1. Introduction
In recent years, companies have adopted a growing trend to migrate their services, data, and applications to cloud-based infrastructures, often attracted by reduced costs, availability, and flexibility. With the cloud, companies have the flexibility to perform dynamic workloads without ever needing additional hardware, allowing them to store new types of data or create new business opportunities without significant infrastructure commitments. However, the migration to the cloud is a process that involves solving new security and privacy issues that were non-existent for on-premise deployments. In the cloud, the lack of visibility and transparency about data processing leads to users losing control over their data [
1]. Companies need to analyze the cost of having their privacy compromised due to some security issues regarding cloud migration that are not solved yet [
2].
Over the years, many technologies have emerged [
3] to reduce users’ data exposure to unauthorized parties, namely, anonymization tools and cloud-of-clouds. Data analysis without knowledge of plain text data is one of the most promising challenges for ensuring user privacy. Data privacy has been a growing concern over the years. For example, Android and iOS apps collect users’ data, namely their behavior, and companies benefit from these data. It is important to note that, even if companies do not collect behavioral data, much of the data sent by mobile devices may be considered sensitive or identifiable [
4], such as IPs, GPS, and MAC addresses, requiring processing to ensure that the collected data are no longer able to identify an individual.
The issue with re-identification—the process of identifying an individual using the collected data—is even greater in cases where data collected by different companies are aggregated, creating a larger dataset and increasing the likelihood of re-identification [
5].
Due to these facts, it is of utmost importance to create pseudo-anonymization protocols so that it is possible to collect patterns about the population without uniquely identifying a user. To this end, this paper explores the usage of anonymization techniques, such as the removal of HIPAA. The HIPAA identifiers are managed by a HIPAA Privacy Rule that establishes national standards to protect individuals’ medical records and other personal health information and applies to health plans, such as name, phone number, address, or postal code. The identifiers, provided by the HIPAA privacy rule, sets forth policies to protect all individually identifiable health information that is held or transmitted [
6]. We also explore the use of MPC (reviewed in
Section 3.4) to exchange information without sharing the cleartext dataset with the other party. MPC provides the critical notion of learning with encrypted data, increasing the trust level and strengthening privacy properties.
In this work, we present a solution that improves user privacy based on a hybrid architecture composed by a local server capable of performing anonymity, MPC, and encryption as well as a public cloud storage component, based on the cloud-of-clouds concept, which is responsible for storing the data received from users confidentially and integrally, providing an extra layer of security with the
data at rest.
Data at rest in information technology means data that are housed physically on computer data storage in any digital form [
7].
Our solution covers the following goals:
Maintains data privacy on the public cloud storage;
Enables cooperation between institutions, through data sharing, without compromising privacy;
Enables data sharing among users;
Uses secure enclaves to increase trust on the private key management;
Reduces, as much as possible, the performance overheads.
The paper is organized as follows:
Section 1 is the introduction and contextualization where we define the assumptions and main contributions.
Section 2 contains the related cloud storage systems and background knowledge about federated learning. In
Section 3, we detail the architecture and the specific implementations/features available in the system.
Section 4 includes the security evaluation of the system, and
Section 5 contains tests performed on the platform, focusing first on the enclaves technologies and then on the system scalability. Lastly,
Section 6 is the future work direction and the conclusion of the work.
1.1. Assumptions
This work assumes that the on-premise server is trustworthy, and therefore, this server is capable of receiving cleartext data from users, performing all privacy-preserving operations, and storing the data off-premise. The threat model assumed for the on-premise server is the typical threat model applied to Intel SGX enclaves, specifically in a trusted cloud environment [
8,
9]. SGX allows the operating system and user-level code to define private regions of memory, called enclaves, whose contents are protected and cannot be read or saved by any process outside the enclave itself, including processes running at higher privilege levels. Additionally, for the system, we assume that any internal process, such as sync information, can be performed using master–slave approaches.
1.2. Contributions
The work presented here provides the following contributions:
Run-time Adjustable Privacy Schemes (RAPS): Given the multitude of possible workloads for which our solution aims to provide support for data sharing, MPC, cloud-of-clouds, we have designed an adjustable privacy mechanism that enables us to tweak the anonymization, storage location, and persistence parameters, allowing them to have more control over the processing that their data might suffer.
Anonymization of sensitive data: When the system detects, using the parameters established on the RAPS, a possible privacy leakage or any other identifiable attribute defined on the scheme, it stores in on-premise storage that specific attribute identified from the dataset. This step is essential before sharing information with other parties, as it enhances anonymization and privacy.
Secure sharing with Machine Learning: When we analyze the data-sharing mechanism on the cloud, we usually have one option to share the entire content of the file. We extend this feature with the possibility of sharing information after removing personal identifiers to allow learning, using MPC or HE protocols.
Cloud-of-clouds deployment: The cloud-of-clouds deployment ensures that the data at rest are not entirely accessible to any public cloud provider. The different clouds only have the vision of a part of the encrypted data. Even if they uncover the encryption keys, they can only access a portion of the file.
SGX integration: We use the Public Key Infrastructure (PKI) as the basis of secure client–server communication, which is based on HTTPS. However, issues related to the private key storage protection on a PKI infrastructure force us to adopt hardware-based solutions. With Intel SGX, we prevent the exposure of the private key by attackers since it never leaves the enclave. This private key protection layer ensures that, even if the system is compromised, the private key associated with the HTTPS communication is secure on the enclave and inaccessible to the attacker, preventing the disclosure of previous HTTPS communications.
Implementation Prototype: We have a working implementation prototype described in this paper. The server includes all the cryptographic computations, being those built on top of OpenSSL and the SGX infrastructure. Our implementation focuses on confidentiality, integrity, availability, persistency, and privacy preservation. In addition to the on-premise server, our implementation contains a front-end Android app capable of fully interacting with the on-premise services.
