
Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers




Abstract
:1. Introduction
- Applying several XAI techniques (GradCAM, LIME, RISE, Squaregrid, Vanilla, Integrated, Smooth Gradients) to compare their resulting heatmaps, and evaluate what biases they expose for the studied classifiers. To our knowledge, this is the first publication that addresses this comparison in a real use case for bias detection in a medical image classifier.
- Analyzing the influence of the architecture choice in classification bias. Namely, this study compares classifiers of the DenseNet, VGG and EfficientNet families. It also compares how these models behave at different stages of validation, as well as the effect of ensembling.
- Analyzing the less explored CT-Scan classifiers and datasets, rather than the already more commonly analyzed CXR ones.
2. Materials and Methods
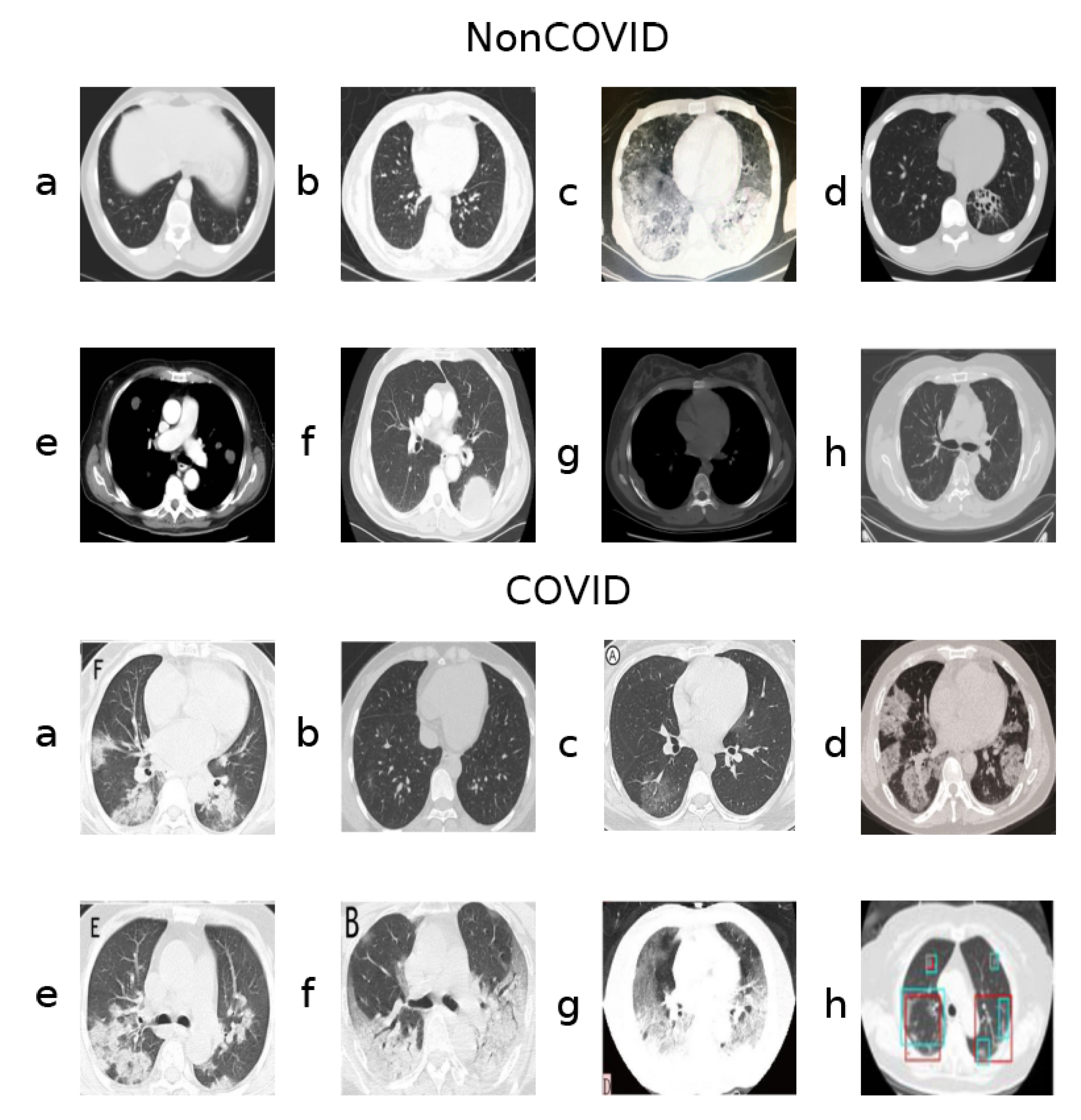
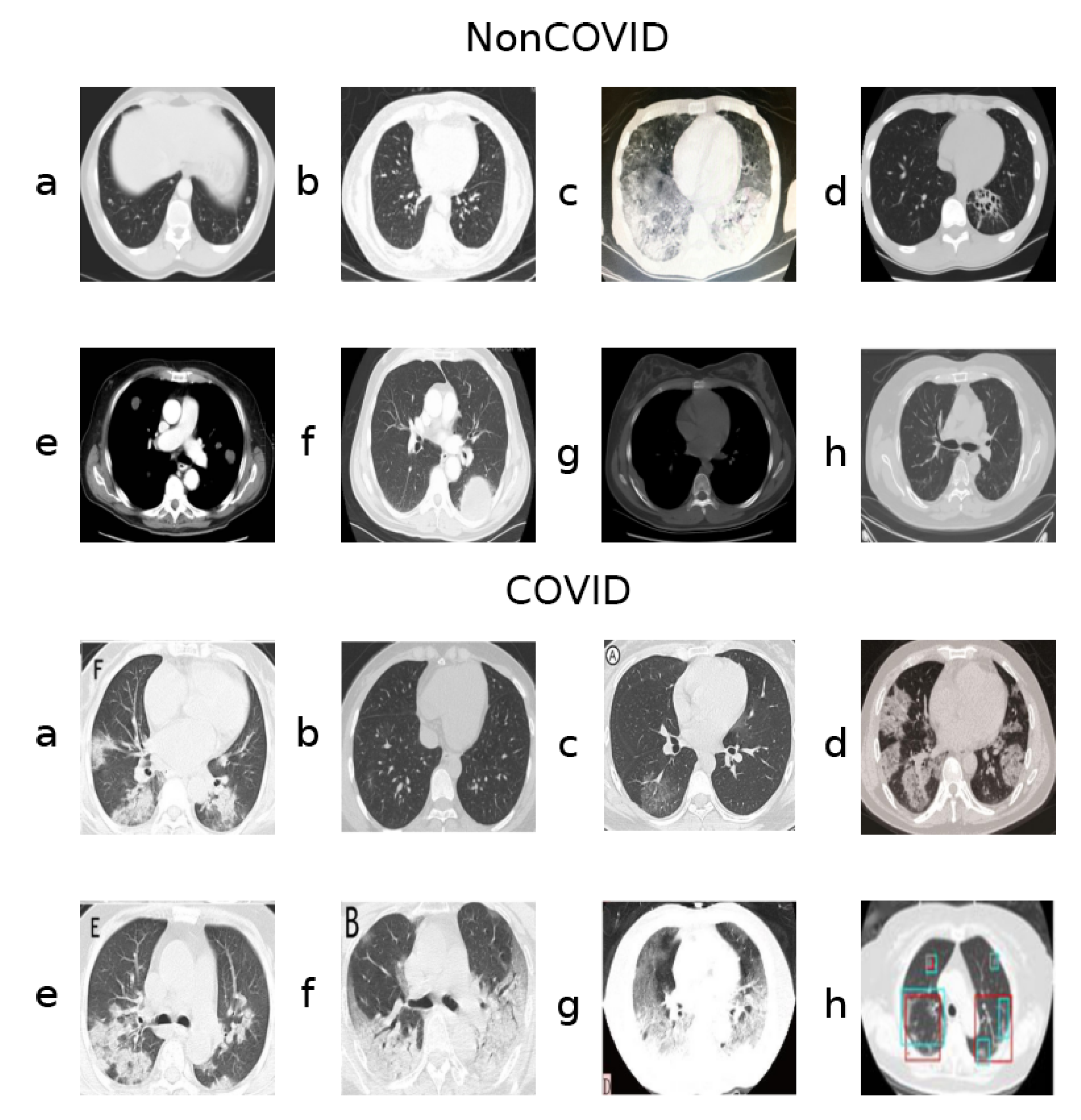
2.1. Dataset
- Training set: 234 class 0 and 191 class 1,
- Validation set: 58 class 0 and 60 class 1
- Test set: 105 class 0 and 98 class 1.
