
Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals



Abstract
:1. Introduction
1.1. Approaches in EEG Signal Analysis
1.2. Objectives and Research Contribution
2. Background and Related Work
2.1. Feature Extraction and Machine Learning
2.2. Deep Learning-Based Approaches
3. Materials and Methods
3.1. Experimental Setup
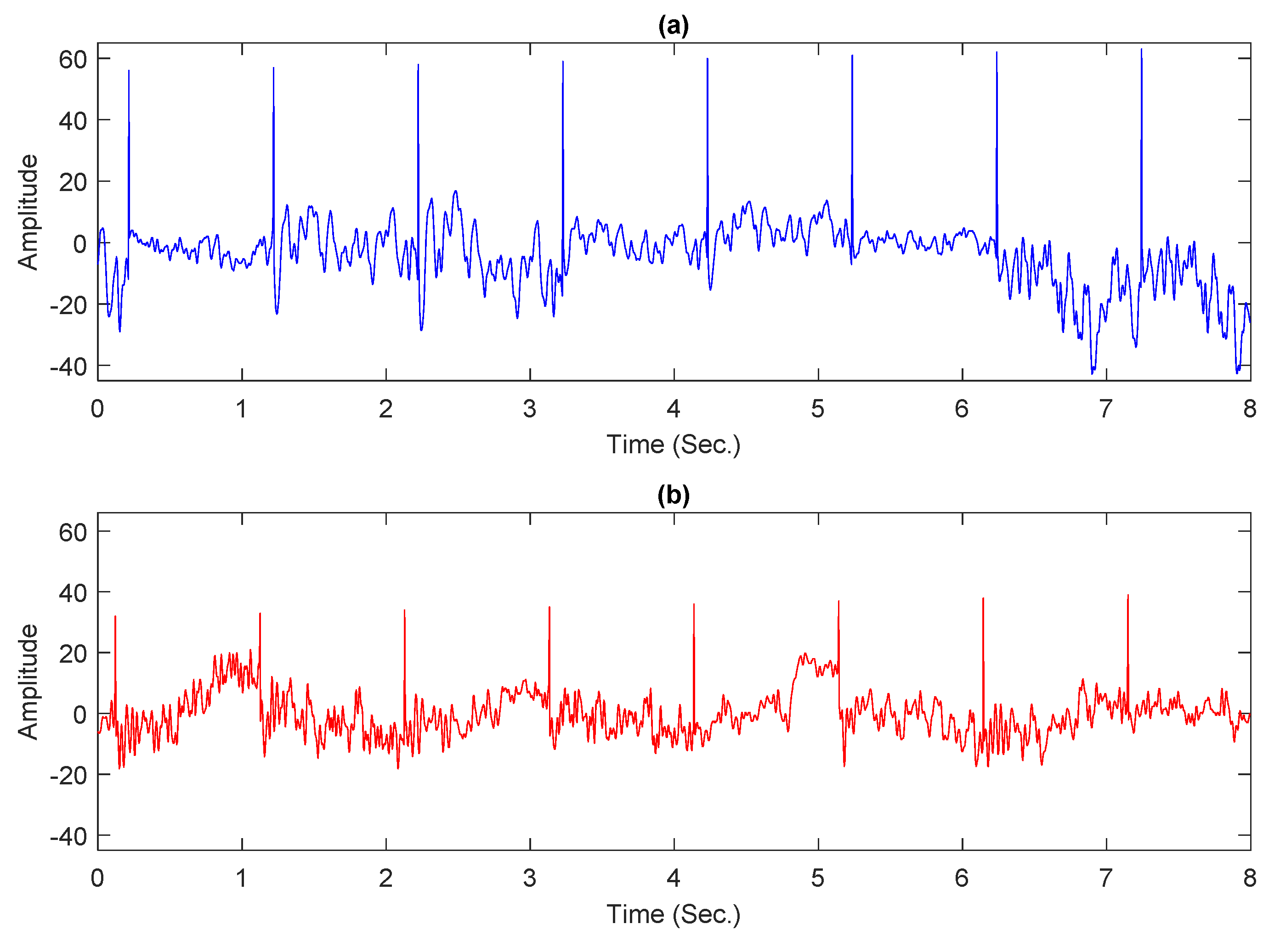
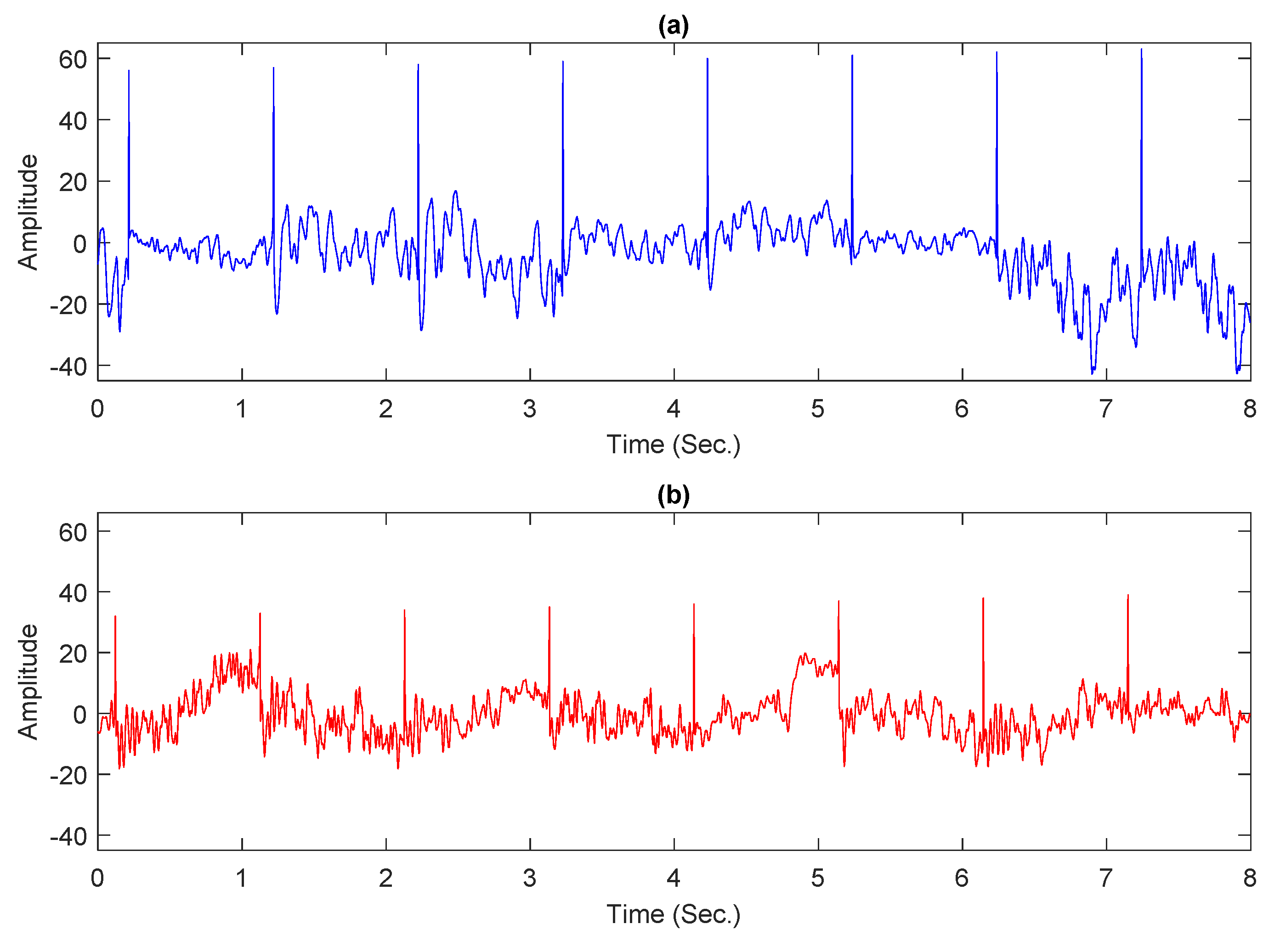
3.2. EEG Dataset
3.3. Data Segmentation
3.4. Data Normalization
3.5. CNN for Feature Selection
3.5.1. Fully Connected Layer for Classification
3.5.2. Hyperparameter Tuning
3.5.3. Performance Metrics and Evaluation
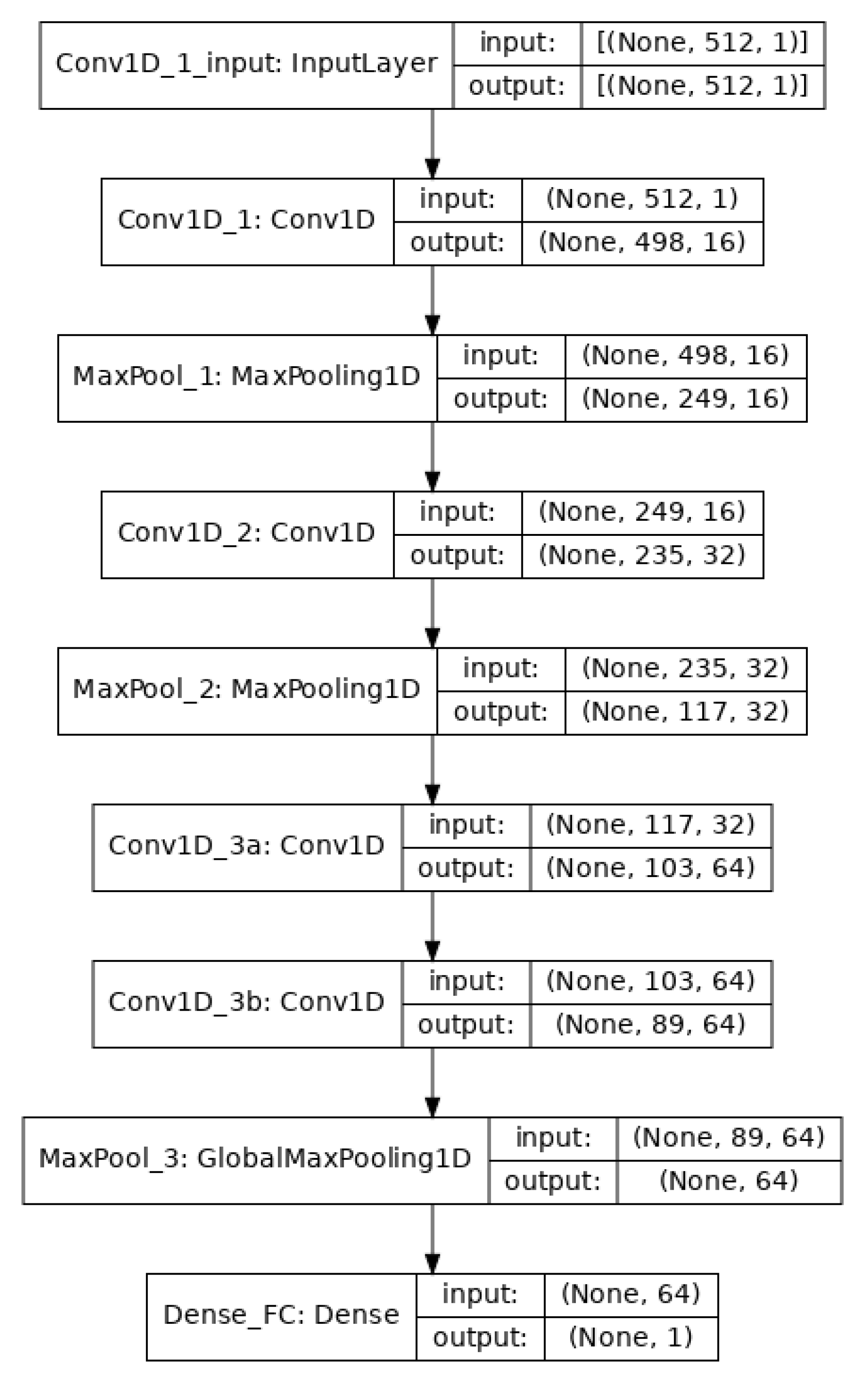
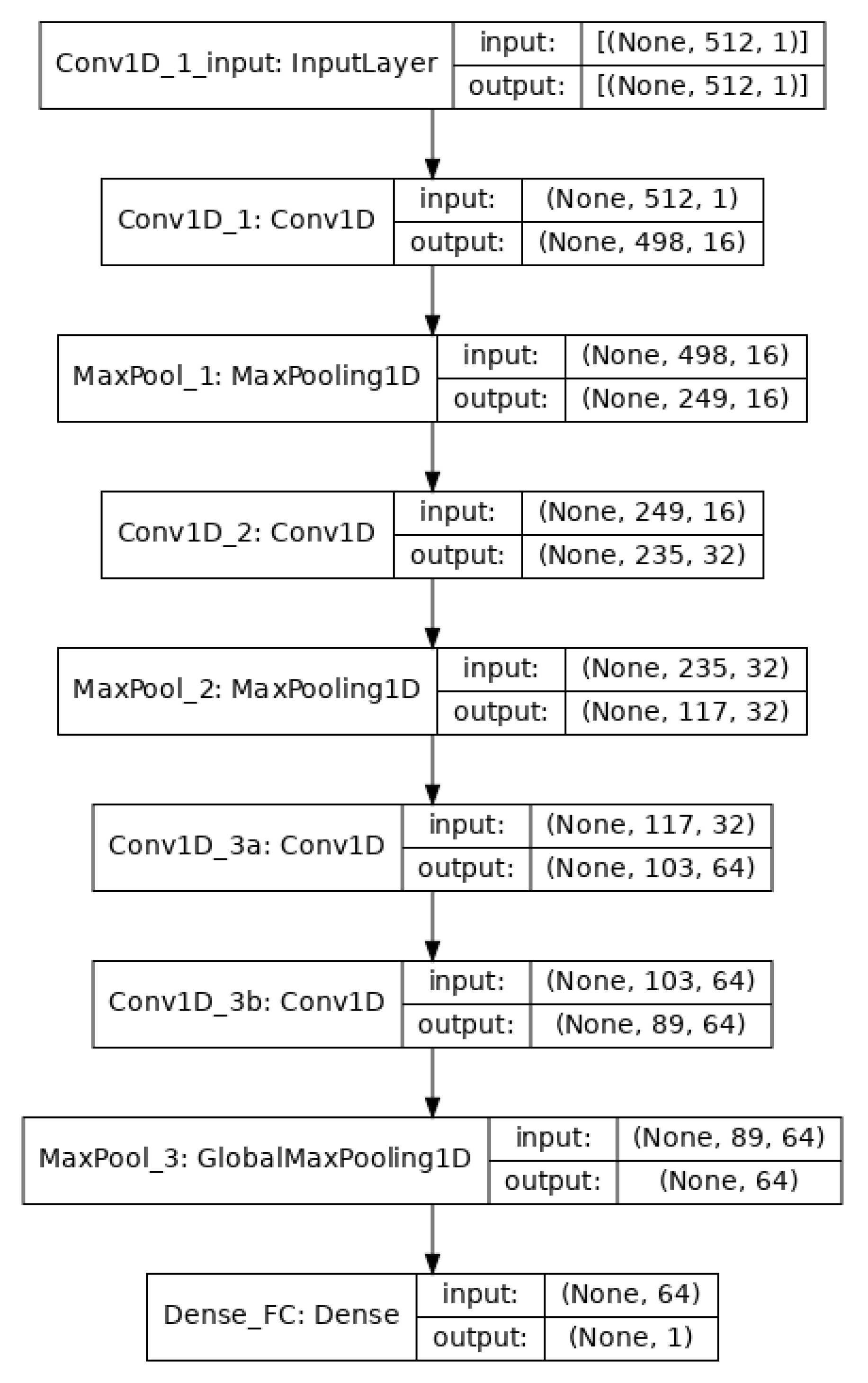
4. CNN Architecture for EEG Classification
4.1. 1D-Convolution and Pooling
4.2. Training and Testing of the Model
4.3. Optimizing the Neural Network Model
4.3.1. Batch Normalization
4.3.2. Dropout Layers
4.3.3. L1/L2 Regularization
4.3.4. Optimizer, Learning Rate, and Early Stopping
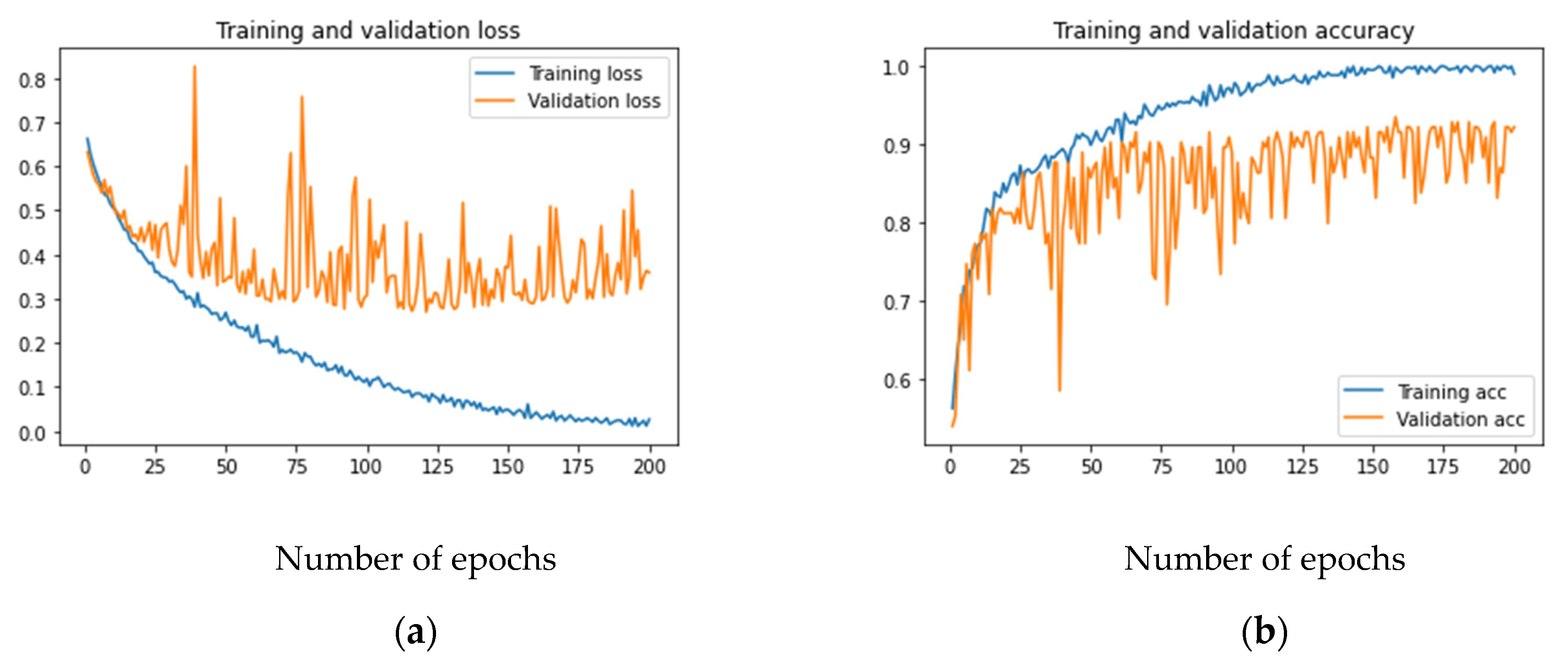
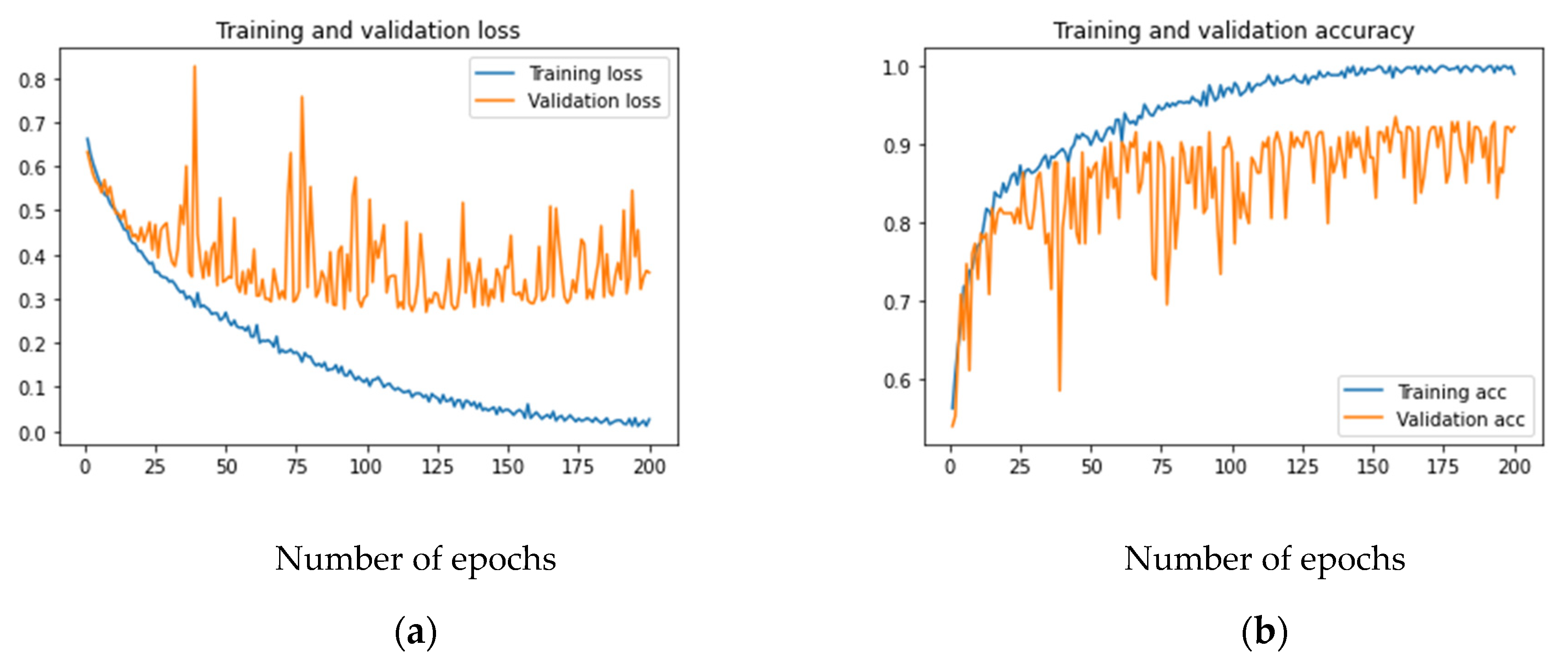
5. Results
6. Discussion
6.1. Importance of Regularization in DNN
6.2. Limitations of the Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADC | Analog-to-Digital Converter |
| AE | Approximate Entropy |
| AUC | Area Under Curve |
| CNN | Convolutional Neural Network |
| DWT | Discrete Wavelet Transform |
| EEG | Electroencephalogram |
| ICA | Independent Component Analysis |
| LDA | Linear Discriminant Analysis |
| LFDA | Local Fisher’s Discriminant Analysis |
| PCA | Principal Component Analysis |
| NB | Naïve Bayes |
| ReLU | Rectified Linear Unit |
| SE | Sample Entropy |
| SVM | Support Vector Machine |
