Abstract
In this paper, efficient gradient updating strategies are developed for the federated learning when distributed clients are connected to the server via a wireless backhaul link. Specifically, a common convolutional neural network (CNN) module is shared for all the distributed clients and it is trained through the federated learning over wireless backhaul connected to the main server. However, during the training phase, local gradients need to be transferred from multiple clients to the server over wireless backhaul link and can be distorted due to wireless channel fading. To overcome it, an efficient gradient updating method is proposed, in which the gradients are combined such that the effective SNR is maximized at the server. In addition, when the backhaul links for all clients have small channel gain simultaneously, the server may have severely distorted gradient vectors. Accordingly, we also propose a binary gradient updating strategy based on thresholding in which the round associated with all channels having small channel gains is excluded from federated learning. Because each client has limited transmission power, it is effective to allocate more power on the channel slots carrying specific important information, rather than allocating power equally to all channel resources (equivalently, slots). Accordingly, we also propose an adaptive power allocation method, in which each client allocates its transmit power proportionally to the magnitude of the gradient information. This is because, when training a deep learning model, the gradient elements with large values imply the large change of weight to decrease the loss function.
1. Introduction
Recently, deep neural networks (DNNs) or convolutional neural networks (CNNs) have been widely applied to complicated signal processing, such as classification tasks and signal regression problems, due to their outstanding performances in nonlinear adaptability and feature extraction ([1,2,3] and references therein) and are also extended to the distributed sensing systems (e.g., the object recognition using distributed micro-Doppler radars in [4] and the data driven digital healthcare applications [5,6,7]). In the distributed sensing systems, centralized training strategies may be adopted to train their common DNN or CNN modules by sharing their sensing data. However, due to the data-size and the privacy issues of the locally collected data, the centralized training is not desirable, especially when the capacity of the backhaul link for the data exchange is limited.
The federated learning approach has been extensively investigated as an alternative distributed machine learning method [8,9] where, rather than sharing their locally collected dataset, the clients report the stochastic gradient information (minimizing the loss function with respect to their local dataset) to the main server. The main server then aggregates the stochastic gradient information and broadcast it to the clients. Accordingly, to achieve the unbiased stochastic gradient at the main server, the training data sampling methods are investigated [10,11]. Furthermore, in [12], to reduce the communication overhead of transmitting the updated gradient information (proportional to the number of weights in the DNNs and CNNs), an efficient weight aggregation protocol for federated learning is proposed and in [13], the structured updating method is proposed for the communication cost reduction. However, they assume that the stochastic gradient information is perfectly transferred from the multiple clients to the main server without any distortion.
In the federated learning process, when the clients are connected with wireless-connected clients, local gradient information needs to be transferred from the distributed clients to the server over the wireless backhaul link and can be distorted due to wireless channel fading. In [14,15,16,17], for the wireless backhaul, the federated learning strategies are proposed for the MNIST hand-writing image classification and the associated wireless resources are efficiently optimized. In [14,15], the average of the local stochastic gradient vectors is recovered at the server when the pre-processed local gradient vectors are transferred from the clients. In [16], the compressive sensing approach is proposed to estimate the local gradient vectors at the server. In [17], joint communication and federated learning model is developed, where the resource allocation and the client selection methods are proposed such that the packet error rates of the communication links between server and clients are optimized. We note that most of the previous works have focused on the estimation of local stochastic gradient vectors at the server.
In this paper, we also consider the federated learning system, where distributed clients are connected to the server via wireless backhaul link and develop efficient training strategies for the federated learning over wireless backhaul link. Differently from the previous works, where the average of the local stochastic gradient vectors (i.e., the equal-weight combining) is recovered at the server, we propose an efficient gradient updating method, in which the local gradients are combined such that the effective signal-to-noise ratio (SNR) is maximized at the server. In addition, we also propose a binary gradient updating strategy based on thresholding in which the round associated with all channel having small channel gains is excluded from federated learning. That is, when the backhaul links for all clients have channel gain smaller than a pre-defined threshold simultaneously, the server may have severely distorted gradient vectors, which can be avoided through the proposed updating with thresholding. Furthermore, because each client has limited transmission power, it is effective to allocate more power on the channel slots carrying specific important information, rather than allocating power equally to all channel resources (equivalently, slots). Accordingly, we also propose an adaptive power allocation method, in which each client allocates its transmit power proportionally to the magnitude of the gradient information. This is because, when training a deep learning model, the gradient elements with large values imply the large change of weight to decrease the loss function.
