
Artificial Intelligence Technologies for Sign Language

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
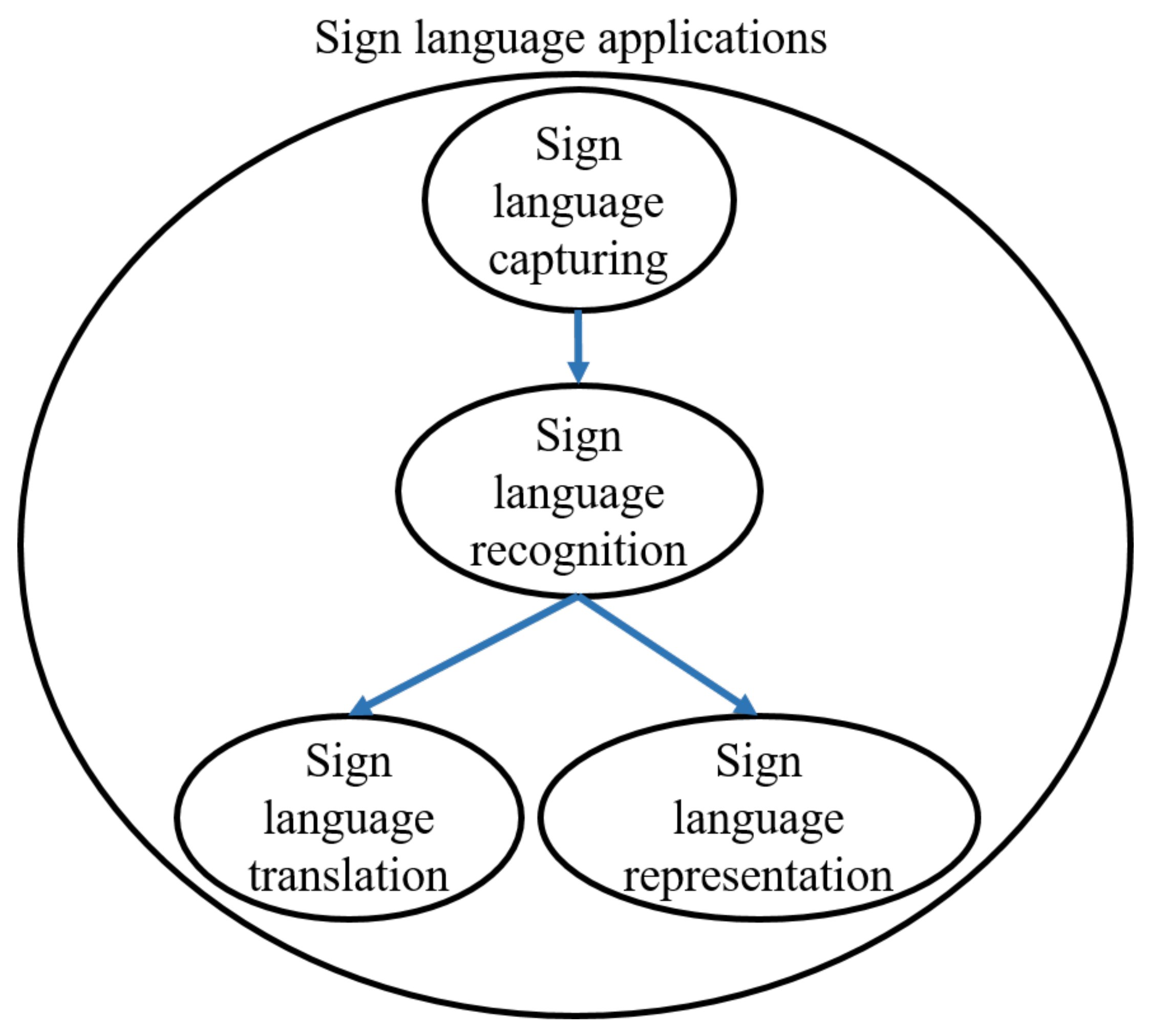
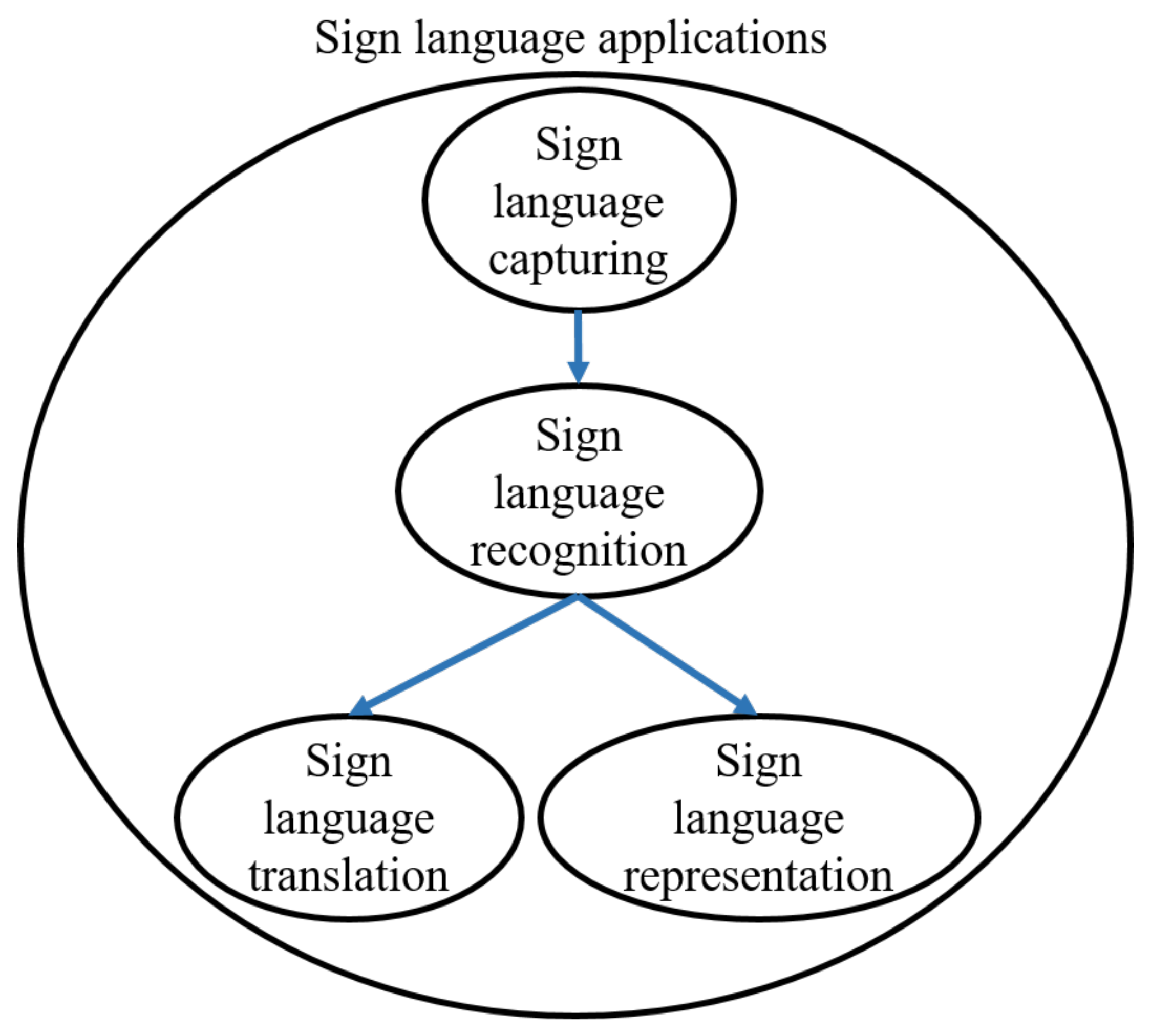
- A comprehensive overview of the use of AI technologies in various sign language tasks (i.e., capturing, recognition, translation and representation), along with their importance to their field, is provided.
