
The Sample Size Matters: To What Extent the Participant Reduction Affects the Outcomes of a Neuroscientific Research. A Case-Study in Neuromarketing Field

 , ,
, ,  ,
,  ,
, 
 and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Sample and Design
2.2. Neurophysiological Data Recording
- Index 3: descriptor of the autonomic response, namely, the emotional index (EI), computed as the combination between the SCL and the HR measures, as described by Vecchiato and colleagues [52].
2.3. Data Analysis and Statistics
- Group-mean values of the index (function of t, i.e., the task duration), for each of the 630 combinations. We so obtained 630 vectors ‘v630’ (thus resulting in a matrix 630 x t);
- Pearson correlation between each ‘v630’ (630 x t) and the vector ‘v’ (1 x t), containing the mean values of the index computed over the entire population (36 subjects);
- Mean Squared Error (MSE) to describe the error committed considering each ‘v630’ rather than ‘v’ along each task (within-task variability):
- 4.
- The standard deviation of the 630 values assumed by the vectors ‘v630’, for every second of the task itself (between-groups variability):
3. Results
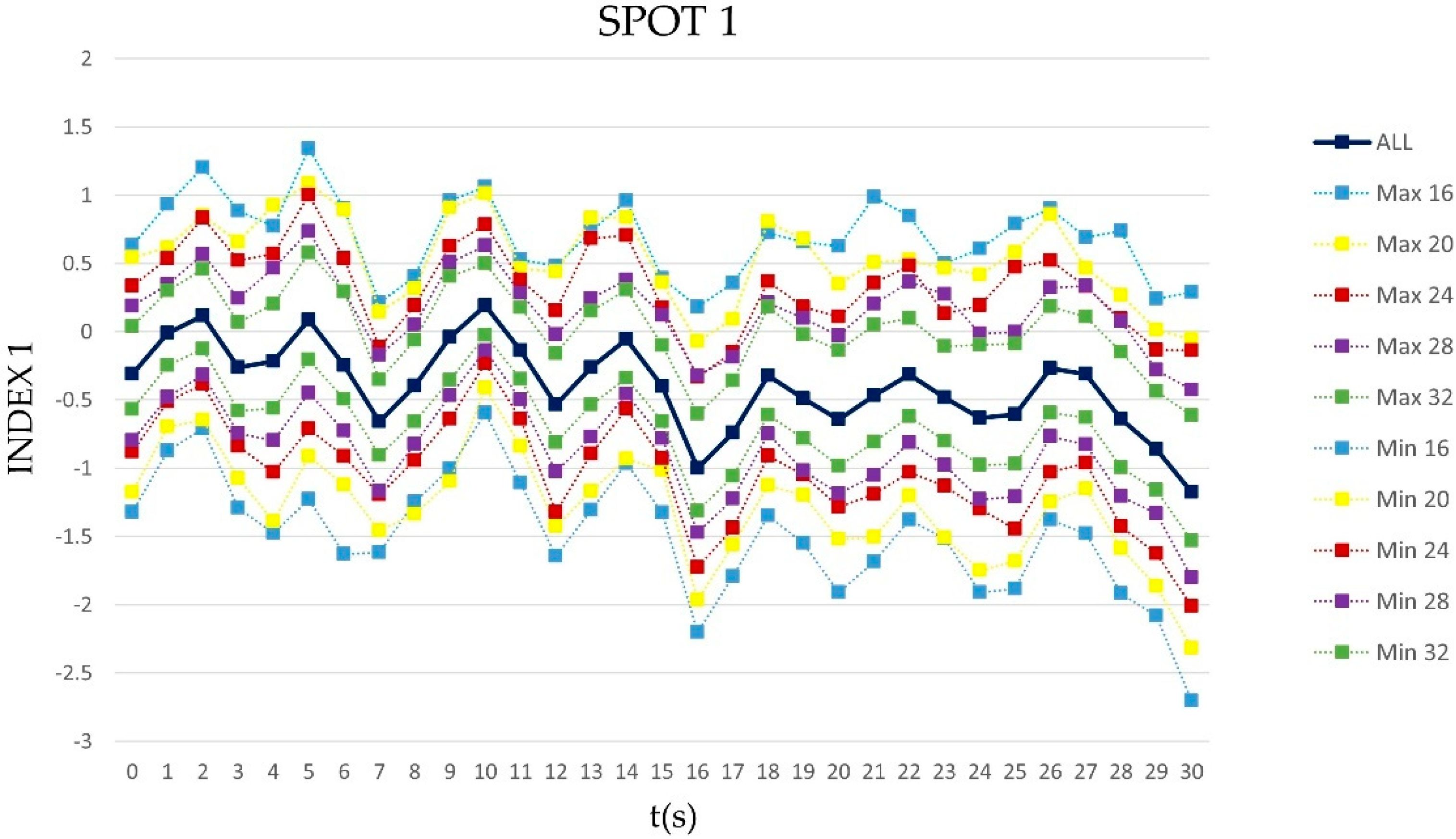
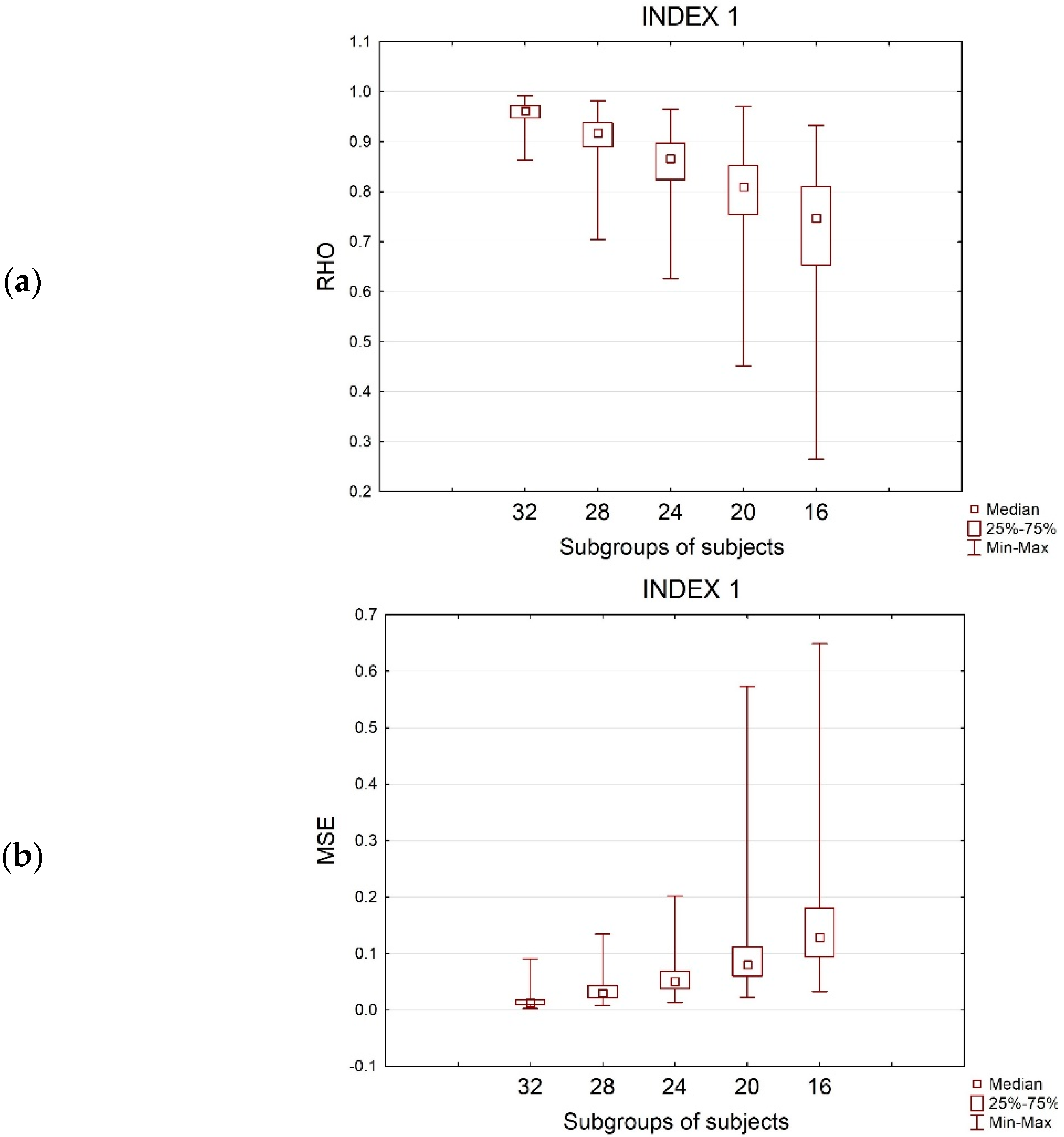
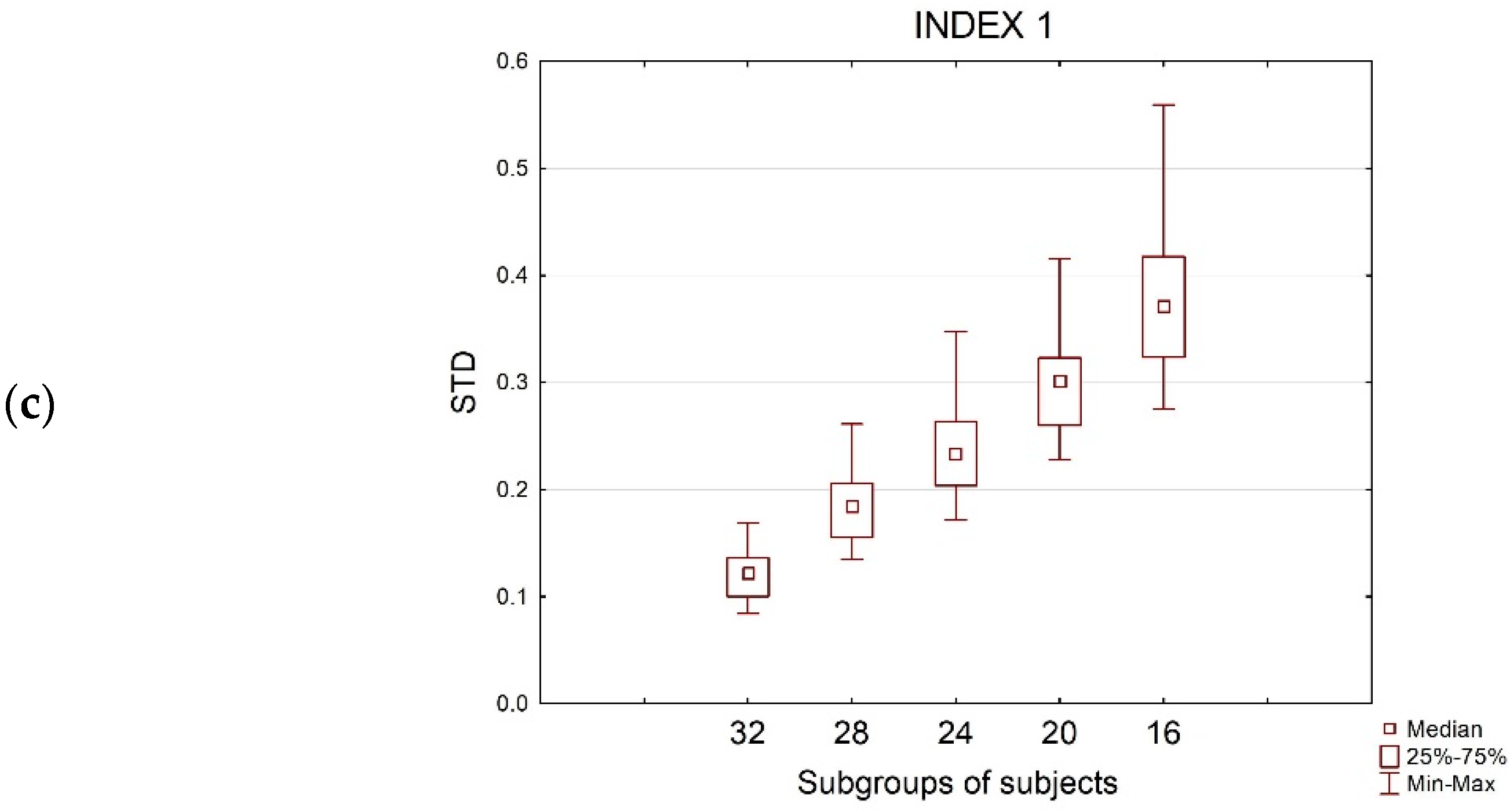
3.1. The Effect of the Index
3.2. The Effect of the Task
3.3. The Effect of the Time
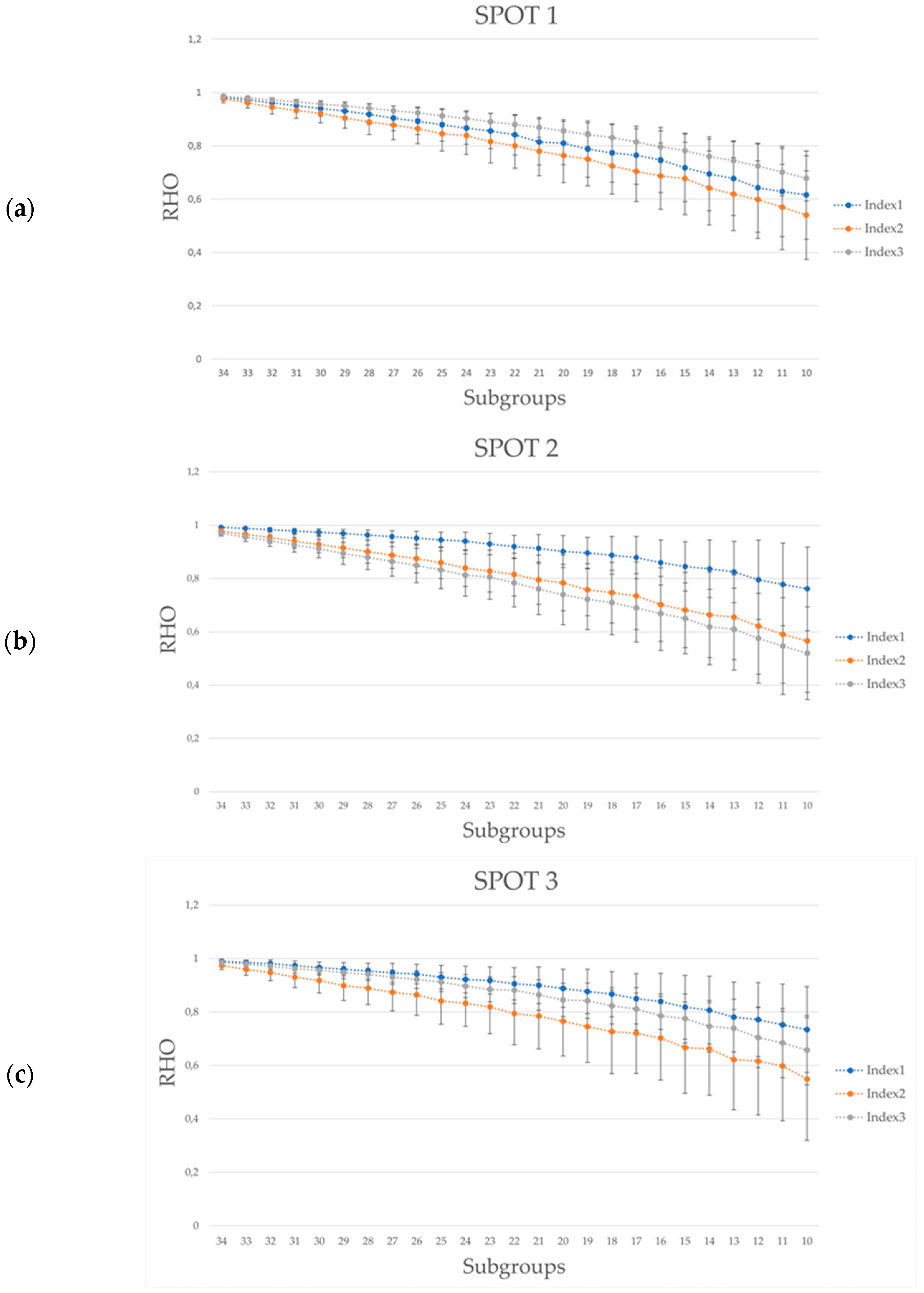
3.4. Rho-Sample Size Relationship
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Larson, M.J.; Carbine, K.A. Sample size calculations in human electrophysiology (EEG and ERP) studies: A systematic review and recommendations for increased rigor. Int. J. Psychophysiol. 2017, 111, 33–41. [Google Scholar] [CrossRef]
- Button, K.S.; Ioannidis, J.P.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.; Munafò, M.R. Power failure: Why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 2013, 14, 365–376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eng, J. Sample size estimation: How many individuals should be studied? Radiology 2003, 227, 309–313. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanders, N.; Choo, S.; Nam, C.S. The EEG cookbook: A practical guide to neuroergonomics research. In Cognitive Science and Technology; Springer: Berlin, Germany, 2020; pp. 33–51. [Google Scholar]