Through the extensive computer simulations, it can be found that the proposed gradient updating methods improve the federated learning performance over the wireless channel. Specifically, due to the distortion over wireless channel, the classification accuracy of the equal-weight combining decreases drastically as the rounds of the federated learning increase. In contrast, the proposed effective SNR maximizing scheme with thresholding exhibits the accuracy performance which is comparable to that for the federated learning over the error-free backhaul link. We note that, as the threshold level increases, the federated learning is performed stably, because the highly distorted gradient update vector due to small channel gain can be discarded by a large threshold level. However, the large threshold level may incur the gradient updating delay, but the adaptive power allocation strategy can improve the trade-off between the federated learning performance and the learning delay due to the threshold level.
The rest of this paper is organized as follows. In Section 2, the system model for the federated learning system with the wireless backhaul is presented in which the distributed clients have a common CNN module for the handwriting character recognition. In Section 4, gradient updating methods are proposed. In addition, the adaptive power allocation method is also developed considering the importance of the gradient information. In Section 5, we provide several simulation results and in Section 6, we give our conclusions.
2. System Model
In Figure 1, we consider the federated learning systems with wireless backhaul, where the L multi-clients have their own datasets to train each local network. Here, a common neural network model is shared for all clients and it is trained through the federated learning over wireless backhaul connected to the main server. The common neural network is designed for the classification problem, in which the label is induced from the network output for the lth client’s measured data with the label d, . That is,
where denotes the non-linear neural network function with the model parameter that gives the estimate of the categorical label probability vector as its output vector. Here, P denotes the number of weights in the common neural network model and is the dth element of the vector . We note that the size of the model parameter (P) is determined by the structure of the neural network model. Specifically, in the case of a convolutional layer with K filters, the number of weights is given as that accounts for the kernel size (), the number of kernels (K) and the number of biases (K). In the case of a single fully-connected layer, the number of weights is calculated as , where and denote the input size and the number of neurons, respectively. See also Section 2.1. We note that, because the collected data at each client are generally of a large dimension with private security issues, it is not desirable to report the collected data to the server. Furthermore, the large dimension of the data may cause the significant burden on the typical backhaul link to transmit a number of training datasets. Instead, the neural network model will be shared over all clients and can be locally trained with the data obtained from each client. By denoting as the model parameter trained at the lth client, is reported to the server through the wireless uplink backhaul for the federated learning. The associated federated learning strategies and power allocation over the wireless backhaul will be discussed in more detail in Section 4.
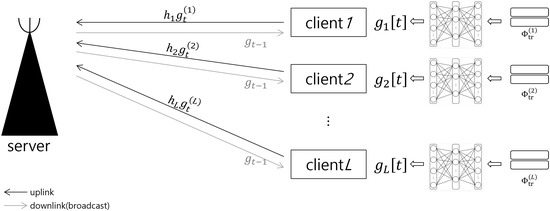
Figure 1.
Federated Learning over wireless communication system for target classification.
2.1. CNN Architecture for Handwriting Character Recognition
Throughout the paper, multiple clients have a common neural network for the handwriting character recognition. Specifically, a typical CNN module is considered for the character image classification as in Figure 2, but the proposed federated learning strategy can be applied to other CNN models. The non-linear neural network function in (1) is composed of an input layer, convolutional layers, activation layers, max pooling layer, a fully-connected layer, and an output layer. See Section 4 for the specific values of the hyperparameters of CNN module.
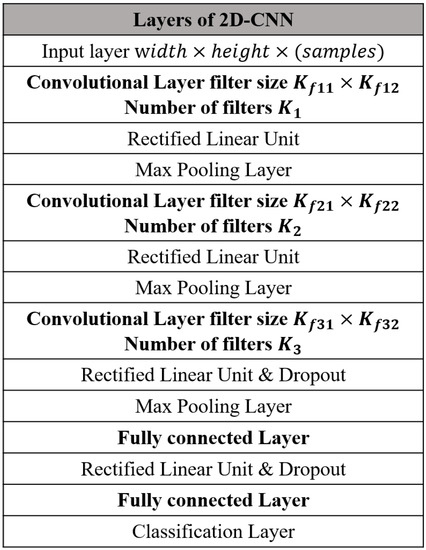
Figure 2.
