1. Introduction
Superpixel segmentation is often used as an important preprocessing method for image algorithms in different research fields, such as the image segmentation [
1,
2] and object recognition [
3,
4]. The superpixel segmentation is used to improve the diagnostic accuracy of medical images and the fruit and road recognition in agricultural automatic systems. It can improve the accuracy and efficiency of computer vision algorithms. Since the superpixel is used for image preprocessing by Ren [
5], many well-known superpixel segmentation methods have been proposed by scholars. Color-based clustering is the most commonly used for superpixel segmentation, such as SLIC [
6,
7], LSC [
8], ERS [
9] and SEEK [
10]. The regular superpixels are segmented by the SLIC and LSC, and the irregular superpixels are produced by the ERS and SEEK. Although the irregular superpixels make the following image algorithms more easily, the boundary adherence is worse than the ERS and SEEK. Their methods work well if the color gradient changes clearly between the different scenes in an image. In addition, a large number of redundant superpixels are produced in the smoothly connected region by those methods.
For improving the performance of the above methods, the DBSCAN [
11,
12] has been optimized in the boundary adherence by irregular superpixels. The sizes of the irregular superpixels in the smoothly connected region are larger by using the SEEDS [
13] so that the redundant superpixels are reduced. Even though the methods are optimized, the redundant superpixels are abundant in superpixel images. Moreover, many useless boundaries, which cannot describe the primary texture and contour features are extracted.
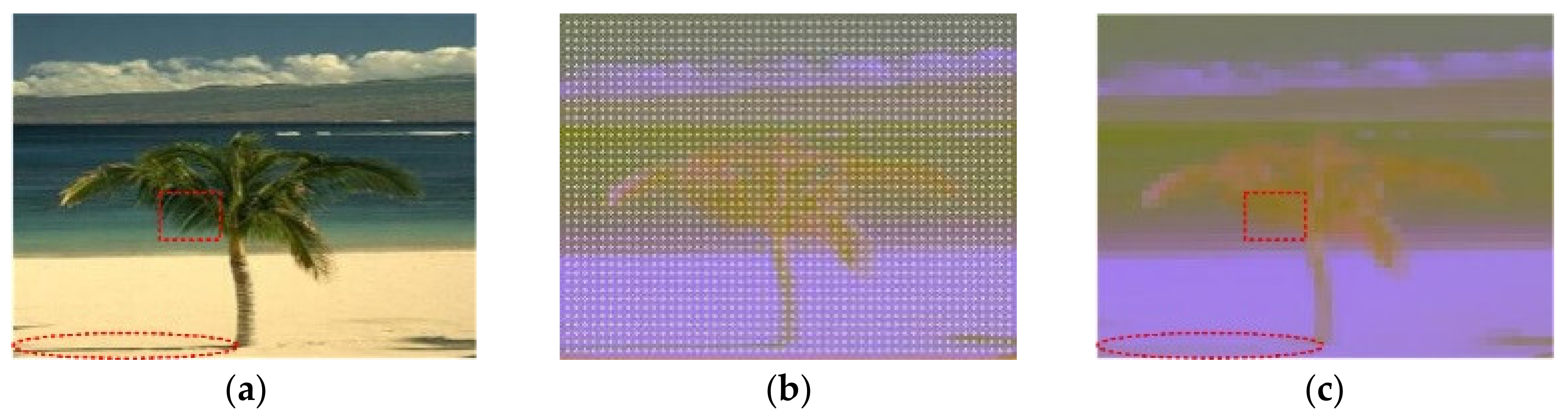
According to the superpixel boundary and shape, there are two main segmentation results as
Figure 1 shows. (1) The superpixel shapes are more regular and evenly distributed in
Figure 1a–d [
11], but the superpixel boundaries cannot describe the texture and contour features well. (2) The boundary adherence in
Figure 1e,f [
9,
13] are generally better than
Figure 1a–d, but the boundaries and shapes are complex and very irregular. In addition, lots of redundant superpixels are produced by all of these methods.
Currently, since the superpixel segmentation is used as a preprocessing step in image processing, the classical and state-of-the-art superpixel methods focus primarily on how to improve the boundaries adherence and less on computation. Therefore, the over-segmentation and redundant superpixels in the smoothly connected region are often ignored. As a result, the complex and useless secondary texture and contour features in the image are extracted by superpixel boundaries. Those boundaries will increase the complexity and difficulty of image processing, such as image segmentation and image recognition.
This paper will focus on the superpixel segmentation whose superpixels can not only reduce the superpixel redundancy in the smoothly connected region, but the complex and useless background textures in an image can also be filtered so that the primary textures and contours of the salient objects can be extracted better. In order to meet the above requirements and successfully execute the described superpixel segmentation method, this paper is organized as follows.
