
Improving Animal Monitoring Using Small Unmanned Aircraft Systems (sUAS) and Deep Learning Networks

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
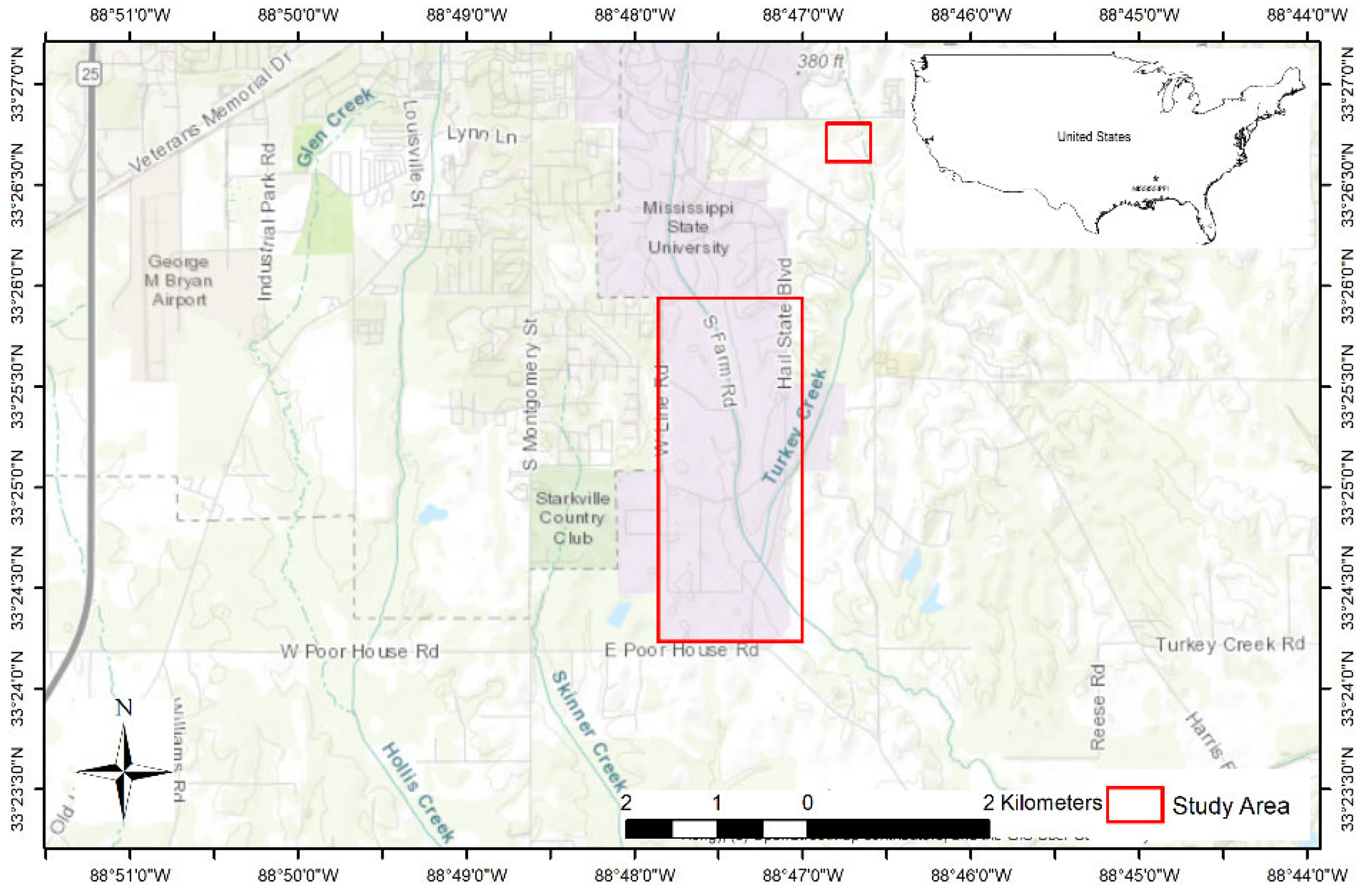
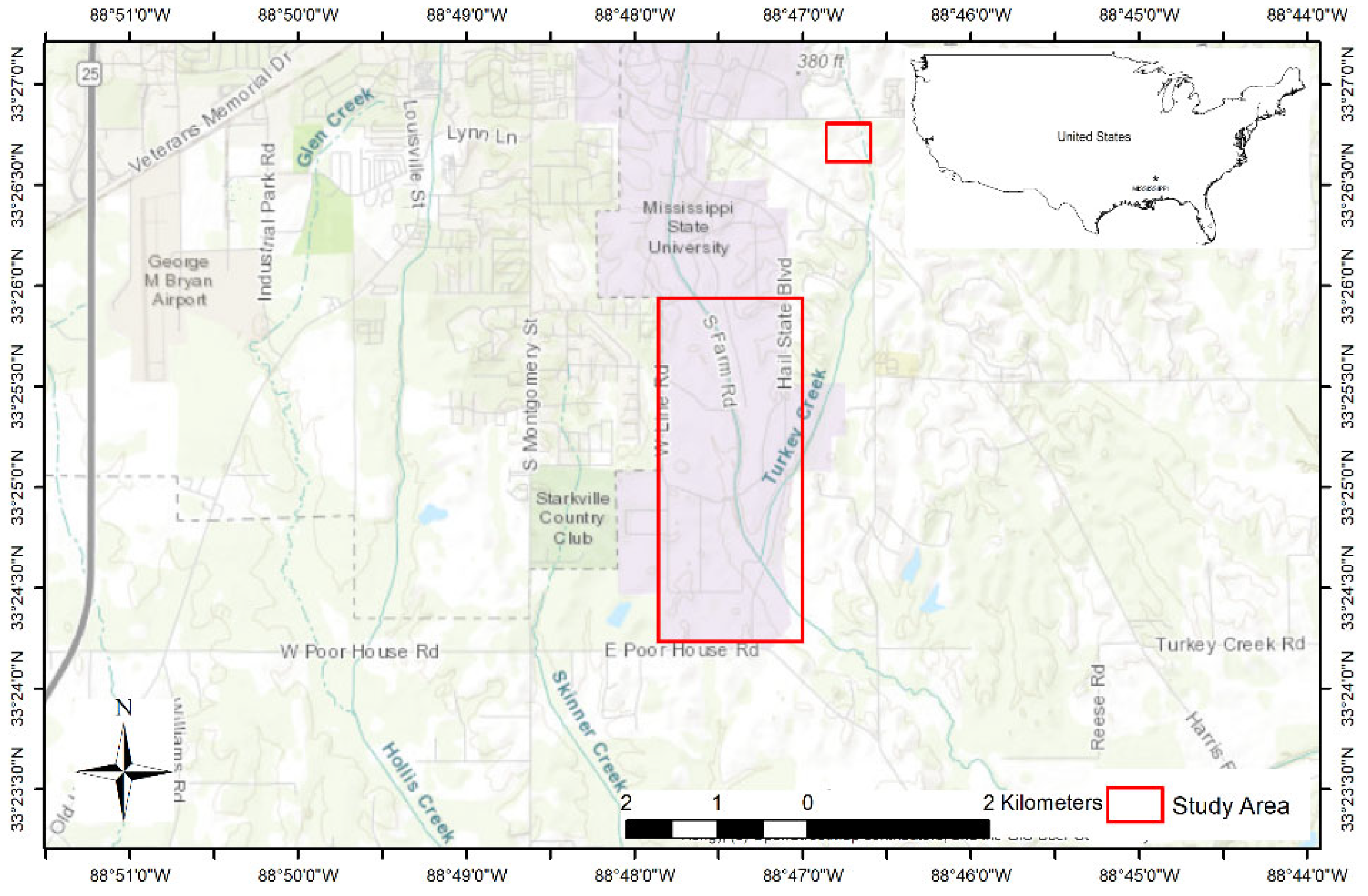
2.1. Study Area and Image Collection
2.2. Image Processing
2.3. Deep Learning
2.3.1. Convolutional Neural Network
2.3.2. Deep Residual Learning Networks
2.4. Image Augmentation
2.5. Experimental Setup
3. Results
3.1. Collected Imagery
3.2. Deep Learning Algorithm Comparisons
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dolbeer, R.A.; Begier, M.J.; Miller, P.R.; Weller, J.R.; Anderson, A.L. Wildlife Strikes to Civil Aircraft in the United States, 1990–2019. Available online: https://trid.trb.org/view/1853561 (accessed on 16 August 2021).