| KNN | K-Nearest Neighbor |
References
- Khemiri, L.; Kaag, A.M.; Joos, L.; Dom, G.; Franck, J.; Goudriaan, A.E.; Jayaram-Lindström, N. Family History of Alcohol Abuse Associated with Higher Impulsivity in Patients with Alcohol Use Disorder: A Multisite Study. Eur. Addict. Res. 2020, 26, 85–95. [Google Scholar] [CrossRef]
- WHO. Global Status Report on Alcohol and Health 2018; World Health Organization: Geneva, Switzerland, 2019. [Google Scholar]
- Mehta, G.; Sheron, N. No safe level of alcohol consumption–Implications for global health. J. Hepatol. 2019, 70, 587–589. [Google Scholar] [CrossRef]
- Le Pham, T.T.; Callinan, S.; Livingston, M. Patterns of alcohol consumption among people with major chronic diseases. Aust. J. Prim. Health 2019, 25, 163–167. [Google Scholar] [CrossRef]
- Schuler, M.S.; Puttaiah, S.; Mojtabai, R.; Crum, R.M. Perceived barriers to treatment for alcohol problems: A latent class analysis. Psychiatr. Serv. 2015, 66, 1221–1228. [Google Scholar] [CrossRef] [Green Version]
- Anuragi, A.; Sisodia, D.S. Alcohol use disorder detection using EEG Signal features and flexible analytical wavelet transform. Biomed. Signal Process. Control 2019, 52, 384–393. [Google Scholar] [CrossRef]
- Anuragi, A.; Sisodia, D.S.; Pachori, R.B. Automated alcoholism detection using fourier-bessel series expansion based empirical wavelet transform. IEEE Sens. J. 2020, 20, 4914–4924. [Google Scholar] [CrossRef]
- Siuly, S.; Bajaj, V.; Sengur, A.; Zhang, Y. An advanced analysis system for identifying alcoholic brain state through EEG signals. Int. J. Autom. Comput. 2019, 16, 737–747. [Google Scholar] [CrossRef]
