
Dual Optical Path Based Adaptive Compressive Sensing Imaging System


Abstract
:1. Introduction
- (1)
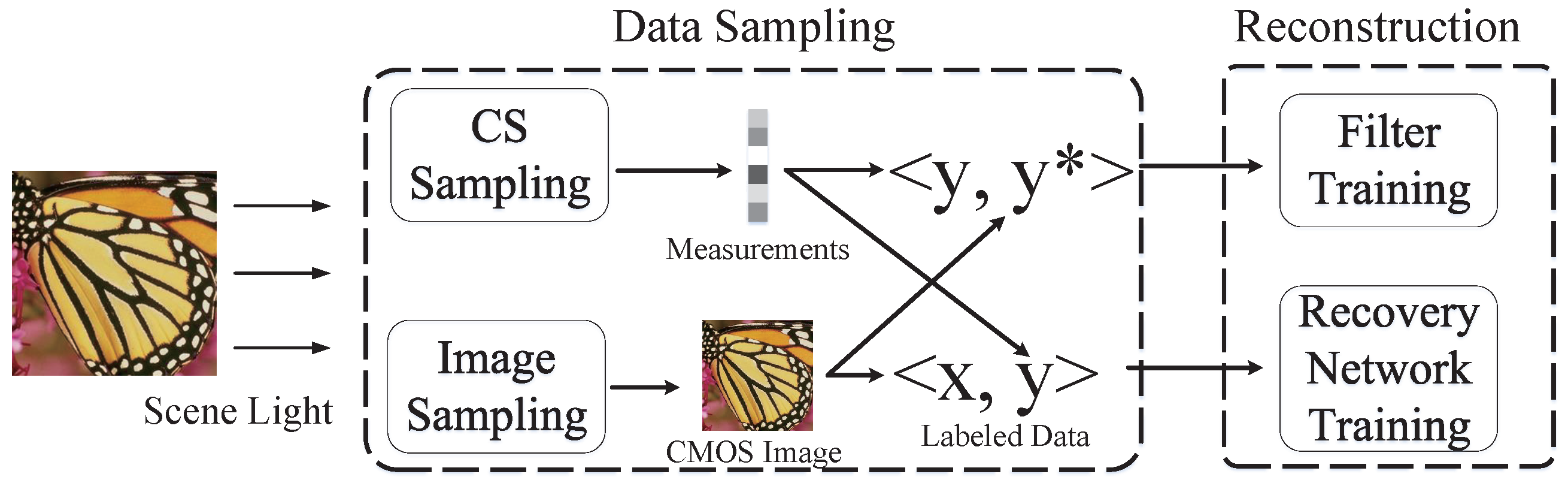
- Aiming at the problem that deep learning data cannot be labeled in the actual CS sampling, a dual light path acquisition and labeling method is proposed, and this method is used to obtain the data required for network training;
- (2)
- A filtering method for a CS imaging system based on deep learning is proposed. At the same time, a reconstruction network is constructed on the basis of this filtering method to better reconstruct CS measurement data;
- (3)
- A CS imaging system is established to adaptively filter the noise created by the hardware, which can significantly improve the imaging quality so that the CS imaging device can be better applied to image acquisition.
