
An Analysis of Android Malware Classification Services


Abstract
:1. Introduction
- We study the historical malware family classification methods, as well as those of Android. We compare the latter to the industry’s practice of Android malware classification.
- We perform an exhaustive study of the industry’s Android malware labeling phenomenon between 2012 and 2020 by analyzing reports of several AV vendors. We do the same in academia by studying relevant papers from top security conferences between 2011 and 2020. To the best of our knowledge, we are the first to do so.
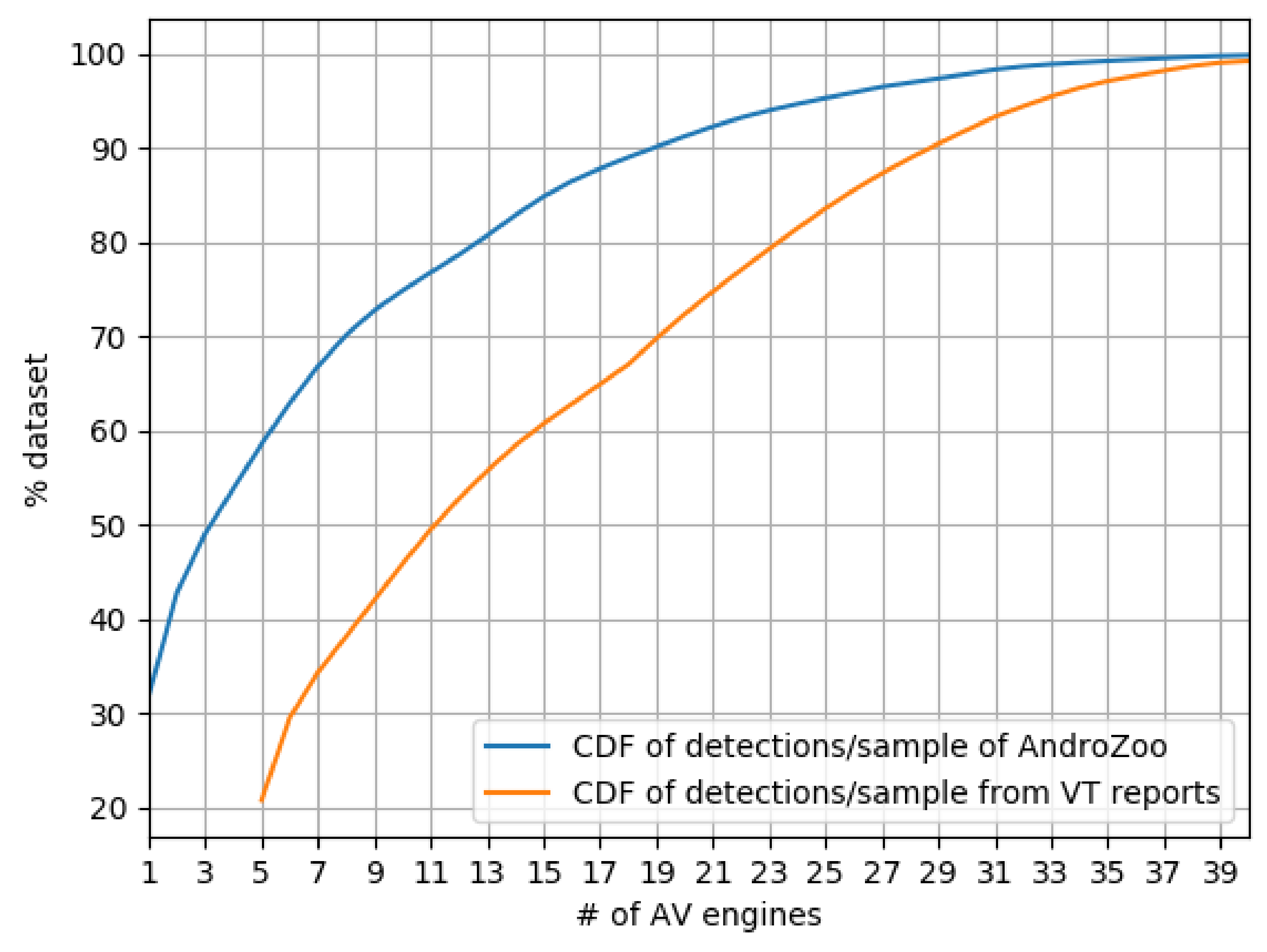
- We analyze 2.47 M Android malware samples using VT and calculate the coverage of single AVs, as well as between each AV pair of the top 10 AVs in coverage.
- We study the prevalence of the usage of generic labels and uncover several inconsistencies within the labels of each of the top 10 AVs in coverage.
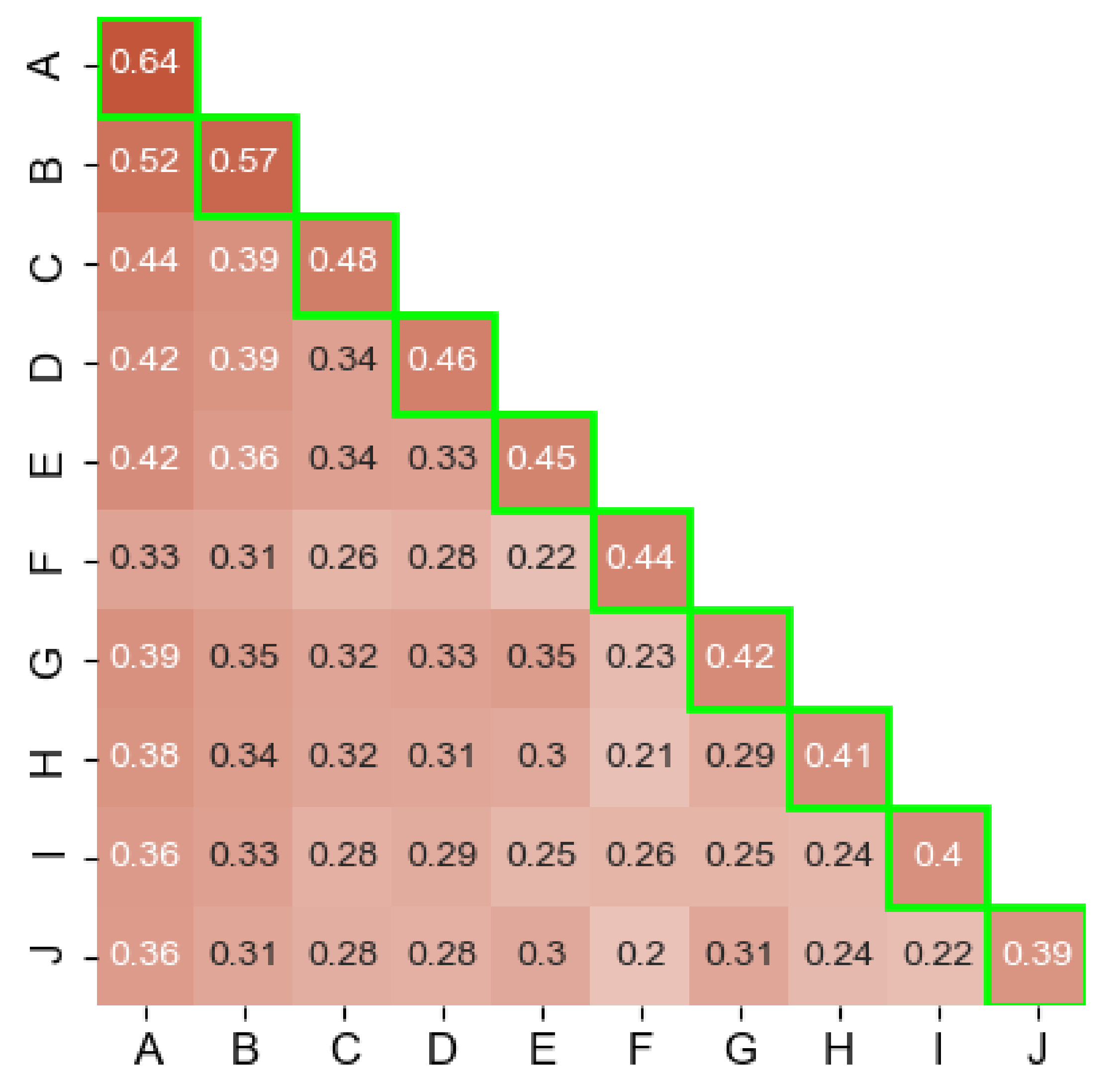
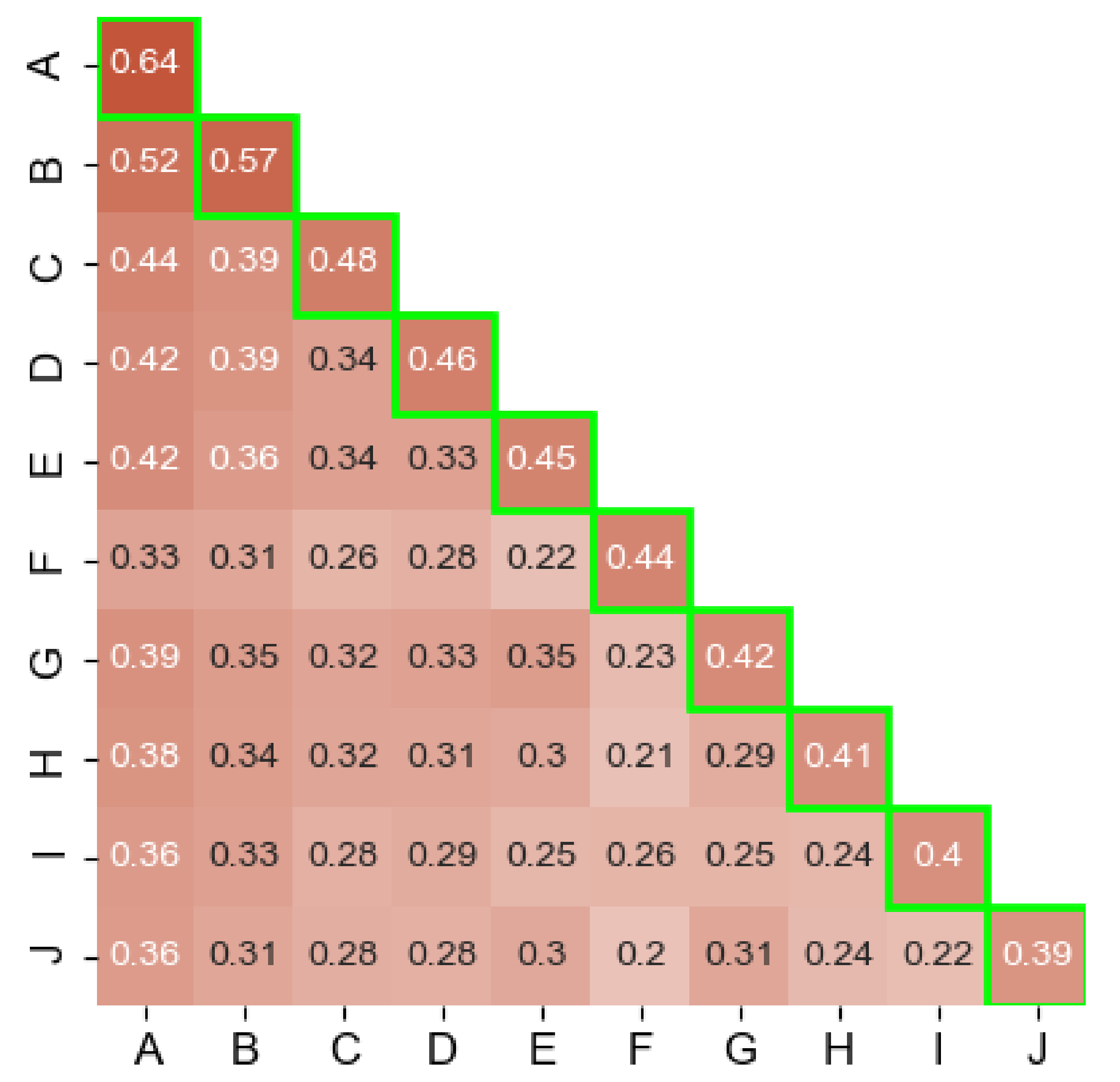
- Using the Rand index metric, we determine the level of agreement on family and class between each AV pair in the top 10 AVs.
