
An On-Demand Charging for Connected Target Coverage in WRSNs Using Fuzzy Logic and Q-Learning †



Abstract
:1. Introduction
- We propose a Fuzzy logic-based algorithm that determines the energy level to be charged to the sensors. The energy level is adjusted dynamically following the network condition.
- Based on the above algorithm, we introduce a new method that optimizes the optimal charging time at each charging location. It considers several parameters (i.e., remaining energy, energy consumption rate, sensor-to-charging location’s distance) to maximize the number of alive sensors.
- We propose Fuzzy Q-charging, which uses Q-learning in its charging scheme to guarantee the target coverage and connectivity. Fuzzy Q-charging’s reward function is designed to maximize the charged amount to essential sensors and the number of monitored targets.
2. Related Work
3. Network Model, Q-Learning, and Fuzzy Logic
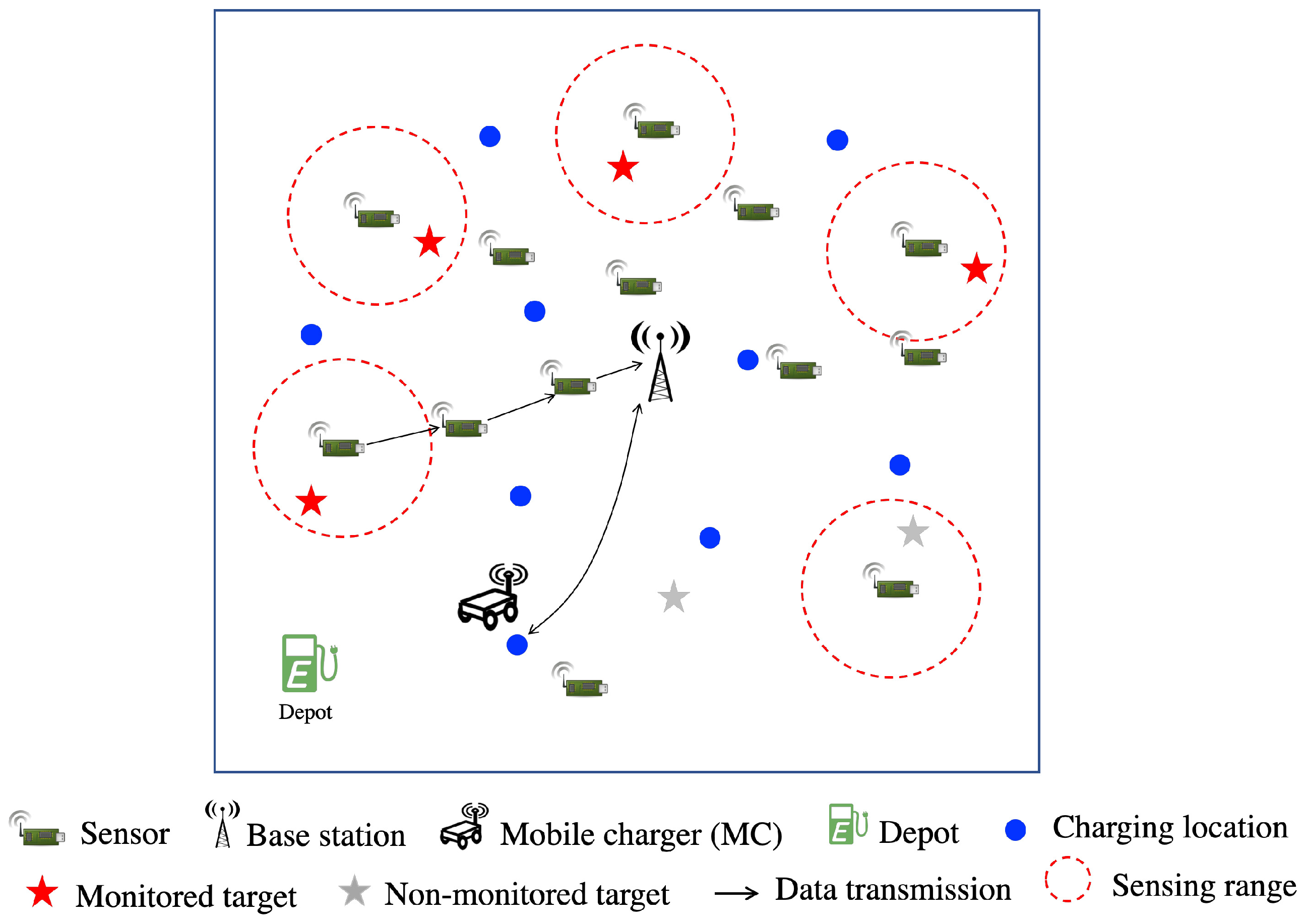
3.1. Network Model and Problem Definition
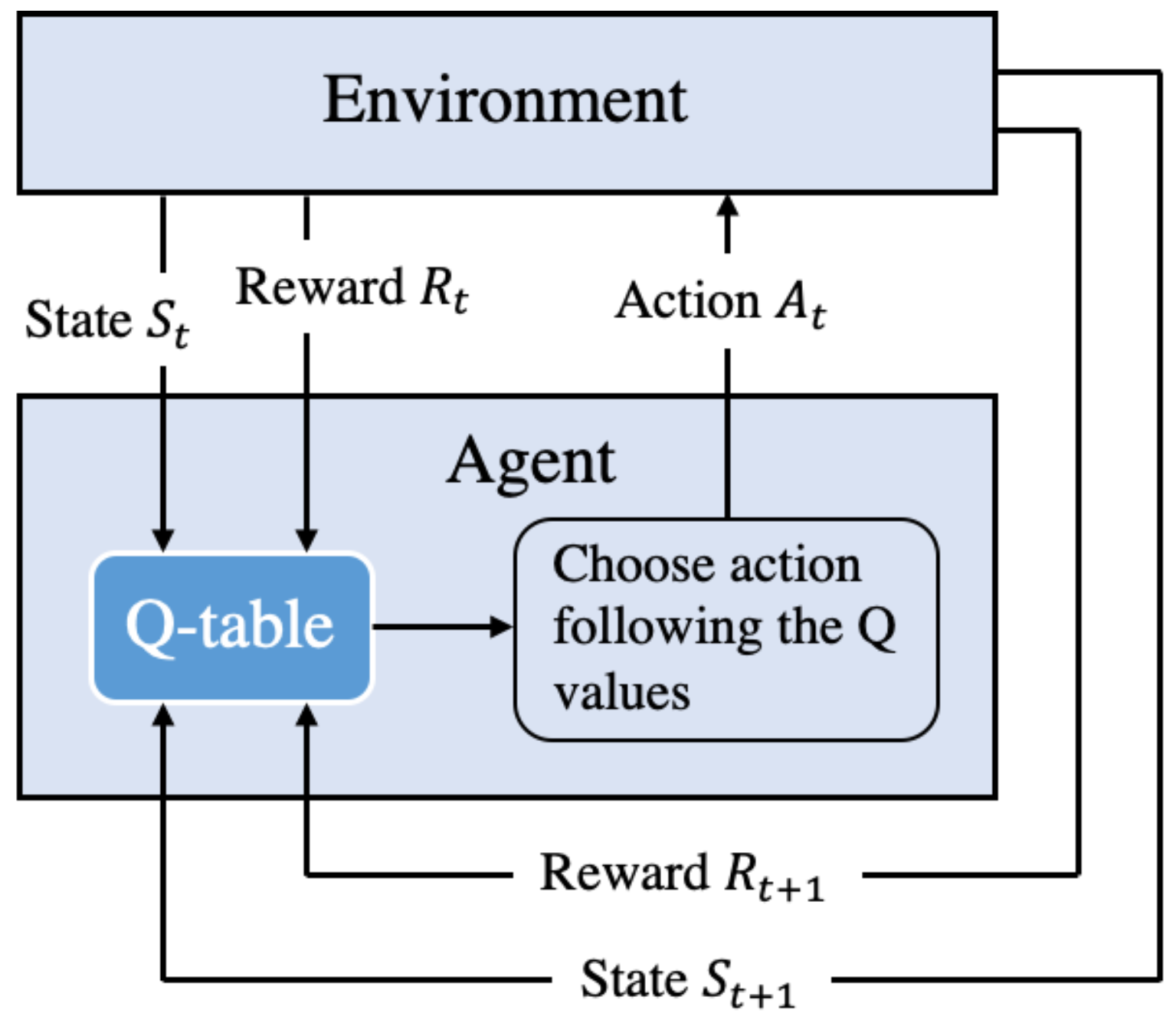
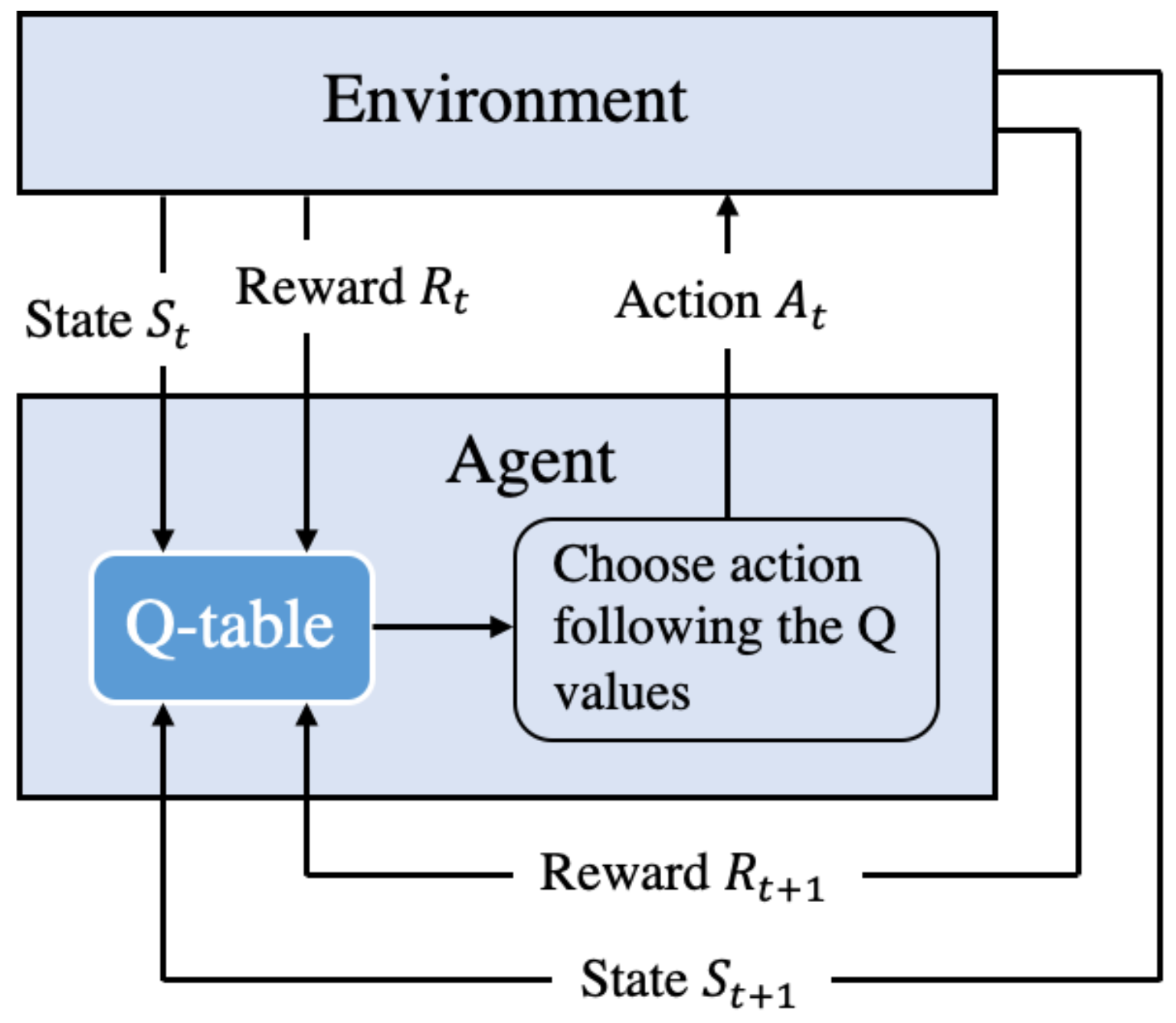
3.2. Q-Learning
3.3. Fuzzy Logic
4. Fuzzy Q-Charging Algorithm
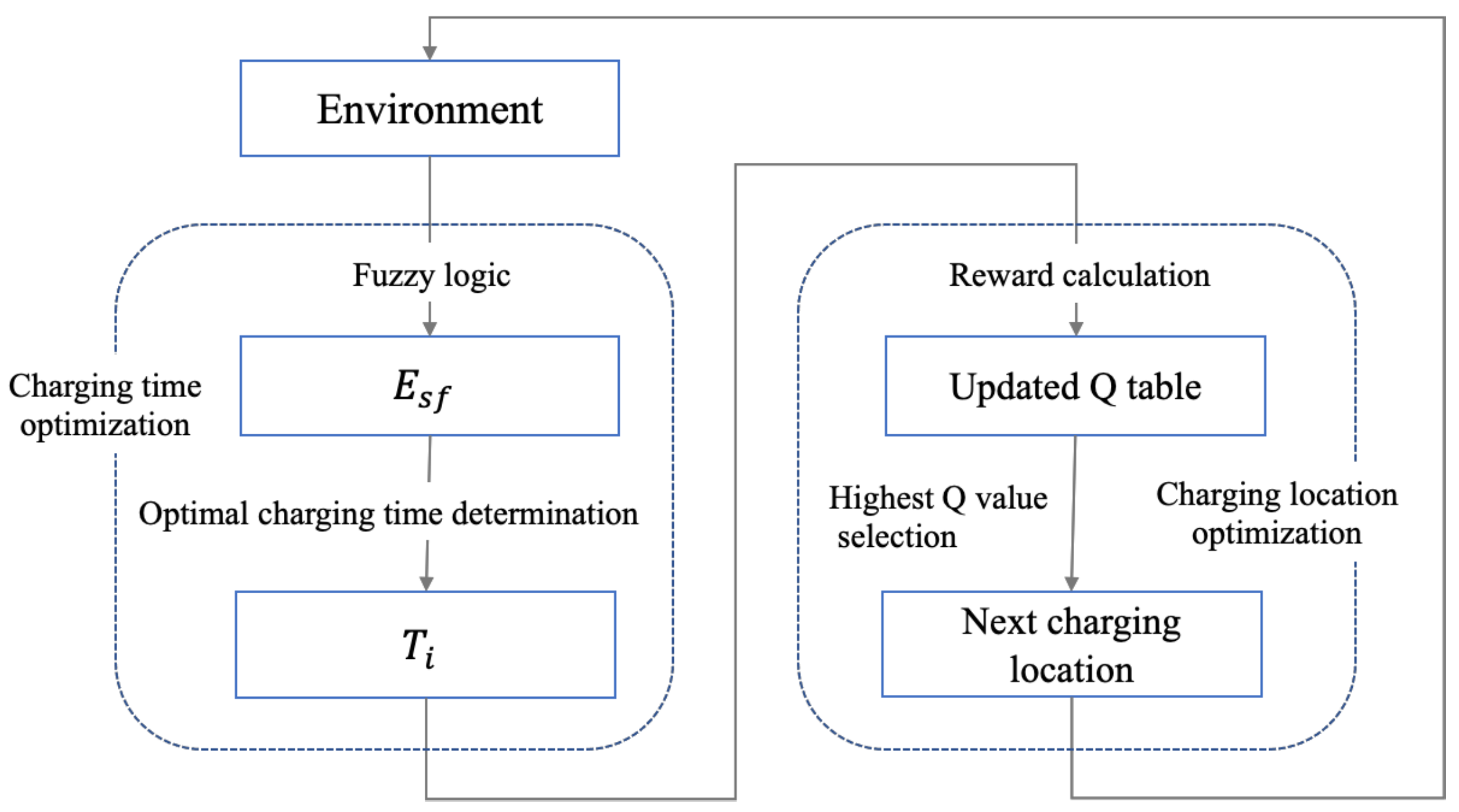
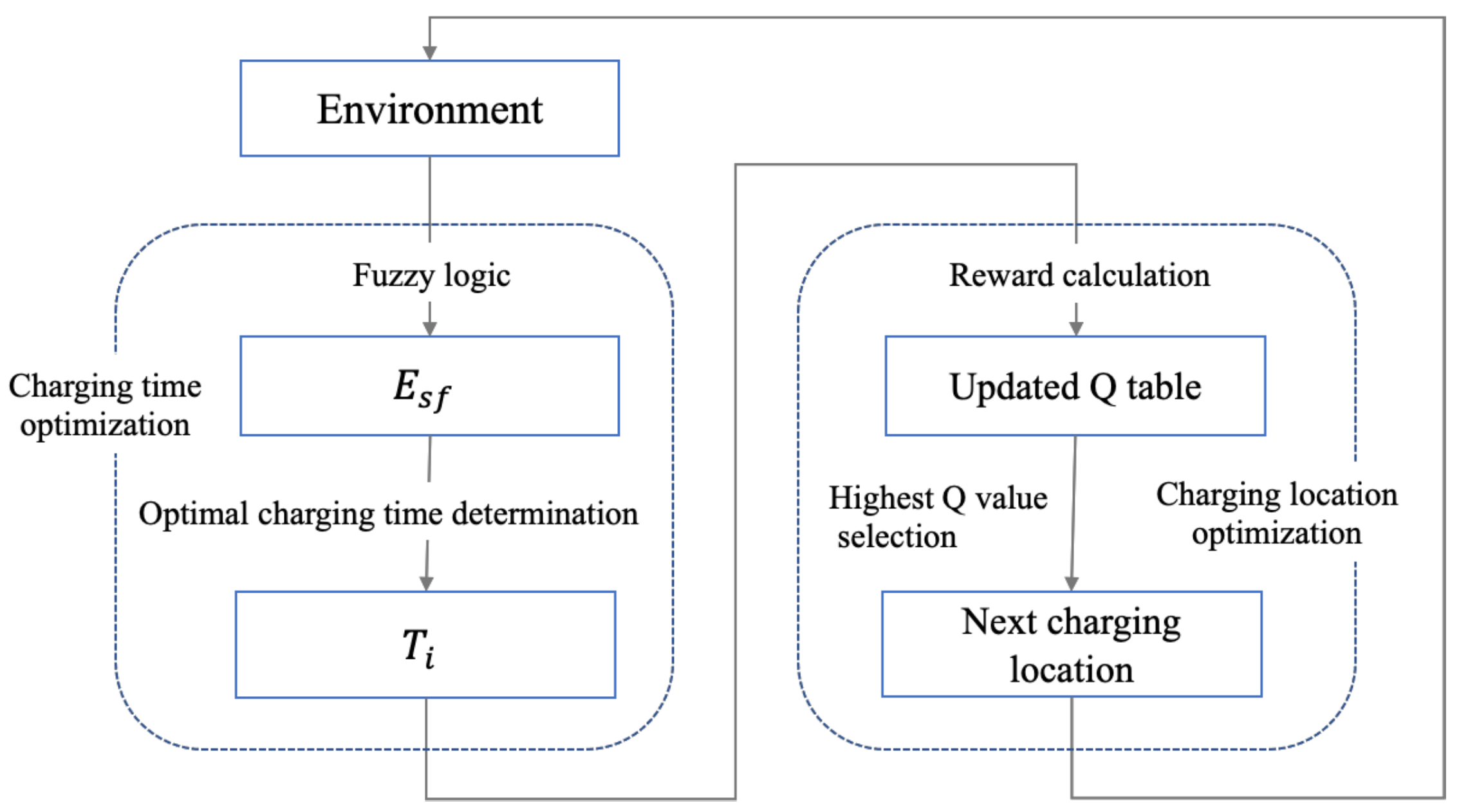
4.1. Overview
- The MC leverages Fuzzy logic to calculate a so-called safe energy level (denoted as ), which is sufficiently higher than . The MC then uses the algorithm described in Section 4.3 to determine the charging time at each charging location. The charging time is optimized to maximize the number of sensors that guarantee the safe energy level.