- Saminu, S.; Xu, G.; Shuai, Z.; Abd El Kader, I.; Jabire, A.H.; Ahmed, Y.K.; Karaye, I.A.; Ahmad, I.S. A Recent Investigation on Detection and Classification of Epileptic Seizure Techniques Using EEG Signal. Brain Sci. 2021, 11, 668. [Google Scholar] [CrossRef]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef]
- Qaisar, S.M.; Subasi, A. Effective epileptic seizure detection based on the event-driven processing and machine learning for mobile healthcare. J. Ambient Intell. Humaniz. Comput. 2020, 1–13. [Google Scholar] [CrossRef]
- Acharya, J.N.; Hani, A.J.; Cheek, J.; Thirumala, P.; Tsuchida, T.N. American clinical neurophysiology society guideline 2: Guidelines for standard electrode position nomenclature. Neurodiagn. J. 2016, 56, 245–252. [Google Scholar] [CrossRef] [PubMed]
- Qaisar, S.M.; Hussain, S.F. Effective epileptic seizure detection by using level-crossing EEG sampling sub-bands statistical features selection and machine learning for mobile healthcare. Comput. Methods Programs Biomed. 2021, 203, 106034. [Google Scholar] [CrossRef] [PubMed]
- Urigüen, J.A.; Garcia-Zapirain, B. EEG artifact removal—State-of-the-art and guidelines. J. Neural Eng. 2015, 12, 031001. [Google Scholar] [CrossRef] [PubMed]
- Ghanem, N.H.; Eltrass, A.S.; Ismail, N.H. Investigation of EEG noise and artifact removal by patch-based and kernel adaptive filtering techniques. In Proceedings of the 2018 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rome, Italy, 11–13 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Mishra, A.; Bhateja, V.; Gupta, A.; Mishra, A. Noise removal in EEG signals using SWT–ICA combinational approach. In Proceedings of the Smart Intelligent Computing and Applications; Chandra, S.S., Vikrant, B., Das, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 217–224. [Google Scholar]