2. Android Malware Classification
2.1. Malware Classification
2.1.1. Unsupervised Learning
2.1.2. Supervised Learning
2.1.3. Hybrid (Supervised + Unsupervised Learning)
2.2. Classifying Android Malware
- Supervised Learning: requires a labeled dataset, which is split into training/testing sets. The designer chooses how to split the set. We have seen 50/50 training% versus testing% splits [42,44], 80/20 [43,44], and 90/10 [11,41], as well as 66.6/33.3 [13,14]. Used algorithms include KNN [42], SVM [14,43], and Random Forest [44].
- Unsupervised Learning: Clustering is mainly used. It requires no labeled datasets and consequently no dataset splitting. One common algorithm, which was used in Reference [44], is DBScan.
2.3. Industry Practices
- Heuristics: includes static and dynamic heuristic analysis. The static heuristic analysis compares the decompiled code of the sample to suspicious code in previously found malware and flags the samples as a possible threat if the suspicious code passes a certain threshold. The dynamic one executes the sample in a sandbox and flags the sample if suspicious behavior is found [51].
3. Usage of Android Malware Family Labels
3.1. Usage by the AV Industry
- Companies are not consistent in (a) including family names in their reports and (b) providing detailed technical information about these families. Instead, reports are rather generic with a shallow technical details and geared towards showing the effectiveness of their solutions.
- Lack of consensus between AVs on the most prominent threats of each year. Even in years when there are a large number of reports discussing specific families (i.e., 2016–2018), consensus is limited; the peak occurred in 2018 with Triada, where 4 out of 6 vendors included it in their top families’ list.
- Even as time passes, transparency in reporting families does not seem to improve, which confirms their marketing tendency versus the technical one: only 2 vendors published reports in 2019 and 2020, although we had 5 reporting vendors in 2018.
3.2. Usage in Academic Research
- Several papers use datasets that they craft from AV companies. Although each one of them is unique, we aggregated them into a single row called Companies for better readability.
- Custom refers to non-specific datasets that were built by the authors themselves for their work and were not released to the community.
- Unknown are those sets for which we could not identify if they were Custom or samples from a different repository/dataset.
- Detection does not necessarily mean malware detection only but, rather, any type of detection (e.g., Reference [16] focuses on ransomware detection).
- Analysis indicates any analytical/measurement study, e.g., comparison between families, benign and malware, results from AVs, etc.
- Family Classification also includes type classification, e.g., ransomware versus other malware types.
- Tools whose goal is not detection/family classification, such as forensic tools, tools for protection, etc.
- Other refers to purposes not falling in the above categories. In our set of papers, this includes attack design, fingerprinting apps through traffic, model-checking based detection, and others.
- Lack of ground truth. Most datasets do not contain family labels. Understandably, only a few early and small datasets were the result of manual labeling efforts, e.g., Malgenome [10]. Knowing the morphology of a dataset (i.e., the family labels) may inform practitioners of how the dataset is balanced towards certain type of threats. While this might have a lesser impact on malware detection research, the lack of ground truth for the families is an obstacle for those studying malware family classification.
- Use of VirusTotal (VT). Academic researchers rely heavily on VT to analyze (and label) their samples: 18 out of the 32 datasets in Table 3 had their samples scanned on VT in at least one of the papers that used that dataset. Researchers generally label a sample as malicious if it is flagged by more than a certain threshold VT engines, e.g., Reference [94], ignoring the fact that many AV products rely on 3rd party AV engines [56].For the research community, the dilemma lies in that VT is an easily accessible resource. However, we argue that this resource should be used with a good understanding of its limitations. For instance, VT relies on a simplified version of the represented AV engines https://blog.virustotal.com/2012/08/av-comparative-analyses-marketing-and.html (accessed on 5 December 2020, which introduces limitations when seeking consensus or comparing engines.
- Unknown representativeness. We find information about when the samples are generally collected. However, details about when the samples were observed in the wild and their subsequent prevalence are usually not reported. We observe discrepancies across papers regarding such dates, even in known datasets, such as Malgenome [10] and Drebin [12]. For instance, the authors of Reference [12] rely on VT to obtain their labels; they mention that the dataset contains samples seen between from 2010 and 2012. However, when we independently query VT, we find that the first_seen dates are between 2009 and 2013 (see Table 4). Taking into account sample dates is important to avoid: (a) training classifiers with outdated samples that are no longer representative of the threat landscape or (b) training the classifier with recent samples while testing it using older ones. However, obtaining an accurate value of the date in which a sample has been in operation can be challenging. First, threat intelligence might not be available. Next, timestamps from the samples can be easily tampered with. Finally, estimating it from the min. SDK and the max. SDK offers a very coarse range of dates.
- Label harmonization. It is a rather common practice to use semi-automated processes to perform label harmonization when performing family classification. A popular tool is AVCLASS [24], although there are others, e.g. Euphony [18] and AVCLASS2 [28]. (Euphony and AVCLASS2 were used in Zhang et al. [136] and Sebastian and Caballero [28] consecutively. We do not include them in Table 3 because they were not used when crafting a dataset but, rather, when authors were designing their experiments.) Manual labeling was used only in Reference [10] when authors inspected the set manually to determine the family of each sample; something not scalable when constructing bigger sets.
- Use distribution. Out of 146 uses of the datasets in our study, more than 70% use 7 popular datasets. Malgenome alone is almost used 25% of the time, even in recent works [28]. On the other hand, our analysis shows that about 30% of the works use an unpopular set. Some of these sets are proprietary or unavailable. This is a clear sign that authors have confidence in well established datasets. For instance, Wang et al.’s dataset [113], which appeared in 2018, has 4.5 M samples and is accessible to the community but was only used once.
4. Coverage Analysis
4.1. Our Dataset
4.2. Results of Coverage Experiments
5. Label Analysis
5.1. Labeling Convention
The full name of a virus consists of up to four parts, desimited by points (‘.’). Any part may be missing, but at least one must be present. The general format is Family_Name.Group_Name.Major_Variant.Minor_Variant[[:Modifier],
5.2. Labeling Challenges
5.3. Engines Label Findings
- ESET-NOD32: 3 K samples have the label multiple detections. Sometimes the string includes a variant of before the label and sometimes it includes potentially unwanted or potentially unsafe after the label. 193 K samples, i.e., 12% of the AV’s flagged samples are labeled a variant of Android/Packed.Jiagu.<some_variant> potentially unsafe. Yet, Jiagu refers to Jiagu 360, a famous Chinese packer, not a family name.
- Ikarus: We found labels, such as AdWare.Adware, AdWare.ANDR, and AdWare.AndroidOS. We are not able to explain the inconsistency in these similar labels. In addition, samples whose labels lacked a family name but used the word Qihoo and Jiangu (both chinese packers) are quite frequent.