3. Architecture Overview
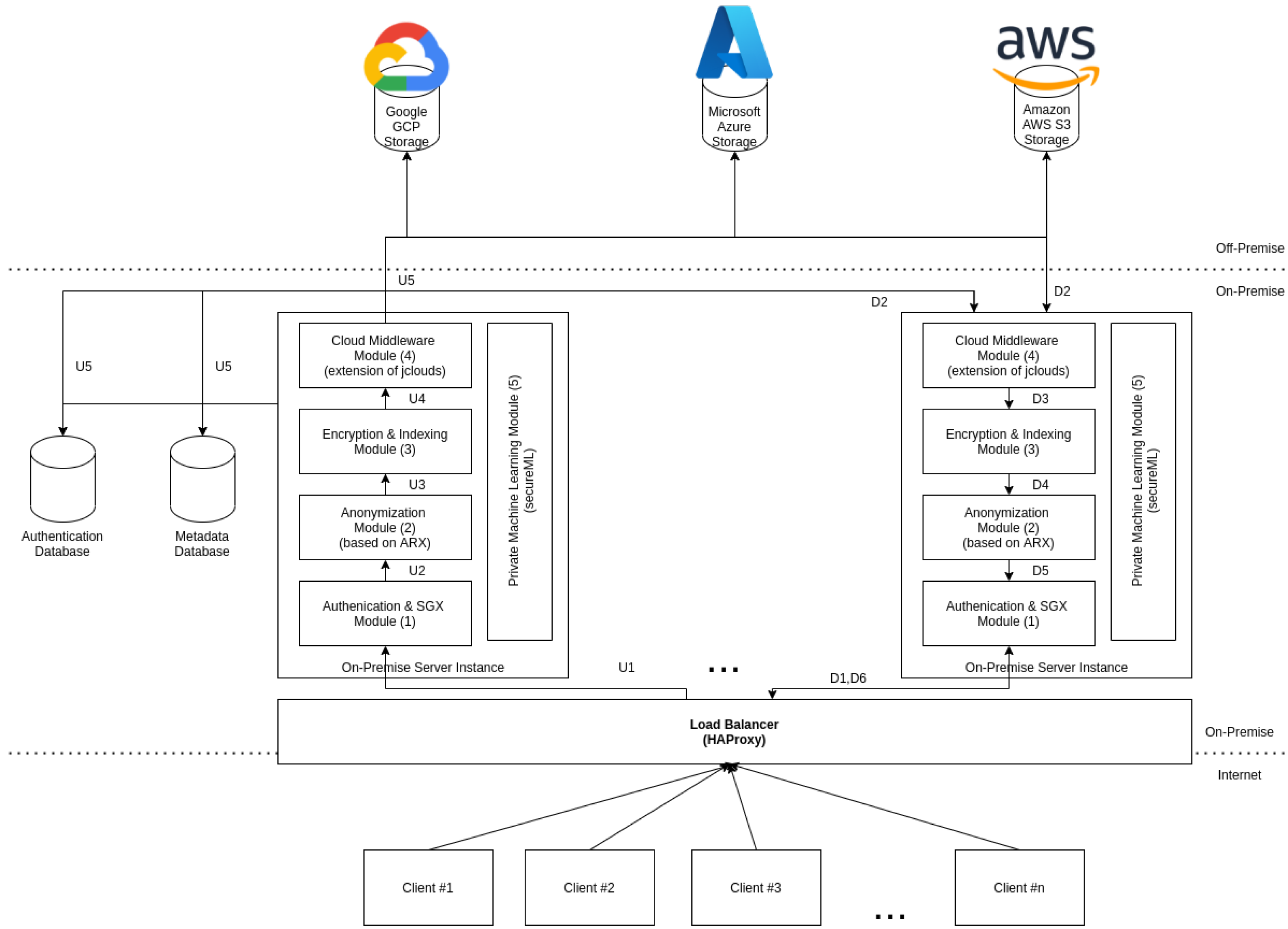
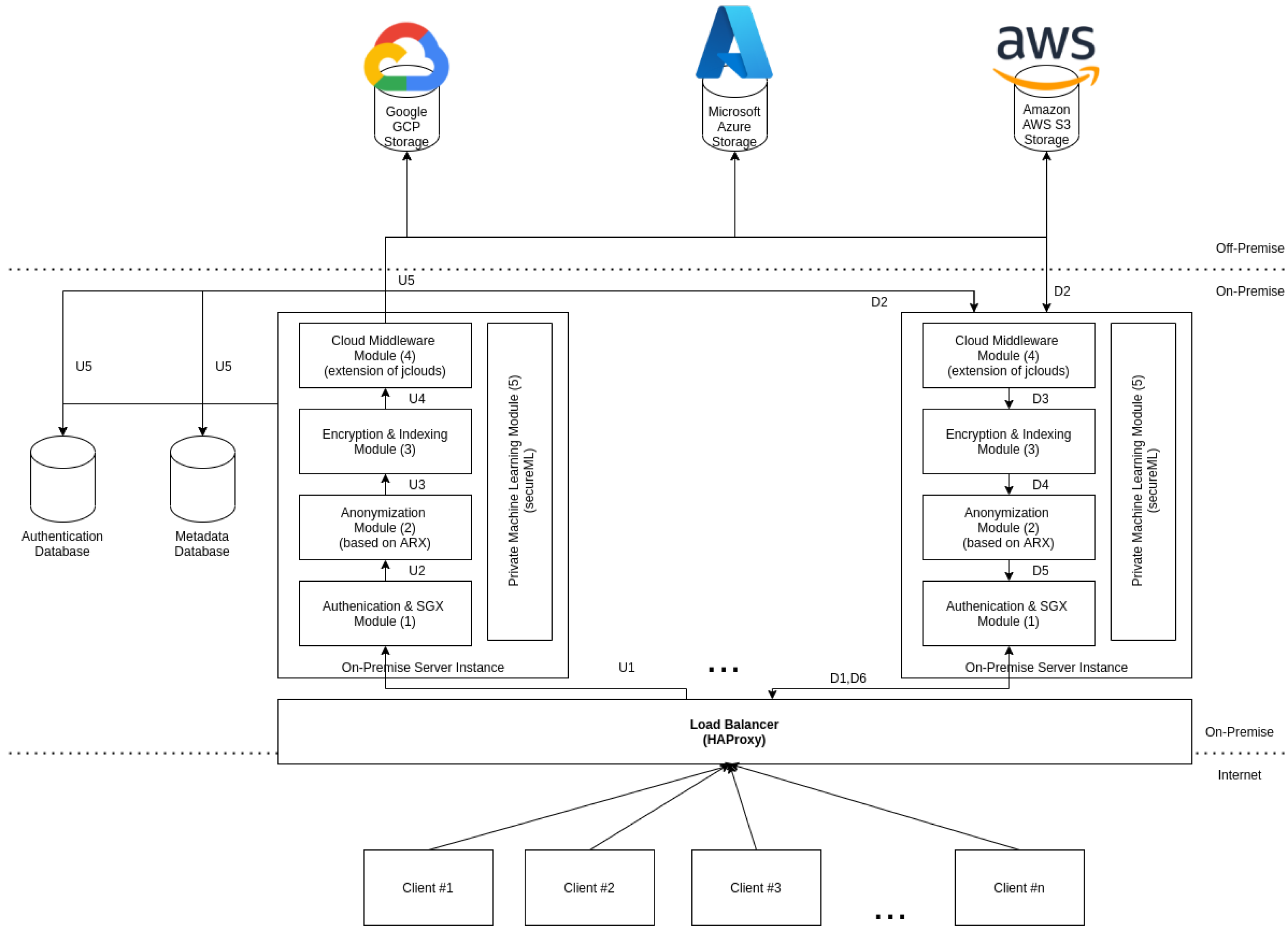
The overall system architecture, represented by
Figure 2, contains three main components: clients, cloud providers, and the on-premise server.
An Android device represents the client with an application capable of sending information to the on-premise server. The on-premise server is the most critical component, as it performs all the necessary tasks to ensure that the clients can use public/private cloud storage. The on-premise server is composed of five main modules:
Authentication and SGX module: it is capable of performing user authentication and serves as TLS termination for the remaining of the on-premise server. The private key associated with the TLS communication is stored on the secure enclave, it being the responsibility of this module to manage the SGX secure enclave as well.
Anonymization module: it enables the anonymization of datasets, documents, photos, or videos, according to the currently active RAPS. This module is also responsible for creating and managing RAPS.
Encryption and indexing module: it is capable of leveraging algorithms that ensure confidentiality and integrity on the data to be uploaded to the cloud. All the metadata produced by this process is stored on an on-premise database.
Private machine learning module: it is based on SecureML, enabling two distinct organizations to train an ML model using their private information, but neither organization has access to the raw private information, only encrypted versions of it, improving privacy and mitigating uncontrolled distribution of private data.
Cloud middleware module: it is based on jClouds, and ensures the proper persistence of the data uploaded across the cloud-of-clouds by using erasure encoding techniques. The component is also responsible for erasure by decoding the data on a download request and providing access to the private cloud storage.
Our architecture is designed to be easily scalable by reducing the number of states that the on-premise server manages locally, which allows the on-premise server to be easily replicated when required. Placing a load balancer between the users and the on-premise server allows loading balance of the requests across all the replicas instantiated on-premise, allowing the system to scale with the increasing number of concurrent users.
In our architecture, the user needs to be authenticated with the on-premise server to upload a file and communicating via
