Design and Implementation of Intelligent Agent Training Systems for Virtual Vehicles



Abstract
1. Introduction
2. State of Research on Intelligent Agents
3. Problem to Be Addressed
4. Material and Methods
- An application with high-quality graphic capacities, which is also able to provide physical representations realistic and suitable for the simulation of a real automobile, is created. In this way, an IA could be trained and tested when taking over such an automobile.
- A movement platform with control commands and Virtual Reality (VR) adequately linked to the same was designed to act as a human control interface. This platform provides the user with stereoscopic vision, a steering wheel, pedals, and movement signs.
- Both training and test tracks are developed.
- Once the IAs are trained, their performances are compared to that of the human expert on both tracks.
4.1. Analysis and Selection of Learning Platforms
- Arcade Learning Environment (ALE) [47]: A simple framework oriented to objects that allows researchers to develop IA for Atari 2600 games. However, it lacks realistic physical representations, and its graphs are over-simplistic.
- DeepMind Lab [48]: A 3D game platform in the first person, designed for AI and ML system researchers. It can be used to study how autonomous artificial agents learn complex tasks in larger realms, partly observed and visually diverse. DeepMind Lab uses the graphic engine of the videogame Quake III and lacks realistic physical representations.
- Project Malmo [49]: A platform designed for research and experiments on AI. It is based on the videogame Minecraft, has polygonal graphs and poor graphic representations.
- Unity [9]: Videogame engine that has a Graphic User Interface (GUI). It provides rendering of high-quality graphs (close to photo realistic), contains physical representations of Nvidia PhysX (Nvidia PhysX is a proprietary mid-layer software engine and development kit designed to perform very complex physical calculations. PhysX is a proprietary “middleware” software layer engine and development kit designed to carry out very complex physical calculations. https://www.ecured.cu/PhysX) and supports scripts in