2. Basic Concepts and Related Work
2.1. Compressive Sensing
2.2. Imaging System
3. Adaptive Compressive Sensing Imaging System
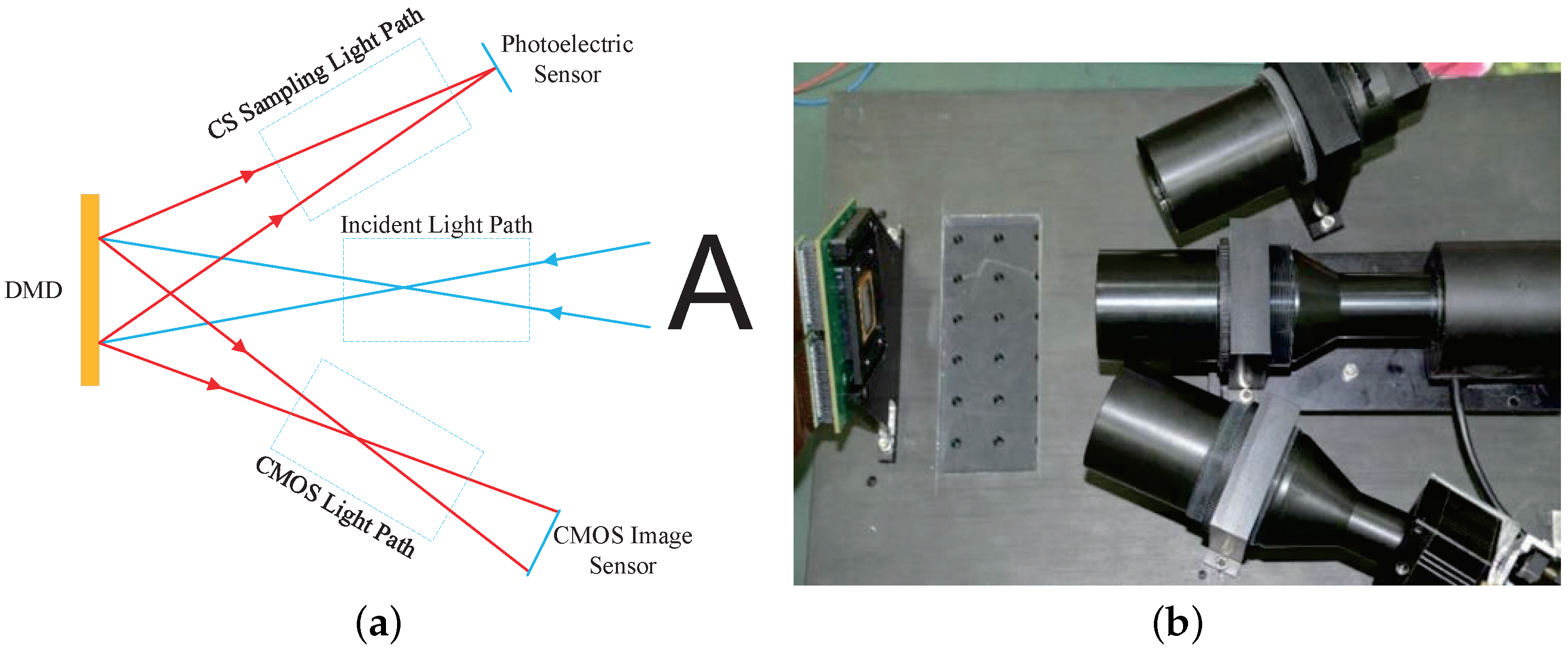
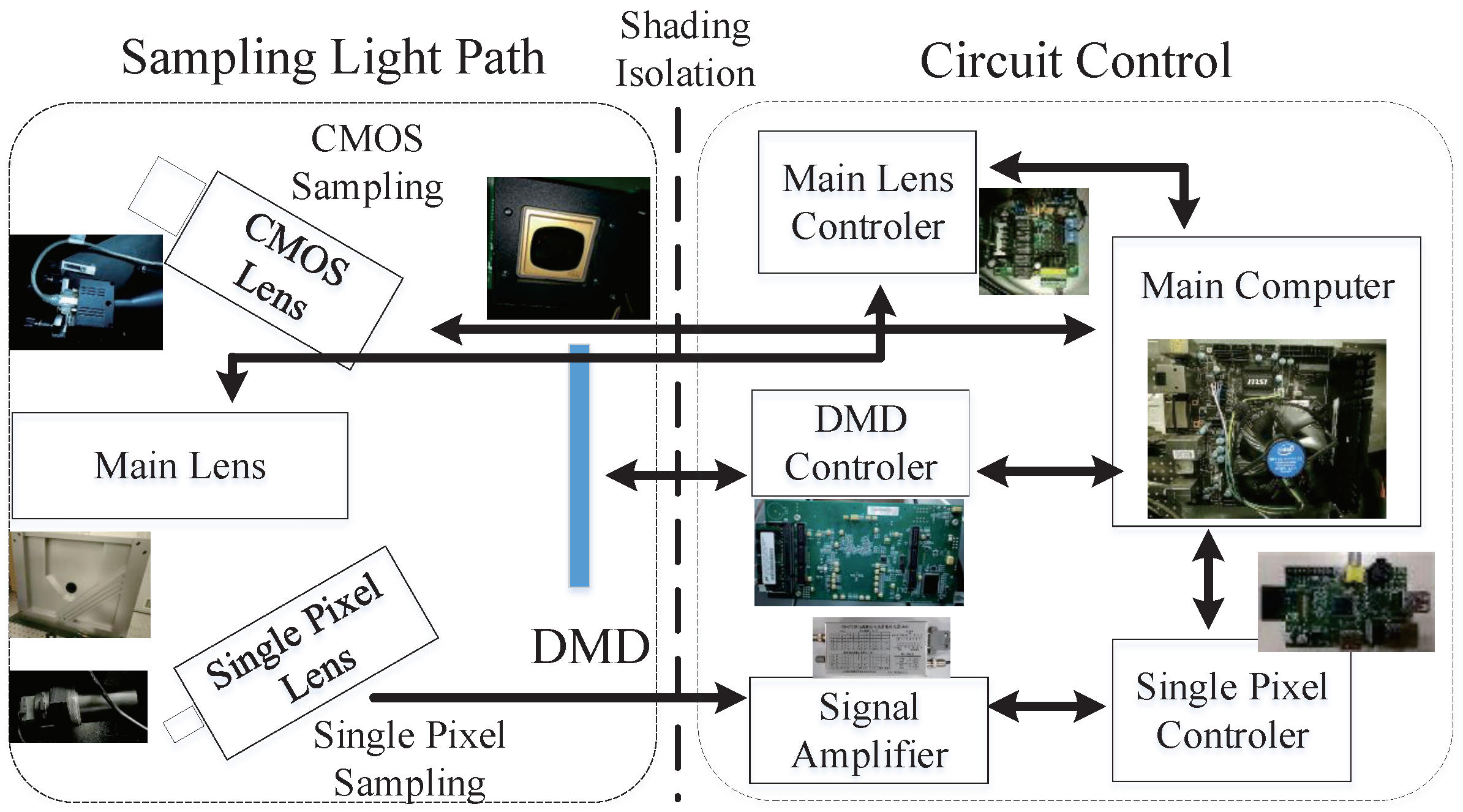
3.1. Dual Optical Path Sampling
3.2. Recovery Network
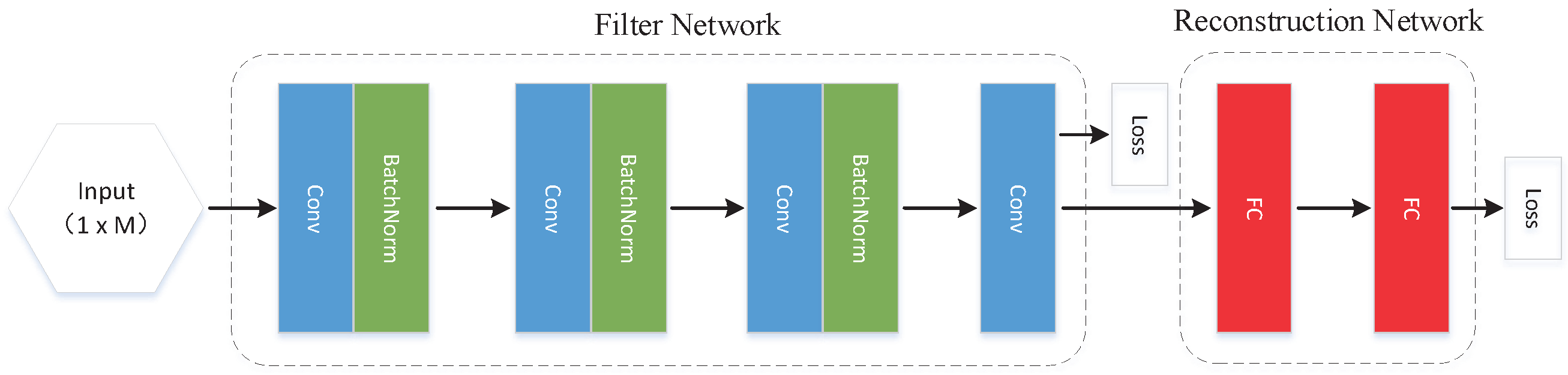
3.2.1. Filter Network
3.2.2. Reconstruction Network
3.2.3. Training
Filter Network Training
Reconstruction Network Training
Joint Training
4. Experimental Results
4.1. Comparison with Existing Methods
- It can be seen from the average value in Table 1 that our method achieves the best reconstruction performance. Our method achieves the best PSNR and SSIM under all the four measurement rates; especially at high sampling rates, the PSNR and SSIM are much higher;
- Observing the results, we can find that the result of the D-AMP algorithm is the second best, and it is obviously better than the other two algorithms. The main reason is that the D-AMP algorithm is an iterative algorithm based on a filter, and the filter has a certain effect on the noise, but the effect is not very good;
- The results of TVAL3, NLR-CS and D-AMP at a high measurement rate of 0.25 are not better than those at a low measurement rate of 0.10. The main reason is that the device samples more data at high measurement rates and the acquisition time is long, which will introduce more cumulative errors.
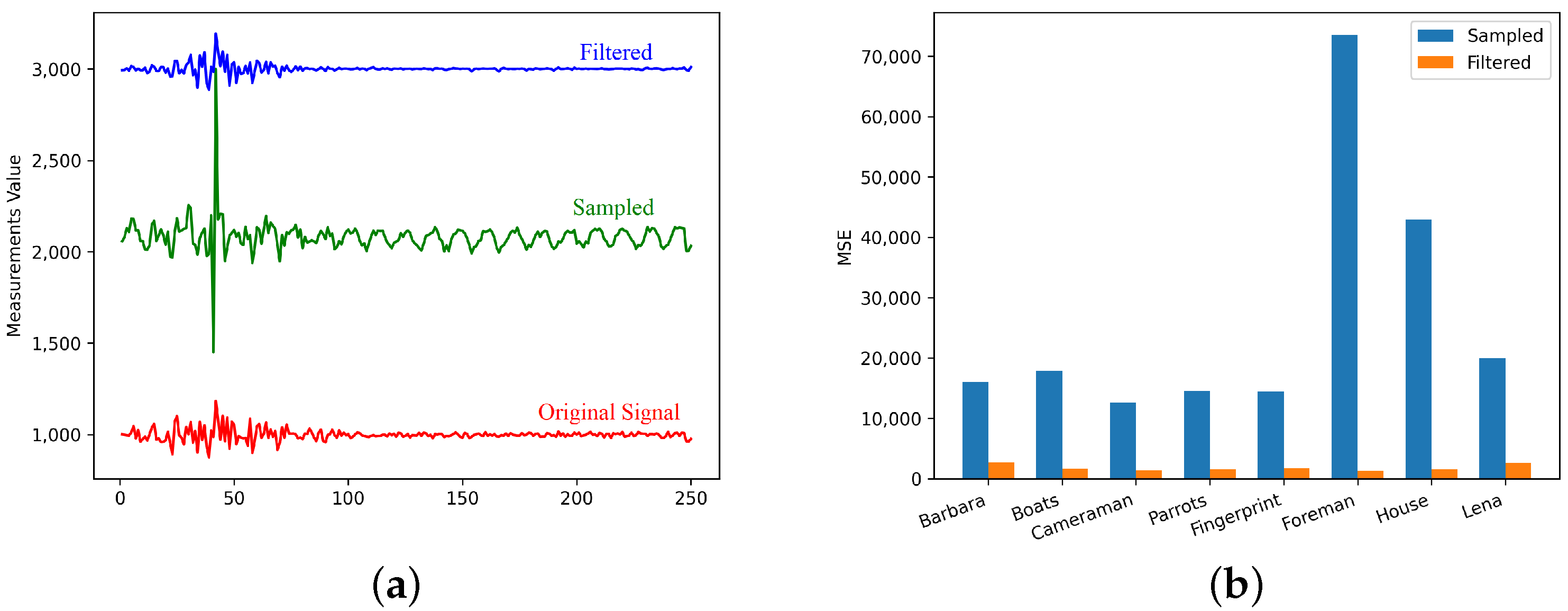
4.2. Evaluation of Filter Network
- The quality of the reconstruction results of TVAL3, NLR-CS and D-AMP has been significantly improved. The increase in PSNR of some algorithms is about 7 dB;