CNN module for handwriting character recognition.
– Convolution Layer: The handwriting image matrix, is exploited as the input of the convolution layers. In addition, each element of their output is computed through the convolution operation with a filter (equivalently, kernel) for ith layer. Specifically, the output of the ith convolution layer can be given as:
where is the th element of , the input of the ith layer and is an activation function. In addition, is the th element of the filter matrix at the ith layer and is the kth element of a bias vector . Throughout the paper, rectified linear unit (ReLU) function is used as the activation function, which is given as
– Max pooling layer: In the pooling layer, to reduce the dimension of the input data without losing useful information, the elements of the input are down-sampled [18]. In the Max pooling layer, after dividing the input matrix into multiple blocks, the maximum value in each block is sampled and forwarded to the dimension-reduced output matrix.
– Flatten, Fully-Connected (FC) layer: The flatten layer is used for changing the shape of output of convolution layer into the vector which is used as the input of FC layer. We note that, in the case of a single fully-connected layer with input elements and neurons, the number of weights is given as . In the FC layer, the output of convolution layer is associated with a proper loss function such that the label is correctly identified after the training.
Throughout the paper, the cross entropy (CE) is used as the loss function which is given as
where is the output of FC and is a label one-hot encoded vector of size D that has zeros in all elements except the dth element, which is assigned a value of 1. Then, by using the local training datasets () at the lth client, the network function parameter can be updated as:
where denotes the gradient such that the loss function is minimized for the local training datasets and is given as with a learning rate, .
2.2. Signal Model for Wireless Backhaul
As in Figure 1, the clients are connected to the server through the wireless backhaul link. For the federated learning, the model parameters aggregated at the server are broadcast at each iteration of training phase through the wireless downlink channel, while the model parameters trained at the lth client are reported to the server through the wireless uplink backhaul link. Throughout the paper, we focus only on the uplink phase of multiple access channel and assume that the broadcast channel for the downlink phase is error-free, as done in [15,16,19].
Assuming that the clients and the server have a single antenna for the backhaul link, when total B channel resources with narrowband signal bandwidth are available (Here, we note that the channel resources may be given in the frequency axis or may be given in the time axis.), the received signal at server for the tth round of the gradient update can be given as
for , where is the precoded transmit signal of the lth client at the bth channel resource with for the tth round. Here, and denote the aggregated Rayleigh fading channel and the zero-mean additive white Gaussian noise (AWGN) at the bth channel resource, respectively. That is, follows a Gaussian distribution with a zero-mean and a variance (that is, ). Likewise, . In addition, the wireless channel is constant over each round of federated learning process, but changes independently from round to round. By concatenating in (4), the received signal at server can be vectorized as:
where and
Here, denotes a diagonal matrix having its diagonal elements as .
3. Federated Learning for Handwriting Character Recognition
Note that, as in (3), the CNN parameter can be trained with the local training datasets at each client, which limits the adaptability of the CNN due to the lack of the globally measured data. Accordingly, to train their parameters globally, federated learning strategy is exploited, known as an efficient learning strategy suitable to the multi-clients environment such as our system model shown in Figure 1.
Specifically, during the tth round of the training phase, each client receives the gradient of the model parameter from the server via the backhaul link. Then, by exploiting instead of in (3) the network function parameter can be updated as:
We note that is the globally aggregated gradient computed at the server, which tends to minimize the loss function with respect to the data collected at all clients. Then, each client can compute its next local gradient such that the local loss function is minimized for the locally collected datasets . Then, the locally updated gradient vector is reported to the server via the backhaul link. The server can then aggregate the local gradient vector to get as:
where the function represents the gradient aggregation function. In [20], the FederatedAveraging technique (i.e., equal weight combining) is proposed which is given as:
The aggregated gradient is again broadcast to the multi-clients and exploited to update the neural network model at each client. The above described steps are repeated for a given number of rounds, T.