- Pfeiffer, M.B.; Blackwell, B.F.; DeVault, T.L. Quantification of avian hazards to military aircraft and implications for wildlife management. PLoS ONE 2018, 13, e0206599. [Google Scholar] [CrossRef] [Green Version]
- DeVault, T.L.; Blackwell, B.F.; Seamans, T.W.; Begier, M.J.; Kougher, J.D.; Washburn, J.E.; Miller, P.R.; Dolbeer, R.A. Estimating interspecific economic risk of bird strikes with aircraft. Wildl. Soc. Bull. 2018, 42, 94–101. [Google Scholar] [CrossRef] [Green Version]
- Washburn, B.E.; Pullins, C.K.; Guerrant, T.L.; Martinelli, G.J.; Beckerman, S.F. Comparing Management Programs to Reduce Red–tailed Hawk Collisions with Aircraft. Wildl. Soc. Bull. 2021, 45, 237–243. [Google Scholar] [CrossRef]
- DeVault, T.; Blackwell, B.; Belant, J.; Begier, M. Wildlife at Airports. Wildlife Damage Management Technical Series. Available online: https://digitalcommons.unl.edu/nwrcwdmts/10 (accessed on 16 August 2021).
- Blackwell, B.; Schmidt, P.; Martin, J. Avian Survey Methods for Use at Airports. USDA National Wildlife Research Center—Staff Publications. Available online: https://digitalcommons.unl.edu/icwdm_usdanwrc/1449 (accessed on 16 August 2021).
- Hubbard, S.; Pak, A.; Gu, Y.; Jin, Y. UAS to support airport safety and operations: Opportunities and challenges. J. Unmanned Veh. Syst. 2018, 6, 1–17. [Google Scholar]
- Anderson, K.; Gaston, K.J. Lightweight unmanned aerial vehicles will revolutionize spatial ecology. Front. Ecol. Environ. 2013, 11, 138–146. [Google Scholar]
- Christie, K.S.; Gilbert, S.L.; Brown, C.L.; Hatfield, M.; Hanson, L. Unmanned aircraft systems in wildlife research: Current and future applications of a transformative technology. Front. Ecol. Environ. 2016, 14, 241251. [Google Scholar] [CrossRef]
- Hodgson, J.C.; Mott, R.; Baylis, S.M.; Pham, T.T.; Wotherspoon, S.; Kilpatrick, A.D.; Raja Segaran, R.; Reid, I.; Terauds, A.; Koh, L.P. Drones count wildlife more accurately and precisely than humans. Methods Ecol. Evol. 2018, 9, 1160–1167. [Google Scholar]
- Linchant, J.; Lisein, J.; Semeki, J.; Lejeune, P.; Vermeulen, C. Are unmanned aircraft systems (UASs) the future of wildlife monitoring? A review of accomplishments and challenges. Mammal. Rev. 2015, 45, 239–252. [Google Scholar] [CrossRef]
- Frederick, P.C.; Hylton, B.; Heath, J.A.; Ruane, M. Accuracy and variation in estimates of large numbers of birds by individual observers using an aerial survey simulator. J. Field Ornithol. 2003. Available online: https://agris.fao.org/agris-search/search.do?recordID=US201600046673 (accessed on 16 August 2021).
