1. Introduction
Nowadays, data are considered a valuable asset generating massive investments. However, how much data should autonomous vehicles collect to generate a reasonable driving model? Currently, Waymo has a fleet composed of around 55 vehicles driving over 1 million kilometres per year, roughly corresponding to 30,000 h. This number roughly corresponds to the driving hours of one taxi driver in their entire work life. The collected data cover most of the common scenarios, different illumination conditions, and weather, but still not enough to allow completely safe driving [
1]. An autonomous road vehicle is expected to encounter a large variety of environmental conditions which might be difficult to take into account fully during the development of its perception modules. Furthermore, the occurrence of specific situations may be rare, and for this reason, hard to grab in a dataset. Increasing the size of the dataset, increases, in turn, the probability of encountering rare events; however, it does not guarantee to assign their proper relevance. Single events may be considered as outliers, and, for this reason, the overall network may perform poorly in such situations.
In this paper, we differentiated the datasets for testing and training our networks by illumination condition (day and night), and by weather conditions (sunny and rain), demonstrating that data fusion techniques and semi-supervised learning may help in segmenting objects in such conditions, showing how the availability of big quantities of data, including non-annotated scenes, can improve the performance of AI-based algorithms. Specifically, it is important to point out that these classes may be strongly unbalanced as sunny days may be better represented in the dataset than rainy nights. For instance, the task of segmenting vehicles or people presents intrinsic difficulties, because all classes of objects during the day, are very well represented in the dataset, whereas some classes, such as people in rainy nights, are more rare (for obvious reasons), but remain important to detect with high confidence.
Our paper thus contributes to the body of knowledge in this field, investigating how sensor fusion and semi-supervised learning can be used to increase the overall performance of the network with a particular emphasis on uncommon events and challenging scenarios. The objective was to carry out a fair evaluation, also using cross validation, of the techniques and how they can be used to improve machine learning in autonomous driving. The study investigated and integrated two lines of research: the use of an individual sensor setup versus sensor fusion, and how to use semi-supervised learning to improve overall network performance using unlabelled data coming from one of the sensors—in this case, the RGB camera or the lidar. It is not in the scope of the present paper to beat the current benchmarking in object segmentation, but to show readers how fusion and semi-supervised learning can be used to improve performance in AI algorithms. However, the results suggest significant segmentation capability improvement in night and in rainy conditions, ranging from 10 to 30 percentage points.
To achieve this goal, we trained different models in a supervised fashion, with data fusion and semi-supervised learning. The supervised learning technique was used to train a baseline model and an upperbound model was used for comparison. The expected result is that the upperbound model would be the best performing one, benefiting from the full knowledge of the full dataset with data annotation. However, acquiring real-world scenarios with full data annotation is not always achievable, especially in tasks such as autonomous driving. Thus, this paper shows that semi-supervised learning and co-training achieve comparable performance (about 2–3 percent points difference) using less data annotations. An additional point of discussion is the cross-validation on different data splits. In this study, we trained 10 different models for each train–validation–test to show the variance in the test results.
This paper is organized as follows:
Section 2 introduces the reader to the topic, offering a review of the state of the art, including recent studies about sensor fusion and semi-supervised learning. The materials and datasets used for this study are thoroughly explained in
Section 3, including the Waymo dataset used for this research.
Section 4 addresses our method for building the neural networks, training, validation and testing modalities. Finally, our results are reported in
Section 5 including a comparison with our previous method, and a discussion of our main findings.
2. Related Work
Most of the state-of-the art methods for autonomous driving involve data-driven techniques at various levels, among which deep neural networks are shown to be promising in solving scene interpretation problems. Working on improving scene interpretation, this paper is focused on the intersection of two problems: sensor fusion and semi-supervised learning. Both topics have been extensively explored in the literature.
Semi-supervised learning is a widely explored idea for exploiting the availability of big unlabelled datasets to train various types of neural networks. In a recent review [
2], Van Engelen et al. explored the topic from a broad non-task-specific perspective. Despite the fact that the idea of semi-supervised learning is applicable in different ways, and for several sources of information, images classification and semantic segmentation are the most historically used. Ouali et al. [
3] used labelled data to train the main encoder–decoder-based network for semantic segmentation using the PASCAL VOC dataset [
4]. The unlabelled data were used in a second stage to train the same network with the addition of auxiliary decoders, and perform a consistency check between the main decoder and the auxiliary decoders. The potential of semi-supervised learning was also used in [
5] to build a network for semantic segmentation where strong pixel-level annotation is only available for part of the dataset, and weak annotation (image-level) is available for the remaining part of the dataset. The semantic segmentation generated on the weakly annotated images was used to train the overall network. Also in this case, the examples were taken from the PASCAL VOC dataset. The main driver for semi-supervised learning was to reduce the cost of labelling [
6], which is time-consuming and intensive work.
