
Filter Pruning via Measuring Feature Map Information

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
2.1. Weight Pruning
2.2. Filter Pruning
3. The Proposed Method
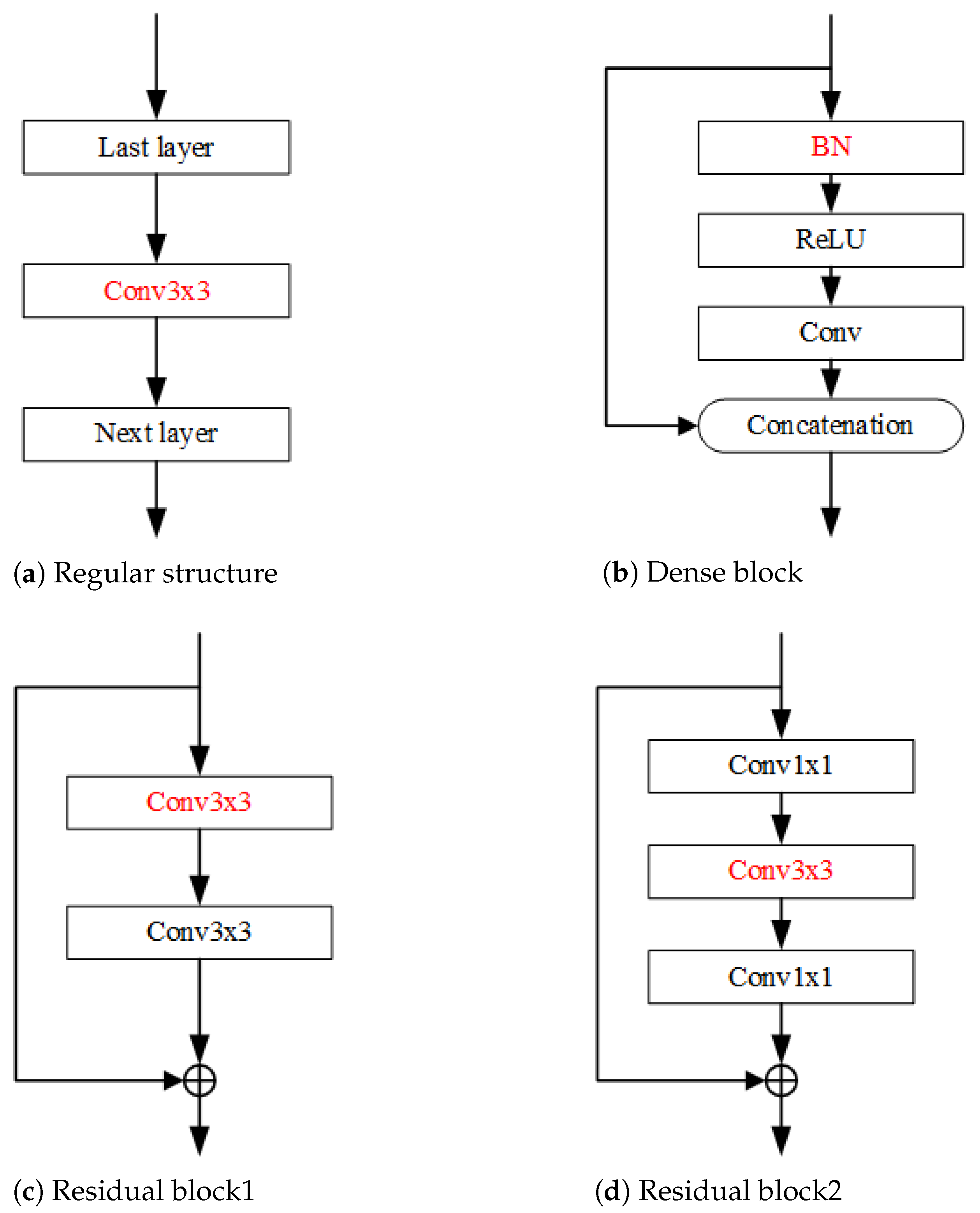
3.1. Notations
3.2. Pruning Criteria
3.2.1. Feature Maps Probability
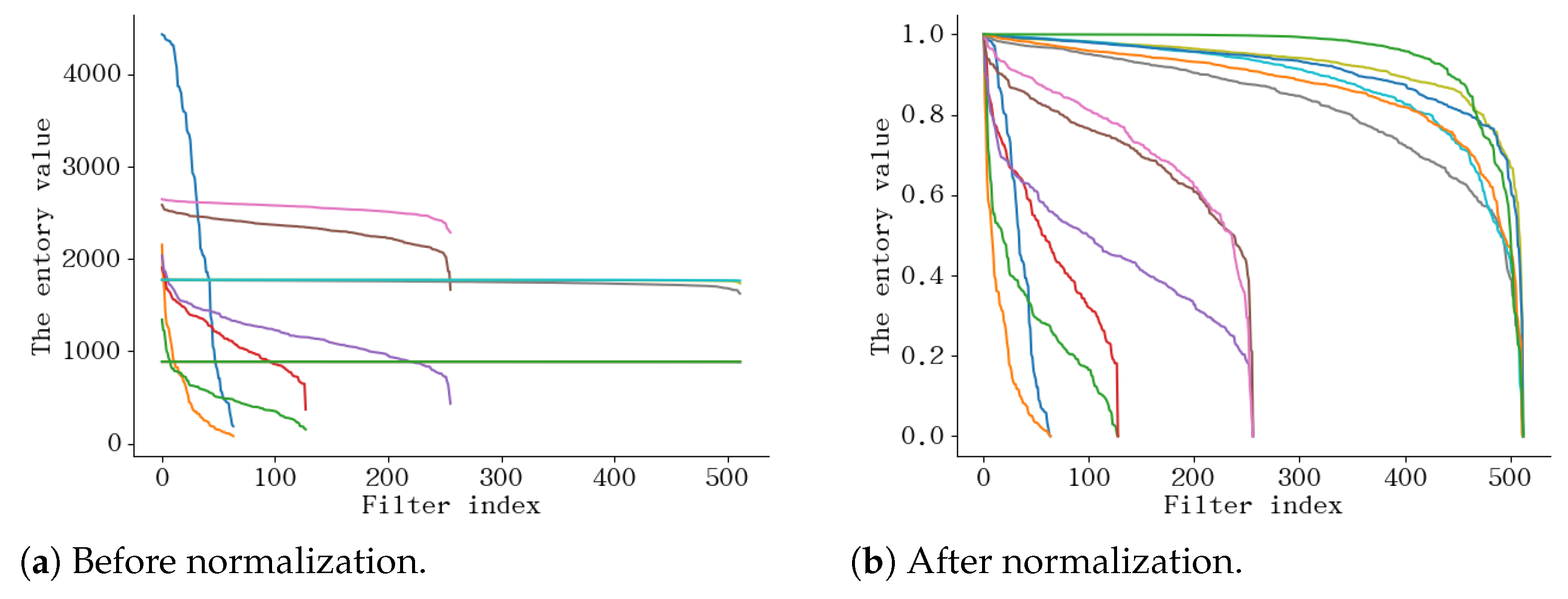
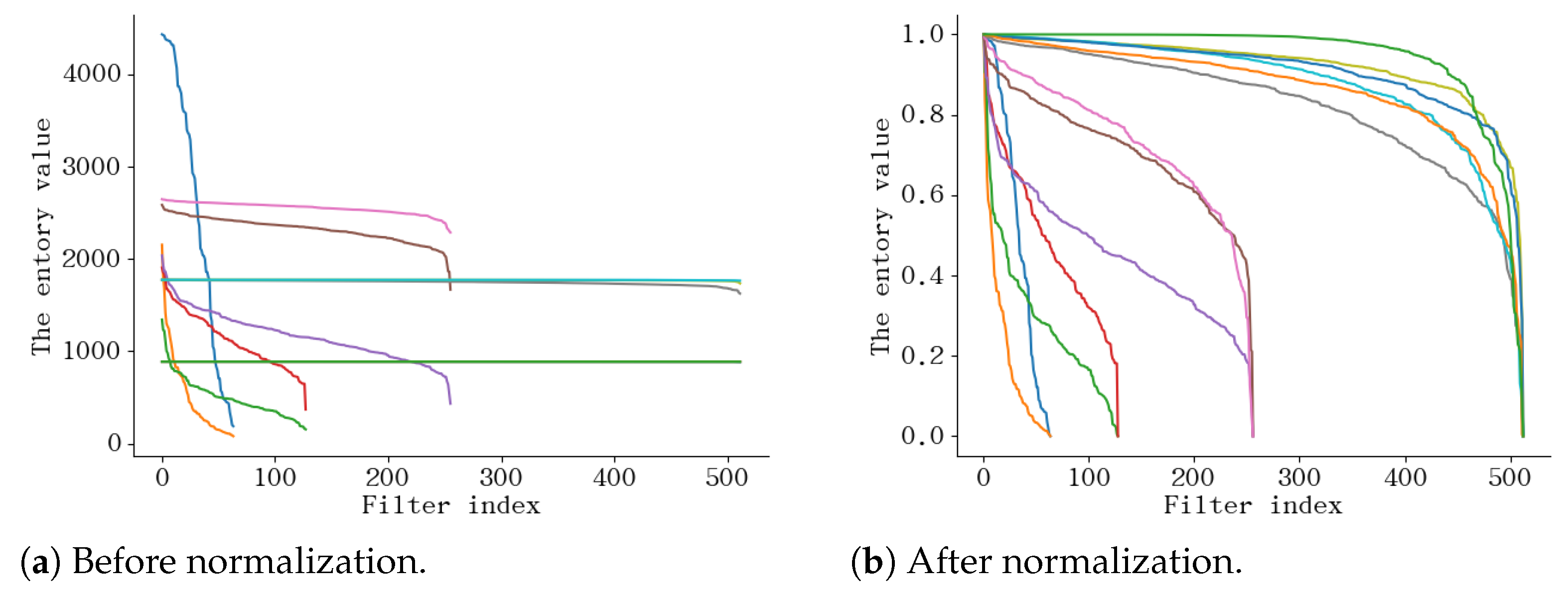
3.2.2. Feature Maps Entropy
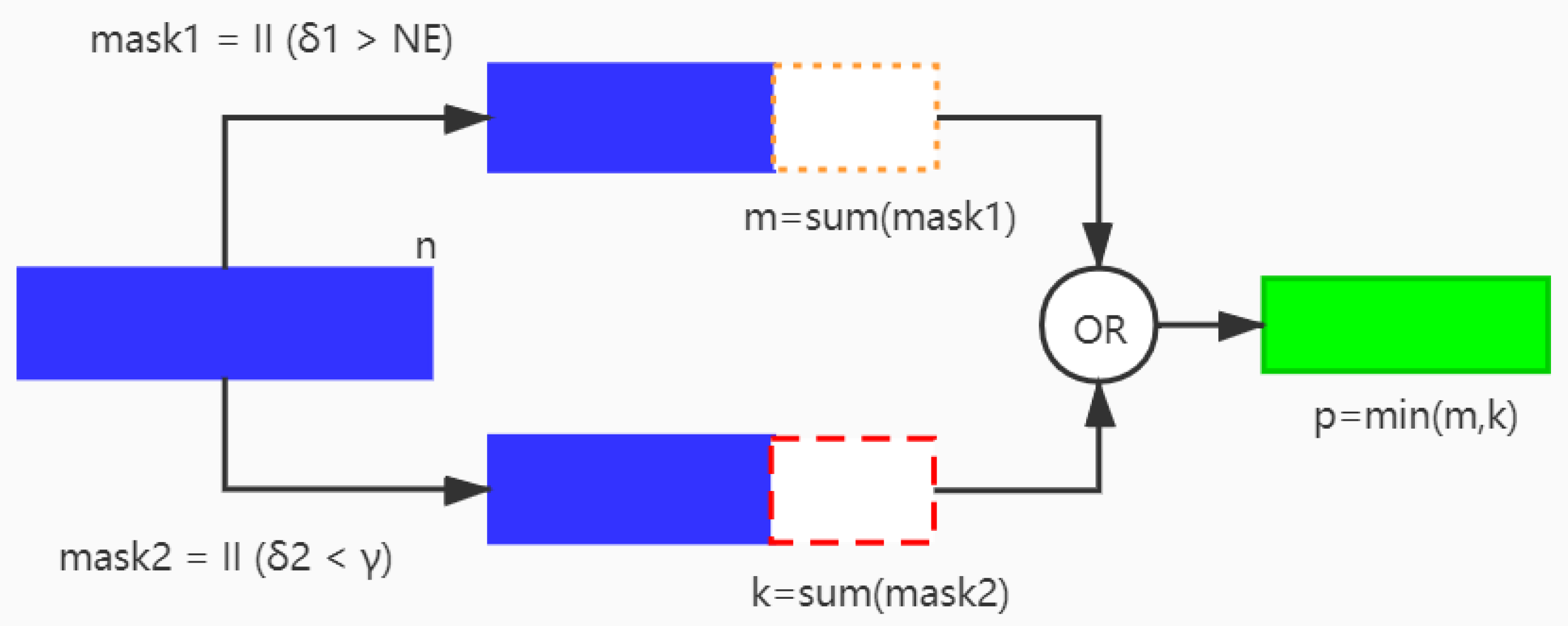
3.3. Parallel Pruning Criteria
| Algorithm 1 A Pruning Algorithm Based on Entropy of Feature Map |
|
| Algorithm 2 A Parallel Pruning Algorithm |
Require: Training set , and two threholds and . Ensure: The compat network.
|
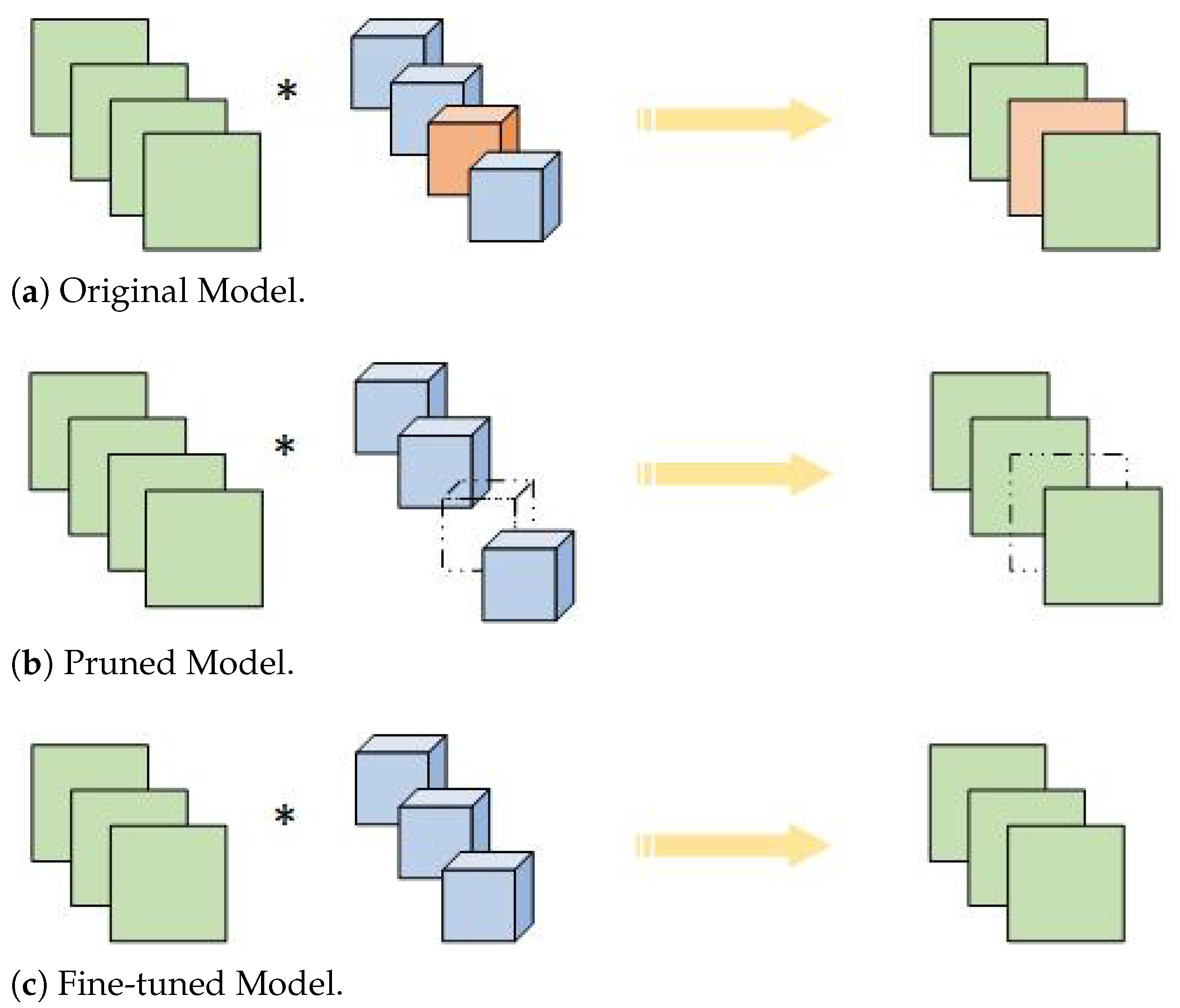
3.4. Pruning Strategy
4. Experimental Results
4.1. Implementation Details
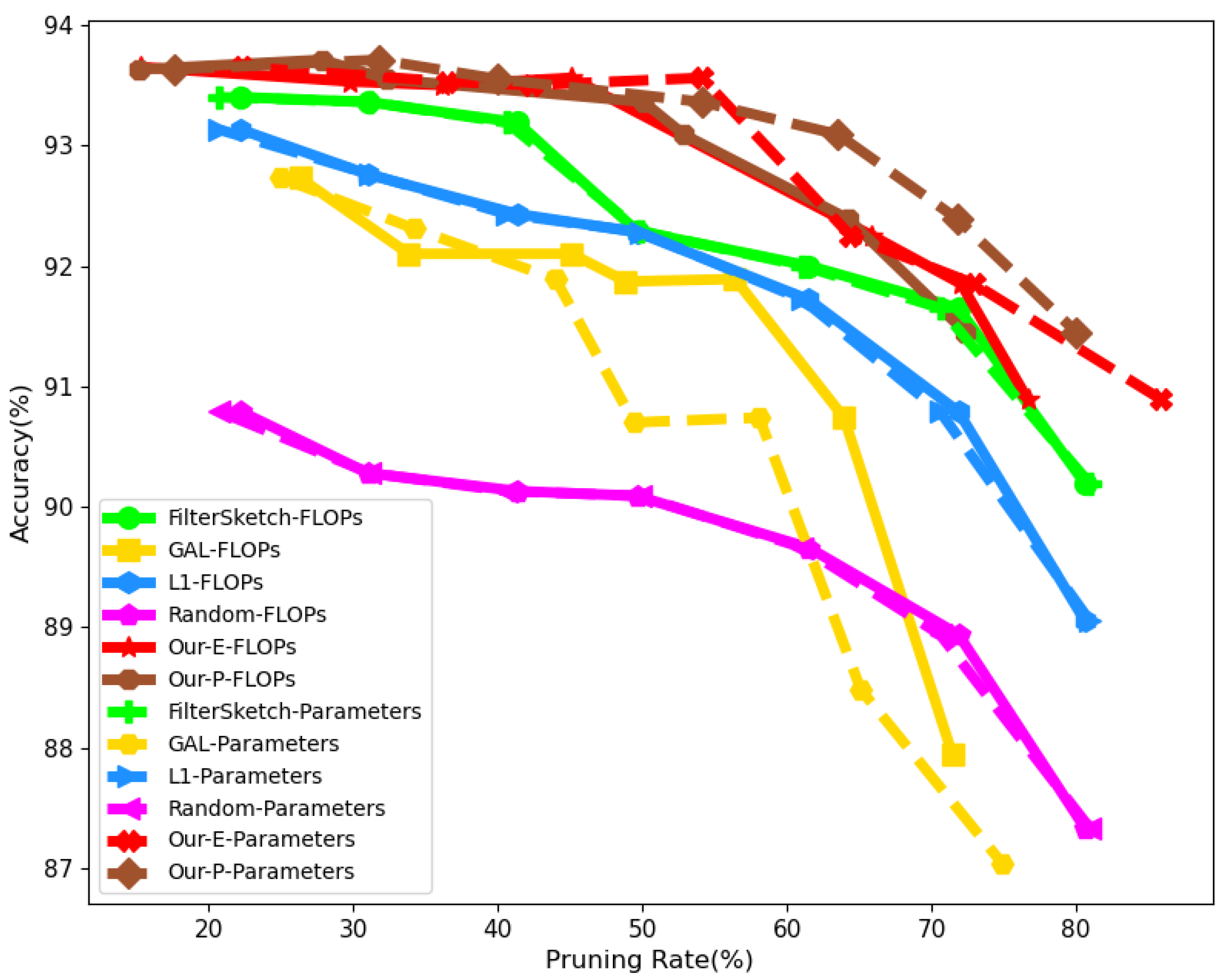
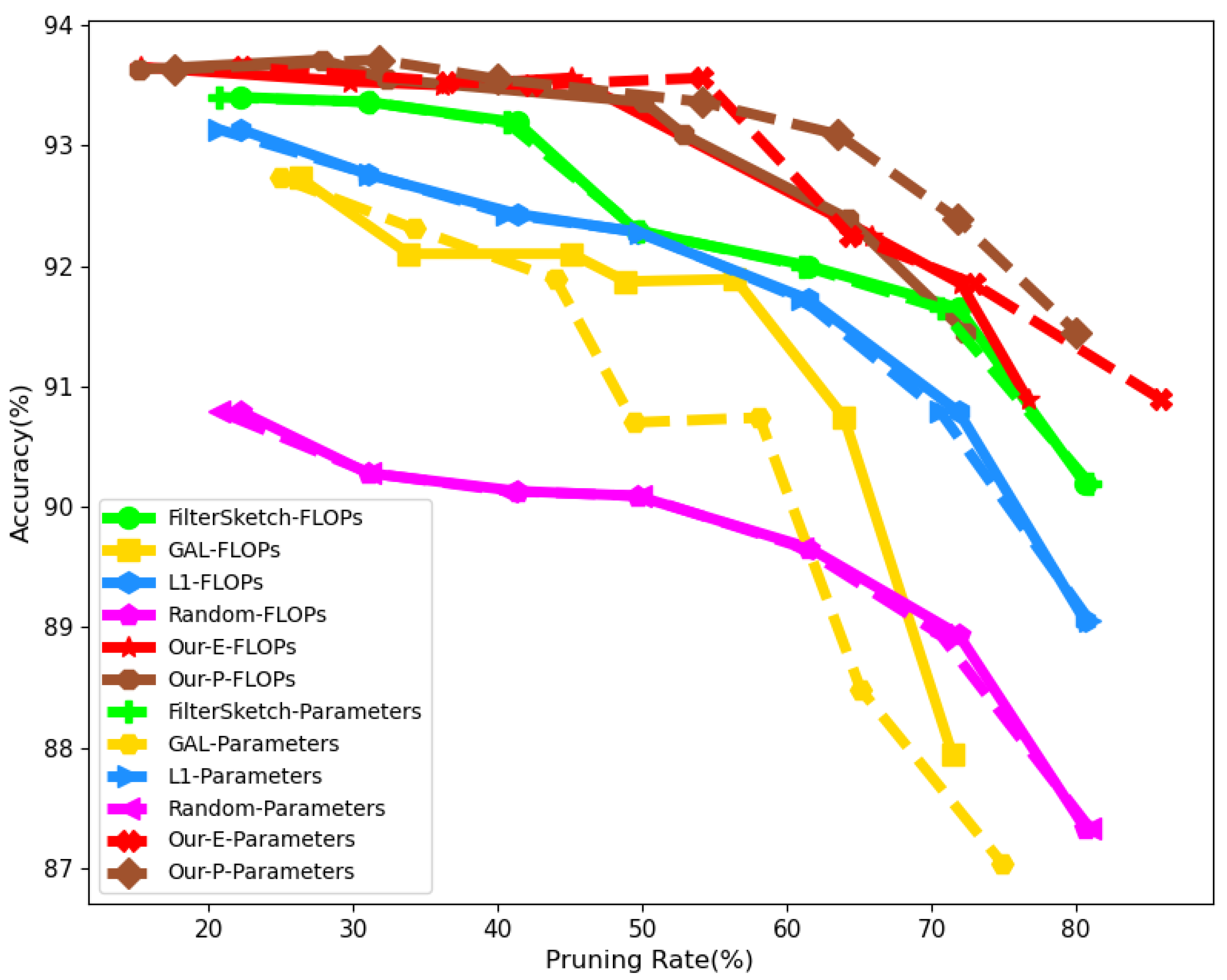
4.2. Comparison on CIFAR10/100
4.3. Comparison on ImageNet
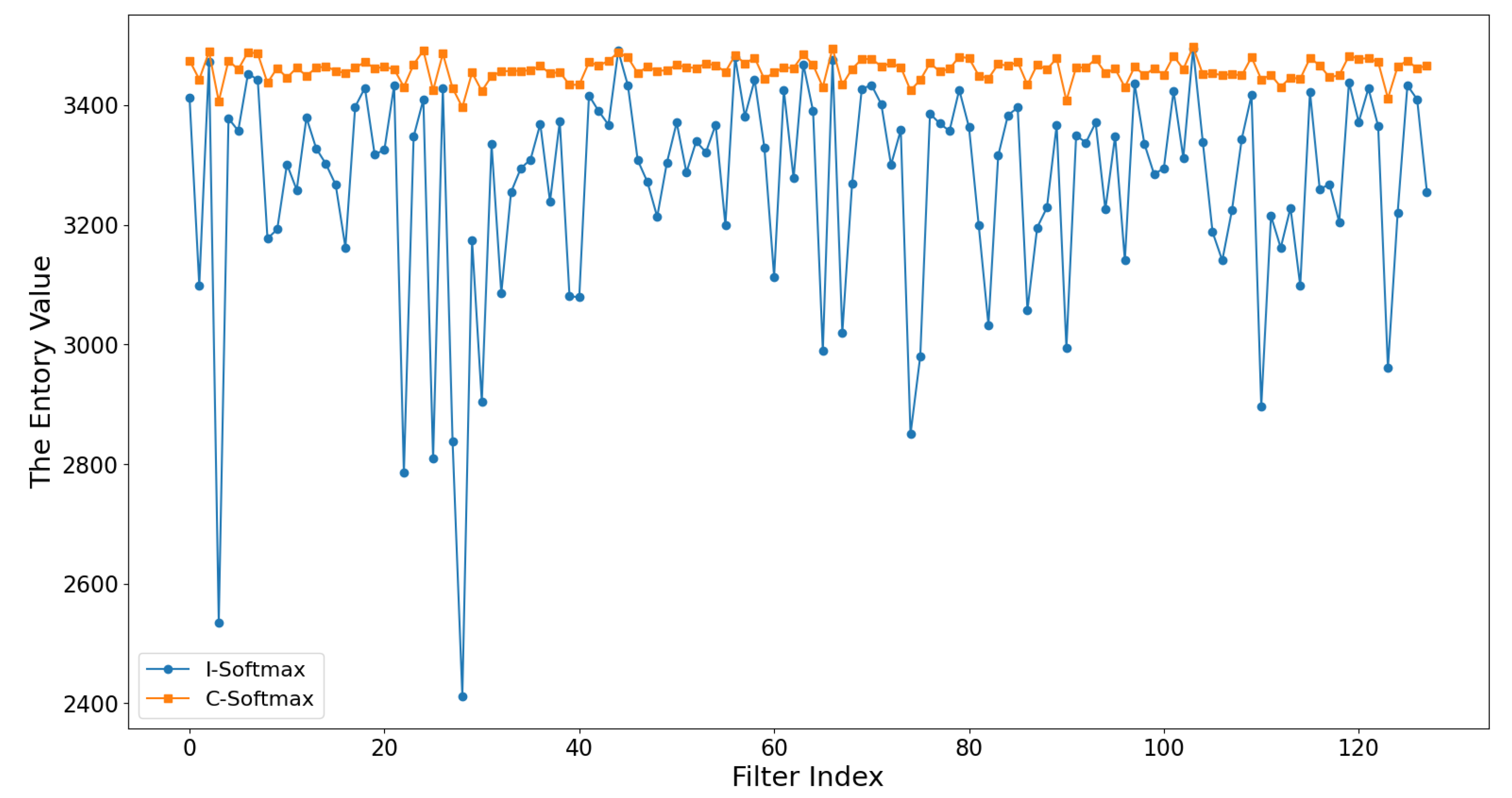
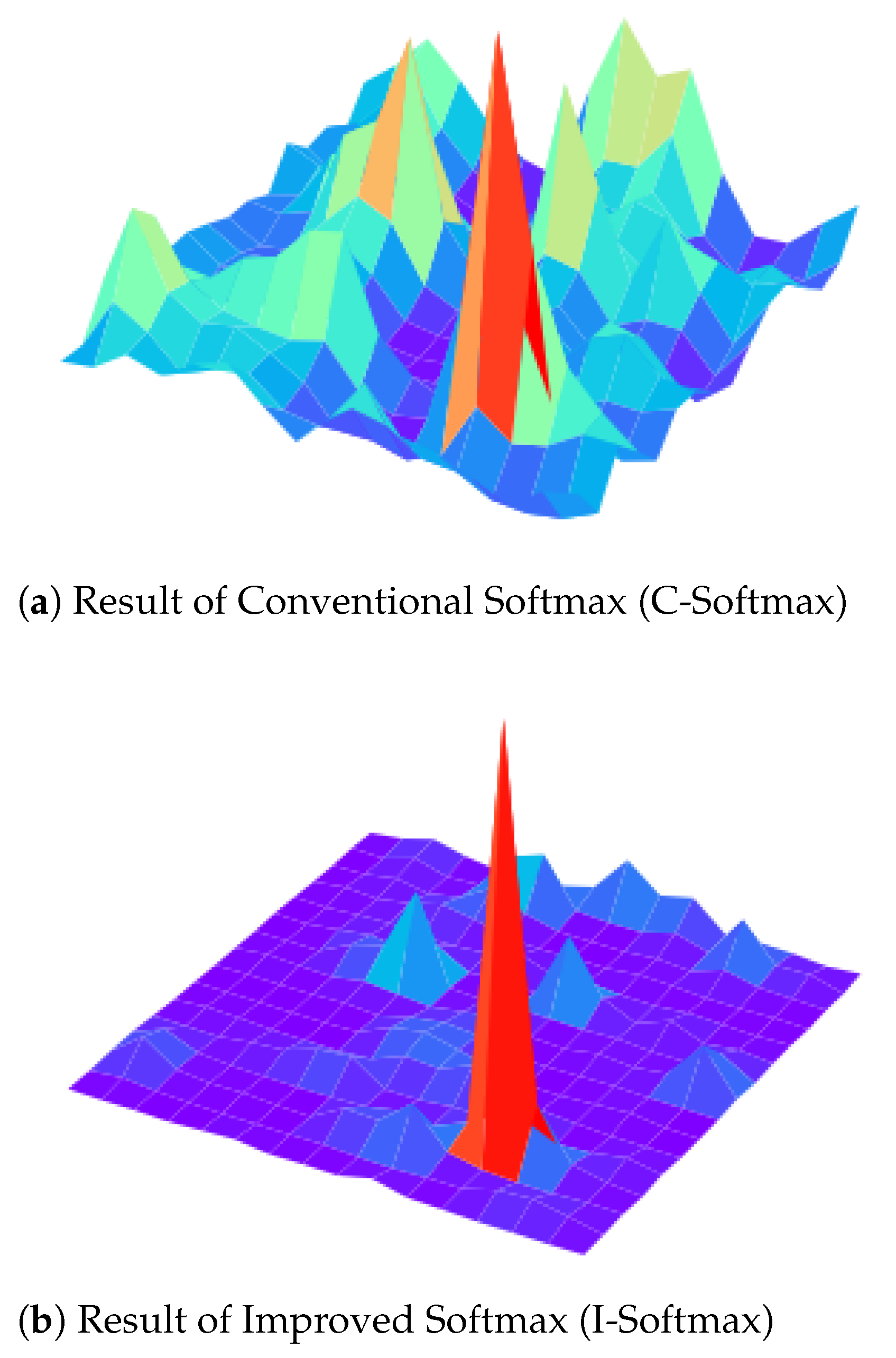
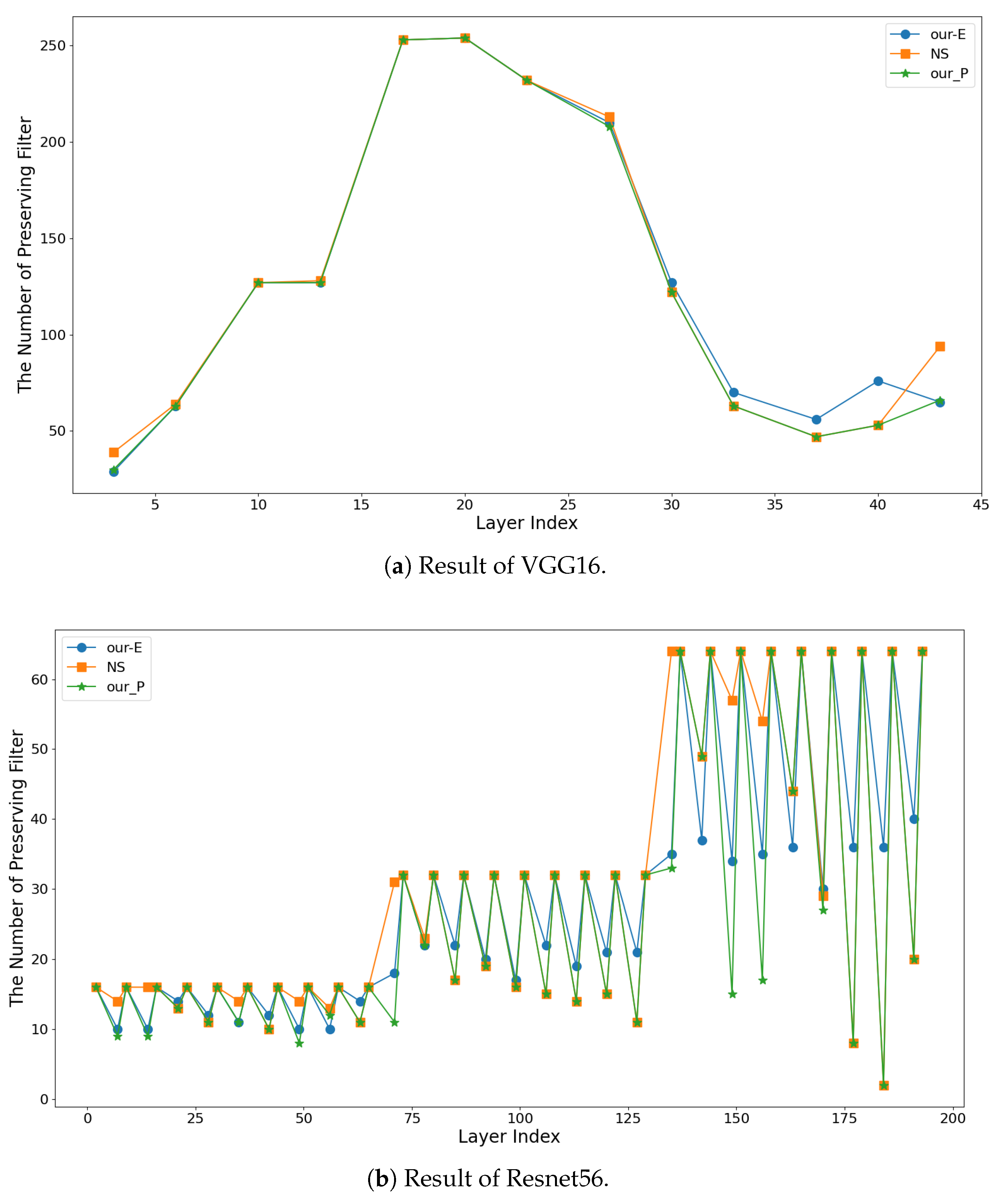
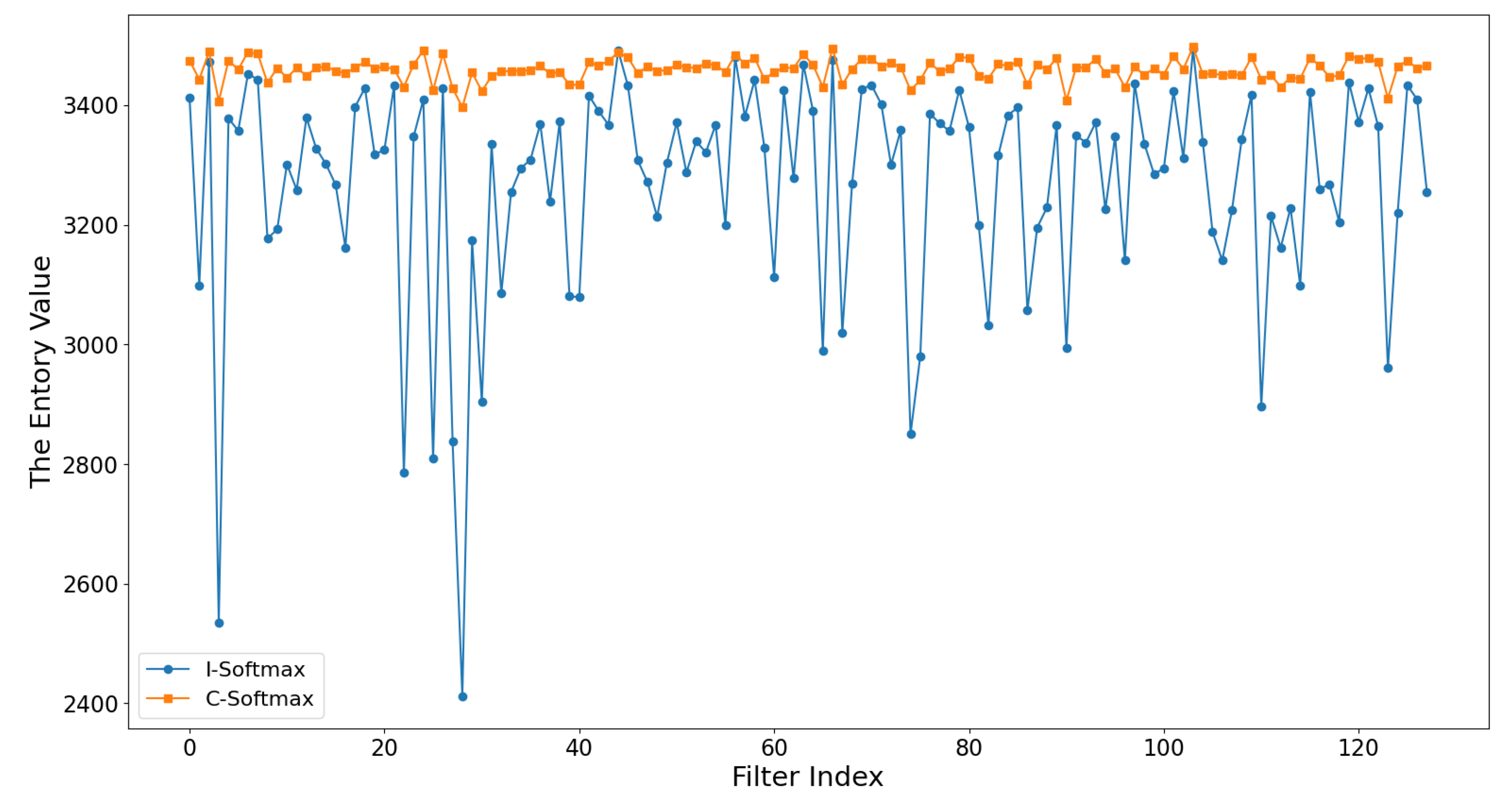
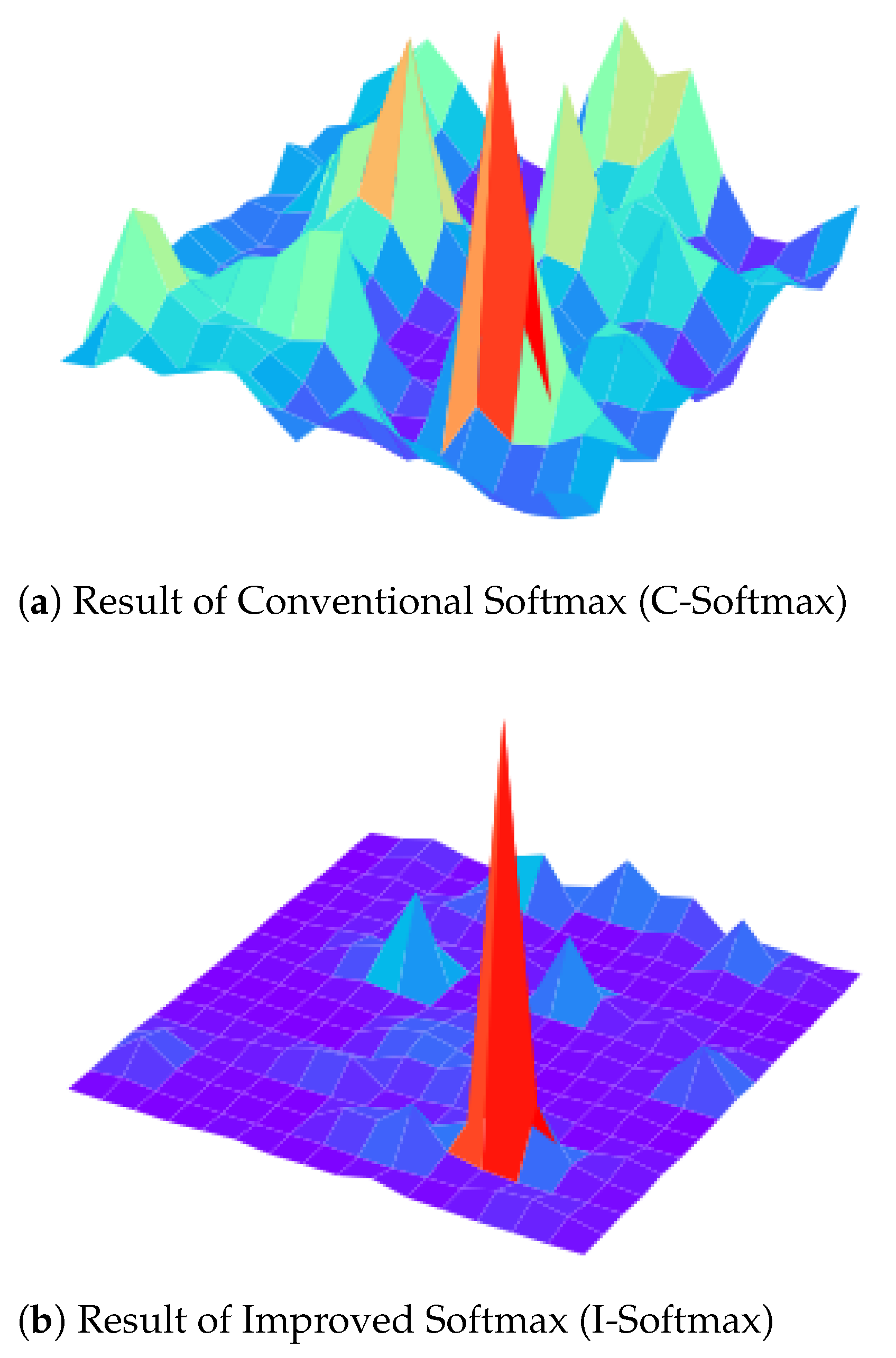
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN/CNNs | Convolutional Neural Networks |
| FLOPs | floating point operations |
| BN | Batch Normalization |
| GAP | global average pooling |
| DNS | Dynamic Network Surgery |
| SNIP | single-hot network pruning |
| APoZ | Average Percentage of Zeros |
| APG | Accelerated Proximal Gradient |
| OBD | Optical brain damage |
| OBS | Optical brain surgeon |
| KD | Knowledge Distillation |
| DML | Deep mutual learning |
| SGD | Stochastic gradient descent |
| SSS | Sparse Structure Selection |
| VCNNP | Variational convolutional neural network pruning |