HTTPS; otherwise, the connection is refused by the Authentication and SGX module (1). When the user uploads a file,
Figure 2 is left, the content is analyzed according to the file type and active RAPS. If personal data are detected, it splits the information according to the anonymization algorithm that applies to the received file type. Depending on the file type, automatic personal data detection may not detect all the personal data on the file. To cope with this, we allow the user to send the file together with a list of portions of the file content that contain personal information. The anonymization uses that information to redact the personal data from the received file, storing the private information on the private cloud (2). After an anonymization process, two files are generated: one stored on the private cloud, containing the personal data, and the other stored on the public cloud, containing the remaining data. Data must be encrypted and split (3) before uploading it to the different public cloud providers configured (4). A hash is generated for the split data chunks used to verify the integrity of the data on the download process. The hash, the encryption keys, and additional file metadata are stored in an index, allowing the on-premise server to know which files are stored and how to retrieve them. The upload process can be seen as a sequential process that starts in U1 up to the storage in U5. Contrarily to the upload of a file, the download is more complicated. It consists of the same processes, but the order is different. First, the user is authenticated in the system (D1), then the information is collected from the cloud-of-clouds and private storage (D2), then the file recovers the original format and is checked against the HMAC (D3), and finally, the final step is the analysis of the personal identifiers (D4) to recreate the final file to return to the client (D5).
In addition to the process of uploading and download files, we also allow on-premise server instances on different organizations to jointly compute ML models, using privacy-preserving multi-party computation protocols (5).
In the following sections, we will discuss each module in more detail, specifying the implementation details.
3.1. Authentication and SGX Module
Internet transactions create security challenges, such as impersonation attacks, in which the attacker can present her/himself as a trusted entity. Franco et al. [
32] describe an example attack where a fake trusted entity tries to use or extract information from the source to make the user believe that they are talking to a legitimate source.