Focusing on the task of autonomous driving, [
7] offered a review of methods and datasets, indicating the increment in labelling efficiency, transfer learning, semi-supervised learning, etc., as open questions for research to leverage lifelong learning by updating networks with continual data collection instead of re-training from scratch. One example of application is provided in [
8], where a semi-supervised learning method that uses labelled and unlabelled camera images to improve traffic sign recognition is proposed. The semi-supervised learning is also used in [
9], where Zhu et al. define a
teacher model which is trained in a supervised manner using labelled camera images. Then, the teacher was used to generate labels on an unlabelled dataset which was used to train a
student model. The authors show that the student model outperformed the teacher model using the data from the Cityscapes [
10], CamVid [
11] and KITTI [
12] datasets.
As autonomous vehicles nowadays are integrated with different sensors, 3D lidar data are also used for semantic segmentation. A review work explores the available datasets and emphasises the importance of the availability of big quantities of labelled data coming from 3D lidar that are expensive to label manually, though strongly needed for autonomous driving [
13]. A method to achieve the task of semi-supervised learning using 3D lidar data is described in [
14], in which a set of manually labelled data and pairwise constraints are used to achieve an improvement in performance.
In addition to many techniques for extracting relevant information from camera or lidar data individually, data fusion is a growing trend to integrate the information coming from both sensors to improve each other in segmentation performance. In [
15], the authors offer a review of different methods for sensor fusion perception in autonomous driving using deep learning techniques, focusing on fusion as a means for solving visual odometry, segmentation, detection and mapping issues, pointing out in their conclusion of how adverse weather can affect overall performance. A focused review on sensors’ performance under adverse weather conditions can be found in [
16], in which the authors better describe the individual strengths and limitations of sensors in the automotive field, providing a comprehensive list of data-driven methods and an open dataset. However, the literature is rich in approaches to sensor fusion that use classical stochastic inference instead of neural networks. For instance, in [
17], the author generalizes the approach in [
18] with the objective to obtain quality-fused values from multiple sources of probabilistic distributions in which quality is related to the lack of uncertainty in the fused value and the use of credible sources. On a different research line, the authors in [
19] addressed the problem of sensor fusion and data analysis integration with emerging technologies and described several classic methods for sensor fusion, such as Kalman filtering and Bayesian inference. The strengths of these methods reside in their simplicity and the high level of control they offer over the design process, with the drawback of low flexibility and adaptability. On the contrary, convolutional neural networks have demonstrated high flexibility and adaptability to input variations, with the drawback of losing control over the design process—as CNNs are, essentially, black boxes.
Among many dedicated techniques of lidar camera fusion that can be found in the literature, a relevant example is described in [
20], where Li et al. defined the so-called “BiFNet” as a bidirectional network for road segmentation that uses camera image and lidar eye-bird view. In [
21], a lidar–camera cross fusion technique was presented, showing an increment in performance using the fusion technique over an individual sensor on the KITTI dataset, and later extended using the co-training method that included labelled and unlabelled examples [
22].
5. Results and Discussion
The model detailed in
Section 4.1 was trained on the 10 random dataset splits
, described in
Section 4.2, and extracted from the Waymo dataset (see
Section 3.1 for more details). The full training procedure is outlined in
Section 4.
