
Optimising Speaker-Dependent Feature Extraction Parameters to Improve Automatic Speech Recognition Performance for People with Dysarthria



Abstract
:1. Introduction
2. Materials and Methods
2.1. IDEA: The Dysarthric Database
2.2. Speaker Selection
2.3. CLIPS: Unimpaired Speech Database
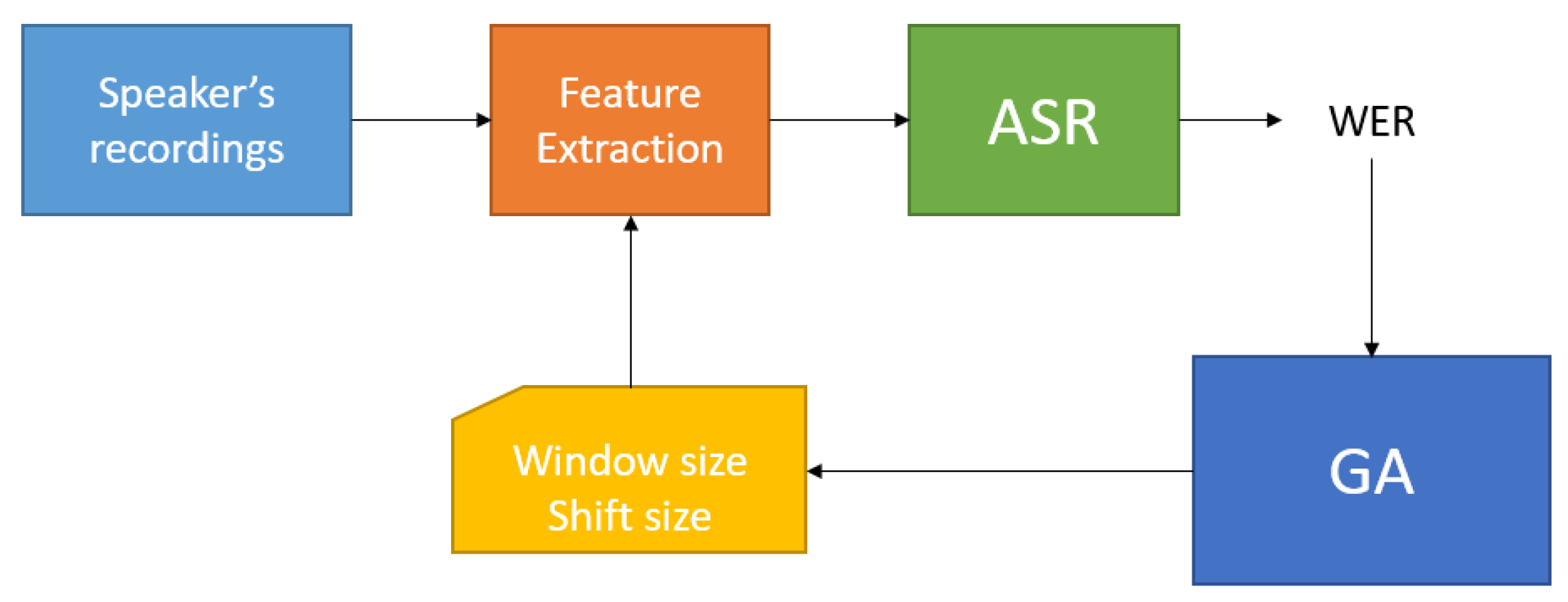
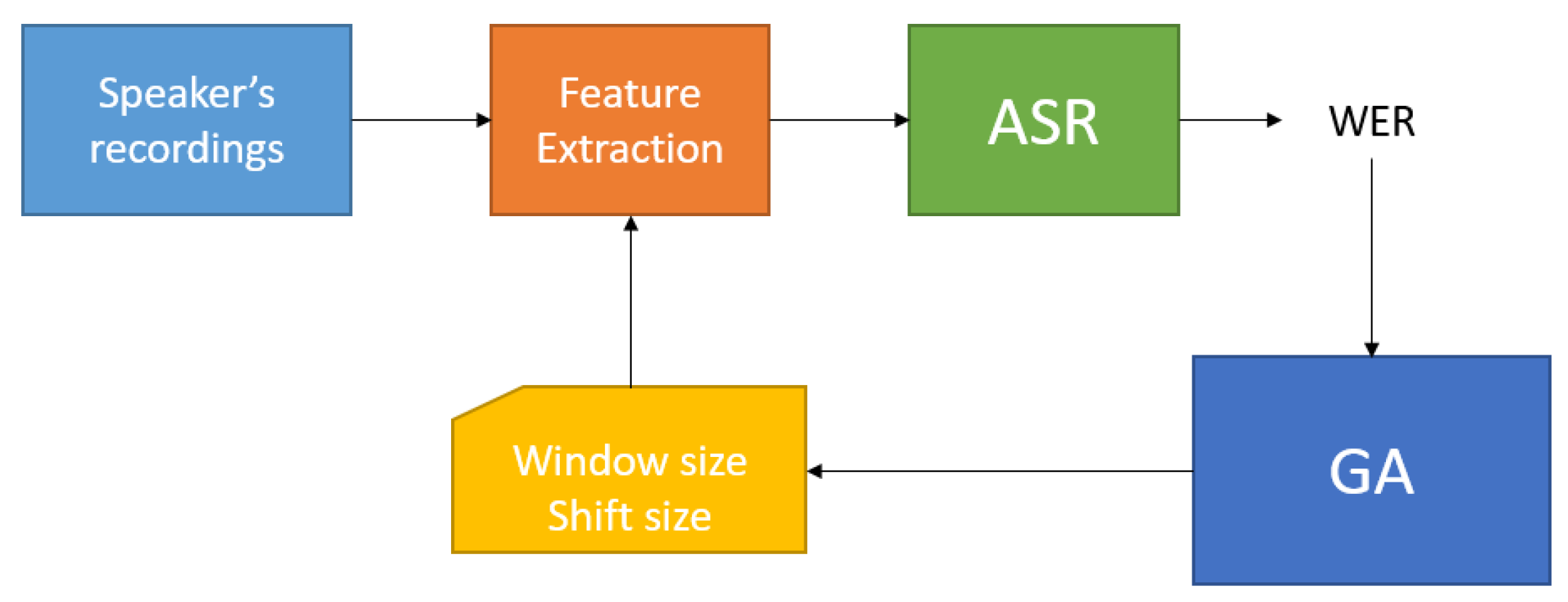
2.4. Automatic Speech Recognition System and Genetic Algorithm Implementation
| Algorithm 1 Genetic Algorithm process steps |
|
- Chromosome: composed by 2 genes (float values) that represent Window and Shift parameters;
- Crossover: single point;
- Likelihood Mutation: 0.15;
- Population Size: 50;
- Stop Criterion: Fitness convergence ();
3. Experimental Setup
3.1. First Experiment
| Algorithm 2 Experiment process steps |
|
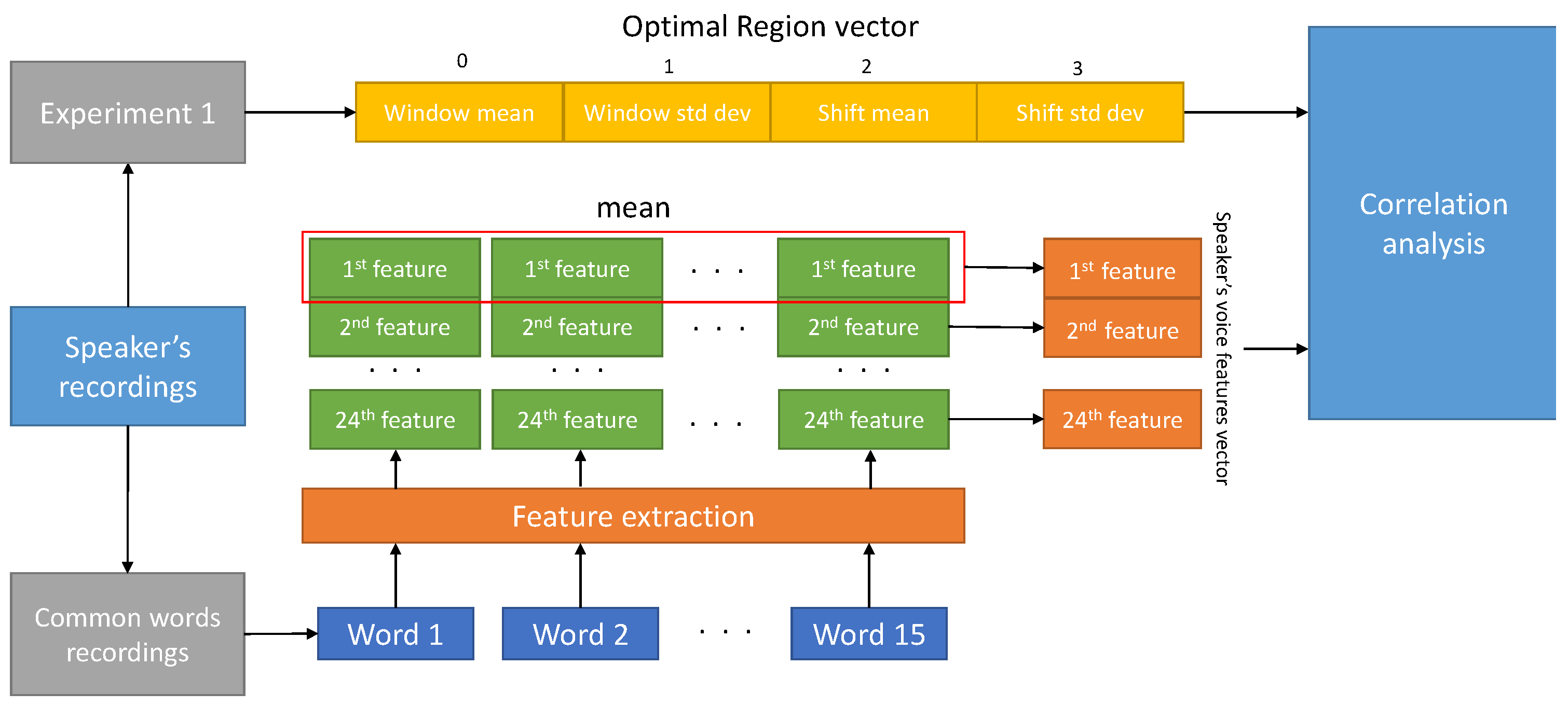
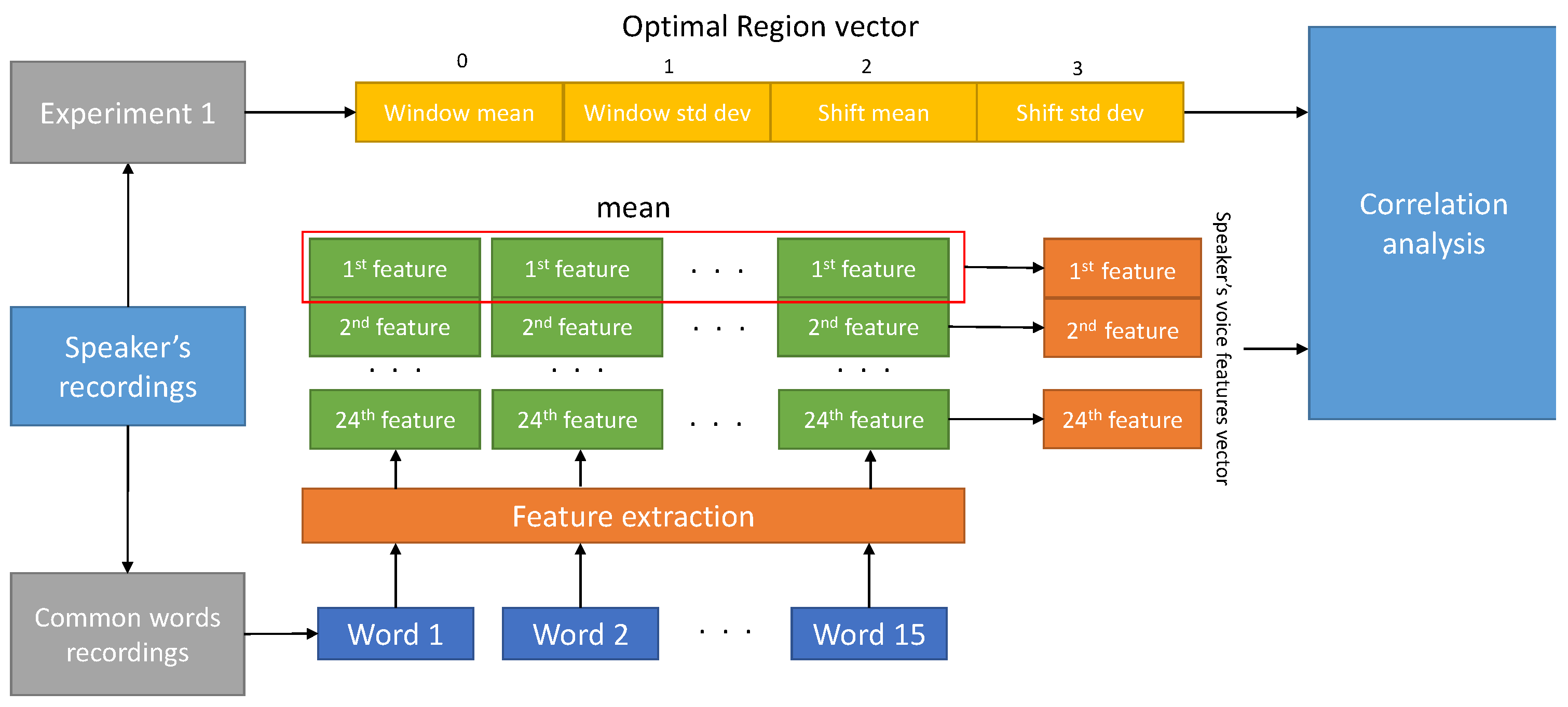
3.2. Second Experiment
- accendi
- cancello
- chiesa
- corridoio
- fanno
- forza
- hanno
- maggiore
- paesi
- pubblico
- scenario
- soffitta
- sveglia
- terrazzo
- zero
- Duration in seconds: it is the length of the voice file in seconds;
- Mean F0: it is the mean of the Fundamental frequency F0;
- STD F0: it is the standard deviation of the Fundamental frequency F0;
- Subharmonics to Harmonic ratio (SHR): amplitude ratio between subharmonics and harmonics according to [24];
- Subharmonics pitch: the fundamental frequency estimate introduced in [24] for impaired speakers;
- Local jitter: parameter of frequency variation from cycle to cycle;
- Absolute jitter https://www.fon.hum.uva.nl/praat/manual/PointProcess__Get_jitter__local__absolute____.html (accessed on 10 May 2021): it is the average absolute difference between consecutive periods in seconds;
- RAP jitter https://www.fon.hum.uva.nl/praat/manual/Voice_2__Jitter.html (accessed on 10 May 2021): Relative Average Perturbation, the average absolute difference between a period and the average of it and its two neighbours, divided by the average period;