- The MC calculates the reward of every charging location using Equation (12) and updates the Q-table using Equation (4).
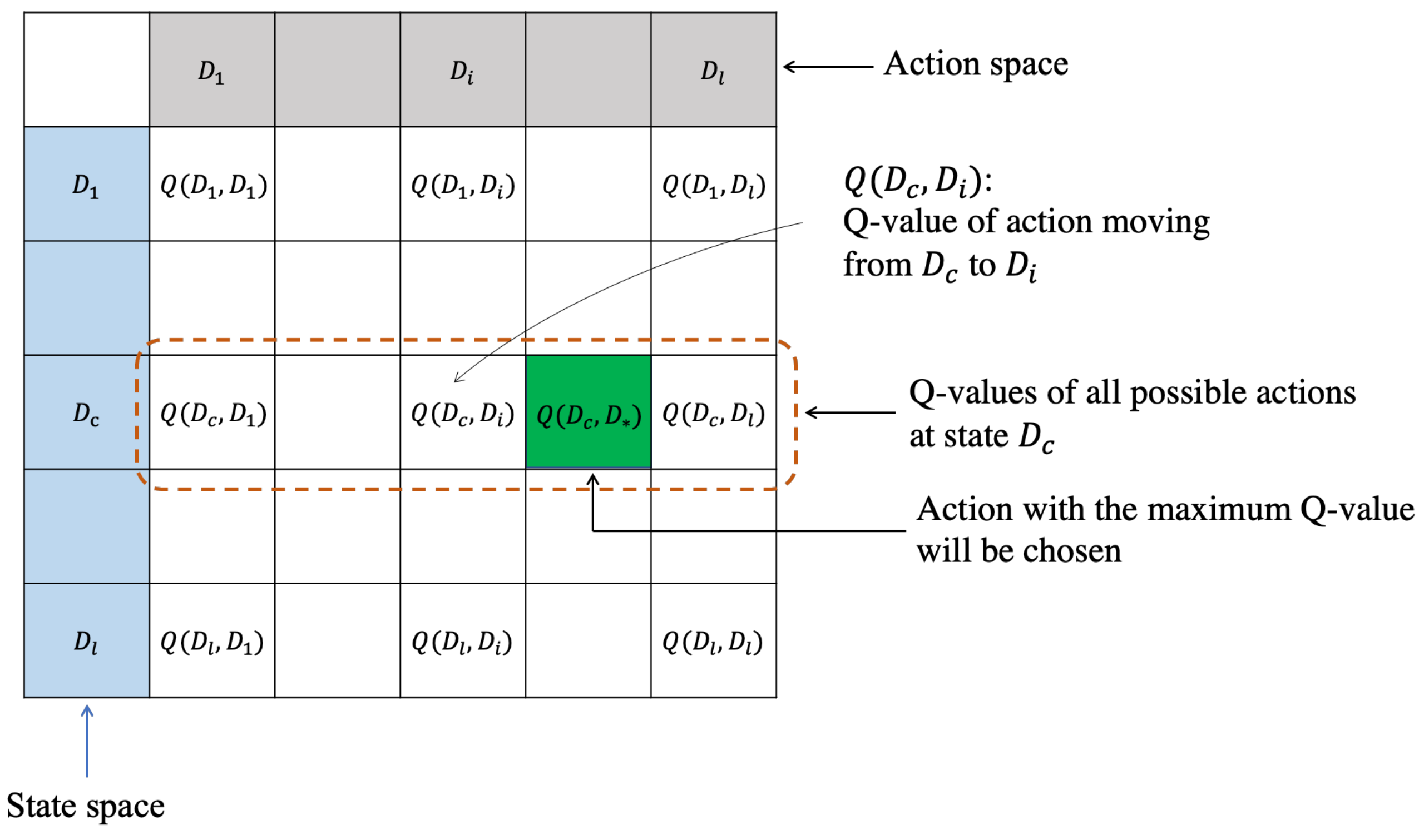
4.2. State Space, Action Space and Q Table
4.3. Charging Time Determination
- First, we calculate the safety energy charging time of all negative normal sensors (denoted as ) and positive critical sensors (denoted as ).
- We then combine the values of and into an array denoted as , where have been sorted by decreasing order (i.e., ). We have an important observation that the value of () does not change when varies in the range from to (). Therefore, the optimal value of can be easily determined by brute force search over .
4.4. Fuzzy Logic-Based Safe Energy Level Determination
4.4.1. Motivation
- The residual energy of all sensors is small.
- Many sensors need to be charged.
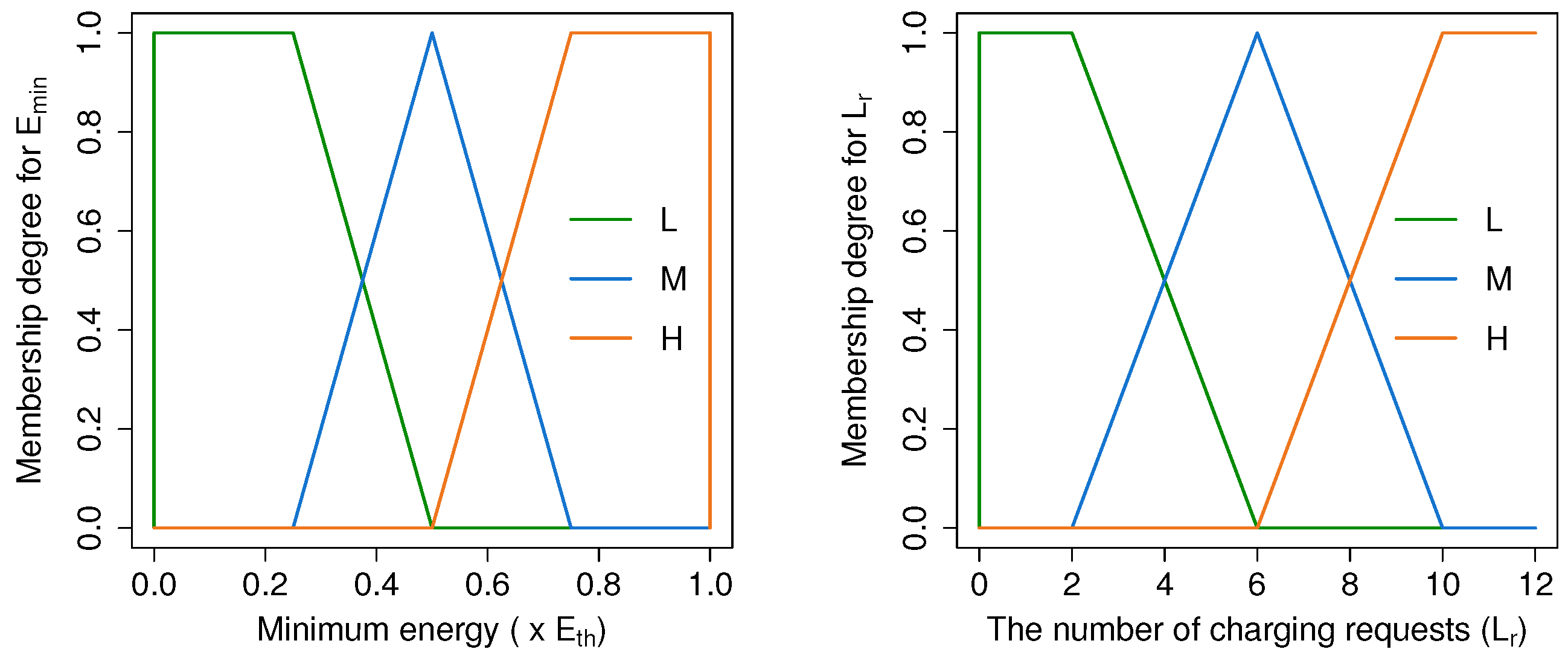
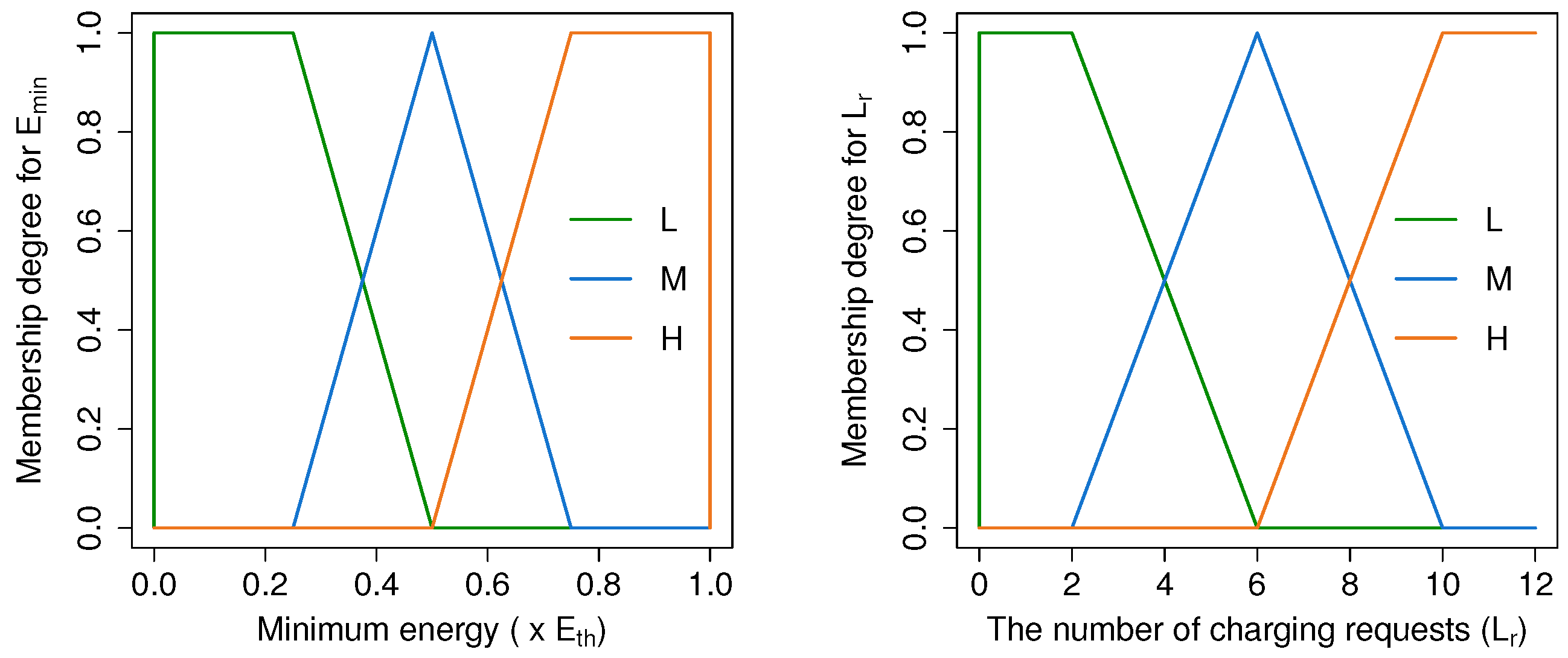
4.4.2. Fuzzification
4.4.3. Fuzzy Controller
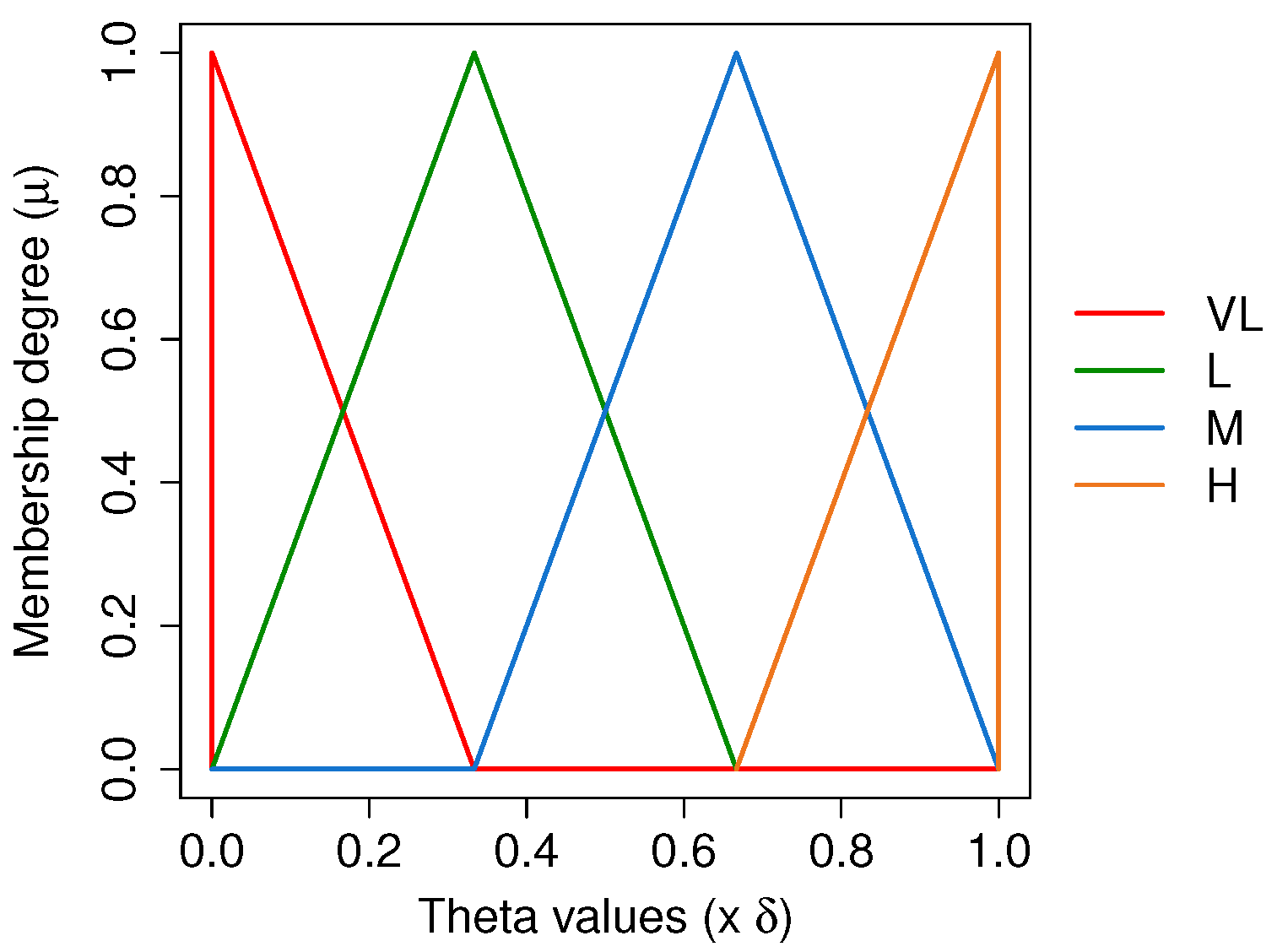
4.4.4. Defuzzification
| Algorithm 1: Fuzzy Logic-based determination |
 |
4.5. Reward Function
- The sensors with either high energy consumption rate or low level of remaining energy;
- The sensors either cover many targets or participate in many routing paths from target-covering sensors to the base station.
4.6. Q Table Update
5. Performance Evaluation
5.1. Impacts of Parameters
5.1.1. Impacts of
5.1.2. Impacts of
5.2. Comparison with Existing Algorithms
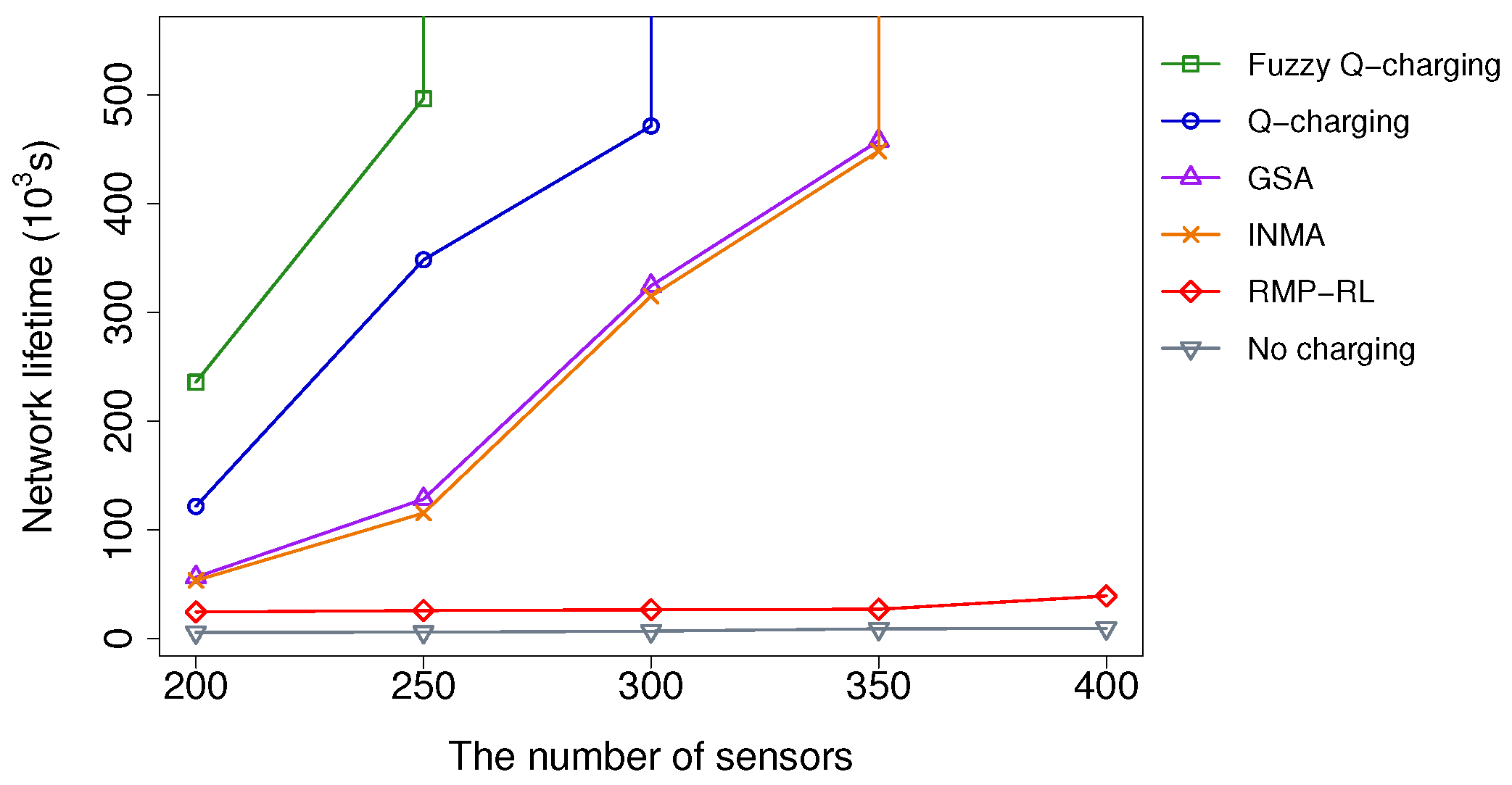
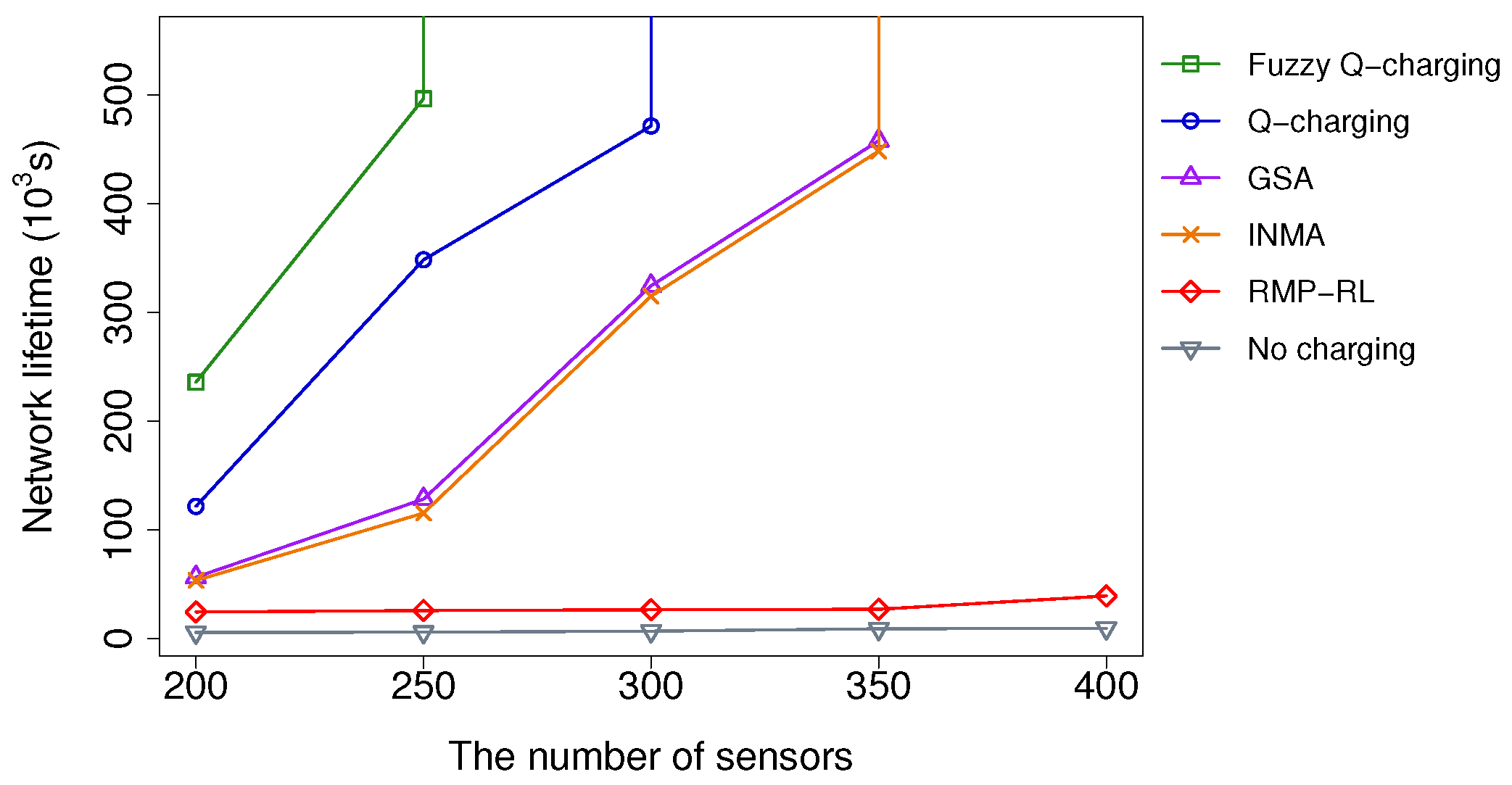
5.2.1. Impacts of the Number of Sensors
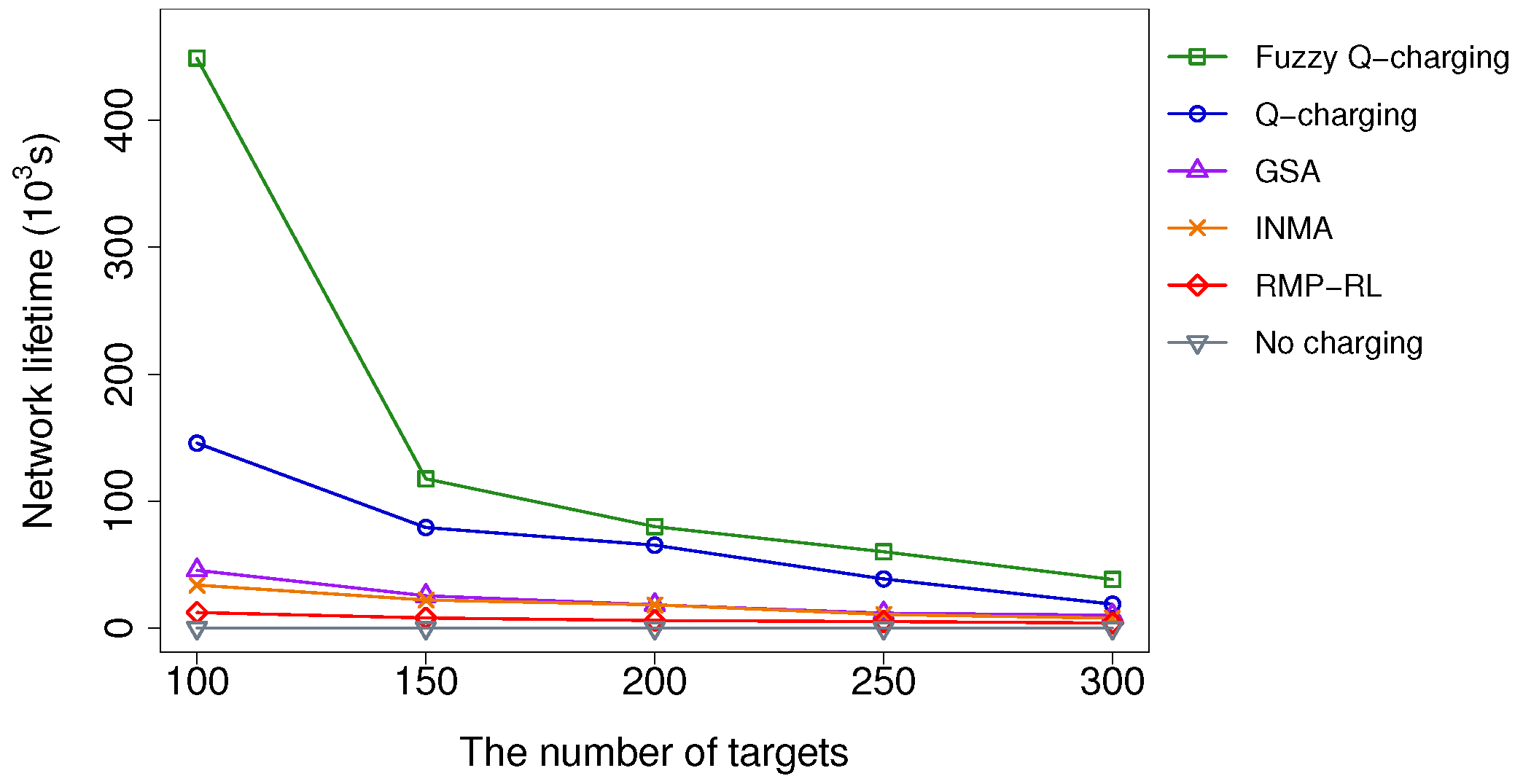
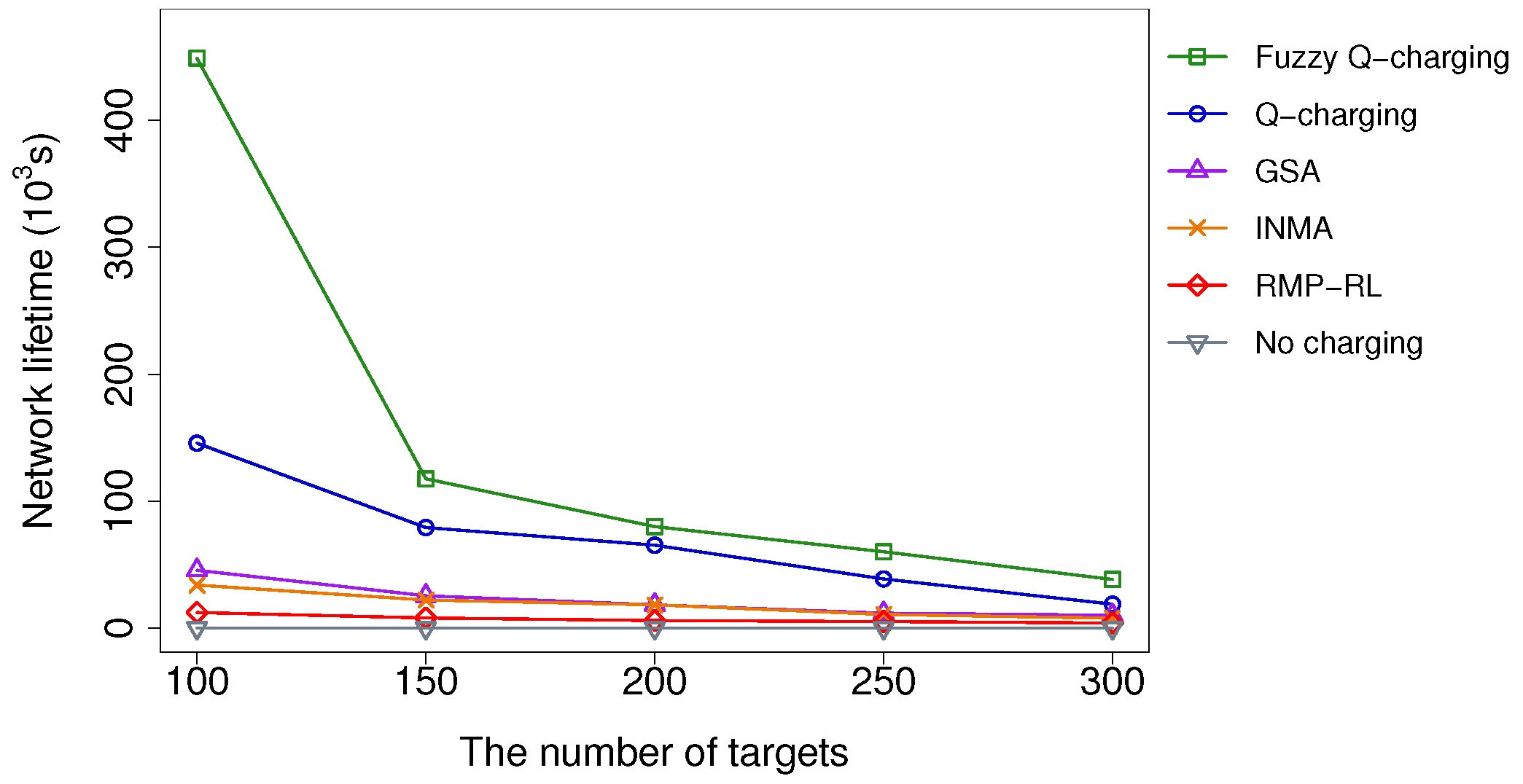
5.2.2. Impacts of the Number of Targets
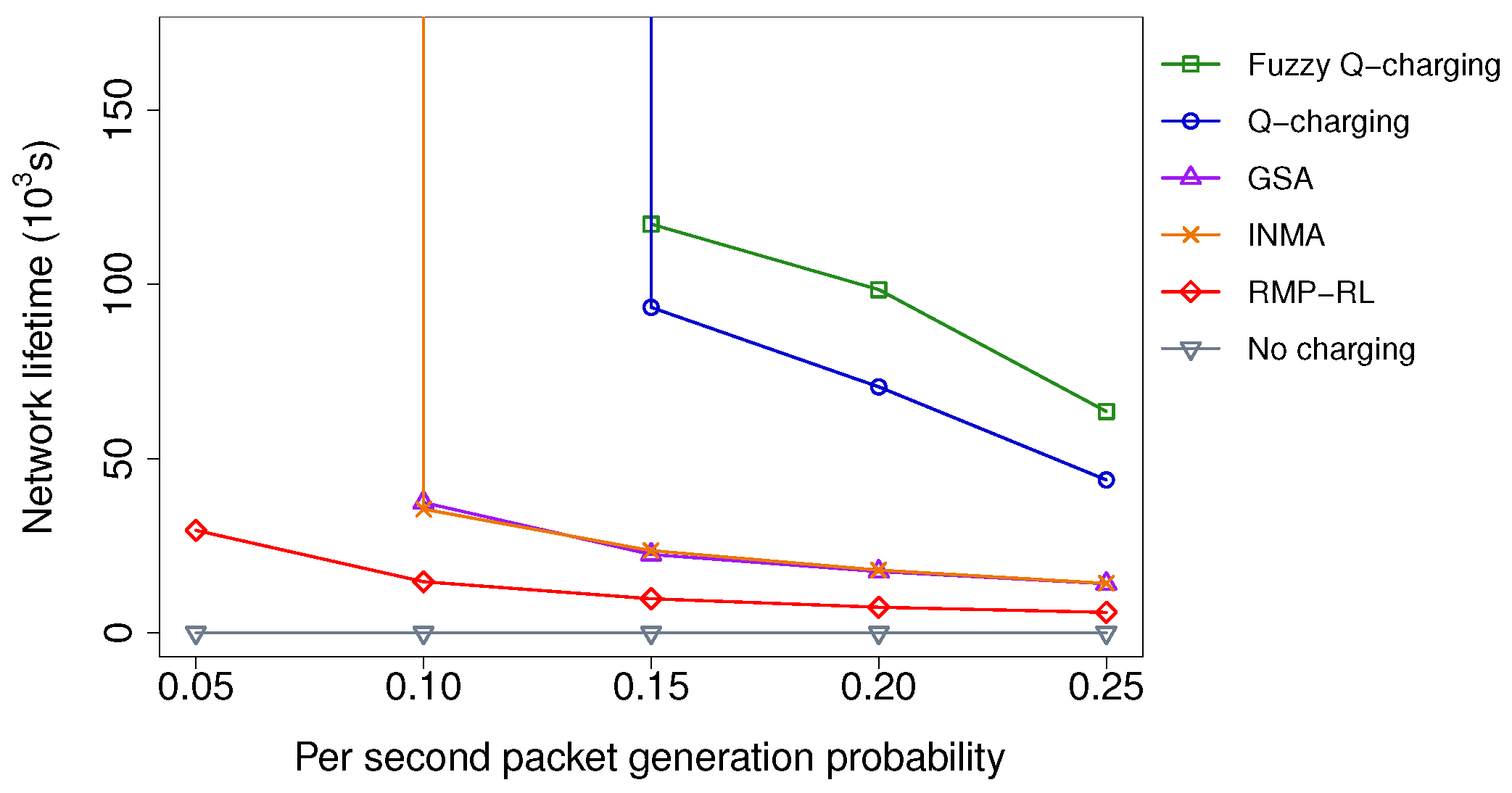
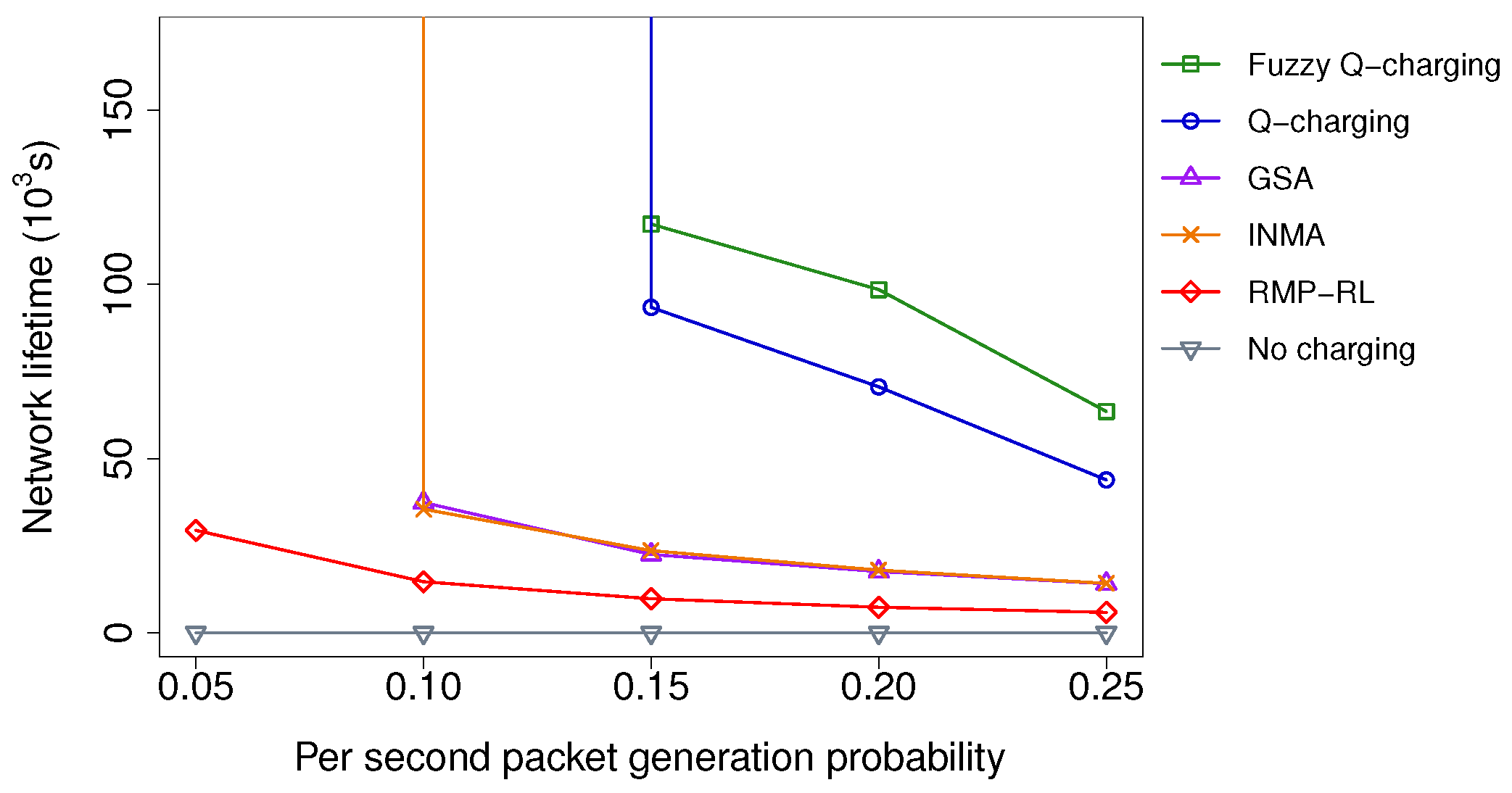
5.2.3. Impacts of the Packet Generation Frequency
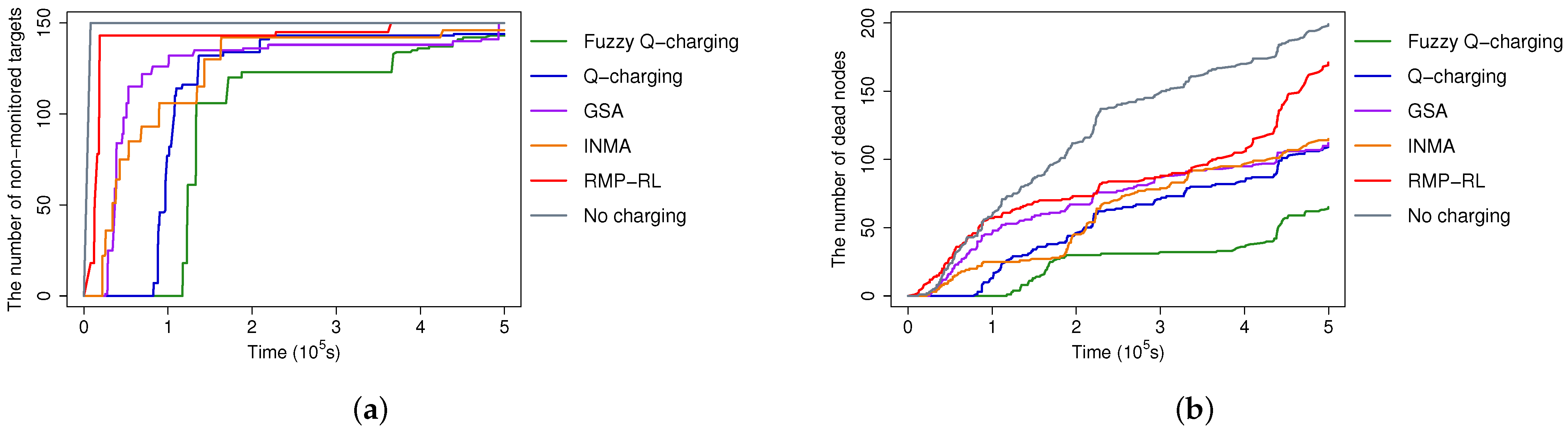
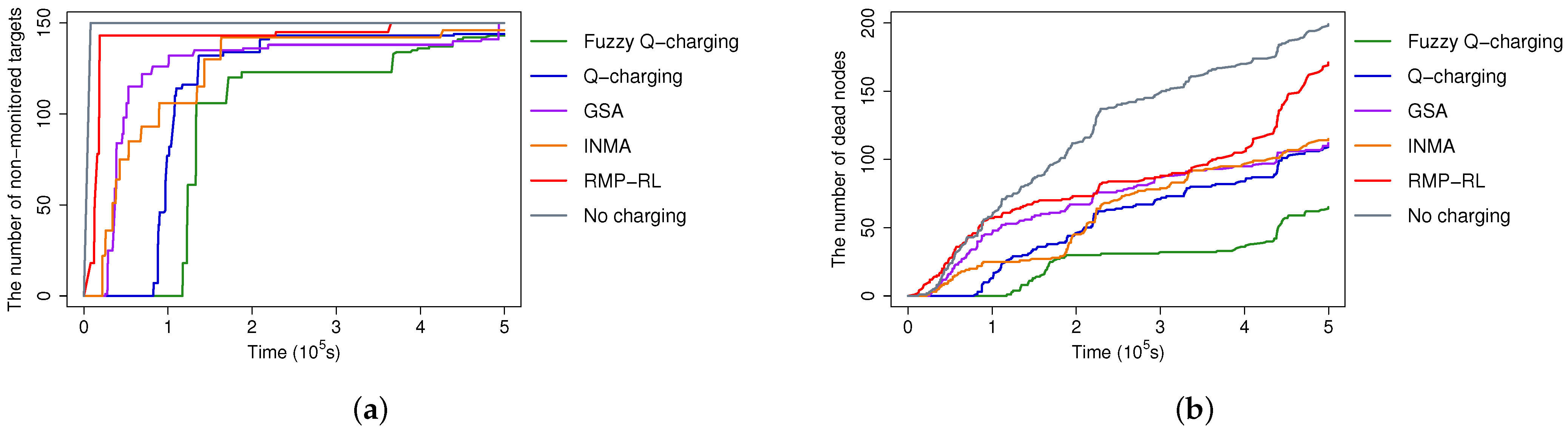
5.2.4. Non-Monitored Targets and Dead Sensors over Time
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, G.; Yang, X.; Liu, L.; Guizani, M.; Zhang, W. A Disaster Management-Oriented Path Planning for Mobile Anchor Node-Based Localization in Wireless Sensor Networks. IEEE Trans. Emerg. Top. Comput. 2017, 8, 115–125. [Google Scholar] [CrossRef]
- Ojha, T.; Misra, S.; Raghuwanshi, N.S. Wireless sensor networks for agriculture: The state-of-the-art in practice and future challenges. Comput. Electron. Agric. 2015, 118, 66–84. [Google Scholar] [CrossRef]