- Mao, Z.; Jung, T.P.; Lin, C.T.; Huang, Y. Predicting EEG sample size required for classification calibration. In Proceedings of the Foundations of Augmented Cognition: Neuroergonomics and Operational Neuroscience—AC 2016, Toronto, ON, Canada, 17–22 July 2016; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer: Cham, Switzerland, 2016; Volume 9743, pp. 57–68. [Google Scholar] [CrossRef]
- Anderson, S.F.; Kelley, K.; Maxwell, S.E. Sample-size planning for more accurate statistical power: A method adjusting sample effect sizes for publication bias and uncertainty. Psychol. Sci. 2017, 28, 1547–1562. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sim, J.; Saunders, B.; Waterfield, J.; Kingstone, T. Can sample size in qualitative research be determined a priori? Int. J. Soc. Res. Methodol. 2018, 21, 619–634. [Google Scholar] [CrossRef]
- Javanmard, A.; Montanari, A. Debiasing the lasso: Optimal sample size for Gaussian designs. Ann. Stat. 2018, 46, 2593–2622. [Google Scholar] [CrossRef] [Green Version]
- Combrisson, E.; Jerbi, K. Exceeding chance level by chance: The caveat of theoretical chance levels in brain signal classification and statistical assessment of decoding accuracy. J. Neurosci. Methods 2015, 250, 126–136. [Google Scholar] [CrossRef]
- Baker, D.H.; Vilidaite, G.; Lygo, F.A.; Smith, A.K.; Flack, T.R.; Gouws, A.D.; Andrews, T.J. Power contours: Optimising sample size and precision in experimental psychology and human neuroscience. Psychol. Methods 2021, 26, 295–314. [Google Scholar] [CrossRef]
- Guttmann-Flury, E.; Sheng, X.; Zhang, D.; Zhu, X. A priori sample size determination for the number of subjects in an EEG experiment. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Berlin, Germany, 23–27 July 2019; pp. 5180–5183. [Google Scholar] [CrossRef]