2.2. Models
2.2.1. DenseNet
- F1 score: 0.854
- Accuracy: 0.847
- AUC: 0.919
2.2.2. VGG
2.2.3. EfficientNet
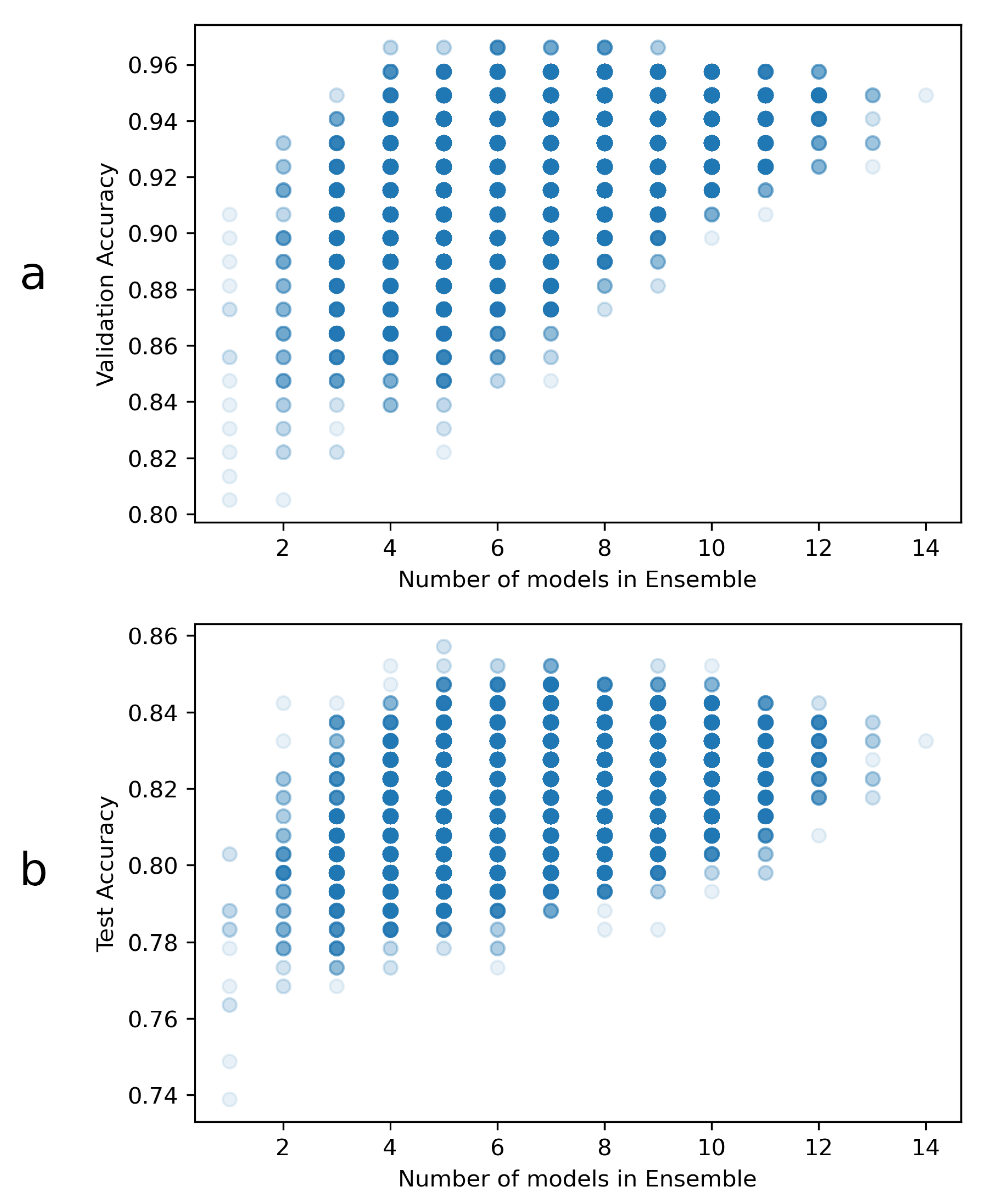
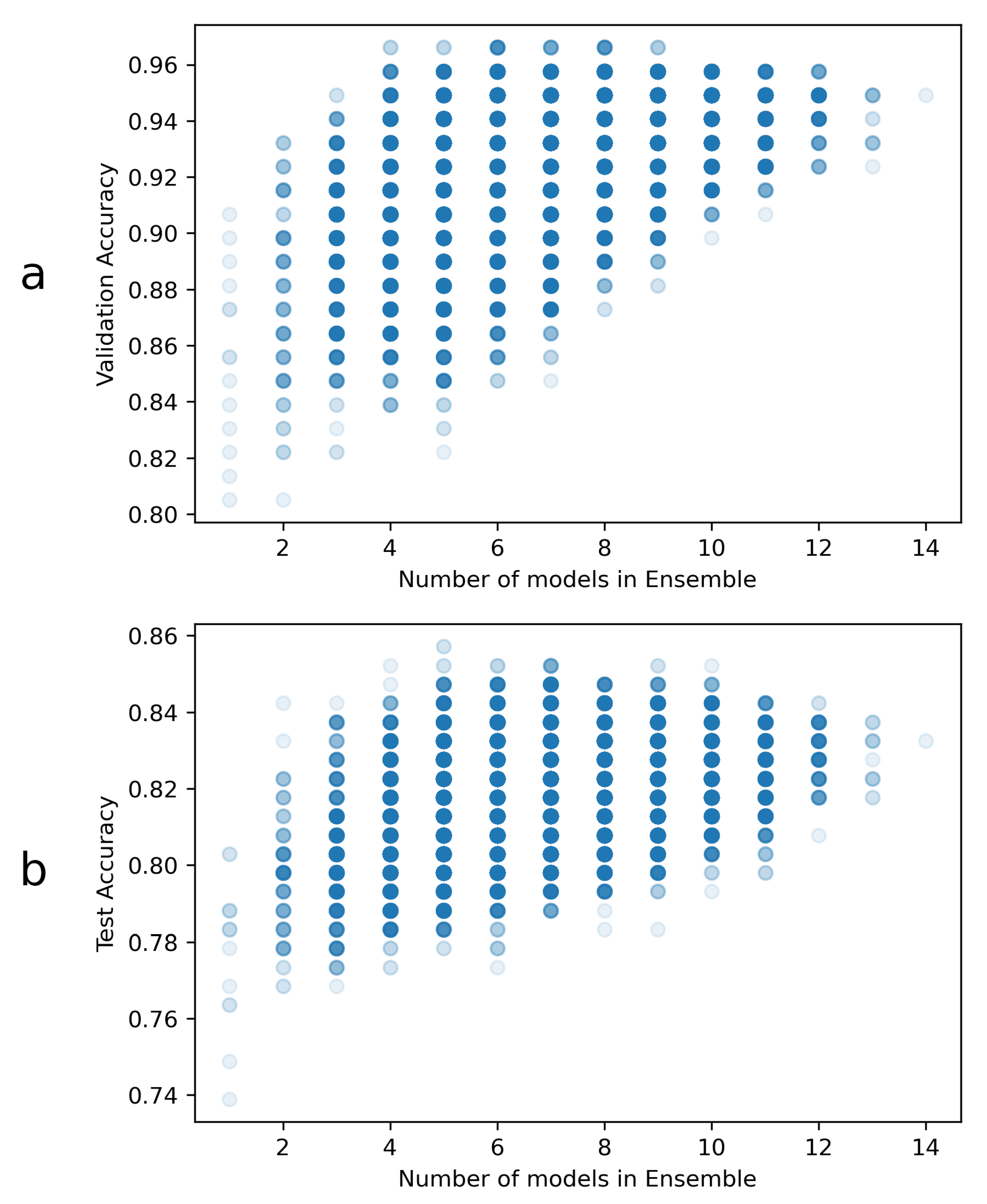
2.2.4. Ensemble
2.2.5. Training
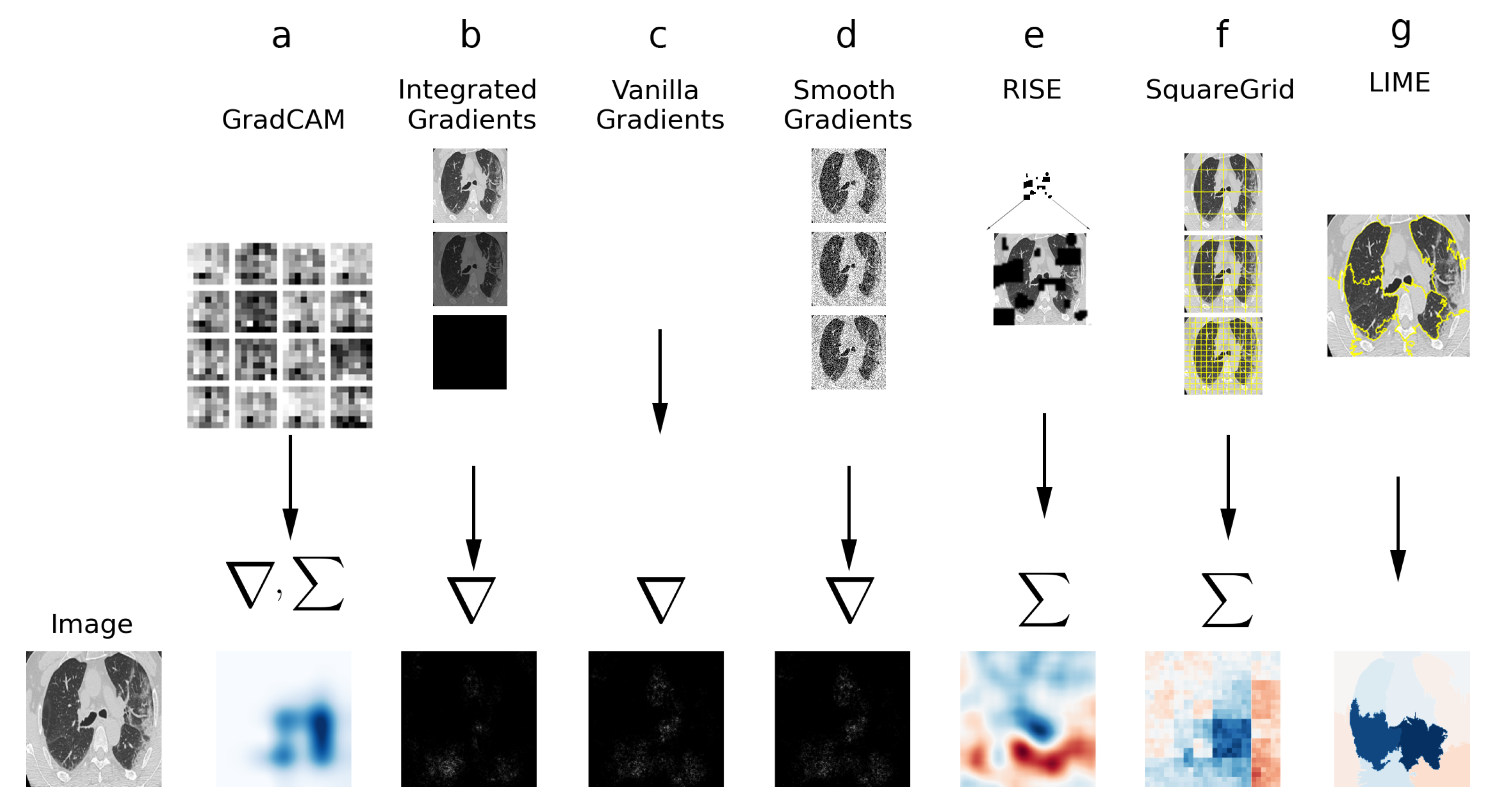
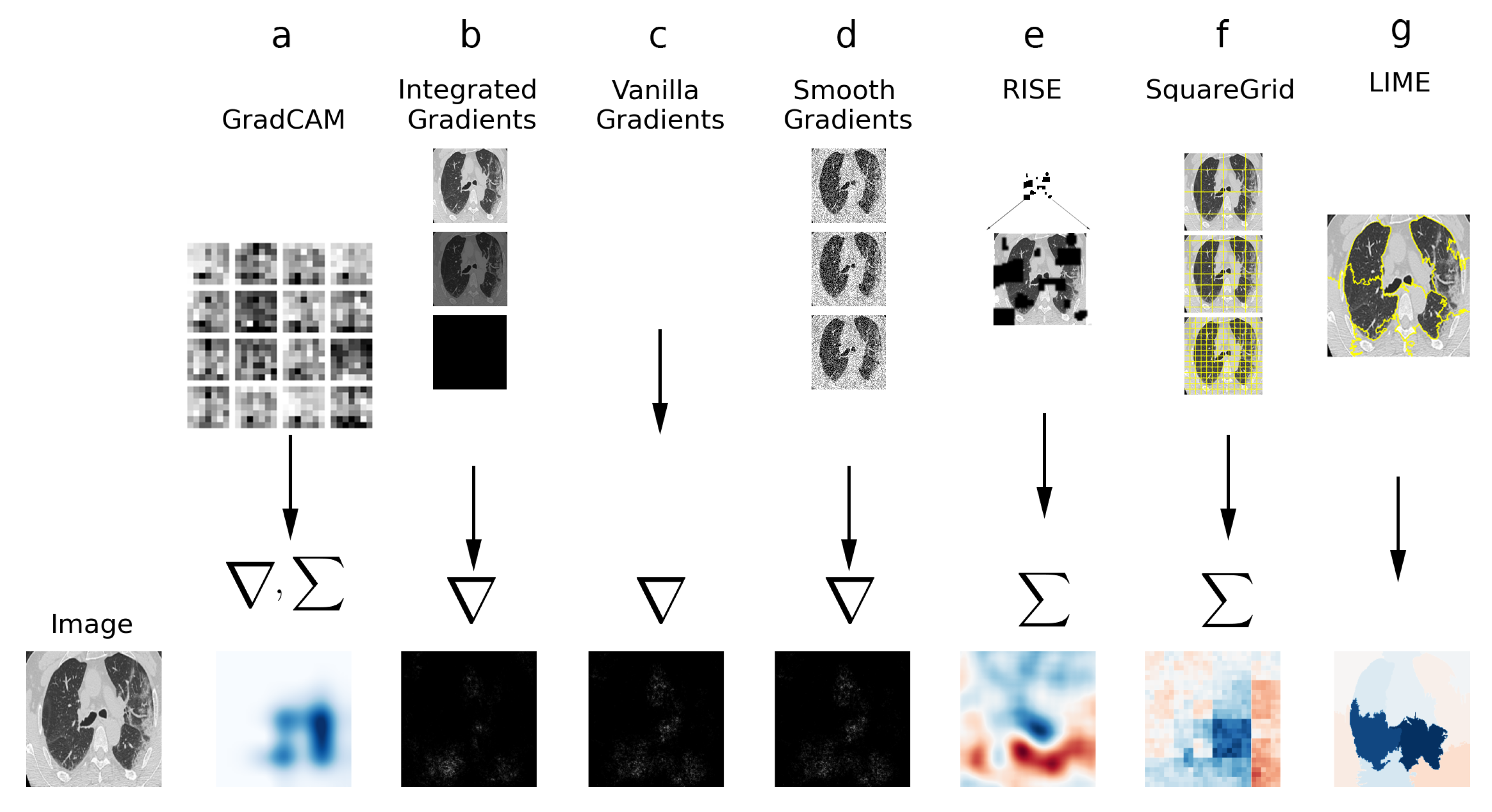
2.3. Explainable AI
2.3.1. LIME
- The image is segmented into superpixels. These are regions of similar colors/textures that hold some type of visual context;
