Abstract
Complementary metal-oxide-semiconductor (CMOS) image sensors can cause noise in images collected or transmitted in unfavorable environments, especially low-illumination scenarios. Numerous approaches have been developed to solve the problem of image noise removal. However, producing natural and high-quality denoised images remains a crucial challenge. To meet this challenge, we introduce a novel approach for image denoising with the following three main contributions. First, we devise a deep image prior-based module that can produce a noise-reduced image as well as a contrast-enhanced denoised one from a noisy input image. Second, the produced images are passed through a proposed image fusion (IF) module based on Laplacian pyramid decomposition to combine them and prevent noise amplification and color shift. Finally, we introduce a progressive refinement (PR) module, which adopts the summed-area tables to take advantage of spatially correlated information for edge and image quality enhancement. Qualitative and quantitative evaluations demonstrate the efficiency, superiority, and robustness of our proposed method.
1. Introduction
Noise usually accompanies images during acquisition or transmission, resulting in contrast reduction, color shift, and poor visual quality. The interference of noise not only contaminates the naturalness of an image, but also damages the precision of various computer vision-based applications, such as semantic segmentation [1,2], motion tracking [3,4], action recognition [5,6], and object detection [7,8,9,10,11,12], to name a few. Consequently, noise removal for these applications has attracted great interest as a preprocessing task over the last two decades. The classical description for the additive noise model can be defined as follows [13]:
where , , and represent an image accompanied with noise, a noise-free image, and noise, respectively.
Numerous approaches have been introduced to obtain noise-free images from the observed noisy ones; these approaches are generally categorized into two groups [14]: (1) model-based denoising methods [14,15,16,17,18], and (2) learning-based denoising methods [19,20,21,22].
Model-based denoising methods are considered as traditional techniques that use filters, such as median-type filter, Gaussian filter, and Gabor filter to remove noise. In efforts to remove impulse noise, Lin et al. [14] proposed a morphological mean filter that first detects the position and number of pixels without noise, and then uses these detected pixels to substitute neighboring noisy pixels in the image. Zhang et al. [15] introduced a new filter, named adaptive weighted mean (AWM). The main idea of this proposed filter is to reduce the error of detecting noise pixel candidates and replace them with suitable value computed using noise-free pixels. The proposed median filter [16] did not require any iteration to detect noises, but could directly identify low- and high-density salt-and-pepper noises as the lowest and highest values, respectively; it then utilized prior information to capture natural pixels and remove these noises. In the work [17], a hybrid filter combining fuzzy switching and median adaptive median filters was introduced for noise reduction in two stages. In the detection stage, the noise pixels are recognized by utilizing the histogram of the noisy images. Then, the detected noise pixels are removed whereas noise-free pixels are retained during the filtering stage to preserve the textures and details included in the original image. Based on the unsymmetrical trimmed median filter, Esakkirajan et al. [18] presented a modified decision method, in which the mean of all elements of a selected window is used to replaced noise pixels for restoration of both color and gray images. In addition, various filtration algorithms [23], such as Wiener filtration, multistage Kalman filtration, and nonlinear Kalman filtration, which are commonly used for the formation of images containing characteristics close to those of real signals, can also be applied for denoising problems. However, although these approaches are simple to implement and achieve satisfying denoising performance in the presence of low-density noise, they are generally unsuitable for processing images featuring high-density noise.
Learning-based denoising methods consist of two main categories, including prior learning and deep learning. Between these methods, deep learning has shown outstanding results for noise removal in recent years. Xu et al. [19] recognized that simple distributions, such as uniform and Gaussian distributions are insufficient to describe the noise in real noisy images. They thus proposed a new method that could first learn the characteristics of real clean images and then use these characteristics to recover noise-free images from real noisy ones. The method in [20] removed noises and retrieved clean images by employing ant-colony optimization to generate candidate noise pixels for sparse approximation learning. Hieu et al. [21] introduced a lightweight denoising model using a convolution neural network (CNN) with only five deconvolutional and convolutional layers, which can be optimized in an end-to-end manner and achieves high running time on high-density noise images. In [22], the authors proposed a model based on a CNN, named DnCNNs, to denoise image with random noise levels. DnCNN accomplished the objective by modifying the VGG network [24] to extract features of the input samples, and engaging the batch normalization and residual learning for effective optimization. Unfortunately, while these methods yield high rates of success for denoising task, they require high computational costs and only work well when trained on a dataset with a massive number of image samples.
