
Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network


Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials and Equipment
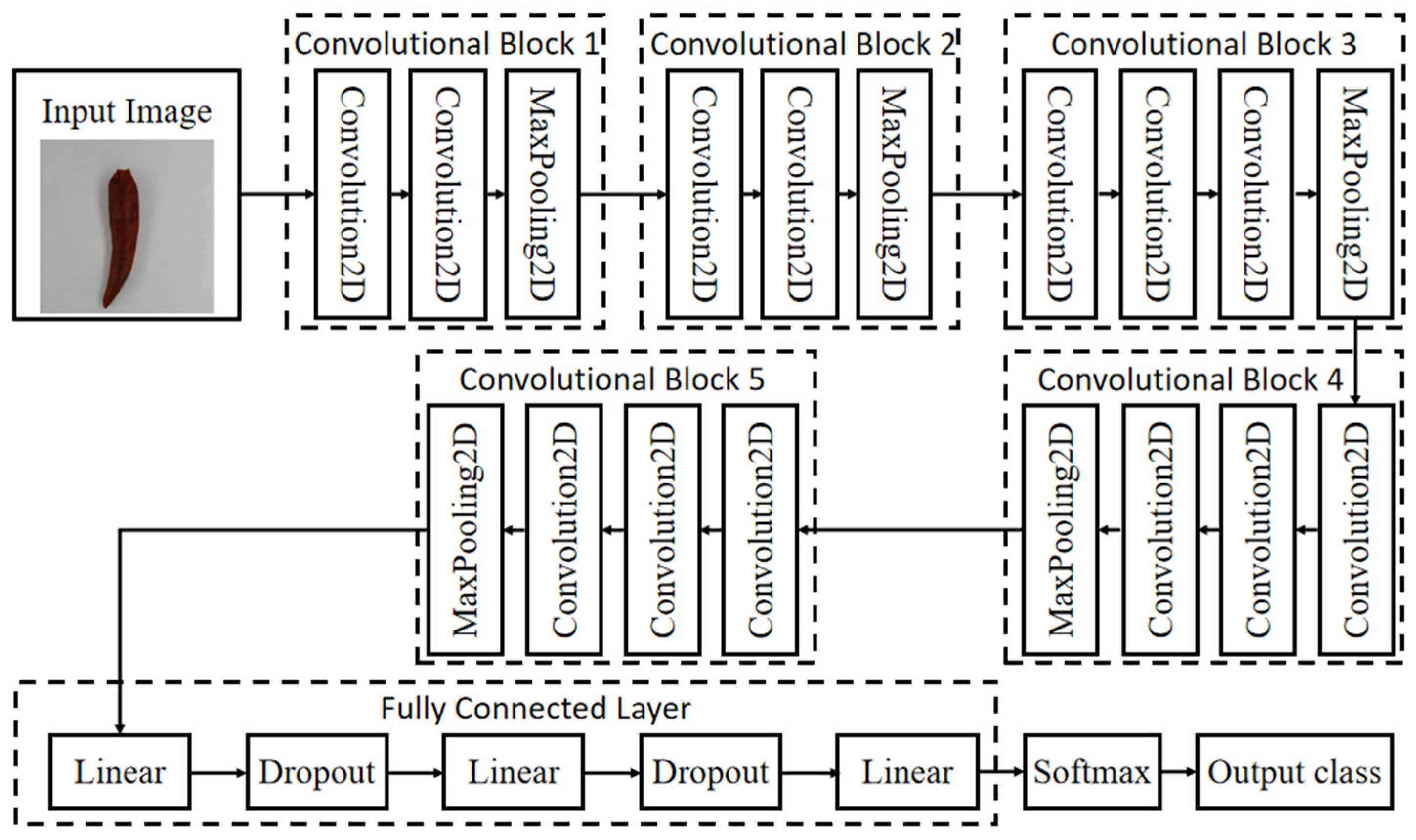
2.2. Model Establishment
3. Results and Analysis
3.1. Model Parameter Trimming
3.1.1. Influence of Dropout on Model Performance