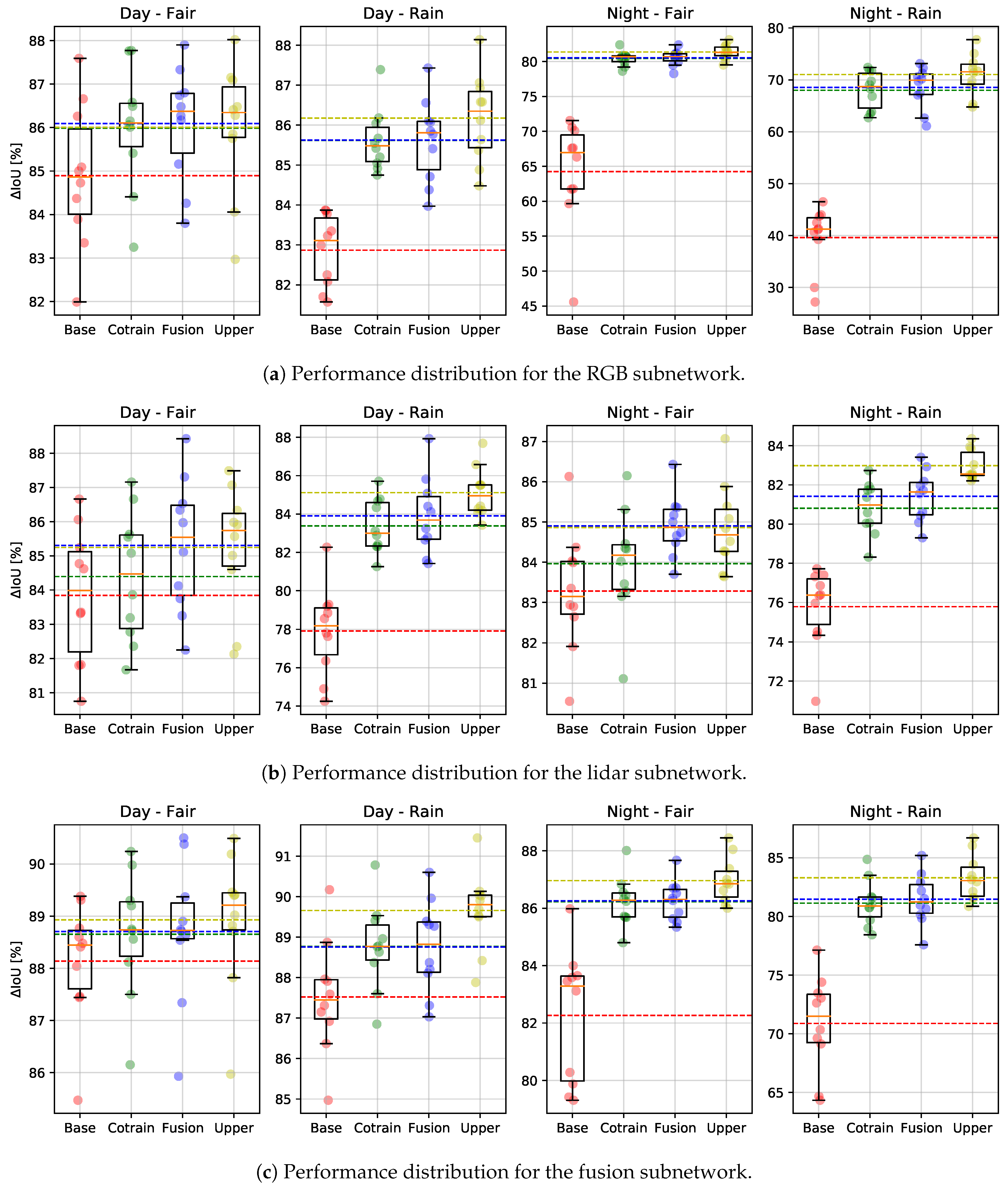
Furthermore, training the model more times provides a reliable result in terms of repeatability, as individual training bouts may perform differently according to different conditions in data-loading randomization, dropout layers and weights initialization. The results on the test sets are summarized in
Table 3 and in
Figure 3.
5.1. Supervised Baseline
The supervised baseline models were trained as described in
Section 4.4 using only sequences collected in day-time and fair weather conditions. As can be seen in
Table 3, the fusion subnetwork performs significantly better than the single modality subnetworks in both the day–fair and day–rain categories. However, the lidar subnetwork performs best in the night-time categories where the performance of the camera subnetwork drops significantly. The fact that the lidar subnetwork performs better than the camera one at night-time is not surprising considering that the lidar is an active sensor. The fusion subnetwork also has access to the lidar input, so its poor performance in night-time sequences is an indication that, during training, it has learned to rely too strongly on the camera-based features. Another interesting result is that the lidar subnetwork performance is negatively affected by rainy weather. As shown in two examples in
Figure 1, the water covering the surrounding surfaces degrades the density, and possibly the quality, of the point clouds captured with the lidar.