- The advantages and limitations of modern sign language technologies and the relations between them are discussed and explored.
- Possible future directions in the development of AI technologies for sign language are suggested to facilitate prospective researchers in the field.
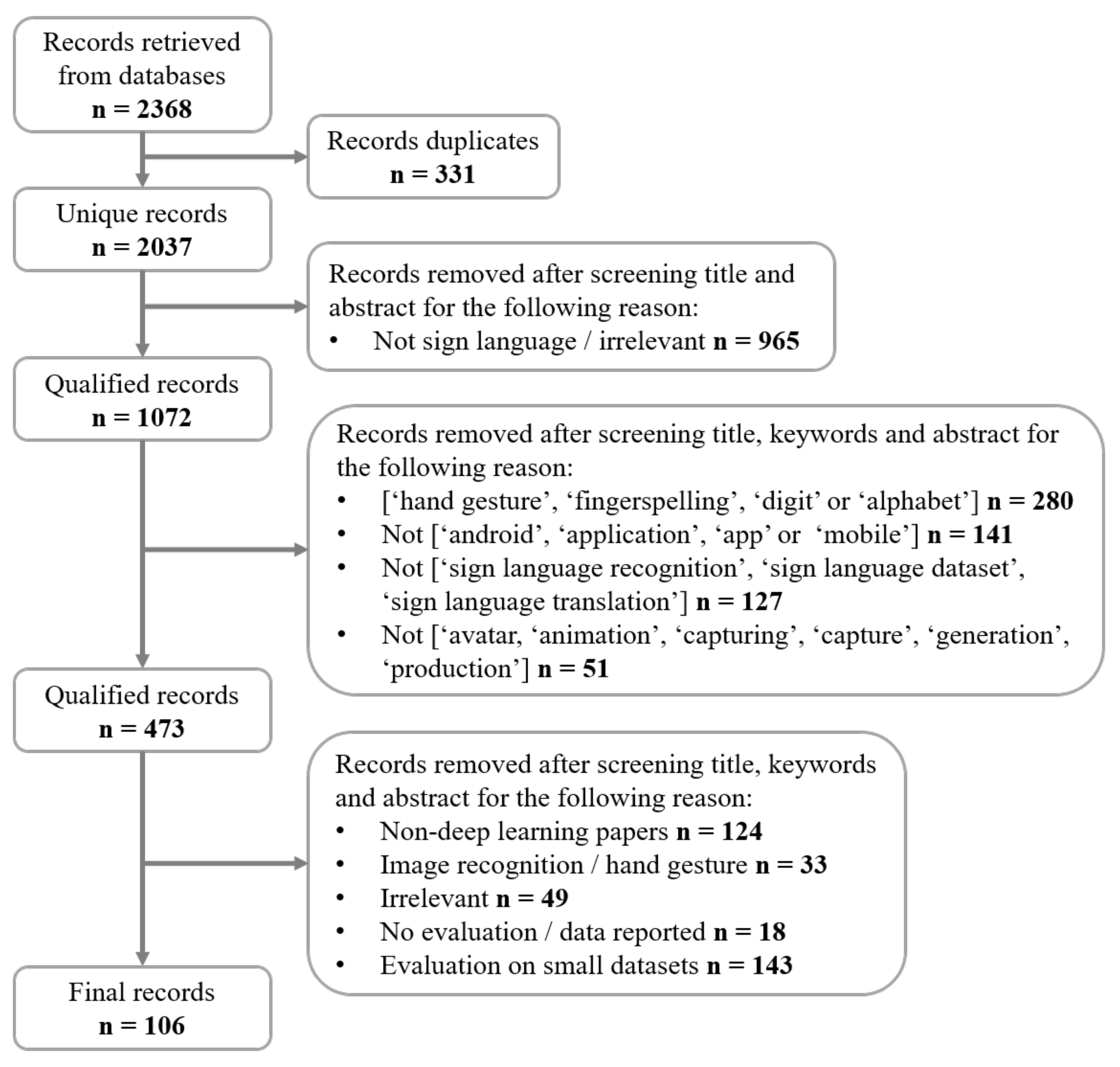
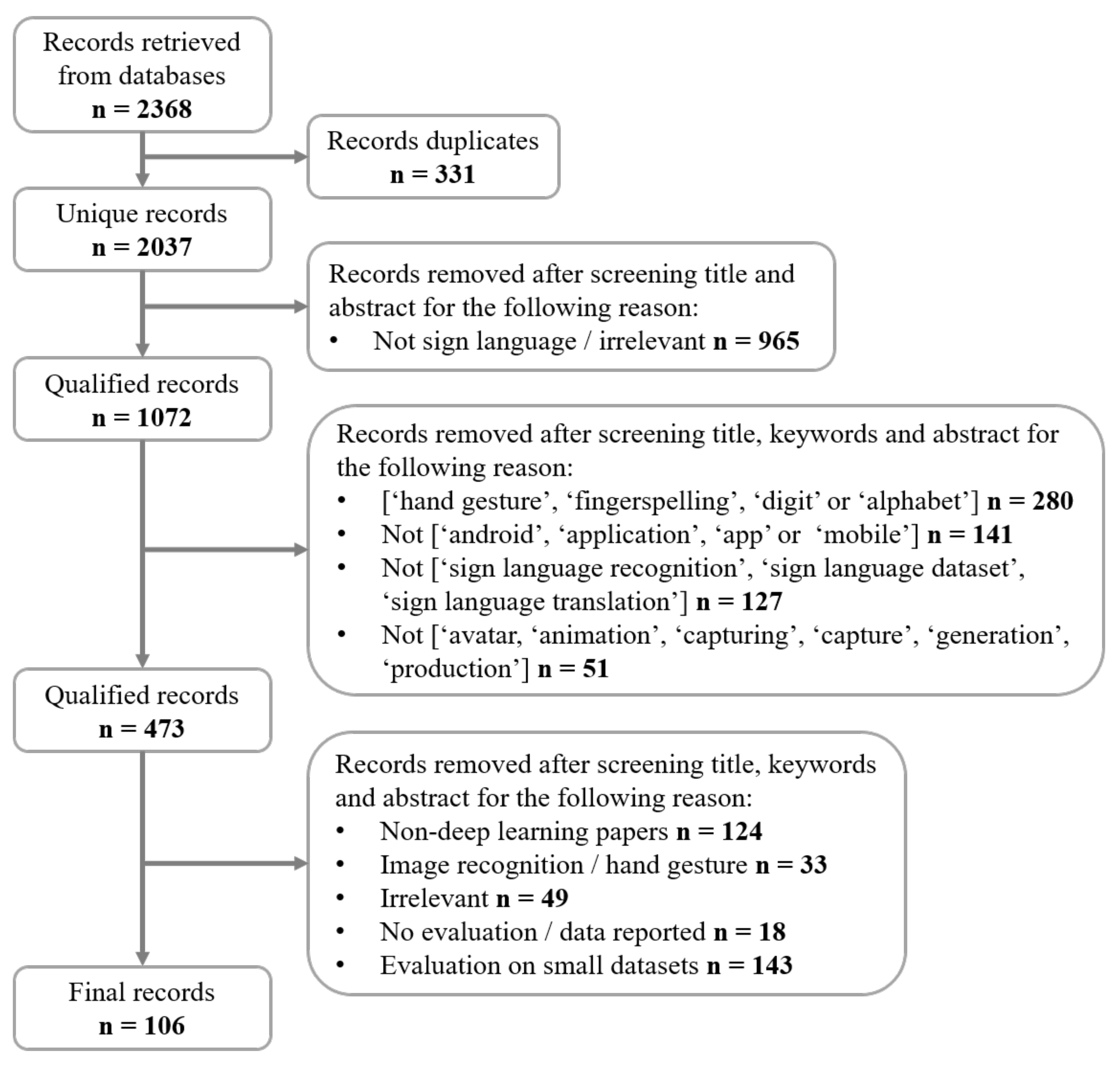
2. Literature Search
3. Sign Language Capturing
3.1. Capturing Sensors
3.2. Datasets
3.2.1. Continuous Sign Language Recognition Datasets
3.2.2. Isolated Sign Language Recognition Datasets
3.2.3. Discussion
4. Sign Language Recognition
4.1. Continuous Sign Language Recognition
4.2. Isolated Sign Language Recognition
4.3. Sign Language Translation
5. Sign Language Representation
5.1. Realistic Avatars
5.2. Sign Language Production
6. Applications
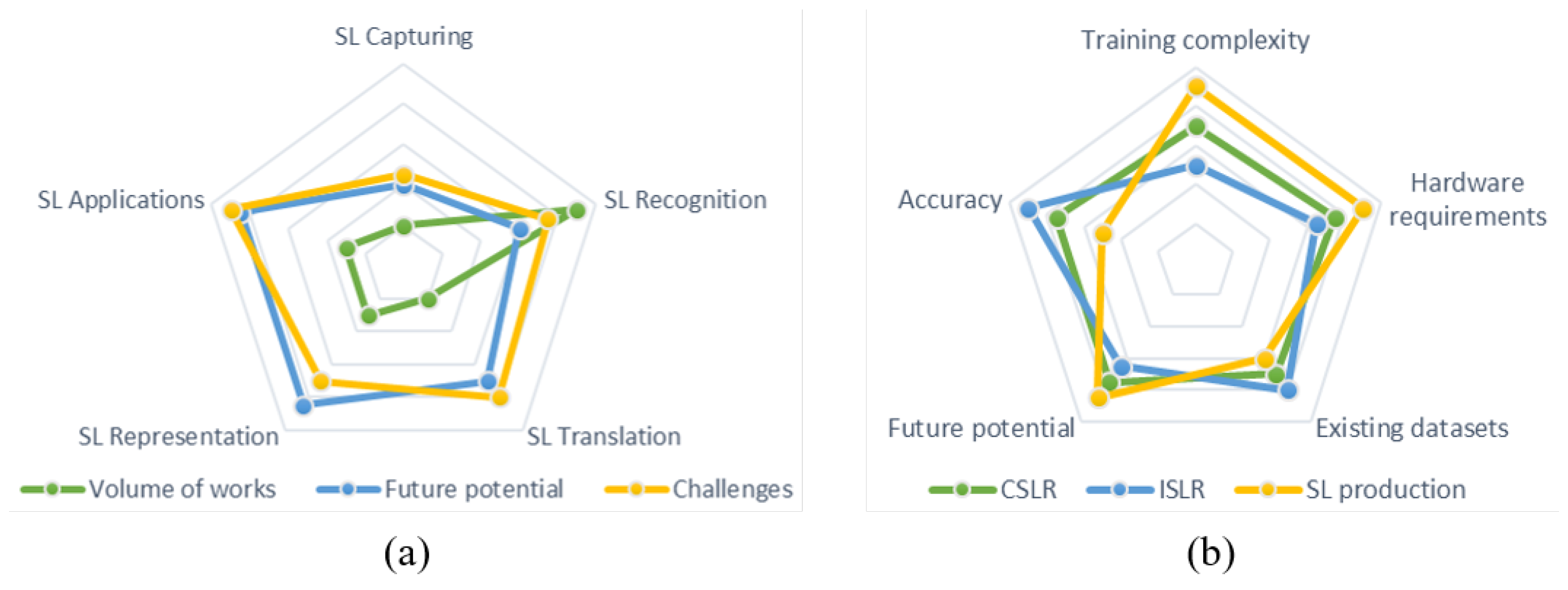
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Kendon, A. Gesture: Visible Action as Utterance; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Stefanidis, K.; Konstantinidis, D.; Kalvourtzis, A.; Dimitropoulos, K.; Daras, P. 3D technologies and applications in sign language. In Recent Advances in 3D Imaging, Modeling, and Reconstruction; IGI Global: Hershey, PA, USA, 2020; pp. 50–78. [Google Scholar]
- Kudrinko, K.; Flavin, E.; Zhu, X.; Li, Q. Wearable Sensor-Based Sign Language Recognition: A Comprehensive Review. IEEE Rev. Biomed. Eng. 2020, 14, 82–97. [Google Scholar] [CrossRef] [PubMed]
- Nimisha, K.; Jacob, A. A brief review of the recent trends in sign language recognition. In Proceedings of the IEEE 2020 International Conference on Communication and Signal Processing (ICCSP), Virtual, 16–18 March 2021; pp. 186–190. [Google Scholar]
- Safeel, M.; Sukumar, T.; Shashank, K.; Arman, M.; Shashidhar, R.; Puneeth, S. Sign Language Recognition Techniques—A Review. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology (INOCON), Bangalore, India, 19–21 November 2021; pp. 1–9. [Google Scholar]
- Sun, Z. A Survey on Dynamic Sign Language Recognition. In Advances in Computer, Communication and Computational Sciences; Springer: Singapore, 2021; pp. 1015–1022. [Google Scholar]
- Wadhawan, A.; Kumar, P. Sign language recognition systems: A decade systematic literature review. Arch. Comput. Methods Eng. 2021, 28, 785–813. [Google Scholar] [CrossRef]
- Ayadi, K.; ElHadj, Y.O.; Ferchichi, A. Automatic Translation from Arabic to Arabic Sign Language: A Review. In Proceedings of the IEEE 2018 JCCO Joint International Conference on ICT in Education and Training, International Conference on Computing in Arabic, and International Conference on Geocomputing (JCCO: TICET-ICCA-GECO), Tunisia, North Africa, 9–11 November 2018; pp. 1–5. [Google Scholar]
- Grover, Y.; Aggarwal, R.; Sharma, D.; Gupta, P.K. Sign Language Translation Systems for Hearing/Speech Impaired People: A Review. In Proceedings of the IEEE 2021 International Conference on Innovative Practices in Technology and Management (ICIPTM), Noida, India, 17–19 February 2021; pp. 10–14. [Google Scholar]
- Falvo, V.; Scatalon, L.P.; Barbosa, E.F. The role of technology to teaching and learning sign languages: A systematic mapping. In Proceedings of the 2020 IEEE Frontiers in Education Conference (FIE), Uppsala, Sweden, 21–24 October 2020; pp. 1–9. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Sign language recognition: A deep survey. Expert Syst. Appl. 2020, 164, 113794. [Google Scholar] [CrossRef]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst. Rev. 2015, 4, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cerna, L.R.; Cardenas, E.E.; Miranda, D.G.; Menotti, D.; Camara-Chavez, G. A multimodal LIBRAS-UFOP Brazilian sign language dataset of minimal pairs using a microsoft Kinect sensor. Expert Syst. Appl. 2021, 167, 114179. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Kosmopoulos, D.; Oikonomidis, I.; Constantinopoulos, C.; Arvanitis, N.; Antzakas, K.; Bifis, A.; Lydakis, G.; Roussos, A.; Argyros, A. Towards a visual Sign Language dataset for home care services. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 May 2020; pp. 520–524. [Google Scholar]