These types of compromises can then affect authentication systems or allow them to reveal confidential information exchanged in previous transactions. The authentication and the session key’s management are essential for us, as an attacker can compromise the current and previous communications by only accessing the private key or the session key of an
HTTPS server. This problem increases if the information is sent in cleartext to the on-premise server. In this scenario, the user must trust the server, so it is paramount that the private key is kept private in any way. To do this, we intend to include all the crucial parts of the computations inside the SGX and use an authentication system to delegate the authorization and authentication to manipulate and request files from the cloud. With systems like SGX, even privileged code is blocked from reading and altering enclave memory: illegal accesses result in CPU exceptions, and read access to enclave memory will always return 0xFF [
8].
Similar systems do not address this issue, as they assume a client that performs uploads to and management of the cloud [
22], or that the server is trusted and not vulnerable to impersonation attacks.
In our implementation, we followed the idea from André Brandão et al. [
33], where the authors modified the Apache webserver SSL module to integrate with Intel SGX, enabling protection against attacks that attempt to compromise the private key. We used the Apache SSL module from the same authors to create a TLS termination point proxy, where all the communications to the premise must travel through before reaching the remainder of on-premise modules. In this proxy, the authentication verification is performed, denying access to the remainder of on-premise modules if the requests are unauthenticated. For the authentication, we used the KeyCloak [
34], which uses tokens to assess the identity of the users behind the request.
3.2. Anonymization Module
Data anonymization is a process by which the personal data are altered to not enable identification by any party that has access to the anonymized contents. Data anonymization increases user privacy and maintains data usability for data analysis procedures, including ML training algorithms. Depending on the model, ML algorithms usually do not require identifiable information (information that can directly or indirectly identify an individual) to be present in order for them to provide satisfactory results. These procedures often look to sensitive attributes, such as illness or income that, once successfully de-linked from an individual, can be used without imposing risks of identifying the individual and, therefore, not compromising their privacy.
The anonymization module is connected to the output of the Authentication and SGX module, meaning that the requests it receives are from authenticated users. When the anonymization module receives a file, it first checks the file type and loads the anonymization algorithm that best deals with that kind of file type. In our implementation prototype, we only deal with the CSV file type anonymization, using K-Anonymity. Then, the anonymization module checks whether the user has added some information about personal data regions on the file, and if they have, that information is passed to the anonymization algorithm that anonymizes the file. Otherwise, the anonymization module checks the file for HIPAA identifiers and passes that information to the anonymization algorithm as personal information to be removed. The remainder anonymization parameters are defined on the active RAPS.
In more detail, K-Anonymity, created by L. Sweeney [
35], is a formal model of privacy that aims to make each record indistinguishable from a defined
K number of other records. This way, an attacker cannot identify the individual represented by the record, as there are
other records with similar information.
A dataset is considered K-Anonymized when, for any data record with a given set of identifiable attributes, there are at least other records with the same attributes. To simplify the anonymization of a dataset, the K-Anonymity assigns properties to data attributes that should be treated differently depending on its risk of identifying the individual. There are three types of attributes: Key, Quasi-identifier, and Sensitive.
Key attributes can identify an individual directly without needing access to any external information, such as names, emails, and social security numbers. Key attributes require removal or obscurity, and the latter can be performed using translation tables.
Quasi-identifiers are attributes that can, with the help of external information, identify an individual. Quasi-identifiers, such as zip-codes, birthday, and gender, are the main concern of K-Anonymity, requiring suppression or generalization so that, at least, there must be K data records with similar quasi-identifiers.
Sensitive attributes are those that an individual is sensitive about revealing, such as income or type of illness, that must be de-linked from the individual to ensure individual anonymity.
The anonymization module is also responsible for managing RAPS. When the RAPS need to be modified, the on-premise server administrator issues new RAPS, and that change has an immediate effect on all the future incoming connections without needing a server restart, enabling us to achieve the run-time adjustability that our solution requires. The active RAPS are stored on a synchronized database to be accessible to all the on-premise server replicas accepting connections. It is implemented in the master–slave approach, where the master is responsible for delegating to the slaves the information.
After the anonymization process, the anonymized data are sent to the encryption and indexing module to process the anonymized file for secure off-premise cloud storage.
3.3. Encryption and Indexing Module
The generation and management of encryption keys must be kept as secure as possible, using international standards. To achieve this, we will focus on the requirements of NIST [
36] to create a state-of-the-art tool. The indexing process locally encrypts all information about the data uploaded to the cloud, including a hash to detect possible unauthorized changes to the block in the cloud after storage.
In our implementation, for each file uploaded, a new AES 256 bit key is generated, and the file is erasure-encoded using Reed Solomon encoding [
37], resulting in a series of file shards. A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance to spread load. [
38]. These shards can become corrupted without losing any information of the file when it is reconstructed. We set our Reed Solomon encoding to output three shards: two of data and one of parity, meaning that we can lose one shard of data or parity, and the system can reconstruct the file without any data loss. To each of the shards outputted by the Reed Solomon encoding, we generate a random 128 bit IV and encrypt the shard, using the AES-CBC with the key created for the file and the IV generated for the shard. To the encryption result, we perform integrity protection in the form of an HMAC. HMAC allows us to add integrity and authenticity properties to the shard on top of the confidentiality provided by encryption. The key used for HMAC is generated for each new file created.
All the metadata generated by this process, namely AES key, HMAC, and IVs, are stored on the synchronized metadata database (similar to the RAPS database) on a new entry that contains the file name and the user that published the file. The encrypted shards are sent to the cloud middleware module that sends each one of the encrypted shards to a different cloud provider, limiting the sovereignty that each provider has over the data.
3.4. Privacy-Preserving Machine Learning Module
The privacy-preserving ML aims to extract useful information from data, while privacy is maintained by concealing information. Thus, it seems difficult to harmonize a system that incorporates these competing interests. However, they frequently must be balanced when mining sensitive data [
39].
Privacy-preserving ML can be deployed using MPC concepts, such as GC and oblivious transfers, and apply them to the construction of protocols that allow parties to train ML models without revealing individual party inputs.
For the implementation of this module, we analyze two state-of-the-art privacy-preserving ML protocols: SecureML and ABY3.
