with a 700 MHz Pentium III processor |
| Liu2017 | NA | A 2.2 GHz Inter Pentium Dual Processor and 4 GB RAM |
| Mattos2018 | NA | NA |
| Song2018 | NA | NA |
| Ye2019 | NA | NA |
| Dev2017 | 1.89 s/image | A 64-bit Ubuntu 14.04 LTS workstation, Intel i5 CPU at 2.67 GHz |
| Beuren2020 | NA | NA |
| Tighe2013 | 30 s/image | A single PC with dual Xeon 2.33 GHz quad core processors and 24 GB RAM |
| Mihail2016 | NA | NA |
| Tsai2016 | 12 s for scene parsing and generating the FCN semantic responses, and 4 s to refine the segmentation results; 0.5 s to retrieve a sky image, and 4 s to match a region with the C++ implementation | A Titan X GPU and 12 GB memory |
| Liu2016 | NA | NA |
| Vargas2019 | 0.036 s | a 64 bit, Core(TM) i7-3770K Intel(R) PC with CPU speed of 3.50 GHz |
| Dev2019 | NA | NA |
| Fu2019 | 322.2 ms (resolution is 280 × 320) | a computer with Inter corei7-990X 5 GHz CPU and 4 GB memory |
| Place2019 | NA | a single Titan X GPU |
| Nice2020 | an Nvidia GeForce GTX 1080 GPU | 12 h for training |
| Hozyn2020 | NA | NA |

References
- Shen, Y.; Lin, C.; Chi, W.; Wang, C.; Hsieh, Y.; Wei, Y.; Chen, Y. Resveratrol Impedes the Stemness, Epithelial-Mesenchymal Transition, and Metabolic Reprogramming of Cancer Stem Cells in Nasopharyngeal Carcinoma through p53 Activation. Evid.-Based Complement. Altern. Med. 2013, 2013, 590393. [Google Scholar] [CrossRef] [PubMed]
- Tsai, Y.-H.; Shen, X.; Lin, Z.; Sunkavalli, K.; Yang, M.-H. Sky is not the limit. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Laffont, P.; Ren, Z.; Tao, X.; Qian, C.; Hays, J. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Trans. Graph. 2014, 33, 1–11. [Google Scholar] [CrossRef]
- Lu, C.; Lin, D.; Jia, J.; Tang, C.K. Two-Class Weather Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2510–2524. [Google Scholar] [CrossRef] [PubMed]
- Ye, B.; Cai, Z.; Lan, T.; Cao, W. A Novel Stitching Method for Dust and Rock Analysis Based on Yutu Rover Panoramic Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4457–4466. [Google Scholar] [CrossRef]
- Liu, W.; Chen, X.; Chu, X.; Wu, Y.; Lv, J. Haze removal for a single inland waterway image using sky segmentation and dark channel prior. IET Image Process. 2016, 10, 996–1006. [Google Scholar] [CrossRef]
- Xiao, J.; Zhu, L.; Zhang, Y.; Liu, E.; Lei, J. Scene-aware image dehazing based on sky-segmented dark channel prior. IET Image Process. 2017, 11, 1163–1171. [Google Scholar] [CrossRef]
- Hoiem, D.; Efros, A.A.; Hebert, M. Geometric context from a single image. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 654–661. [Google Scholar] [CrossRef]
- Tighe, J.; Lazebnik, S. Superparsing. Int. J. Comput. Vis. 2013, 101, 329–349. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured Edge Network for Sea–Land Segmentation. IEEE Geosci. Remote Sens. Lett. 2017, 14, 247–251. [Google Scholar] [CrossRef]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. CloudSegNet: A Deep Network for Nychthemeron Cloud Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef] [Green Version]
- Krauz, L.; Janout, P.; Blažek, M.; Páta, P. Assessing Cloud Segmentation in the Chromacity Diagram of All-Sky Images. Remote Sens. 2020, 12, 1902. [Google Scholar] [CrossRef]
- Li, X.; Zheng, H.; Han, C.; Zheng, W.; Chen, H.; Jing, Y.; Dong, K. SFRS-Net: A Cloud-Detection Method Based on Deep Convolutional Neural Networks for GF-1 Remote-Sensing Images. Remote Sens. 2021, 13, 2910. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Wróżyński, R.; Pyszny, K.; Sojka, M. Quantitative Landscape Assessment Using LiDAR and Rendered 360 degree Panoramic Images. Remote Sens. 2020, 12, 386. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.M.; Bertrand, O.J.N.; Differt, D.; Egelhaaf, M. The problem of home choice in skyline-based homing. PLoS ONE 2018, 13, e0194070. [Google Scholar] [CrossRef] [Green Version]
- Towne, W.F.; Ritrovato, A.E.; Esposto, A.; Brown, D.F. Honeybees use the skyline in orientation. J. Exp. Biol. 2017, 220, 2476–2485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stone, T.; Differt, D.; Milford, M.; Webb, B. Skyline-based localisation for aggressively manoeuvring robots using UV sensors and spherical harmonics. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5615–5622. [Google Scholar]