- Sasse, D.B. Job-Related Mortality of Wildlife Workers in the United States. Wildl. Soc. Bull. 2003, 31, 1015–1020. [Google Scholar]
- Buckland, S.T.; Burt, M.L.; Rexstad, E.A.; Mellor, M.; Williams, A.E.; Woodward, R. Aerial surveys of seabirds: The advent of digital methods. J. Appl. Ecol. 2012, 49, 960–967. [Google Scholar] [CrossRef]
- Chabot, D.; Bird, D.M. Wildlife research and management methods in the 21st century: Where do unmanned aircraft fit in? J. Unmanned Veh. Syst. 2015, 3, 137–155. [Google Scholar] [CrossRef] [Green Version]
- Pimm, S.L.; Alibhai, S.; Bergl, R.; Dehgan, A.; Giri, C.; Jewell, Z.; Joppa, L.; Kays, R.; Loarie, S. Emerging Technologies to Conserve Biodiversity. Trends Ecol. Evol. 2015, 30, 685–696. [Google Scholar] [CrossRef] [PubMed]
- Hodgson, J.C.; Baylis, S.M.; Mott, R.; Herrod, A.; Clarke, R.H. Precision wildlife monitoring using unmanned aerial vehicles. Sci. Rep. 2016, 6, 22574. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinstein, B.G. A computer vision for animal ecology. J. Anim. Ecol. 2018, 87, 533–545. [Google Scholar] [CrossRef]
- Reintsma, K.M.; McGowan, P.C.; Callahan, C.; Collier, T.; Gray, D.; Sullivan, J.D.; Prosser, D.J. Preliminary Evaluation of Behavioral Response of Nesting Waterbirds to Small Unmanned Aircraft Flight. Cowa 2018, 41, 326–331. [Google Scholar] [CrossRef]
- Scholten, C.N.; Kamphuis, A.J.; Vredevoogd, K.J.; Lee-Strydhorst, K.G.; Atma, J.L.; Shea, C.B.; Lamberg, O.N.; Proppe, D.S. Real-time thermal imagery from an unmanned aerial vehicle can locate ground nests of a grassland songbird at rates similar to traditional methods. Biol. Conserv. 2019, 233, 241–246. [Google Scholar] [CrossRef]
- Lyons, M.B.; Brandis, K.J.; Murray, N.J.; Wilshire, J.H.; McCann, J.A.; Kingsford, R.T.; Callaghan, C.T. Monitoring large and complex wildlife aggregations with drones. Methods Ecol. Evol. 2019, 10, 1024–1035. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal Recognition and Identification with Deep Convolutional Neural Networks for Automated Wildlife Monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Tabak, M.A.; Norouzzadeh, M.S.; Wolfson, D.W.; Sweeney, S.J.; Vercauteren, K.C.; Snow, N.P.; Halseth, J.M.; Di Salvo, P.A.; Lewis, J.S.; White, M.D.; et al. Machine learning to classify animal species in camera trap images: Applications in ecology. Methods Ecol. Evol. 2019, 10, 585–590. [Google Scholar] [CrossRef] [Green Version]
- Rush, G.P.; Clarke, L.E.; Stone, M.; Wood, M.J. Can drones count gulls? Minimal disturbance and semiautomated image processing with an unmanned aerial vehicle for colony-nesting seabirds. Ecol. Evol. 2018, 8, 12322–12334. [Google Scholar] [CrossRef]
- Chabot, D.; Francis, C.M. Computer-automated bird detection and counts in high-resolution aerial images: A review. J. Field Ornithol. 2016, 87, 343–359. [Google Scholar] [CrossRef]
- Hong, S.-J.; Han, Y.; Kim, S.-Y.; Lee, A.-Y.; Kim, G. Application of Deep-Learning Methods to Bird Detection Using Unmanned Aerial Vehicle Imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef] [Green Version]
- Ratcliffe, N.; Guihen, D.; Robst, J.; Crofts, S.; Stanworth, A.; Enderlein, P. A protocol for the aerial survey of penguin colonies using UAVs. J. Unmanned Veh. Syst. 2015, 3, 95–101. [Google Scholar] [CrossRef] [Green Version]
- Hayes, M.C.; Gray, P.C.; Harris, G.; Sedgwick, W.C.; Crawford, V.D.; Chazal, N.; Crofts, S.; Johnston, D.W. Drones and deep learning produce accurate and efficient monitoring of large-scale seabird colonies. Ornithol. Appl. 2021, 123. Available online: https://doi.org/10.1093/ornithapp/duab022 (accessed on 16 August 2021).