3.4.1. SecureML
SecureML [
26] is a two-party efficient ML training protocol that enables the training of linear regression, logistic regression and neural network models.
SecureML implements a server-aided multi-party computation in which the two parties that run the
SecureML protocol are servers that receive data from a set of clients. At the end of the protocol, each client receives the model trained with the clients’ joint data. In
SecureML, the two parties participating in the protocol must be non-colluding, meaning that they do not work together to defeat the protocol and retrieve the clients’ private inputs.
SecureML authors state that their solution is orders of magnitude faster than previous privacy-preserving techniques. To achieve these higher efficiency levels, SecureML splits the multiparty computation into two phases: the setup phase and the online phase. In the setup phase, each party tries to compute all the necessary multiplication triplet shares needed to perform the computations where the secret sharing of the multiplication triplets is achieved, using Yao GC and OT. After the setup phase, the online phase uses the multiplication triplets and the secret shared inputs to compute the required ML model.
For optimization,
SecureML also deployed tests with homomorphic encryption to improve the intermediate results. The authors provide a complete overview in [
26] and the theoretical proofs required to validate the functionalities.
3.4.2. ABY3
ABY3 [
40] is a three-party general framework for privacy-preserving ML that trains linear, logistic, and neural network models, using three-party computation. ABY3 introduces several improvements that allow it to achieve greater performance than the
Secure ML [
26], in terms of the number of communications and the amount of data transferred, while allowing support for three or more parties (multiparty) computation instead of a two-party computation of
SecureML [
26]. ABY3 improvements include new fixed-point multiplication protocols for shared decimal values and a new general framework for efficiently converting between binary sharing (secret sharing of binary values), arithmetic sharing [
41] and Yao’s sharing [
42], with security against malicious adversaries.
From our analysis of the publicly available implementations of
SecureML [
43] and ABY3 [
44], we found that ABY3 implementation is vulnerable to eavesdropping attacks. An eavesdropper could capture the random seeds that generate the randomness used to mask the secret inputs that are sent to other parties, which defeats the entire purpose of a multiparty computation protocol, enabling an external attacker to obtain the private inputs of one or multiple parties that participate on the ABY3 protocol. Due to that fact, we chose to use
SecureML as our privacy-preserving ML protocol.
The data used to feed the SecureML protocol can be anonymous or private. In our architecture, anonymous data are never made public in plaintext form, which can prevent threats where an attacker uses background knowledge and other anonymous data to aggregate the information to find out if there are entities that belong to both sets of data. Our system never reveals anonymous data in cleartext, even in ML, so it is resilient to these types of attacks.
3.5. Cloud Middleware Module
The cloud middleware is solely responsible for storing and retrieving data from public and private storage. The implementation of the cloud middleware module is based on the jClouds framework, which enables us to deploy our solution to a vast number of supported cloud storage backends, including Amazon AWS, Google GCP, Microsoft Azure, and locally deployed OpenStack Swift instances [
45]. Our implementation uses AWS, GCP, and Azure for our public cloud backends, each one receiving one of the anonymized file shards received from the encryption and indexing module, and our private cloud storage are based on the OpenStack Swift. This choice of storage backends allows us to work with both public and private cloud storage, using the same framework.
To improve the upload and download speed, we have made our process multithread. In the upload process, we split the fragments into 2 MB blocks. Then, ten threads are generated, where, for example, the first thread is responsible for uploading blocks 1, 11, 21, etc., storing the location where the block is stored in the cloud-of-clouds on the metadata server. By doing this, we always have ten blocks being loaded simultaneously, improving performance. For the download process, we generate ten threads and start the download for each block that was previously sent in such a way that, for example, the first thread is responsible for downloading blocks 1, 11, 21, etc. However, by doing this, the snippet may be received out of order as the modules that requested the download. To make the cloud middleware module, we order the blocks as they arrive, producing a continuous stream of data where all are ordered, reducing the need for other modules to handle the out-of-order reception of data.
5. Performance Evaluation
In this section, we aim to evaluate the performance of our system. In Test 1, we started by testing the performance overheads that SGX might cause. In the second and third tests, we followed a different approach, as we focused on a dedicated machine and removed the performance overhead of the communication between the on-premise server and the Android device, which allows us to compare the related work without having to include the overhead/latency of the client/server communications. Thus, in the second test, we compared with the related work, and finally, in the third test, we addressed the system’s scalability.
5.1. Test 1—SGX Overhead
For this test, we defined three environments:
- 1.
The on-premise server is used without SGX;
- 2.
The SGX stores the private key and is only used on the public key operations of TLS;
- 3.
Every cryptographic operation of TLS is handled on SGX, including a public key and symmetric key operations, such as the encryption and decryption of packets.
For this first test, we used a Xiaomi MI A2 lite (on-premise client) featuring Android 9, a Ubiquiti Uap-Ac-Pro Access Point (AP), and an Intel NUC6i7KYK for supporting our on-premise server. The smartphone was connected to the AP, using 802.11n AC with a standard 20 MHz channel width in the 5 GHz wireless frequency range. The network connectivity was a 1 GB upload and download internet.
For these runs and each test, we used five repetitions of each scenario.
Table 4 shows that there is an increase in the performance overheads in the usage of SGX. However, using SGX to protect the HTTPS certificate private key has less performance overhead, providing usable upload and download performance. When SGX is responsible for all cryptographic operations over HTTPS, the performance overhead is too much to have a usable system. Because of this, the on-premise server implementation only has SGX responsible for public-key cryptography operations that require access to the certificate’s private key. We also represent the standard deviation for the five repetitions of each sample.