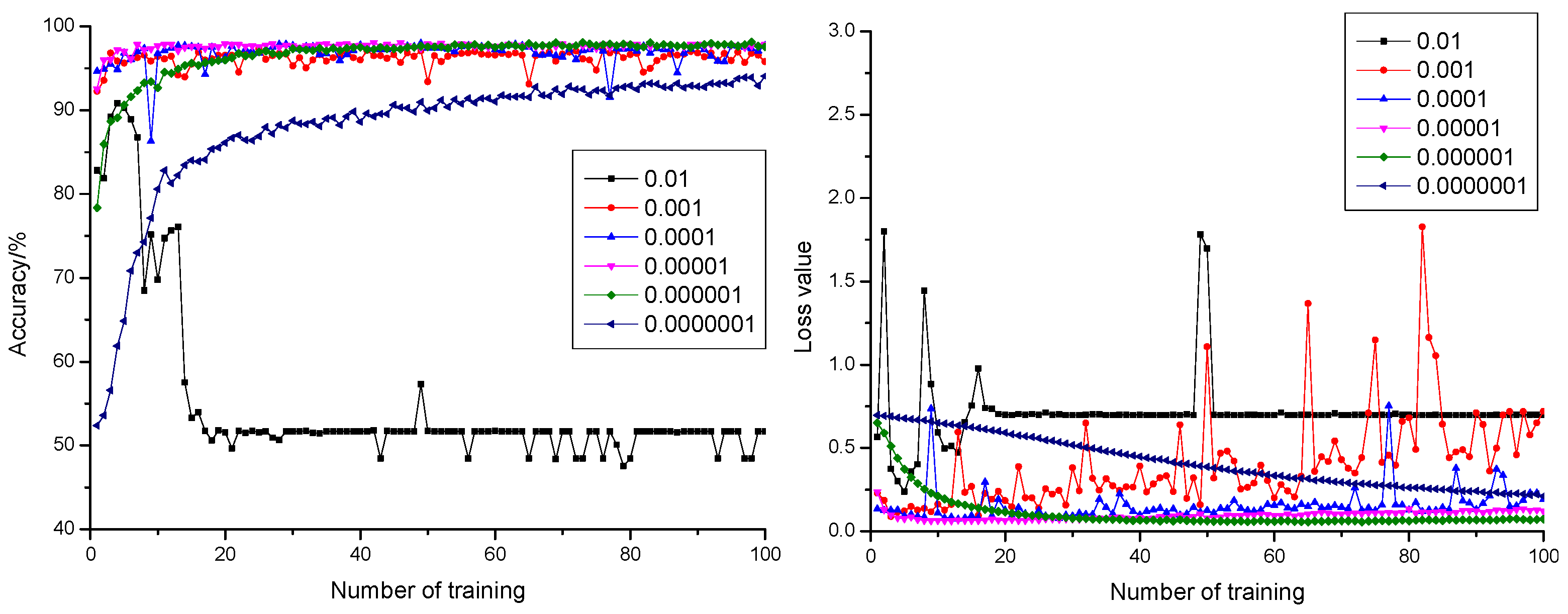
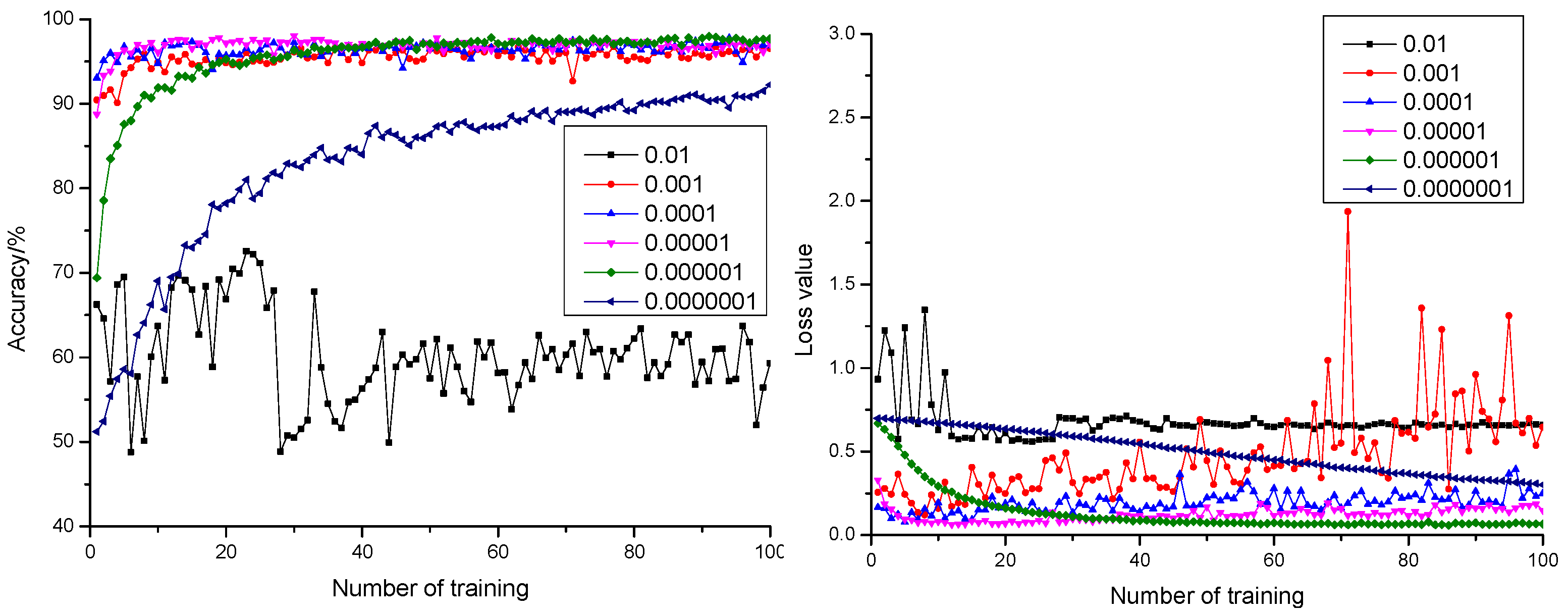
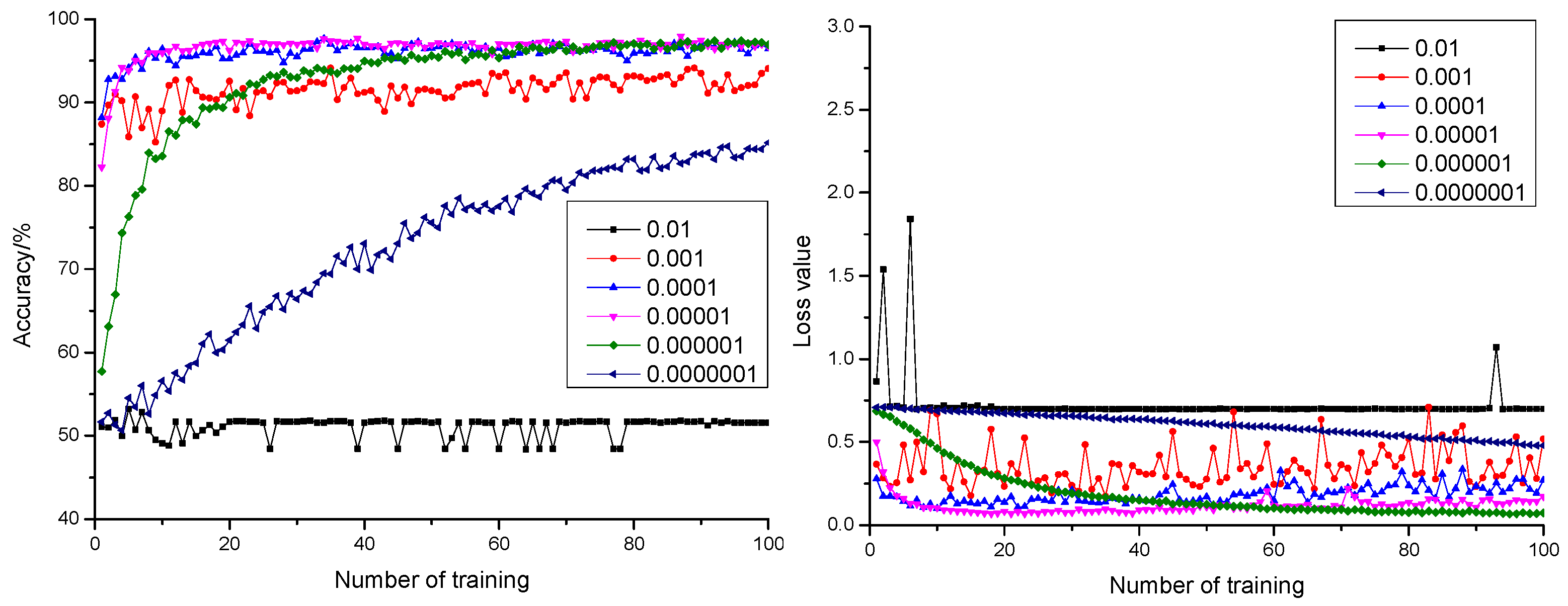
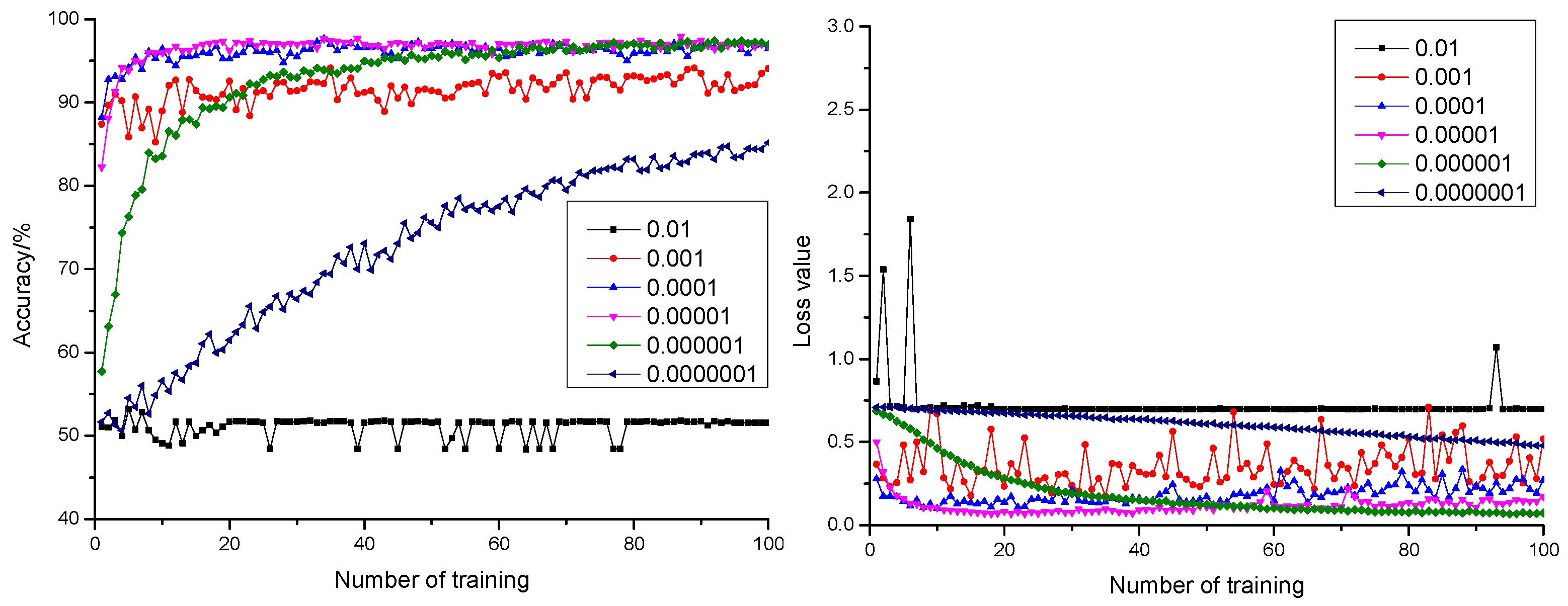
3.1.2. Influence of Learning Rate on the Model
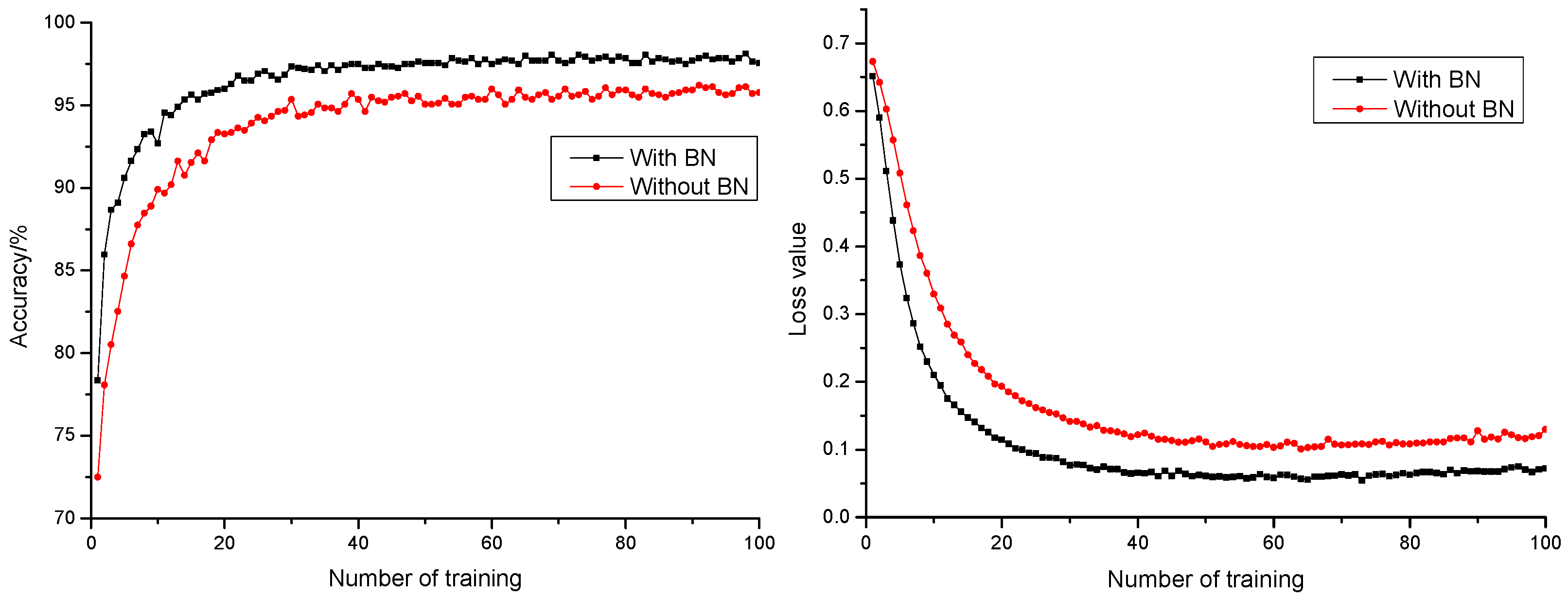
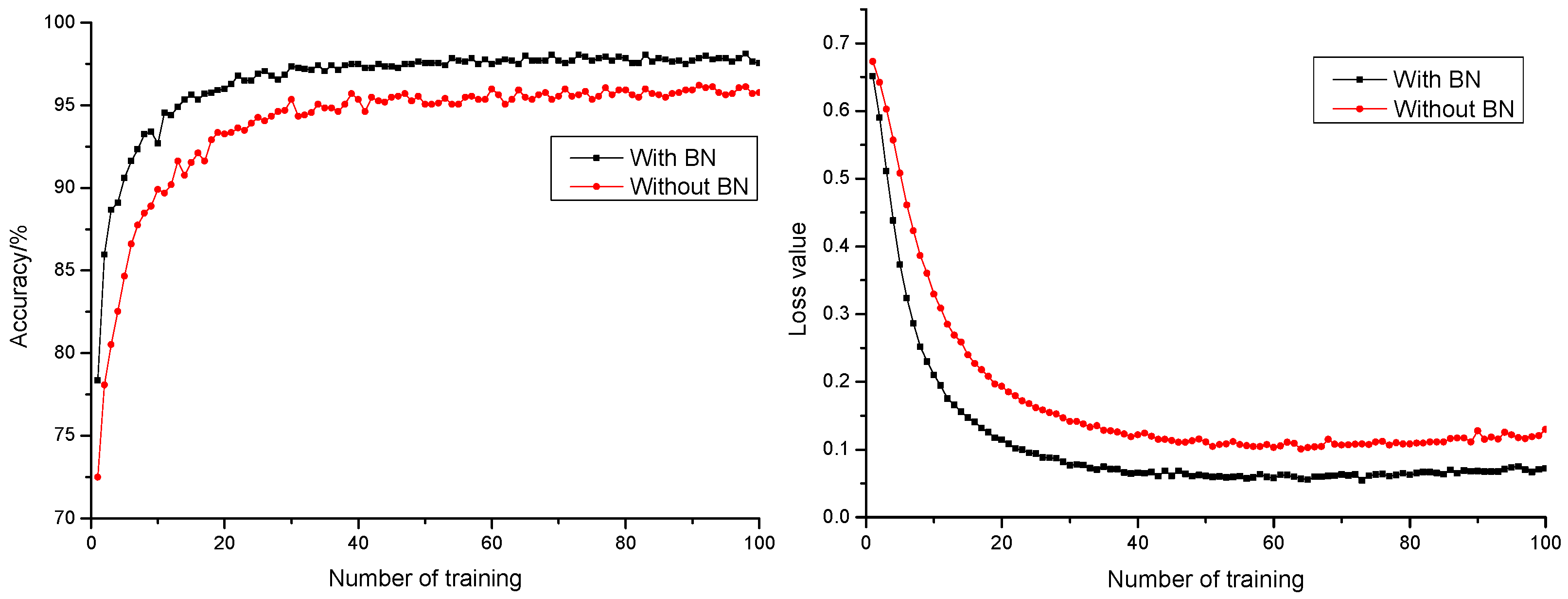
3.1.3. Influence of Batch Normalization Layer on Model Performance