- The higher the measurement rate, the greater the improvement in image quality. The main reason is that the measurement rate is high, the device acquisition time is long, and the cumulative error introduced will be large, so the effect achieved by the filter network is better;
- In fact, the reconstruction result of 0.01 is already very poor; the image basically cannot show the content of the original image. The SSIM of the image is also very low and the PSNR of D-AMP after filtering is reduced, which is meaningless.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 449–458. [Google Scholar]
- Candes, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef] [Green Version]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef] [Green Version]
- Baraniuk, R.G. Compressive Sensing [Lecture Notes]. IEEE Signal Process. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Antonin, C.; Pierre-Louis, L. Image recovery via total variation minimization and related problems. Numer. Math. 1997, 76, 167–188. [Google Scholar]
- Tony, C.; Selim, E.; Frederick, P.; Yip, A. Recent developments in total variation image restoration. Math. Model. Comput. Vis. 2005, 17, 2. [Google Scholar]
- Li, C.; Yin, W.; Jiang, H.; Zhang, Y. An efficient augmented lagrangian method with applications to total variation minimization. CAAM Technical Report. Comput. Optim. Appl. 2013, 56, 507–530. [Google Scholar] [CrossRef] [Green Version]
- Dong, W.; Shi, G.; Li, X.; Ma, Y.; Huang, F. Compressive sensing via nonlocal low-rank regularization. IEEE Trans. Image Process. Publ. 2014, 23, 3618–3632. [Google Scholar] [CrossRef] [PubMed]