At the beginning of the training phase, the server needs to initialize the global model parameters and, throughout the paper, the parameters are initialized based on He normal weight initialization method [21], which is advantageous when used with ReLU activation function. Based on the above description, generalized federated learning process is summarized in Algorithm 1.
| Algorithm 1. Generalized federated learning train process. |
|
Differently from the centralized learning, the datasets collected by each client are not necessarily reported to the main server in Algorithm 1. We note that, in many cases, data sharing is not free from security, regulatory and privacy issues [8]. We also note that the communication cost for the centralized learning depends on the number/size of the collected data [22,23]. In contrast, the communication cost for the federated learning is independent with the data size, but depends on the CNN architecture (specifically, the number of weights in the CNN).
4. Gradient Updating and Adaptive Power Allocation Strategies for the Federated Learning over Wireless Backhaul
In line 6 of Algorithm 1, multi-clients should report their local gradient vectors through the backhaul link with B channel resources at each round. Specifically, each client should design the transmit signal to transmit in (5). In addition, the server should estimate from the received signal in (5).
4.1. Linear Gradient Estimation for Federated Learning over Wireless Backhaul
To avoid the inter-channel interference over the wireless backhaul link, conventional orthogonal multiple access method with linear precoding is considered in which the wireless resource blocks are orthogonally allocated to each client. Specifically, by letting , which is assumed to be an integer, can be given as
where is a predefined pseudo-random matrix satisfying the restricted isometry property (RIP) condition [24] and unitary such as:
Note that in (3) is split into multiple dimensional vectors, and each split vector is transmitted through wireless resources.
When , can be estimated from (11) by exploiting the linear estimation methods such as zero-forcing or MMSE estimation. That is, ZF estimate of can be given as:
where . When and is sparse, compressive sensing approach such as basis pursuit or orthogonal matching pursuit algorithms [25,26] can be applied to estimate .
4.2. Proposed Gradient Updating Method Using Maximal Ratio Combining and Thresholding
From (12), the server can estimate the gradient reported from the lth client, . Note that, because the channel gain of the wireless backhaul link is varying over the round during the federated learning process. The ill-conditioned channel with small channel gain may increase the estimation error and distort the gradient information associated with the lth client. Accordingly, in what follows, we propose two gradient update methods based on the channel gain, .
4.2.1. Gradient Update by Maximum Ratio Combining
Note that the estimate of is more reliable for larger channel gain. To see this, by considering a simple case with , we can rewrite (12) as:
Accordingly, the mean squared estimation error is proportional to . Equivalently, the effective SNR can be given as . Therefore, when updating the aggregated gradient at the server from , , instead of (8), we can exploit the weighted sum of as
where the weight that maximizes the effective output SNR can be derived as:
which is denoted as the maximum ratio combining (MRC) weights and allows the gradient vector that has undergone a better channel to contribute more to the aggregated gradient at the server. This is because it is more reliable and less-distorted through the wireless backhaul link, as observed from (13). To the best of our knowledge, the gradient update strategy by channel-based MRC in federated learning system with wireless backhaul has not been considered before.
4.2.2. Binary Gradient Update by Thresholding
When the backhaul links for all clients have small channel gain simultaneously, the server may receive severely distorted gradient vectors even though it exploits the MRC strategy, such as (14). Accordingly, we propose a method in which the round associated with all channel having small channel gains is excluded from federated learning. Specifically, if , the associated gradient is not updated at the server, where is a pre-defined constant. Based on the above description, the proposed federated learning process is summarized in Algorithm 2.
| Algorithm 2. Proposed federated learning train process. |
|
4.3. Adaptive Power Allocation Strategy Based on the Gradient Information
When the transmission power of each client is limited, rather than allocating power equally to all channel resources (equivalently, slots), it is effective to allocate more power on the channel slots carrying specific important information. Note that, when training a deep learning model, the gradient elements with large values imply the large change of weight to decrease the loss function. Accordingly, because in (3) is split into multiple dimensional vectors, in (9), each client allocate its transmit power proportionally to the magnitude of in our proposed power allocation strategy. Assuming that is an integer and then, the number of multiple split vectors is given as . The adaptive power allocation strategy can be accomplished by setting:
We note that the constraint of (10) allows the equal power to be used when transmitting the split vector , while the constraint of (16) allows the power to be used in proportion to the magnitude of at each transmission, exhibiting the same total transmit power as in (10). In addition, the power allocation as (16) has not been considered in the conventional federated learning methods over wireless channels.