- Fortinet: Lack of class name is quite frequent, e.g., Android/Styricka.A!tr. Riskware/Jiagu!Android is the top label with 103 K samples (9%). Android/Agent.FS!tr.dldr represents 4% of the labeled samples. Adware/Waps!Android and Adware/Waps.G appear to be the same, but one has the platform name, while the other lacks it (they collectively represents 4.5% of labeled samples).
- Cat-QuickHeal: Lack of identifiable family name, e.g., in Android.km.Aeb23 (PUP) is km the family name or just a randomly generated string with some automation tool? Generic labels Android.Downloader.N and Android.Agent.GEN23333 (PUP) represent 8% of the dataset. Similarly, Android.Jiagu.A (PUP) represents 4.3% of the set.
- Nano-Antivirus: 5% of the samples are labeled Riskware.Android.Agent.entxvm, which is the top label in the set.
- SymantecMobileInsight: 64% of the labels are not associated with a family. The labels follow this format: AppRisk:Generisk, AdLibrary:Generisk, Other:Android.Reputation.1, and Other:Android.Reputation.2
- Avira: 4.7% of the samples have the generic label ANDROID/Dldr.Agent.FS.Gen, the second most frequent label. Labels with numbers as family name, e.g., 33 in Android/DownLoader.33.31, are not uncommon. In addition, we are not sure if the family name can be represented by all uppercase or the family part is just randomly generated and the samples lacks a family name, e.g., AMAA in the label ADWARE/ANDR.AdDisplay.AMAA.Gen.
- Cyren: It uses completely different taxonomies in its labels, such as AndroidOS/GenPua.95BB2BF2! Olympus and Trojan.BYLR-9. In addition, there is a lack of family name in the first, and unidentifiable family name and missing platform in the second.
- K7GW: Lacking family name, as well as platform, in all of its labels, e.g., Adware (0053361f1), Exploit (004c0f451).
- F-Secure: Lack of consistency in top labels Adware:Android/AdWo and Android.Adware. Adwo.A, which represent, collectively, 8.4% of the labels.
- Prioritizing detection over family identification. This is seen in ESET-NOD32, Fortinet, and Cat-QuickHeal, which give packed samples labels related to packing rather than their unwanted behavior.
- Lack of knowledge of the territory because of Android’s relative novelty compared to the well-established expertise in Windows, which has been there for decades.
6. Family and Class Analysis
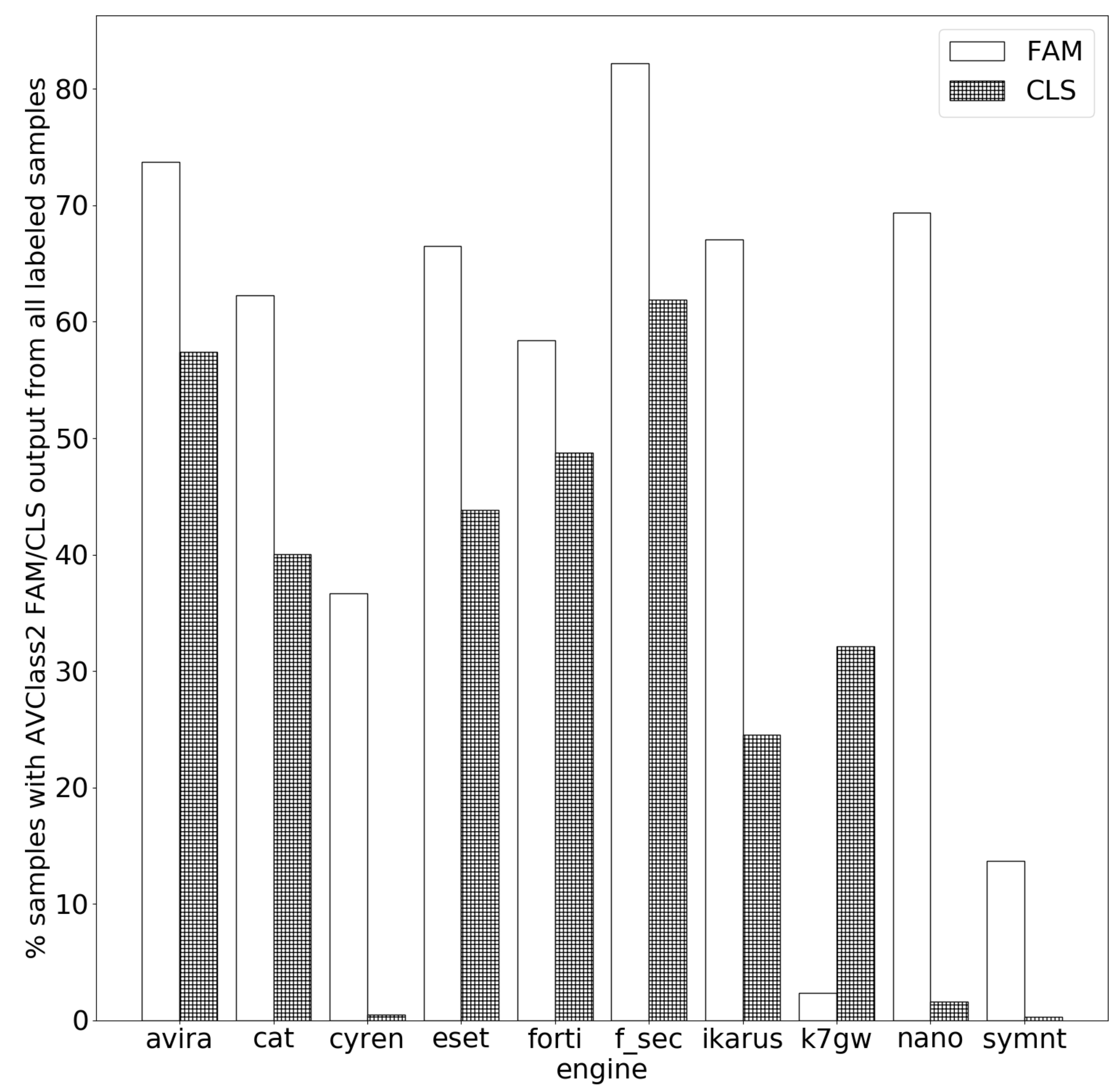
- Measuring the ability of unifying tools (AVCLASS2 in this case) to extract family and class names from the samples that each of the engines flags. We also run the same experiments for the AV pairs.
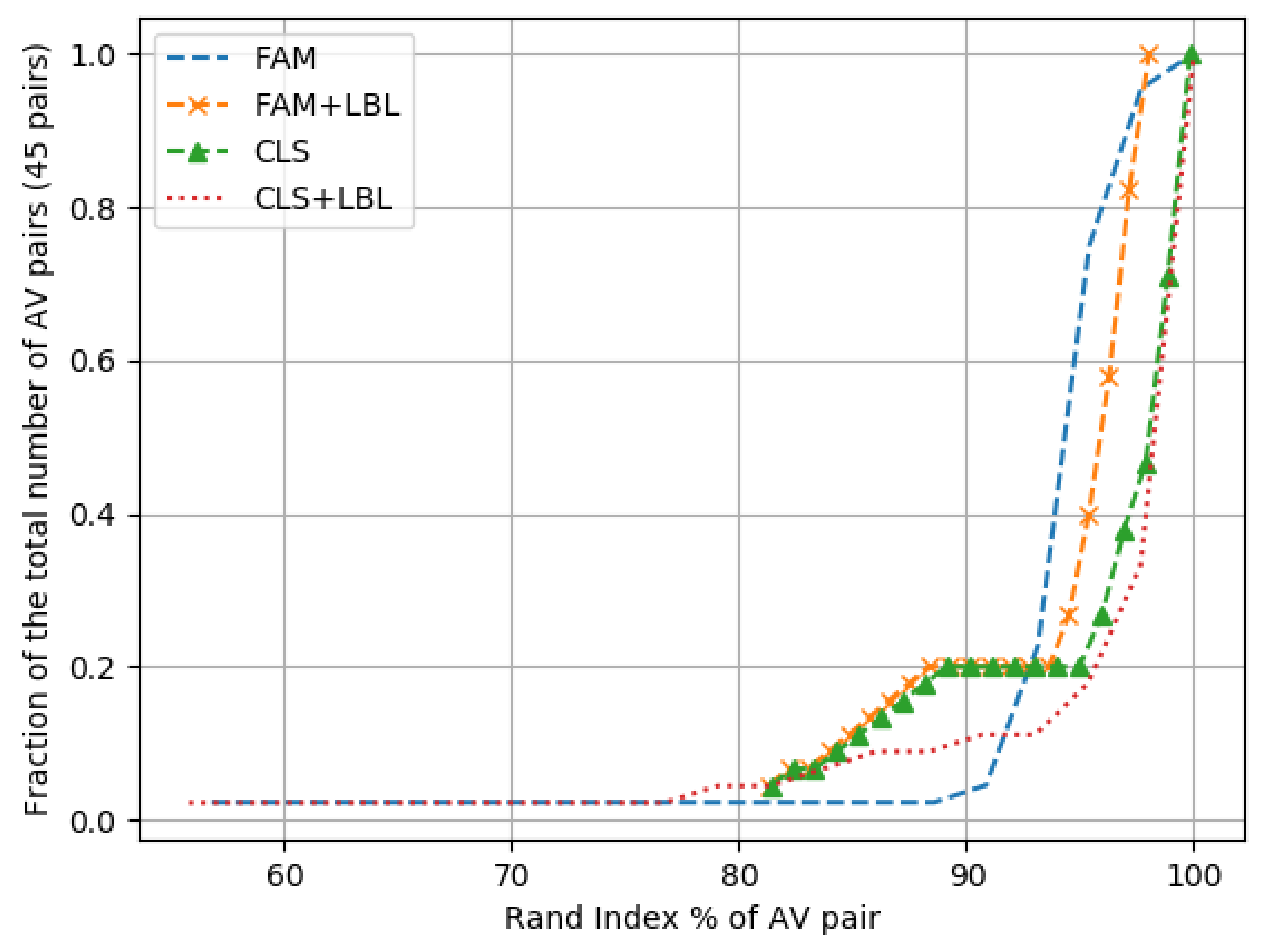
- Measuring the coherence across engine pairs when grouping together samples according to their families by identifying the agreement level among the family clusters of the different AV engines without taking into consideration the actual family names used by the engines. We repeat the analysis for the class labels. Both coherence experiments help us determine if the underlying classification methodologies used by different AVs produce similar results or not.