- Nosek, B.A.; Spies, J.R.; Motyl, M. Scientific Utopia: II. Restructuring incentives and practices to promote truth over publishability. Perspect. Psychol. Sci. 2012, 7, 615–631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arico, P.; Borghini, G.; Di Flumeri, G.; Sciaraffa, N.; Babiloni, F. Passive BCI beyond the lab: Current trends and future directions. Physiol. Meas. 2018, 39, 08TR02. [Google Scholar] [CrossRef]
- Di Flumeri, G.; Aricò, P.; Borghini, G.; Sciaraffa, N.; Di Florio, A.; Babiloni, F. The dry revolution: Evaluation of three different eeg dry electrode types in terms of signal spectral features, mental states classification and usability. Sensors 2019, 19, 1365. [Google Scholar] [CrossRef] [Green Version]
- Ayaz, H.; Dehais, F. Neuroergonomics: The Brain at Work and in Everyday Life; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Mühl, C.; Jeunet, C.; Lotte, F. EEG-based workload estimation across affective contexts. Front. Neurosci. 2014, 8, 114. [Google Scholar] [CrossRef] [Green Version]
- Berka, C.; Levendowski, D.J.; Lumicao, M.N.; Yau, A.; Davis, G.; Zivkovic, V.T.; Olmstead, R.E.; Tremoulet, P.D.; Craven, P.L. EEG correlates of task engagement and mental workload in vigilance, learning, and memory tasks. Aviat. Space Environ. Med. 2007, 78, B231–B244. [Google Scholar]
- Di Flumeri, G.; De Crescenzio, F.; Berberian, B.; Ohneiser, O.; Kramer, J.; Aricò, P.; Borghini, G.; Babiloni, F.; Bagassi, S.; Piastra, S. Brain–computer interface-based adaptive automation to prevent out-of-the-loop phenomenon in air traffic controllers dealing with highly automated systems. Front. Hum. Neurosci. 2019, 13, 296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karthaus, M.; Wascher, E.; Getzmann, S. Proactive vs. reactive car driving: EEG evidence for different driving strategies of older drivers. PLoS ONE 2018, 13, e0191500. [Google Scholar] [CrossRef] [Green Version]