| GAL | generative adversarial learning |
| GDP | Gobal and Dynamic pruning |
| DCFF | dynamic-coded filter fusion |
| NS | Network Slimming |
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, X.; Weng, J.; Lu, W.; Xu, J.; Weng, J. Deep manifold learning combined with convolutional neural networks for action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3938–3952. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1737–1746. [Google Scholar]
- Shin, S.; Hwang, K.; Sung, W. Fixed-point performance analysis of recurrent neural networks. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 976–980. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or -1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 525–542. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on KNOWLEDGE Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3713–3722. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Luo, J.H.; Wu, J. An entropy-based pruning method for cnn compression. arXiv 2017, arXiv:1706.05791. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. HRank: Filter Pruning using High-Rank Feature Map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1529–1538. [Google Scholar]
- Yan, Y.; Li, C.; Guo, R.; Yang, K.; Xu, Y. Channel Pruning via Multi-Criteria based on Weight Dependency. arXiv 2020, arXiv:2011.03240. [Google Scholar]
- Lin, M.; Cao, L.; Li, S.; Ye, Q.; Tian, Y.; Liu, J.; Tian, Q.; Ji, R. Filter sketch for network pruning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Cun, Y.L.; Denker, J.S.; Solla, S.A. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1989, 2, 598–605. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural networks. arXiv 2015, arXiv:1506.02626. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. Play and prune: Adaptive filter pruning for deep model compression. arXiv 2019, arXiv:1905.04446. [Google Scholar]