- Thenappan, S. Performance Improvement in Electroencephalogram Signal by Using DWT. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 2770–2775. [Google Scholar]
- Yakoubi, M.; Hamdi, R.; Salah, M.B. EEG enhancement using extended Kalman filter to train multi-layer perceptron. Biomed. Eng. Appl. Basis Commun. 2019, 31, 1950005. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef]
- Shaheen, F.; Verma, B.; Asafuddoula, M. Impact of automatic feature extraction in deep learning architecture. In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Zhang, H.; Silva, F.H.; Ohata, E.F.; Medeiros, A.G.; Rebouças Filho, P.P. Bi-Dimensional Approach based on Transfer Learning for Alcoholism Predisposition Classification via EEG Signals. Front. Hum. Neurosci. 2020, 14, 365. [Google Scholar] [CrossRef]
- Srabonee, J.F.; Peya, Z.J.; Akhand, M.; Siddique, N. Alcoholism Detection from 2D Transformed EEG Signal. In Proceedings of the International Joint Conference on Advances in Computational Intelligence, Dhaka, Bangladesh, 20–21 November 2020; Springer: Singapore, 2020; pp. 297–308. [Google Scholar]
- Xu, G.; Shen, X.; Chen, S.; Zong, Y.; Zhang, C.; Yue, H.; Liu, M.; Chen, F.; Che, W. A deep transfer convolutional neural network framework for EEG signal classification. IEEE Access 2019, 7, 112767–112776. [Google Scholar] [CrossRef]
- Gong, S.; Xing, K.; Cichocki, A.; Li, J. Deep Learning in EEG: Advance of the Last Ten-Year Critical Period. IEEE Trans. Cogn. Dev. Syst. 2021, 1. [Google Scholar] [CrossRef]