- Manohar, N.; Sharath Kumar, Y.H.; Kumar, G.H. Supervised and unsupervised learning in animal classification. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 156–161. [Google Scholar]
- Chaganti, S.Y.; Nanda, I.; Pandi, K.R.; Prudhvith, T.G.N.R.S.N.; Kumar, N. Image Classification using SVM and CNN. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Sydney, Australia, 19–20 December 2020; pp. 1–5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2015. Available online: http://arxiv.org/abs/1512.03385 (accessed on 16 August 2021).
- Han, X.; Jin, R. A Small Sample Image Recognition Method Based on ResNet and Transfer Learning. In Proceedings of the 2020 5th International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 19–21 June 2020; pp. 76–81. [Google Scholar]
- Marcon dos Santos, G.A.; Barnes, Z.; Lo, E.; Ritoper, B.; Nishizaki, L.; Tejeda, X.; Ke, A.; Lin, H.; Schurgers, C.; Lin, A.; et al. Small Unmanned Aerial Vehicle System for Wildlife Radio Collar Tracking. In Proceedings of the 2014 IEEE 11th International Conference on Mobile Ad Hoc and Sensor Systems, Philadelphia, PA, USA, 28–30 October 2014. [Google Scholar]
- McEvoy, J.F.; Hall, G.P.; McDonald, P.G. Evaluation of unmanned aerial vehicle shape, flight path and camera type for waterfowl surveys: Disturbance effects and species recognition. PeerJ 2016, 4, e1831. [Google Scholar] [CrossRef] [Green Version]
- Bennitt, E.; Bartlam-Brooks, H.L.A.; Hubel, T.Y.; Wilson, A.M. Terrestrial mammalian wildlife responses to Unmanned Aerial Systems approaches. Sci. Rep. 2019, 9, 2142. [Google Scholar] [CrossRef]
- Steele, W.K.; Weston, M.A.; Steele, W.K.; Weston, M.A. The assemblage of birds struck by aircraft differs among nearby airports in the same bioregion. Wildl Res. 2021, 48, 422–425. [Google Scholar] [CrossRef]
- Quenouille, M.H. Notes on Bias in Estimation. Biometrika 1956, 43, 353–360. [Google Scholar] [CrossRef]
- Training a Classifier—PyTorch Tutorials 1.9.0+cu102 documentation. Available online: https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html (accessed on 16 August 2021).
- Wu, H.; Gu, X. Max-Pooling Dropout for Regularization of Convolutional Neural Networks. arXiv 2015, arXiv:151201400. Available online: http://arxiv.org/abs/1512.01400 (accessed on 16 August 2021).
- Liu, T.; Fang, S.; Zhao, Y.; Wang, P.; Zhang, J. Implementation of Training Convolutional Neural Networks. arXiv 2015, arXiv:150601195. Available online: http://arxiv.org/abs/1506.01195 (accessed on 16 August 2021).
- Zualkernan, I.A.; Dhou, S.; Judas, J.; Sajun, A.R.; Gomez, B.R.; Hussain, L.A.; Sakhnini, D. Towards an IoT-based Deep Learning Architecture for Camera Trap Image Classification. In Proceedings of the 2020 IEEE Global Conference on Artificial Intelligence and Internet of Things (GCAIoT), Dubai, United Arab Emirates, 12–16 December 2020; pp. 1–6. [Google Scholar]
- Torchvision.transforms—Torchvision 0.10.0 documentation. Available online: https://pytorch.org/vision/stable/transforms.html (accessed on 16 August 2021).
- Amari, S. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Attoh-Okine, N.O. Analysis of learning rate and momentum term in backpropagation neural network algorithm trained to predict pavement performance. Adv. Eng. Softw. 1999, 30, 291–302. [Google Scholar] [CrossRef]
- Wilson, D.R.; Martinez, T.R. The need for small learning rates on large problems. In Proceedings of the IJCNN’01 International Joint Conference on Neural Networks Proceedings (Cat No01CH37222), Washington, DC, USA, 15–19 July 2001; Volume 1, pp. 115–119. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Bach, F., Ed.; Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2016; 800p. [Google Scholar]
- Cho, K.; Raiko, T.; Ilin, A. Enhanced gradient and adaptive learning rate for training restricted boltzmann machines. In Proceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11; Omnipress: Madison, WI, USA, 2011; pp. 105–112. [Google Scholar]
- Torch.optim—PyTorch 1.9.0 documentation. Available online: https://pytorch.org/docs/stable/optim.html (accessed on 16 August 2021).