To reduce the dependence of the deep CNNs on a large training dataset, Ulyanov et al. [25] presented a deep image prior (DIP) approach, in which a handcrafted prior can be replaced with a randomly-initialized CNN for obtaining impressive results in common inverse tasks, such as blind restoration, super-resolution, and inpainting. Many research works based on DIP have been proposed [26,27,28], which introduce an additional regularization term to achieve robust performance. The method in [26] coped with the problem of denoising by combining both denoised and contrast-enhanced denoised results generated by DIP model. Cheng et al. [27] explained DIP from a Bayesian point of view and exploited a fully Bayesian posterior inference for better denoising result. In [28], DIP was adopted for image decomposition problems, such as image dehazing and watermark removal. The authors showed that stacking multiple DIPs and using the hybrid objective function allow the model to decompose an image into the desired layers.
Inspired by DIP, in this paper, we propose a novel method to address the problems of noise removal, which can reach remarkable denoising performance without necessitating a large training dataset. Our proposed model is comprised of three modules: (1) a DIP-based module, (2) an image fusion (IF) module, and (3) a progressive refinement (PR) module, as displayed in Figure 1. In the proposed model, first, the DIP-based module applies DIP to learn contrast enhancement and noise removal, simultaneously. Next, the IF module based on Laplacian pyramid (LP) decomposition, is used to avoid color shift and noise amplification during image production. Finally, the summed-area tables (SATs) are employed in the PR module to enhance edge information for acquiring high-quality output noise-free images of our proposed model. The details of these three modules are further presented in Section 2.
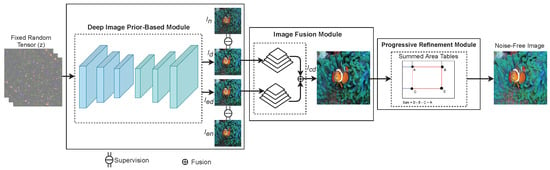
Figure 1.
Flowchart of the proposed denoising method. is a noisy image, is an enhanced noisy image obtained by applying a contrast enhancement method to . and represent two denoised images that are supervised by and , respectively.
In summary, three technical contributions of our work are listed below:
- Noise removal and contrast enhancement are simultaneously learned for effective performance improvement without requiring large amounts of training data.
- The color distortion of denoised images is prevented by applying LP decomposition.
- Edge information is enhanced to achieve high-quality output images by taking advantage of spatially correlated information obtained from SATs.
To prove the efficiency of the proposed method, we use images from the DIV2K dataset [29] and create noisy images with various noise levels for evaluation. Our approach improved the results of competitive methods on 10 randomly selected test images by up to in terms of noise removal.
The rest of our paper is organized as follows. In Section 2, we present the proposed method, including the DIP-based module, the IF module, and the PR module, in detail. Quantitative and qualitative evaluations, as well as a discussion of our findings, are provided in Section 3. Finally, we conclude our work in Section 4.
2. Proposed Method
This section presents a novel image denoising approach that could effectively remove noise and enhance edge information for image quality improvement. The proposed method is composed of three modules, namely, (1) a DIP-based module, (2) an IF module, and (3) a PR module, as illustrated in Figure 1. The details of each module are described in the following subsections.
2.1. DIP-Based Module
As mentioned in Section 1, numerous CNN-based noise removal models have been introduced to boost the denoising performance. However, these methods must be trained on a large dataset to learn better the features of images for the noise removal. In addition, the work [30] showed that although the deep CNN model learns well on a massive number of samples, it might also over fit the samples when labels are randomiized.