First of all, the image is preprocessed, and the grid feature points are extracted. On this basis, the densities of all points are defined with color features in
Section 2.
Section 3 describes the superpixel segmentation method in detail. In
Section 4, the superpixel segmentation experiments are carried out with the Berkeley database BSDS500. The effectiveness and superiority of the proposed method will be discussed in
Section 5. Finally,
Section 6 concludes the study.
3. Superpixel Segmentation with Density Peak-Based Clustering
In this section, there are two rules about the color and brightness features for the superpixel segmentation method.
(1) The more similar the color and brightness features between two points, the more similar the densities of them. In this case, the two feature points are easier to be segmented into the same superpixel.
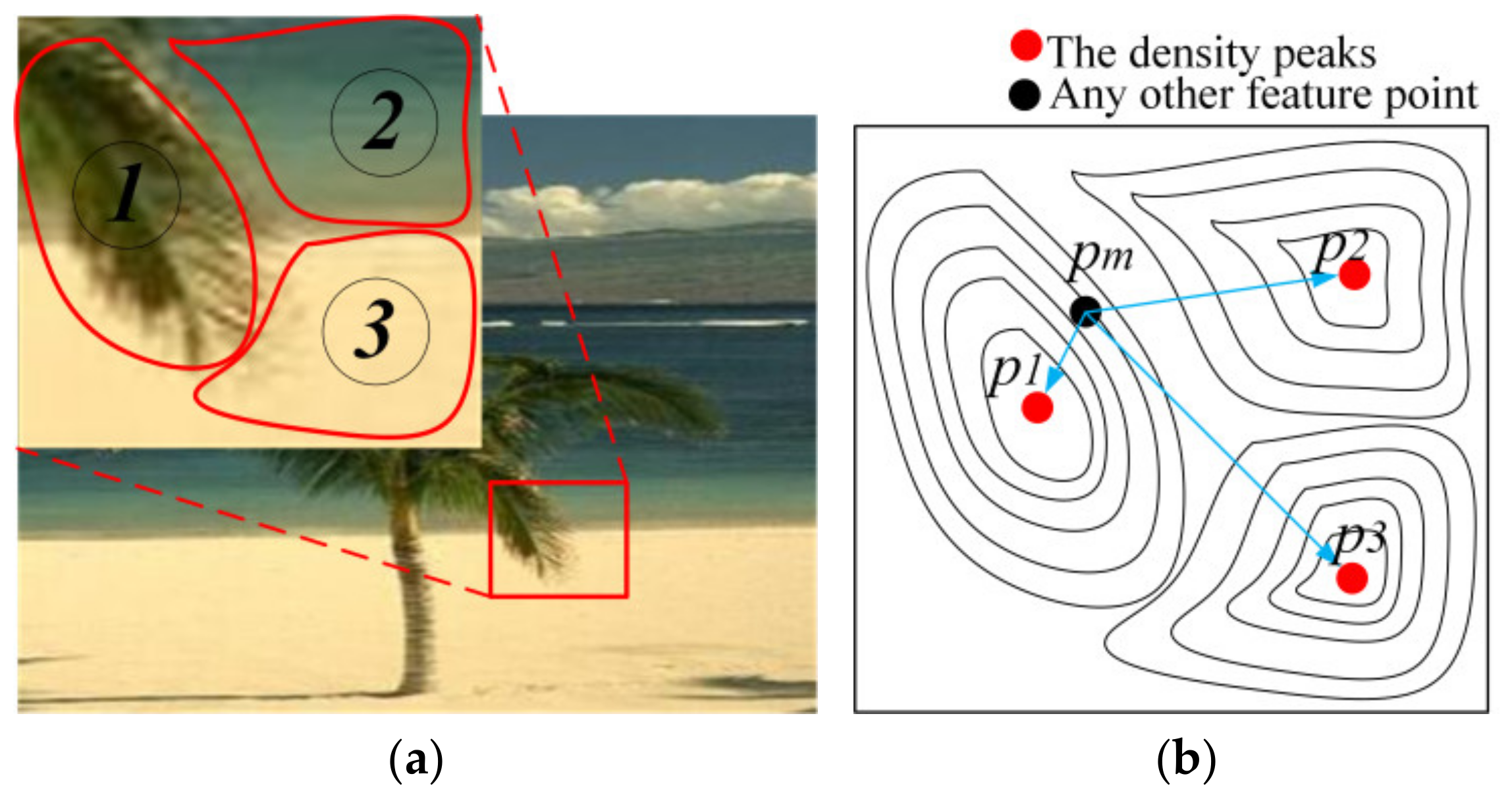
(2) If the color and brightness features are all different among the neighborhood points, they will be segmented into different superpixels even if the densities of them are similar. For example, as
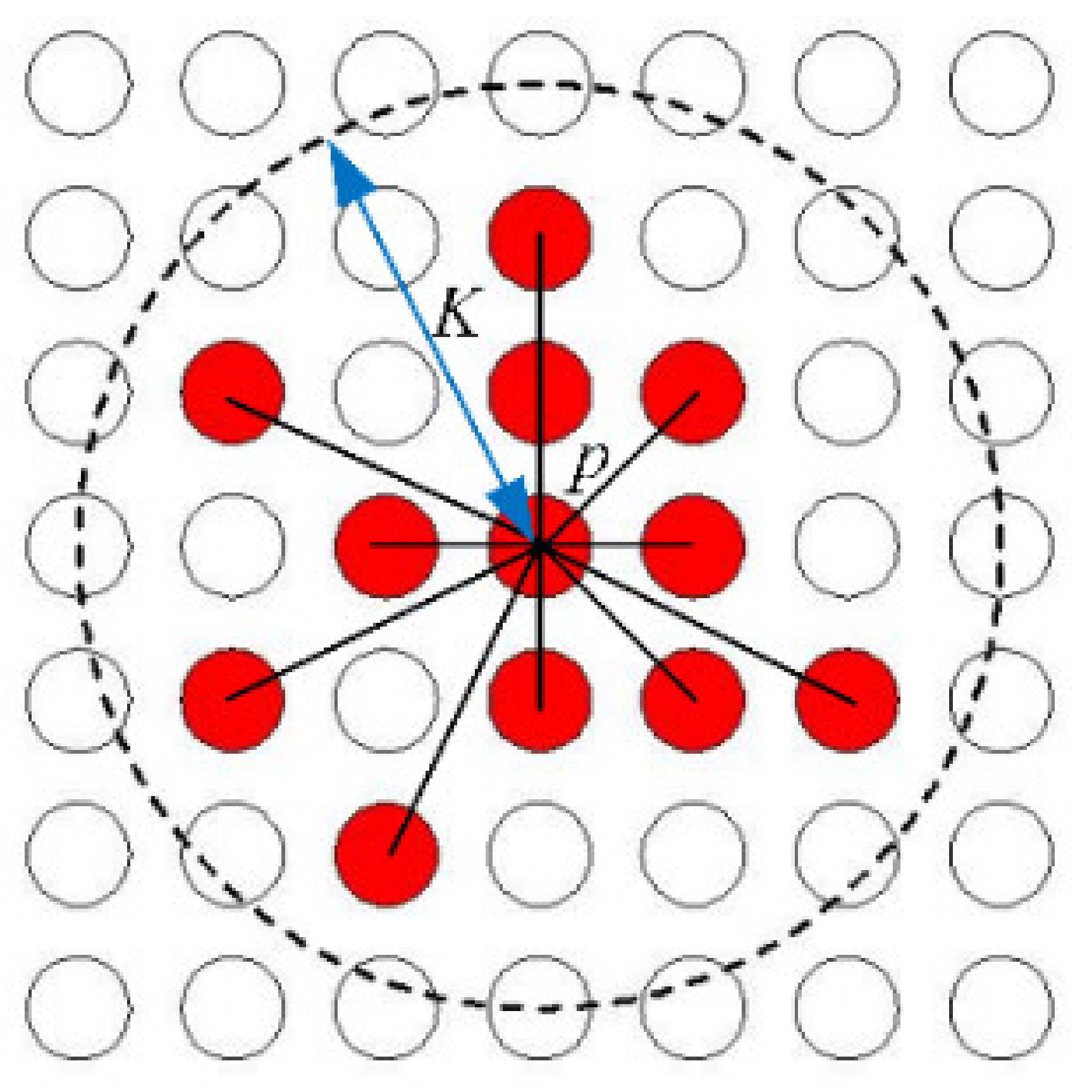
Figure 4a shows, the regions of the foliage, the sea and the beach have obvious differences in color and brightness features, so that the three regions would be probability segmented into three superpixels, which are marked by ①, ② and ③.
There must be at least one feature point whose density is higher than the neighborhood points; for example, the red points in
Figure 4b are defined as density peaks in this paper. The density peaks will be probability defined as the cluster center. According to the densities, the other points could be distributed among the density peaks, and they can be described as the contour maps. For example,
pm is one of many other feature points, and if the density of
pm is close to
p1 and the distance between them is also closed, the point
pm and
p1 will be segmented in the same superpixel with high probability.
First of all, the densities of all the feature points must be calculated by the Formulas (6) and (7), and the results are stored in a data set {ρm | 0 ≤ m ≤ N}, m is the sequence number of the points and N is the total number of the feature points. According to the densities, all the points are sorted in descending order. {om | 0 ≤ m ≤ N} is the result after rearrangement and om is the feature point. Dmn is the distance between any two points om and on. Dmn can be calculated by the Formula (7).
In order to cluster the points, the membership grade between any two points must be obtained. The membership grade parameter
δm can be obtained by Formula (8).
If m > 0 and n < m, δm is the minimum distance between om and on. Actually, δm means the probability that om and on are in the same cluster or not. If m = 0, δ0 is the maximum of all δ. The parameters δm and ρm are used to extract cluster centers. If δm and ρm both are relatively large, it means that the point om would be a density peak and it will be defined as the cluster center with great probability. If m = 0, o0 must be a cluster center.
To determine whether the point
om is a cluster center or not, the
δm and
ρm should first be normalized, and the values fall within the range of [0, 1]. The normalization formulas are shown as follows.