- Sincan, O.M.; Keles, H.Y. Autsl: A large scale multi-modal turkish sign language dataset and baseline methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Adaloglou, N.M.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.; Antzakas, K.; Papazachariou, D.; Daras, P. A Comprehensive Study on Deep Learning-based Methods for Sign Language Recognition. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Mittal, A.; Kumar, P.; Roy, P.P.; Balasubramanian, R.; Chaudhuri, B.B. A modified LSTM model for continuous sign language recognition using leap motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- Meng, X.; Feng, L.; Yin, X.; Zhou, H.; Sheng, C.; Wang, C.; Du, A.; Xu, L. Sentence-Level Sign Language Recognition Using RF signals. In Proceedings of the IEEE 2019 6th International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Beijing, China, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Galea, L.C.; Smeaton, A.F. Recognising Irish sign language using electromyography. In Proceedings of the IEEE 2019 International Conference on Content-Based Multimedia Indexing (CBMI), Dublin, Ireland, 4–6 September 2019; pp. 1–4. [Google Scholar]
- Zhang, Q.; Wang, D.; Zhao, R.; Yu, Y. MyoSign: Enabling end-to-end sign language recognition with wearables. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019; pp. 650–660. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hou, J.; Li, X.Y.; Zhu, P.; Wang, Z.; Wang, Y.; Qian, J.; Yang, P. Signspeaker: A real-time, high-precision smartwatch-based sign language translator. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–15. [Google Scholar]
- Wang, Z.; Zhao, T.; Ma, J.; Chen, H.; Liu, K.; Shao, H.; Wang, Q.; Ren, J. Hear Sign Language: A Real-time End-to-End Sign Language Recognition System. IEEE Trans. Mob. Comput. 2020. [Google Scholar] [CrossRef]
- How, D.N.T.; Ibrahim, W.Z.F.B.W.; Sahari, K.S.M. A Dataglove Hardware Design and Real-Time Sign Gesture Interpretation. In Proceedings of the IEEE 2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19thInternational Symposium on Advanced Intelligent Systems (ISIS), Toyama, Japan, 5–8 December 2018; pp. 946–949. [Google Scholar]
- Forster, J.; Schmidt, C.; Koller, O.; Bellgardt, M.; Ney, H. Extensions of the Sign Language Recognition and Translation Corpus RWTH-PHOENIX-Weather. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 1911–1916. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7784–7793. [Google Scholar]
- Albanie, S.; Varol, G.; Momeni, L.; Afouras, T.; Chung, J.S.; Fox, N.; Zisserman, A. BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 35–53. [Google Scholar]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Pu, J.; Zhou, W.; Li, H. Sign language recognition with multi-modal features. In Pacific Rim Conference on Multimedia; Springer: Cham, Switzerland, 2016; pp. 252–261. [Google Scholar]
- Zhang, J.; Zhou, W.; Xie, C.; Pu, J.; Li, H. Chinese sign language recognition with adaptive HMM. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Joze, H.R.V.; Koller, O. Ms-asl: A large-scale data set and benchmark for understanding american sign language. arXiv 2018, arXiv:1812.01053. [Google Scholar]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Ronchetti, F.; Quiroga, F.; Estrebou, C.A.; Lanzarini, L.C.; Rosete, A. LSA64: An Argentinian sign language dataset. In Proceedings of the XXII Congreso Argentino de Ciencias de la Computación (CACIC 2016), Argentina, South America, 3–7 October 2016. [Google Scholar]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. Chalearn looking at people rgb-d isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 56–64. [Google Scholar]
- Sidig, A.A.I.; Luqman, H.; Mahmoud, S.; Mohandes, M. KArSL: Arabic Sign Language Database. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–19. [Google Scholar] [CrossRef]
- Klakow, D.; Peters, J. Testing the correlation of word error rate and perplexity. Speech Commun. 2002, 38, 19–28. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. A deep neural framework for continuous sign language recognition by iterative training. IEEE Trans. Multimed. 2019, 21, 1880–1891. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Koishybay, K.; Mukushev, M.; Sandygulova, A. Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-tuning. In Proceedings of the IEEE 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 10211–10218. [Google Scholar]
- Cheng, K.L.; Yang, Z.; Chen, Q.; Tai, Y.W. Fully Convolutional Networks for Continuous Sign Language Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 697–714. [Google Scholar]
- Niu, Z.; Mak, B. Stochastic Fine-Grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 172–186. [Google Scholar]