- Viera, A.J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam Med. 2005, 37, 360–363. [Google Scholar] [PubMed]
- Keshari, R.; Vatsa, M.; Singh, R.; Noore, A. Learning Structure and Strength of CNN Filters for Small Sample Size Training. arXiv 2018, arXiv:180311405. Available online: http://arxiv.org/abs/1803.11405 (accessed on 16 August 2021).
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. arXiv 2020, arXiv:190803265. Available online: http://arxiv.org/abs/1908.03265 (accessed on 16 August 2021).
- Li, Y.; Wei, C.; Ma, T. Towards Explaining the Regularization Effect of Initial Large Learning Rate in Training Neural Networks. arXiv 2020, arXiv:190704595. Available online: http://arxiv.org/abs/1907.04595 (accessed on 16 August 2021).
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Świnouście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:171204621. Available online: http://arxiv.org/abs/1712.04621 (accessed on 16 August 2021).
- Thanapol, P.; Lavangnananda, K.; Bouvry, P.; Pinel, F.; Leprévost, F. Reducing Overfitting and Improving Generalization in Training Convolutional Neural Network (CNN) under Limited Sample Sizes in Image Recognition. In Proceedings of the 2020-5th International Conference on Information Technology (InCIT), Chonburi, Thailand, 21–22 October 2020; pp. 300–305. [Google Scholar]
- Brownlee, J. Difference Between a Batch and an Epoch in a Neural Network. Machine Learning Mastery. 2018. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 16 August 2021).
- Lawrence, S.; Giles, C.L. Overfitting and neural networks: Conjugate gradient and backpropagation. In Proceedings of the Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks IJCNN 2000 Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; Volume 1, pp. 114–119. [Google Scholar]
- Seymour, A.C.; Dale, J.; Hammill, M.; Halpin, P.N.; Johnston, D.W. Automated detection and enumeration of marine wildlife using unmanned aircraft systems (UAS) and thermal imagery. Sci. Rep. 2017, 7, 45127. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Layer Name | Output Size | Layer Info | Processing |
|---|---|---|---|---|
| 1 | 2D Convolution | 28 × 28 | 5 × 5, 6, stride 1 | Input 32 × 32, ReLu |
| 2 | Pooling | 14 × 14 | 2 × 2 Max Pooling, stride 2 | |
| 3 | 2D Convolution | 10 × 10 | 5 × 5, 16, stride 1 | ReLu, stride 1 |
| 4 | Pooling | 5 × 5 | 2 × 2 Max Pooling, stride 2 | 2 × 2 Max Pool, stride 1 |
| 5 | Fully Connected ANN | 4 × 1 | Cross Entropy Loss, 0.9 Momentum | ReLu |
| Layer | Layer Name | Output Size | ResNet 18 | ResNet 34 | Processing |
|---|---|---|---|---|---|
| 1 | 2D Convolution | 112 × 112 | 7 × 7, 64, stride 2 3 × 3 Max Pooling, stride 2 | Input 224 × 224, ReLu | |