Ρ′ and
δ′ are the normalized parameters,
ρmax and
ρmin are the maximum and minimum values of
ρ,
δmax and
δmax are the maximum and minimum values of
δ. In order to analyze how to extract the cluster center,
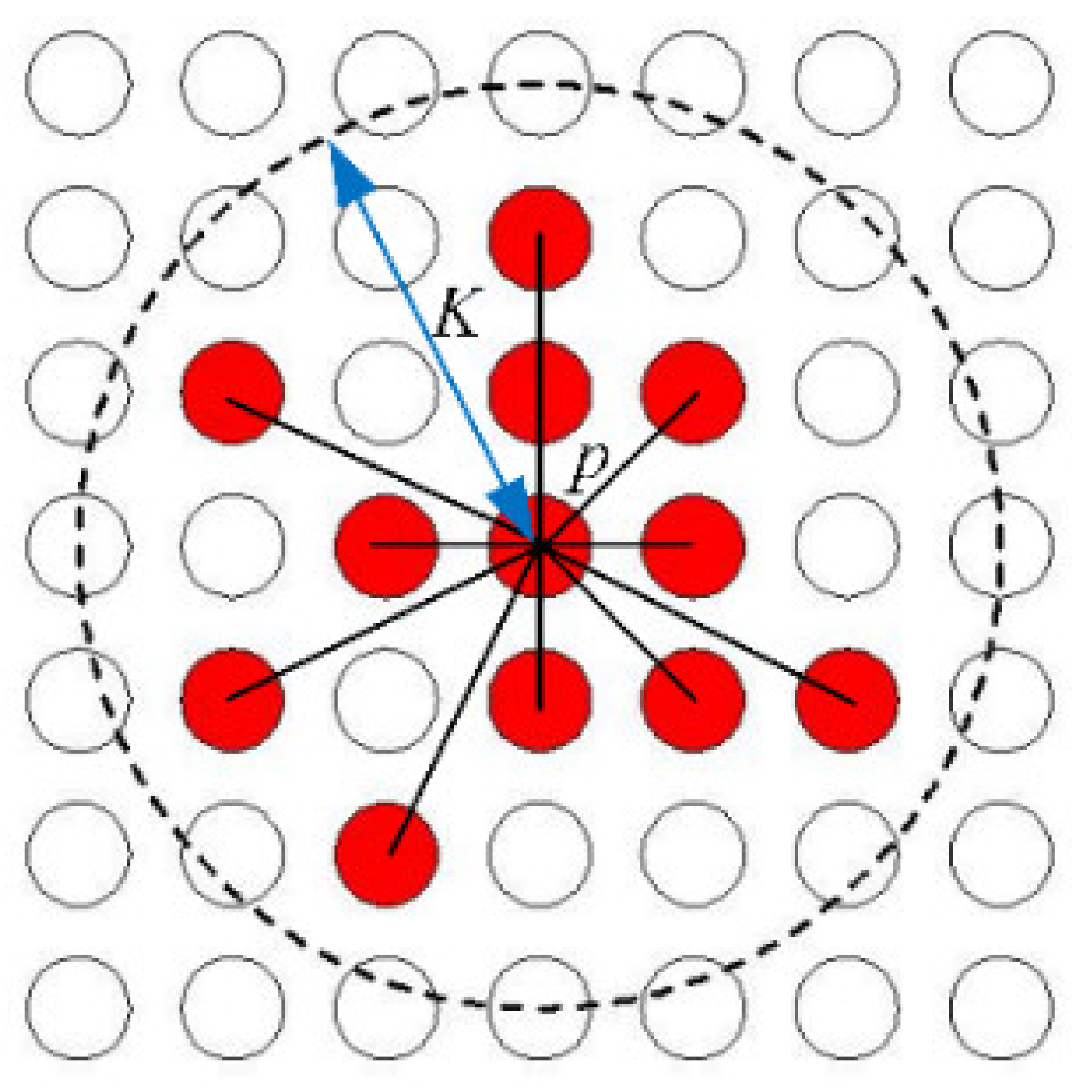
Figure 2 is used as an example. The neighborhood parameter
K and the threshold parameter
ψ are assigned firstly, with
K = 1.3
R and
ψ = 13 as an example. Then the
ρ′–
δ′ coordinate system will show the distribution of all the feature points in
Figure 5.
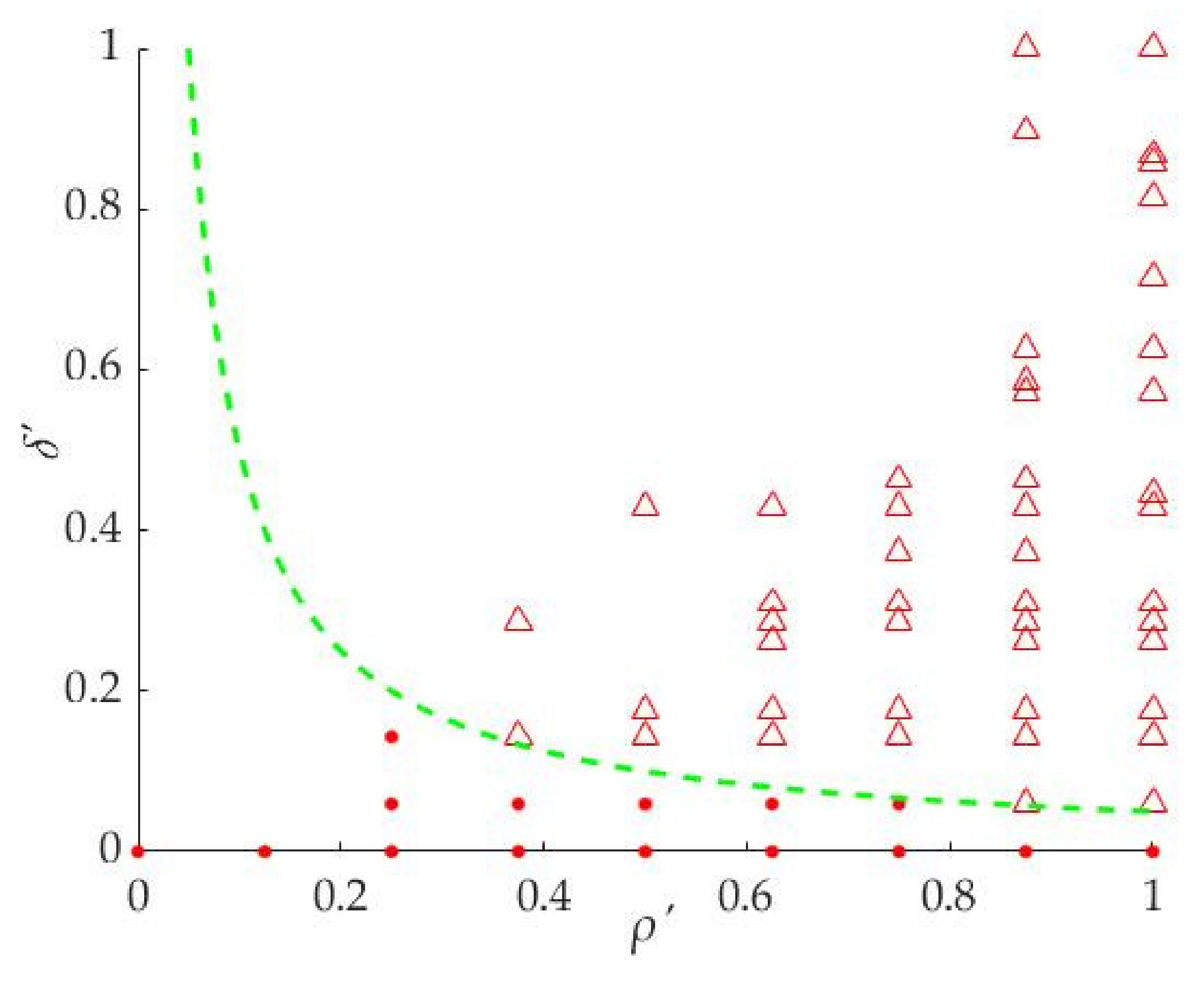
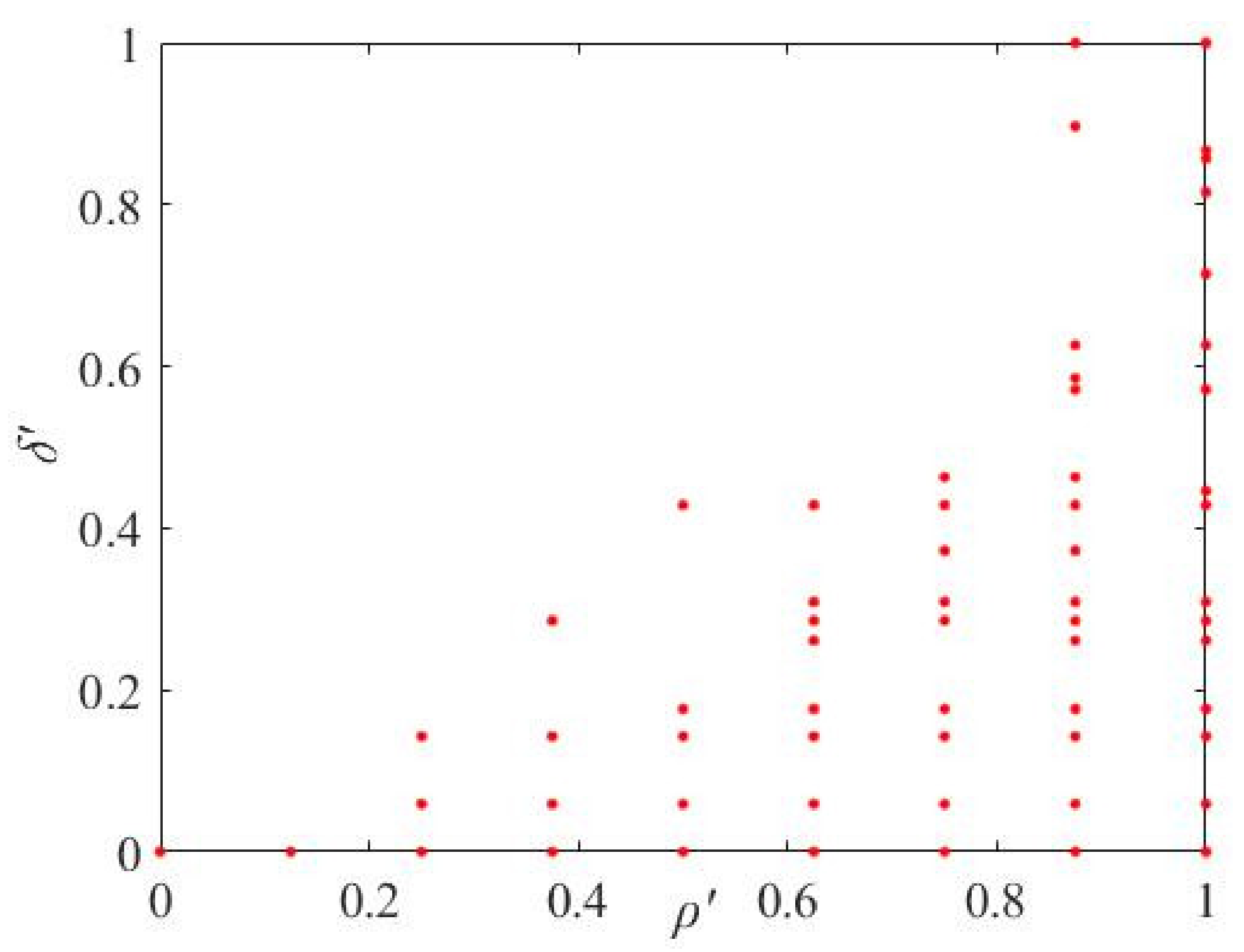
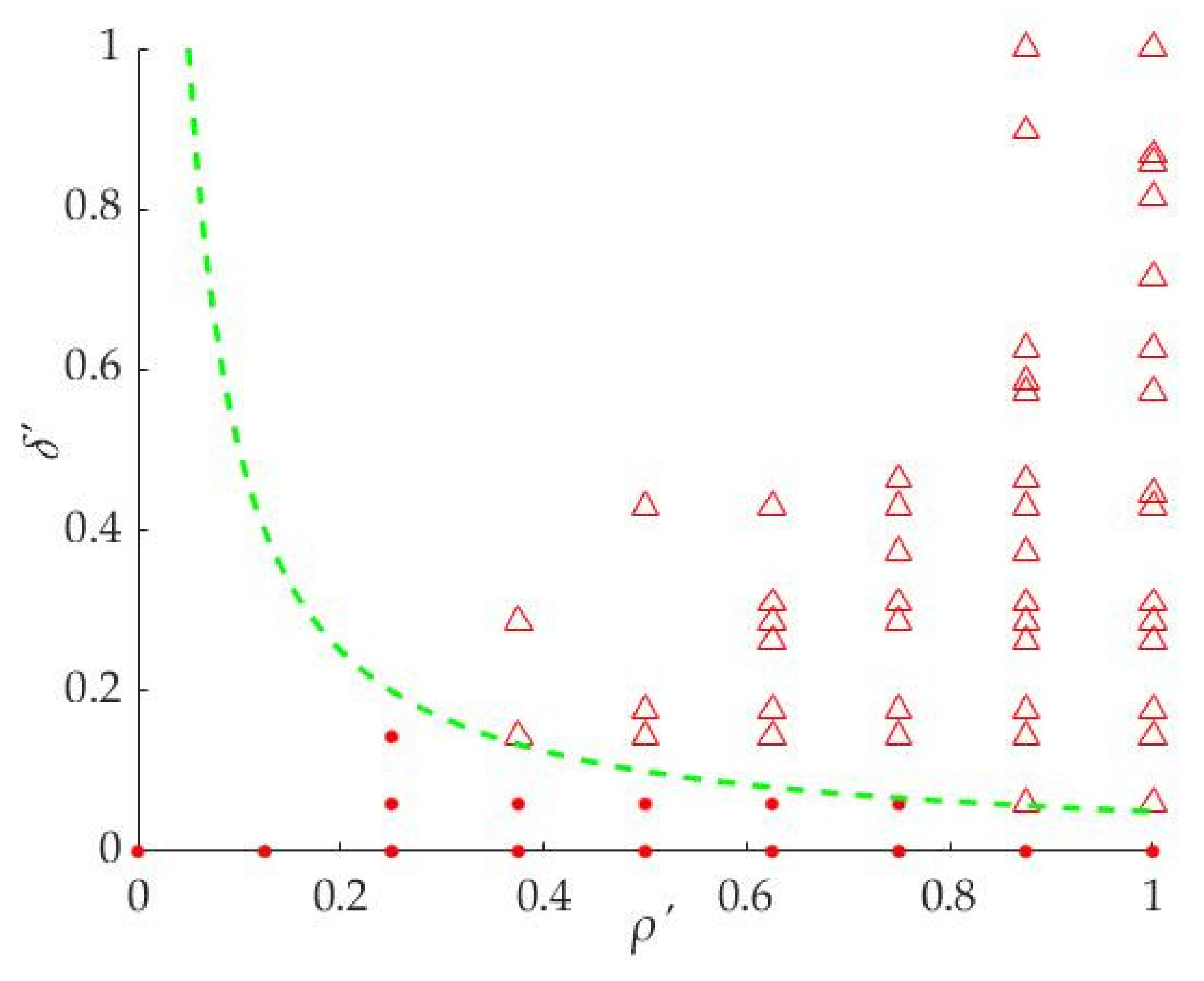
It can be seen from
Figure 5 that the larger the
ρ′ and
δ′ of the points are, the more likely it is that the points are distributed in the upper right part of the coordinate system. In other words, the points in the upper right part are the candidates for cluster centers. For extracting the cluster centers from the points, the following two Equations (10) or (11) are used to determine which ones are the cluster centers in this paper.
The Equation (10) is an inverse function and its function curve divides the points into two parts, the upper right part and the lower left part. We take
a = 0.005 as an example for analysis in this section. The points ‘Δ’ will be the cluster centers as shown in
Figure 6 and the set of the cluster centers is
CM, and M is the total number of cluster centers. In this step, the curve of the function can be changed by the parameter
a, so that the different cluster centers can be extracted to meet the requirement of the superpixel segmentation algorithm. The method can extract the cluster centers well, but it is difficult to predict the number of the cluster centers.