- Zhao, C.; Ni, B.; Zhang, J.; Zhao, Q.; Zhang, W.; Tian, Q. Variational convolutional neural network pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2780–2789. [Google Scholar]
- Lin, S.; Ji, R.; Yan, C.; Zhang, B.; Cao, L.; Ye, Q.; Huang, F.; Doermann, D. Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2790–2799. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Dubey, A.; Chatterjee, M.; Ahuja, N. Coreset-based neural network compression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 454–470. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.W.; Tang, C.K. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Luo, J.H.; Wu, J. Neural network pruning with residual-connections and limited-data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1458–1467. [Google Scholar]
- Lin, M.; Ji, R.; Xu, Z.; Zhang, B.; Wang, Y.; Wu, Y.; Huang, F.; Lin, C.W. Rotated binary neural network. arXiv 2020, arXiv:2009.13055. [Google Scholar]
- Yang, J.; Shen, X.; Xing, J.; Tian, X.; Li, H.; Deng, B.; Huang, J.; Hua, X.s. Quantization networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7308–7316. [Google Scholar]
- Gong, Y.; Liu, L.; Yang, M.; Bourdev, L. Compressing deep convolutional networks using vector quantization. arXiv 2014, arXiv:1412.6115. [Google Scholar]
- Zhu, C.; Han, S.; Mao, H.; Dally, W.J. Trained ternary quantization. arXiv 2016, arXiv:1612.01064. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. In Handbook of Systemic Autoimmune Diseases. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf (accessed on 31 July 2021).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, N. Data-driven sparse structure selection for deep neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 304–320. [Google Scholar]
- Lin, M.; Ji, R.; Chen, B.; Chao, F.; Liu, J.; Zeng, W.; Tian, Y.; Tian, Q. Training Compact CNNs for Image Classification using Dynamic-coded Filter Fusion. arXiv 2021, arXiv:2107.06916. [Google Scholar]
- Meng, F.; Cheng, H.; Li, K.; Luo, H.; Guo, X.; Lu, G.; Sun, X. Pruning filter in filter. arXiv 2020, arXiv:2009.14410. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.F.; Lai, J.H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.Y.; Davis, L.S. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018; pp. 9194–9203. [Google Scholar]
- Li, Y.; Lin, S.; Zhang, B.; Liu, J.; Doermann, D.; Wu, Y.; Huang, F.; Ji, R. Exploiting kernel sparsity and entropy for interpretable CNN compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2800–2809. [Google Scholar]
- Lin, S.; Ji, R.; Li, Y.; Wu, Y.; Huang, F.; Zhang, B. Accelerating Convolutional Networks via Global & Dynamic Filter Pruning. IJCAI 2018, 2, 2425–2432. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on COMPUTER Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- Hassibi, B. Second Order Derivatives for Network Pruning: Optimal Brain Surgeon. Adv. Neural Inf. Process. Syst. 1992, 5, 164–171. [Google Scholar]
- Srinivas, S.; Babu, R.V. Data-free parameter pruning for Deep Neural Networks. arXiv 2015, arXiv:1507.06149. [Google Scholar]
- Dong, X.; Chen, S.; Pan, S.J. Learning to prune deep neural networks via layer-wise optimal brain surgeon. arXiv 2017, arXiv:1705.07565. [Google Scholar]