C# programming language. In relation to its simulation potential, the calculations conducted by Unity are independent from rendered photograms and the simulation parameters can be changed during use. Additionally, this software has a free version that offers most of the features in the paid version.
- UE4: High quality videogame engine with realistic graphics. It has a plug-in for TensorFlow. However, both user documentation and quantity of demos offered by the program are poor compared to Unity. Therefore, after the analysis of the main learning platforms currently in use on AI research, Unity was selected for the design and implementation of the development environment presented in this paper, due to its outstanding features.
4.2. Advantages of the Proposed Research
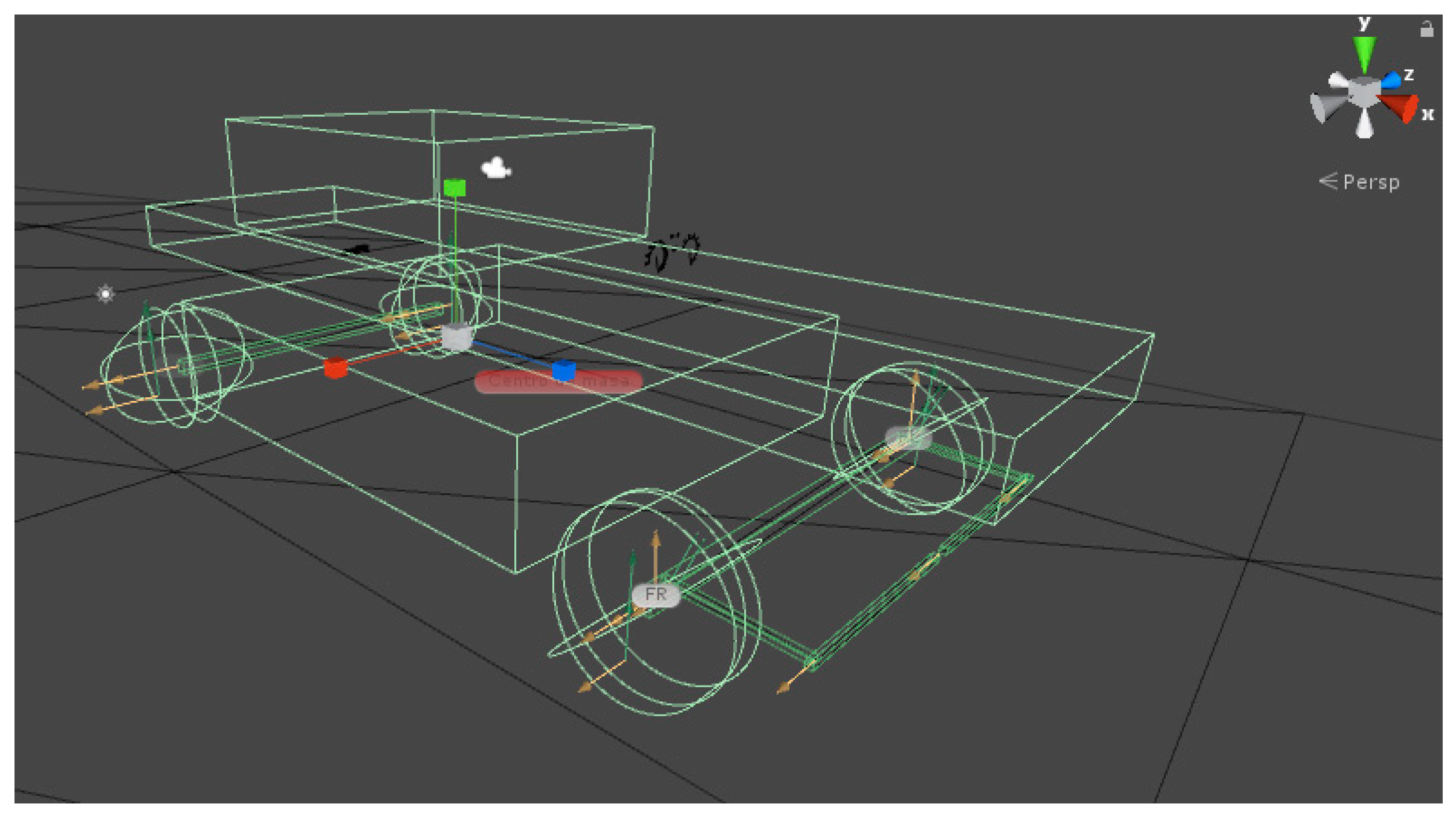
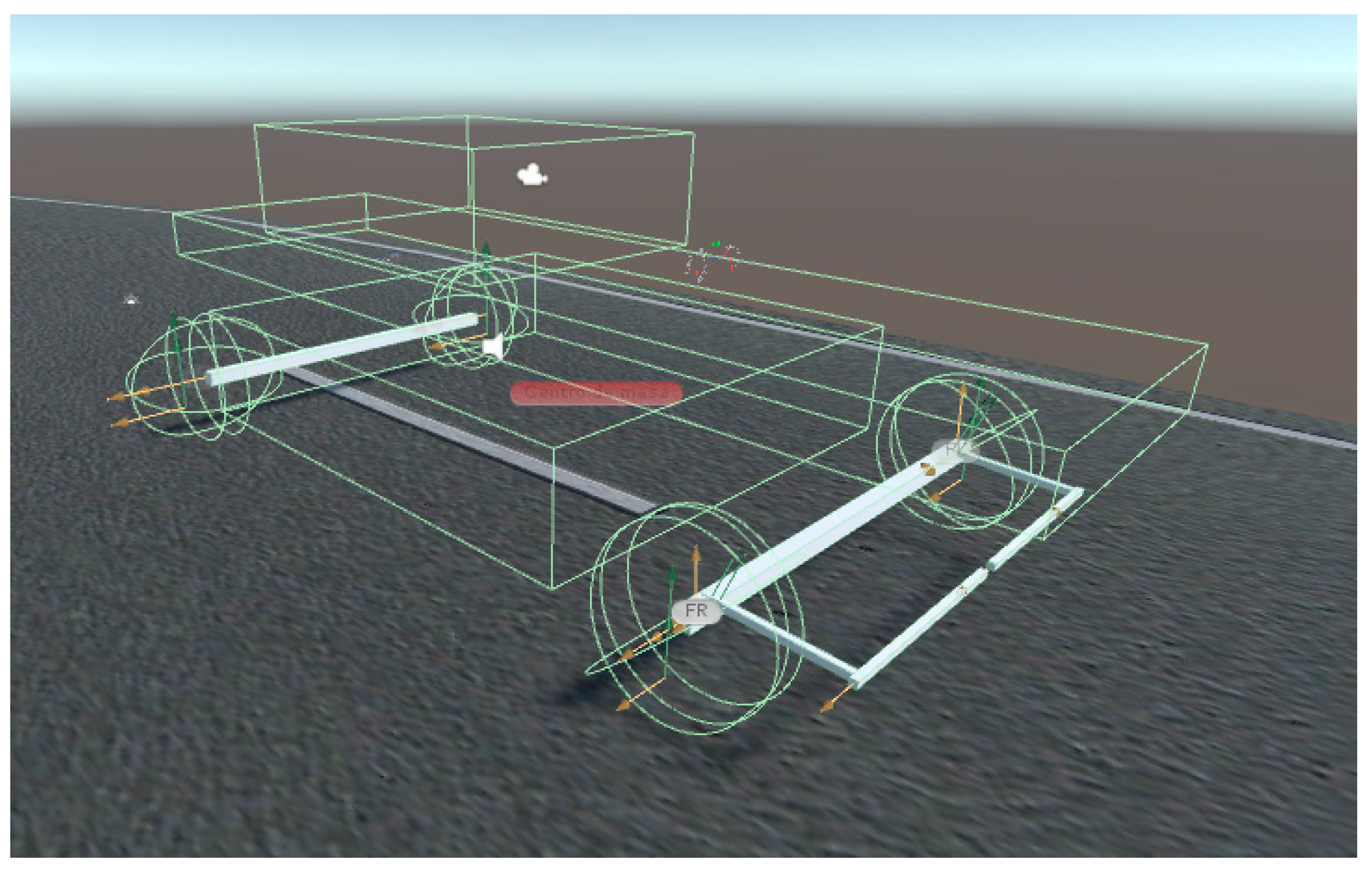
5. Design of the Virtual Vehicle
5.1. Control Interface
5.2. Training Track
5.3. Test Track
6. Theory/Calculation
6.1. Implementation of Learning by Reinforcement and Imitation
6.1.1. Observation Vectors
6.1.2. Reward Function