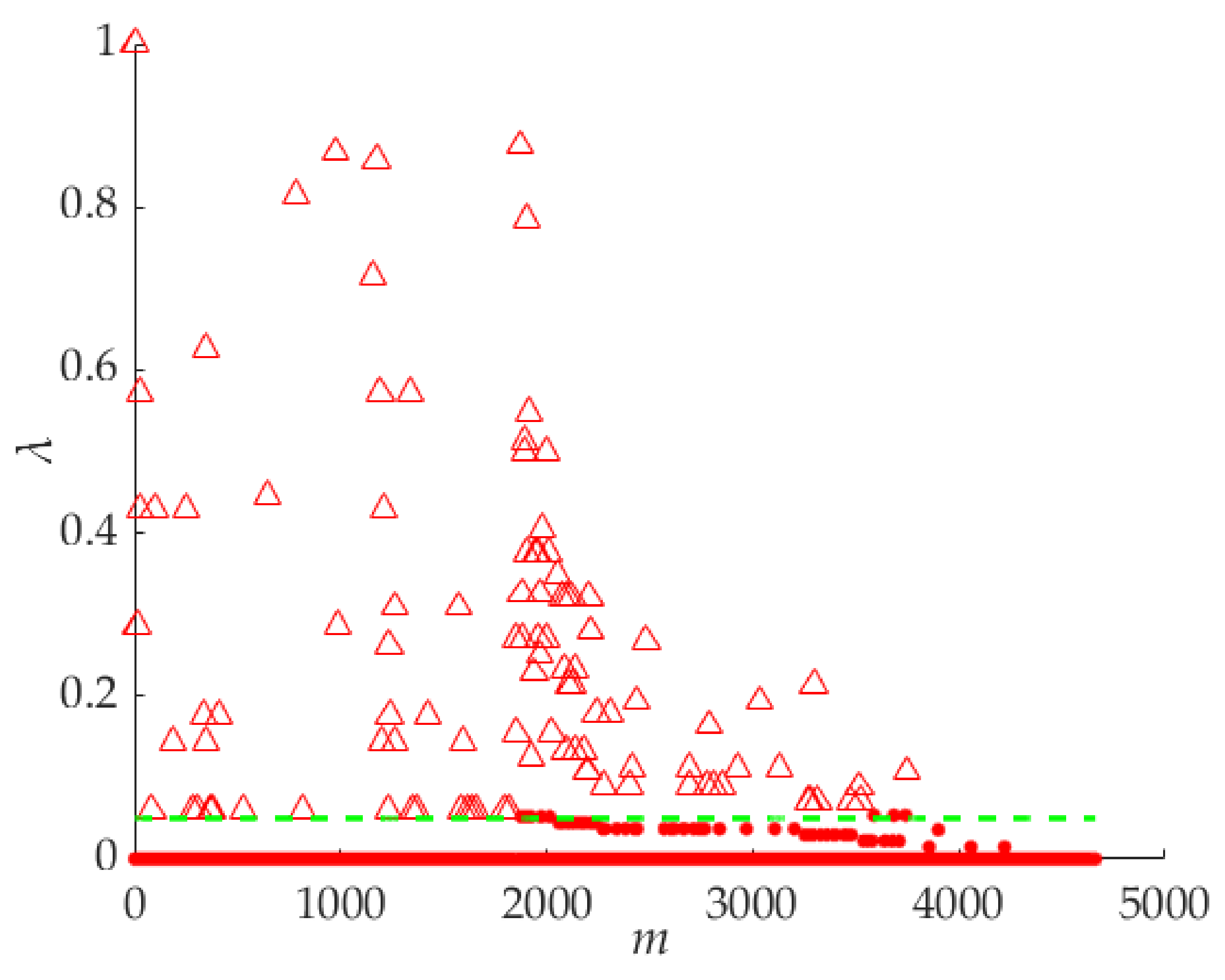
The parameter
λ in Equation (11) is a comprehensive parameter of the
ρ′ and
δ′. The greater the value of
λ, the greater the probability that the points are the cluster centers. All the points are shown in the
m–
λ coordinate system in
Figure 7. The values of the
m-axis are the serial number of all the points. We take
λ = 0.005, for example, and the points on the upside of the function curve are the cluster centers.
Sometimes the number of the cluster centers must be obtained before superpixel segmentation. For producing a specified number of cluster centers, the parameter λ will be sorted in descending order λ0 > λ1 > λ2 > … > λm > … > λN−1 > λN. N is the total number of the feature points, m is the serial number of the feature points. If the specified number is M, the points whose λm are meet the condition {λm | 0 ≤ m ≤ M} will be the cluster centers, and the number of the cluster centers is M.
After obtaining the cluster centers, the other points om would be clustered to one of them. According to the Formula (8), if δm = Dmn, it means that the points om and on would be in the same cluster, and they will be expressed by om→on in this paper. According to whether on is a cluster center or not, there are two cases about how to cluster the point om.
Case 1, if on is a cluster center, om will be a member of the cluster which include the on;
Case 2, if on is not a clustered center, iterative and recurrence such as om→on, on→oh, oh→oi, oi→oj, …, until the cluster center is found. In this case, it is easy to deduce that om→oj, and if the point oj is a cluster center, the point om will be a member of the cluster in which the oj is cluster center.
According to the above method, all the points
om would be clustered, and the ensemble of the clusters are represented by the set
S. The key steps of the clustering method are given as follows. Algorithm 1 [
15] The key steps of the Density Peak-Based Clustering.
| Algorithm 1. Density Peak-Based Clustering |
Input: The set of the feature points On;
The set of the parameters δn;
The set of the parameters λn; |
| Output: Ensemble of clusters S; |
1: Extracting the set of cluster centers from the feature points On with the help of the parameters δn or λn.
The set of the cluster center is CM; |
2: for each i∈[0, N] do
3: Iterative and recurrence formulas oi→oh, oh→oj, …, ok→oc,until the cluster center oc is found;
4: oi→oc; |
| 5: end for |
| 6: for each i∈[0,M] do |
| 7: for each j∈[0, N] do |
| 8: if the point oj meet the condition oj→ci is true then |
| 9: Si= Si∪oj; |
| 10: end if |
| 11: end for |
| 12: end for |
| 13: return S; |
4. Superpixel Segmentation Experiment Results
The clusters in
Section 3 are actually the pixel blocks, and they are used for superpixel segmentation. The image in
Figure 2a is used as an example for the superpixel segmentation experiment. According to the method in
Section 3, the initial value should be assigned to the parameters
R,
K,
ψ and
a; for example, if
R = 6,
K = 1.3R,
ψ = 13 and
a = 0.005. The results of the cluster are shown in
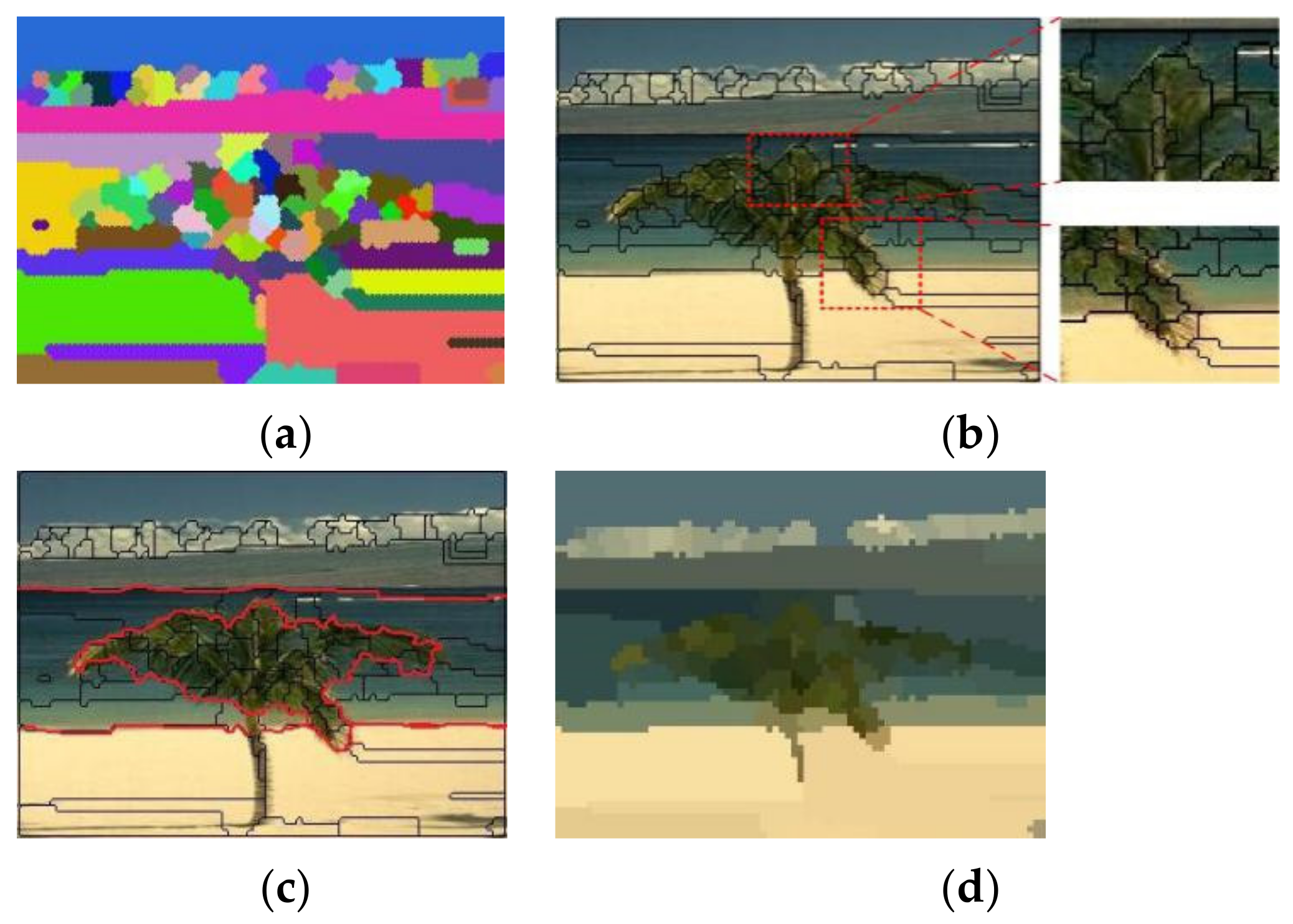
Figure 8a with the color blocks. Actually, the blocks are the superpixels.