- Liu, Z.; Xu, J.; Peng, X.; Xiong, R. Frequency-domain dynamic pruning for convolutional neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Vancouver, Canada, 8–14 December 2019; pp. 1051–1061. [Google Scholar]
- Alvarez, J.M.; Salzmann, M. Learning the number of neurons in deep networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, 5–10 December 2016; pp. 2270–2278. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic network surgery for efficient dnns. arXiv 2016, arXiv:1608.04493. [Google Scholar]
- Lin, T.; Stich, S.U.; Barba, L.; Dmitriev, D.; Jaggi, M. Dynamic model pruning with feedback. arXiv 2020, arXiv:2006.07253. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient inference engine on compressed deep neural network. ACM SIGARCH Comput. Archit. News 2016, 44, 243–254. [Google Scholar] [CrossRef]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. arXiv 2016, arXiv:1608.03665. [Google Scholar]
- Kang, M.; Han, B. Operation-aware soft channel pruning using differentiable masks. In Proceedings of the International Conference on Machine Learning, Virtual event, 13–18 July 2020; pp. 5122–5131. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 31 July 2021).
- Lee, M.K.; Lee, S.; Lee, S.H.; Song, B.C. Channel Pruning Via Gradient Of Mutual Information For Light-Weight Convolutional Neural Networks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1751–1755. [Google Scholar]

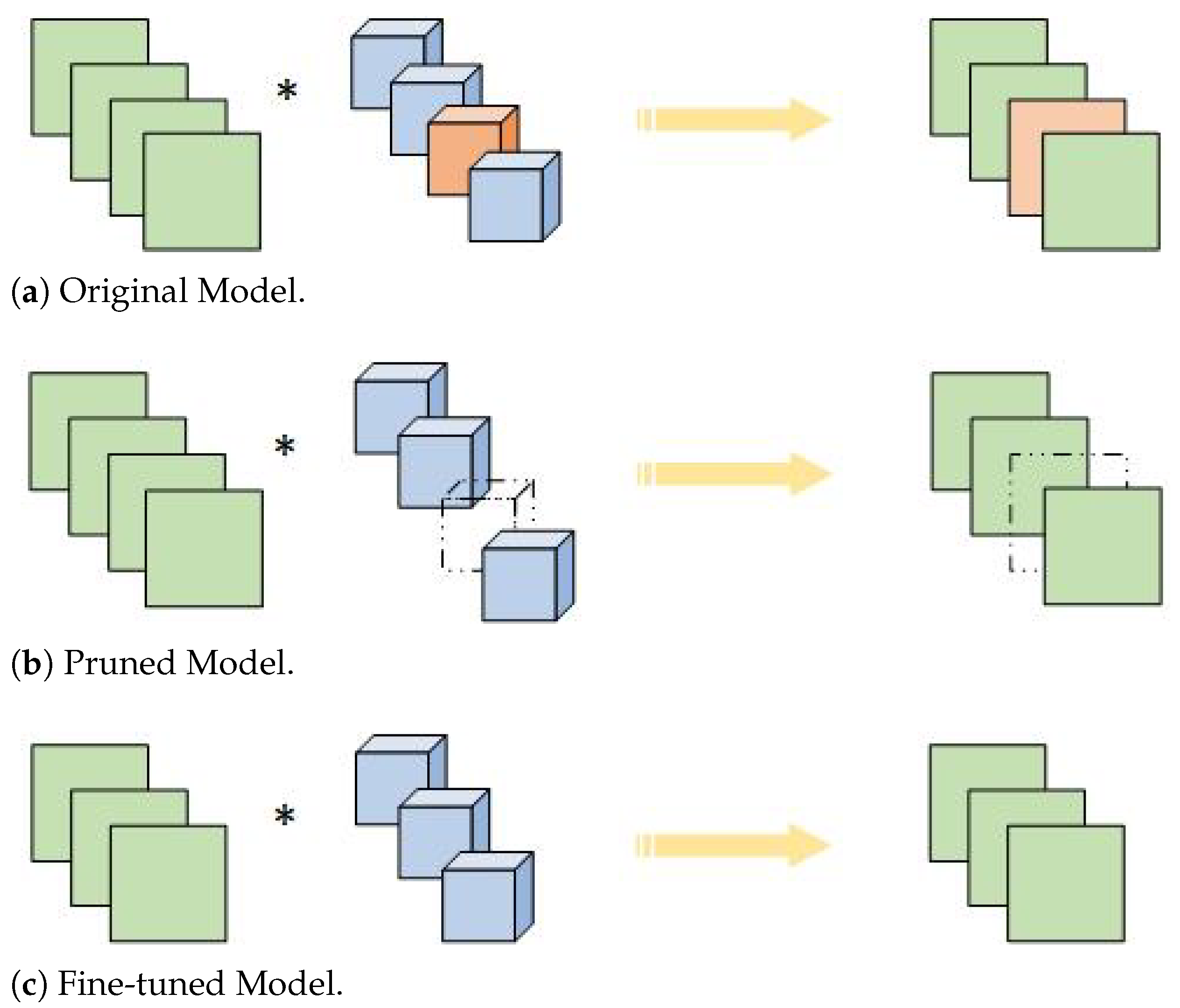
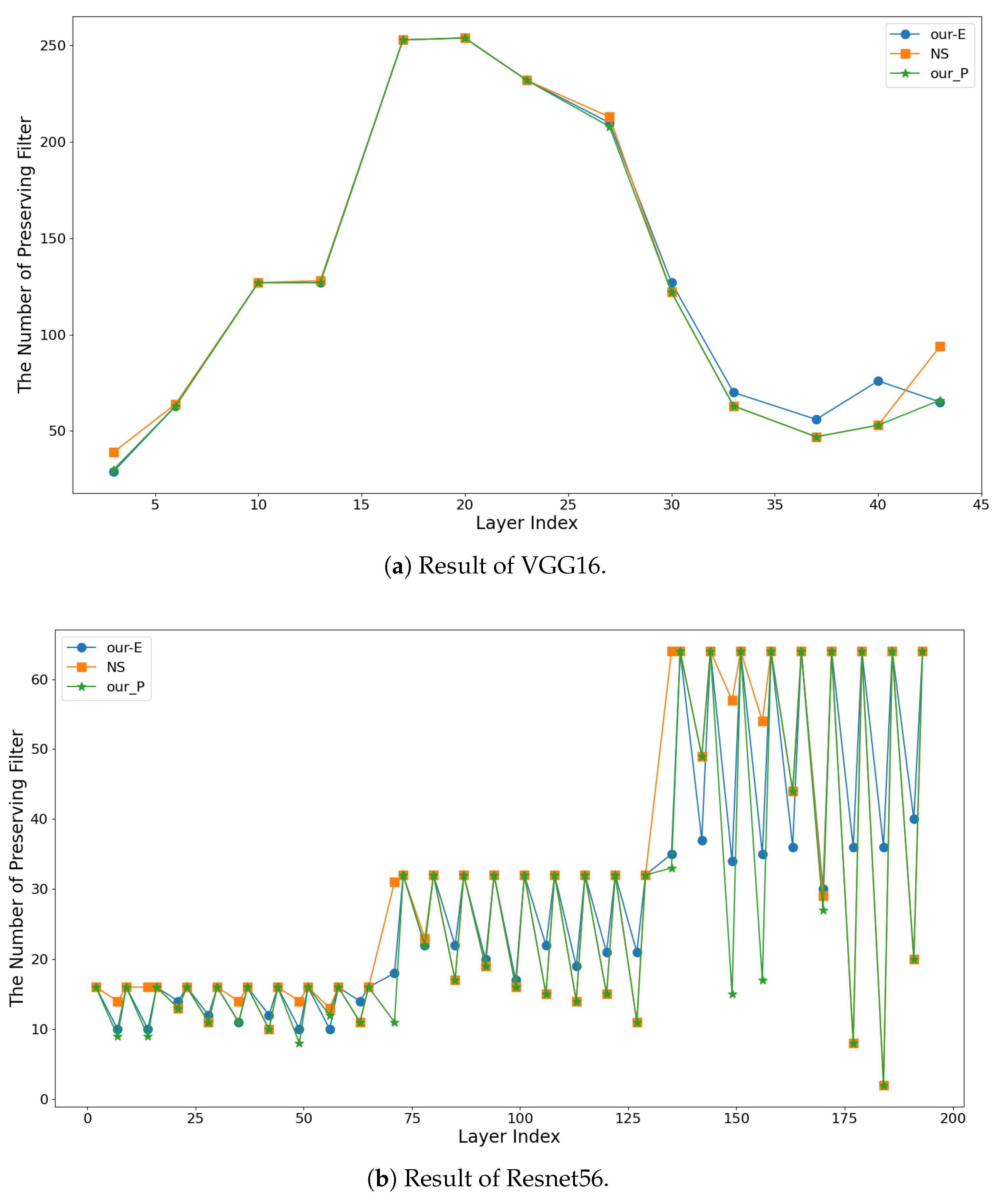
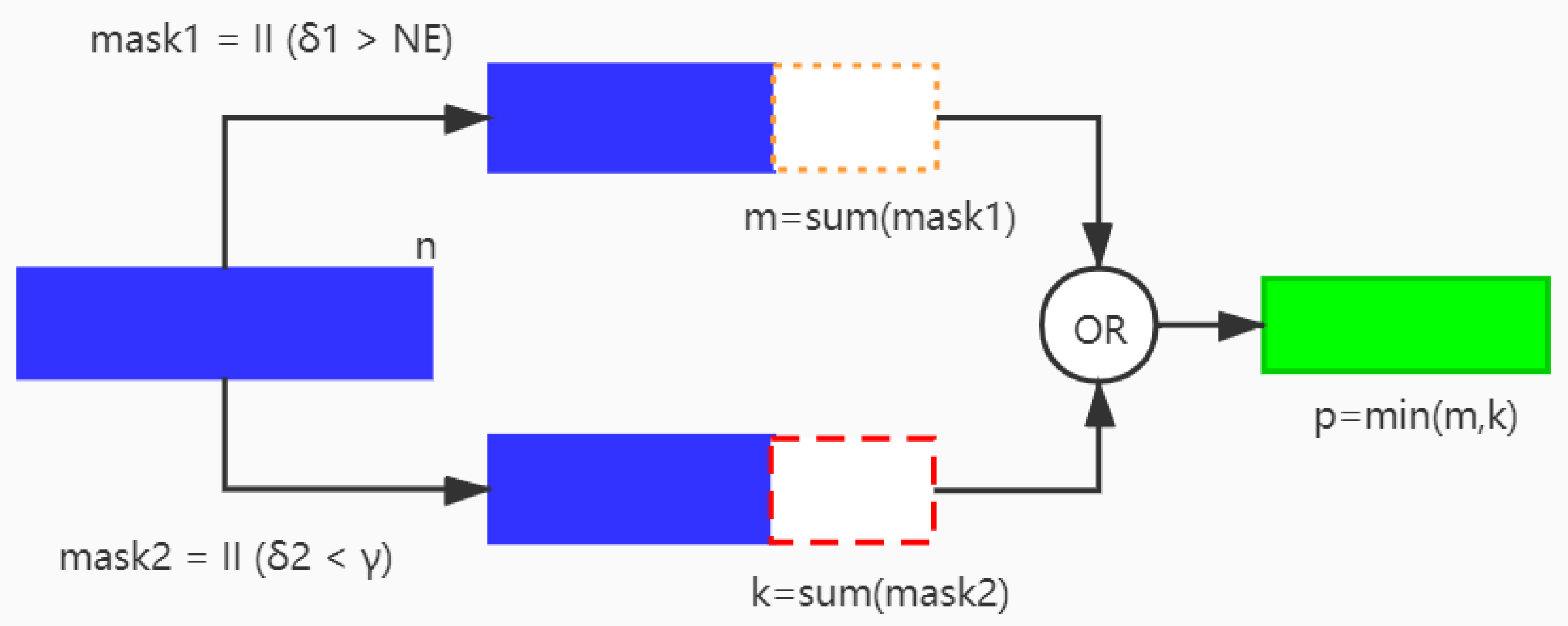
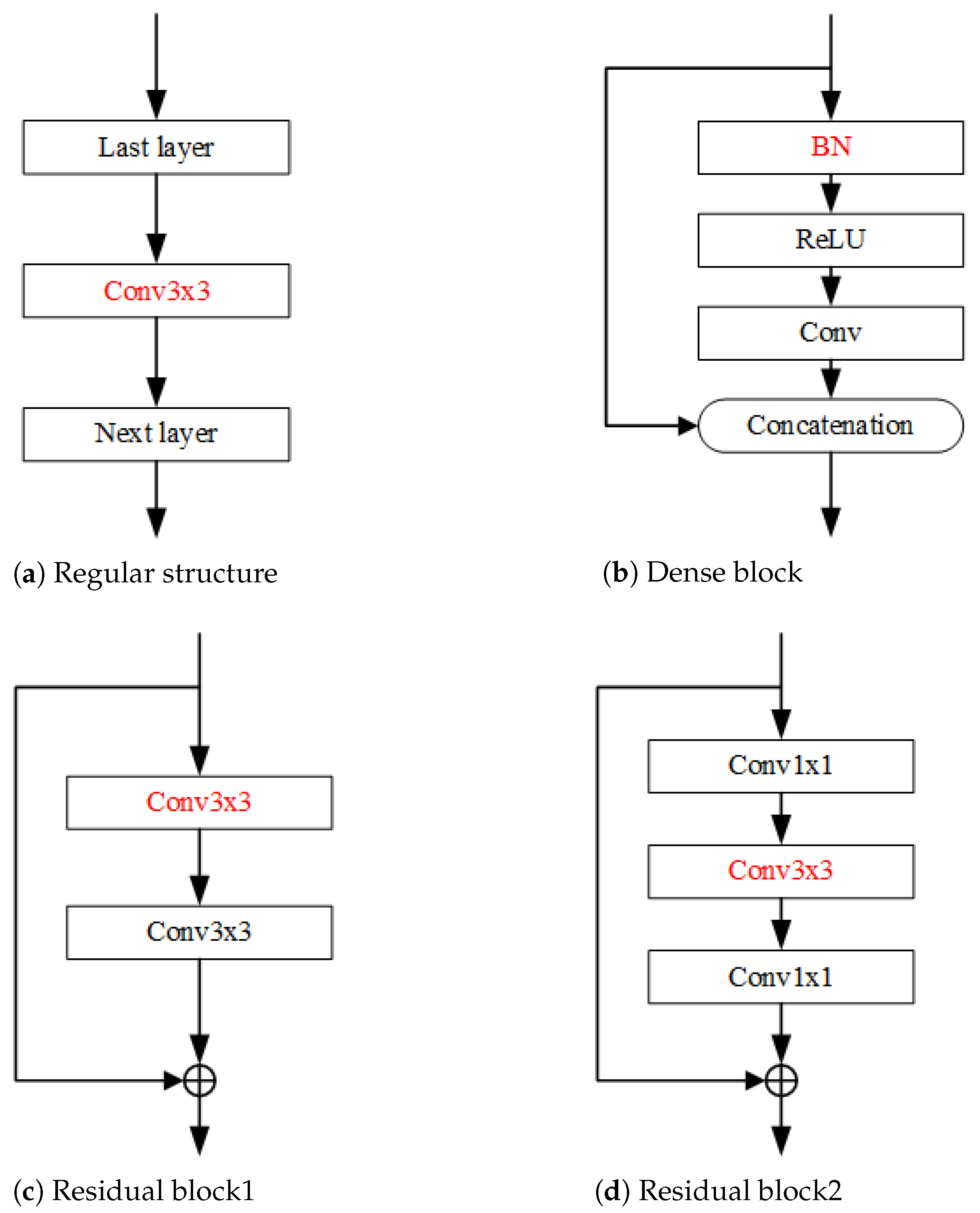