| Algorithm 1 Award accumulated in each IA’s observation-action cycle |
| for i = 1:20 if ray[i].hit = true Add reward(−0.5/ray[i].distance); end end if velocity ≤ 0 AddReward(−0.1 · f); if velocity > 0 AddReward(2 · f); if 2 < velocity < 12 AddReward(velocity · f); if 12 < velocity ≤ 27 AddReward(0.1 · f); AddReward(−0.1 · acceleration); AddReward(−0.01 · steer · steer); |
6.1.3. Action Vectors
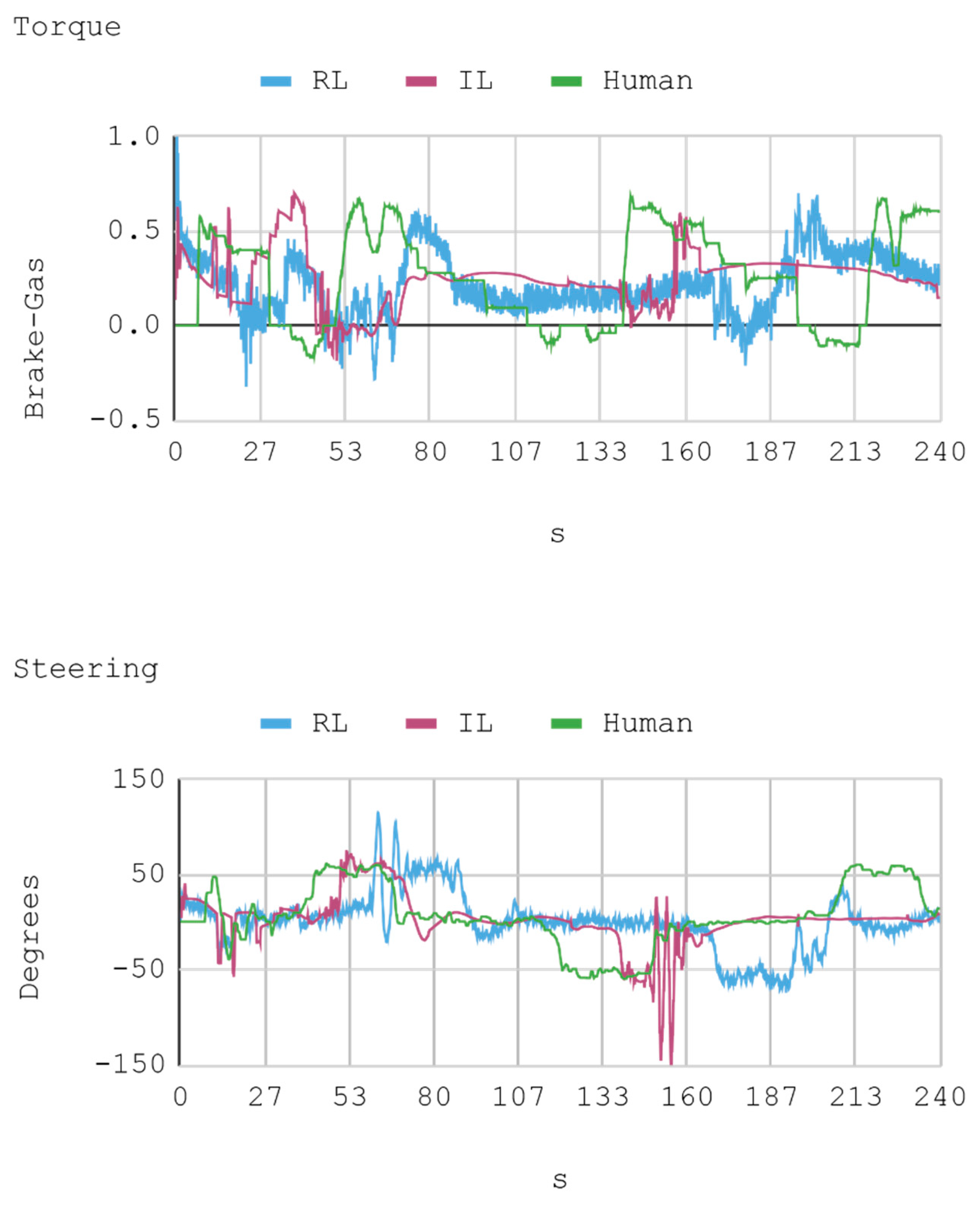
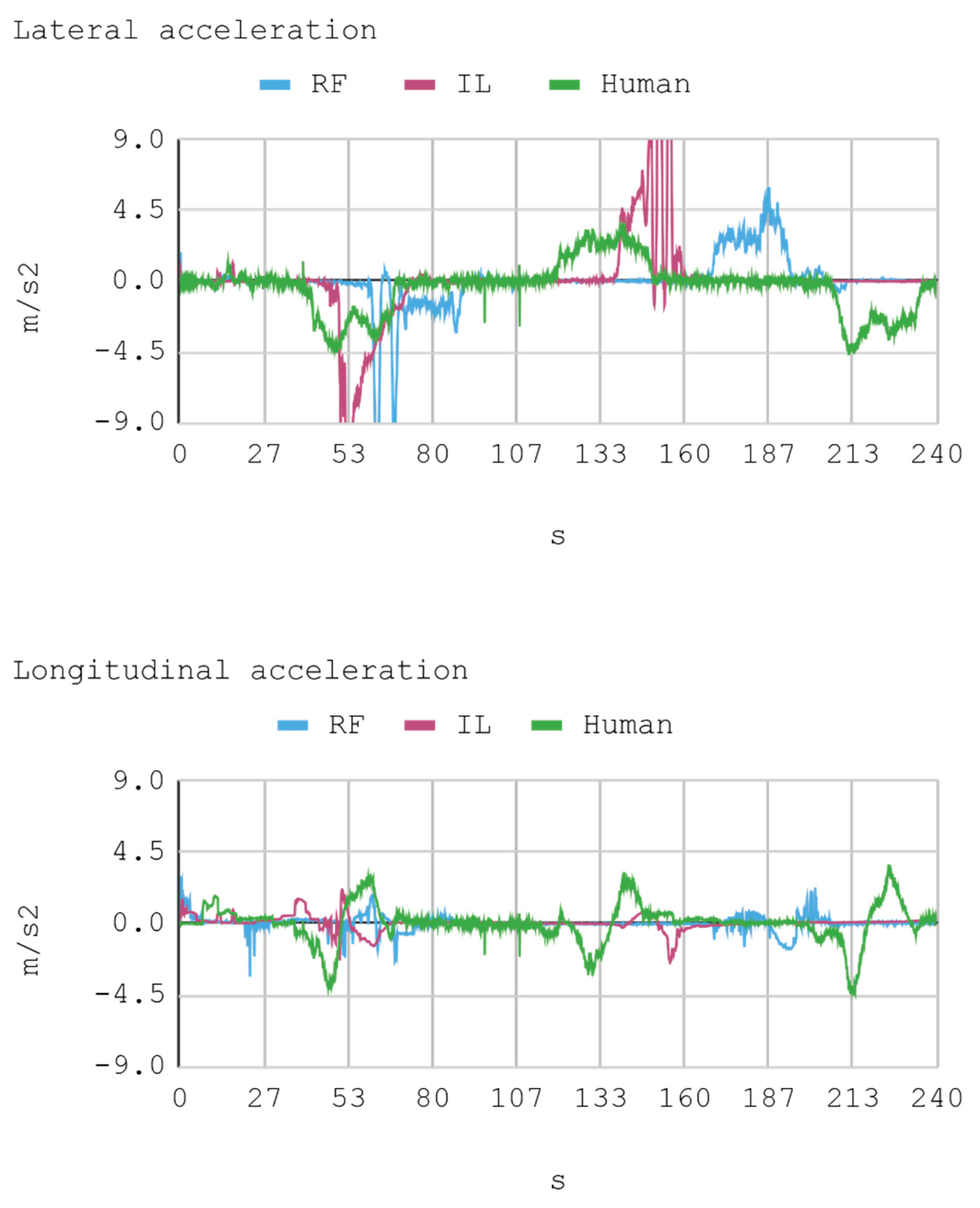
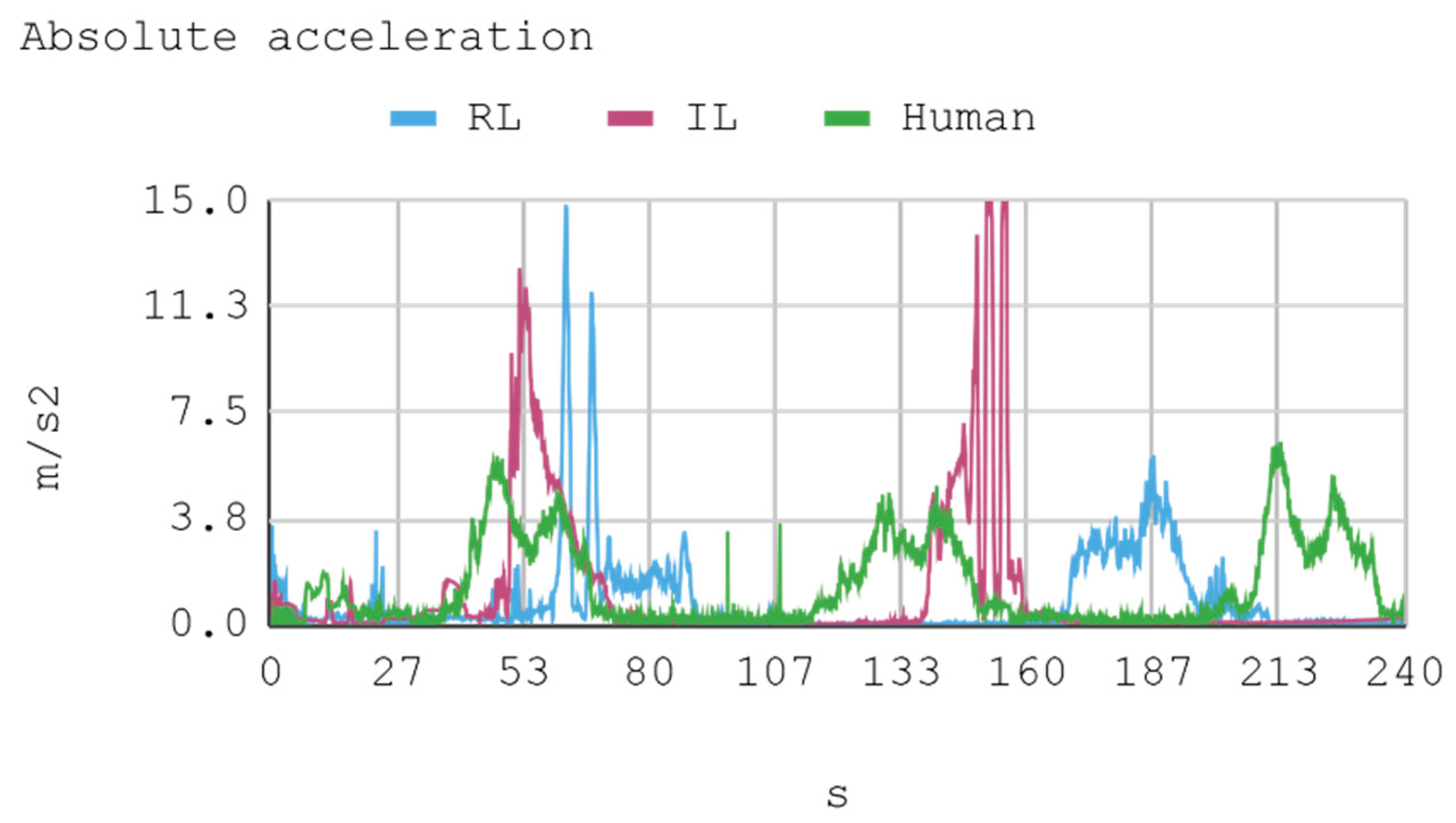
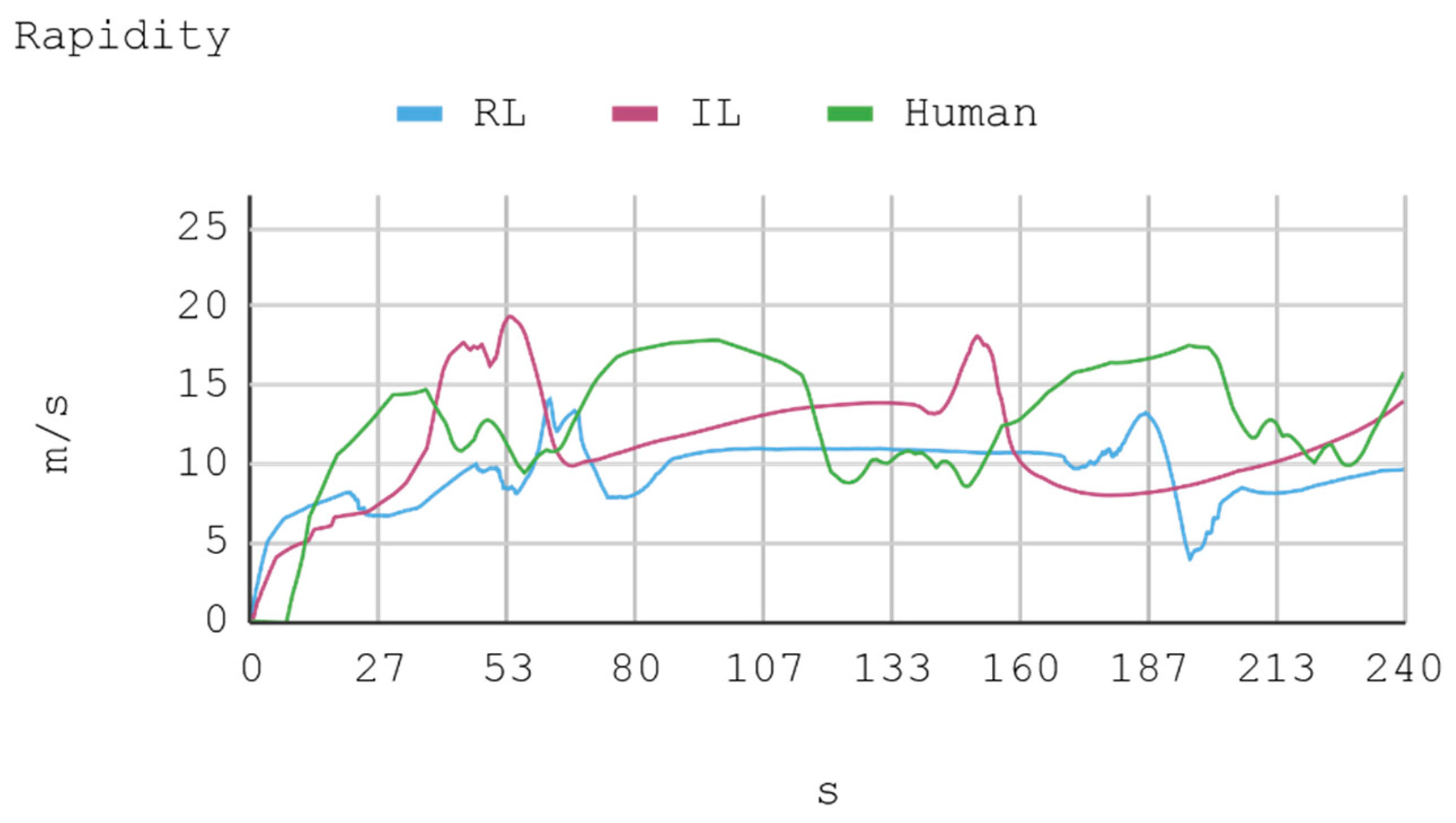
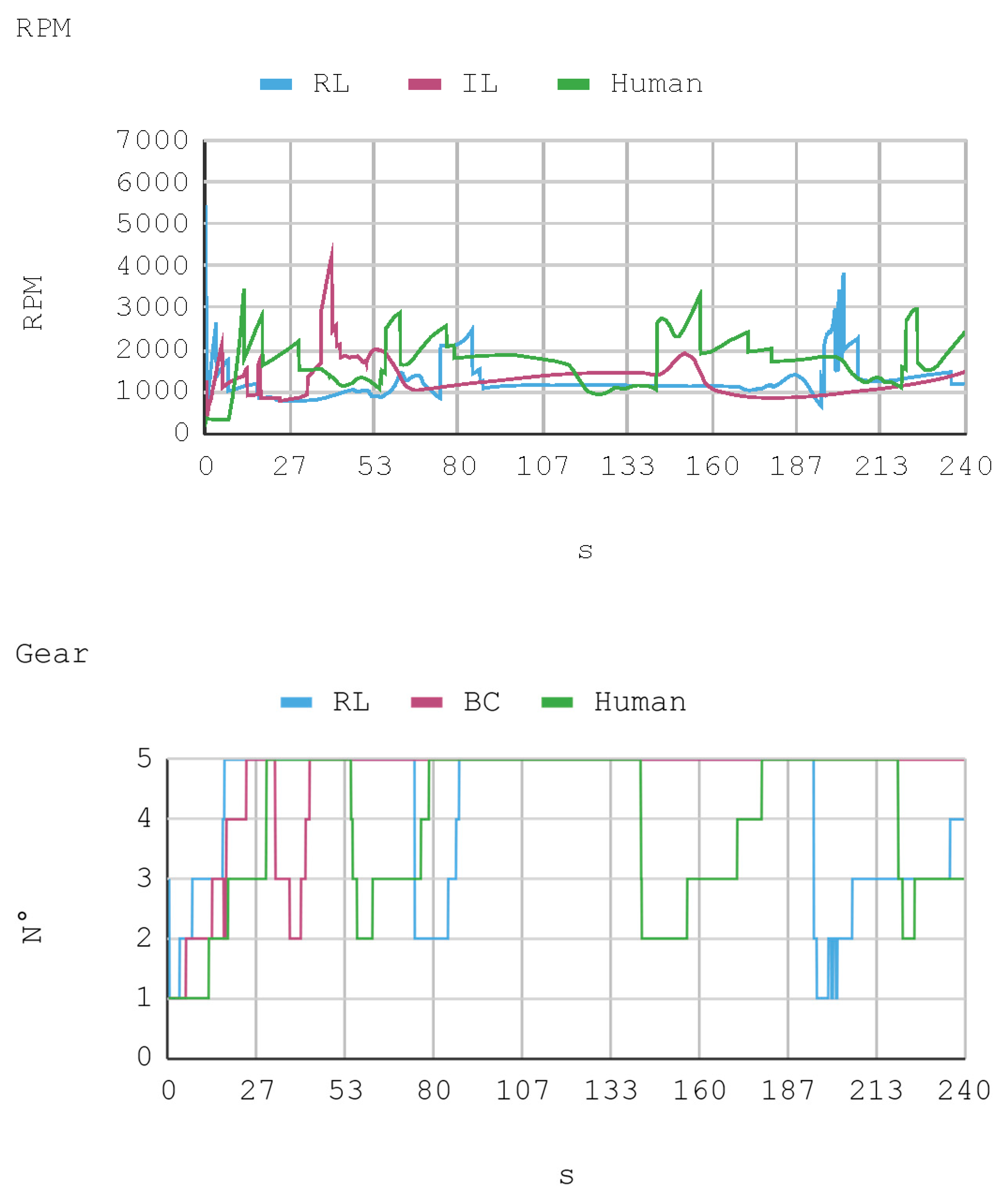
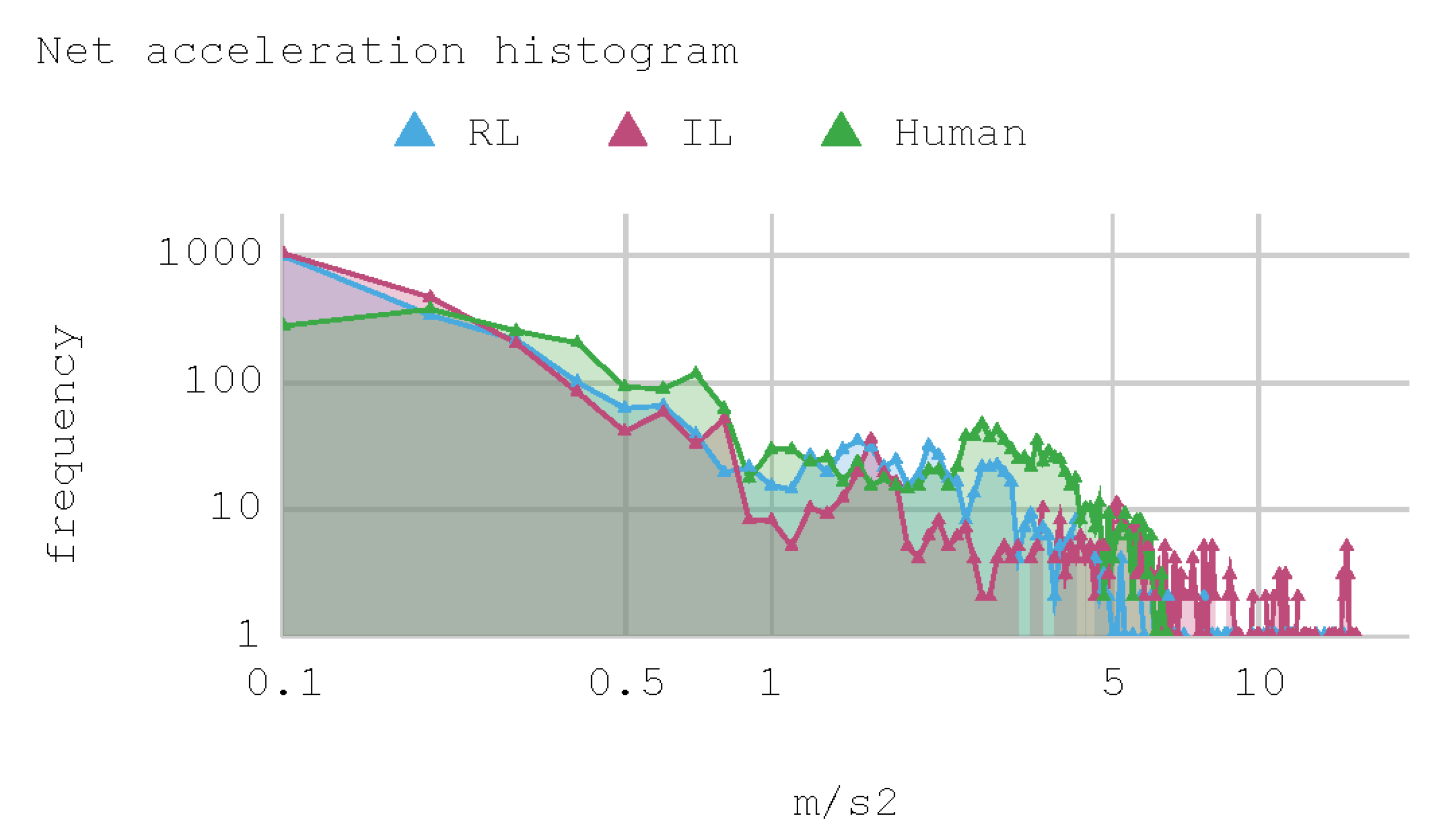
7. Results
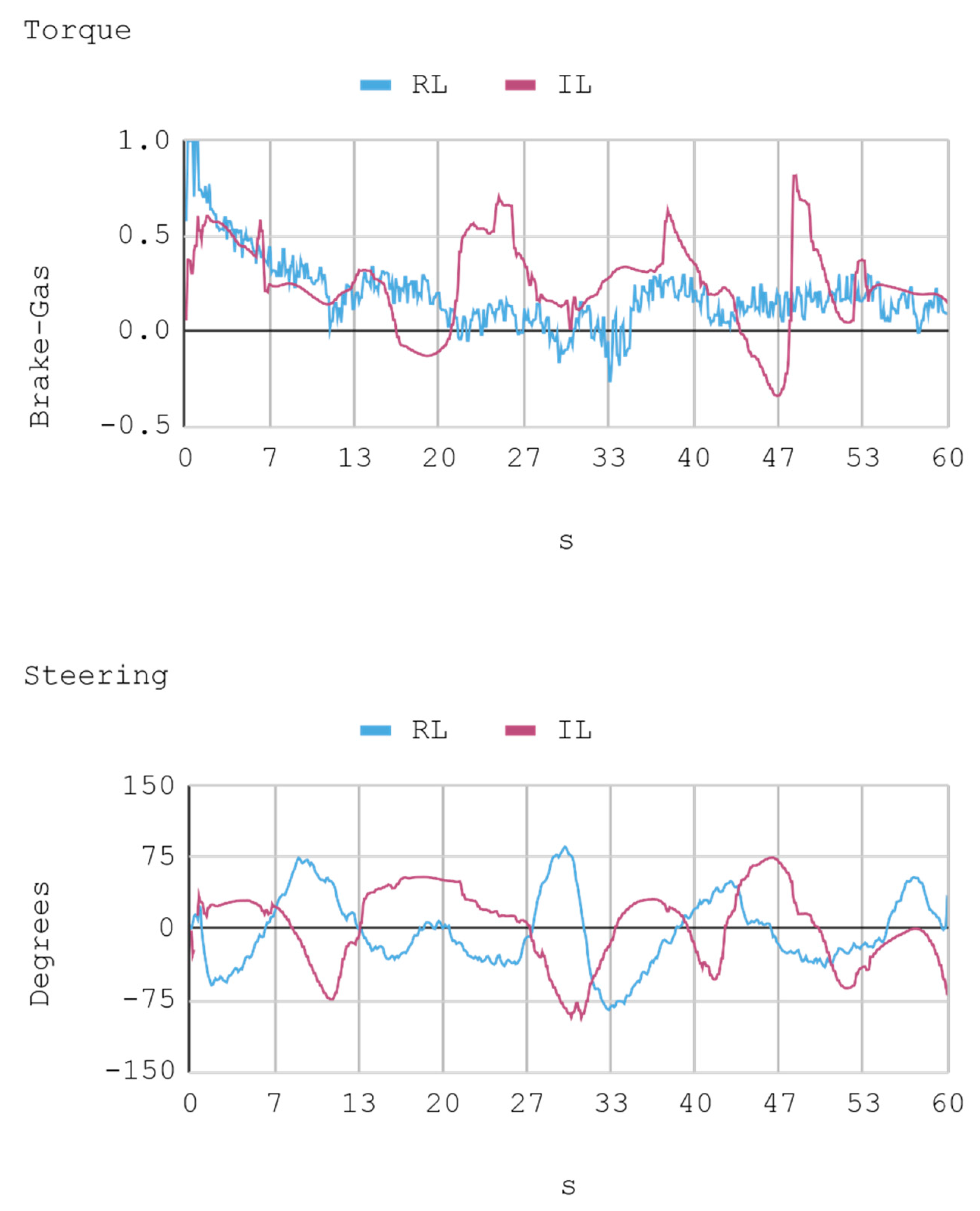
- Gas: A positive torque –representing how open or closed is the flow of fuel to the motor– is obtained for positive values, which enables the vehicle to speed up. Instead, negative values imply that the automobile activates its brakes.
- Steering: This angle allows for controlling the automobile’s steering wheel. Positive values translate into turns to the right, while negative ones indicate turns to the left.