By contrast, not all sample priors need to be learned from the data, DIP [25] represents a self-supervised learning model based on a nested U-net with a randomly initialized input tensor trained on a noisy image for denoising; this model obtains impressive results compared with state-of-the-art denoising approaches. Thus, to enhance the denoised results, we first introduced DIP-based module to generate two different denoised images and . Our DIP-based module employs an encoder–decoder U-net architecture as a backbone network and relies on two target images, including a noisy image and an enhanced noisy image , to supervise the production of and , respectively. Here, is acquired by applying the contrast enhancement method [31] to .
The architecture of the DIP-based module is displayed in Figure 2, where the input z and the output image have the same spatial resolution. The LeakyReLU [32] is used as a non-linearity. The strides executed within convolutional layers are applied for downsampling, while the bilinear interpolation and nearest neighbor techniques are utilized for upsampling. In all convolutional layers, except for the inversion of feature, zero padding is replaced with reflection padding. The detailed architecture of the DIP-based module is depicted in Table 1.
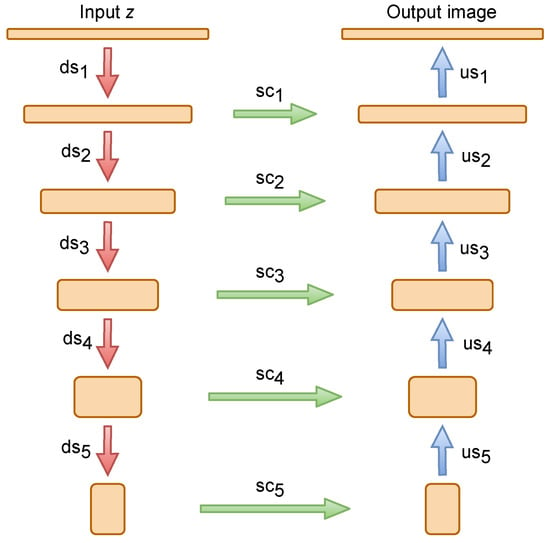
Figure 2.
The architecture of the DIP-based module. Note that sc, us, and ds denote skip-connections, upsampling, and downsampling, respectively.

Table 1.
The detailed architecture of the DIP-based module.
For training the DIP-based module, the objective function is described as follows.
where represents the DIP-based module, are parameters of , and and represent the generated images and , respectively.
2.2. Image Fusion Module
Direct application of contrast enhancement to the noise removal stage may cause noise amplification and color shifts, resulting in the introduction of many visual artifacts [26]. To address this problem, we introduce an IF module to combine two denoised images and generated by the DIP-based module.
LP was introduced by Burt et al. [33] to represent a compact image. The basic concept of the LP includes the following steps: (1) a lowpass filter w, such as the Gaussian filter, is used to transform the original image and downsample it by two to produce a decimated lowpass version; (2) the resulting image is upsampled by padding zeros between each column and row and convolving it with the filter w to interpolate the missing values and create an expanded image . Subsequently, a detailed image is created by subtracting pixel by pixel from . Based on the LP, many image fusion methods have been studied and acquired impressive results [34].
Inspired by the works in [33,34], our IF module employs LP decomposition to combine images effectively and prevent the image from shifting color and amplifying noise. Both denoised images and are fed in the IF module and performed by the LP decomposition, denoted as and . The output image of the module is defined as follows:
where n = 1, 2,…, l denotes the n-th level in the pyramid, l denotes the number of pyramid levels, is a hyperparameter, controlling the relative of two the LP decompositions. In our experiments, l is set to 5, and is set to to achieve the best results.
2.3. Progressive Refinement Module
After the combined image is produced by the IF module, the edge information of this image is purified to improve the image quality. This objective is accomplished by utilizing our proposed PR module.