- Le Nguyen, P.; Nguyen, K.; Vu, H.; Ji, Y. TELPAC: A time and energy efficient protocol for locating and patching coverage holes in WSNs. J. Netw. Comput. Appl. 2019, 147, 102439. [Google Scholar] [CrossRef]
- Le Nguyen, P.; Ji, Y.; Le, K.; Nguyen, T. Load balanced and constant stretch routing in the vicinity of holes in WSNs. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–6. [Google Scholar]
- Hanh, N.T.; Le Nguyen, P.; Tuyen, P.T.; Binh, H.T.T.; Kurniawan, E.; Ji, Y. Node placement for target coverage and network connectivity in WSNs with multiple sinks. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–6. [Google Scholar]
- Lyu, Z.; Wei, Z.; Pan, J.; Chen, H.; Xia, C.; Han, J.; Shi, L. Periodic charging planning for a mobile WCE in wireless rechargeable sensor networks based on hybrid PSO and GA algorithm. Appl. Soft Comput. 2019, 75, 388–403. [Google Scholar] [CrossRef]
- Jiang, G.; Lam, S.; Sun, Y.; Tu, L.; Wu, J. Joint Charging Tour Planning and Depot Positioning for Wireless Sensor Networks Using Mobile Chargers. IEEE/ACM Trans. Netw. 2017, 25, 2250–2266. [Google Scholar] [CrossRef]
- Ma, Y.; Liang, W.; Xu, W. Charging Utility Maximization in Wireless Rechargeable Sensor Networks by Charging Multiple Sensors Simultaneously. IEEE/ACM Trans. Netw. 2018, 26, 1591–1604. [Google Scholar] [CrossRef]
- Xu, W.; Liang, W.; Kan, H.; Xu, Y.; Zhang, X. Minimizing the Longest Charge Delay of Multiple Mobile Chargers for Wireless Rechargeable Sensor Networks by Charging Multiple Sensors Simultaneously. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 881–890. [Google Scholar]
- Lin, C.; Zhou, Y.; Ma, F.; Deng, J.; Wang, L.; Wu, G. Minimizing Charging Delay for Directional Charging in Wireless Rechargeable Sensor Networks. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1819–1827. [Google Scholar]
- Feng, Y.; Liu, N.; Wang, F.; Qian, Q.; Li, X. Starvation avoidance mobile energy replenishment for wireless rechargeable sensor networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Lin, C.; Zhou, J.; Guo, C.; Song, H.; Wu, G.; Obaidat, M.S. TSCA: A Temporal-Spatial Real-Time Charging Scheduling Algorithm for On-Demand Architecture in Wireless Rechargeable Sensor Networks. IEEE Trans. Mobile Comput. 2018, 17, 211–224. [Google Scholar] [CrossRef]
- Lin, C.; Sun, Y.; Wang, K.; Chen, Z.; Xu, B.; Wu, G. Double warning thresholds for preemptive charging scheduling in Wireless Rechargeable Sensor Networks. Comput. Netw. 2019, 148, 72–87. [Google Scholar] [CrossRef]