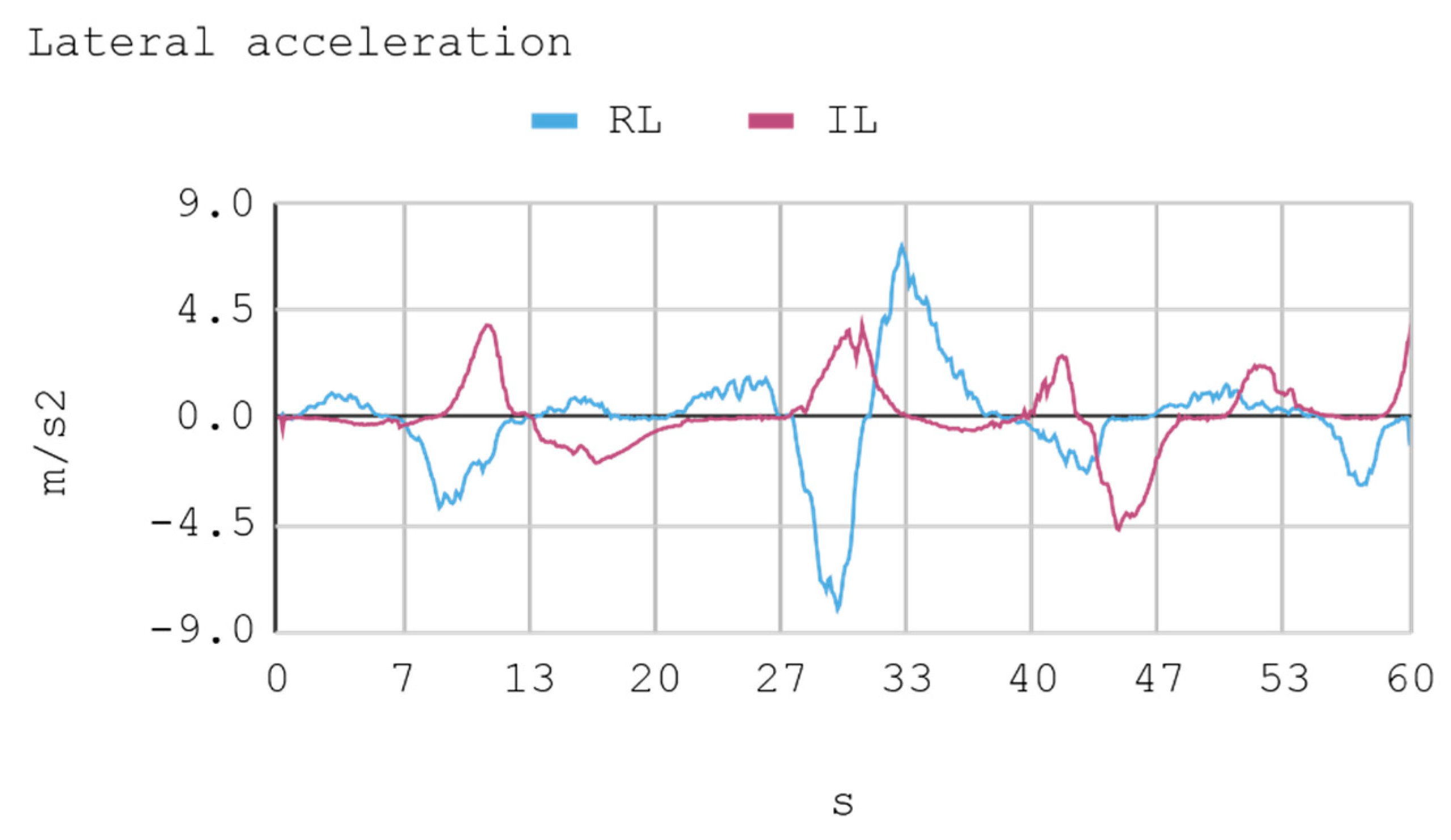
- Lateral acceleration: This acceleration is the result of variation in the direction angle.
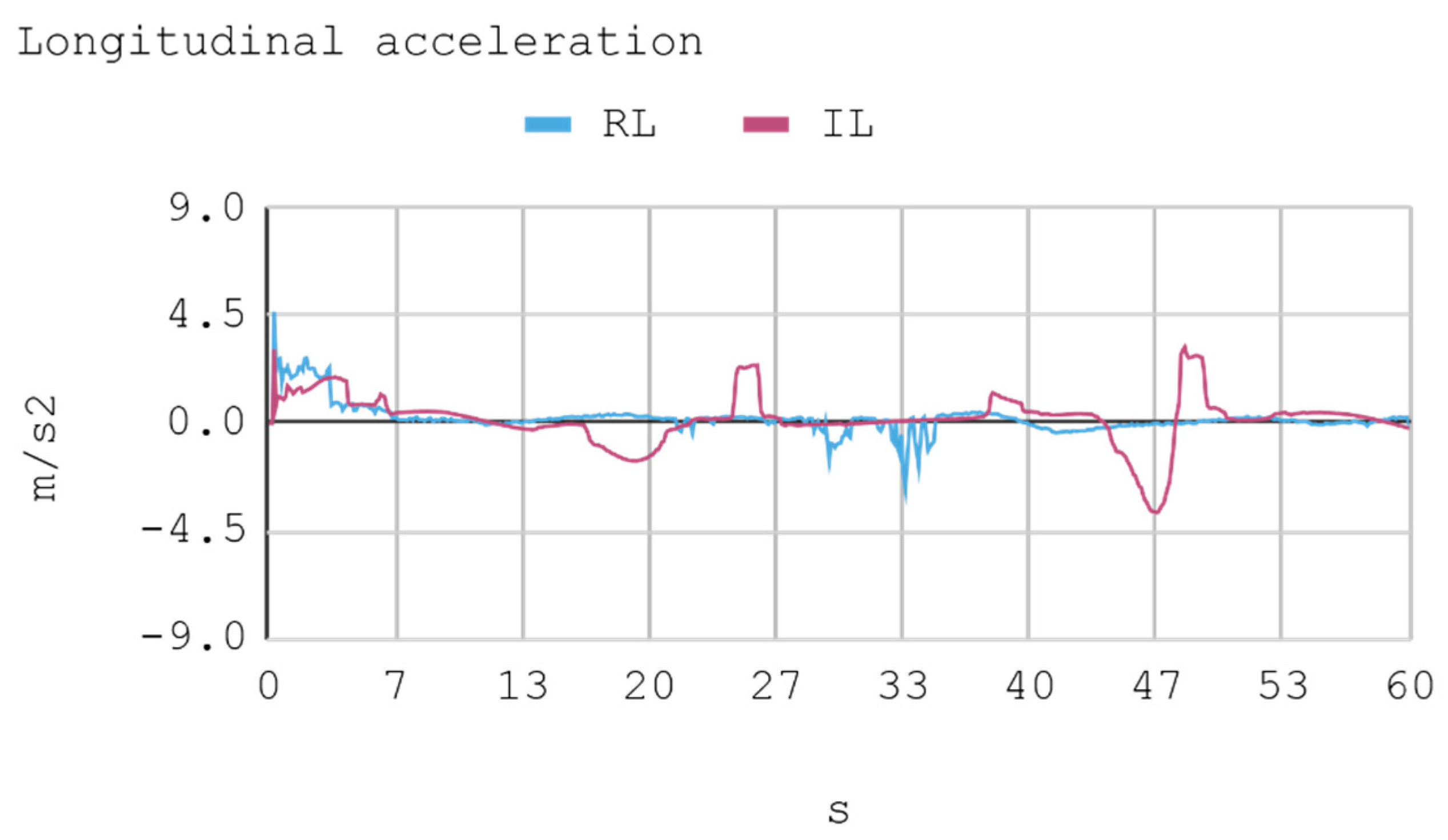
- Longitudinal acceleration: This acceleration is the result of gas variation.