The PR module adopts SATs [35], which functions as a spatial filter and takes advantage of spatially correlated information for edge information enhancement. In the image , for each color component c with each pixel at position (), the SAT calculates the summation of a patch as follows:
We facilitate fast calculations by passing through the image with the SAT only once to achieve each pixel. Equation (4) is rewritten as follows:
where and present the direction offsets.
Through the SAT, the pixels that are unrepresentative of their surroundings in the image are effectively eliminated. Thus, the proposed method could achieve enhanced edge information and generate high-quality images.
3. Experimental Results
All experimental results of our method for noise removal are summarized in this section. To conduct the experiments, we use the DIV2K dataset [29], randomly select 10 images and then resize these images to for testing, as shown in Figure 3. Noisy images are obtained by applying additive white Gaussian noise (AWGN) [36] with amplitudes following a Gaussian distribution:
where and represent the noise standard deviation and mean value of the distribution, respectively. For zero-mean AWGN, is set to 0, and is a key parameter.

Figure 3.
The images from the DIV2K dataset.
We create test noisy images by adding zero-mean AWGN with noise levels () of 60, 70, and 80. Some examples of created noisy images are displayed in Figure 4. Since the number of runs necessary to obtain good denoised results are contingent upon the noise level, we run 1500, 1000, and 980 epochs on average to acquire our denoised results. For comparison, competitive denoising methods are used, including DIP [25], combination model of contrast enhancement method CLAHE [31] and DIP, denoted as CLAHE-DIP, and the method of Cheng et al. [26], denoted as DIPIF.

Figure 4.
Example of “chicken” image with three noise levels.
For quantitative assessment, we utilize a full-reference metric that exploits deep features to evaluate a perceptual similarity between a denoised image and a ground-truth image, called the Learned Perceptual Image Patch Similarity (LPIPS) metric [37]. Here, smaller LPIPS values indicate greater perceptual similarity of the compared images.
3.1. Ablation Study
To investigate the impact of some important design factors and select the best ones for our model, we conduct experiments using many different settings on a "chicken" image with , , and noise corruptions, as shown in Figure 4. Four different structures are established to select the factors of the designed model: (1) model with DIP, , , and the IF module, denoted as DIP-IF, (2) model with DIP, , and the IF and PR modules, denoted as DIP-IF1-PR, (3) model with DIP, , and the IF and PR modules, denoted as DIP-IF2-PR, and (4) model with DIP, , , and the IF and PR modules, denoted as DIP-IF-PR.
Figure 5 reveals that the DIP-IF-PR model achieves an LPIPS score of , which is better than DIP-IF, DIP-IF1-PR, and DIP-IF2-PR models by , , and , respectively, in terms of denoising. Therefore, all the components used to constitute the DIP-IF-PR model are adopted in our proposed model, as shown in Figure 1.
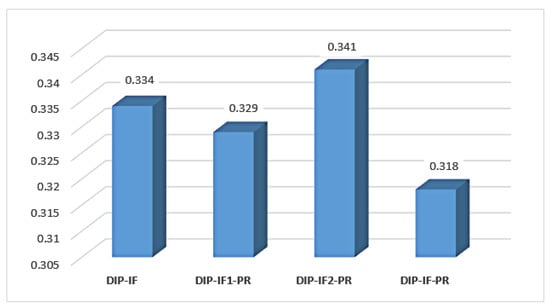
Figure 5.
The average LPIPS scores of the models with different settings on a “chicken” image with , , and noise corruptions. Note that a smaller value of LPIPS implies a better result in denoising.