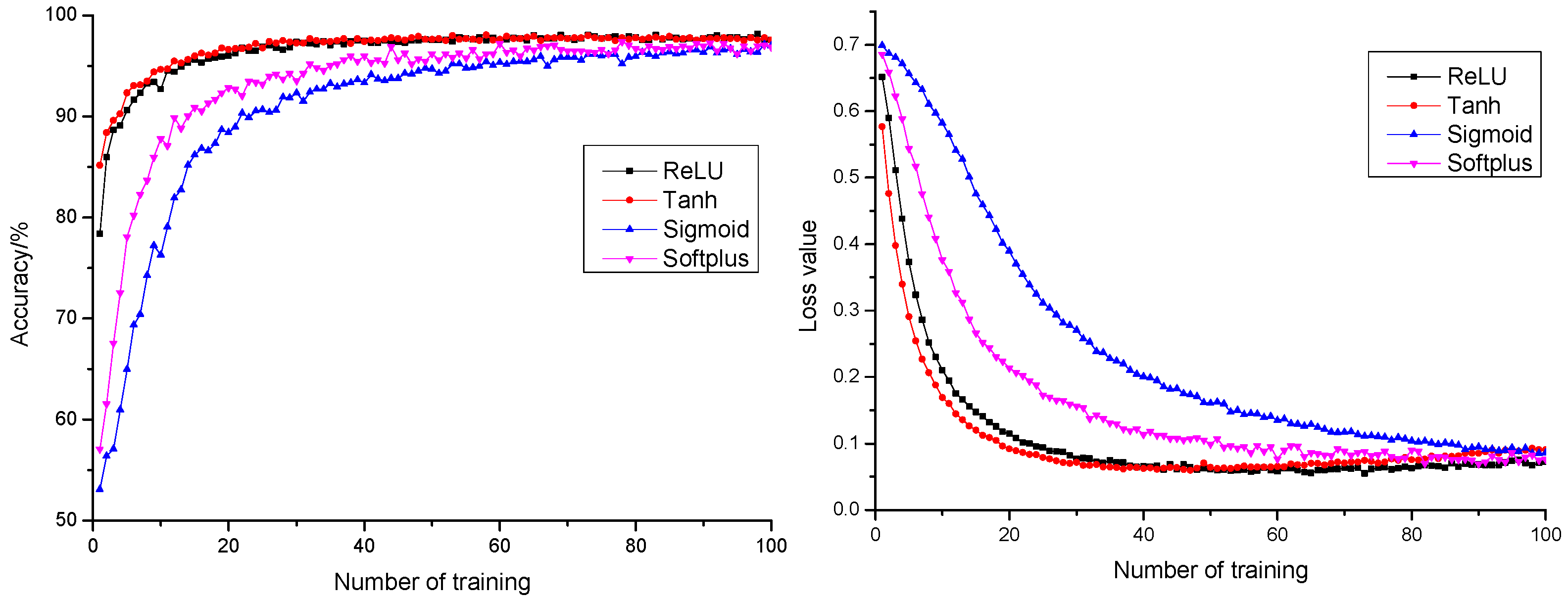
3.1.4. Influence of Activation Function on Model Performance
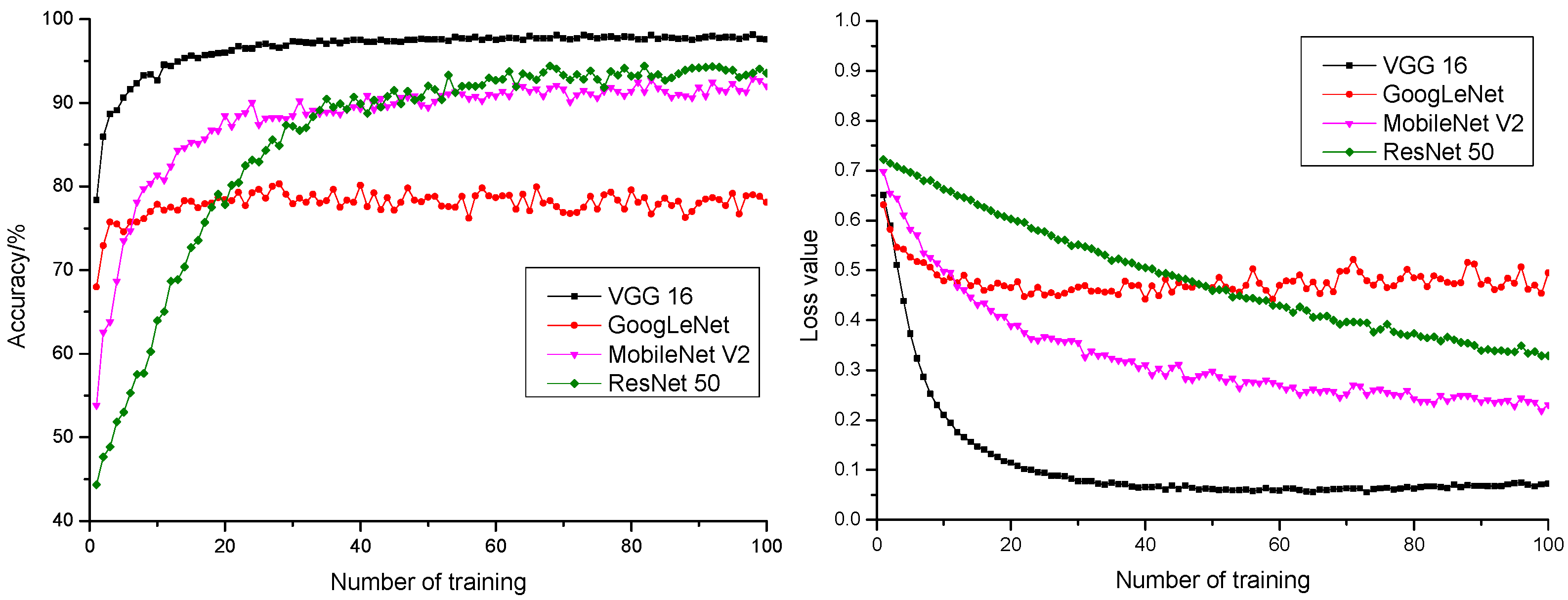
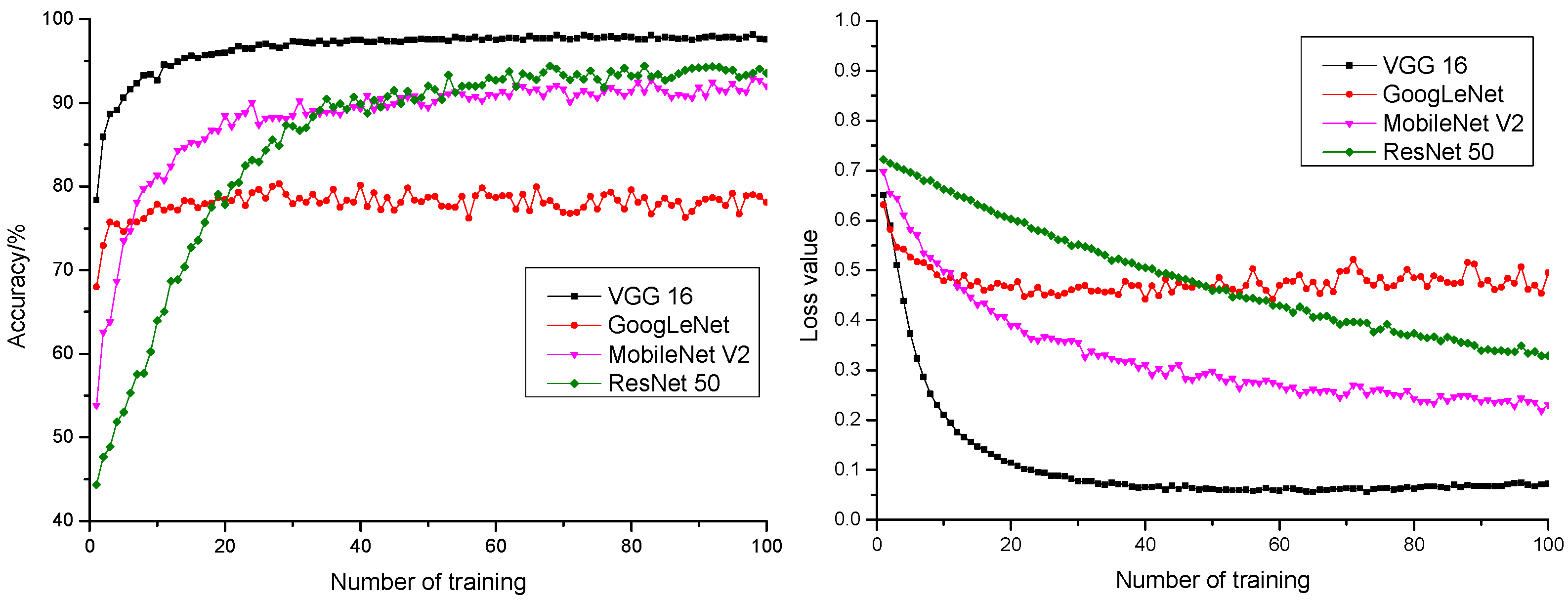
3.2. Model Performance Comparison
4. Discussion
5. Conclusions
- According to the comparison of 18 dropout and learning rate combinations, appropriate configuration of dropout and learning rate under the condition of maintaining stable training could promote generalization performance and training precision of the model. Therefore, the configuration of dropout as 0.3 and learning rate as 0.000001 could realize the highest anticipation precision rate of 98.14% and the smallest anticipation loss value of 0.0669.
- With the addition of a BN layer as a method for model normalization, the model could effectively accelerate network convergence rate, promote the model anticipation precision rate by 1.94%, and reduce the model anticipation loss value by 0.0482. It promoted generalization capability of the model and realized a better and more stable model anticipation performance. With ReLU as activation function, the model had a faster convergence rate. This saved time cost for optimization, which indicated the strong fitting capability of the model.