- Di Flumeri, G.; Borghini, G.; Aricò, P.; Sciaraffa, N.; Lanzi, P.; Pozzi, S.; Vignali, V.; Lantieri, C.; Bichicchi, A.; Simone, A.; et al. EEG-based mental workload neurometric to evaluate the impact of different traffic and road conditions in real driving settings. Front. Hum. Neurosci. 2018, 12, 509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, M.R.; Barua, S.; Ahmed, M.U.; Begum, S.; Aricò, P.; Borghini, G.; Di Flumeri, G. A novel mutual information based feature set for drivers’ mental workload evaluation using machine learning. Brain Sci. 2020, 10, 551. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhang, J.; Yin, J.; Bi, S.; Eisenbach, M.; Wang, Y. Monte Carlo simulation of order-disorder transition in refractory high entropy alloys: A data-driven approach. Comput. Mater. Sci. 2021, 187, 110135. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Khaliliardali, Z.; Gheorghe, L.; Iturrate, I.; Millán, J.D.R. EEG-based decoding of error-related brain activity in a real-world driving task. J. Neural Eng. 2015, 12, 066028. [Google Scholar] [CrossRef] [Green Version]
- Marucci, M.; Di Flumeri, G.; Borghini, G.; Sciaraffa, N.; Scandola, M.; Pavone, E.F.; Babiloni, F.; Betti, V.; Aricò, P. The impact of multisensory integration and perceptual load in virtual reality settings on performance, workload and presence. Sci. Rep. 2021, 11, 4831. [Google Scholar] [CrossRef]
- Cherubino, P.; Martinez-Levy, A.C.; Caratu, M.; Cartocci, G.; Di Flumeri, G.; Modica, E.; Rossi, D.; Mancini, M.; Trettel, A. Consumer behaviour through the eyes of neurophysiological measures: State-of-the-art and future trends. Comput. Intell. Neurosci. 2019, 2019, 1976847. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morin, C. Neuromarketing: The new science of consumer behavior. Society 2011, 48, 131–135. [Google Scholar] [CrossRef] [Green Version]
- Sciaraffa, N.; Borghini, G.; Di Flumeri, G.; Cincotti, F.; Babiloni, F.; Aricò, P. Joint analysis of eye blinks and brain activity to investigate attentional demand during a visual search task. Brain Sci. 2021, 11, 562. [Google Scholar] [CrossRef]