- Pan, W.; Zhang, X.; Ye, Z. Attention-Based Sign Language Recognition Network Utilizing Keyframe Sampling and Skeletal Features. IEEE Access 2020, 8, 215592–215602. [Google Scholar]
- Huang, S.; Ye, Z. Boundary-Adaptive Encoder With Attention Method for Chinese Sign Language Recognition. IEEE Access 2021, 9, 70948–70960. [Google Scholar] [CrossRef]
- Li, H.; Gao, L.; Han, R.; Wan, L.; Feng, W. Key Action and Joint CTC-Attention based Sign Language Recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 2348–2352. [Google Scholar]
- Slimane, F.B.; Bouguessa, M. Context Matters: Self-Attention for Sign Language Recognition. In Proceedings of the IEEE 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 7884–7891. [Google Scholar]
- Zhou, M.; Ng, M.; Cai, Z.; Cheung, K.C. Self-Attention-based Fully-Inception Networks for Continuous Sign Language Recognition. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 2832–2839. [Google Scholar]
- Zhang, Z.; Pu, J.; Zhuang, L.; Zhou, W.; Li, H. Continuous sign language recognition via reinforcement learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 285–289. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Wei, C.; Zhao, J.; Zhou, W.; Li, H. Semantic Boundary Detection with Reinforcement Learning for Continuous Sign Language Recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1138–1149. [Google Scholar] [CrossRef]
- Papastratis, I.; Dimitropoulos, K.; Konstantinidis, D.; Daras, P. Continuous sign language recognition through cross-modal alignment of video and text embeddings in a joint-latent space. IEEE Access 2020, 8, 91170–91180. [Google Scholar] [CrossRef]
- Papastratis, I.; Dimitropoulos, K.; Daras, P. Continuous Sign Language Recognition through a Context-Aware Generative Adversarial Network. Sensors 2021, 21, 2437. [Google Scholar] [CrossRef]
- Wei, C.; Zhou, W.; Pu, J.; Li, H. Deep grammatical multi-classifier for continuous sign language recognition. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 435–442. [Google Scholar]
- Pu, J.; Zhou, W.; Li, H. Iterative alignment network for continuous sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4165–4174. [Google Scholar]
- Cuturi, M.; Blondel, M. Soft-dtw: A differentiable loss function for time-series. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 894–903. [Google Scholar]
- Guo, D.; Wang, S.; Tian, Q.; Wang, M. Dense Temporal Convolution Network for Sign Language Translation. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 744–750. [Google Scholar]
- Pei, X.; Guo, D.; Zhao, Y. Continuous Sign Language Recognition Based on Pseudo-supervised Learning. In Proceedings of the 2nd Workshop on Multimedia for Accessible Human Computer Interfaces, Nice, France, 25 October 2019; pp. 33–39. [Google Scholar]
- Zhou, H.; Zhou, W.; Li, H. Dynamic pseudo label decoding for continuous sign language recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1282–1287. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Chakrabarty, A.; Pandit, O.A.; Garain, U. Context sensitive lemmatization using two successive bidirectional gated recurrent networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1481–1491. [Google Scholar]
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-Temporal Multi-Cue Network for Sign Language Recognition and Translation. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Rastgoo, R.; Kiani, K.; Escalera, S. Video-based isolated hand sign language recognition using a deep cascaded model. Multimed. Tools Appl. 2020, 79, 22965–22987. [Google Scholar] [CrossRef]
- Kumar, D.A.; Sastry, A.; Kishore, P.; Kumar, E.K.; Kumar, M.T.K. S3DRGF: Spatial 3-D relational geometric features for 3-D sign language representation and recognition. IEEE Signal Process. Lett. 2018, 26, 169–173. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Fu, K. DABNet: Deformable contextual and boundary-weighted network for cloud detection in remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2021. [Google Scholar] [CrossRef]
- Liao, Y.; Xiong, P.; Min, W.; Min, W.; Lu, J. Dynamic sign language recognition based on video sequence with BLSTM-3D residual networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Aly, S.; Aly, W. DeepArSLR: A novel signer-independent deep learning framework for isolated arabic sign language gestures recognition. IEEE Access 2020, 8, 83199–83212. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Gökçe, Ç.; Özdemir, O.; Kındıroğlu, A.A.; Akarun, L. Score-level Multi Cue Fusion for Sign Language Recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 294–309. [Google Scholar]