- A comparison was also conducted with ResNet 50, MobileNet V2, and GoogLeNet models in transfer learning after parameter optimization. It turned out that the VGG 16 model gave the best performance with 100% training precision rate, 98.14% anticipation precision rate, the fastest convergence rate, and stable convergence in anticipation precision rate curve and anticipation loss value curve, as well as the highest anticipation precision rate and the lowest anticipation loss value. Therefore, VGG 16 was more suitable for pepper quality detection.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Zhuang, Y.; Chen, L.; Sun, L.; Cao, J. Bioactive characteristics and antioxidant activities of nine peppers. J. Funct. Foods 2012, 4, 331–338. [Google Scholar] [CrossRef]
- Rong, D.; Rao, X.; Ying, Y. Computer vision detection of surface defect on oranges by means of a sliding comparison window local segmentation algorithm. Comput. Electron. Agric. 2017, 137, 59–68. [Google Scholar] [CrossRef]
- Habib, M.T.; Majumder, A.; Jakaria, A.Z.M.; Akter, M.; Uddin, M.S.; Ahmed, F. Machine vision based papaya disease recognition. J. King. Saud. Univ. Sci. 2020, 32, 300–309. [Google Scholar] [CrossRef]
- Liu, J.; Guo, J.; Patiguli, S.; Shi, J.; Zhang, X.; Huang, H. Discrimination of Walnut External Defects Based on Machine Vision and Support Vector Machine. Food. Sci. 2015, 36, 211–217. [Google Scholar] [CrossRef]
- Zhao, J.; Peng, Y.; Sagar, D.; Zhang, L. On-line Detection of Apple Surface Defect Based on Image Processing Method. Trans. Chin. Soc. Agric. Mach. 2013, 44, 260–263. [Google Scholar] [CrossRef]
- Zhou, F.; Jin, L.; Dong, J. Review of Convolutional Neural Network. Chin. J. Comput. 2017, 40, 1229–1251. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale. In Proceedings of the Image Recognition, IEEE Conference on Learning Representations, San Diego, CA, USA, 10 April 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Representation, Los Alamitos, LA, USA, 10 December 2015. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Christian, S.; Vincent, V.; Sergey, I.; Jonathon, S. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 10 December 2015. [Google Scholar]
- Xiang, Y.; Lin, J.; Li, Y.; Hu, Z.; Xiong, Y. Mango double-sided maturity online detection and classification system. Trans. Chin. Soc. Agric. Eng. 2019, 35, 259–266. [Google Scholar] [CrossRef]
- Caladcad, J.A.; Cabahug, S.; Catamco, M.R.; Villaceran, P.E.; Cosgafa, L.; Cabizares, K.N.; Hermosilla, M.; Piedad, E., Jr. Determining Philippine coconut maturity level using machine learning algorithms based on acoustic signal. Comput. Electron. Agric. 2020, 172, 105327. [Google Scholar] [CrossRef]
- Wang, T.; Zhao, Y.; Sun, Y.; Yang, R.; Han, Z.; Li, J. Recognition Approach Based on Data-balanced Faster R CNN for Winter Jujube with Different Levels of Maturity. Trans. Chin. Soc. Agric. Mach. 2020, 51, 457–463, 492. [Google Scholar] [CrossRef]
- Fan, S.; Li, J.; Zhang, Y.; Tian, X.; Wang, Q.; He, X.; Zhang, C.; Huang, W. On line detection of defective apples using computer vision system combined with deep learning methods. J. Food Eng. 2020, 286, 110102. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; Deng, L.; Han, Z. Intelligent detection of appearance quality of carrot grade using knowledge distillation. Trans. Chin. Soc. Agric. Eng. 2020, 36, 181–187. [Google Scholar] [CrossRef]
- Gao, J.; Ni, J.; Yang, H.; Han, Z. Pistachio visual detection based on data balance and deep learning. Trans. Chin. Soc. Agric. Mach. 2021, in press. [Google Scholar]
- Cao, J.; Sun, T.; Zhang, W.; Zhong, M.; Huang, B.; Zhou, G.; Chai, X. An automated zizania quality grading method based on deep classification model. Comput. Electron. Agric. 2021, 183, 106004. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Z.; Hao, J.; Sun, L.; Li, H.; Han, P. Image recognition of peanut pod grades based on transfer learning with convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2020, 36, 171–180. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, A.; Liu, Y.; Zhang, L.; Xia, Y. Intelligent Fresh-tea-leaves Sorting System Research Based on Convolution Neural Network. Trans. Chin. Soc. Agric. Mach. 2017, 48, 53–58. [Google Scholar] [CrossRef]
- da Costa, A.Z.; Figueroa, H.E.H.; Fracarolli, J.A. Computer vision based detection of external defects on tomatoes using deep learning. Biosyst. Eng. 2020, 190, 131–144. [Google Scholar] [CrossRef]
- Momeny, M.; Jahanbakhshi, A.; Jafarnezhad, K.; Zhang, Y.-D. Accurate classification of cherry fruit using deep CNN based on hybrid pooling approach. Postharvest Biol. Technol. 2020, 166, 111204. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, L.; Zhang, Y.; Shen, Q. Defect Detection Method of Apples Based on GoogLeNet Deep Transfer Learning. Trans. Chin. Soc. Agric. Mach. 2020, 51, 30–35. [Google Scholar] [CrossRef]
- Geng, L.; Xu, W.; Zhang, F.; Xiao, Z.; Liu, Y. Dried Jujube Classification Based on a Double Branch Deep Fusion Convolution Neural Network. Food Sci. Technol. Res. 2018, 24, 1007–1015. [Google Scholar] [CrossRef]