- Metzler, C.A.; Maleki, A.; Baraniuk, R.G. From denoising to compressed sensing. IEEE Trans. Inf. Theory 2016, 62, 5117–5144. [Google Scholar] [CrossRef]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. Communication, Control, and Computing (Allerton). In Proceedings of the 2015 53rd Annual Allerton Conference, Monticello, IL, USA, 29 September 2015; pp. 1336–1343. [Google Scholar]
- Dong, C.; Loy, C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Adler, A.; Boublil, D.; Zibulevsky, M. Block-based compressed sensing of images via deep learning. In Proceedings of the 2017 IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), London, UK, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Akbari, A.; Trocan, M. Robust image reconstruction for block-based compressed sensing using a binary measurement matrix. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1832–1836. [Google Scholar]
- Yu, Y.; Wang, B.; Zhang, L. Saliency-based compressive sampling for image signals. IEEE Signal Process. Lett. 2010, 17, 973–976. [Google Scholar]
- Zhou, S.; He, Y.; Liu, Y. Multi-Channel Deep Networks for Block-Based Image Compressive Sensing. IEEE Trans. Multimed. 2021, 23, 2627–2640. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, J. AMP-Net: Denoising-based deep unfolding for compressive image sensing. IEEE Trans. Image Process. 2020, 30, 1487–1500. [Google Scholar] [CrossRef] [PubMed]
- Lohit, S.; Kulkarni, K.; Kerviche, R.; Turaga, P.K.; Ashok, A. Convolutional Neural Networks for Noniterative Reconstruction of Compressively Sensed Images. IEEE Trans. Comput. Imaging 2018, 4, 326–340. [Google Scholar] [CrossRef] [Green Version]
- Theis, L.; Bethge, M. Generative image modeling using spatial LSTMs. Adv. Neural Inf. Process. Syst. 2015, 28, 1927–1935. [Google Scholar]