- Local shimmer: amplitude variation of the sound wave [25];
- F1 mean: it is the first formant https://www.fon.hum.uva.nl/praat/manual/Formant__Track___.html (accessed on 10 May 2021);
- F2 mean: it is the second formant;
- F3 mean: it is the third formant;
- F4 mean: it is the fourth formant;
- Formant dispersion: it is the difference between F4 and F1 divided by 3;
- Mean intensity https://www.fon.hum.uva.nl/praat/manual/Intensity__Get_mean___.html (accessed on 10 May 2021): the mean (in dB) of the intensity values of the frames within a specified time domain;
- Speech rate: number of syllables divided by file duration in seconds;
- Signal to Noise ratio (SNR);
- LTAS https://www.fon.hum.uva.nl/praat/manual/Spectrum__To_Ltas__1-to-1_.html (accessed on 10 May 2021): it is the mean of logarithmic power spectral density as a function of frequency, computed over the entire domain frequency (from 0 Hz to 5000 Hz);
- LTAS slope;
- LTAS standard deviation;
- RMS energy: root-mean-square of energy;
- Spectrum centre of gravity (SCG) https://www.fon.hum.uva.nl/praat/manual/Spectrum__Get_centre_of_gravity___.html (accessed on 10 May 2021): it is the average of frequency over the entire spectrum, weighted by the power spectrum;
- Spectrum standard deviation https://www.fon.hum.uva.nl/praat/manual/Spectrum__Get_standard_deviation___.html (accessed on 10 May 2021): it is the variance of the frequencies in the spectrum;
- Band Energy difference https://www.fon.hum.uva.nl/rob/NKI_TEVA/TEVA/HTML/Analysis.html (accessed on 10 May 2021): it is the ratio between the average power over low (between 0 Hz and 500 Hz) and high (between 500 Hz and 4000 Hz) frequency bins in decibel scale;
4. Analysis of Experimental Results
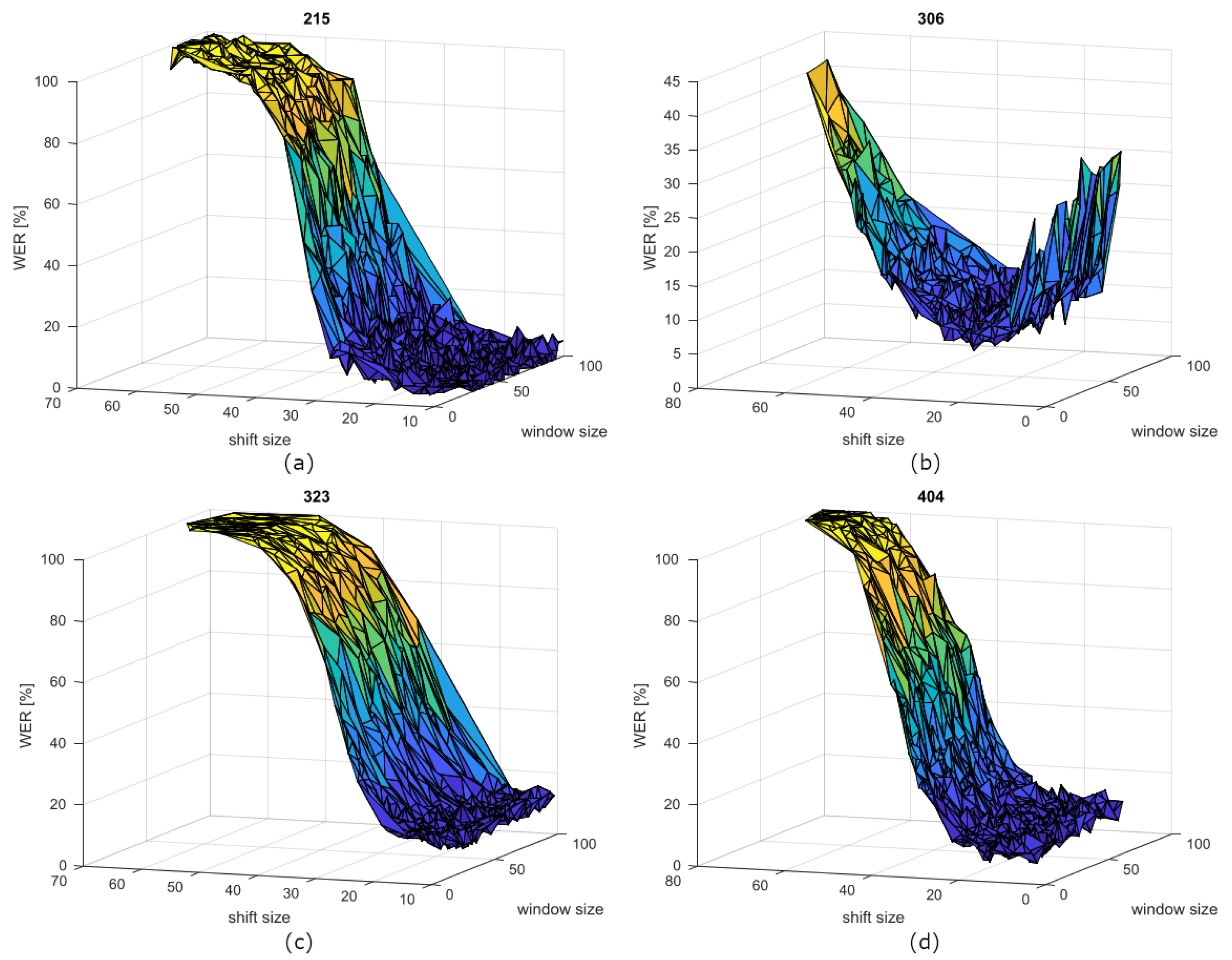
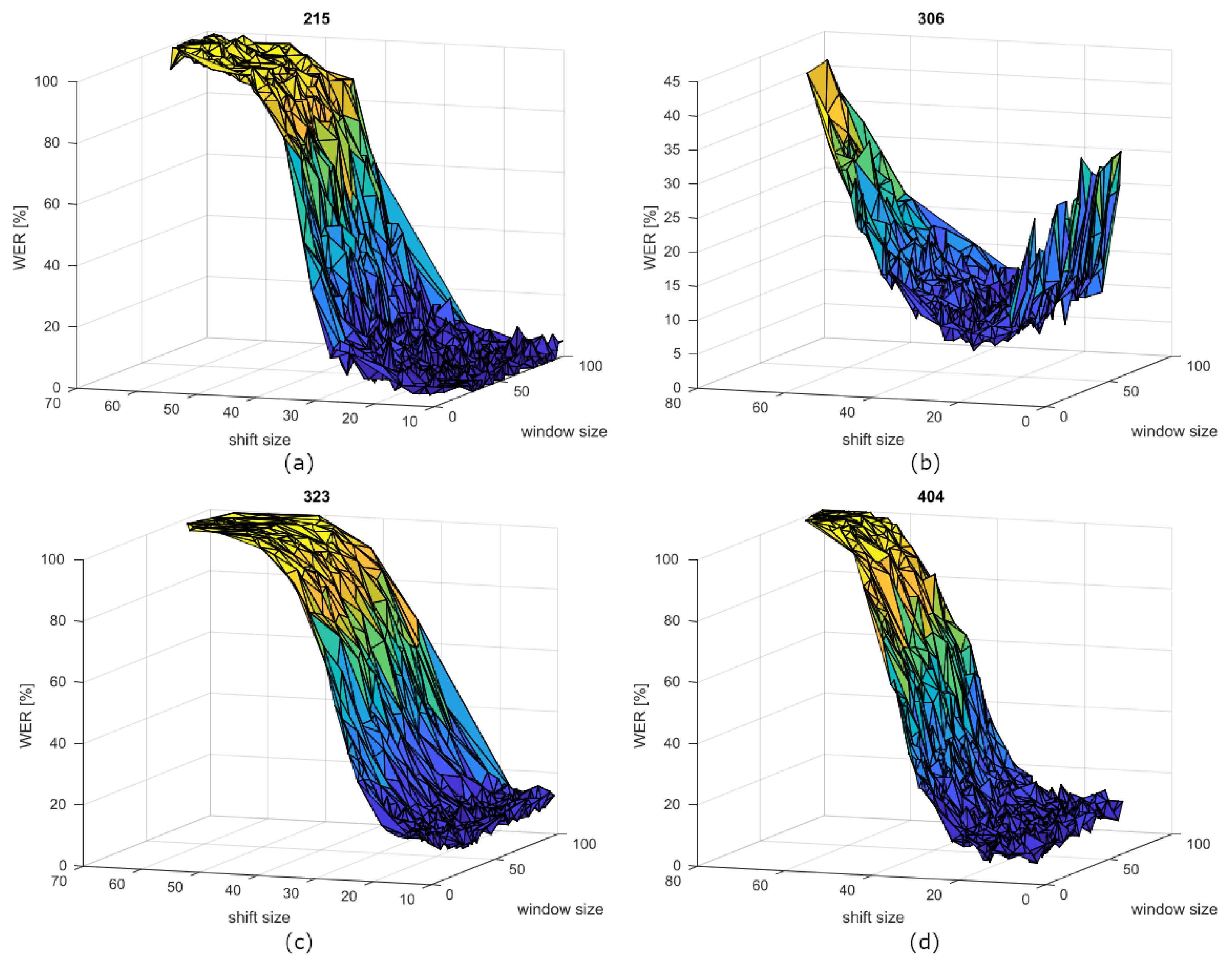
4.1. First Experiment Results—IDEA
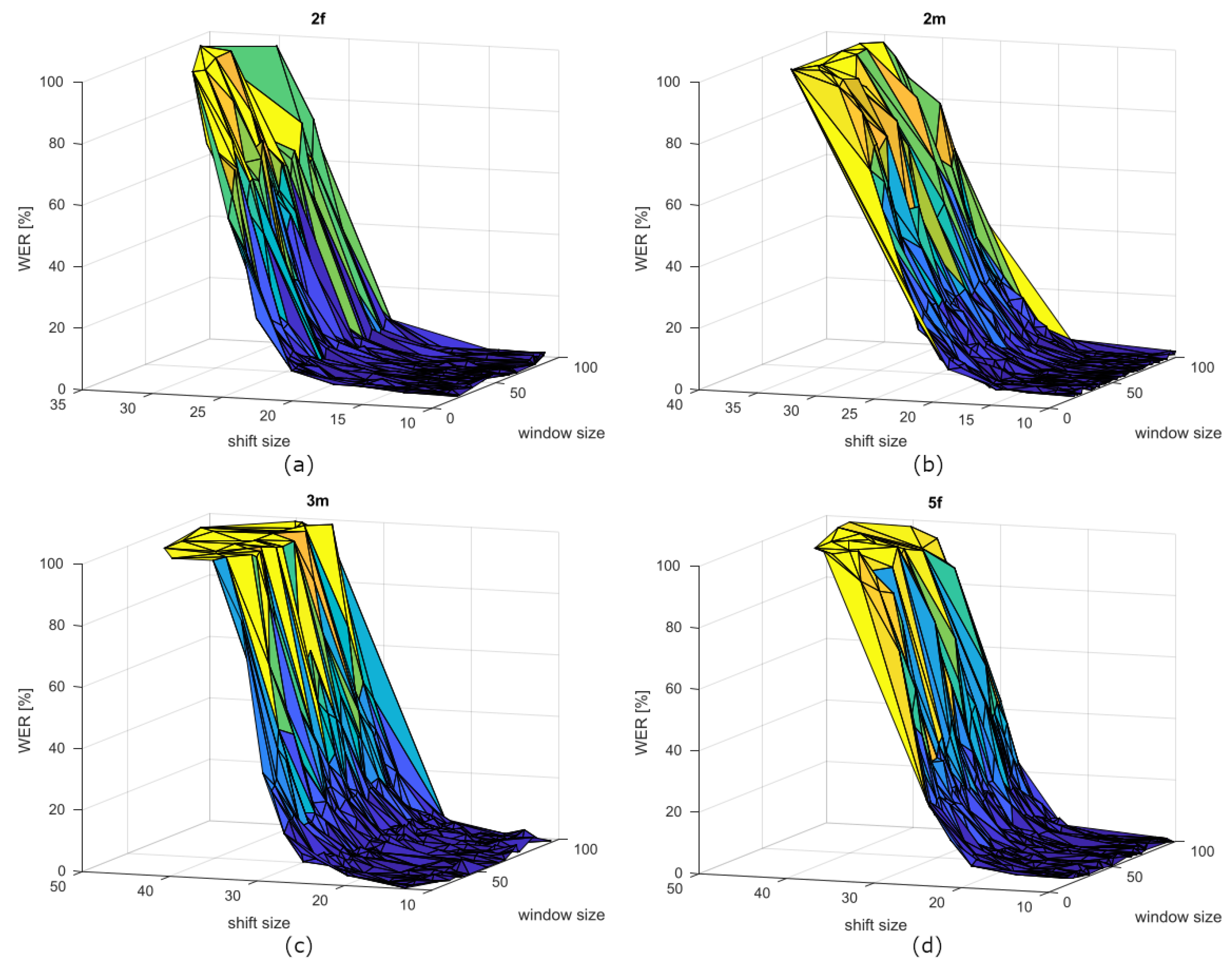
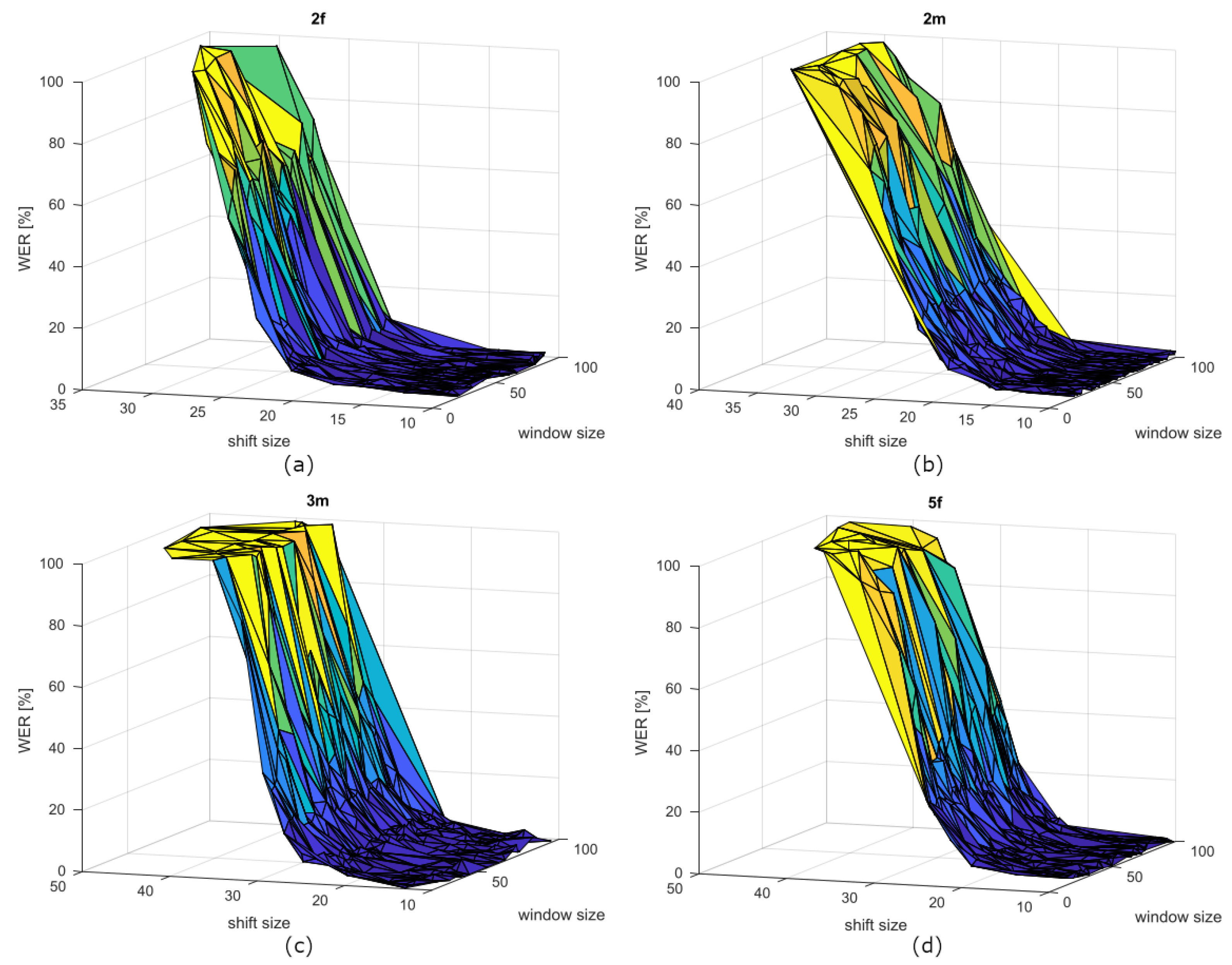
4.2. First Experiment Results—CLIPS
4.3. Second Experiment Results—IDEA