- A distribution of perturbed images is created from the segmented original image, by stochastic perturbation of the original;
- The perturbed images are presented to the classifier model, and their prediction probabilities are computed;
- With the perturbed distribution and prediction probabilities, a surrogate linear model is trained to approximate the CNN locally for the image of interest;
- The weights of this linear model indicate how much each superpixel contributes positively or negatively to the classification;
- These weights are plotted on a heatmap, which is the final output of LIME.
2.3.2. Squaregrid
2.3.3. RISE
2.3.4. GradCAM
2.3.5. Vanilla Gradients
2.3.6. Smooth Gradients
2.3.7. Integrated Gradients
3. Results and Discussion
- VGG16 with validation acc of 83.1% (hereinafter referred as )
- EfficientNet with validation acc of 85.6% (hereinafter referred as )
- DenseNet with validation acc of 89.8% (hereinafter referred as )
- DenseNet with validation acc of 90.7% (hereinafter referred as )
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Zhang, Y.; He, X.; Xie, P. COVID-CT-Dataset: A CT scan dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Wang, L.; Lin, Z.Q.; Wong, A. Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.P.; Morrison, P.; Dao, L.; Roth, K.; Duong, T.Q.; Ghassemi, M. COVID-19 Image Data Collection: Prospective Predictions Are the Future. arXiv 2020, arXiv:2006.11988. [Google Scholar]
- Chan, J. DLAI3 Hackathon Phase3 COVID-19 CXR Challenge. 2020. Available online: https://www.kaggle.com/c/dlai3-phase3/overview (accessed on 19 August 2021).