- Freas, C.A.; Whyte, C.; Cheng, K. Skyline retention and retroactive interference in the navigating Australian desert ant, Melophorus bagoti. J. Comp. Physiol. A 2017, 203, 353–367. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Geng, Y.; Zhang, W. Autonomous planetary rover navigation via active SLAM. Aircr. Eng. Aerosp. Technol. 2018, 91, 60–68. [Google Scholar] [CrossRef]
- Clark, B.C.; Kolb, V.M.; Steele, A.; House, C.H.; Lanza, N.L.; Gasda, P.J.; VanBommel, S.J.; Newsom, H.E.; Martínez-Frías, J. Origin of Life on Mars: Suitability and Opportunities. Life 2021, 11, 539. [Google Scholar] [CrossRef]
- McGee, T.G.; Sengupta, R.; Hedrick, K. Obstacle Detection for Small Autonomous Aircraft Using Sky Segmentation. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 4679–4684. [Google Scholar]
- Liu, Y.; Li, H.; Wang, M. Single Image Dehazing via Large Sky Region Segmentation and Multiscale Opening Dark Channel Model. IEEE Access 2017, 5, 8890–8903. [Google Scholar] [CrossRef]
- De Mattos, F.; Beuren, A.T.; de Souza, B.M.N.; De Souza Britto, A.; Facon, J. Supervised Approach to Sky and Ground Classification Using Whiteness-Based Features. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), LNAI; Springer Nature: Chem, Switzerland, 2018; Volume 10633, pp. 248–258. ISBN 9783030028398. [Google Scholar]
- Song, Y.; Luo, H.; Ma, J.; Hui, B.; Chang, Z. Sky Detection in Hazy Image. Sensors 2018, 18, 1060. [Google Scholar] [CrossRef] [Green Version]
- Dev, S.; Lee, Y.H.; Winkler, S. Color-Based Segmentation of Sky/Cloud Images from Ground-Based Cameras. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 231–242. [Google Scholar] [CrossRef]
- Beuren, A.T.; de Souza Britto, A.; Facon, J. Sky/Ground Segmentation Using Different Approaches. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Gonzalez-Cid, Y.; Burguera, A.; Bonin-Font, F.; Matamoros, A. Machine learning and deep learning strategies to identify Posidonia meadows in underwater images. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Mihail, R.P.; Workman, S.; Bessinger, Z.; Jacobs, N. Sky segmentation in the wild: An empirical study. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Vargas-Munoz, J.E.; Chowdhury, A.S.; Alexandre, E.B.; Galvao, F.L.; Vechiatto Miranda, P.A.; Falcao, A.X. An Iterative Spanning Forest Framework for Superpixel Segmentation. IEEE Trans. Image Process. 2019, 28, 3477–3489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, H.; Wu, B.; Shao, Y.; Zhang, H. Scene-Awareness Based Single Image Dehazing Technique via Automatic Estimation of Sky Area. IEEE Access 2019, 7, 1829–1839. [Google Scholar] [CrossRef]
- La Place, C.; Urooj, A.; Borji, A. Segmenting Sky Pixels in Images: Analysis and Comparison. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1734–1742. [Google Scholar]
- Nice, K.A.; Wijnands, J.S.; Middel, A.; Wang, J.; Qiu, Y.; Zhao, N.; Thompson, J.; Aschwanden, G.D.P.A.; Zhao, H.; Stevenson, M. Sky pixel detection in outdoor imagery using an adaptive algorithm and machine learning. Urban Clim. 2020, 31, 100572. [Google Scholar] [CrossRef]
- Hożyń, S.; Zalewski, J. Shoreline Detection and Land Segmentation for Autonomous Surface Vehicle Navigation with the Use of an Optical System. Sensors 2020, 20, 2799. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V. SVMs modeling for highly imbalanced classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 281–288. [Google Scholar] [CrossRef] [Green Version]
- Saltzer, J.H.; Reed, D.P.; Clark, D.D. End-to-end arguments in system design. ACM Trans. Comput. Syst. 1984, 2, 277–288. [Google Scholar] [CrossRef] [Green Version]
- Ye, L.; Cao, Z.; Xiao, Y.; Yang, Z. Supervised Fine-Grained Cloud Detection and Recognition in Whole-Sky Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7972–7985. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, Q. Sky Region Detection in a Single Image for Autonomous Ground Robot Navigation. Int. J. Adv. Robot. Syst. 2013, 10, 362. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Bebis, G.; Nicolescu, M.; Nefian, A.; Fong, T. Fusion of edge-less and edge-based approaches for horizon line detection. In Proceedings of the 2015 6th International Conference on Information, Intelligence, Systems and Applications (IISA), Corfu, Greece, 6–8 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Shang, Y.; Li, G.; Luan, Z.; Zhou, X.; Guo, G. Sky detection by effective context inference. Neurocomputing 2016, 208, 238–248. [Google Scholar] [CrossRef]