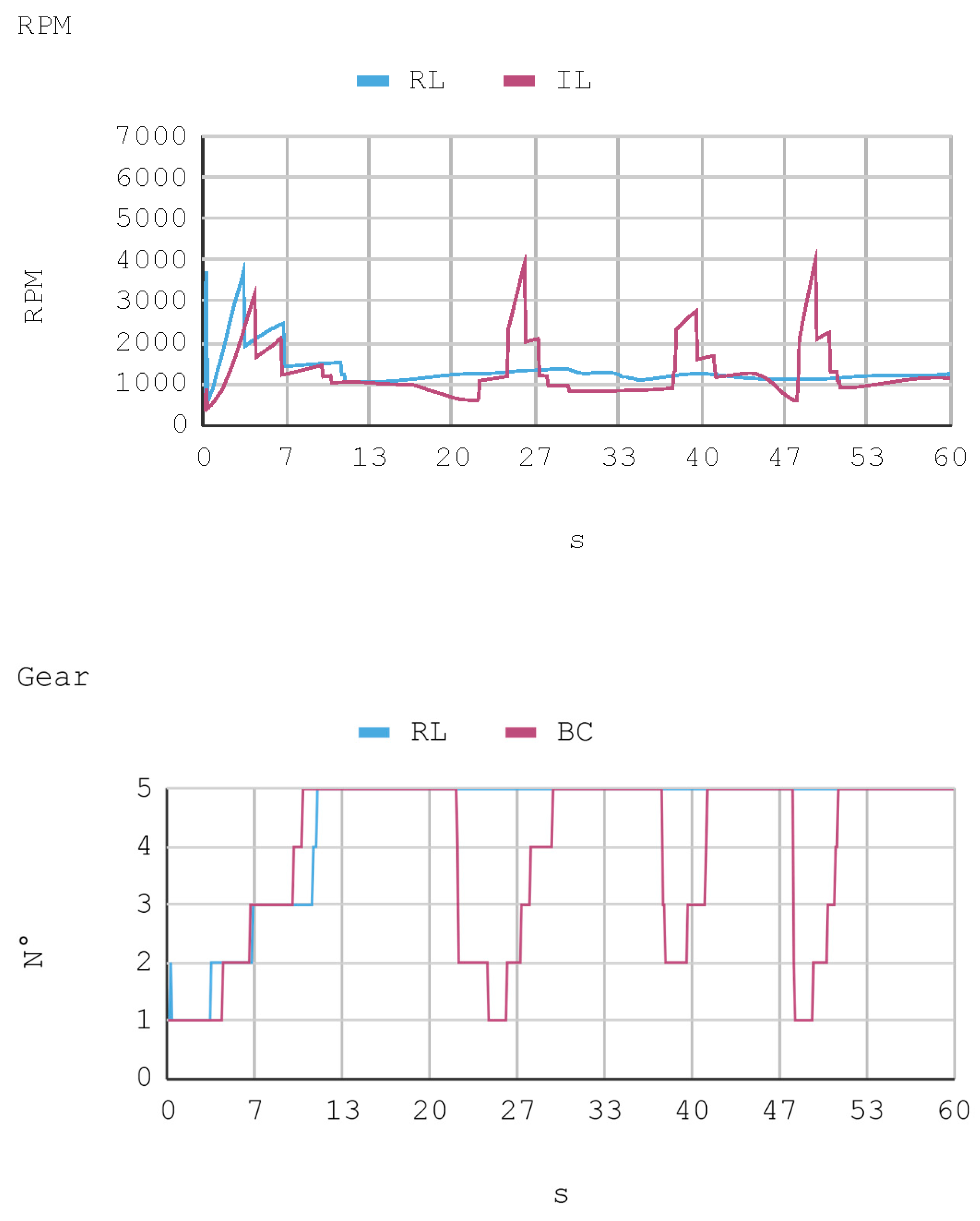
- RPM: Number of turns the motor crankshaft conducts per minute.
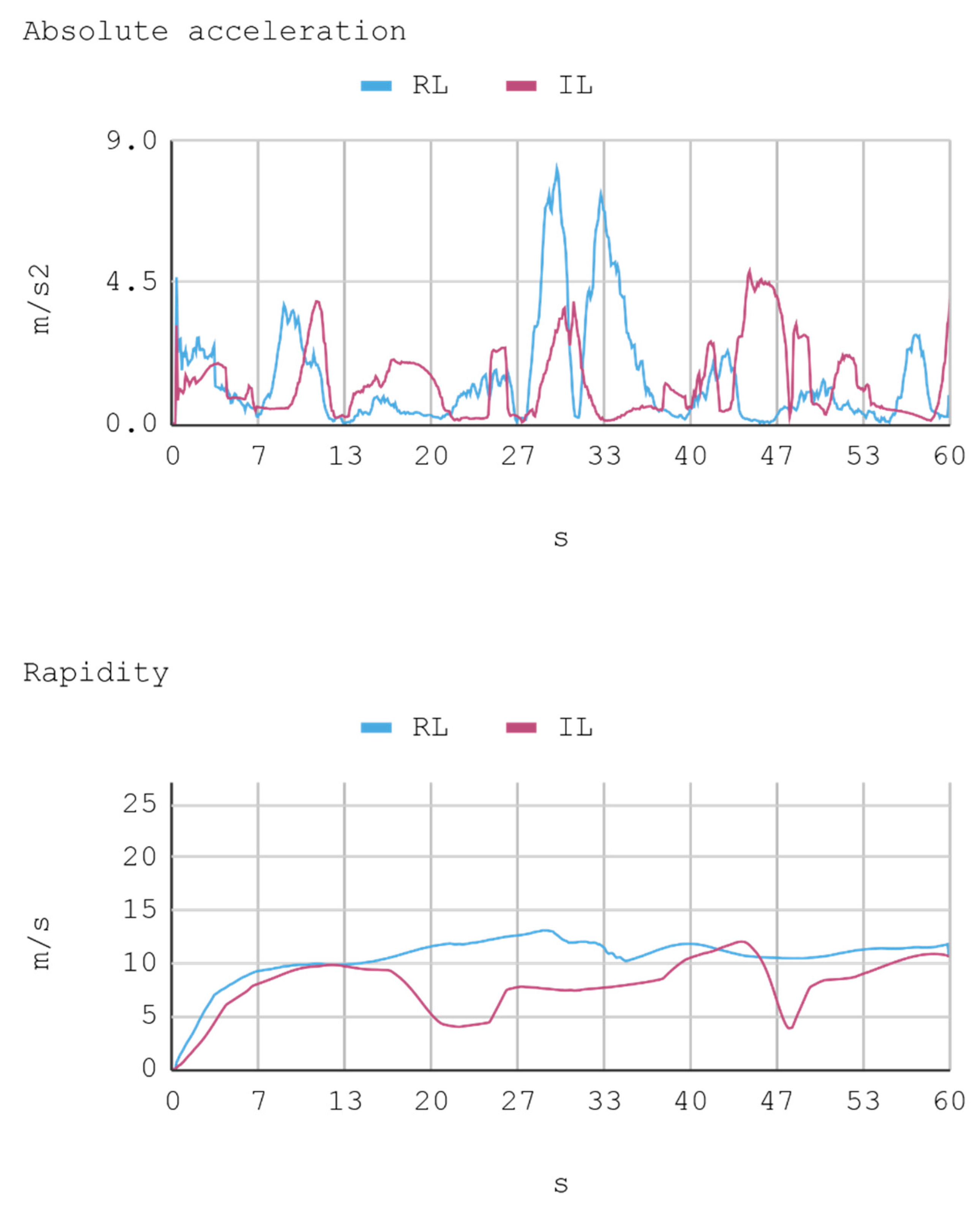
- Instant rapidity: The speed vector tangential to the automobile trajectory.
- Gear: Number of gears used by the automobile transmission. The vehicle considered has five gears in total.
7.1. Case 1: Telemetry on the Training Track
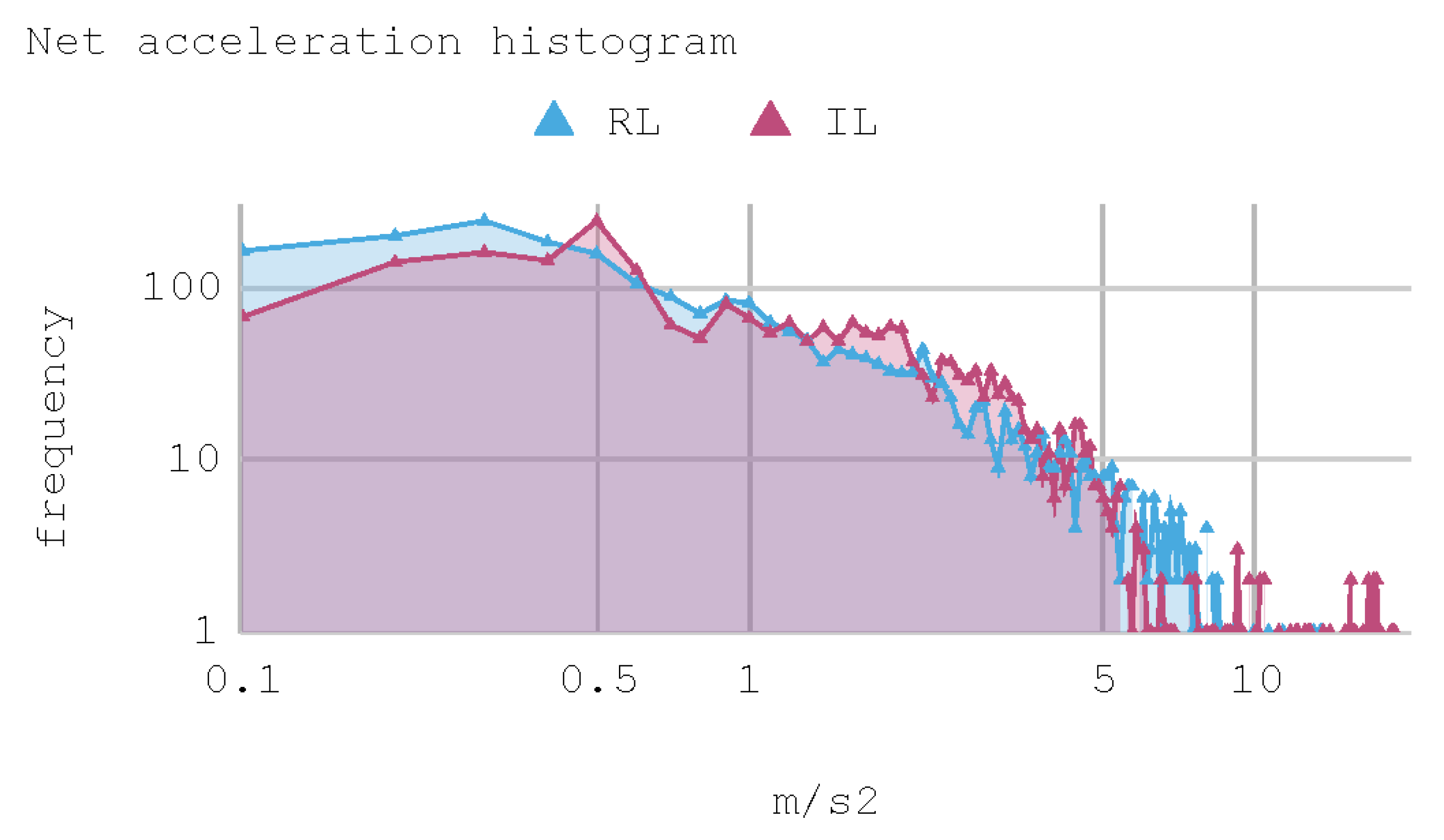
7.2. Case 2: Telemetry on the Test Track
8. Discussion
8.1. Case 1: Telemetry on the Training Track
8.2. Case 2: Telemetry on Test Tracks
9. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Initials | Meaning |
| ALE | Arcade Learning Environment |
| AI | Artificial Intelligence |
| BC | Behavioral Cloning |
| BM | Bush-Mosteller |
| CPPS | Cyber-Physical-Production-System |
| DoF | Degrees of Freedom |
| GAE | General Advantage Estimator |
| GUI | Graphic User Interface |
| IA | Intelligent Agent |
| IL | Imitation Learning |
| QL | Q-Learning |
| LA | Learning Automata |
| ML | Machine Learning |
| MAS | Multi Agent System |
| OSD | One Stage Detector |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| SSD | Single Shot Detector |
| SARSA | State-Action-Reward-State-Action |
| TD | Temporal-Difference |
| TORCS | The Open Racing Car Simulator |
| TSD | Two Stage Detector |
| VR | Virtual Reality |
References
- Farley, B.; Clark, W. Simulation of self-organizing systems by digital computer. Trans. IRE Prof. Group Inf. Theory 1954, 4, 76–84. [Google Scholar] [CrossRef]
- McCarthy, J.; Minsky, M.L.; Rochester, N.; Shannon, C.E. A proposal for the dartmouth summer research project on artificial intelligence, August 31, 1955. AI Mag. 2006, 27. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Pfeiffer, M.; Schaeuble, M.; Nieto, J.; Siegwart, R.; Cadena, C. From perception to decision: A data-driven approach to end-to-end motion planning for autonomous ground robots. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 1527–1533. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Las Condes, Chile, 11–18 December 2015; pp. 2722–2730. [Google Scholar]
- Urbaniak, K.; Wątróbski, J.; Sałabun, W. Identification of players ranking in e-sport. Appl. Sci. 2020, 10, 6768. [Google Scholar] [CrossRef]
- Risi, S.; Preuss, M. From chess and atari to starcraft and beyond: How game ai is driving the world of ai. KI-Künstl. Intell. 2020, 34, 7–17. [Google Scholar] [CrossRef]
- Tang, X.; Song, H.; Wang, W.; Yang, Y. Vehicle spatial distribution and 3D trajectory extraction algorithm in a cross-camera traffic scene. Sensors 2020, 20, 6517. [Google Scholar] [CrossRef]
- Juliani, A.; Berges, V.P.; Vckay, E.; Gao, Y.; Henry, H.; Mattar, M.; Lange, D. Unity: A general platform for intelligent agents. Comput. Sci. Math. 2018, 52185833. [Google Scholar]
- Kwon, O. Very simple statistical evidence that alphago has exceeded human limits in playing go game. Comput. Sci. 2020, 11107. [Google Scholar]
- Urrea, C.; Kern, J.; Alvarado, J. Design and evaluation of a new fuzzy control algorithm applied to a manipulator robot. Appl. Sci. 2020, 10, 7482. [Google Scholar] [CrossRef]
- Zhao, Y.; Borovikov, I.; Silva, F.M.; Beirami, A.; Rupert, J.; Somers, C.; Harder, J.; Kolen, J.; Pinto, J.; Pourabolghasem, R.; et al. Winning isn’t everything: Enhancing game development with intelligent agents. IEEE Trans. Games 2020, 12, 199–212. [Google Scholar] [CrossRef]
- Li, L.; Wang, X.; Wang, K.; Lin, Y.; Xin, J.; Chen, L.; Xu, L.; Tian, B.; Ai, Y.; Wang, J.; et al. Parallel testing of vehicle intelligence via virtual-real interaction. Sci. Robot. 2019, 4, eaaw4106. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Shi, G.; Xie, G.; Cheng, B. Car-following method based on inverse reinforcement learning for autonomous vehicle decision-making. Int. J. Adv. Robot. Syst. 2018, 15. [Google Scholar] [CrossRef]
- Gao, H.; Shi, G.; Wang, K.; Xie, G.; Liu, Y. Research on decision-making of autonomous vehicle following based on reinforcement learning method. Ind. Robot. Int. J. 2019, 46, 444–452. [Google Scholar] [CrossRef]