6.1. Family and Class Name Extraction
6.2. Classification Coherence across Services
6.3. Family and Class Coherence
- We use the results of the Family Name Extraction experiment of AV pairs as an input.
- We complement the list of family names with full labels of AVi, for which AVCLASS2 could not obtain a FAM value.
6.4. Analysis of Family and Class Coherence Results
7. Discussion
7.1. Recommendations
- Understanding the interdependencies among the different engines and discarding results from redundant ones, such as in the case of F-Secure and Avira.
- Taking into account: (a) the tendency of AV engines to give generic labels instead of family identifying ones and b) the variability of generic labels, e.g., Avira’s generic labels: ANDROID/Agent.qzqlq, SPR/ANDR.Agent.cdhey, Android/Spy.Agent.FI.Gen.
- Machine-Learning-based family classification systems that discard samples with generic labels, despite their very high accuracy, would not stand in a real-world scenario where there is non-stop influx of incoming malware. In these systems, the classifier is fitted with features extracted from the samples in the dataset and would be greatly affected by changes to the structure of that particular dataset. ML have been historically tied to ground-truth non-changing samples, such as image recognition, and applying that to a continuous changing field, such as malware detection/classification is challenging [7]. In addition, these classification systems cannot be compared to AV engines, whose goal is detection rather than family classification.
- Blind usage of label unification tools does not take into account the variability in family names that AVs might use for the same family, thus introducing noise into the ML algorithm. For example, samples that were flagged by Ikarus as part of the coogos family have been majorly flagged (80%) by ESET-NOD32 as belonging to the kuogo family. We deduce that ESET-NOD32’s kuogo is in fact Ikarus’s coogos. Yet, we are convinced that this label equivalence requires a much deeper analysis to be able to compare equivalent families from different AVs. This phenomenon is even confirmed by the industry [142], which indicated that different AVs give different names to the same family. Using techniques, such as Rand Index, to measure similarity between label clusters of AV families along side label unification is essential so as not to introduce subtle noise in the classifier.
7.2. Limitations and Biases
- Lack of transparency and limited information from AV vendors regarding data on malware families: We were not able to obtain relevant information except from the vendors on which we reported. Hence, the real-world status of malware families might differ from our version.
- Lack of ground-truth for samples in our dataset: While we tried our best to use previously flagged samples, we set our initial threshold at 1 engine before rescanning them on VT. The rescanning yielded a minimum of 5 flaggings per samples and considered 300 K samples as benign. However, we cannot confirm that all of the samples in the rescanned set are malware or that the labels in the VT reports are 100% accurate.
- We lacked knowledge about the flagging influence among the AVs for this particular dataset, especially that it includes only Android samples. While Zhu et al. [140] were able to identify relationships and dependencies between several AV engines, we could not claim that these inter-dependencies extend to our dataset.
- We were unable to study and analyze different generic labels because of the different taxonomies used by each AV. This affected our ability to extract any possible existing FAM/CLASS intelligence by updating AVCLASS2 with new family/class names, which, of course, could have changed the output of the coherence experiments seen in Figure 5.
8. Related Work
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Paper Distribution over Conferences

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Venue | Year (20xx) | Total | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
| CCS | - | 1 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 11 |
| USENIX | - | - | 2 | - | - | - | - | 2 | 2 | 1 | - | 7 |
| RAID | - | - | - | 1 | 2 | 1 | 1 | - | 2 | - | 7 | |
| ACSAC | - | 1 | 1 | 1 | 2 | 2 | 1 | 4 | 3 | - | 1 | 16 |
| DIMVA | - | - | 2 | - | 1 | 1 | - | 1 | - | - | - | 5 |
| ASIACSS | - | - | - | 2 | 1 | 3 | 4 | 5 | - | 1 | 1 | 17 |
| S&P | - | - | - | - | - | 2 | 1 | - | - | - | - | 3 |
| NDSS | - | - | - | 2 | 3 | 2 | 3 | 3 | 1 | - | 1 | 15 |
| sum Yr | - | 2 | 6 | 8 | 9 | 13 | 11 | 17 | 7 | 5 | 4 | 81 |
References
- Curry, D. Android Statistics. 2021. Available online: https://www.businessofapps.com/data/android-statistics/ (accessed on 23 June 2021).
- Emm, D.; Kaspersky Security Bulletin 2012. Malware Evolution. Available online: https://securelist.com/kaspersky-security-bulletin-2012-malware-evolution/36732/ (accessed on 23 June 2021).
- Development of New Android Malware Worldwide from June 2016 to March 2020. Available online: https://www.statista.com/statistics/680705/global-android-malware-volume/ (accessed on 4 August 2021).
- Kaspersky Mobile Security Lite Now Available for Free on Android Market. Available online: https://www.kaspersky.com/about/press-releases/2011_kaspersky-mobile-security-lite-now-available-for-free-on-android-market (accessed on 25 May 2021).
- Early Reviews of Avast! Free Mobile Security. Available online: https://blog.avast.com/2012/01/02/early-reviews-of-avast-free-mobile-security/ (accessed on 25 May 2021).
- Norton Mobile Security for Android 1.5 Beta. Available online: https://uk.pcmag.com/antivirus/21480/norton-mobile-security-for-android-15-beta (accessed on 25 May 2021).
- Machine Learning for Malware Detection. Available online: https://media.kaspersky.com/en/enterprise-security/Kaspersky-Lab-Whitepaper-Machine-Learning.pdf (accessed on 9 August 2021).
- Gheorghescu, M. An automated virus classification system. In Proceedings of the Virus Bulletin Conference, Dublin, Ireland, 5–7 October 2005; pp. 294–300. [Google Scholar]
- Harley, D. AVIEN Malware Defense Guide for the Enterprise; Elsevier: Burlington, MA, USA, 2007. [Google Scholar]
- Zhou, Y.; Jiang, X. Dissecting android malware: Characterization and evolution. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; p. 95. [Google Scholar]
- Garcia, J.; Hammad, M.; Malek, S. [Journal First] Lightweight, Obfuscation-Resilient Detection and Family Identification of Android Malware. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE), Gothenburg, Sweden, 27 May–3 June 2018; p. 497. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and Explainable Detection of Android Malware in your Pocket. In Proceedings of the NDSS, San Diego, CA, USA, 23–26 February 2014; pp. 23–26. [Google Scholar]
- Suarez-Tangil, G.; Dash, S.K.; Ahmadi, M.; Kinder, J.; Giacinto, G.; Cavallaro, L. Droidsieve: Fast and accurate classification of obfuscated android malware. In Proceedings of the Seventh ACM on Conference on Data and Application Security and Privacy, Scottsdale, AZ, USA, 22–24 March 2017; pp. 309–320. [Google Scholar]
- Fan, M.; Liu, J.; Luo, X.; Chen, K.; Chen, T.; Tian, Z.; Zhang, X.; Zheng, Q.; Liu, T. Frequent subgraph based familial classification of android malware. In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; pp. 24–35. [Google Scholar]
- Zhang, M.; Duan, Y.; Yin, H.; Zhao, Z. Semantics-aware android malware classification using weighted contextual api dependency graphs. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1105–1116. [Google Scholar]
- Andronio, N.; Zanero, S.; Maggi, F. Heldroid: Dissecting and detecting mobile ransomware. In International Symposium on Recent Advances in Intrusion Detection; Springer: Kyoto, Japan, 2015; pp. 382–404. [Google Scholar]
- Damshenas, M.; Dehghantanha, A.; Choo, K.K.R.; Mahmud, R. M0droid: An android behavioral-based malware detection model. J. Inf. Priv. Secur. 2015, 11, 141–157. [Google Scholar] [CrossRef]
- Hurier, M.; Suarez-Tangil, G.; Dash, S.K.; Bissyandé, T.F.; Traon, Y.L.; Klein, J.; Cavallaro, L. Euphony: Harmonious unification of cacophonous anti-virus vendor labels for Android malware. In Proceedings of the 14th International Conference on Mining Software Repositories, Buenos Aires, Argentina, 20–21 May 2017; pp. 425–435. [Google Scholar]
- Dashevskyi, S.; Zhauniarovich, Y.; Gadyatskaya, O.; Pilgun, A.; Ouhssain, H. Dissecting Android Cryptocurrency Miners. In Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 16–18 March 2020; pp. 191–202. [Google Scholar]
- Kadir, A.F.A.; Stakhanova, N.; Ghorbani, A.A. Understanding android financial malware attacks: Taxonomy, characterization, and challenges. J. Cyber Secur. Mobil. 2018, 7, 1–52. [Google Scholar] [CrossRef]
- Duan, Y.; Zhang, M.; Bhaskar, A.V.; Yin, H.; Pan, X.; Li, T.; Wang, X.; Wang, X. Things You May Not Know about Android (Un) Packers: A Systematic Study based on Whole-System Emulation. In Proceedings of the NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Lindorfer, M.; Neugschwandtner, M.; Platzer, C. Marvin: Efficient and comprehensive mobile app classification through static and dynamic analysis. In Proceedings of the 2015 IEEE 39th Annual Computer Software and Applications Conference, Taichung, Taiwan, 1–5 July 2015; Volume 2, pp. 422–433. [Google Scholar]
- Wang, H.; Si, J.; Li, H.; Guo, Y. Rmvdroid: Towards a reliable android malware dataset with app metadata. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 404–408. [Google Scholar]
- Sebastián, M.; Rivera, R.; Kotzias, P.; Caballero, J. Avclass: A tool for massive malware labeling. In International Symposium on Research in Attacks, Intrusions, and Defenses; Springer: Evry, France, 2016; pp. 230–253. [Google Scholar]
- Botacin, M.; Ceschin, F.; Sun, R.; Oliveira, D.; Grégio, A. Challenges and Pitfalls in Malware Research. Comput. Secur. 2021, 106, 102287. [Google Scholar] [CrossRef]
- Perdisci, R.; ManChon, U. VAMO: Towards a fully automated malware clustering validity analysis. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 329–338. [Google Scholar]
- Bayer, U.; Comparetti, P.M.; Hlauschek, C.; Kruegel, C.; Kirda, E. Scalable, Behavior-Based Malware Clustering. In Proceedings of the NDSS, San Diego, CA, USA, 8–11 February 2009; pp. 8–11. [Google Scholar]
- Sebastián, S.; Caballero, J. AVclass2: Massive Malware Tag Extraction from AV Labels. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 42–53. [Google Scholar]
- Rieck, K.; Trinius, P.; Willems, C.; Holz, T. Automatic analysis of malware behavior using machine learning. J. Comput. Secur. 2011, 19, 639–668. [Google Scholar] [CrossRef]
- IBM Cloud Education. Unsupervised Learning. Available online: https://www.ibm.com/cloud/learn/unsupervised-learning (accessed on 4 August 2021).