Figure 8b shows the boundaries of the superpixels, and the primary textures and contours of the objects are drawn very well by the boundaries. In addition, the skyline, the shoreline and the outline of the tree can be drawn with the red lines that are drawn by concatenation of superpixel boundaries in
Figure 8c. The image can be segmented into four regions by the red lines representing the beach, the sea, the sky and the tree.
Figure 8d is a superpixel image, and it is clear that the image can not only draw the salient objects well, such as the beach, the sea, the sky and the tree, but can also reduce the redundant complex textures of the image, such as the spiculate margin of the leaves.
It is easy to conclude that the results of superpixel segmentation mainly depend on these parameters R, K, ψ, a and λ. Generally, if there is a good segmentation result with a set of parameter values such as K = 1.3R, ψ = 13, a = 0.005, λ = 0.005, the different superpixel segmentation results can be obtained by changing the value of the parameter R without other parameters changed.
In order to analyze the superpixel segmentation results with the proposed method, the Berkeley database BSDS500 is used in this paper, and the sample images are resized to 320 × 240. The experiments are performed when
R = 4, 6, 8 and 10, respectively. The superpixel segmentation results are shown in
Figure 9. It can be seen from the segmentation results that the smaller the
R is, the better the boundaries adherence is, and the clearer the textures and boundaries of the objects. It can be found that regardless of the value of
R, the superpixels can depict the salient objects every well, such as the eagle, starfish, flowers and people. (The method was tested on a computer with an Intel i5 @ 2.5 GHz processor with 4 GB RAM).
The texture complexity of different images is often different, so that the number and the size of superpixels are different from one image to another. As
Figure 9a shows, the textures and contours of the building, bird and branches are relatively simple, and there are large smoothly connected homogenous regions, so that the satisfactory segmentation results can be obtained with fewer and larger superpixels. However, in
Figure 9b, more and smaller superpixels must be segmented to extract the complex textures and contours of the mountain, people, starfish and flowers. Experiments showed that small and larger value of the parameter
R can be taken in
Figure 9a,b respectively. Therefore, the appropriate values of the parameter
R can be taken for producing satisfactory superpixels according to the texture complexity. Furthermore, even if the value of the parameter R remains the same, the numbers and the sizes of the superpixels are always different so that the segmentation method can adapt to the different images. The segmentation results clearly show that the method can not only reduce the redundant superpixels in smoothly connected homogenous regions, but the textures and contours of the salient objects in the image can also be depicted very well by the superpixel boundaries. In addition, the contours between different objects in the image are extracted well by the boundaries. The boundary recalls of the salient objects are shown in
Table 1.
It can be seen from
Table 1 that the smaller value of the parameter
R, the better Boundary Recall, and that means the better boundary adherence. Otherwise, there is not much difference in Boundary Recall in the superpixel segmentation in different images with the same value of the parameter