- Lefèbre, S.; Vásquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. ROBOMECH J. 2014, 1. [Google Scholar]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object classification using CNN-based fusion of vision and LIDAR in autonomous vehicle environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Li, L.; Huang, W.-L.; Liu, Y.; Zheng, N.; Wang, F.-Y. Intelligence testing for autonomous vehicles: A new approach. IEEE Trans. Intell. Veh. 2016, 1, 158–166. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Glaser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 1–20. [Google Scholar] [CrossRef]
- Wooldridge, M.; Jennings, N.R. Intelligent agents: Theory and practice. Knowl. Eng. Rev. 1995, 10, 115–152. [Google Scholar] [CrossRef]
- Mishra, N.; Singh, A.; Kumari, S.; Govindan, K.; Ali, S.I. Cloud-based multi-agent architecture for effective planning and scheduling of distributed manufacturing. Int. J. Prod. Res. 2016, 54, 7115–7128. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-fidelity visual and physical simulation for autonomous vehicles. Distributed Auton. Robotic Syst. 2018, 621–635. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement learning: An introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Brearcliffe, D.; Crooks, A. Creating Intelligent Agents: Combining Agent-Based Modeling with Machine Learning. 2020, p. 4403. Available online: https://easychair.org/publications/preprint/w3H1 (accessed on 3 January 2021).
- Bennewitz, M.; Burgard, W.; Cielniak, G.; Thrun, S. Learning motion patterns of people for compliant robot motion. Int. J. Robot. Res. 2005, 24, 31–48. [Google Scholar] [CrossRef]
- Pouliquen, M.; Bernard, A.; Marsot, J.; Chodorge, L. Virtual hands and virtual reality multimodal platform to design safer industrial systems. Comput. Ind. 2007, 58, 46–56. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Urrea, C.; Venegas, D. Design and development of control systems for an aircraft. Comparison of performances through computational simulations. IEEE Lat. Am. Trans. 2018, 16, 735–740. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M. Humanlike driving: Empirical decision-making system for autonomous vehicles. IEEE Trans. Veh. Technol. 2018, 67, 6814–6823. [Google Scholar] [CrossRef]
- Pérez, L.; Diez, E.; Usamentiaga, R.; García, D.F. Industrial robot control and operator training using virtual reality interfaces. Comput. Ind. 2019, 109, 114–120. [Google Scholar] [CrossRef]
- Urrea, C.; Saa, D. Design and implementation of a graphic simulator for calculating the inverse kinematics of a redundant planar manipulator robot. Appl. Sci. 2020, 10, 6770. [Google Scholar] [CrossRef]
- De Bruyne, J. Driving autonomous vehicles. Rev. Droit Technol. Inf. 2020, 75, 86–95. [Google Scholar]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.-B. Shot classification of field sports videos using AlexNet convolutional neural network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef]
- Miclea, R.-C.; Dughir, C.; Alexa, F.; Sandru, F.; Silea, I. Laser and LIDAR in A system for visibility distance estimation in fog conditions. Sensors 2020, 20, 6322. [Google Scholar] [CrossRef]
- Urrea, C.; Matteoda, R. Development of a virtual reality simulator for a strategy for coordinating cooperative manipulator robots using cloud computing. Robot. Auton. Syst. 2020, 126, 103447. [Google Scholar] [CrossRef]
- Gao, H.; Zhu, J.; Zhang, T.; Xie, G.; Kan, Z.; Hao, Z.; Liu, K. Situational assessment for intelligent vehicles based on Stochastic model and Gaussian distributions in typical traffic scenarios. IEEE Trans. Syst. Man, Cybern. Syst. 2020, 1–11. [Google Scholar] [CrossRef]
- Palmerini, L.; Klenk, J.; Becker, C.; Chiari, L. Accelerometer-based fall detection using machine learning: Training and testing on real-world falls. Sensors 2020, 20, 6479. [Google Scholar] [CrossRef] [PubMed]
- Wymann, B.; Espié, E.; Guionneau, C.; Dimitrakakis, C.; Coulom, R.; Sumner, A. Torcs, the Open Racing Car Simulator. 2000, p. 4. Available online: http://torcs.sourceforge.net (accessed on 3 January 2021).