- Amores, J.; Richer, R.; Zhao, N.; Maes, P.; Eskofier, B.M. Promoting relaxation using virtual reality, olfactory interfaces and wearable EEG. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN 2018), Las Vegas, NV, USA, 4–7 March 2018; Volume 2018, pp. 98–101. [Google Scholar] [CrossRef] [Green Version]
- Di Flumeri, G.; Aricò, P.; Borghini, G.; Sciaraffa, N.; Maglione, A.G.; Rossi, D.; Modica, E.; Trettel, A.; Babiloni, F.; Colosimo, A.; et al. EEG-based Approach-Withdrawal index for the pleasantness evaluation during taste experience in realistic settings. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Jeju, Korea, 11–15 July 2017; pp. 3228–3231. [Google Scholar] [CrossRef]
- Yoto, A.; Moriyama, T.; Yokogoshi, H.; Nakamura, Y.; Katsuno, T.; Nakayama, T. Effect of smelling green tea rich in aroma components on EEG activity and memory task performance. Int. J. Affect. Eng. 2014, 13, 227–233. [Google Scholar] [CrossRef] [Green Version]
- Velavan, T.P.; Meyer, C.G. The COVID-19 epidemic. Trop. Med. Int. Health 2020, 25, 278–280. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bazzani, A.; Ravaioli, S.; Trieste, L.; Faraguna, U.; Turchetti, G. Is EEG suitable for marketing research? A systematic review. Front. Neurosci. 2020, 14, 594566. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. Ten ironic rules for non-statistical reviewers. Neuroimage 2012, 61, 1300–1310. [Google Scholar] [CrossRef] [PubMed]
- Vecchiato, G.; Toppi, J.; Astolfi, L.; Fallani, F.D.V.; Cincotti, F.; Mattia, D.; Bez, F.; Babiloni, F. Spectral EEG frontal asymmetries correlate with the experienced pleasantness of TV commercial advertisements. Med. Biol. Eng. Comput. 2011, 49, 579–583. [Google Scholar] [CrossRef]
- Cartocci, G.; Cherubino, P.; Rossi, D.; Modica, E.; Maglione, A.G.; Di Flumeri, G.; Babiloni, F. Gender and age related effects while watching TV advertisements: An EEG study. Comput. Intell. Neurosci. 2016, 2016, 3795325. [Google Scholar] [CrossRef] [Green Version]
- Nielsen. Advertising and Audiences: Making Ad Dollars Make Sense. Available online: https://www.nielsen.com/us/en/insights/article/2014/advertising-and-audiences-making-ad-dollars-make-sense/ (accessed on 27 August 2021).