- Zhang, X.; Li, X. Dynamic gesture recognition based on MEMP network. Future Internet 2019, 11, 91. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Yu, X.; Xu, C.; Petersson, L.; Li, H. Transferring cross-domain knowledge for video sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 6205–6214. [Google Scholar]
- Sarhan, N.; Frintrop, S. Transfer Learning For Videos: From Action Recognition To Sign Language Recognition. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1811–1815. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Hand sign language recognition using multi-view hand skeleton. Expert Syst. Appl. 2020, 150, 113336. [Google Scholar] [CrossRef]
- Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Sign language recognition based on hand and body skeletal data. In Proceedings of the IEEE 2018-3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Stockholm, Sweden, 3–5 June 2018; pp. 1–4. [Google Scholar]
- Konstantinidis, D.; Dimitropoulos, K.; Daras, P. A deep learning approach for analyzing video and skeletal features in sign language recognition. In Proceedings of the 2018 IEEE International Conference on Imaging Systems and Techniques (IST), Krakow, Poland, 16–18 October 2018; pp. 1–6. [Google Scholar]
- Papadimitriou, K.; Potamianos, G. Multimodal Sign Language Recognition via Temporal Deformable Convolutional Sequence Learning. In Proceedings of the INTERSPEECH 2020, Shanghai, China, 25–29 October 2020; pp. 2752–2756. [Google Scholar]
- Gündüz, C.; POLAT, H. Turkish sign language recognition based on multistream data fusion. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 1171–1186. [Google Scholar] [CrossRef]
- Bilge, Y.C.; Ikizler-Cinbis, N.; Cinbis, R.G. Zero-Shot Sign Language Recognition: Can Textual Data Uncover Sign Languages? arXiv 2019, arXiv:1907.10292. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kumar, E.K.; Kishore, P.; Kumar, M.T.K.; Kumar, D.A. 3D sign language recognition with joint distance and angular coded color topographical descriptor on a 2–stream CNN. Neurocomputing 2020, 372, 40–54. [Google Scholar] [CrossRef]
- Parelli, M.; Papadimitriou, K.; Potamianos, G.; Pavlakos, G.; Maragos, P. Exploiting 3D hand pose estimation in deep learning-based sign language recognition from RGB videos. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 249–263. [Google Scholar]
- de Amorim, C.C.; Macêdo, D.; Zanchettin, C. Spatial-temporal graph convolutional networks for sign language recognition. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 646–657. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2016; pp. 2014–2023. [Google Scholar]
- Tunga, A.; Nuthalapati, S.V.; Wachs, J. Pose-based Sign Language Recognition using GCN and BERT. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 31–40. [Google Scholar]
- Meng, L.; Li, R. An Attention-Enhanced Multi-Scale and Dual Sign Language Recognition Network Based on a Graph Convolution Network. Sensors 2021, 21, 1120. [Google Scholar] [CrossRef]
- Tur, A.O.; Keles, H.Y. Isolated sign recognition with a siamese neural network of RGB and depth streams. In Proceedings of the IEEE EUROCON 2019—18th International Conference on Smart Technologies, Novi Sad, Serbia, 1–4 July 2019; pp. 1–6. [Google Scholar]
- Ravi, S.; Suman, M.; Kishore, P.; Kumar, K.; Kumar, A. Multi modal spatio temporal co-trained CNNs with single modal testing on RGB–D based sign language gesture recognition. J. Comput. Lang. 2019, 52, 88–102. [Google Scholar] [CrossRef]
- Rastgoo, R.; Kiani, K.; Escalera, S. Hand pose aware multimodal isolated sign language recognition. Multimed. Tools Appl. 2021, 80, 127–163. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Attention-based 3D-CNNs for large-vocabulary sign language recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2822–2832. [Google Scholar] [CrossRef]
- Huang, S.; Mao, C.; Tao, J.; Ye, Z. A novel chinese sign language recognition method based on keyframe-centered clips. IEEE Signal Process. Lett. 2018, 25, 442–446. [Google Scholar] [CrossRef]
- Zhang, S.; Meng, W.; Li, H.; Cui, X. Multimodal Spatiotemporal Networks for Sign Language Recognition. IEEE Access 2019, 7, 180270–180280. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Orbay, A.; Akarun, L. Neural Sign Language Translation by Learning Tokenization. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020) (FG), Buenos Aires, Argentina, 16–20 November 2020; pp. 9–15. [Google Scholar]