R. This means that the method could work well whether the texture features are simple or complex in different images. Therefore, it is further proved that the proposed method has good adjustability.
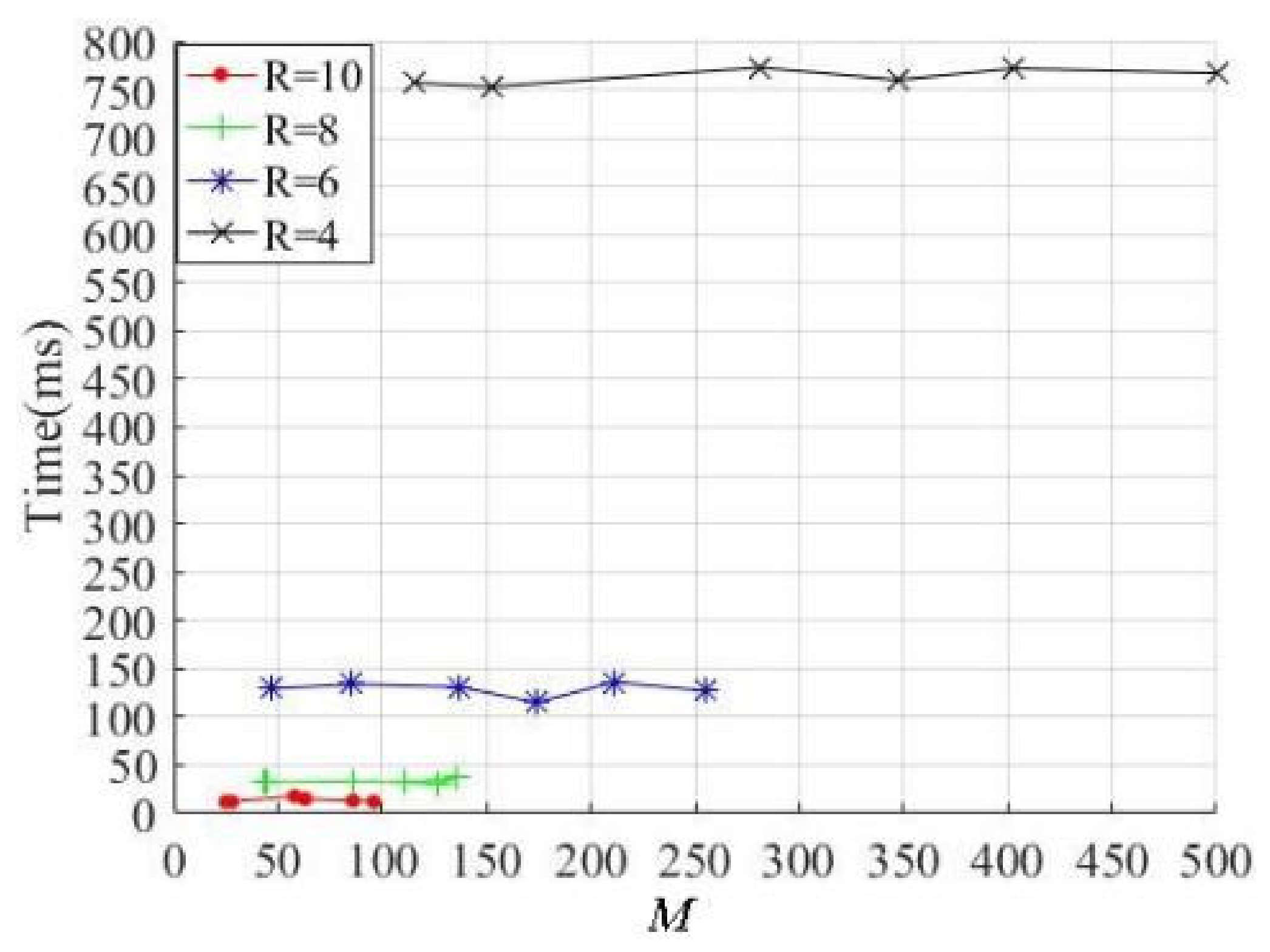
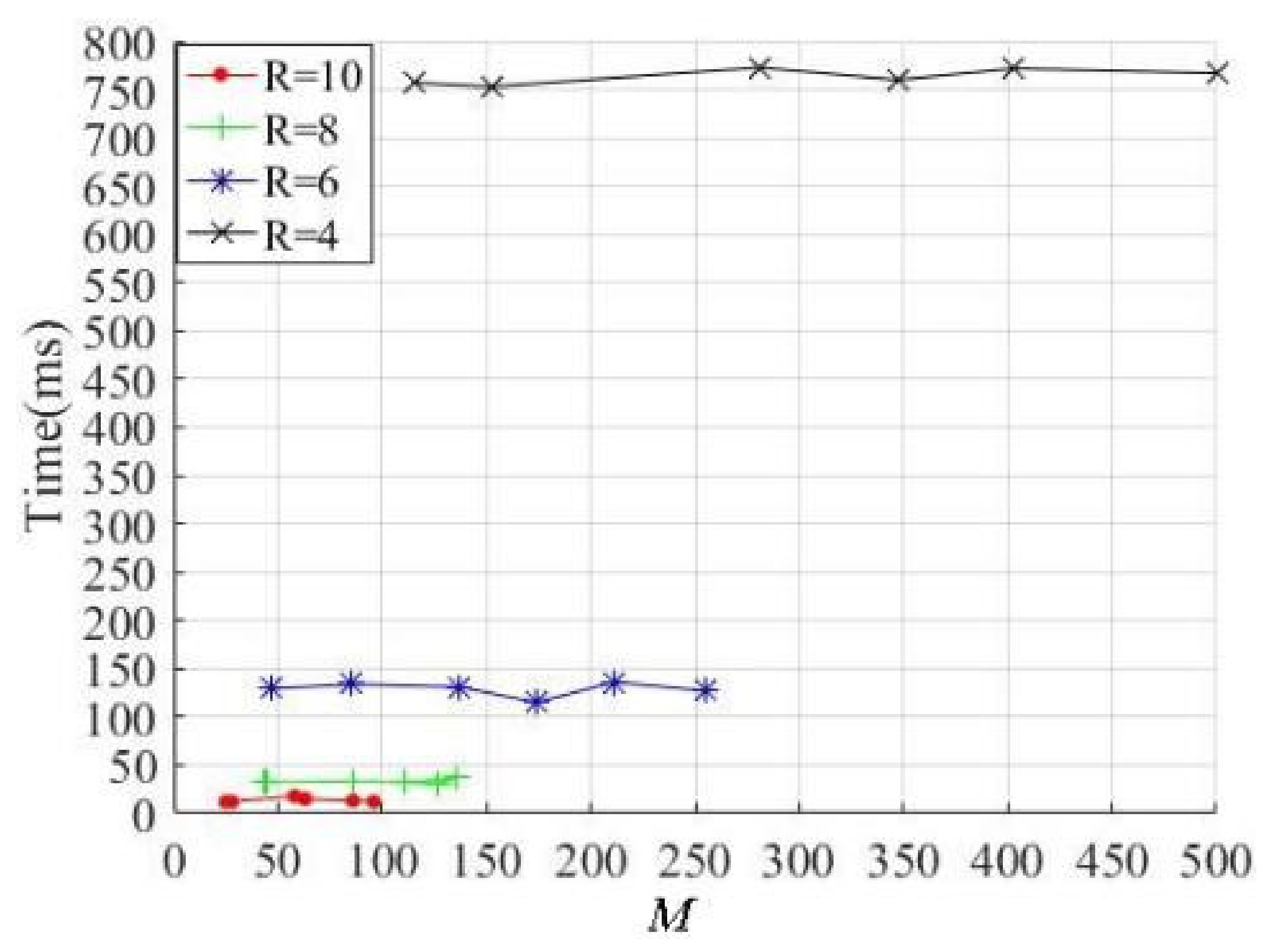
In the process of superpixel segmentation, the algorithm efficiency must be considered. The relationship between the superpixel number
M and the segmentation efficiency are shown in
Figure 10.
Figure 10 shows that the efficiencies are determined with the parameters
R = 4, 6, 8 and 10, respectively. Obviously, the larger the parameter values, the more efficient the method. Although the superpixel numbers increase with the increase in texture complexity, the efficiency is almost constant when the value of the parameter
R remains unchanged. Therefore, it can be concluded that the method efficiency mainly depends on the parameter
R, and it is almost independent of the number of superpixels. The segmentation results in
Figure 9 show that if the
R = 8 and 10, the primary texture and contour features of the salient objects in an image can be extracted well, and the average times are 13.8 ms and 33.2 ms, respectively. This means that the proposed method has good efficiency under the condition that the segmentation results are satisfactory.
5. Discussion
According to the shape and size of the superpixels, the superpixel methods can be divided into two cases. For example, the typical and well-known methods, such as the Lattice, ERS, SLIC and LSC, could produce regular superpixels. The irregular superpixels with sawtooth boundaries would be obtained by methods such as SEEDS, EneOpt1, quick shift and ERS. The segmentation results of them [
8,
16] are shown in
Figure 11a–h. The number of the superpixels in the upper left and lower right parts in image are approximately 400 and 200, respectively. In order to obtain the similar segmentation results, we take
R = 4 and 8 for segmentation, and the results of the proposed method are shown in
Figure 11i. The numbers of superpixels are
M = 162 and
M = 66 in the upper left and lower right parts.
Generally, the primary textures and contours of the image are the features that we care about in superpixel segmentation. Those are benefits to improve the accuracy of image segmentation and object recognition. According to the comparison results, although the more regular superpixels can be obtained in
Figure 11a–d and they can help to reduce the complexity of the image recognition methods, a large number of redundant superpixels are produced in the smoothly connected homogenous regions. The texture and contour features are extracted very well, and the boundaries have good adhesion in
Figure 11e–h. That will help for extracting the target objects in the image more accurately. However, not only are most of the secondary textures extracted, which does not help with object recognition, but the extremely irregular and redundant superpixels are also produced in the smoothly connected homogenous regions. Normally, that will improve the complexity and reduce the efficiency of the image recognition algorithm. Compared to
Figure 11a–h, the smoothly connected homogenous regions are segmented by fewer superpixels, and the superpixels are sketched by fewer jagged boundaries in
Figure 11i. In addition, the primary textures and contours of the salient objects in the image can be extracted accurately by the proposed method. In comparison with the other methods, the proposed method can greatly reduce the redundant superpixels, and that could improve the efficiency of the superpixel algorithm.