5.2. Test 2—Comparison with Other Cloud-of-Clouds
For this test, we used Google GCP storage as our cloud storage, writing in different buckets. For the setup, we used a network powered by a NOS Power Router 4.0 router with a 200 Mb/s internet down-link and a 150 Mb/s internet up-link. The machine used to host the services and run the tests used by the evaluation is a machine running in an Intel i7-8750H 6-core CPU with a 512 GB SSD connected to the router via a gigabit Ethernet cable.
Having an SGX mode selected, we started by comparing our solution with other state-of-the-art offloading technologies to see our performance overhead of encryption, erasure coding, and the cloud-of-clouds offload.
In our testing, we used three files with sizes of 100 MB, 500 MB, and 1 GB, uploading and downloading them ten times for each file size. To reduce the possibility of having noisy readings caused by network latency, we placed the client and the on-premise server on the same machine.
Contrarily to the previous test, we tested with the cloud-of-clouds and with local swift instances on the same machine, allowing us to test the scenario without the overhead associated with the public cloud provider. For this, we used four instances of the OpenStack Swift storage container deployed on the same machine as the client and the on-premise server that simulates the off-premise public cloud storage that our solution uses.
We tested our solution against Charon, configured without pre-fetching and compression, and against rClone. We compare our solutions’ offload with the Charon, as it also uses multiple cloud providers for storing the information persistently. rClone tests should allow us to see the maximum throughput that the cloud backends allow, enabling us to verify how much offload performance is left on the table due to our overhead.
For sake of completion, we ran the same tests using Google GCP storage as our cloud storage backends to see how the network latency affected our results.
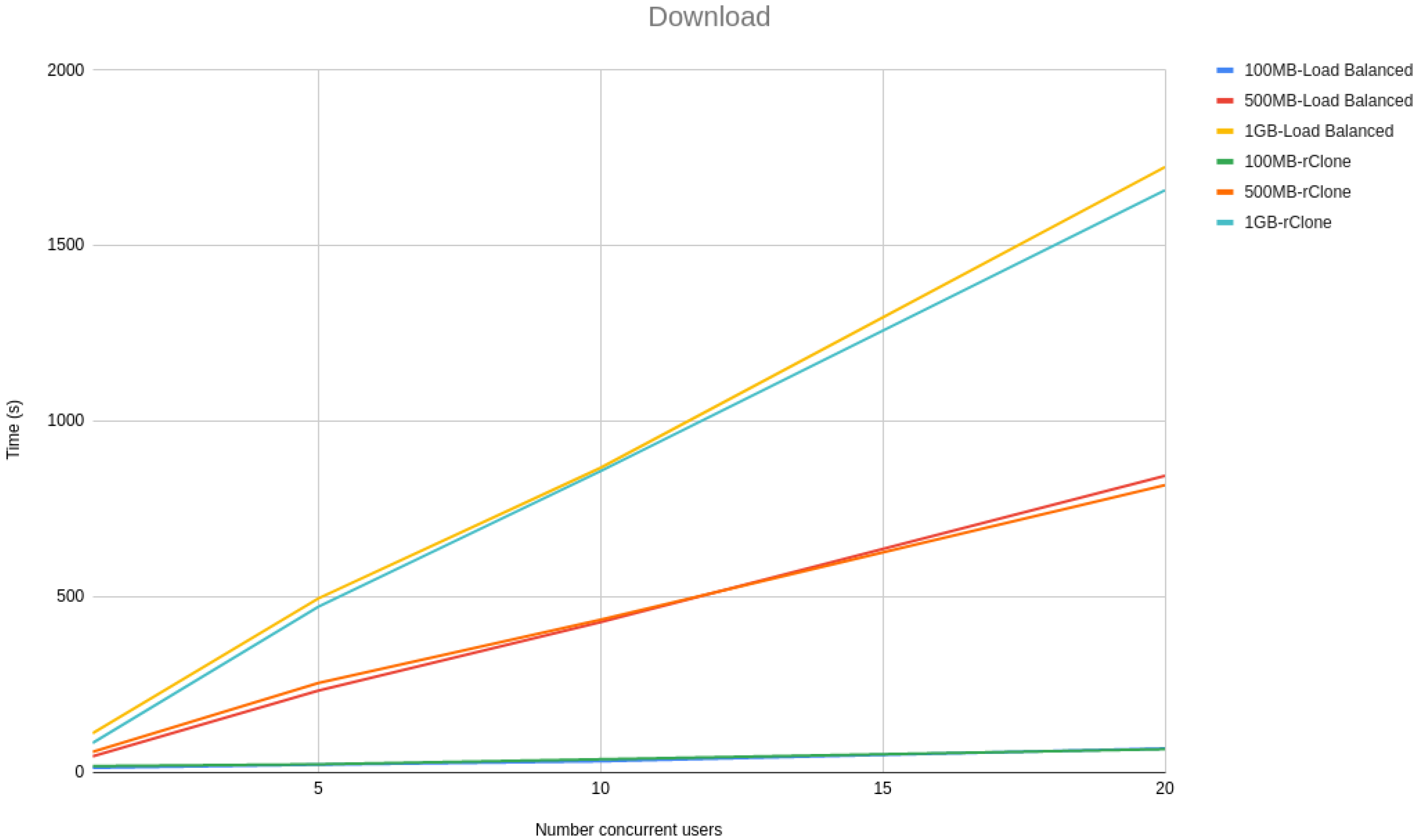
Table 5 shows the results of our testing in seconds with an average of ten runs for each scenario. We also have the standard deviations to understand the min and max values of each run.
Regarding the tests with the cloud, we can achieve a better performance than Charon in the download process. However, in comparison with RClone, for 1 GB size files, we have a weaker performance. RClone only communicates with the cloud provider, so it has better performance. However, Charon has to wait for the cloud providers so that it can explain its results.
On the other hand, in the upload process, we only achieve the best results on the 1 GB file, as Charon seems optimized to small files because the difference between 100 MB and 500 MB is greater than 90 s.