- Carrio, A.; Sampedro, C.; Fu, C.; Collumeau, J.F.; Campoy, P. A real-time supervised learning approach for sky segmentation onboard unmanned aerial vehicles. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; pp. 8–14. [Google Scholar] [CrossRef]
- Chiodini, S.; Pertile, M.; Debei, S.; Bramante, L.; Ferrentino, E.; Villa, A.G.; Musso, I.; Barrera, M. Mars rovers localization by matching local horizon to surface digital elevation models. In Proceedings of the 2017 IEEE International Workshop on Metrology for AeroSpace (MetroAeroSpace), Padua, Italy, 21–23 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 374–379. [Google Scholar]
- Verbickas, R.; Whitehead, A. Sky and Ground Detection Using Convolutional Neural Networks. In Proceedings of the International Conference on Machine Vision and Machine Learning, Prague, Czech Republic, 14–15 August 2014; pp. 1–10. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Hewitt, R.A.; Boukas, E.; Azkarate, M.; Pagnamenta, M.; Marshall, J.A.; Gasteratos, A.; Visentin, G. The Katwijk beach planetary rover dataset. Int. J. Robot. Res. 2018, 37, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Gerdes, L.; Azkarate, M.; Sánchez-Ibáñez, J.R.; Joudrier, L.; Perez-del-Pulgar, C.J. Efficient autonomous navigation for planetary rovers with limited resources. J. Field Robot. 2020, 37, 21981. [Google Scholar] [CrossRef]
- Geromichalos, D.; Azkarate, M.; Tsardoulias, E.; Gerdes, L.; Petrou, L.; Perez Del Pulgar, C. SLAM for autonomous planetary rovers with global localization. J. Field Robot. 2020, 37, 830–847. [Google Scholar] [CrossRef]
- Lamarre, O.; Limoyo, O.; Marić, F.; Kelly, J. The Canadian Planetary Emulation Terrain Energy-Aware Rover Navigation Dataset. Int. J. Robot. Res. 2020, 39, 641–650. [Google Scholar] [CrossRef]
- Sánchez-Ibánez, J.R.; Pérez-del-Pulgar, C.J.; Azkarate, M.; Gerdes, L.; García-Cerezo, A. Dynamic path planning for reconfigurable rovers using a multi-layered grid. Eng. Appl. Artif. Intell. 2019, 86, 32–42. [Google Scholar] [CrossRef] [Green Version]
- Chiodini, S.; Torresin, L.; Pertile, M.; Debei, S. Evaluation of 3D CNN Semantic Mapping for Rover Navigation. In Proceedings of the 2020 IEEE 7th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Pisa, Italy, 22–24 June 2020; pp. 32–36. [Google Scholar]
- Furlán, F.; Rubio, E.; Sossa, H.; Ponce, V. CNN Based Detectors on Planetary Environments: A Performance Evaluation. Front. Neurorobot. 2020, 14, 1–9. [Google Scholar] [CrossRef]
- Ono, M.; Fuchs, T.J.; Steffy, A.; Maimone, M.; Yen, J. Risk-aware planetary rover operation: Autonomous terrain classification and path planning. In Proceedings of the 2015 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015; pp. 1–10. [Google Scholar]
- Furgale, P.; Carle, P.; Enright, J.; Barfoot, T.D. The Devon Island rover navigation dataset. Int. J. Robot. Res. 2012, 31, 707–713. [Google Scholar] [CrossRef] [Green Version]
- NASA. NASA Science Mars Exploration Program. Available online: https://mars.nasa.gov/mars2020/multimedia/raw-images/ (accessed on 29 May 2021).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 9783319245737. [Google Scholar]
- Zhou, Z.; Rahman, S.M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11045, pp. 3–11. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Xiao, J.; Li, J.; Yuan, Q.; Zhang, L. A Dual-UNet with Multistage Details Injection for Hyperspectral Image Fusion. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Ciecholewski, M.; Kassjański, M. Computational Methods for Liver Vessel Segmentation in Medical Imaging: A Review. Sensors 2021, 21, 2027. [Google Scholar] [CrossRef]
- Hinton, G.E. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Martin-Abadal, M.; Guerrero-Font, E.; Bonin-Font, F.; Gonzalez-Cid, Y. Deep Semantic Segmentation in an AUV for Online Posidonia Oceanica Meadows Identification. IEEE Access 2018, 6, 60956–60967. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Panigrahi, S.; Nanda, A.; Swarnkar, T. A Survey on Transfer Learning. In Smart Innovation, Systems and Technologies; IEEE: Piscataway, NJ, USA, 2021; Volume 194, pp. 781–789. ISBN 9789811559709. [Google Scholar]
- Frosst, N.; Hinton, G. Distilling a Neural Network into a Soft Decision Tree. arXiv 2017, arXiv:1711.09784. [Google Scholar]
- Keskar, N.S.; Nocedal, J.; Tang, P.T.P.; Mudigere, D.; Smelyanskiy, M. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2017, arXiv:1609.04836. [Google Scholar]
- Zhixuhao Unet. Available online: https://github.com/zhixuhao/unet (accessed on 23 July 2021).