- Dave, A.; Vadathya, A.K.; Mitra, K. Compressive image recovery using recurrent generative model. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1702–1706. [Google Scholar]
- Mdrafi, R.; Gurbuz, A.C. Joint learning of measurement matrix and signal reconstruction via deep learning. IEEE Trans. Comput. Imaging 2020, 6, 818–829. [Google Scholar] [CrossRef]
- Mu, Q.; Meng, Z.; Ma, J.; Yuan, X. Deep learning for video compressive sensing. Apl Photonics 2020, 5, 030801. [Google Scholar]
- Cheng, Z.; Lu, R.; Wang, Z.; Zhang, H.; Chen, B.; Meng, Z.; Yuan, X. BIRNAT: Bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 258–275. [Google Scholar]
- Huang, G.; Jiang, H.; Matthews, K.; Wilford, P. Lensless imaging by compressive sensing. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Melbourne, Australia, 15–18 September 2013; pp. 2101–2105. [Google Scholar]
- Zhang, Z.; Ma, X.; Zhong, J. Single-pixel imaging by means of Fourier spectrum acquisition. Nat. Commun. 2015, 6, 6225. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Algorithm | MR = 0.25 | MR = 0.10 | MR = 0.04 | MR = 0.01 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Barbara | TVAL3 | 9.84 | 0.43 | 10.23 | 0.42 | 11.66 | 0.03 | 12.51 | 0.23 |
| NLR-CS | 9.79 | 0.42 | 10.64 | 0.39 | 9.99 | 0.33 | 10.96 | 0.28 | |
| D-AMP | 12.80 | 0.58 | 12.18 | 0.49 | 11.88 | 0.40 | 14.17 | 0.32 | |
| Ours | 22.65 | 0.70 | 22.61 | 0.77 | 20.83 | 0.68 | 14.01 | 0.38 | |
| Boats | TVAL3 | 9.95 | 0.44 | 8.32 | 0.38 | 7.45 | 0.30 | 6.47 | 0.20 |
| NLR-CS | 9.57 | 0.41 | 7.64 | 0.32 | 7.29 | 0.28 | 6.05 | 0.17 | |
| D-AMP | 11.98 | 0.50 | 11.42 | 0.41 | 10.44 | 0.37 | 12.66 | 0.29 | |