Regarding the Swift tests, the download and upload times decrease for all solutions, as they are performed locally and there is no connection overhead with the cloud provider. RClone performs better in all the results, while our solution can achieve similar results as Charon, except for the 1 GB upload, where the performance of our solution is much better.
Swift tests also allow us to test the dependency of the public cloud providers, as RClone has better results than the other solutions. Compared with Charon, our solution has an overhead decrease of almost 50%.
5.3. Test 3—Scalability
In this test, we used the same setup provided in Test 2. We used a network powered by a NOS Power Router 4.0 router with a 200 Mb/s internet down-link and a 150 Mb/s internet up-link, and the machine used to host the services and run the tests used by the evaluation is a machine running in an Intel i7-8750H 6-core CPU with a 512 GB SSD connected to the router via a gigabit Ethernet cable.
In the architecture section, we stated that our architecture is built to be scalable. We achieved this by allowing multiple machines to run the same on-premise server code behind a load balancer. The load balancer allowed us to split the load equally among all the available machines running the on-premise server. In our implementation, we used
HAProxy [
46] as our load balancing technology with a round-robin configuration, meaning that the number of requests are divided equally among all the machines running the on-premise server. To verify whether our solution is indeed scalable, we devised a test where we have 1, 5, 10, and 20 concurrent users uploading files of 100 MB, 500 MB, and 1 GB, running ten times for each number of concurrent users and file size configuration. To simulate a more realistic use case, we used Google GCP as our storage backends. In our testing, we used three on-premise server instances running locally on the same machine where the requests were made. To help us compare our solution scalability with other state-of-the-art cloud offload technologies, we compared our solution with
rClone.
rClone is a standalone solution, meaning that it should have no scalability issues, as it connects directly with the cloud storage without any additional processing made locally. That
rClone properties will help us to understand the maximum capacity that our testing environment has and to have a baseline on which to compare our solution. We did not use Charon on this test since it uses a caching service, making it only upload a file at a time instead of continuously uploading all the files, making it impractical for this performance comparison.
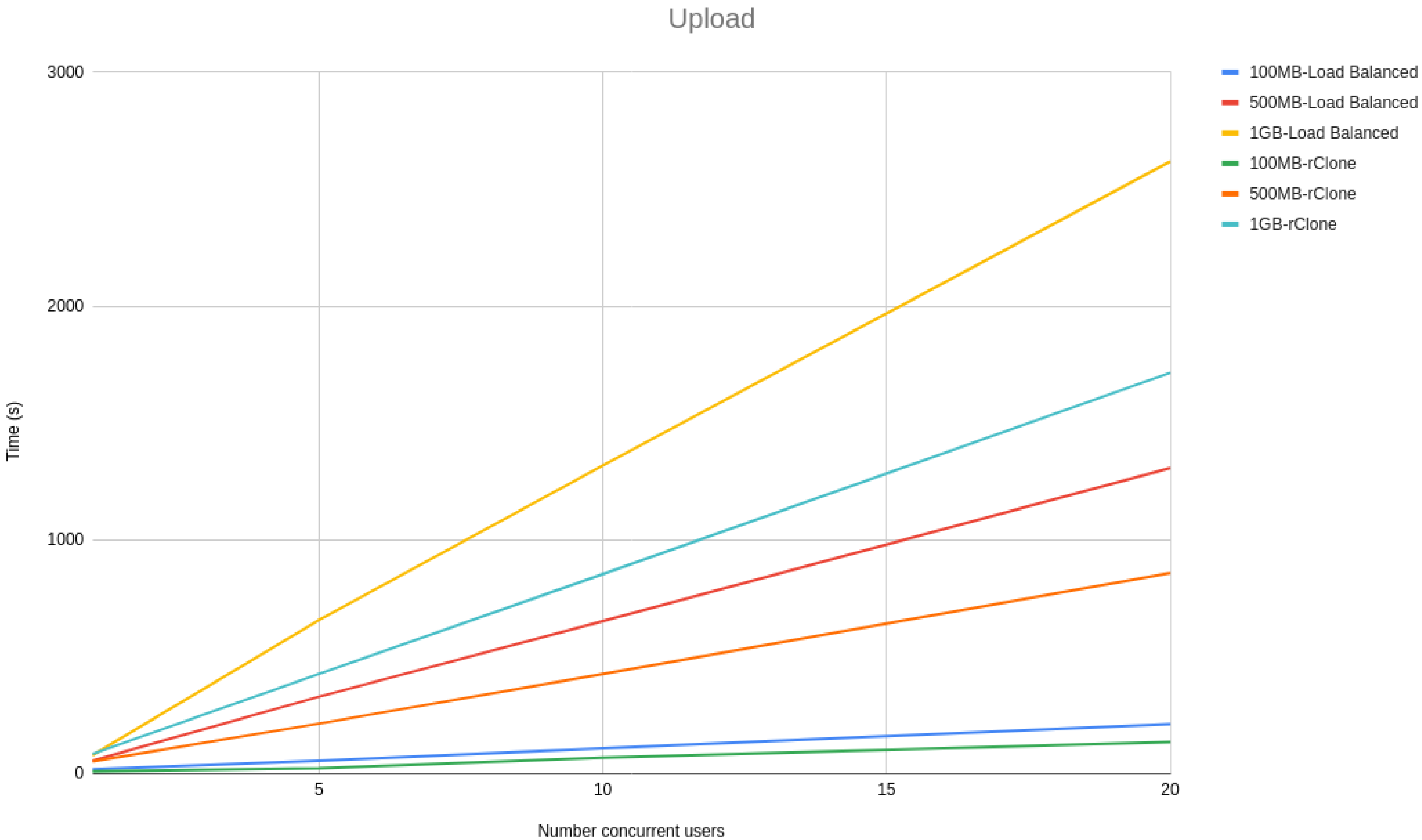
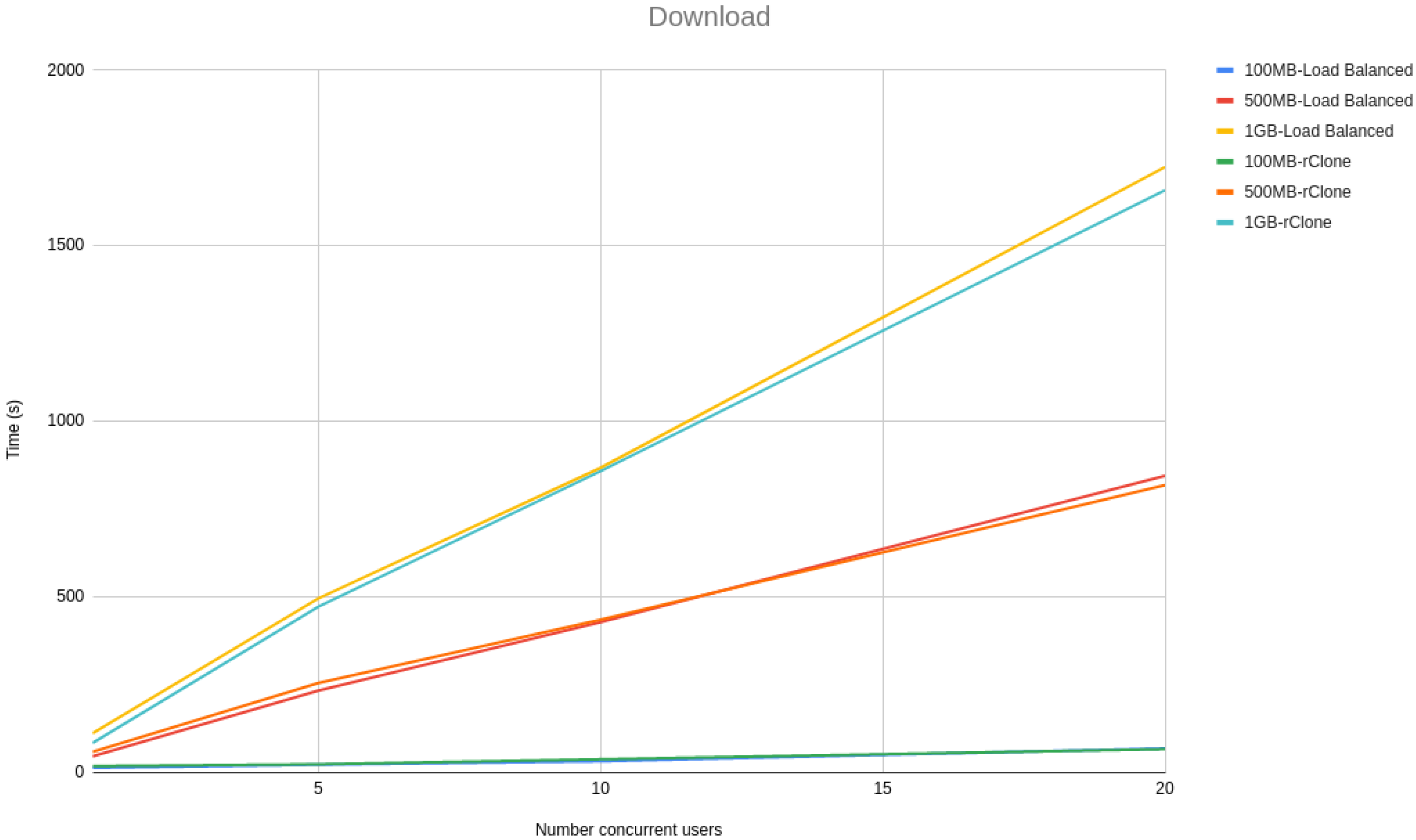
Figure 3 and