3.2. Quantitative Results
Table 2 and Table 3 list the average LPIPS values and LPIPS values, respectively, computed by the compared methods on test noisy images with three noise levels of = 60, = 70, and = 80. The best LPIPS results achieved by the denoising methods are shown in boldface. As can be seen, our method surpasses the other methods on all randomly selected test images. The average LPIPS scores of compared methods on test images with noise corruption are presented in the second column of Table 2. In this case, our proposed method reaches an LPIPS score of , outperforming the DIP, DIP, CLAHE-DIP, and DIPIF methods by 1.8%, 5.5%, 8.4%, and 1.1% in noise reduction, respectively. The average LPIPS scores of compared methods on test images with noise corruption are shown in the third column of Table 2. Here, our proposed method obtains an LPIPS score of , improving the DIP, DIP, CLAHE-DIP, and DIPIF methods by 3.4%, 9%, 14.1%, and 1.5%, respectively, in terms of noise reduction. The average LPIPS scores of the compared methods on test images with noise corruption are listed in the fourth column of Table 2. Our proposed method achieves an LPIPS score of , surpassing DIP, DIP, CLAHE-DIP, and DIPIF methods by 4%, 9.9%, 16.7%, and 2.3%, respectively, in terms of noise reduction.
Table 2.
The average LPIPS values of our proposed method and the competitive denoising methods on 10 randomly selected test images. Note that a smaller value of LPIPS implies a better result in denoising.
Table 3.
The LPIPS values of our proposed method and the competitive denoising methods on 10 randomly selected test images. Note that a smaller value of LPIPS implies a better result in denoising.
3.3. Qualitative Results
We visually display the denoised image results of our proposed method and the competitive methods for various images corrupted by noise with three levels , , and .
The denoised results of our method and compared methods on a “jellyfish” image, “house” image, and “statue” image with , , and noise corruption are depicted in Figure 6, Figure 7 and Figure 8, respectively. As can be observed, the denoised results of the competitive methods still contain visible noises, resulting in blurred edges, darkening effects, and visual artifacts. By simultaneously optimizing denoising and contrast enhancement, and applying an edge enhancement technique, our method produces fewer artifacts and clearer natural-looking denoised images.
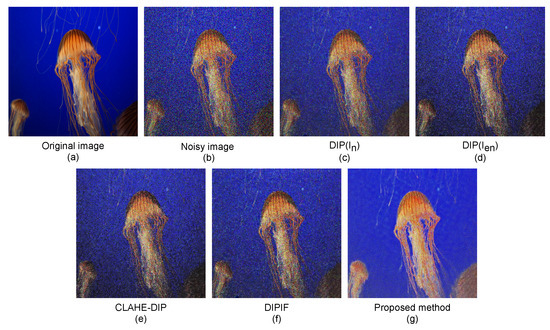
Figure 6.
Noise-free images produced by our proposed method and competitive denoising methods on a “jellyfish” image with noise corruption. (a) Clean image, (b) noisy image , (c) image restored by the DIP method using the original noisy image for supervision, (d) image restored by the DIP method using enhanced noisy image for supervision, (e) image restored by the CLAHE-DIP method, (f) image restored by the DIPIF method, and (g) image restored by our proposed method.

Figure 7.
Noise-free images produced by our proposed method and competitive denoising methods on a “house” image with noise corruption. (a) Clean image, (b) noisy image , (c) image restored by the DIP method using the original noisy image for supervision, (d) image restored by the DIP method using enhanced noisy image for supervision, (e) image restored by the CLAHE-DIP method, (f) image restored by the DIPIF method, and (g) image restored by our proposed method.

Figure 8.
Noise-free images produced by our proposed method and competitive denoising methods on a “statue” image with noise corruption. (a) Clean image, (b) noisy image , (c) image restored by the DIP method using the original noisy image for supervision, (d) image restored by the DIP method using enhanced noisy image for supervision, (e) image restored by the CLAHE-DIP method, (f) image restored by the DIPIF method, and (g) image restored by our proposed method.
4. Conclusions
In this paper, we propose to apply deep image prior, image fusion, and edge enhancement techniques for the noise removal task. To succeed in denoising, our proposed method is structured using three modules, namely, the DIP-based module for concurrently learning noise reduction and contrast enhancement, the IF module for combining images and counteracting color shift and noise amplification, and the PR module for enhancing edge information. The experimental results on randomly selected test images proved that our method is able to yield satisfactory denoised images. Quantitative and qualitative assessments showed that the proposed method outperforms the competitive methods in terms of noise removal and image reconstruction.