- Khosla, A.; Khandnor, P.; Chand, T. A comparative analysis of signal processing and classification methods for different applications based on EEG signals. Biocybern. Biomed. Eng. 2020, 40, 649–690. [Google Scholar] [CrossRef]
- Orosco, L.; Correa, A.G.; Laciar, E. A survey of performance and techniques for automatic epilepsy detection. J. Med. Biol. Eng. 2013, 33, 526–537. [Google Scholar] [CrossRef]
- Zhu, G.; Li, Y.; Wen, P.P.; Wang, S. Analysis of alcoholic EEG signals based on horizontal visibility graph entropy. Brain Inform. 2014, 1, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Shri, T.P.; Sriraam, N. Pattern recognition of spectral entropy features for detection of alcoholic and control visual ERP’s in multichannel EEGs. Brain Inform. 2017, 4, 147–158. [Google Scholar] [CrossRef] [Green Version]
- Jiajie, L.; Narasimhan, K.; Elamaran, V.; Arunkumar, N.; Solarte, M.; Ramirez-Gonzalez, G. Clinical decision support system for alcoholism detection using the analysis of EEG signals. IEEE Access 2018, 6, 61457–61461. [Google Scholar] [CrossRef]
- Velu, P.; de Sa, V.R. Single-trial classification of gait and point movement preparation from human EEG. Front. Neurosci. 2013, 7, 84. [Google Scholar] [CrossRef] [Green Version]
- Ren, W.; Han, M. Classification of EEG Signals Using Hybrid Feature Extraction and Ensemble Extreme Learning Machine. Neural Process. Lett. 2019, 50, 1281–1301. [Google Scholar] [CrossRef]
- Rahman, S.; Sharma, T.; Mahmud, M. Improving alcoholism diagnosis: Comparing instance-based classifiers against neural networks for classifying EEG signal. In Proceedings of the International Conference on Brain Informatics, Padova, Italy, 18–20 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 239–250. [Google Scholar]