- Bailey, M.; Oberheide, J.; Andersen, J.; Mao, Z.M.; Jahanian, F.; Nazario, J. Automated classification and analysis of internet malware. In International Workshop on Recent Advances in Intrusion Detection; Springer: Gold Goast, Australia, 2007; pp. 178–197. [Google Scholar]
- Kinable, J.; Kostakis, O. Malware classification based on call graph clustering. J. Comput. Virol. 2011, 7, 233–245. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel feature extraction, selection and fusion for effective malware family classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018, arXiv:1802.10135. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Australasian Joint Conference on Artificial Intelligence; Springer: Hobart, TAS, Australia, 2016; pp. 137–149. [Google Scholar]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.; Wang, Y.; Iqbal, F. Malware classification with deep convolutional neural networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Hu, X.; Chiueh, T.c.; Shin, K.G. Large-scale malware indexing using function-call graphs. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–3 November 2009; pp. 611–620. [Google Scholar]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware images: Visualization and automatic classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; pp. 1–7. [Google Scholar]
- Tian, R.; Batten, L.; Islam, R.; Versteeg, S. An automated classification system based on the strings of trojan and virus families. In Proceedings of the 2009 4th International conference on malicious and unwanted software (MALWARE), Montreal, QC, Canada, 13–14 October 2009; pp. 23–30. [Google Scholar]
- IDA Pro. A Powerful Disassembler and a Versatile Debugger. Available online: https://hex-rays.com/ida-pro/ (accessed on 23 June 2021).
- Deshotels, L.; Notani, V.; Lakhotia, A. Droidlegacy: Automated familial classification of android malware. In Proceedings of the ACM SIGPLAN on Program Protection and Reverse Engineering Workshop, San Diego, CA, USA, 22–24 January 2014; ACM: New York, NY, USA, 2014; p. 3. [Google Scholar]
- Suarez-Tangil, G.; Tapiador, J.E.; Peris-Lopez, P.; Blasco, J. Dendroid: A text mining approach to analyzing and classifying code structures in android malware families. Expert Syst. Appl. 2014, 41, 1104–1117. [Google Scholar] [CrossRef] [Green Version]
- Dash, S.K.; Suarez-Tangil, G.; Khan, S.; Tam, K.; Ahmadi, M.; Kinder, J.; Cavallaro, L. Droidscribe: Classifying android malware based on runtime behavior. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22 May 2016; pp. 252–261. [Google Scholar]
- Chakraborty, T.; Pierazzi, F.; Subrahmanian, V. EC2: Ensemble clustering and classification for predicting android malware families. IEEE Trans. Dependable Secur. Comput. 2017, 17, 262–277. [Google Scholar] [CrossRef] [Green Version]
- Androguard. Available online: https://github.com/androguard/androguard (accessed on 6 May 2020).
- Apktool. Available online: https://ibotpeaches.github.io/Apktool/ (accessed on 6 May 2020).
- Lantz, P. Dynamic Analysis of Android Apps. Available online: https://github.com/pjlantz/droidbox (accessed on 19 November 2019).
- Cuckoo Automated Malware Analysis. Available online: https://cuckoosandbox.org/ (accessed on 19 November 2019).
- Kaspersky Scan Engine Detection Technologies. Available online: https://support.kaspersky.com/ScanEngine/1.0/en-US/179821.htm (accessed on 25 May 2021).
- What are Signatures and How Does Signature-Based Detection Work? Available online: https://home.sophos.com/en-us/security-news/2020/what-is-a-signature.aspx (accessed on 25 May 2021).
- What is Heuristic Analysis? Available online: https://usa.kaspersky.com/resource-center/definitions/heuristic-analysis. (accessed on 8 August 2021).
- Chistyakov, A.; Andreev, A. AI Under Attack: How to Secure Machine Learning in Security Systems; Technical Report; Kaspersky Threat Research. 2019. Available online: https://media.kaspersky.com/en/business-security/enterprise/machine-learning-cybersecurity-whitepaper.pdf (accessed on 22 February 2021).
- Machine Learning in Cybersecurity. Available online: https://www.kaspersky.com/enterprise-security/wiki-section/products/machine-learning-in-cybersecurity (accessed on 22 February 2021).
- What Is a Honeypot? Available online: https://www.kaspersky.com/resource-center/threats/what-is-a-honeypot (accessed on 22 February 2021).
- Cyber Threat Alliance. Available online: https://cyberthreatalliance.org/ (accessed on 22 February 2021).
- List of Consumer AV Vendors (PC). Available online: https://www.av-comparatives.org/list-of-consumer-av-vendors-pc/ (accessed on 14 February 2021).
- Johnston, J.R. Technological Turf Wars: A Case Study of the Computer Antivirus Industry; Temple University Press: Philadelphia, PA, USA, 2008. [Google Scholar]
- Aviews. Available online: http://web.archive.org/web/20080511191350/http://www.aviews.net/ (accessed on 22 February 2021).
- About ASC. Available online: https://web.archive.org/web/20120624014952/http://www.antispywarecoalition.org/documents/index.htm (accessed on 22 February 2021).
- Broadcom Inc. 2016 Internet Security Threat Report. Available online: https://docs.broadcom.com/doc/istr-21-2016-en (accessed on 5 August 2021).
- Internet Security Threat Report; Volume 22. Available online: https://docs.broadcom.com/doc/istr-22-2017-en (accessed on 5 August 2021).
- Internet Security Threat Report; Volume 23. Available online: https://docs.broadcom.com/doc/istr-23-2018-en (accessed on 5 August 2021).
- Internet Security Threat Report; Volume 24. Available online: https://docs.broadcom.com/doc/istr-24-2019-en (accessed on 5 August 2021).
- Motive Security Labs Malware Report—H2 2014. Available online: http://www.alcatel-lucent.com/press/2015/alcatel-lucent-report-malware-2014-sees-rise-device-and-network-attacks-place-personal-and-workplace (accessed on 5 August 2021).
- Nokia Threat Intelligence Report—H2 2015. Available online: http://resources.alcatel-lucent.com/asset/193174 (accessed on 5 August 2021).
- Motive Security Labs Malware Report—H1 2015. Available online: http://https//www.alcatel-lucent.com/press/2015/alcatel-lucent-malware-report-shows-significant-rise-mobile-infections-pcs-and-adware-first-six (accessed on 5 August 2021).
- Nokia Threat Intelligence Report—H1 2016. Available online: https://onestore.nokia.com/asset/200492?_ga=2.143738807.324392894.1628194291-917306451.1628194291 (accessed on 5 August 2021).
- Nokia Threat Intelligence Report—H2 2016. Available online: https://onestore.nokia.com/asset/201094?_ga=2.147017525.324392894.1628194291-917306451.1628194291 (accessed on 5 August 2021).
- Nokia Threat Intelligence Report 2017. Available online: https://onestore.nokia.com/asset/201621?_ga=2.144314295.324392894.1628194291-917306451.1628194291 (accessed on 5 August 2021).
- Nokia Threat Intelligence Report 2019. Available online: https://onestore.nokia.com/asset/205835?_ga=2.180503333.324392894.1628194291-917306451.1628194291 (accessed on 5 August 2021).
- Nokia Threat Intelligence Report 2020. Available online: https://pages.nokia.com/T005JU-Threat-Intelligence-Report-2020.html?_ga=2.215575189.324392894.1628194291-917306451.1628194291 (accessed on 5 August 2021).