Although the DIP is successfully applied to our proposed method for noise removal, the use of images and as the inputs of the IF module can limit the speed of the whole model. This problem could be addressed by using features from the DIP module instead of its output images. We leave this work for future research.
Author Contributions
Supervision, S.-C.H. and B.C.M.F.; data curation, C.Z.; formal analysis, C.-C.H.; validation, Q.-V.H. and K.-H.C.; visualization, Q.-V.H. and S.-W.H.; writing—original draft preparation, T.-H.L. and Q.-V.H.; Writing—review & editing, S.-C.H., T.-H.L. and Y.-T.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology, Taiwan, under Grant MOST 109-2622-E-027-006-CC3, Grant MOST 108-2221-E-027-047-MY3, Grant MOST 106-2221-E-027-017-MY3, Grant MOST 110-2218-E-A49 -018, Grant MOST 108-2638-E-002-002-MY2, Grant MOST 110-2221-E-027-046-MY3, Grant MOST 110-2221-E-004-010, Grant MOST 109-2221-E-004-014, and Grant MOST 109-2622-E-004-002.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Anagnostis, A.; Tagarakis, A.C.; Kateris, D.; Moysiadis, V.; Sørensen, C.G.; Pearson, S.; Bochtis, D. Orchard Mapping with Deep Learning Semantic Segmentation. Sensors 2021, 21, 3813. [Google Scholar] [CrossRef]
- Shirokanev, A.; Ilyasova, N.; Andriyanov, N.; Zamytskiy, E.; Zolotarev, A.; Kirsh, D. Modeling of Fundus Laser Exposure for Estimating Safe Laser Coagulation Parameters in the Treatment of Diabetic Retinopathy. Mathematics 2021, 9, 967. [Google Scholar] [CrossRef]
- Lee, K.; Tang, W. A Fully Wireless Wearable Motion Tracking System with 3D Human Model for Gait Analysis. Sensors 2021, 21, 4051. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Wang, A.; Bu, C.; Wang, W.; Sun, H. Human Motion Tracking with Less Constraint of Initial Posture from a Single RGB-D Sensor. Sensors 2021, 21, 3029. [Google Scholar] [CrossRef] [PubMed]
- Nan, M.; Trăscău, M.; Florea, A.M.; Iacob, C.C. Comparison between Recurrent Networks and Temporal Convolutional Networks Approaches for Skeleton-Based Action Recognition. Sensors 2021, 21, 2051. [Google Scholar] [CrossRef]
- Wu, N.; Kawamoto, K. Zero-Shot Action Recognition with Three-Stream Graph Convolutional Networks. Sensors 2021, 21, 3793. [Google Scholar] [CrossRef]
- Le, T.H.; Huang, S.C.; Jaw, D.W. Cross-Resolution Feature Fusion for Fast Hand Detection in Intelligent Homecare Systems. IEEE Sens. J. 2019, 19, 4696–4704. [Google Scholar] [CrossRef]
- Huang, S.C.; Le, T.H.; Jaw, D.W. DSNet: Joint Semantic Learning for Object Detection in Inclement Weather Conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2623–2633. [Google Scholar] [CrossRef]
- Le, T.H.; Jaw, D.W.; Lin, I.C.; Liu, H.B.; Huang, S.C. An efficient hand detection method based on convolutional neural network. In Proceedings of the 2018 7th International Symposium on Next Generation Electronics (ISNE), Taipei, Taiwan, 7–9 May 2018; pp. 1–2. [Google Scholar]
- Hoang, Q.V.; Le, T.H.; Huang, S.C. An Improvement of RetinaNet for Hand Detection in Intelligent Homecare Systems. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taoyuan, Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]
- Hoang, Q.V.; Le, T.H.; Huang, S.C. Data Augmentation for Improving SSD Performance in Rainy Weather Conditions. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taoyuan, Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]
- Huang, S.C.; Le, T.H. Principles and Labs for Deep Learning; Academic Press: London, UK, 2021. [Google Scholar]