- Ko, S.K.; Kim, C.J.; Jung, H.; Cho, C. Neural sign language translation based on human keypoint estimation. Appl. Sci. 2019, 9, 2683. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Zhao, Z.; Chen, M.; Chen, J.; Wu, C.; Chen, Y.; Shi, X.; Tong, Y. An Improved Sign Language Translation Model with Explainable Adaptations for Processing Long Sign Sentences. Comput. Intell. Neurosci. 2020, 2020. [Google Scholar] [CrossRef]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Snowmass Village, CO, USA, 1–5 March 2020; pp. 10023–10033. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Multi-channel transformers for multi-articulatory sign language translation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 301–319. [Google Scholar]
- Kim, S.; Kim, C.J.; Park, H.M.; Jeong, Y.; Jang, J.Y.; Jung, H. Robust Keypoint Normalization Method for Korean Sign Language Translation using Transformer. In Proceedings of the IEEE 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 21–23 October 2020; pp. 1303–1305. [Google Scholar]
- Balayn, A.; Brock, H.; Nakadai, K. Data-driven development of virtual sign language communication agents. In Proceedings of the 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Nanjing, China, 27–31 August 2018; pp. 370–377. [Google Scholar]
- Shaikh, F.; Darunde, S.; Wahie, N.; Mali, S. Sign language translation system for railway station announcements. In Proceedings of the 2019 IEEE Bombay Section Signature Conference (IBSSC), Mumbai, India, 26–28 July 2019; pp. 1–6. [Google Scholar]
- Melchor, F.B.; Palacios, J.C.A.; Pichardo-Lagunas, O.; Martinez-Seis, B. Speech to Mexican Sign Language for Learning with an Avatar. In Mexican International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 179–192. [Google Scholar]
- Uchida, T.; Sumiyoshi, H.; Miyazaki, T.; Azuma, M.; Umeda, S.; Kato, N.; Hiruma, N.; Kaneko, H.; Yamanouchi, Y. Systems for Supporting Deaf People in Viewing Sports Programs by Using Sign Language Animation Synthesis. ITE Trans. Media Technol. Appl. 2019, 7, 126–133. [Google Scholar] [CrossRef] [Green Version]
- Das Chakladar, D.; Kumar, P.; Mandal, S.; Roy, P.P.; Iwamura, M.; Kim, B.G. 3D Avatar Approach for Continuous Sign Movement Using Speech/Text. Appl. Sci. 2021, 11, 3439. [Google Scholar] [CrossRef]
- Mehta, N.; Pai, S.; Singh, S. Automated 3D sign language caption generation for video. Univers. Access Inf. Soc. 2020, 19, 725–738. [Google Scholar] [CrossRef]
- Patel, B.D.; Patel, H.B.; Khanvilkar, M.A.; Patel, N.R.; Akilan, T. ES2ISL: An advancement in speech to sign language translation using 3D avatar animator. In Proceedings of the 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), London, ON, Canada, 30 August–2 September 2020; pp. 1–5. [Google Scholar]
- Hanke, T. HamNoSys-representing sign language data in language resources and language processing contexts. In Proceedings of the LREC, Lisbon, Portugal, 26–28 May 2004; Volume 4, pp. 1–6. [Google Scholar]
- Elliott, R.; Glauert, J.R.; Jennings, V.; Kennaway, J. An overview of the SiGML notation and SiGML Signing software system. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC), Lisbon, Portugal, 26–28 May 2004; pp. 98–104. [Google Scholar]
- Kumar, P.; Kaur, S. Indian Sign Language Generation System. Computer 2021, 54, 37–46. [Google Scholar]
- Kumar, P.; Kaur, S. Sign Language Generation System Based on Indian Sign Language Grammar. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 19, 1–26. [Google Scholar] [CrossRef]
- Brock, H.; Law, F.; Nakadai, K.; Nagashima, Y. Learning three-dimensional skeleton data from sign language video. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–24. [Google Scholar] [CrossRef]
- Stoll, S.; Camgöz, N.C.; Hadfield, S.; Bowden, R. Sign language production using neural machine translation and generative adversarial networks. In Proceedings of the 29th British Machine Vision Conference (BMVC 2018), Newcastle, UK, 2–6 September 2018; British Machine Vision Association: Newcastle, UK, 2018. [Google Scholar]
- Stoll, S.; Camgoz, N.C.; Hadfield, S.; Bowden, R. Text2Sign: Towards sign language production using neural machine translation and generative adversarial networks. Int. J. Comput. Vis. 2020, 128, 891–908. [Google Scholar] [CrossRef] [Green Version]