- Tomar, A.; Muduli, L.; Jana, P.K. A Fuzzy Logic-based On-demand Charging Algorithm for Wireless Rechargeable Sensor Networks with Multiple Chargers. IEEE Trans. Mobile Comput. 2020, 1233, 2715–2727. [Google Scholar] [CrossRef]
- Cao, X.; Xu, W.; Liu, X.; Peng, J.; Liu, T. A Deep Reinforcement Learning-Based On-Demand Charging Algorithm for Wireless Rechargeable Sensor Networks. Ad Hoc Netw. 2020, 110, 102278. [Google Scholar] [CrossRef]
- Zhu, J.; Feng, Y.; Liu, M.; Chen, G.; Huang, Y. Adaptive online mobile charging for node failure avoidance in wireless rechargeable sensor networks. Comput. Netw. 2018, 126, 28–37. [Google Scholar] [CrossRef]
- Kaswan, A.; Tomar, A.; Jana, P.K. An efficient scheduling scheme for mobile charger in on-demand wireless rechargeable sensor networks. J. Netw. Comput. Appl. 2018, 114, 123–134. [Google Scholar] [CrossRef]
- Xu, W.; Liang, W.; Jia, X.; Xu, Z. Maximizing Sensor Lifetime in a Rechargeable Sensor Network via Partial Energy Charging on Sensors. In Proceedings of the 2016 13th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), London, UK, 27–30 June 2016; pp. 1–9. [Google Scholar]
- Krishnamurthi, R.; Goyal, M. Hybrid Neuro-fuzzy Method for Data Analysis of Brain Activity Using EEG Signals. Soft Comput. Signal Process. 2019, 900, 165–173. [Google Scholar]
- Behera, S.K.; Jena, L.; Rath, A.K.; Sethy, P.K. Disease Classification and Grading of Orange Using Machine Learning and Fuzzy Logic. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 678–682. [Google Scholar]
- Yang, C.; Jiang, Y.; Na, J.; Li, Z.; Cheng, L.; Su, C. Finite-Time Convergence Adaptive Fuzzy Control for Dual-Arm Robot with Unknown Kinematics and Dynamics. IEEE Trans. Fuzzy Syst. 2019, 27, 574–588. [Google Scholar] [CrossRef]
- Castillo, O.; Amador-Angulo, L. A generalized type-2 fuzzy logic approach for dynamic parameter adaptation in bee colony optimization applied to fuzzy controller design. Inf. Sci. 2018, 460–461, 476–496. [Google Scholar] [CrossRef]
- Yang, C.S.; Kim, C.K.; Moon, J.; Park, S.; Kang, C.G. Channel Access Scheme With Alignment Reference Interval Adaptation (ARIA) for Frequency Reuse in Unlicensed Band LTE: Fuzzy Q-Learning Approach. IEEE Access 2018, 6, 26438–26451. [Google Scholar] [CrossRef]
- Jain, A.; Goel, A. Energy Efficient Fuzzy Routing Protocol for Wireless Sensor Networks. Wirel. Pers. Commun. 2020, 110, 1459–1474. [Google Scholar] [CrossRef]