| Ours | 20.76 | 0.64 | 19.97 | 0.71 | 17.75 | 0.63 | 15.92 | 0.43 | |
| Cameraman | TVAL3 | 9.68 | 0.46 | 9.85 | 0.48 | 11.06 | 0.44 | 10.01 | 0.30 |
| NLR-CS | 9.71 | 0.43 | 10.20 | 0.45 | 11.12 | 0.40 | 10.02 | 0.30 | |
| D-AMP | 12.86 | 0.55 | 12.49 | 0.55 | 12.50 | 0.46 | 11.03 | 0.32 | |
| Ours | 18.80 | 0.41 | 18.10 | 0.50 | 17.34 | 0.30 | 14.39 | 0.18 | |
| Parrots | TVAL3 | 10.38 | 0.0.53 | 9.53 | 0.41 | 9.85 | 0.41 | 9.60 | 0.23 |
| NLR-CS | 10.13 | 0.50 | 9.38 | 0.36 | 9.35 | 0.35 | 9.46 | 0.20 | |
| D-AMP | 11.77 | 0.54 | 13.32 | 0.58 | 11.91 | 0.50 | 10.57 | 0.27 | |
| Ours | 23.27 | 0.70 | 22.86 | 0.80 | 18.93 | 0.61 | 15.92 | 0.52 | |
| Fingerprint | TVAL3 | 10.54 | 0.21 | 12.57 | 0.21 | 10.11 | 0.11 | 6.60 | 0.10 |
| NLR-CS | 10.34 | 0.20 | 12.20 | 0.21 | 8.08 | 0.15 | 6.77 | 0.10 | |
| D-AMP | 12.76 | 0.23 | 12.46 | 0.22 | 10.63 | 0.16 | 15.33 | 0.17 | |
| Ours | 17.79 | 0.30 | 18.14 | 0.34 | 17.28 | 0.29 | 14.96 | 0.20 | |
| Foreman | TVAL3 | 3.44 | 0.06 | 12.11 | 0.47 | 3.46 | 0.06 | 4.36 | 0.19 |
| NLR-CS | 3.45 | 0.06 | 5.25 | 0.29 | 4.86 | 0.24 | 4.32 | 0.17 | |
| D-AMP | 11.40 | 0.56 | 13.44 | 0.59 | 13.03 | 0.52 | 12.40 | 0.47 | |
| Ours | 20.99 | 0.77 | 17.93 | 0.77 | 20.93 | 0.77 | 14.58 | 0.36 | |
| House | TVAL3 | 4.23 | 0.09 | 12.43 | 0.43 | 4.45 | 0.12 | 5.45 | 0.21 |
| NLR-CS | 4.30 | 0.10 | 5.86 | 0.28 | 5.15 | 0.21 | 5.42 | 0.19 | |
| D-AMP | 10.99 | 0.54 | 11.50 | 0.46 | 11.53 | 0.49 | 12.94 | 0.44 | |
| Ours | 24.42 | 0.72 | 17.57 | 0.82 | 17.59 | 0.70 | 16.87 | 0.42 | |
| Lena | TVAL3 | 11.81 | 0.48 | 14.09 | 0.25 | 11.99 | 0.25 | 11.79 | 0.28 |