- Abbas, W.; Khan, N.A. DeepMI: Deep learning for multiclass motor imagery classification. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 219–222. [Google Scholar]
- Wei, X.; Zhou, L.; Chen, Z.; Zhang, L.; Zhou, Y. Automatic seizure detection using three-dimensional CNN based on multi-channel EEG. BMC Med. Inform. Decis. Mak. 2018, 18, 71–80. [Google Scholar] [CrossRef] [Green Version]
- Bavkar, S.; Iyer, B.; Deosarkar, S. Rapid screening of alcoholism: An EEG based optimal channel selection approach. IEEE Access 2019, 7, 99670–99682. [Google Scholar] [CrossRef]
- Chaabene, S.; Bouaziz, B.; Boudaya, A.; Hökelmann, A.; Ammar, A.; Chaari, L. Convolutional Neural Network for Drowsiness Detection Using EEG Signals. Sensors 2021, 21, 1734. [Google Scholar] [CrossRef]
- Qazi, E.-u.-H.; Hussain, M.; AboAlsamh, H.A. Electroencephalogram (EEG) Brain Signals to Detect Alcoholism Based on Deep Learning. CMC Comput. Mater. Contin. 2021, 67, 3329–3348. [Google Scholar]
- Bhuvaneshwari, M.; Kanaga, E.G.M. Convolutional Neural Network for Addiction Detection using Improved Activation Function. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Tamil Nadu, India, 8–10 April 2021; pp. 996–1000. [Google Scholar]
- Rodrigues, J.d.C.; Filho, P.P.R.; Peixoto, E.; Kumar N, A.; de Albuquerque, V.H.C. Classification of EEG signals to detect alcoholism using machine learning techniques. Pattern Recognit. Lett. 2019, 125, 140–149. [Google Scholar] [CrossRef]
- Begleiter, H. EEG Database Data Set; Ingber, L., Ed.; UCI Machine Learning Repository, University of California at Irvine: Irvine, CA, USA, 1999; Available online: https://archive.ics.uci.edu/ml/datasets/EEG+Database (accessed on 4 August 2021).