- Sophos Security Threat Report 2014. Available online: http://www.sophos.com/en-us/medialibrary/pdfs/other/sophos-security-threat-report-2014.pdf (accessed on 6 August 2021).
- SophosLabs Looking Ahead: SophosLabs 2017 Malware Forecast. Available online: https://www.sophos.com/en-us/medialibrary/PDFs/technical-papers/sophoslabs-2017-malware-forecast-report.pdf (accessed on 6 August 2021).
- SophosLabs 2018 Malware Forecast. Available online: https://www.sophos.com/en-us/medialibrary/PDFs/technical-papers/malware-forecast-2018.pdf (accessed on 6 August 2021).
- Kaspersky Security Bulletin 2012. The Overall Statistics for 2012. Available online: https://securelist.com/kaspersky-security-bulletin-2012-the-overall-statistics-for-2012/36703/#1 (accessed on 6 August 2021).
- Kaspersky Security Bulletin 2014. Overall Statistics for 2014. Available online: https://securelist.com/kaspersky-security-bulletin-2014-overall-statistics-for-2014/68010/ (accessed on 6 August 2021).
- Mobile Malware Evolution 2015. Available online: https://securelist.com/mobile-malware-evolution-2015/73839/ (accessed on 6 August 2021).
- Mobile Malware Evolution 2016. Available online: https://media.kasperskycontenthub.com/wp-content/uploads/sites/43/2018/03/07180734/Mobile_report_2016.pdf (accessed on 6 August 2021).
- Mobile Malware Evolution 2017. Available online: https://securelist.com/mobile-malware-review-2017/84139/ (accessed on 6 August 2021).
- Mobile Malware Evolution 2018. Available online: https://securelist.com/mobile-malware-evolution-2018/89689/ (accessed on 6 August 2021).
- Mobile Malware Evolution 2019. Available online: https://securelist.com/mobile-malware-evolution-2019/96280/ (accessed on 6 August 2021).
- Mobile Malware Evolution 2020. Available online: https://securelist.com/mobile-malware-evolution-2020/101029/ (accessed on 6 August 2021).
- H1 2016 Global and Regional Trends of the ‘Most Wanted’ Malware. Available online: https://blog.checkpoint.com/wp-content/uploads/2016/10/H1_Malware_Report_161028v2.pdf (accessed on 6 August 2021).
- Check Point Research’s 2017 Global Cyber Attack Trends Report. Available online: https://www.checkpoint.com/downloads/product-related/infographic/H2_2017_Global_Cyber_Attack_Trends_Report.pdf (accessed on 6 August 2021).
- Check Point Research’s Cyber Attack Trends Analysis: Key Insights to Gear up for in 2019. Available online: https://www.checkpointdirect.co.uk/media/downloads/check-point-2019-security-report-volume-1.pdf (accessed on 6 August 2021).
- Check Point Research’s 2020 Cyber Security Report. Available online: https://www.checkpoint.com/downloads/resources/cyber-security-report-2020.pdf (accessed on 6 August 2021).
- Android Security 2016 Year In Review. Available online: https://source.android.com/security/reports/Google_Android_Security_2016_Report_Final.pdf (accessed on 6 August 2021).
- Android Security 2017 Year In Review. Available online: https://source.android.com/security/reports/Google_Android_Security_2017_Report_Final.pdf (accessed on 6 August 2021).
- Android Security 2018 Year In Review. Available online: https://source.android.com/security/reports/Google_Android_Security_2018_Report_Final.pdf (accessed on 6 August 2021).
- Contagio Mobile Malware Mini Dump. Available online: https://contagiominidump.blogspot.com/ (accessed on 14 January 2020).
- VirusShare. Available online: https://virusshare.com/ (accessed on 11 September 2019).
- VirusTotal. Available online: https://www.virustotal.com/gui/home/upload (accessed on 11 September 2019).
- DroidBench. Available online: https://github.com/secure-software-engineering/DroidBench (accessed on 10 February 2021).
- Wei, F.; Li, Y.; Roy, S.; Ou, X.; Zhou, W. Deep ground truth analysis of current android malware. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Bonn, Germany, 2017; pp. 252–276. [Google Scholar]
- SandDroid. Available online: http://sanddroid.xjtu.edu.cn:8080/ (accessed on 10 November 2020).
- Allix, K.; Bissyandé, T.F.; Klein, J.; Le Traon, Y. Androzoo: Collecting millions of android apps for the research community. In Proceedings of the 2016 IEEE/ACM 13th Working Conference on Mining Software Repositories (MSR), Austin, TX, USA, 4–15 May 2016; pp. 468–471. [Google Scholar]
- Google Play. Available online: https://play.google.com/store (accessed on 14 January 2020).
- Lindorfer, M.; Neugschwandtner, M.; Weichselbaum, L.; Fratantonio, Y.; Van Der Veen, V.; Platzer, C. Andrubis–1,000,000 apps later: A view on current Android malware behaviors. In Proceedings of the 2014 Third International Workshop on Building Analysis Datasets and Gathering Experience Returns for Security (BADGERS), Wroclaw, Poland, 11 September 2014; pp. 3–17. [Google Scholar]
- DARPA APAC Program. Available online: https://www.darpa.mil/program/automated-program-analysis-for-cybersecurity (accessed on 10 February 2021).
- 7723 Market. Available online: https://goo.gl/iMi4Bo (accessed on 11 February 2021).
- Android Life. Available online: https://goo.gl/hAov2G (accessed on 11 February 2021).
- Eoemarket. Available online: https://goo.gl/FB0ykP (accessed on 11 February 2021).
- Mobomarket. Available online: https://goo.gl/tzpjY7 (accessed on 11 February 2021).
- Wong, M.Y.; Lie, D. Tackling runtime-based obfuscation in Android with {TIRO}. In Proceedings of the 27th {USENIX} Security Symposium ({USENIX} Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1247–1262. [Google Scholar]
- android_run_root_shell. Available online: https://github.com/android-rooting-tools/android_run_root_shell (accessed on 10 February 2021).
- CVE-2012-6422. Available online: https://github.com/dongmu/vulnerability-poc/tree/master/CVE-2012-6422 (accessed on 10 February 2021).
- CVE-2014-3153. Available online: https://github.com/timwr/CVE-2014-3153 (accessed on 10 February 2021).
- Root-Zte-Open. Available online: https://github.com/poliva/root-zte-open (accessed on 10 February 2021).
- CVE-2015-3636. Available online: https://github.com/fi01/CVE-2015-3636 (accessed on 10 February 2021).
- AndroTotal. Available online: http://andrototal.org/ (accessed on 10 February 2021).
- Lindorfer, M.; Volanis, S.; Sisto, A.; Neugschwandtner, M.; Athanasopoulos, E.; Maggi, F.; Platzer, C.; Zanero, S.; Ioannidis, S. AndRadar: Fast discovery of android applications in alternative markets. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Egham, UK, 2014; pp. 51–71. [Google Scholar]
- Lashkari, A.H.; Kadir, A.F.A.; Taheri, L.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark android malware datasets and classification. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; pp. 1–7. [Google Scholar]
- Wang, H.; Liu, Z.; Liang, J.; Vallina-Rodriguez, N.; Guo, Y.; Li, L.; Tapiador, J.; Cao, J.; Xu, G. Beyond google play: A large-scale comparative study of chinese android app markets. In Proceedings of the Internet Measurement Conference 2018, Boston, MA, USA, 31 October–2 November 2018; pp. 293–307. [Google Scholar]
- Kotzias, P.; Caballero, J.; Bilge, L. How Did That Get In My Phone? Unwanted App Distribution on Android Devices. arXiv 2020, arXiv:cs.CR/2010.10088. [Google Scholar]
- Spreitzenbarth, M.; Freiling, F.; Echtler, F.; Schreck, T.; Hoffmann, J. Mobile-sandbox: Having a deeper look into android applications. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1808–1815. [Google Scholar]
- MobiSec Lab Website. Available online: http://www.mobiseclab.org/ (accessed on 10 February 2021).
- Hacking Team Spying Tool Listens to Calls. Available online: https://www.trendmicro.com/en_us/research/15/g/hacking-team-rcsandroid-spying-tool-listens-to-calls-roots-devices-to-get-in.html (accessed on 10 February 2021).
- android-malware. Available online: https://github.com/ashishb/android-malware (accessed on 10 February 2021).
- Canfora, G.; Mercaldo, F.; Moriano, G.; Visaggio, C.A. Composition-malware: Building android malware at run time. In Proceedings of the 2015 10th International Conference on Availability, Reliability and Security, Toulouse, France, 24–27 August 2015; pp. 318–326. [Google Scholar]
- Mirsky, Y.; Shabtai, A.; Rokach, L.; Shapira, B.; Elovici, Y. Sherlock vs moriarty: A smartphone dataset for cybersecurity research. In Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security, Vienna, Austria, 24–28 October 2016; pp. 1–12. [Google Scholar]
- Arbor Networks. Available online: https://www.netscout.com/arbor-ddos (accessed on 11 February 2021).
- Trend Micro. Available online: https://trendmicro.com/ (accessed on 11 February 2021).
- McAfee. Available online: https://mcafee.com/ (accessed on 11 February 2021).
- Comodo Cybersecurity. Available online: https://comodo.com/ (accessed on 11 February 2021).
- Antiy Labs. Available online: https://antiy.net/ (accessed on 11 February 2021).
- Symantec. Available online: https://broadcom.com/ (accessed on 11 February 2021).