5.2. Co-Training
Co-training shows slight improvements for day–fair weather data, which is expected as full information content already provides reliable results for the supervised baseline. The improvement using the co-training approach with respect to the baseline is higher in case of night–fair data than day–light data. Here, the performance is over 80% accuracy in almost all generated models, showing an improvement in the camera-based network case of about 15 percent points. The only case in which the performance is lower, but still a big improvement with respect to camera data baseline, is the night–rain scenario, in which the performance against the baseline increases in all cases ranging between 5 percent points, in the lidar case, to almost 30 points, in the camera case.
5.3. Fusion-Based Semi-Supervised Learning
Result from
Table 3 for semi-supervised fusion and co-training are fully comparable, with only little difference in all scenarios. In most of the cases, fusion seems to outperform the co-training on average, with some cases in which the opposite happens. The variance, however, shows that co-training seems to be more stable, showing lower variance in many cases. In all cases, there is an improvement that is more significant in the case of night and rainy weather and even comparable to the upperbound.
An important observation is that the upperbound model clearly shows the best performance in all cases, which is not a surprise. It is well known that the availability of large quantities of well-annotated data is a fundamental issue, and the best performance is achieved with increased information availability. However, real-world cases show that this is not always possible, achievable or cost-effective. This result shows that co-training and semi-supervised learning can help to fill this gap, and in some cases even over-performing on the upperbound model, for example, in the case of night–fair lidar data. It is reasonable to expected that semi-supervised learning and co-training would surpass the upperbound model if more data were available.
5.4. Cross-Validation
The results in
Table 3 also show the variance across several models trained under the same conditions but on different data splits (as described in
Section 4.1). Using cross-validation, these results confirm that fusion and co-training have similar performance improving the baseline performance, reaching the upperbound-level performance.
Figure 3b shows the performance for each subnetwork (RGB, lidar and fusion) of each data split, the average accuracy and the variance. From
Figure 3a, one can observe that in the day–fair case, the camera performances are comparable in all cases (baseline, co-training, fusion and upperboud), while fusion and co-training clearly help in rain and night for all data splits. The same behaviour can be seen in
Figure 3b for the lidar sub-network, though showing (as expected) better performance during night-time. Finally,
Figure 3c shows the performance distribution over all the data splits for the fusion sub-network.
5.5. Discussion
The purpose of the experiments proposed in
Section 5 is three-fold: (1) to evaluate the potential benefits of using a multi-sensor system over single modality approaches; (2) to investigate the model generalization capabilities to more challenging domains; and (3) to evaluate whether co-training and our newly introduced fusion-based strategy could be useful for domain adaptation.
According to the results shown in
Section 5, several potential benefits support the use of semi-supervised learning, sensor fusion and co-training strategies. First, a multi-sensor system is shown to provide high reliability and redundancy, for all the cases reported in
Table 3 in which sensor-fusion outperforms the single-sensor approach (RGB camera or lidar). Second,
Table 3 also shows that co-training and semi-supervised learning help the model to generalize better to more challenging domains. The best improvement in the semi-supervised learning techniques is shown in the night–rain case with an over 10 percent points IoU performance increase, starting from
IoU accuracy of the fusion baseline, and reaching
in the fusion-semi case.
The use of non-annotated data has clearly been shown to improve the overall performance, resulting in big savings in practical applications where data annotation is a heavy and complex task. However, data annotation cannot be neglected, the upperbound model is shown to be the best performing one, and hence full data annotation is still the best way to achieve high reliability and stability in neural networks.
6. Conclusions and Future Work
In conclusion, this paper offered a comparative study that analysed two semi-supervised methods of sensor fusion techniques for lidar–camera data in deep learning, showing a comparison among different networks’ performance, the baseline model and a supervised upperbound model. Our results confirm the overall trend that the semi-supervised method could boost performance, taking advantage of the availability of a big un-annotated dataset. The paper shows that the upperbound model performance level can be reached using other methods such as semi-supervised learning and co-training, resulting in a cost-effective method that uses less data annotation. This result is supported by a cross-validation using 10 different data splits. Furthermore, the statistical analysis on single model training shows how benchmarking in autonomous driving could be affected by randomization in individual training.
Future work could extend the analysis over different conditions including additional subcategories in which deep learning in autonomous driving performance still suffers from the availability of data such as adverse weather-related data.







{kind=link}
{kind=link}
{kind=link}