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McNeil, M.R. Clinical Management of Sensorimotor Speech Disorders; Thieme: New York, NY, USA, 2009. [Google Scholar]
- Ballati, F.; Corno, F.; De Russis, L. “Hey Siri, do you understand me?”: Virtual Assistants and Dysarthria. In Intelligent Environments 2018; IOS Press: Amsterdam, The Netherlands, 2018; pp. 557–566. [Google Scholar]
- Gales, M.; Young, S. The Application of Hidden Markov Models in Speech Recognition; Publishers Inc.: Norwell, MA, USA, 2008. [Google Scholar]
- Li, J.; Yu, D.; Huang, J.T.; Gong, Y. Improving wideband speech recognition using mixed-bandwidth training data in CD-DNN-HMM. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 131–136. [Google Scholar]
- Ballati, F.; Corno, F.; De Russis, L. Assessing virtual assistant capabilities with Italian dysarthric speech. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility, Galway, Ireland, 22–24 October 2018; pp. 93–101. [Google Scholar]
- Rudzicz, F.; Namasivayam, A.K.; Wolff, T. The TORGO database of acoustic and articulatory speech from speakers with dysarthria. Lang. Resour. Eval. 2012, 46, 523–541. [Google Scholar] [CrossRef]
- Kim, H.; Hasegawa-Johnson, M.; Perlman, A.; Gunderson, J.; Huang, T.S.; Watkin, K.; Frame, S. Dysarthric speech database for universal access research. In Proceedings of the Ninth Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- James, X.M.P.; Polikoff, J.B.; Peters, S.M.; Leonzio, J.E.; Bunnell, H. The Nemours database of dysarthric speech. In Proceedings of the Fourth International Conference on Spoken Language Processing, Philadelphia, PA, USA, 3–6 October 1996. [Google Scholar]
- Mengistu, K.T.; Rudzicz, F. Adapting acoustic and lexical models to dysarthric speech. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4924–4927. [Google Scholar]
- Joy, N.M.; Umesh, S. Improving acoustic models in TORGO dysarthric speech database. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 637–645. [Google Scholar] [CrossRef] [PubMed]