- Mulesial Pytorch-UNet. Available online: https://github.com/milesial/Pytorch-UNet (accessed on 23 July 2021).
- Qin, X.; He, S.; Zhang, Z.; Dehghan, M.; Jagersand, M. ByLabel: A boundary based semi-automatic image annotation tool. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1804–1813. [Google Scholar] [CrossRef]
- NASA. MARS Exploration Rovers. Available online: https://mars.nasa.gov/mer/multimedia/raw/ (accessed on 19 October 2021).







| Networks | Item | Loss | Accuracy | IoU | Dice Score |
|---|---|---|---|---|---|
| Unit | NA | % | % | % | |
| U-Net | Training set | 0.0268 | 98.844 | 97.625 | 98.798 |
| Validation set | 0.0455 | 98.281 | 96.113 | 98.018 | |
| Testing set | 0.0453 | 98.285 | 96.142 | 98.033 | |
| NI-U-Net | Training set | 0.0372 | 99.411 | 98.664 | 99.327 |
| Validation set | 0.0433 | 99.212 | 98.169 | 99.076 | |
| Testing set | 0.0427 | 99.232 | 98.224 | 99.104 |
| Metrics | Accuracy | Precision | Recall | Dice Score | MCR | RMSE | IoU | Retained Amount |
|---|---|---|---|---|---|---|---|---|
| Unit | % | % | % | % | % | NA | NA | Images |
| Hoiem (2005) | NA | NA | NA | NA | 22.83 | NA | NA | 18,000 |
| Tighe (2010) | NA | NA | NA | NA | 19.51 | NA | NA | 18,000 |
| Lu (2014) | NA | NA | NA | NA | 25.08 | NA | NA | 18,000 |
| Mihail (2016) | NA | NA | NA | NA | 12.96 | NA | NA | NA |
| Song (2018) | NA | NA | NA | NA | 96.30 | NA | NA | 18,000 |
| Place (2019) | NA | NA | NA | NA | 58.90 | NA | 0.8300 | 60,000 |
| Nice (2020) | NA | 94.6 | 96.5 | 95.2 | NA | 0.063 | NA | 38,000 |
| U-Net | 98.285 | 98.464 | 98.094 | 98.033 | 0.0172 | 0.131 | 0.9614 | 70,000 |
| NI-U-Net | 99.232 | 99.211 | 99.221 | 99.104 | 0.0077 | 0.0427 | 0.9822 | 70,000 |
| 1.5606375 × 10−7 | ~100.0% | ~100.0% | ~100.0% |
| Evaluation Loss | Evaluation Accuracy | Evaluation IoU | Evaluation Dice Score |
|---|---|---|---|
| 0.0916 | 99.269% | 99.256% | 99.626% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, B.; Rana, Z.A.; Zhao, Y. Sky and Ground Segmentation in the Navigation Visions of the Planetary Rovers. Sensors 2021, 21, 6996. https://doi.org/10.3390/s21216996
Kuang B, Rana ZA, Zhao Y. Sky and Ground Segmentation in the Navigation Visions of the Planetary Rovers. Sensors. 2021; 21(21):6996. https://doi.org/10.3390/s21216996
Chicago/Turabian StyleKuang, Boyu, Zeeshan A. Rana, and Yifan Zhao. 2021. "Sky and Ground Segmentation in the Navigation Visions of the Planetary Rovers" Sensors 21, no. 21: 6996. https://doi.org/10.3390/s21216996
APA StyleKuang, B., Rana, Z. A., & Zhao, Y. (2021). Sky and Ground Segmentation in the Navigation Visions of the Planetary Rovers. Sensors, 21(21), 6996. https://doi.org/10.3390/s21216996