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Alg | Acc(%) | Param | FLOPs |
|---|---|---|---|---|
| VGG16 | Baseline | 93.90 | 14.72M | 313.75M |
| NS [12] | 93.69 | 3.45M | 199.66M | |
| L1 [22] | 93.40 | 5.40M | 206.00M | |
| SSS [35] | 93.02 | 3.93M | 183.13M | |
| GAL-0.05 [21] | 92.03 | 3.36M | 189.49M | |
| VCNNP [20] | 93.18 | 3.92M | 190.01M | |
| HRank [14] | 92.34 | 2.64M | 108.61M | |
| DCFF [36] | 93.47 | 1.06M | 72.77M | |
| CP MC [15] | 93.40 | 1.04M | 106.68M | |
| SWP [37] | 92.85 | 1.08M | 90.60M | |
| 83.96M | ||||
| 93.47 | 89.02M | |||
| 93.16 | 79.85M | |||
| VGG19 | Baseline | 93.68 | 20.04M | 398.74M |
| NS [12] | 93.66 | 2.43M | 208.54M | |
| 93.63 | 129.21M | |||
| 93.58 | 127.44M | |||
| ResNet56 | Baseline | 93.22 | 0.85M | 126.55M |
| NS [12] | 92.94 | 0.41M | 64.94M | |
| L1 [22] | 93.06 | 0.73M | 90.90M | |
| NISP [38] | 93.01 | 0.49M | 81.00M | |
| GAL-0.6 [21] | 92.98 | 0.75M | 78.30M | |
| HRank [14] | 93.17 | 0.49M | 62.72M | |
| KSE (G = 4) [39] | 93.23 | 0.43M | 60M | |
| DCFF [36] | 93.26 | 0.38M | 55.84M | |
| KSE (G = 5) [39] | 92.88 | 0.36M | 50M | |
| FilterSketch [16] | 93.19 | 0.50M | 73.36M | |
| 0.39M | 69.52M | |||
| 93.36 | 0.39M | 63.15M | ||
| 93.09 | 59.66M | |||
| ResNet164 | Baseline | 95.04 | 1.71M | 254.50M |
| NS [12] | 94.73 | 1.10M | 137.50M | |
| CP MC [15] | 94.76 | 0.75M | 144.02M | |
| 94.66 | ||||
| 93.65 | 0.73M | 105.86M | ||
| DenseNet40 | Baseline | 94.26 | 1.06M | 290.13M |
| GAL-0.01 [21] | 94.9 | 0.67M | 182.92M | |
| HRank [14] | 94.24 | 0.66M | 167.41M | |
| VCNNP [20] | 93.16 | 0.42M | 156.00M | |
| CP MC [15] | 93.74 | 0.42M | 121.73M | |
| KSE (G = 6) [39] | 94.70 | 0.39M | 115M | |
| NS [12] | 94.09 | 0.40M | 132.16M | |