Figure 4 show a line graph of the meantime that took to, respectively, upload and download 100 MB, 500 MB and 1 GB files with 1, 5, 10 and 20 concurrent users.
From the line graphs, it is possible to see that the difference between our solution and rClone grows linearly with the size of the file and not with the number of users, meaning that our solution scalability is independent of the number of users but dependent on the file sizes. However, the growth is linear with the file size rather than being exponential, proving that our solution architecture is scalable.
6. Conclusions and Future Work
To the best of our knowledge, we described the first system that stores information in multiple cloud providers, focused on ensuring that users can share data and train ML models without exposing the data in cleartext, using MPC to compute the information jointly. The described system also uses known anonymization algorithms, such as K-Anonymity, storing the private information on the private cloud and storing the anonymized data in cloud-of-clouds storage.
With the evaluation we made of our data offload system, we demonstrated that our solution is scalable and can benefit the user experience, compared to the related work. In this scenario, the major disadvantage is using SGX to perform all calculations and manage encryption and decryption processes, as the performance overhead limits the system. Contrarily, if we manage only the private key inside the enclave, there is no overhead associated with this usage, ensuring that the private key never leaves the device.
This solution helps to achieve secure storage of information at a reduced price of the cloud providers, maintaining the data encrypted outside of the perimeter of the infrastructure to allow sharing with other entities to maintain user privacy. In addition, it can help to solve some open research challenges, such as designing secure privacy protection schemes to ensure that sensitive information in shared data is hidden, and designing efficient and secure third-party privacy protection schemes to support more machine learning algorithms [
1,
5].
There are still some challenges to address in the current implementations. The most important is related to the future developments of the multiparty computation and the scalability issue associated with such computations, but principally in the auditing and verification of the implementations.
As future work, we can also enhance the identification and removal of the identifiers, and redacting can be a possibility of using a PDF or other type of document to remove or create blocks that do not allow other parties to read from the file [
47]. A user can select confidential information with a mark redaction tool. Then, the information marked as redacted will be encrypted and restricted to authorized users.





{kind=link}
{kind=link}
{kind=link}
{kind=link}