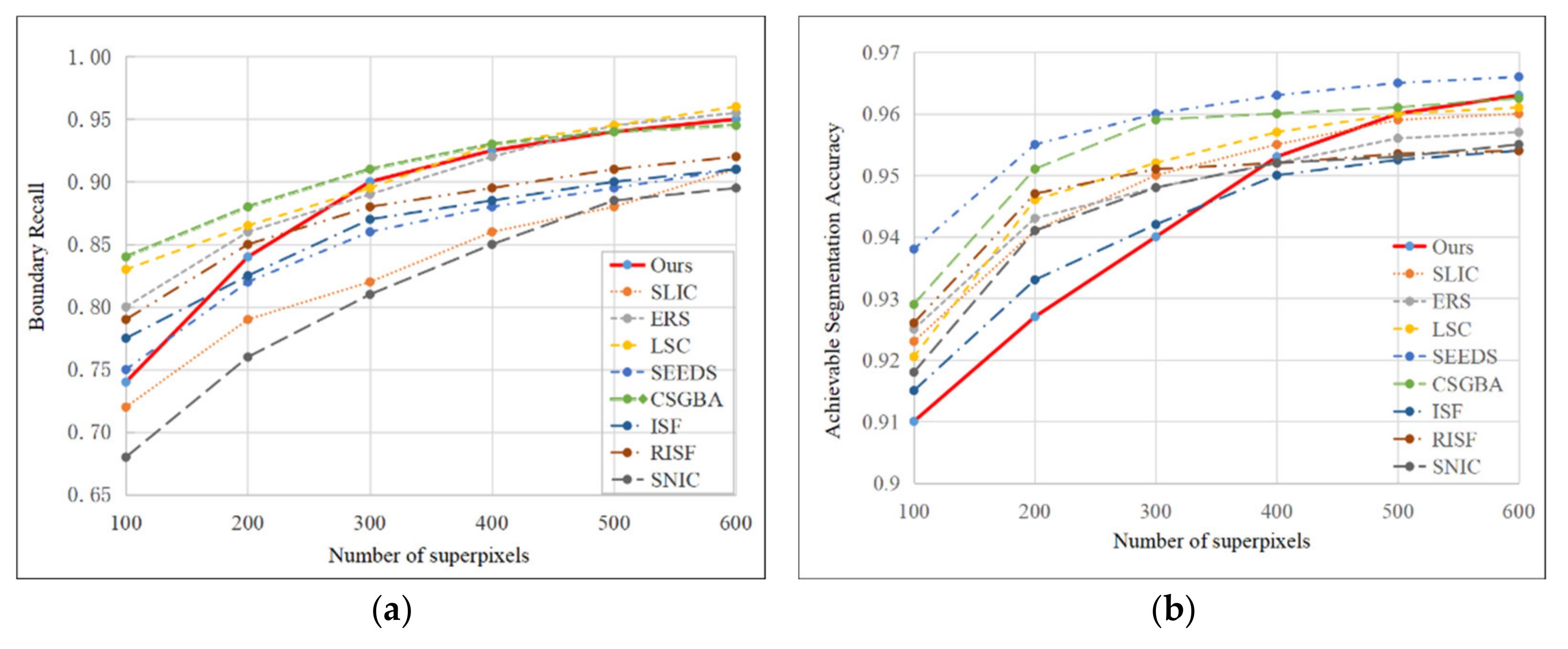
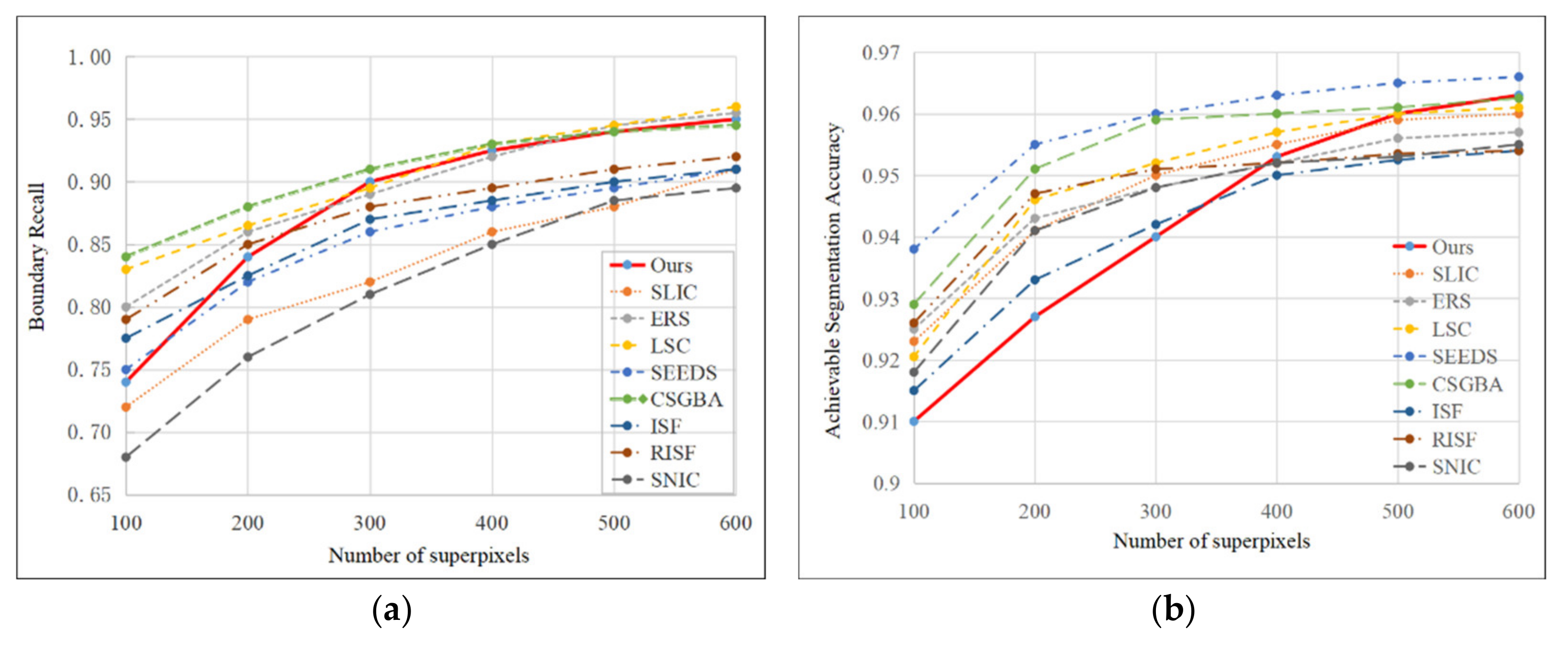
Moreover, with the decrease in R and the increase in the number of superpixels, the superpixel boundaries will become smoother, and the boundary adherence will be better as well. In order to analyze the effectiveness of the proposed method, the Boundary Recall (BR) and Achievement Segmentation Accuracy (ASA) of ours and the state-of-the-art superpixel segmentation methods are shown in
Figure 12.
A comparison of each superpixel segmentation method is proposed in
Figure 12. It is clear that the BR and ASA of the proposed method have good results. Specifically, the BR can achieve satisfactory results with a smaller number of superpixels (
M = 300), and it is more than 90%. That is better than most of the classical and the state-of-the-art superpixel segmentation methods and it is 95.0% when
M = 600. If the number of superpixels is too small, the results of the ASA are inferior to other methods. However, as the number M increases, the results of the ASA improve quickly. The ASA is 96.3% when
M = 600, and it is better than most of the methods.
It is well-known that the efficiency of a superpixel method is very important for real-time image processing. The segmentation results in
Figure 9 and
Figure 11 show that the primary texture and contour features of the salient objects in the image can be extracted well by the superpixels, in which the parameter
R = 8. In addition, the superpixel boundaries have good adhesion to the textures and contours. Therefore, the efficiency of the proposed method would be analyzed by
R = 8. To be clearer, the numeric values of the metrics are listed when the number of superpixels
M ≈ 400. The computational time and BR of the segmentation methods are summarized, and they are shown in
Table 2.
It can be seen from
Table 2 that the efficiency of the proposed method is superior to the classical and state-of-the-art methods. The speed of the superpixel segmentation is nearly 30 fps, and it indicates that the method has better real-time performance. Moreover, the BR is 92.5% with the same condition, and it is better than most of the classical and state-of-the-art methods. This means that the proposed method has good comprehensive performance both in efficiency and accuracy.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}