| 94.04 | ||||
| 93.75 |
| Model | Alg | Acc(%) | Param | FLOPs |
|---|---|---|---|---|
| VGG16 | Baseline | 73.80 | 14.77M | 313.8M |
| VCNNP [20] | 73.33 | 9.14M | 256.00M | |
| NS [12] | 73.72 | 8.83M | 274.00M | |
| CPGMI [54] | 73.53 | 4.99M | 198.20M | |
| CPMC [15] | 73.01 | 4.80M | 162.00M | |
| 73.17 | ||||
| 73.06 | ||||
| 73.17 | 4.09M | 147.99M | ||
| VGG19 | Baseline | 73.81 | 20.08M | 398.79M |
| NS [12] | 73.00 | 5.84M | 274.36M | |
| 4.21M | ||||
| 195.77M | ||||
| 180.51M | ||||
| ResNet56 | Baseline | 71.77 | 0.86M | 71.77M |
| NS [12] | 70.51 | 0.60M | 62,82M | |
| 0.50M | 80.48M | |||
| 70.67 | 69.88M | |||
| ResNet164 | Baseline | 76.74 | 1.73M | 253.97M |
| NS [12] | 76.18 | 1.21M | 123.50M | |
| CPMC [15] | 77.22 | 0.96M | 151.92M | |
| 76.28 | 150.57M | |||
| 75.27 | ||||
| DenseNet40 | Baseline | 74.37 | 1.11M | 287.75M |
| VCNNP [20] | 72.19 | 0.65M | 218.00M | |
| CPGMI [54] | 73.84 | 0.66M | 198.50M | |
| CPMC [15] | 73.93 | 0.58M | 155.24M | |
| NS [12] | 73.87 | 0.55M | 164.36M | |
| 73.74 | ||||
| 73.62 |
| Model | Top-1% | Top-5% | FLOPs | Parameters |
|---|---|---|---|---|
| ResNet50 [41] | 76.15 | 92.87 | 4.09 | 25.50 |
| SSS-32 [35] | 74.18 | 91.91 | 2.82 | 18.60 |
| [50] | 72.30 | 90.80 | 2.73 | - |
| GAL-0.5 [21] | 71.95 | 90.94 | 2.33 | 21.20 |
| HRank [14] | 74.98 | 92.33 | 2.30 | 16.15 |
| GDP-0.6 [40] | 71.19 | 90.71 | 1.88 | - |
| GDP-0.5 [40] | 69.58 | 90.14 | 1.57 | - |
| SSS-26 [35] | 71.82 | 90.79 | 2.33 | 15.60 |
| GAL-1 [21] | 69.88 | 89.75 | 1.58 | 14.67 |
| GAL-0.5-joint [21] | 71.80 | 90.82 | 1.84 | 19.31 |
| HRank [14] | 71.98 | 91.01 | 1.55 | 13.77 |
| ThiNet-50 [41] | 68.42 | 88.30 | 1.10 | 8.66 |