- Stoll, S.; Hadfield, S.; Bowden, R. SignSynth: Data-Driven Sign Language Video Generation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 353–370. [Google Scholar]
- Saunders, B.; Camgoz, N.C.; Bowden, R. Progressive transformers for end-to-end sign language production. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 687–705. [Google Scholar]
- Xiao, Q.; Qin, M.; Yin, Y. Skeleton-based Chinese sign language recognition and generation for bidirectional communication between deaf and hearing people. Neural Netw. 2020, 125, 41–55. [Google Scholar] [CrossRef]
- Cui, R.; Cao, Z.; Pan, W.; Zhang, C.; Wang, J. Deep Gesture Video Generation With Learning on Regions of Interest. IEEE Trans. Multimed. 2019, 22, 2551–2563. [Google Scholar] [CrossRef]
- Liang, X.; Angelopoulou, A.; Kapetanios, E.; Woll, B.; Al Batat, R.; Woolfe, T. A multi-modal machine learning approach and toolkit to automate recognition of early stages of dementia among British sign language users. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 278–293. [Google Scholar]
- Zhou, Z.; Neo, Y.; Lui, K.S.; Tam, V.W.; Lam, E.Y.; Wong, N. A Portable Hong Kong Sign Language Translation Platform with Deep Learning and Jetson Nano. In Proceedings of the 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual, 26–28 October 2020; pp. 1–4. [Google Scholar]
- Ozarkar, S.; Chetwani, R.; Devare, S.; Haryani, S.; Giri, N. AI for Accessibility: Virtual Assistant for Hearing Impaired. In Proceedings of the IEEE 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–7. [Google Scholar]
- Joy, J.; Balakrishnan, K.; Sreeraj, M. SiLearn: An intelligent sign vocabulary learning tool. J. Enabling Technol. 2019, 13, 173–187. [Google Scholar] [CrossRef]
- Paudyal, P.; Lee, J.; Kamzin, A.; Soudki, M.; Banerjee, A.; Gupta, S.K. Learn2Sign: Explainable AI for Sign Language Learning. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 16–20 March 2019. [Google Scholar]
- Luccio, F.L.; Gaspari, D. Learning Sign Language from a Sanbot Robot. In Proceedings of the 6th EAI International Conference on Smart Objects and Technologies for Social Good, Antwerp, Belgium, 14–16 September 2020; pp. 138–143. [Google Scholar]
- Chaikaew, A.; Somkuan, K.; Sarapee, P. Mobile Application for Thai Sign language. In Proceedings of the IEEE 2018 22nd International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 21–24 November 2018; pp. 1–4. [Google Scholar]
- Ku, Y.J.; Chen, M.J.; King, C.T. A Virtual Sign Language Translator on Smartphones. In Proceedings of the IEEE 2019 Seventh International Symposium on Computing and Networking Workshops (CANDARW), Nagasaki, Japan, 26–29 November 2019; pp. 445–449. [Google Scholar]
- Potamianos, G.; Papadimitriou, K.; Efthimiou, E.; Fotinea, S.E.; Sapountzaki, G.; Maragos, P. SL-ReDu: Greek sign language recognition for educational applications. Project description and early results. In Proceedings of the 13th ACM International Conference on Pervasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June–3 July 2020; pp. 1–6. [Google Scholar]
- Lee, H.; Park, D. AI TTS Smartphone App for Communication of Speech Impaired People. In Data Science and Digital Transformation in the Fourth Industrial Revolution; Springer: Berlin/Heidelberg, Germany, 2021; pp. 219–229. [Google Scholar]
- Schioppo, J.; Meyer, Z.; Fabiano, D.; Canavan, S. Sign Language Recognition: Learning American Sign Language in a Virtual Environment. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Bansal, D.; Ravi, P.; So, M.; Agrawal, P.; Chadha, I.; Murugappan, G.; Duke, C. CopyCat: Using Sign Language Recognition to Help Deaf Children Acquire Language Skills. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Virtual, 8–13 May 2021; pp. 1–10. [Google Scholar]
- Quandt, L.C.; Lamberton, J.; Willis, A.S.; Wang, J.; Weeks, K.; Kubicek, E.; Malzkuhn, M. Teaching ASL Signs using Signing Avatars and Immersive Learning in Virtual Reality. In Proceedings of the 22nd International ACM SIGACCESS Conference, on Computers and Accessibility, Virtual, 26–28 October 2020; pp. 1–4. [Google Scholar]
- Cass, S. Nvidia makes it easy to embed AI: The Jetson nano packs a lot of machine-learning power into DIY projects-[Hands on]. IEEE Spectr. 2020, 57, 14–16. [Google Scholar] [CrossRef]
- Sanbot Robot. Available online: https://www.sanbot.co.uk/#sanbot-robot (accessed on 8 August 2021).