- Chandra, T.B.; Verma, K.; Singh, B.K.; Jain, D.; Netam, S.S. Coronavirus disease (COVID-19) detection in Chest X-Ray images using majority voting based classifier ensemble. Expert Syst. Appl. 2021, 165, 113909. [Google Scholar] [CrossRef] [PubMed]
- Khuzani, A.Z.; Heidari, M.; Shariati, S.A. COVID-Classifier: An automated machine learning model to assist in the diagnosis of COVID-19 infection in chest X-ray images. medRxiv 2020, 165, 9887. [Google Scholar]
- Yoo, S.H.; Geng, H.; Chiu, T.L.; Yu, S.K.; Cho, D.C.; Heo, J.; Choi, M.S.; Choi, I.H.; Cung Van, C.; Nhung, N.V.; et al. Deep learning-based decision-tree classifier for COVID-19 diagnosis from chest X-ray imaging. Front. Med. 2020, 7, 427. [Google Scholar] [CrossRef]
- Catalá, O.D.T.; Igual, I.S.; Pérez-Benito, F.J.; Escrivá, D.M.; Castelló, V.O.; Llobet, R.; Peréz-Cortés, J.C. Bias analysis on public X-ray image datasets of pneumonia and COVID-19 patients. IEEE Access 2021, 9, 42370–42383. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Graziani, M.; Andrearczyk, V.; Marchand-Maillet, S.; Müller, H. Concept attribution: Explaining CNN decisions to physicians. Comput. Biol. Med. 2020, 123, 103865. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, X.; Yang, X.; Zhang, S.; Zhao, J.; Zhang, Y.; Xing, E.; Xie, P. Sample-Efficient Deep Learning for COVID-19 Diagnosis Based on CT Scans. medRxiv 2020. [Google Scholar] [CrossRef]
- He, X. DenseNet169 Baseline. 2020. Available online: https://github.com/UCSD-AI4H/COVID-CT/tree/master/baseline%20methods/Self-Trans (accessed on 19 August 2021).
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Zebin, T.; Rezvy, S. COVID-19 detection and disease progression visualization: Deep learning on chest X-rays for classification and coarse localization. Appl. Intell. 2021, 51, 1010–1021. [Google Scholar] [CrossRef]
- Horry, M.J.; Chakraborty, S.; Paul, M.; Ulhaq, A.; Pradhan, B.; Saha, M.; Shukla, N. X-ray image based COVID-19 detection using pre-trained deep learning models. engrXiv 2020, 20, 100427. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R. Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3462–3471. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Palatnik de Sousa, I.; Maria Bernardes Rebuzzi Vellasco, M.; Costa da Silva, E. Local Interpretable Model-Agnostic Explanations for Classification of Lymph Node Metastases. Sensors 2019, 19, 2969. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petsiuk, V.; Das, A.; Saenko, K. Rise: Randomized input sampling for explanation of black-box models. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. arXiv 2017, arXiv:1703.01365. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | F1Score | AUC | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Train | Val | Test | Train | Val | Test | Train | Val | Test |
| 0.871 | 0.831 | 0.764 | 0.871 | 0.831 | 0.764 | 0.948 | 0.906 | 0.867 | |
| 0.995 | 0.856 | 0.788 | 0.995 | 0.856 | 0.788 | 1.000 | 0.884 | 0.828 | |
| 0.988 | 0.898 | 0.803 | 0.988 | 0.898 | 0.803 | 1.000 | 0.963 | 0.880 | |
| 1.000 | 0.907 | 0.803 | 1.000 | 0.907 | 0.803 | 1.000 | 0.917 | 0.830 | |
| 1.000 | 0.966 | 0.833 | 1.000 | 0.966 | 0.833 | 1.000 | 0.963 | 0.894 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palatnik de Sousa, I.; Vellasco, M.M.B.R.; Costa da Silva, E. Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers. Sensors 2021, 21, 5657. https://doi.org/10.3390/s21165657
Palatnik de Sousa I, Vellasco MMBR, Costa da Silva E. Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers. Sensors. 2021; 21(16):5657. https://doi.org/10.3390/s21165657
Chicago/Turabian StylePalatnik de Sousa, Iam, Marley M. B. R. Vellasco, and Eduardo Costa da Silva. 2021. "Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers" Sensors 21, no. 16: 5657. https://doi.org/10.3390/s21165657
APA StylePalatnik de Sousa, I., Vellasco, M. M. B. R., & Costa da Silva, E. (2021). Explainable Artificial Intelligence for Bias Detection in COVID CT-Scan Classifiers. Sensors, 21(16), 5657. https://doi.org/10.3390/s21165657