- Wei, F.; Lin, X.; Ou, X.; Chen, T.; Zhang, X. Jn-saf: Precise and efficient ndk/jni-aware inter-language static analysis framework for security vetting of android applications with native code. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1137–1150. [Google Scholar]
- Felt, A.P.; Finifter, M.; Chin, E.; Hanna, S.; Wagner, D. A survey of mobile malware in the wild. In Proceedings of the 1st ACM workshop on Security and Privacy in Smartphones and Mobile Devices, Chicago, IL, USA, 17 October 2011; pp. 3–14. [Google Scholar]
- Hoffmann, J.; Neumann, S.; Holz, T. Mobile malware detection based on energy fingerprints—A dead end? In Proceedings of the International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2013; pp. 348–368. [Google Scholar]
- Mutti, S.; Fratantonio, Y.; Bianchi, A.; Invernizzi, L.; Corbetta, J.; Kirat, D.; Kruegel, C.; Vigna, G. Baredroid: Large-scale analysis of android apps on real devices. In Proceedings of the 31st Annual Computer Security Applications Conference, Los Angeles, CA, USA, 7–11 December 2015; pp. 71–80. [Google Scholar]
- Mulliner, C.; Oberheide, J.; Robertson, W.; Kirda, E. Patchdroid: Scalable third-party security patches for android devices. In Proceedings of the 29th Annual Computer Security Applications Conference, New Orleans, LA, USA, 9–13 December 2013; pp. 259–268. [Google Scholar]
- Nadji, Y.; Giffin, J.; Traynor, P. Automated remote repair for mobile malware. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 413–422. [Google Scholar]
- Yuan, L.P.; Hu, W.; Yu, T.; Liu, P.; Zhu, S. Towards large-scale hunting for Android negative-day malware. In Proceedings of the 22nd International Symposium on Research in Attacks, Intrusions and Defenses ({RAID} 2019), Beijing, China, 23–25 September 2019; pp. 533–545. [Google Scholar]
- Chen, K.Z.; Johnson, N.M.; D’Silva, V.; Dai, S.; MacNamara, K.; Magrino, T.R.; Wu, E.X.; Rinard, M.; Song, D.X. Contextual Policy Enforcement in Android Applications with Permission Event Graphs. In Proceedings of the NDSS, San Diego, CA, USA, 24–27 February 2013. [Google Scholar]
- Wu, C.; Zhou, Y.; Patel, K.; Liang, Z.; Jiang, X. AirBag: Boosting Smartphone Resistance to Malware Infection. In Proceedings of the NDSS, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Zhang, X.; Zhang, Y.; Zhong, M.; Ding, D.; Cao, Y.; Zhang, Y.; Zhang, M.; Yang, M. Enhancing State-of-the-art Classifiers with API Semantics to Detect Evolved Android Malware. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 757–770. [Google Scholar]
- OTX AlienVault. Available online: https://otx.alienvault.com/ (accessed on 10 March 2021).
- Amit, I.; Matherly, J.; Hewlett, W.; Xu, Z.; Meshi, Y.; Weinberger, Y. Machine learning in cyber-security-problems, challenges and data sets. arXiv 2018, arXiv:1812.07858. [Google Scholar]
- Salem, A.; Banescu, S.; Pretschner, A. Maat: Automatically Analyzing VirusTotal for Accurate Labeling and Effective Malware Detection. arXiv 2020, arXiv:2007.00510. [Google Scholar]
- Zhu, S.; Shi, J.; Yang, L.; Qin, B.; Zhang, Z.; Song, L.; Wang, G. Measuring and modeling the label dynamics of online anti-malware engines. In Proceedings of the 29th {USENIX} Security Symposium ({USENIX} Security 20), Virtual Event, 12–14 August 2020; pp. 2361–2378. [Google Scholar]
- A New Virus Naming Convention. Available online: http://www.caro.org/articles/naming.html (accessed on 22 February 2021).
- Malware Family Naming Hell is Our Own Fault. Available online: https://www.gdatasoftware.com/blog/malware-family-naming-hell (accessed on 23 June 2021).
- Malware Names. Available online: https://docs.microsoft.com/en-us/windows/security/threat-protection/intelligence/malware-naming (accessed on 12 June 2021).
- Suarez-Tangil, G.; Stringhini, G. Eight Years of Rider Measurement in the Android Malware Ecosystem. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Trojan:AndroidOS/Fakeplayer.B. Available online: https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=Trojan%3AAndroidOS%2FFakeplayer.B (accessed on 22 February 2021).
- Trojan:AndroidOS/Fakebrows.A. Available online: https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?Name=Trojan:AndroidOS/Fakebrows.A (accessed on 22 February 2021).
- Miller, B.; Kantchelian, A.; Tschantz, M.C.; Afroz, S.; Bachwani, R.; Faizullabhoy, R.; Huang, L.; Shankar, V.; Wu, T.; Yiu, G.; et al. Reviewer integration and performance measurement for malware detection. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, San Sebastian, Spain, 7–8 July 2016; Springer: Cham, Switzerland, 2016; pp. 122–141. [Google Scholar]
- Kantchelian, A.; Tschantz, M.C.; Afroz, S.; Miller, B.; Shankar, V.; Bachwani, R.; Joseph, A.D.; Tygar, J.D. Better malware ground truth: Techniques for weighting anti-virus vendor labels. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security, Denver, CO, USA, 12–16 October 2015; pp. 45–56. [Google Scholar]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Warrens, M.J.; van der Hoef, H. Understanding partition comparison indices based on counting object pairs. arXiv 2019, arXiv:1901.01777. [Google Scholar]
- App Defense Alliance. Available online: https://developers.google.com/android/play-protect/app-defense-alliance/ (accessed on 4 April 2021).
- Maggi, F.; Bellini, A.; Salvaneschi, G.; Zanero, S. Finding non-trivial malware naming inconsistencies. In Proceedings of the International Conference on Information Systems Security, Kolkata, India, 15–19 December 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 144–159. [Google Scholar]
- Zhang, Y.; Sui, Y.; Pan, S.; Zheng, Z.; Ning, B.; Tsang, I.; Zhou, W. Familial clustering for weakly-labeled android malware using hybrid representation learning. IEEE Trans. Inf. Forensics Secur. 2019, 15, 3401–3414. [Google Scholar] [CrossRef]
- Pirch, L.; Warnecke, A.; Wressnegger, C.; Rieck, K. TagVet: Vetting Malware Tags using Explainable Machine Learning. In Proceedings of the 14th European Workshop on Systems Security 2021, Online, 26 April 2021. [Google Scholar]