- Espana-Bonet, C.; Fonollosa, J.A. Automatic speech recognition with deep neural networks for impaired speech. In International Conference on Advances in Speech and Language Technologies for Iberian Languages; Springer: Berlin/Heidelberg, Germany, 2016; pp. 97–107. [Google Scholar]
- Aizawa, K.; Nakamura, Y.; Satoh, S. Advances in Multimedia Information Processing-PCM 2004: 5th Pacific Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3332. [Google Scholar]
- Marini, M.; Meoni, G.; Mulfari, D.; Vanello, N.; Fanucci, L. Enabling Smart Home Voice Control for Italian People with Dysarthria: Preliminary Analysis of Frame Rate Effect on Speech Recognition. In International Conference on Applications in Electronics Pervading Industry, Environment and Society; Springer: Berlin/Heidelberg, Germany, 2020; pp. 104–110. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In IEEE 2011 Workshop on Automatic Speech Recognition and Understanding; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. [Google Scholar]
- Marini, M.; Viganò, M.; Corbo, M.; Zettin, M.; Simoncini, G.; Fattori, B.; D’Anna, C.; Donati, M.; Fanucci, L. IDEA: An Italian Dysarthric Speech Database. In 2021 IEEE Spoken Language Technology Workshop (SLT); IEEE: Manhattan, NY, USA, 2021; pp. 1086–1093. [Google Scholar]
- Shahin, M.; Ahmed, B.; McKechnie, J.; Ballard, K.; Gutierrez-Osuna, R. A comparison of GMM-HMM and DNN-HMM based pronunciation verification techniques for use in the assessment of childhood apraxia of speech. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Gopinath, R.A. Maximum likelihood modeling with Gaussian distributions for classification. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Washington, DC, USA, 12–15 May 1998; Volume 2, pp. 661–664. [Google Scholar]
- Benjamini, Y.; Yekutieli, D. The control of the false discovery rate in multiple testing under dependency. Ann. Stat. 2001, 29, 1165–1188. [Google Scholar] [CrossRef]