| NLR-CS | 11.38 | 0.46 | 10.96 | 0.40 | 10.92 | 0.37 | 11.73 | 0.26 | |
| D-AMP | 12.32 | 0.55 | 12.01 | 0.45 | 11.56 | 0.42 | 10.04 | 0.21 | |
| Ours | 22.14 | 0.76 | 22.18 | 0.87 | 20.51 | 0.76 | 14.52 | 0.28 | |
| Mean | TVAL3 | 8.73 | 0.34 | 11.14 | 0.38 | 8.75 | 0.22 | 8.34 | 0.22 |
| NLR-CS | 8.58 | 0.32 | 9.02 | 0.34 | 8.35 | 0.29 | 8.09 | 0.21 | |
| D-AMP | 12.11 | 0.51 | 12.35 | 0.47 | 11.69 | 0.42 | 12.39 | 0.31 | |
| Ours | 21.35 | 0.63 | 19.92 | 0.70 | 18.89 | 0.59 | 15.14 | 0.34 | |
| Image | Algorithm | MR = 0.25 | MR = 0.10 | MR = 0.04 | MR = 0.01 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Mean | TVAL3 | 16.29 | 0.48 | 15.81 | 0.37 | 14.73 | 0.34 | 10.82 | 0.19 |
| NLR-CS | 16.19 | 0.46 | 15.66 | 0.39 | 14.43 | 0.32 | 10.61 | 0.22 | |
| D-AMP | 17.55 | 0.50 | 16.86 | 0.46 | 15.25 | 0.32 | 10.44 | 0.17 | |
| Ours | 21.35 | 0.63 | 19.92 | 0.70 | 18.05 | 0.50 | 15.14 | 0.34 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Lu, K.; Xue, J.; Dai, F.; Zhang, Y. Dual Optical Path Based Adaptive Compressive Sensing Imaging System. Sensors 2021, 21, 6200. https://doi.org/10.3390/s21186200
Li H, Lu K, Xue J, Dai F, Zhang Y. Dual Optical Path Based Adaptive Compressive Sensing Imaging System. Sensors. 2021; 21(18):6200. https://doi.org/10.3390/s21186200
Chicago/Turabian StyleLi, Hongliang, Ke Lu, Jian Xue, Feng Dai, and Yongdong Zhang. 2021. "Dual Optical Path Based Adaptive Compressive Sensing Imaging System" Sensors 21, no. 18: 6200. https://doi.org/10.3390/s21186200
APA StyleLi, H., Lu, K., Xue, J., Dai, F., & Zhang, Y. (2021). Dual Optical Path Based Adaptive Compressive Sensing Imaging System. Sensors, 21(18), 6200. https://doi.org/10.3390/s21186200