- Belouchrani, A.; Abed-Meraim, K.; Cardoso, J.F.; Moulines, E. A blind source separation technique using second-order statistics. IEEE Trans. Signal. Process. 1997, 45, 434–444. [Google Scholar] [CrossRef] [Green Version]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [Green Version]
- EEGLAB Wiki. 6. Reject Artifacts. Available online: https://eeglab.org/tutorials/06_RejectArtifacts/ (accessed on 28 May 2021).
- Doppelmayr, M.; Klimesch, W.; Pachinger, T.; Ripper, B. Individual differences in brain dynamics: Important implications for the calculation of event-related band power. Biol. Cybern. 1998, 79, 49–57. [Google Scholar] [CrossRef]
- Klimesch, W. EEG alpha and theta oscillations reflect cognitive and memory performance: A review and analysis. Brain Res. Rev. 1999, 29, 169–195. [Google Scholar] [CrossRef]
- Skrandies, W. Global field power and topographic similarity. Brain Topogr. 1990, 3, 137–141. [Google Scholar] [CrossRef] [PubMed]
- Society for Psychophysiological Research Ad Hoc Committee on Electrodermal Measures; Boucsein, W.; Fowles, D.C.; Grimnes, S.; Ben-Shakhar, G.; Roth, W.T.; Dawson, M.E.; Filion, D.L. Publication recommendations for electrodermal measurements. Psychophysiology 2012, 49, 1017–1034. [Google Scholar] [CrossRef]
- Pan, J.; Tompkins, W.J. A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 1985, BME-32, 230–236. [Google Scholar] [CrossRef] [PubMed]
- Benedek, M.; Kaernbach, C. A continuous measure of phasic electrodermal activity. J. Neurosci. Methods 2010, 190, 80–91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klimesch, W. Alpha-band oscillations, attention, and controlled access to stored information. Trends Cogn. Sci. 2012, 16, 606–617. [Google Scholar] [CrossRef] [Green Version]
- Magosso, E.; De Crescenzio, F.; Ricci, G.; Piastra, S.; Ursino, M. EEG alpha power is modulated by attentional changes during cognitive tasks and virtual reality immersion. Comput. Intell. Neurosci. 2019, 2019, 7051079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Briesemeister, B.B.; Tamm, S.; Heine, A.; Jacobs, A.M. Approach the good, withdraw from the bad—A review on frontal alpha asymmetry measures in applied psychological research. Psychology 2013, 4, 261–267. [Google Scholar] [CrossRef] [Green Version]
- Modica, E.; Cartocci, G.; Rossi, D.; Martinez Levy, A.C.; Cherubino, P.; Maglione, A.G.; Di Flumeri, G.; Mancini, M.; Montanari, M.; Perrotta, D.; et al. Neurophysiological responses to different product experiences. Comput. Intell. Neurosci. 2018, 2018, 9616301. [Google Scholar] [CrossRef]
- Cartocci, G.; Modica, E.; Rossi, D.; Inguscio, B.; Arico, P.; Martinez Levy, A.C.; Mancini, M.; Cherubino, P.; Babiloni, F. Antismoking campaigns’ perception and gender differences: A comparison among EEG indices. Comput. Intell. Neurosci. 2019, 2019, 7348795. [Google Scholar] [CrossRef] [Green Version]
- Davidson, R.J.; Ekman, P.; Saron, C.D.; Senulis, J.A.; Friesen, W.V. Approach-withdrawal and cerebral asymmetry: Emotional expression and brain physiology I. J. Pers. Soc. Psychol. 1990, 58, 330–341. [Google Scholar] [CrossRef]
- Vecchiato, G.; Maglione, A.G.; Cherubino, P.; Wasikowska, B.; Wawrzyniak, A.; Latuszynska, A.; Latuszynska, M.; Nermend, K.; Graziani, I.; Leucci, M.R.; et al. Neurophysiological tools to investigate consumer’s gender differences during the observation of TV commercials. Comput. Math. Methods Med. 2014, 2014, 912981. [Google Scholar] [CrossRef]
- Bonferroni, C.E. Teoria Statistica delle Classi e Calcolo delle Probabilità—Google Libri. Available online: https://books.google.it/books/about/Teoria_statistica_delle_classi_e_calcolo.html?id=3CY-HQAACAAJ&redir_esc=y (accessed on 24 August 2021).