- Krishnaswamy, V.; Manvi, S. Fuzzy and PSO Based Clustering Scheme in Underwater Acoustic Sensor Networks Using Energy and Distance Parameters. Wirel. Pers. Commun. 2019, 108, 1529–1546. [Google Scholar] [CrossRef]
- Ghosh, N.; Banerjee, I.; Sherratt, R. On-demand fuzzy clustering and ant-colony optimisation based mobile data collection in wireless sensor network. Wirel. Netw. 2019, 25, 1829–1845. [Google Scholar] [CrossRef] [Green Version]
- Wan, R.; Xiong, N.; Hu, Q.; Wang, H.; Shang, J. Similarity-aware data aggregation using fuzzy c-means approach for wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 59. [Google Scholar] [CrossRef] [Green Version]
- Kofinas, P.; Dounis, A.; Vouros, G. Fuzzy Q-Learning for multi-agent decentralized energy management in microgrids. Appl. Energy 2018, 219, 53–67. [Google Scholar] [CrossRef]
- Avin, N.; Sharma, R. A fuzzy reinforcement learning approach to thermal unit commitment problem. Neural Comput. Appl. 2019, 31, 737–750. [Google Scholar]
- Van Quan, L.; Nguyen, P.L.; Nguyen, T.H.; Nguyen, K. Q-learning-based, Optimized On-demand Charging Algorithm in WRSN. In Proceedings of the 2020 IEEE 19th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 24–27 November 2020; pp. 1–8. [Google Scholar]
- He, S.; Chen, J.; Jiang, F.; Yau, D.K.Y.; Xing, G.; Sun, Y. Energy Provisioning in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2013, 12, 1931–1942. [Google Scholar] [CrossRef]
- Karp, B.; Kung, H.T. GPSR: Greedy Perimeter Stateless Routing for Wireless Networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 243–254. [Google Scholar]
- Bulusu, N.; Heidemann, J.; Estrin, D. GPS-less low-cost outdoor localization for very small devices. IEEE Pers. Commun. 2000, 7, 28–34. [Google Scholar] [CrossRef] [Green Version]
- Fang, Q.; Gao, J.; Guibas, L.J. Locating and bypassing routing holes in sensor networks. In Proceedings of the IEEE INFOCOM, Hong Kong, China, 7–11 March 2004; pp. 2458–2468. [Google Scholar]
- Yu, F.; Park, S.; Tian, Y.; Jin, M.; Kim, S. Efficient Hole Detour Scheme for Geographic Routing in Wireless Sensor Networks. In Proceedings of the VTC Spring 2008-IEEE Vehicular Technology Conference, Marina Bay, Singapore, 11–14 May 2008; pp. 153–157. [Google Scholar]