- Barsties, B.; De Bodt, M. Assessment of voice quality: Current state-of-the-art. Auris Nasus Larynx 2015, 42, 183–188. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, J.P.; Oliveira, C.; Lopes, C. Vocal acoustic analysis–jitter, shimmer and hnr parameters. Procedia Technol. 2013, 9, 1112–1122. [Google Scholar] [CrossRef] [Green Version]
- Vizza, P.; Mirarchi, D.; Tradigo, G.; Redavide, M.; Bossio, R.B.; Veltri, P. Vocal signal analysis in patients affected by Multiple Sclerosis. Procedia Comput. Sci. 2017, 108, 1205–1214. [Google Scholar] [CrossRef]
- Tanner, K.; Roy, N.; Ash, A.; Buder, E.H. Spectral moments of the long-term average spectrum: Sensitive indices of voice change after therapy? J. Voice 2005, 19, 211–222. [Google Scholar] [CrossRef] [PubMed]
- Sun, X. Pitch determination and voice quality analysis using subharmonic-to-harmonic ratio. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 1. [Google Scholar]
- Zwetsch, I.C.; Fagundes, R.D.R.; Russomano, T.; Scolari, D. Digital signal processing in the differential diagnosis of benign larynx diseases. Sci. Medica 2006, 16, 109–114, (Abstract in English). [Google Scholar]
- Rousseeuw, P.J.; Hubert, M. Robust statistics for outlier detection. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 73–79. [Google Scholar] [CrossRef]
- Feinberg, D.R.; Cook, O. VoiceLab: Automated Reproducible Acoustic Analysis. PsyArXiv 2020. [CrossRef]
- Boersma, P. Praat: Doing Phonetics by Computer. Available online: http://www.praat.org/ (accessed on 10 May 2021).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker’s ID | # Records | Train | Test | |
|---|---|---|---|---|
| 1 | 320 | 618 | 422 | 196 |
| 2 | 310 | 559 | 413 | 146 |
| 3 | 306 | 557 | 411 | 146 |
| 4 | 316 | 546 | 414 | 132 |
| 5 | 323 | 523 | 408 | 115 |
| 6 | 322 | 505 | 392 | 113 |
| 7 | 302 | 505 | 395 | 110 |
| 8 | 303 | 494 | 384 | 110 |
| 9 | 314 | 492 | 388 | 104 |
| 10 | 308 | 477 | 382 | 95 |
| 11 | 311 | 405 | 338 | 67 |
| 12 | 405 | 444 | 379 | 65 |
| 13 | 321 | 391 | 328 | 63 |