| 2 | Pooling | 56 × 56 | |||
| 3 | 2D Convolution | 56 × 56 | ReLu | ||
| 4 | 2D Convolution | 28 × 28 | ReLu | ||
| 5 | 2D Convolution | 14 × 14 | |||
| 6 | 2D Convolution | 7 × 7 | |||
| 7 | Fully Connected ANN | 1 × 1 | Cross Entropy Loss, 0.9 Momentum | Average Pool, Softmax | |
| 10% Training Samples | 20% Training Samples | ||||||
|---|---|---|---|---|---|---|---|
| Algorithm | Learning Rate | Run Time | OA | Kappa | Run Time | OA | Kappa |
| CNN (1000 epochs) | 0.0001 | 13 m 30 s | 71.27% | 0.59 | 19 m 38 s | 74.38% | 0.65 |
| 0.001 | 9 m 21 s | 66.12% | 0.53 | 9 m 44 s | 80.54% | 0.68 | |
| 0.01 | 9 m 24 s | 72.62% | 0.63 | 9 m 59 s | 78.72% | 0.66 | |
| ResNet 18 (25 epochs) | 0.0001 | 9 m 8 s | 94.04% | 0.92 | 9 m 47 s | 94.59% | 0.93 |
| 0.001 | 10 m 8 s | 96.74% | 0.96 | 9 m 58 s | 97.89% | 0.97 | |
| 0.01 | 8 m 14 s | 72.89% | 0.63 | 9 m 42 s | 85.71% | 0.80 | |
| ResNet 34 (25 epochs) | 0.0001 | 17 m 17 s | 93.04% | 0.90 | 17 m 32 s | 96.06% | 0.96 |
| 0.001 | 15 m 26 s | 97.83% | 0.97 | 16 m 53 s | 98.48% | 0.98 | |
| 0.01 | 14 m 15 s | 68.56% | 0.54 | 17 m 11 s | 59.89% | 0.45 | |
| 10% Training Samples | 20% Training Samples | ||||||
|---|---|---|---|---|---|---|---|
| Algorithm | Epochs | Run Time | OA | Kappa | Run Time | OA | Kappa |
| CNN (0.0001 LR) | 100 | 1 m 30 s | 60.07% | 0.50 | 1 m 30 s | 65.54% | 0.51 |
| 150 | 2 m 11 s | 58.98% | 0.49 | 3 m | 75.53% | 0.66 | |
| 200 | 2 m 50 s | 66.67% | 0.53 | 3 m 45 s | 72.64% | 0.60 | |
| 1000 | 13 m 30 s | 71.27% | 0.59 | 19 m 38 s | 74.38% | 0.65 | |
| ResNet 18 (0.0001 LR) | 25 | 9 m 8 s | 94.04% | 0.90 | 9 m 47 s | 94.59% | 0.93 |
| 50 | 36 m 39 s | 94.03% | 0.90 | 43 m 42 s | 98.48% | 0.98 | |
| 100 | 73 m 23 s | 95.93% | 0.93 | 83 m 18 s | 98.17% | 0.97 | |
| 200 | 147 m 8 s | 96.20% | 0.94 | 158 m 16 s | 98.78% | 0.98 | |
| ResNet 34 (0.0001 LR) | 25 | 17 m 17 s | 93.04% | 0.92 | 17 m 32 s | 96.09% | 0.95 |
| 50 | 41 m 20 s | 97.87% | 0.97 | 42 m 30 s | 96.96% | 0.95 | |
| 100 | 83 m 14 s | 98.48% | 0.98 | 81 m 45 s | 97.26% | 0.97 | |
| 200 | 166 m 42 s | 95.12% | 0.92 | 167 m 11 s | 98.92% | 0.98 | |
| Random Rotation | 10% Training Samples | 20% Training Samples | |||||
|---|---|---|---|---|---|---|---|
| Algorithm | Epochs | Run Time | OA | Kappa | Run Time | OA | Kappa |
| CNN (0.0001 LR) | 100 | 1 m 0 s | 44.98% | 0.26 | 1 m 8 s | 83.19% | 0.77 |
| 150 | 1 m 29 s | 58.26% | 0.44 | 1 m 53 s | 81.02% | 0.73 | |
| 200 | 1 m 58 s | 67.47% | 0.56 | 2 m 13 s | 83.19% | 0.77 | |
| 1000 | 9 m 53 s | 72.64% | 0.63 | 11 m 40 s | 84.55% | 0.79 | |
| ResNet 18 (0.0001 LR) | 25 | 11 m 27 s | 93.22% | 0.91 | 16 m 2 s | 96.20% | 0.94 |