- Kim, S.; Kim, C.; Cho, H.; Yim, Y.; Kim, S. Void Avoidance Scheme for Real-Time Data Dissemination in Irregular Wireless Sensor Networks. In Proceedings of the 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland, 23–25 March 2016; pp. 438–443. [Google Scholar]
- Tian, Y.; Yu, F.; Choi, Y.; Park, S.; Lee, E.; Jin, M.; Kim, S.-H. Energy-Efficient Data Dissemination Protocol for Detouring Routing Holes in Wireless Sensor Networks. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 2322–2326. [Google Scholar]
- Li, F.; Zhang, B.; Zheng, J. Geographic hole-bypassing forwarding protocol for wireless sensor networks. IET Commun. 2011, 5, 737–744. [Google Scholar] [CrossRef]
- Won, M.; Stoleru, R. A Low-Stretch-Guaranteed and Lightweight Geographic Routing Protocol for Large-Scale Wireless Sensor Networks. ACM Trans. Sens. Netw. (TOSN) 2014, 11, 18:1–18:22. [Google Scholar] [CrossRef]
- Nguyen, P.L.; Ji, Y.; Liu, Z.; Nguyen, K.V. Distributed Hole-Bypassing Protocol in WSNs with Constant Stretch and Load Balancing. Comput. Netw. 2017, 129, 232–250. [Google Scholar] [CrossRef]
- Nguyen, P.; Ji, Y.; Trung, N.T.; Hung, N.T. Constant stretch and load balanced routing protocol for bypassing multiple holes in wireless sensor networks. In Proceedings of the 2017 IEEE 16th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–1 November 2017; pp. 1–9. [Google Scholar]
- Huang, H.; Yin, H.; Min, G.; Zhang, J.; Wu, Y.; Zhang, X. Energy-Aware Dual-Path Geographic Routing to Bypass Routing Holes in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2018, 17, 1339–1352. [Google Scholar] [CrossRef] [Green Version]
- Fu, L.; Cheng, P.; Gu, Y.; Chen, J.; He, T. Optimal Charging in Wireless Rechargeable Sensor Networks. IEEE Trans. Veh. Technol. 2016, 65, 278–291. [Google Scholar] [CrossRef]
- Mohammed, S.L. Distance Estimation Based on RSSI and Log-Normal Shadowing Models for ZigBee Wireless Sensor Network. Eng. Technol. J. 2016, 34, 2950–2959. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| The i-th charging location | |
| Action value of the action moving from to | |
| Reward obtained after the MC moves to | |
| The learning rate of the Q-learning algorithm | |
| The discount factor of the Q-learning algorithm | |
| The threshold for sending a charging request | |
| The safe charging level | |
| The safe energy factor | |
| The maximum energy capacity of the sensors | |
| The per second energy that a sensor is charged when the MC stays at | |
| Energy consumption rate of sensor | |
| Remaining energy of sensor | |
| The optimal charging time at | |