| 14 | 404 | 432 | 372 | 60 |
| 15 | 307 | 412 | 358 | 54 |
| 16 | 313 | 394 | 340 | 54 |
| 17 | 401 | 246 | 196 | 50 |
| 18 | 215 | 129 | 90 | 39 |
| 19 | 403 | 134 | 97 | 37 |
| 20 | 214 | 127 | 90 | 37 |
| 21 | 205 | 125 | 89 | 36 |
| 22 | 301 | 299 | 264 | 35 |
| 23 | 402 | 354 | 320 | 34 |
| 24 | 206 | 121 | 88 | 33 |
| 25 | 211 | 121 | 89 | 32 |
| 26 | 203 | 118 | 88 | 30 |
| 27 | 305 | 274 | 245 | 29 |
| 28 | 208 | 118 | 89 | 29 |
| 29 | 213 | 112 | 86 | 26 |
| 30 | 312 | 432 | 409 | 23 |
| 31 | 207 | 96 | 79 | 17 |
| 32 | 210 | 83 | 71 | 12 |
| 33 | 209 | 72 | 61 | 11 |
| 34 | 212 | 69 | 61 | 8 |
| 35 | 315 | 235 | 230 | 5 |
| 36 | 317 | 194 | 190 | 4 |
| 37 | 201 | 59 | 55 | 4 |
| 38 | 319 | 235 | 235 | 0 |
| 39 | 318 | 201 | 201 | 0 |
| 40 | 309 | 104 | 104 | 0 |
| 41 | 204 | 30 | 30 | 0 |
| 42 | 216 | 24 | 24 | 0 |
| 43 | 202 | 9 | 9 | 0 |
| 44 | 304 | 9 | 9 | 0 |
| 45 | 406 | 7 | 7 | 0 |
| Spk ID | Window (ms) | Shift (ms) | WER (%) | ||||
|---|---|---|---|---|---|---|---|
| Avg | Stdev | Avg | Stdev | Avg | Stdev | Baseline | |
| 215 | 57.34 | 21.17 | 16.07 | 3.75 | 2.68 | 3.05 | 0.768 |
| 305 | 48.84 | 20.27 | 20.32 | 4.13 | 9.05 | 4.29 | 6.9 |
| 211 | 45.14 | 19.84 | 13.92 | 2.07 | 7.49 | 5.37 | 5.94 |
| 213 | 62.28 | 23.49 | 15.55 | 3.87 | 12.49 | 5.76 | 11.54 |
| 401 | 54.30 | 19.73 | 18.45 | 4.37 | 3.98 | 3.25 | 3.8 |
| 311 | 44.77 | 16.74 | 13.64 | 2.48 | 8.71 | 3.20 | 8.36 |
| 206 | 56.00 | 19.41 | 18.79 | 5.20 | 2.69 | 3.28 | 2.73 |
| 323 | 51.58 | 20.68 | 13.84 | 2.20 | 10.10 | 2.32 | 10.61 |
| 301 | 52.74 | 25.78 | 13.56 | 2.55 | 16.66 | 5.15 | 18 |
| 308 | 45.35 | 14.29 | 14.15 | 2.08 | 6.41 | 3.27 | 7.37 |
| 316 | 47.98 | 19.30 | 15.43 | 2.20 | 8.52 | 2.56 | 9.93 |
| 322 | 60.81 | 19.90 | 21.34 | 4.35 | 12.03 | 2.66 | 14.87 |
| 208 | 57.39 | 19.51 | 21.63 | 4.85 | 4.10 | 3.36 | 5.17 |
| 404 | 46.48 | 17.92 | 16.89 | 3.64 | 5.94 | 2.60 | 7.5 |
| 214 | 40.09 | 17.04 | 11.21 | 1.25 | 7.14 | 5.20 | 9.19 |
| 313 | 46.08 | 21.54 | 17.65 | 2.62 | 11.53 | 3.78 | 15.37 |