- Begleiter, H. Multiple Electrode Time Series EEG Recordings of Control and Alcoholic Subjects. Available online: https://kdd.ics.uci.edu/databases/eeg/ (accessed on 4 August 2021).
- Zhang, X.L.; Begleiter, H.; Porjesz, B.; Wang, W.; Litke, A. Event related potentials during object recognition tasks. Brain Res. Bull. 1995, 38, 531–538. [Google Scholar] [CrossRef]
- Mehla, V.K.; Singhal, A.; Singh, P. A novel approach for automated alcoholism detection using Fourier decomposition method. J. Neurosci. Methods 2020, 346, 108945. [Google Scholar] [CrossRef]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Ranjani, M.; Supraja, P. Classifying the Autism and Epilepsy Disorder Based on EEG Signal Using Deep Convolutional Neural Network (DCNN). In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 880–886. [Google Scholar]
- Thomas, J.; Comoretto, L.; Jin, J.; Dauwels, J.; Cash, S.S.; Westover, M.B. EEG classification via convolutional neural network-based interictal epileptiform event detection. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3148–3151. [Google Scholar]
- Gao, Y.; Gao, B.; Chen, Q.; Liu, J.; Zhang, Y. Deep convolutional neural network-based epileptic electroencephalogram (EEG) signal classification. Front. Neurol. 2020, 11, 375. [Google Scholar] [CrossRef] [PubMed]
- Mao, W.; Fathurrahman, H.; Lee, Y.; Chang, T. EEG dataset classification using CNN method. In Proceedings of the Journal of Physics: Conference Series 1456, The 5th International Conference on Technology and Vocational Teachers (ICTVT 2019), Yogyakarta, Indonesia, 14–15 September 2019; p. 012017. [Google Scholar]
- Abdelhameed, A.; Bayoumi, M. A deep learning approach for automatic seizure detection in children with epilepsy. Front. Comput. Neurosci. 2021, 15, 29. [Google Scholar] [CrossRef]
- Sun, J.; Cao, R.; Zhou, M.; Hussain, W.; Wang, B.; Xue, J.; Xiang, J. A hybrid deep neural network for classification of schizophrenia using EEG Data. Sci. Rep. 2021, 11, 4706. [Google Scholar] [CrossRef]
- Lun, X.; Yu, Z.; Chen, T.; Wang, F.; Hou, Y. A simplified CNN classification method for MI-EEG via the electrode pairs signals. Front. Hum. Neurosci. 2020, 14, 338. [Google Scholar] [CrossRef]
- Stancin, I.; Cifrek, M.; Jovic, A. A Review of EEG Signal Features and Their Application in Driver Drowsiness Detection Systems. Sensors 2021, 21, 3786. [Google Scholar] [CrossRef]
- Chriskos, P.; Frantzidis, C.A.; Papanastasiou, E.; Bamidis, P.D. Applications of Convolutional Neural Networks in neurodegeneration and physiological aging. Int. J. Psychophysiol. 2021, 159, 1–10. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications Co.: Shelter Island, NY, USA, 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bengaluru, India, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1542–1547. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Dean, J.; Patterson, D.; Young, C. A new golden age in computer architecture: Empowering the machine-learning revolution. IEEE Micro 2018, 38, 21–29. [Google Scholar] [CrossRef]
- Li, X.; Zhang, P.; Song, D.; Yu, G.; Hou, Y.; Hu, B. EEG Based Emotion Identification Using Unsupervised Deep Feature Learning. In SIGIR2015 Workshop on Neuro-Physiological Methods in IR Research, Santiago, Chile, 13 August 2015. Available online: https://sigir.org/files/forum/2015D/p083.pdf (accessed on 4 August 2021).
- Thimm, G.; Fiesler, E. Neural network initialization. In Proceedings of the International Workshop on Artificial Neural Networks, Torremolinos, Malaga, Spain, 7–9 June 1995; pp. 535–542. [Google Scholar]
- Bgegleiter, H. EEG Dataset for Alcoholism Classification: CSV Version. 240 Records; Mukhtar, H., Ed.; Kaggle: San Francisco, CA, USA, 2021; Available online: https://www.kaggle.com/yahamid/eeg-alcohol-normal-combined (accessed on 4 August 2021).