| Fuzzy input variables | |
| The priority index of | |
| The energy severity index of , . |
| Input Variable | Linguistic Value | Membership Function |
|---|---|---|
| L | ||
| M | ||
| H | ||
| L | ||
| M | ||
| H |
| Output Variable | Linguistic Value | Membership Function |
|---|---|---|
| VL | ||
| L | ||
| M | ||
| H |
| Input | Output | ||
|---|---|---|---|
| 1 | L | L | H |
| 2 | L | M | M |
| 3 | L | H | L |
| 4 | M | L | M |
| 5 | M | M | L |
| 6 | M | H | VL |
| 7 | H | L | L |
| 8 | H | M | VL |
| 9 | H | H | VL |
| Input Variable | Membership Function | Value |
|---|---|---|
| 0.75 | ||
| 0.25 | ||
| 0.00 | ||
| 0.00 | ||
| 0.00 | ||
| 1.00 |
| 1 | 0.00 | 4 | 0.00 | 7 | 0.00 |
| 2 | 0.00 | 5 | 0.00 | 8 | 0.00 |
| 3 | 0.75 | 6 | 0.25 | 9 | 0.00 |
| Factor | Value |
|---|---|
| Initial energy of the MC | 100 J |
| Battery capacity of MC | 500 J |
| The velocity of the MC | 5 m/s |
| Initial energy of sensors | 10 J |
| Battery capacity of sensors | 10 J |
| 4 J | |
| Sensing range | m |
| Transmission range | 15 m |
| Number of sensors | 200~400 |
| Number of targets | 100~300 |
| Per second packet generation probability | 0.05~0.25 |
| 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | |
|---|---|---|---|---|---|---|
| Network lifetime ( s) | 235.042 | 246.601 | 246.268 | 243.493 | 243.719 | 244.183 |
| 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | |
|---|---|---|---|---|---|
| Network lifetime ( s) | ∞ | ∞ | 302.876 | 302.876 | 126.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, P.L.; La, V.Q.; Nguyen, A.D.; Nguyen, T.H.; Nguyen, K. An On-Demand Charging for Connected Target Coverage in WRSNs Using Fuzzy Logic and Q-Learning. Sensors 2021, 21, 5520. https://doi.org/10.3390/s21165520
Nguyen PL, La VQ, Nguyen AD, Nguyen TH, Nguyen K. An On-Demand Charging for Connected Target Coverage in WRSNs Using Fuzzy Logic and Q-Learning. Sensors. 2021; 21(16):5520. https://doi.org/10.3390/s21165520
Chicago/Turabian StyleNguyen, Phi Le, Van Quan La, Anh Duy Nguyen, Thanh Hung Nguyen, and Kien Nguyen. 2021. "An On-Demand Charging for Connected Target Coverage in WRSNs Using Fuzzy Logic and Q-Learning" Sensors 21, no. 16: 5520. https://doi.org/10.3390/s21165520
APA StyleNguyen, P. L., La, V. Q., Nguyen, A. D., Nguyen, T. H., & Nguyen, K. (2021). An On-Demand Charging for Connected Target Coverage in WRSNs Using Fuzzy Logic and Q-Learning. Sensors, 21(16), 5520. https://doi.org/10.3390/s21165520