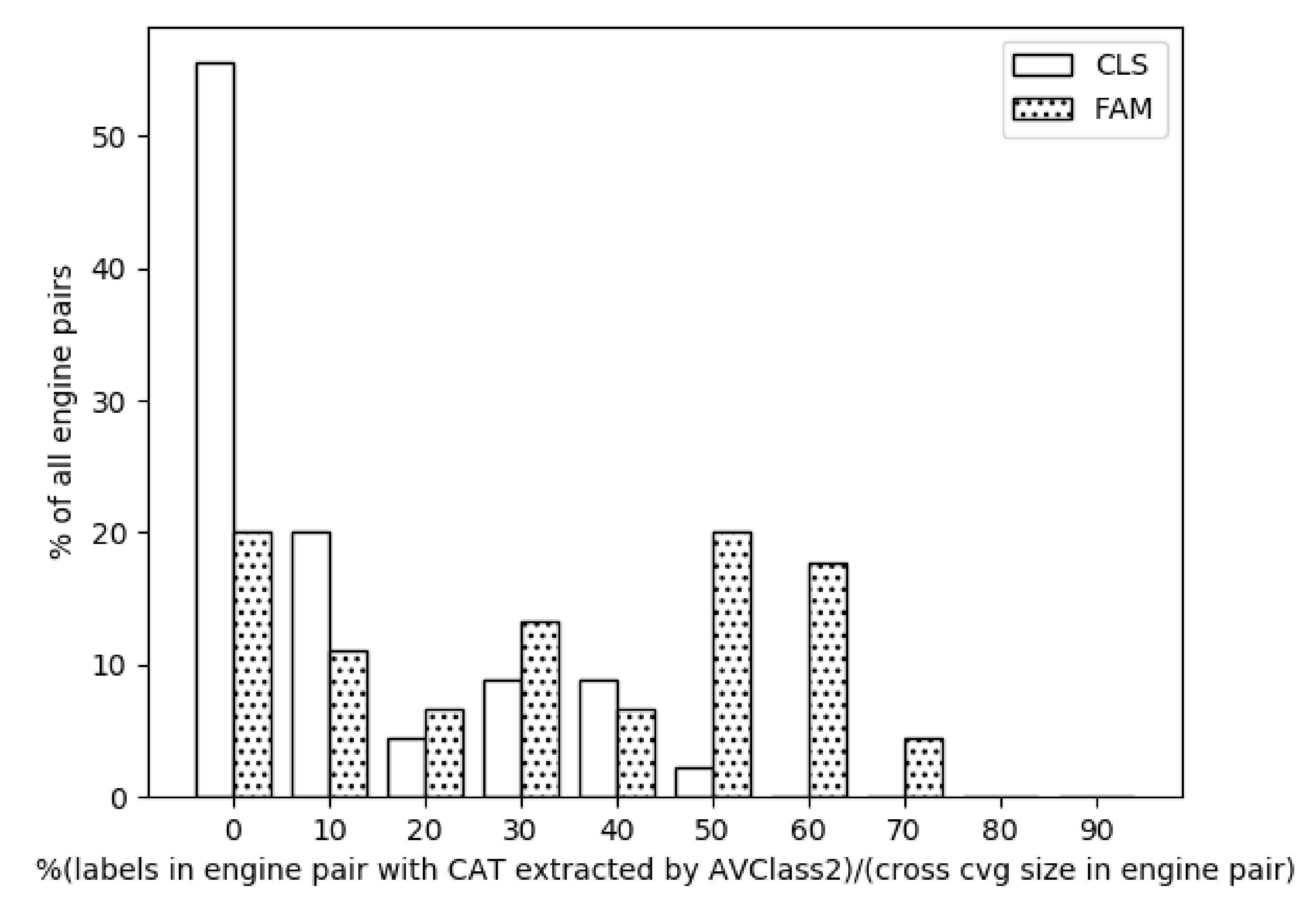
| Company | Year (20xx) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| Symantec® | - | - | - | Y [60] | Y [61] | Y [62] | Y [63] | - | - |
| Nokia® | - | - | H2 [64] | H1,H2 [65,66] | H1,H2 [67,68] | Y [69] | Y [70] | - | Y [71] |
| Sophos® | - | Y [72] | - | - | Y [73] | Y [74] | - | - | - |
| Kaspersky® | Y [75] | - | Y [76] | Y [77] | Y [78] | Y [79] | Y [80] | Y [81] | Y [82] |
| CheckPoint® | - | - | - | - | H1 [83] | Y [84] | Y [85] | Y [86] | - |
| Google® | - | - | - | - | Y [87] | Y [88] | Y [89] | - | - |
| Companies/Yr Tot. | 1 | 1 | 2 | 3 | 6 | 6 | 5 | 2 | 2 |
| Year | Reports | Common Families |
|---|---|---|
| 14 | 2 | N/A |
| 15 | 3 | Opfake (K, SM), Lotoor (K, SM), Leech (N, K) |
| 16 | 6 | Opfake (SM,SP), FakeInst (SM,SP), HiddenApp (SM,N), |
| Hummingbad (C,G), Ztorg (C,K), Rootnik (SM,N) | ||
| 17 | 6 | Simplocker (SM, SP), Rootnik (N, SP), Sivu (K, N), Ztorg (K, N), |
| Hiddad (K,C), Triada (K,C), Ztorg (K,C) | ||
| 18 | 5 | Triada (G, K, N, C), HiddenApp (SM, N), Lotoor (K, C), Xiny (G, N) |
| 19 | 2 | Necro (K, C) |
| 20 | 2 | Hiddad (N, K) |
| Dataset | # Papers | Labl | # Fams | # Samples | VT | Class. Mthd | Collection Time (20xx) | Papers Using the Dataset by Year (20xx) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||||||||
| Malgenome (MG) [10] | 34 (42%) | Y | 49 | 1260 | N | Manual | 10–11 | 4 | 4 | 3 | 9 | 6 | 4 | 2 | 1 | |||
| Contagio (repo) [90] | 17 (21%) | N | - | UNK-395 | N | N/A | 11- | 2 | 2 | 2 | 3 | 2 | 4 | 1 | 1 | |||
| Drebin [12] | 14 (17%) | Y | 179 | 5560 | Y | Own | 10–12 | 1 | 4 | 7 | 1 | 1 | ||||||
| VirusShare [91] | 10 (12%) | N | - | 11 K–35 K | N/A | N/A | N/A | 1 | 1 | 1 | 4 | 1 | 1 | 1 | ||||
| VT-malware [92] | 9 (11%) | N | - | 2 K-238 K | Y | N/A | N/A | 4 | 3 | 1 | ||||||||
| DroidBench [93] | 4 (5%) | N | - | UNK-200 | N | N/A | N/A | 2 | 1 | |||||||||
| AMD [94] | 3 (3.7%) | Y | 71 | 24 K | Y | Own | 10–16 | 1 | 1 | 2 | ||||||||
| SandDroid (repo) [95] | 3 (3.7%) | N | - | 112-38 K | N/A | N/A | N/A | 2 | 1 | |||||||||
| Androzoo (repo) [96] | 3 (3.7%) | N | - | 3 K–13 K | Y | N/A | N/A | 1 | 2 | |||||||||
| GPlay-mal (repo) [97] | 3 (3.7%) | N | - | UNK-27 | Y | N/A | N/A | 1 | 1 | 1 | ||||||||
| Andrubis [98] | 3 (3.7%) | N | - | 422 K | Y | N/A | N/A | 1 | 1 | 2 | ||||||||
| DARPA [99] | 2 (2.5%) | N | - | 11 | N | N/A | N/A | 1 | 1 | |||||||||
| RmvDroid [23] | 1 (1.2%) | Y | 56 | 9.1 K | Y | AVClass | 14,15,17 | 1 | ||||||||||
| alt markets(repo) [100,101,102,103] | 1 (1.2%) | N | - | 2 K | Y | N/A | N/A | 1 | ||||||||||
| AndroMalTeam [104] | 1 (1.2%) | N | - | 34 | N | N/A | N/A | 1 | ||||||||||
| Marvin [22] | 1 (1.2%) | N | - | 15 K | Y | N/A | N/A | 1 | ||||||||||
| Github (repos) [105,106,107,108,109] | 1 (1.2%) | N | - | 5 | Y | N/A | N/A | 1 | ||||||||||
| AndroTotal [110] | 1 (1.2%) | N | - | 4.1 K | N | N/A | N/A | 1 | ||||||||||
| AndRadar [111] | 1 (1.2%) | N | - | N/A | Y | N/A | N/A | 1 | ||||||||||
| CICAndMal17 [112] | 1 (1.2%) | N | - | 4.3 K | Y | N/A | N/A | 1 | ||||||||||
| Wang et al. [113] | 1 (1.2%) | N | - | 4.5 M | Y | AVClass | 09-17 | 1 | ||||||||||
| AndroPUP [114] | 1 (1.2%) | N | - | 4.6 M | Y | N/A | N/A | 1 | ||||||||||
| Spreitzenbarth et al. [115] | 1 (1.2%) | N | - | 7.5 K | Y | N/A | N/A | 1 | ||||||||||
| MobiSec Lab [116] | 1 (1.2%) | N | - | 2 K | N/A | N/A | N/A | 1 | ||||||||||
| HackingTeam [117] | 1 (1.2%) | N | - | 1 | N | N/A | N/A | 1 | ||||||||||
| ashishb [118] | 1 (1.2%) | N | - | 298 | N | N/A | N/A | 1 | ||||||||||
| M0Droid [17] | 1 (1.2%) | N | - | N/A | Y | N/A | N/A | 1 | ||||||||||
| Canfora et al. [119] | 1 (1.2%) | N | - | 2 | N | N/A | N/A | 1 | ||||||||||
| Sherlock vs. Moriarty [120] | 1 (1.2%) | N | - | 12 | Y | N/A | 2016 | 1 | ||||||||||
| Companies [121,122,123,124,125,126] | 12 (15%) | N | - | 69-1.5 K | N/A | N/A | N/A | 1 | 1 | 3 | 2 | 1 | 4 | |||||
| Custom [16,21,127,128,129,130,131,132] | 9 (11%) | N | - | 2-1 K | Y/N | N/A | N/A | 2 | 2 | 3 | 1 | 1 | ||||||
| unknown [133,134,135] | 3 (3.7%) | N | - | 20–362 | Y/N | N/A | N/A | 1 | 1 | |||||||||
| Summary | 81 | - | 49–179 | UNK-422 K | - | - | 10-UNK | 0 | 2 | 6 | 8 | 9 | 13 | 11 | 17 | 7 | 5 | 4 |
| Dataset | First Seen Range |
|---|---|
| Malgenome | 14 October 2009–12 June 2012 |
| Contagio | 25 February 2011–20 March 2018 |
| Drebin | 14 October 2009–10 August 2013 |
| VirusShare | 11 April 2010-UNK |
| AMD | 17 November 2010–14 May 2016 |
| Research Purpose | # Papers |
|---|---|
| Detection | 34 |
| Analysis/Measurement | 23 |
| Tools | 21 |
| Family Classification | 8 |
| Other | 5 |
| Source | Samples | 1st_seen Range |
|---|---|---|
| Malgenome | 1.2 K | 14 October 2009–12 June 2012 |
| Contagio | 1.6 K | 25 February 2011–20 March 2018 |
| Drebin | 5.6 K | 14 October 2009–10 August 2013 |
| AMD | 24 K | 17 November 2010–14 May 2016 |
| Palo Alto | 104 K | 7 November 2011–3 May 2019 |
| OTX | 116 K | 26 September 2012–9 July 2020 |
| VirusShare | 170 K | 11 April 2010–27 December 2019 |
| AndroZoo | 2.24 M | 14 October 2009–3 November 2020 |
| Total | 2.47 M | ∼late 2009 to late 2020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashed, M.; Suarez-Tangil, G. An Analysis of Android Malware Classification Services. Sensors 2021, 21, 5671. https://doi.org/10.3390/s21165671
Rashed M, Suarez-Tangil G. An Analysis of Android Malware Classification Services. Sensors. 2021; 21(16):5671. https://doi.org/10.3390/s21165671
Chicago/Turabian StyleRashed, Mohammed, and Guillermo Suarez-Tangil. 2021. "An Analysis of Android Malware Classification Services" Sensors 21, no. 16: 5671. https://doi.org/10.3390/s21165671
APA StyleRashed, M., & Suarez-Tangil, G. (2021). An Analysis of Android Malware Classification Services. Sensors, 21(16), 5671. https://doi.org/10.3390/s21165671