| 312 | 56.37 | 22.79 | 18.51 | 3.83 | 2.79 | 3.03 | 3.92 |
| 205 | 49.39 | 22.05 | 15.30 | 2.70 | 3.35 | 2.73 | 4.72 |
| 310 | 53.25 | 17.28 | 19.77 | 3.02 | 1.87 | 1.27 | 2.67 |
| 303 | 41.39 | 13.44 | 18.82 | 2.36 | 4.50 | 1.71 | 6.54 |
| 320 | 65.85 | 17.02 | 24.17 | 4.94 | 7.26 | 1.36 | 10.87 |
| 302 | 49.09 | 17.58 | 18.44 | 3.03 | 2.60 | 2.14 | 4.55 |
| 203 | 60.09 | 19.57 | 18.51 | 5.51 | 6.35 | 5.78 | 11.66 |
| 403 | 64.95 | 22.06 | 27.78 | 10.79 | 1.91 | 2.21 | 3.51 |
| 314 | 66.87 | 16.37 | 38.80 | 8.73 | 43.15 | 6.14 | 80.67 |
| 405 | 48.88 | 17.63 | 17.15 | 2.26 | 8.59 | 4.12 | 16.92 |
| 402 | 42.60 | 20.51 | 20.13 | 2.03 | 7.54 | 5.57 | 16.18 |
| 307 | 49.78 | 14.74 | 15.68 | 3.22 | 6.40 | 3.37 | 13.89 |
| 321 | 43.57 | 16.84 | 18.49 | 3.02 | 6.87 | 3.24 | 16.35 |
| 306 | 55.42 | 17.04 | 27.25 | 4.91 | 7.89 | 1.97 | 19.11 |
| Spk ID | Window (ms) | Shift (ms) | WER (%) | ||||
|---|---|---|---|---|---|---|---|
| Avg | Stdev | Avg | Stdev | Avg | Stdev | Baseline | |
| 1f | 71.73 | 21.74 | 13.17 | 1.39 | 1.14 | 0.65 | 0.65 |
| 2f | 56.91 | 21.57 | 13.26 | 1.65 | 1.02 | 0.52 | 0.68 |
| 3f | 59.85 | 19.94 | 14.71 | 1.65 | 0.52 | 0.45 | 0.59 |
| 4f | 60.87 | 21.61 | 11.74 | 0.89 | 1.46 | 1.02 | 0.68 |
| 5f | 59.79 | 21.41 | 12.63 | 2.76 | 1.08 | 0.52 | 1.19 |
| 1m | 70.40 | 21.41 | 10.54 | 1.22 | 1.33 | 0.81 | 1.11 |
| 2m | 56.00 | 23.92 | 11.66 | 2.06 | 0.99 | 0.46 | 0.85 |
| 3m | 64.73 | 22.95 | 13.37 | 2.14 | 1.23 | 1.05 | 0.94 |
| 4m | 62.73 | 22.01 | 11.13 | 1.24 | 0.92 | 0.87 | 0.37 |
| 5m | 52.88 | 23.67 | 12.44 | 1.86 | 1.02 | 0.69 | 0.74 |
| Features | Window Mean | Shift Mean | ||
|---|---|---|---|---|
| corr. coef. | p-Value | corr. coef. | p-Value | |
| Duration in sec | 0.1172 | 0.5448 | 0.1294 | 0.5034 |
| Mean F0 | 0.1532 | 0.4276 | −0.1092 | 0.5728 |
| STD F0 | −0.1056 | 0.5856 | −0.374 | 0.0456 |
| SHR | 0.0256 | 0.8951 | −0.2287 | 0.2327 |
| Subharmonics pitch | −0.0805 | 0.678 | 0.0799 | 0.6803 |