- Li, X.; Ma, B.; Yu, G.; Chen, J.; Li, Y.; Li, C. Dried Jujube Classification Based on a Double Branch Deep Fusion Convolution Neural Network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 223–232. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ding, F.; Liu, Y.; Zhuang, Z.; Wang, Z. A Sawn Timber Tree Species Recognition Method Based on AM-SPPResNet. Sensors 2021, 21, 3699. [Google Scholar] [CrossRef]
- Luo, Z.; Yu, H.; Zhang, Y. Pine Cone Detection Using Boundary Equilibrium Generative Adversarial Networks and Improved YOLOv3 Model. Sensors 2020, 20, 4430. [Google Scholar] [CrossRef] [PubMed]
- Rong, D.; Wang, H.; Xie, L.; Ying, Y.; Zhang, Y. Impurity detection of juglans using deep learning and machine vision. Comput. Electron. Agric. 2020, 178, 105764. [Google Scholar] [CrossRef]
- Kozłowski, M.; Górecki, P.; Szczypiński, P.M. Varietal classification of barley by convolutional neural networks. Biosyst. Eng. 2019, 184, 155–165. [Google Scholar] [CrossRef]
- Wu, H.; Gu, X. Towards dropout training for convolutional neural networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Hou, J.; Yao, E.; Zhu, H. Classification of Castor Seed Damage Based on Convolutional Neural Network. Trans. Chin. Soc. Agric. 2020, 51, 440–449. [Google Scholar] [CrossRef]
- Rauf, H.T.; Lali, M.I.U.; Zahoor, S.; Shah, S.Z.H.; Rehman, A.U.; Bukhari, S.A.C. Visual features based automated identification of fish species using deep convolutional neural networks. Comput. Electron. Agric. 2019, 167, 105075. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Theivaprakasham, H. Identification of Indian butterflies using Deep Convolutional Neural Network. J. Asia-Pacif. Entomol. 2021, 24, 329–340. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, H.; Luo, X.; Xu, J. Research process on batch normalization of deep learning and its related algorithms. Acta. Automatica. Sin. 2015, 71, 1–10. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q. Design and Implementation Based on Color Feature Extraction of Pepper Automatic Classification System. Master’s Thesis, Jilin University, Changchun, China, 2013. [Google Scholar]
- Cui, C. Pepper External Quality Detection Technology Based on Machine Vision. Master’s Thesis, Jilin University, Changchun, China, 2013. [Google Scholar]
- Ren, R.; Zhang, S.; Zhao, H.; Sun, H.; Li, C.; Lian, M. Study on external quality detection of pepper based on machine vision. Food. Mach. 2021, 37, 165–168. [Google Scholar] [CrossRef]
- Nasiri, A.; Taheri-Garavand, A.; Zhang, Y.-D. Image-based deep learning automated sorting of date fruit. Postharvest Biol. Technol. 2019, 153, 133–141. [Google Scholar] [CrossRef]
- Behera, S.K.; Rath, A.K.; Sethy, P.K. Maturity status classification of papaya fruits based on machine learning and transfer learning approach. Inf. Process. Agric. 2020, 5, 1–7. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment Code | Learning Rate | Dropout | Precision Rate in Training | Anticipation Precision Rate | Loss Value in Training | Anticipation Loss Value |
|---|---|---|---|---|---|---|
| 1 | 0.01 | 0.3 | 90.64% | 90.83% | 0.293 | 0.2997 |
| 2 | 0.5 | 70.92% | 72.56% | 0.5714 | 0.5616 | |
| 3 | 0.7 | 50.28% | 53.22% | 0.8628 | 0.7067 | |
| 4 | 0.001 | 0.3 | 99.97% | 97.35% | 0.0017 | 0.1388 |
| 5 | 0.5 | 99.48% | 96.78% | 0.0279 | 0.3399 | |
| 6 | 0.7 | 95.92% | 94.13% | 0.1659 | 0.1731 | |
| 7 | 0.0001 | 0.3 | 100.00% | 97.99% | 0.0001 | 0.1152 |
| 8 | 0.5 | 100.00% | 97.78% | 0.0001 | 0.1723 | |
| 9 | 0.7 | 99.91% | 97.64% | 0.0049 | 0.1331 | |
| 10 | 0.00001 | 0.3 | 100.00% | 98.07% | 0.0001 | 0.0808 |
| 11 | 0.5 | 100.00% | 98.07% | 0.0001 | 0.0984 | |
| 12 | 0.7 | 100.00% | 97.99% | 0.0002 | 0.1193 | |
| 13 | 0.000001 | 0.3 | 100.00% | 98.14% | 0.00001 | 0.0669 |
| 14 | 0.5 | 100.00% | 97.99% | 0.0012 | 0.0647 | |
| 15 | 0.7 | 99.88% | 97.42% | 0.0172 | 0.0732 | |
| 16 | 0.0000001 | 0.3 | 95.28% | 94.05% | 0.1933 | 0.2106 |
| 17 | 0.5 | 92.82% | 92.26% | 0.2844 | 0.2996 | |
| 18 | 0.7 | 85.17% | 86.35% | 0.4779 | 0.4655 |
| Model | Precision Rate in Training | Anticipation Precision Rate | Loss Value in Training | Anticipation Loss Value |
|---|---|---|---|---|
| VGG 16 | 100.00% | 98.14% | 0.0001 | 0.0669 |
| GoogLeNet | 98.13% | 80.30% | 0.0692 | 0.4541 |
| MobileNet V2 | 92.82% | 92.91% | 0.2258 | 0.2357 |
| ResNet 50 | 96.47% | 94.41% | 0.3079 | 0.4001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, R.; Zhang, S.; Sun, H.; Gao, T. Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network. Sensors 2021, 21, 5305. https://doi.org/10.3390/s21165305
Ren R, Zhang S, Sun H, Gao T. Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network. Sensors. 2021; 21(16):5305. https://doi.org/10.3390/s21165305
Chicago/Turabian StyleRen, Rui, Shujuan Zhang, Haixia Sun, and Tingyao Gao. 2021. "Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network" Sensors 21, no. 16: 5305. https://doi.org/10.3390/s21165305
APA StyleRen, R., Zhang, S., Sun, H., & Gao, T. (2021). Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network. Sensors, 21(16), 5305. https://doi.org/10.3390/s21165305