- Shapiro, S.S.; Wilk, M. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675. [Google Scholar] [CrossRef]
- Nemenyi, P.B. Distribution-Free Multiple Comparisons; ProQuest: Ann Arbor, MI, USA, 1963. [Google Scholar]
- Xu, J.; Zhong, B. Review on portable EEG technology in educational research. Comput. Hum. Behav. 2018, 81, 340–349. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Routledge: New York, NY, USA, 1988. [Google Scholar]
- Mukaka, M.M. Statistics corner: A guide to appropriate use of correlation coefficient in medical research. Malawi Med. J. 2012, 24, 69–71. Available online: www.mmj.medcol.mw (accessed on 1 July 2021). [PubMed]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Khodayari-Rostamabad, A.; Reilly, J.P.; Hasey, G.M.; de Bruin, H.; MacCrimmon, D.J. A machine learning approach using EEG data to predict response to SSRI treatment for major depressive disorder. Clin. Neurophysiol. 2013, 124, 1975–1985. [Google Scholar] [CrossRef]
- Zander, T.O.; Andreessen, L.M.; Berg, A.; Bleuel, M.; Pawlitzki, J.; Zawallich, L.; Krol, L.R.; Gramann, K. Evaluation of a dry EEG system for application of passive brain-computer interfaces in autonomous driving. Front. Hum. Neurosci. 2017, 11, 78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kar, S.; Bhagat, M.; Routray, A. EEG signal analysis for the assessment and quantification of driver’s fatigue. Transp. Res. Part F Traffic Psychol. Behav. 2010, 13, 297–306. [Google Scholar] [CrossRef]
- Noshadi, S.; Abootalebi, V.; Sadeghi, M.T.; Shahvazian, M.S. Selection of an efficient feature space for EEG-based mental task discrimination. Biocybern. Biomed. Eng. 2014, 34, 159–168. [Google Scholar] [CrossRef]
- Frederick, J.A. Psychophysics of EEG alpha state discrimination. Conscious. Cogn. 2012, 21, 1345–1354. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dietrich, A.; Kanso, R. A review of EEG, ERP, and neuroimaging studies of creativity and insight. Psychol. Bull. 2010, 136, 822–848. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SPOT1(30 s) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #s.c. (p < 8 × 10−5) | Rho | MSE | STD | |||||||||
| I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | |
| 32 | 630 * | 630 * | 630 * | 0.96 ± 0.02 | 0.94 ± 0.02 | 0.97 ± 0.01 | 0.012 ± 0.01 | 0.014 ± 0.01 | 0.001 ± 0.0005 | 0.12 ± 0.02 | 0.13 ± 0.01 | 0.03 ± 0.003 |
| 28 | 630 * | 630 * | 630 * | 0.91 ± 0.04 | 0.89 ± 0.05 | 0.94 ± 0.02 | 0.029 ± 0.02 | 0.032 ± 0.02 | 0.002 ± 0.001 | 0,18 ± 0.03 | 0,19 ± 0.02 | 0.05 ± 0.004 |
| 24 | 628 (−0.3%) | 617 (−2.1%) | 630 * | 0.87 ± 0.06 | 0.84 ± 0.07 | 0.90 ± 0.03 | 0,05 ± 0.03 | 0,053 ± 0.03 | 0,004 ± 0.002 | 0.23 ± 0.04 | 0.23 ± 0.03 | 0.07 ± 0.007 |
| 20 | 597 (−5.2%) | 538 (−14.6%) | 630 * | 0.81 ± 0,08 | 0.76 ± 0.10 | 0.86 ± 0.04 | 0,079 ± 0.06 | 0,089 ± 0.05 | 0,007 ± 0.003 | 0.30 ± 0.05 | 0.31 ± 0.04 | 0.09 ± 0.007 |
| 16 | 479 (−23.9%) | 393 (−37.6%) | 618 (−1.9%) | 0.74 ± 0.12 | 0.69 ± 0.12 | 0.79 ± 0.06 | 0.128 ± 0.08 | 0.136 ± 0.08 | 0.011 ± 0.005 | 0.37 ± 0.06 | 0.38 ± 0.04 | 0.11 ± 0.01 |
| SPOT2 (30 s) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #s.c. (p < 8 × 10−5) | Rho | MSE | STD | |||||||||
| I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | |
| 32 | 630 * | 630 * | 630 * | 0.98 ± 0.007 | 0.95 ± 0.02 | 0.94 ± 0.02 | 0.02 ± 0.01 | 0.02 ± 0.01 | 0.001 ± 0.00 | 0.14 ± 0.02 | 0.13 ± 0.02 | 0.03 ± 0.004 |
| 28 | 630 * | 630 * | 630 * | 0.96 ± 0.01 | 0.9 ± 0.04 | 0.88 ± 0.04 | 0.04 ± 0.01 | 0.04 ± 0.02 | 0.002 ± 0.00 | 0.21 ± 0.02 | 0.19 ± 0.03 | 0.05 ± 0.006 |
| 24 | 630 * | 620 (−1.6%) | 598 (−5.1%) | 0.94 ± 0.03 | 0.84 ± 0.07 | 0.81 ± 0.07 | 0.07 ± 0.03 | 0.07 ± 0.03 | 0.004 ± 0.001 | 0.27 ± 0.04 | 0.26 ± 0.05 | 0.07 ± 0.008 |