| Local jitter | −0.1857 | 0.3348 | −0.6993 | 0 |
| Absolute jitter | −0.2534 | 0.1847 | −0.6352 | 0.0002 |
| RAP jitter | −0.1794 | 0.3517 | −0.6516 | 0.0001 |
| Local shimmer | −0.2875 | 0.1305 | −0.4762 | 0.009 |
| F1 mean | −0.0968 | 0.6175 | −0.0263 | 0.8923 |
| F2 mean | −0.0007 | 0.997 | 0.0291 | 0.8807 |
| F3 mean | 0.1708 | 0.3756 | 0.0914 | 0.6373 |
| F4 mean | 0.1763 | 0.3604 | 0.0103 | 0.9578 |
| Formant dispersion | 0.3078 | 0.1043 | 0.0365 | 0.8509 |
| Mean intensity | −0.0476 | 0.8063 | 0.4274 | 0.0207 |
| Speech rate | 0.1263 | 0.5138 | −0.309 | 0.1029 |
| SNR | 0.2536 | 0.1843 | 0.3175 | 0.0932 |
| LTAS mean | 0.1306 | 0.4996 | 0.5245 | 0.0035 |
| LTAS slope | 0.1232 | 0.5242 | 0.1859 | 0.3342 |
| LTAS std | −0.122 | 0.5284 | 0.2414 | 0.2071 |
| RMS energy | −0.0116 | 0.9524 | 0.3516 | 0.0614 |
| SCG | 0.5398 | 0.0025 | 0.3867 | 0.0382 |
| Spectrum std | 0.4291 | 0.0202 | 0.0634 | 0.7437 |
| Band Energy difference | 0.443 | 0.0161 | 0.4837 | 0.0078 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marini, M.; Vanello, N.; Fanucci, L. Optimising Speaker-Dependent Feature Extraction Parameters to Improve Automatic Speech Recognition Performance for People with Dysarthria. Sensors 2021, 21, 6460. https://doi.org/10.3390/s21196460
Marini M, Vanello N, Fanucci L. Optimising Speaker-Dependent Feature Extraction Parameters to Improve Automatic Speech Recognition Performance for People with Dysarthria. Sensors. 2021; 21(19):6460. https://doi.org/10.3390/s21196460
Chicago/Turabian StyleMarini, Marco, Nicola Vanello, and Luca Fanucci. 2021. "Optimising Speaker-Dependent Feature Extraction Parameters to Improve Automatic Speech Recognition Performance for People with Dysarthria" Sensors 21, no. 19: 6460. https://doi.org/10.3390/s21196460
APA StyleMarini, M., Vanello, N., & Fanucci, L. (2021). Optimising Speaker-Dependent Feature Extraction Parameters to Improve Automatic Speech Recognition Performance for People with Dysarthria. Sensors, 21(19), 6460. https://doi.org/10.3390/s21196460