| 50 | 21 m 11 s | 94.85% | 0.93 | 26 m 11 s | 97.83% | 0.97 | |
| 100 | 42 m 48 s | 96.74% | 0.95 | 73 m 13 s | 99.18% | 0.98 | |
| 200 | 84 m 12 s | 97.56% | 0.96 | 149 m 16 s | 99.18% | 0.98 | |
| ResNet 34 (0.0001 LR) | 25 | 19 m 17 s | 89.43% | 0.85 | 30 m 59 s | 96.47% | 0.95 |
| 50 | 37 m 10 s | 95.66% | 0.94 | 51 m 50 s | 98.64% | 0.98 | |
| 100 | 74 m 32 s | 96.47% | 0.95 | 100 m 42 s | 97.56% | 0.96 | |
| 200 | 146 m 24 s | 97.56% | 0.96 | 182 m 50 s | 98.91% | 0.98 | |
| Horizontal Flip | 10% Training Samples | 20% Training Samples | |||||
|---|---|---|---|---|---|---|---|
| Algorithm | Epochs | Run Time | OA | Kappa | Run Time | OA | Kappa |
| CNN (0.0001 LR) | 100 | 1 m 2 s | 68.83% | 0.58 | 1 m 15 s | 78.31% | 0.71 |
| 150 | 1 m 37 s | 71.00% | 0.61 | 2 m 4 s | 84.01% | 0.78 | |
| 200 | 2 m 14 s | 72.35% | 0.63 | 2 m 31 s | 83.19% | 0.77 | |
| 1000 | 11 m 0 s | 71.54% | 0.62 | 12 m 37 s | 81.57% | 0.75 | |
| ResNet 18 (0.0001 LR) | 25 | 11 m 43 s | 93.49% | 0.91 | 14 m 4 s | 97.83% | 0.97 |
| 50 | 21 m 29 s | 92.41% | 0.89 | 28 m 15 s | 99.18% | 0.98 | |
| 100 | 44 m 1 s | 97.56% | 0.96 | 61 m 17 s | 98.64% | 0.98 | |
| 200 | 85 m 42 s | 95.66% | 0.94 | 118 m 41 s | 98.91% | 0.98 | |
| ResNet 34 (0.0001 LR) | 25 | 21 m 35 s | 96.74% | 0.95 | 23 m 21 s | 98.10% | 0.97 |
| 50 | 41 m 33 s | 97.01% | 0.96 | 47 m 33 s | 98.64% | 0.98 | |
| 100 | 80 m 16 s | 96.20% | 0.94 | 99 m 55 s | 98.64% | 0.98 | |
| 200 | 155 m 31 s | 97.01% | 0.96 | 195 m 39 s | 99.18% | 0.98 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, M.; Elmore, J.A.; Samiappan, S.; Evans, K.O.; Pfeiffer, M.B.; Blackwell, B.F.; Iglay, R.B. Improving Animal Monitoring Using Small Unmanned Aircraft Systems (sUAS) and Deep Learning Networks. Sensors 2021, 21, 5697. https://doi.org/10.3390/s21175697
Zhou M, Elmore JA, Samiappan S, Evans KO, Pfeiffer MB, Blackwell BF, Iglay RB. Improving Animal Monitoring Using Small Unmanned Aircraft Systems (sUAS) and Deep Learning Networks. Sensors. 2021; 21(17):5697. https://doi.org/10.3390/s21175697
Chicago/Turabian StyleZhou, Meilun, Jared A. Elmore, Sathishkumar Samiappan, Kristine O. Evans, Morgan B. Pfeiffer, Bradley F. Blackwell, and Raymond B. Iglay. 2021. "Improving Animal Monitoring Using Small Unmanned Aircraft Systems (sUAS) and Deep Learning Networks" Sensors 21, no. 17: 5697. https://doi.org/10.3390/s21175697
APA StyleZhou, M., Elmore, J. A., Samiappan, S., Evans, K. O., Pfeiffer, M. B., Blackwell, B. F., & Iglay, R. B. (2021). Improving Animal Monitoring Using Small Unmanned Aircraft Systems (sUAS) and Deep Learning Networks. Sensors, 21(17), 5697. https://doi.org/10.3390/s21175697