| 20 | 622 (−1.2%) | 540 (−14.3%) | 492 (−21.9%) | 0.91 ± 0.06 | 0.78 ± 0.10 | 0.74 ± 0.11 | 0.12 ± 0.05 | 0.11 ± 0.05 | 0.007 ± 0.003 | 0.34 ± 0.04 | 0.32 ± 0.06 | 0.08 ± 0.01 |
| 16 | 581 (−7.8%) | 415 (−34.1%) | 340 (−46%) | 0.86 ± 0.08 | 0.70 ± 0.13 | 0.67 ± 0.14 | 0.18 ± 0.07 | 0.17 ± 0.07 | 0.01 ± 0.004 | 0.42 ± 0.06 | 0.40 ± 0.07 | 0.1 ± 0.02 |
| SPOT3 (20 s) | SPOT4 (15 s) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #s.c. (p < 8 × 10−5) | Rho | #s.c. (p < 8 × 10−5) | Rho | |||||||||
| I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | I1 | I2 | I3 | |
| 32 | 630 * | 630 * | 630 * | 0.98 ± 0.01 | 0.95 ± 0.03 | 0.98 ± 0.01 | 630 * | 623 (−1.1%) | 630 * | 0.96 ± 0.026 | 0.96 ± 0.04 | 0.97 ± 0.01 |
| 28 | 630 * | 607 (−3.6%) | 630 * | 0.95 ± 0.03 | 0.88 ± 0.06 | 0.95 ± 0.02 | 567 (−10%) | 548 (−13%) | 611 (−3%) | 0.92 ± 0.04 | 0.93 ± 0.05 | 0.94 ± 0.02 |
| 24 | 618 (−1.9%) | 515 (−18.2%) | 628 (−0.3%) | 0.92 ± 0.05 | 0.83 ± 0.08 | 0.92 ± 0.04 | 416 (−33.9%) | 427 (−32.2%) | 508 (−19.3%) | 0.87 ± 0.09 | 0.87 ± 0.13 | 0.89 ± 0.04 |
| 20 | 577 (−8.4%) | 340 (−46%) | 567 (−10%) | 0.88 ± 0.07 | 0.76 ± 0.13 | 0.87 ± 0.06 | 295 (−53.2%) | 288 (−54.3%) | 334 (−46.9%) | 0.80 ± 0.12 | 0.81 ± 0.19 | 0.84 ± 0.06 |
| 16 | 494 (−21.6%) | 222 (−64.7%) | 414 (−34.3%) | 0.83 ± 0.10 | 0.70 ± 0.16 | 0.81 ± 0.07 | 166 (−73.7%) | 180 (−71.4%) | 207 (−67.1%) | 0.74 ± 0.17 | 0.77 ± 0.24 | 0.78 ± 0.08 |
| INDEX1 | INDEX2 | INDEX3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #s.c. (p < 8 × 10−5) | #s.c. (p < 8 × 10−5) | #s.c. (p < 8 × 10−5) | ||||||||||
| 30 s | 30 s | 20 s | 15 s | 30 s | 30 s | 20 s | 15 s | 30 s | 30 s | 20 s | 15 s | |
| 32 | 630 * | 630 * | 630 * | 630 * | 630 * | 630 * | 630 * | 623 (−1.1%) | 630 * | 630 * | 630 * | 630 * |
| 28 | 630 * | 630 * | 630 * | 567 (−10%) | 630 * | 630 * | 607 (−3,6%) | 548 (−13%) | 630 * | 630 * | 630 * | 611 (−3%) |
| 24 | 628 (−0.3%) | 630 * | 618 (−1.9%) | 416 (−33.9%) | 617 (−2.1%) | 620 (−1.6%) | 515 (−18.2%) | 427 (−32.2%) | 630 * | 598 (−5.1%) | 628 (−0.3%) | 508 (−19.3%) |
| 20 | 597 (−5.2%) | 622 (−1.2%) | 577 (−8.4%) | 295 (−53.2%) | 538 (−14.6%) | 540 (−14.3%) | 340 (−46%) | 288 (−54.3%) | 630 * | 492 (−21.9%) | 567 (−10%) | 334 (−46.9%) |
| 16 | 479 (−23.9%) | 581 (−7.8%) | 494 (−21.6%) | 166 (−73.7%) | 393 (−37.6%) | 415 (−34.1%) | 222 (−64.7%) | 180 (−71.4%) | 618 (−1.9%) | 340 (−46%) | 414 (−34.3%) | 207 (−67.1%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vozzi, A.; Ronca, V.; Aricò, P.; Borghini, G.; Sciaraffa, N.; Cherubino, P.; Trettel, A.; Babiloni, F.; Di Flumeri, G. The Sample Size Matters: To What Extent the Participant Reduction Affects the Outcomes of a Neuroscientific Research. A Case-Study in Neuromarketing Field. Sensors 2021, 21, 6088. https://doi.org/10.3390/s21186088
Vozzi A, Ronca V, Aricò P, Borghini G, Sciaraffa N, Cherubino P, Trettel A, Babiloni F, Di Flumeri G. The Sample Size Matters: To What Extent the Participant Reduction Affects the Outcomes of a Neuroscientific Research. A Case-Study in Neuromarketing Field. Sensors. 2021; 21(18):6088. https://doi.org/10.3390/s21186088
Chicago/Turabian StyleVozzi, Alessia, Vincenzo Ronca, Pietro Aricò, Gianluca Borghini, Nicolina Sciaraffa, Patrizia Cherubino, Arianna Trettel, Fabio Babiloni, and Gianluca Di Flumeri. 2021. "The Sample Size Matters: To What Extent the Participant Reduction Affects the Outcomes of a Neuroscientific Research. A Case-Study in Neuromarketing Field" Sensors 21, no. 18: 6088. https://doi.org/10.3390/s21186088
APA StyleVozzi, A., Ronca, V., Aricò, P., Borghini, G., Sciaraffa, N., Cherubino, P., Trettel, A., Babiloni, F., & Di Flumeri, G. (2021). The Sample Size Matters: To What Extent the Participant Reduction Affects the Outcomes of a Neuroscientific Research. A Case-Study in Neuromarketing Field. Sensors, 21(18), 6088. https://doi.org/10.3390/s21186088