- Wang, F.; Huang, H.; Liu, J. Variational-based mixed noise removal with CNN deep learning regularization. IEEE Trans. Image Process. 2019, 29, 1246–1258. [Google Scholar] [CrossRef] [Green Version]
- Lin, P.H.; Chen, B.H.; Cheng, F.C.; Huang, S.C. A morphological mean filter for impulse noise removal. J. Disp. Technol. 2016, 12, 344–350. [Google Scholar] [CrossRef]
- Zhang, P.; Li, F. A new adaptive weighted mean filter for removing salt-and-pepper noise. IEEE Signal Process. Lett. 2014, 21, 1280–1283. [Google Scholar] [CrossRef]
- Hsieh, M.H.; Cheng, F.C.; Shie, M.C.; Ruan, S.J. Fast and efficient median filter for removing 1–99% levels of salt-and-pepper noise in images. Eng. Appl. Artif. Intell. 2013, 26, 1333–1338. [Google Scholar] [CrossRef]
- Toh, K.K.V.; Isa, N.A.M. Noise adaptive fuzzy switching median filter for salt-and-pepper noise reduction. IEEE Signal Process. Lett. 2009, 17, 281–284. [Google Scholar] [CrossRef] [Green Version]
- Esakkirajan, S.; Veerakumar, T.; Subramanyam, A.N.; PremChand, C.H. Removal of High Density Salt and Pepper Noise Through Modified Decision Based Unsymmetric Trimmed Median Filter. IEEE Signal Process. Lett. 2011, 18, 287–290. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, L.; Zhang, D. External prior guided internal prior learning for real-world noisy image denoising. IEEE Trans. Image Process. 2018, 27, 2996–3010. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.C.; Peng, Y.T.; Chang, C.H.; Cheng, K.H.; Huang, S.W.; Chen, B.H. Restoration of Images with High-Density Impulsive Noise Based on Sparse Approximation and Ant-Colony Optimization. IEEE Access 2020, 8, 99180–99189. [Google Scholar] [CrossRef]
- Le, T.H.; Lin, P.H.; Huang, S.C. LD-Net: An Efficient Lightweight Denoising Model Based on Convolutional Neural Network. IEEE Open J. Comput. Soc. 2020, 1, 173–181. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vasil’ev, K.K.; Dement’ev, V.E.; Andriyanov, N.A. Doubly stochastic models of images. Pattern Recognit. Image Anal. 2015, 25, 105–110. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Cheng, K.H.; Huang, S.W.; Peng, Y.T. Image Denoising with Edge Enhancement based on Deep Image Prior and Image Fusion. In Proceedings of the 33rd IPPR Conference on Computer Vision, Graphics, and Image Processing (CVGIP), Hsinchu, Taiwan, 16–18 August 2020. [Google Scholar]
- Cheng, Z.; Gadelha, M.; Maji, S.; Sheldon, D. A bayesian perspective on the deep image prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5443–5451. [Google Scholar]
- Gandelsman, Y.; Shocher, A.; Irani, M. “Double-DIP”: Unsupervised Image Decomposition via Coupled Deep-Image-Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11026–11035. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv 2016, arXiv:1611.03530. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Qin, H. Autonomous environment and target perception of underwater offshore vehicles. In Fundamental Design and Automation Technologies in Offshore Robotics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 91–113. [Google Scholar]
- Crow, F.C. Summed-area tables for texture mapping. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques, Minneapolis, MN, USA, 23–27 July 1984; pp. 207–212. [Google Scholar]
- Russo, F. A method for estimation and filtering of Gaussian noise in images. IEEE Trans. Instrum. Meas. 2003, 52, 1148–1154. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).