{kind=link}
{kind=link}
{kind=link}
| CNN Model | Accuracy | Precision | Recall | F1-Score | AUC | Kappa |
|---|---|---|---|---|---|---|
| Baseline | 91.15% | 92.22% | 89.24% | 90.71% | 91.08% | 82.25% |
| Regularized | 98.43% | 100% | 96.77% | 98.36% | 98.38% | 96.87% |
| 3-Fold | 5-Fold | 10-Fold | |||||
|---|---|---|---|---|---|---|---|
| Validation | Test | Validation | Test | Validation | Test | Best Run | |
| Samples | 256 | 192 | 153 | 192 | 76 | 192 | |
| Batch size | μ (σ) | μ (σ) | μ (σ) | ||||
| 4 | 0.92 (0.01) | 0.96 | 0.92 (0.01) | 0.93 | 0.95 (0.01) | 0.97 | 0.97 |
| 8 | 0.93 (0.01) | 0.94 | 0.94 (0.02) | 0.95 | 0.94 (0.02) | 0.96 | 0.97 |
| 16 | 0.92 (0.01) | 0.94 | 0.94 (0.01) | 0.96 | 0.94 (0.01) | 0.98 | 0.96 |
| 32 | 0.93 (0.02) | 0.95 | 0.93 (0.03) | 0.95 | 0.94 (0.03) | 0.96 | 0.97 |
| 64 | 0.92 (0.01) | 0.95 | 0.94 (0.01) | 0.95 | 0.94 (0.03) | 0.95 | 1.0 |
| 128 | 0.92 (0.01) | 0.90 | 0.92 (0.02) | 0.95 | 0.95 (0.03) | 0.95 | 0.99 |
| 256 | 0.88 (0.02) | 0.89 | 0.90 (0.03) | 0.90 | 0.90 (0.04) | 0.89 | 0.97 |
| Approach | Feature Extractor | Classifiers | Performance |
|---|---|---|---|
| Transfer learning [21] | GLM, Hu moment, LBP + 12 CNN models | KNN, SVM linear/poly/RBF, RF, MLP, and NB Best: SVM RBF | Accuracy: 95.33 |
| Precision: 95.68 | |||
| Recall: 95.00 | |||
| F1-score: 95.24 | |||
| Machine learning [29] | AE, SE, mean, std | SVM cubic/quadratic, KNN, ensemble tree Best: quadratic SVM | Accuracy: 95 |
| Sensitivity: 95 | |||
| AUC: 98 | |||
| Hybrid Features + EELM [31] | AR, WT, WPD, SE, and class separability | ELM, bagging, boosting Best: LDA + EELM | Accuracy: 91.17 |
| ML + MLP [36] | Min/max, mean, std, power value, Daubechies, coiflets, symlets, and biorthogonal wavelets | SVM, OPF, KNN, NB, MLP Best: NB | Accuracy: 99.6 |
| Specificity: 99.6 | |||
| Sensitivity: 99.6 | |||
| PPV: 99.6 | |||
| MP-CNN [37] | 5 MP-CNN models | Best: 19 best channels in CNN with 3 convolution layers and softmax classifier | Accuracy: 100 |
| Specificity: 100 | |||
| Sensitivity: 100 | |||
| F1-score: 100 | |||
| 2D-CNN [22] | PCC and 2D spectrograms followed by CNN | CNN with four convolution and pooling layers | Accuracy: 98.13 |
| Specificity: 97 | |||
| Sensitivity: 98 | |||
| F1-score: 98 | |||
| Our approach, CNN | CNN | CNN with 3 convolution layers, dropout, batch normalization, and kernel regularization and softmax classifier on two channels | Accuracy: 98 |
| Precision: 100 | |||
| Recall: 96.8 | |||
| F1-score: 98.4 | |||
| AUC: 98.4 |
| Baseline CNN Model | Regularized CNN Model | ||||
|---|---|---|---|---|---|
| Layer (Type) | Output Shape | Params | Layer (type) | Output Shape | Params |
| Conv1D | (None, 498, 16) | 256 | Conv1D | (None, 498, 16) | 256 |
| Max Pooling 1D | (None, 249, 16) | 0 | Max Pooling 1D | None, 249, 16) | 0 |
| Conv1D | (None, 235, 32) | 7712 | Batch Normal | None, 249, 16) | 64 |
| Max Pooling 1D | (None, 117, 32) | 0 | Dropout | None, 249, 16) | 0 |
| Conv1D | (None, 103, 64) | 30,784 | Conv1D | (None, 235, 32) | 7712 |
| Conv1D | (None, 89, 64) | 61,504 | Max Pooling 1D | (None, 117, 32) | 0 |
| Global Max Pooling | (None, 64) | 0 | Batch Normal | (None, 117, 32) | 128 |
| Dense | (None, 1) | 65 | Dropout | (None, 117, 32) | 0 |
| Total params | 100,321 | Conv1D | (None, 103, 64) | 30,784 | |
| Trainable params | 100,321 | Conv1D | (None, 89, 64) | 61,504 | |
| Nontrainable params | 0 | Global Max Pooling | (None, 64) | 0 | |
| Batch Normal | (None, 64) | 256 | |||
| Dropout | (None, 64) | 0 | |||
| Dense | (None, 1) | 65 | |||
| Total params | 100,769 | ||||
| Trainable params | 100,545 | ||||
| Nontrainable params | 224 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhtar, H.; Qaisar, S.M.; Zaguia, A. Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals. Sensors 2021, 21, 5456. https://doi.org/10.3390/s21165456
Mukhtar H, Qaisar SM, Zaguia A. Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals. Sensors. 2021; 21(16):5456. https://doi.org/10.3390/s21165456
Chicago/Turabian StyleMukhtar, Hamid, Saeed Mian Qaisar, and Atef Zaguia. 2021. "Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals" Sensors 21, no. 16: 5456. https://doi.org/10.3390/s21165456
APA StyleMukhtar, H., Qaisar, S. M., & Zaguia, A. (2021). Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals. Sensors, 21(16), 5456. https://doi.org/10.3390/s21165456