5. Experiment Results
To see the validation of the proposed federated learning train strategy discussed in Section 4, we develop the CNN module for handwriting character recognition having the architecture in Figure 2. Specifically, the CNN module has three two-dimensional convolutional layers and the values for the hyperparameters exploited in the computer simulations are summarized in Table 1. Then, the number of elements in the gradient vector is given as . The CNN module is shared by three clients connected to the server over the wireless channel. Throughout the simulations, we exploit the handwriting MNIST dataset where . In addition, three clients are considered and the received SNR at the server is defined as:
where is the variance of the AWGN. In addition, we split the gradient vector into multiple vectors having 128 elements (i.e., in (9)).

Table 1.
The values for the hyperparameters of the CNN module for handwriting character recognition.
In Figure 3 (respectively, Figure 4), we evaluate the classification accuracy and CE loss of the conventional gradient updating method based on the equal-weight combining and the proposed updating method based on MRC, discussed in Section 4.2 for high SNR ( dB) (respectively, low SNR ( dB)). For comparison purposes, the performance of the federated learning with error-free backhaul link is also evaluated. Here, the channel gain of each client is set as and the threshold level in given as , and this value was experimentally determined. For the local training of the commonly shared CNN module, ADAM optimizer is adopted [27] at each client with a fixed learning rate, .
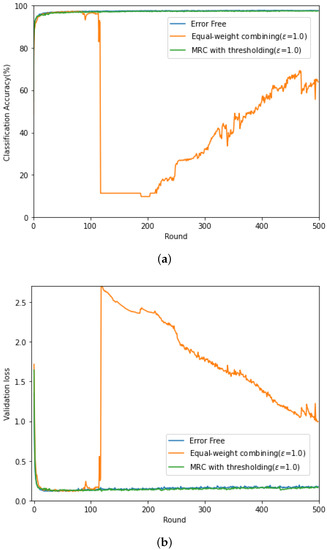
Figure 3.
(a) Classification accuracy and (b) CE loss curves at dB.
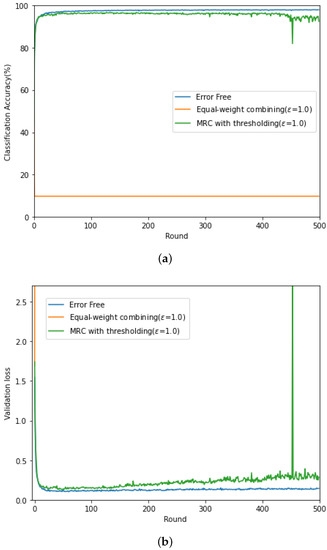
Figure 4.
(a) Classification accuracy and (b) CE loss curves at dB.
From Figure 3, when the backhaul link is perfect and noise free, the classification accuracy increases in proportion to the rounds and the accuracy up to 0.97 can be achieved. In contrast, due to the channel fading and noise in the wireless backhaul link, training does not proceed stably when the conventional equal-weight combining is exploited. In Round 120, there is a sharp increase at the loss curve from to , resulting in the decrease in the accuracy from to . In contrast, the performance of the proposed updating method based on MRC in Section 4.2 exhibits a similar performance to that with the perfect backhaul link. In Figure 4, it can be found that, for low SNR, the classification accuracy of the equal-weight combining is not improved as the rounds increases and is below 0.15. In addition, the associated CE loss goes to infinity. At low SNR, it is difficult to recover the distortion caused over the wireless backhaul link when transmitting the gradient for model update. Especially, when there is channel distortion, the equal-weight combining does not reflect the received SNR in the gradient update and fails to train the distributed CNN modules. Interestingly, the updating method based on MRC and thresholding shows unstable peak in the CE loss, but it can avoid the CE loss divergence and improve the classification accuracy as the learning round increases.