{kind=link}
{kind=link}
{kind=link}
| Datasets | Characteristics | |||||||
|---|---|---|---|---|---|---|---|---|
| Language | Signers | Classes | Video Instances | Resolution | Type | Modalities | Year | |
| Phoenix-2014 [27] | German | 9 | 1231 | 6841 | 210 × 260 | CSLR | RGB | 2014 |
| CSL [30,31] | Chinese | 50 | 178 | 25,000 | 1920 × 1080 | CSLR | RGB, depth | 2016 |
| Phoenix-2014-T [28] | German | 9 | 1231 | 8257 | 210 × 260 | CSLR | RGB | 2018 |
| GRSL [15] | Greek | 15 | 1500 | 4000 | varying | CSLR | RGB, depth, skeleton | 2020 |
| BSL-1K [29] | British | 40 | 1064 | 273,000 | varying | CSLR | RGB | 2020 |
| GSL [17] | Greek | 7 | 310 | 10,295 | 848 × 480 | CSLR | RGB, depth | 2021 |
| CSL-500 [30,31] | Chinese | 50 | 500 | 125,000 | 1920 × 1080 | ISLR | RGB, depth | 2016 |
| MS-ASL [33] | American | 222 | 1000 | 25,513 | varying | ISLR | RGB | 2019 |
| WASL [34] | American | 119 | 2000 | 21,013 | varying | ISLR | RGB | 2020 |
| AUTSL [16] | Turkish | 43 | 226 | 38,336 | 512 × 512 | ISLR | RGB, depth | 2020 |
| KArSL [37] | Arabic | 3 | 502 | 75,300 | varying | ISLR | RGB, depth, skeleton | 2021 |
| Method | Input Modality | Dataset | Test Set (WER) |
|---|---|---|---|
| PL [58] | RGB | Phoenix-2014 | 40.6 |
| RL [49] | RGB | 38.3 | |
| Align-iOpt [55] | RGB | 36.7 | |
| DenseTCN [57] | RGB | 36.5 | |
| DPD [59] | RGB | 34.5 | |
| CNN-1D-RNN [41] | RGB | 34.4 | |
| Fully-Inception Networks [48] | RGB | 31.3 | |
| SAN [47] | RGB | 29.7 | |
| SFD [43] | RGB | 25.3 | |
| CrossModal [52] | RGB | 24.0 | |
| Fully-Conv-Net [42] | RGB | 23.9 | |
| SLRGAN [53] | RGB | 23.4 | |
| CNN-TEMP-RNN [39] | RGB+Optical flow | 22.8 | |
| STMC [62] | RGB+Hands+Skeleton | 20.7 | |
| DenseTCN [57] | RGB | CSL Split 1 | 14.3 |
| Key-action [46] | RGB | 9.1 | |
| Align-iOpt [55] | RGB | 6.1 | |
| WIC-NGC [54] | RGB | 5.1 | |
| DPD [59] | RGB | 4.7 | |
| Fully-Conv-Net [42] | RGB | 3.0 | |
| CrossModal [52] | RGB | 2.4 | |
| SLRGAN [53] | RGB | 2.1 | |
| STMC [62] | RGB+Hands+Skeleton | 2.1 | |
| Key-action [46] | RGB | CSL Split 2 | 49.1 |
| DenseTCN [57] | RGB | 44.7 | |
| Align-iOpt [55] | RGB | 32.7 | |
| STMC [62] | RGB+Hands+Skeleton | 28.6 | |
| CrossModal [52] | RGB | GSL SI | 3.52 |
| SLRGAN [53] | RGB | 2.98 | |
| CrossModal [52] | RGB | GSL SD | 41.98 |
| SLRGAN [53] | RGB | 37.11 |
| Method | Dataset | Accuracy (%) |
|---|---|---|
| Konstantinidis et al. [74] | LSA64 [35] | 98.09 |
| Zhang et al. [70] | 99.06 | |
| Konstantinidis et al. [75] | 99.84 | |
| Gündüz et al. [77] | 99.9 | |
| Huang et al. [89] | CSL-500 [31,32] | 91.18 |
| Zhang et al. [91] | 96.7 | |
| Meng et al. [85] | 97.36 | |
| Sarhan et al. [72] | IsoGD [36] | 62.09 |
| Zhang et al. [91] | 63.78 | |
| Zhang et al. [70] | 78.85 | |
| Rastgoo et al. [88] | 86.1 | |
| Rastgoo et al. [63] | 86.32 |
| Method | Validation Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | |
| Sign2Gloss2Text [28] | 42.88 | 30.30 | 23.02 | 18.40 | 43.29 | 30.39 | 22.82 | 18.13 |
| MCT [97] | - | - | - | 19.51 | - | - | 18.51 | |
| S2(G+T)-Transformer [96] | 47.26 | 34.40 | 27.05 | 22.38 | 46.61 | 33.73 | 26.19 | 21.32 |
| STMC-T [62] | 47.60 | 36.43 | 29.18 | 24.09 | 46.98 | 36.09 | 28.70 | 23.65 |
| Method | Operating System | Sign Language | Scenario |
|---|---|---|---|
| Liang et al. [117] | Windows desktop | British | Dementia screening |
| Zhou et al. [118] | iOS | Hong Kong | Translation |
| Ozarkar et al. [119] | Android | Indian | Translation |
| Joy et al. [120] | Android | Indian | Learning |
| Paudyal et al. [121] | Android | American | Learning |
| Luccio et al. [122] | Android | Multiple | Learning |
| Chaikaew et al. [123] | Android, iOS | Thai | Learning |
| Ku et al. [124] | - | American | Translation |
| Potamianos et al. [125] | - | Greek | Learning |
| Lee et al. [126] | - | Korean | Translation |
| Schioppo et al. [127] | - | American | Learning |
| Bansal et al. [128] | - | American | Learning |
| Quandt et al. [129] | - | American | Learning |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papastratis, I.; Chatzikonstantinou, C.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 2021, 21, 5843. https://doi.org/10.3390/s21175843
Papastratis I, Chatzikonstantinou C, Konstantinidis D, Dimitropoulos K, Daras P. Artificial Intelligence Technologies for Sign Language. Sensors. 2021; 21(17):5843. https://doi.org/10.3390/s21175843
Chicago/Turabian StylePapastratis, Ilias, Christos Chatzikonstantinou, Dimitrios Konstantinidis, Kosmas Dimitropoulos, and Petros Daras. 2021. "Artificial Intelligence Technologies for Sign Language" Sensors 21, no. 17: 5843. https://doi.org/10.3390/s21175843
APA StylePapastratis, I., Chatzikonstantinou, C., Konstantinidis, D., Dimitropoulos, K., & Daras, P. (2021). Artificial Intelligence Technologies for Sign Language. Sensors, 21(17), 5843. https://doi.org/10.3390/s21175843