| GAL-1-joint [21] | 69.31 | 89.12 | 1.11 | 10.21 |
| HRank [14] | 69.10 | 89.58 | 0.98 | 8.27 |
| NS [12] | 70.43 | 89.93 | ||
| 90.69 | ||||
| 70.41 | 89.91 | |||
| 69.91 | 89.46 | |||
| 68.62 | 88.62 |
| Model | Algorithm | Acc(%) | Param | FLOPs |
|---|---|---|---|---|
| VGG16 | 93.04 | 0.97M | 69.06M | |
| ResNet164 | 94.55 | 0.90M | 133.06M | |
| DenseNet40 | 93.83 | 0.37M | 149.75M | |
| Model | Algorithm | Acc(%) | Param | FLOPs |
|---|---|---|---|---|
| VGG16 | C-softmax | 92.97 | 0.98M | 65.38M |
| I-softmax | 0.99M | 83.96M | ||
| VGG19 | C-softmax | 91.85 | 1.72M | 63.64M |
| I-softmax | 1.55M | 129.21M | ||
| ResNet56 | C-softmax | 93.21 | 0.45M | 63.11M |
| I-softmax | 0.39M | 69.52M | ||
| ResNet164 | C-softmax | 93.91 | 0.67M | 112.73M |
| I-softmax | 0.67M | 111.33M | ||
| DenseNet40 | C-softmax | 94.17 | 0.39M | 118.01M |
| I-softmax | 94.04 | 0.38M | 110.72M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, L.; Zuo, H.; Zhang, J.; Xu, Z.; Yao, J.; Wang, Z.; Li, H. Filter Pruning via Measuring Feature Map Information. Sensors 2021, 21, 6601. https://doi.org/10.3390/s21196601
Shao L, Zuo H, Zhang J, Xu Z, Yao J, Wang Z, Li H. Filter Pruning via Measuring Feature Map Information. Sensors. 2021; 21(19):6601. https://doi.org/10.3390/s21196601
Chicago/Turabian StyleShao, Linsong, Haorui Zuo, Jianlin Zhang, Zhiyong Xu, Jinzhen Yao, Zhixing Wang, and Hong Li. 2021. "Filter Pruning via Measuring Feature Map Information" Sensors 21, no. 19: 6601. https://doi.org/10.3390/s21196601
APA StyleShao, L., Zuo, H., Zhang, J., Xu, Z., Yao, J., Wang, Z., & Li, H. (2021). Filter Pruning via Measuring Feature Map Information. Sensors, 21(19), 6601. https://doi.org/10.3390/s21196601