In Figure 5, we evaluate the classification accuracy for various threshold levels with (a) dB and (b) dB when the updating method with MRC and thresholding in Section 4.2.2 is exploited. From Figure 5a, at high SNR, the federated learning can be well operated through the gradient updating method with MRC and thresholding, regardless of the threshold levels. However, for , the accuracy does not effectively increase as the learning round increases. That is, for a larger threshold level, more local gradient vectors transferred through the wireless channel can be discarded. In Figure 5b, it can be found that the classification performance is more sensitive to the threshold level at low SNR compared to the high SNR case. Specifically, as is larger, the federated learning is performed stably. This is also because the gradient update vector containing the amplified noise due to small channel gain can be discarded for large . We note that the large may incur the gradient updating delay, which leads the trade-off between the federated learning performance and the learning delay.
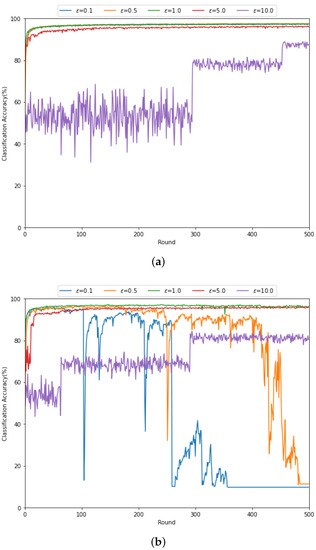
Figure 5.
Classification accuracy according to various threshold levels when the updating method with MRC and thresholding in Section 4.2.2 are exploited for (a) dB and (b) dB.
In Figure 6, to validate the adaptive power allocation strategy in Section 4.3, we evaluate the classification accuracy of various gradient updating methods with/without the adaptive power allocation strategy when the received SNR is low with different threshold levels (i.e., (a) and (b) ). It can be found that the accuracy of the MRC based gradient updating method with in Figure 6a is more stable compared to that with in Figure 6b, which coincides with the observation in Figure 5. Interestingly, by exploiting the adaptive power allocation strategy jointly with the MRC based gradient updating method in Figure 6a, the accuracy can be improved by 96.7% and it is comparable to the performance with error-free backhaul link. In addition, from Figure 6b, the adaptive power allocation strategy drastically stabilizes the federated learning performance during the learning process over wireless channel even for small . Accordingly, the adaptive power allocation strategy improves the trade-off between the federated learning performance and the learning delay due to the threshold level discussed in Figure 5.
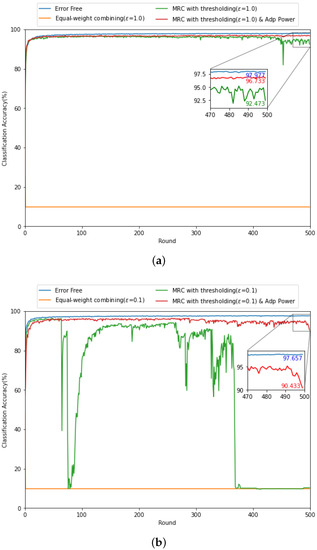
Figure 6.
Comparison of classification accuracy with (a) and (b) for dB.
In Table 2 and Table 3, the confusion matrices for the test dataset are evaluated after the federated learning is completed, where the proposed gradient updating method (Table 2) and the conventional updating method (Table 3) are, respectively, exploited. From Table 2, the proposed gradient updating method shows the classification accuracy of 0.9 or more for all labels. However, from Table 3, the CNN module trained through the conventional gradient updating method over wireless channel misclassifies most test data with specific labels.
Table 2.
Confusion matrix for hand writing character recognition of the proposed gradient updating method.
Table 3.
Confusion matrix for hand writing character recognition of equal-weight combining based gradient updating method.