- Cha, M.; Yang, J.; Han, S. An interactive data-driven driving simulator using motion blending. Comput. Ind. 2008, 59, 520–531. [Google Scholar] [CrossRef]
- Mezgebe, T.T.; El Haouzi, H.B.; Demesure, G.; Pannequin, R.; Thomas, A. Multi-agent systems negotiation to deal with dynamic scheduling in disturbed industrial context. J. Intell. Manuf. 2020, 31, 1367–1382. [Google Scholar] [CrossRef]
- Salazar, L.A.C.; Ryashentseva, D.; Lüder, A.; Vogel-Heuser, B. Cyber-physical production systems architecture based on multi-agent’s design pattern-comparison of selected approaches mapping four agent patterns. Int. J. Adv. Manuf. Technol. 2019, 105, 4005–4034. [Google Scholar] [CrossRef]
- Ocker, F.; Kovalenko, I.; Barton, K.; Tilbury, D.M.; Vogel-Heuser, B. A framework for automatic initialization of multi-agent production systems using semantic web technologies. IEEE Robot. Autom. Lett. 2019, 4, 4330–4337. [Google Scholar] [CrossRef]
- Ciortea, A.; Mayer, S.; Michahelles, F. Repurposing manufacturing lines on the fly with multi-agent systems for the web of things. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, Stockholm, Sweden, 10–15 July 2018; pp. 813–822. [Google Scholar]
- Orio, G.D.; Rocha, A.; Ribeiro, L.; Barata, J. The PRIME semantic language: Plug and produce in standard-based manufacturing production systems. In Proceedings of the International Conference on Flexible Automation and Intelligent Manufacturing 2015 (FAIM’15), Wolverhampton, UK, 23–26 June 2015. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. (CSUR) 2017, 50, 50. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. In Proceedings of the NIPS Deep Learning Workshop 2013, Lake Tahoe, NV, USA, 9 December 2013; Available online: https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf (accessed on 3 January 2021).
- Beattie, C.; Leibo, J.Z.; Teplyashin, D.; Ward, T.; Wainwright, M.; Küttler, H.; Lefrancq, A.; Green, S.; Valdés, V.; Sadik, A.; et al. Deepmind Lab. 2016. Available online: https://deepmind.com/research; https://arxiv.org/pdf/1612.03801.pdf (accessed on 3 January 2021).
- Johnson, M.; Hofmann, K.; Hutton, T.; Bignell, D. The Malmo Platform for Artificial Intelligence Experimentation. In Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 4246–4247. [Google Scholar]
- Rill, G. Vehicle Dynamics; University of Applied Sciences Hochschule: Regensburg, Germany, 2009; Available online: https://www.twirpx.com/file/1067713 (accessed on 3 January 2021).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2017. Available online: https://arxiv.org/pdf/1707.06347v2.pdf (accessed on 3 January 2021).
- Bain, M.; Sammut, C. A framework for behavioural cloning. Mach. Intell. 1999, 15. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reinforcement Learning Type | Description | Reference |
|---|---|---|
| Bush-Mosteller (BM) | A type of statistical learning where a predictive function is derived from data. | Bush & Mosteller (1955) 1 |
| Learning Automata (LA) | Simple algorithm operating in a stochastic environment where agents can improve their actions during operation. | Narendra & Thathachar (1974) 2 |
| Q-Learning (QL) | A policy, expressed as a matrix of values for states and actions, is learned so an agent knows what to do in different circumstances. It does not require a model of the problem to be solved. (State→Action→Reward). | Watkins (1989) 3 |
| State → Action → Reward → State → Action (SARSA) | Extends Q-Learning by also considering the future selected state-action. Uses a model it builds. | Rummery & Niranjan (1994) 4 |
| Temporal-Difference (TD) | Learning from experience without an environmental model, which updates estimates before outcome is known. | Sutton (1988) 5 |
| Features |
|---|
| Development of open programming codes. |
| Promotion of the use of free software, such as: Unity3d and its Unity ML-Agents Toolkit. |
| Supports virtual reality. |
| The user can train IAs using the driving simulator. |
| Democratizes Access to ML research. |
| The system proposed, as an open system, would support the incorporation of new algorithms, the creation of training environments for other types of robots and/or learning paradigms. |
| Component | Design Characteristics |
|---|---|
| Traction and suspension | Front-wheel drive. Suspension with a rigid axle in the front and the rear. Anti-roll bar in the front axle. Ackerman steering geometry and differential. |
| Weight | 1000-kg mass. |
| Engine | 100 HP maximum power at 5500 rpm. 134 Nm maximum torque at 3500 rpm (includes look up table with torque curve). |
| Transmission | Automatic 5 speed transmission. |
| Controls | Acceleration pedal. Brake pedal. Steering wheel. |
| Unity Objects | Components |
|---|---|
| Rigid bodies | Mass. |
| Joints | Hinge and ball joints. |
| Colliders | Box and capsule colliders. |
| Components | Detail |
|---|---|
| Actuators | Two direct current electric motors. 12 V; 1350 W peak, and 28:1 gear box equipped with two optical quadrature encoders –one for each motor– that estimate the turning angle of the motors. Two Pololu VNH519 H bridges of 12 V and 30 A, respectively, model. Driven from a 12 V and 60 A power source. |
| Microcontrollers | Two Arduino Uno development boards; the first one estimates the rotation angle of both motors by means of interruptions via hardware and the second one to achieve the serial communication and control of the two H bridges by PWM signals. |
| Steering wheel and pedals | Logitech g27 steering wheel. |
| Virtual Reality System | HTC VIVE Pro Virtual Reality System. Headset and two hand controllers. |
| Feature | Detail |
|---|---|
| Distance of the virtual automobile from the road barriers | Punishment for the virtual automobile performance when this is too close to the road barriers. |
| Virtual automobile speed | Reward if speed is positive. Reward if speed is within a specific interval. Punishment if speed is negative. |
| Virtual automobile acceleration | Punishment for positive and negative acceleration. |
| Collisions | Punishment if the automobile collides with the road barriers. |
| Steering angles | Punishment if the virtual automobile is not at the left of the track. |
| Hyperparameter | Description |
|---|---|
| Batch size | Number of experiences within each iteration of the gradient descent. This number is expected to be a fraction of the buffer size. |
| Beta | Force with which entropy stabilizes. Entropy causes random policies through which the IA explores the action space during training. |
| Buffer size | Number of experiences gathered before updating the random policy model that allows for the learning of the IA. |
| Epsilon | Acceptable divergence threshold –while the gradient descent is being updated– between new and old random policies. This threshold allows for determining how fast the random policy model evolves during IA training. |
| Gamma | Discount factor for future rewards. This factor allows for determining whether the agent should value the current gains or worry about potential future rewards. |
| Hidden units | Number of units in the hidden layer of the neural network. |
| Lambda | Factor used to calculate the General Advantage Estimator (GAE). This factor allows for determining –after calculating a new value estimation– to what extent the IA is dependent on its previous value estimation compared to the new estimation. The IA could trust more in the previous estimation, or more in the rewards received from its environment (corresponding to the new value estimation). |
| Learning rate | Initial learning rate from the gradient descent. During the initial learning of the IA, this rate represents the weight of each update stage. |
| Max steps | Number of steps in the IA training process. |
| Num epoch | Number of iterations, through the experience buffer, when conducting the gradient descent optimization. |
| Num layers | Number of hidden layers in the neural network. |
| Time horizon | Number of experience steps gathered before sending them to the experience buffer. |
| Trainer | PPO |
|---|---|
| Batch size | 16 |
| Beta | 0.01 |
| Buffer size | 256 |
| Epsilon | 0.15 |
| Gamma | 0.9 |
| Hidden units | 64 |
| Lambda | 0.9 |
| Learning rate | 5 × 10−4 |
| Max steps | 10 × 104 |
| Num epoch | 10 |
| Num layers | 3 |
| Time horizon | 4 |
| Trainer | BC (Online) 1 |
|---|---|
| Batch size | 16 |
| Hidden units | 128 |
| Learning rate | 5 × 10−5 |
| Max steps | 5 × 105 |
| Batches per epoch | 2 |
| Num layers | 5 |
| Time horizon | 2 |
| Statistics/Actor | IA IL | IA RL | Human |
|---|---|---|---|
| Mean speed (m/s) | 11.22 | 9.75 | 12.8 |
| Effective acceleration (m/s2) | 0.84 | 0.55 | 0.63 |
| Abs(a) mode, bin = 0.1 (m/s2) | 0.1 | 0.1 | 0.2 |
| Abs(a) statistical frequency | 1.012 | 970 | 369 |
| Abs(a) median (m/s2) | 0.12 | 0.16 | 0.52 |
| Abs(a) standard deviation (m/s2) | 2.44 | 1.53 | 1.51 |
| Abs(a) maximum (m/s2) | 15.7 | 14.9 | 6.5 |
| N over 6 (m/s2) | 123 | 35 | 13 |
| Statistics/Actor | IA IL | IA RL |
|---|---|---|
| Mean speed (m/s) | 10.44 | 10.84 |
| Effective acceleration (m/s2) | 0.84 | 0.79 |
| Abs(a) mode, bin = 0.1 (m/s2) | 0.5 | 0.3 |
| Abs(a) statistical frequency | 246 | 247 |
| Abs(a) median (m/s2) | 1.09 | 0.77 |
| Abs(a) standard deviation (m/s2) | 2.22 | 2.06 |
| Abs(a) maximum (m/s2) | 18.7 | 56.4 1 |
| N over 6 (m/s2) | 66 | 74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urrea, C.; Garrido, F.; Kern, J. Design and Implementation of Intelligent Agent Training Systems for Virtual Vehicles. Sensors 2021, 21, 492. https://doi.org/10.3390/s21020492
Urrea C, Garrido F, Kern J. Design and Implementation of Intelligent Agent Training Systems for Virtual Vehicles. Sensors. 2021; 21(2):492. https://doi.org/10.3390/s21020492
Chicago/Turabian StyleUrrea, Claudio, Felipe Garrido, and John Kern. 2021. "Design and Implementation of Intelligent Agent Training Systems for Virtual Vehicles" Sensors 21, no. 2: 492. https://doi.org/10.3390/s21020492
APA StyleUrrea, C., Garrido, F., & Kern, J. (2021). Design and Implementation of Intelligent Agent Training Systems for Virtual Vehicles. Sensors, 21(2), 492. https://doi.org/10.3390/s21020492