6. Conclusions
In this paper, efficient gradient updating strategies are developed for federated learning when distributed clients are connected to the server via a wireless backhaul link. That is, a common CNN module is shared for all the distributed clients and it is trained through the federated learning over wireless backhaul connected to the main server. During the training phase, local gradients need to be transferred from the distributed clients to the server over a wireless noisy backhaul link. To overcome the distortion due to wireless channel fading, an effective SNR maximizing gradient updating method is proposed, in which the gradients are combined such that the effective SNR is maximized at the server. In addition, when the backhaul links for all clients have small channel gain simultaneously, the server may have severely distorted gradient vectors. Accordingly, we propose a binary gradient updating strategy based on thresholding in which the round associated with all channels having small channel gains is excluded from federated learning, which results in the trade-off between the federated learning performance and the learning delay. Due to the channel fading and noise in the wireless backhaul link, training does not proceed stably with the conventional equal-weight combining especially at low SNR. In contrast, the updating method based on MRC and thresholding improves the classification accuracy as the learning round increases by avoiding the CE loss divergence. Finally, we also propose an adaptive power allocation method, in which each client allocates its transmit power proportionally to the magnitude of the gradient information. Note that the gradient elements with large values imply the large change of weight to decrease the loss function. Through the computer simulations, it is confirmed that the adaptive power allocation strategy can improve the trade-off between the federated learning performance and the learning delay due to the threshold level.
Author Contributions
Conceptualization, Y.Y. and J.P.; methodology, Y.Y. and J.P.; software, Y.Y., Y.H. and J.P.; validation, J.P.; formal analysis, J.P.; investigation, Y.Y. and Y.H.; writing—original draft preparation, Y.Y.; writing—review and editing, J.P.; supervision, J.P.; project administration, J.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Basic Science Research Program through the National Research Foundation of Korea, funded by the Ministry of Education (2018R1D1A1B07043786).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hadhrami, E.A.; Mufti, M.A.; Taha, B.; Werghi, N. Transfer learning with convolutional neural networks for moving target classification with micro-Doppler radar spectrograms. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–28 May 2018; pp. 148–154. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, Y.; Moon, T. Human Detection and Activity Classification Based on Micro-Doppler Signatures Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 8–12. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Chaabene, S.; Bouaziz, B.; Boudaya, A.; Hökelmann, A.; Ammar, A.; Chaari, L. Convolutional Neural Network for Drowsiness Detection Using EEG Signals. Sensors 2021, 21, 1734. [Google Scholar] [CrossRef] [PubMed]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, B.; Ramage, D. Federated optimization: Distributed optimization beyond the datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Amiri, M.M.; Gündüz, D. Federated Learning Over Wireless Fading Channels. IEEE Trans. Wirel. Commun. 2020, 19, 3546–3557. [Google Scholar] [CrossRef] [Green Version]
- Amiri, M.M.; Gündüz, D. Machine Learning at the Wireless Edge: Distributed Stochastic Gradient Descent Over-the-Air. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1432–1436. [Google Scholar] [CrossRef] [Green Version]
- Jeon, Y.S.; Amiri, M.M.; Li, J.; Poor, H.V. A Compressive Sensing Approach for Federated Learning Over Massive MIMO Communication Systems. IEEE Trans. Wirel. Commun. 2021, 20, 1990–2004. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A Joint Learning and Communications Framework for Federated Learning Over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 269–283. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zhu, G.; Wang, Y.; Huang, K. Broadband Analog Aggregation for Low-Latency Federated Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 491–506. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Xiong, J.; Bi, R.; Zhao, M.; Guo, J.; Yang, Q. Edge-Assisted Privacy-Preserving Raw Data Sharing Framework for Connected Autonomous Vehicles. IEEE Wirel. Commun. 2020, 27, 24–30. [Google Scholar] [CrossRef]
- Kang, D.; Ahn, C.W. Communication Cost Reduction with Partial Structure in Federated Learning. Electronics 2021, 10, 2081. [Google Scholar] [CrossRef]
- Candès, E.J. The restricted isometry property and its implications for compressed sensing. C. R. Math. 2008, 346, 589–592. [Google Scholar] [CrossRef]
- Kim, S.; Yun, U.; Jang, J.; Seo, G.; Kang, J.; Lee, H.; Lee, M. Reduced Computational Complexity Orthogonal Matching Pursuit Using a Novel Partitioned Inversion Technique for Compressive Sensing. Electronics 2018, 7, 206. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Donoho, D. Basis pursuit. In Proceedings of the 1994 28th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 31 October–2 November 1994; Volume 1, pp. 41–44. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).