1. Introduction
Depression is one of the most severe mental disorders worldwide, which can severely affect people’s daily lives. There are still many debates about the causes of depression, but the three main causes are psychological, genetic, and social and environmental problems. As numerous people suffer from depression worldwide, it has become important to detect depression using computer-aided methods. The detection of depression is a challenging task as many of its symptoms are widely distributed in ages, gender, regions, and cultures. The limitations in the detection of depression using computer-aided methods necessitate the development of more effective methods to accomplish this task. In recent years, numerous approaches have been proposed to automatically detect the levels of depression.
Recently, many computer-aided methods, especially deep learning (DL)-based methods, have been proposed to estimate depression levels. Concretely, DL models take data collected from people suffering from depression as input and then output predicted results. These data collected from patients include videos, audio, texts, and other information, which can be perceived as different modalities. Although many contributions have been made in the field of depression detection, many unresolved issues still exist. First, the data used in detecting depression are generally rather long in temporal dimension as depression cannot be detected in a short time. However, processing long-term sequences has always been a challenge in DL [
1]. Recurrent neural networks (RNNs) have been widely used for the extraction of temporal information to detect depression in the past few years [
2,
3,
4], including the baseline model provided by the Detecting Depression with AI Sub-challenge (DDS) [
5] which is one of the challenges in the AVEC 2019 [
5]. Traditional RNN structures, including long short-term memory (LSTM), bi-directional LSTM (Bi-LSTM), and gated recurrent units (GRUs), can effectively process short-term time sequences. However, they cannot satisfactorily process long-term sequences. As the length of sequences increases, the performance of RNNs rapidly decreases due to the forgetting problem. The forgetting issue of RNNs means that RNNs will lose the primary information when reading later series at the scenario of processing long-term sequences. Second, there have always been various fusion approaches to fuse information from different modalities, early fusion and late fusion for example. It has been proven that multi-modal learning can improve the performance of depression detection in recent research [
2,
6,
7]. However, many proposed DL-based methods train their models in a simple multi-modal manner, ignoring the differences in the contribution of different modalities.
In this study, we have proposed a multi-modal adaptive fusion transformer network to address these two challenges mentioned above. For the first challenge, a transformer model [
8] has been proposed to process long-term sequences while effectively handling the forgetting issue. To the best of our knowledge, this is the first application of the transformer method for depression detection. For the second challenge, it is important to weight modalities as they have different contributions to the final results. Thus, we proposed an adaptive late-fusion strategy to fuse results from different modalities adaptively. In the Adaptive Late-Fusion strategy, we will increase the weights of effective modalities or features, while lessening the weights of ineffective modalities or features. Identifying which modalities or features are effective is also one of purposes of our research, which will be shown in
Section 5.3. In addition, we employ a multi-task representation learning strategy in our work as many current research studies [
3,
9] have proven that multi-task learning can positively contribute to depression detection. Therefore, in this study, we apply multi-modal learning and multi-task learning to the transformer-based network to detect depression on the AVEC 2019 DDS Challenge dataset [
5].
The remainder of this paper is organized as follows.
Section 2 summarizes the related works.
Section 3 describes the details of the proposed network.
Section 4 presents experiments with corresponding results in
Section 5.
Section 6 presents the discussions. Finally,
Section 7 concludes the paper.
3. Proposed Technologies
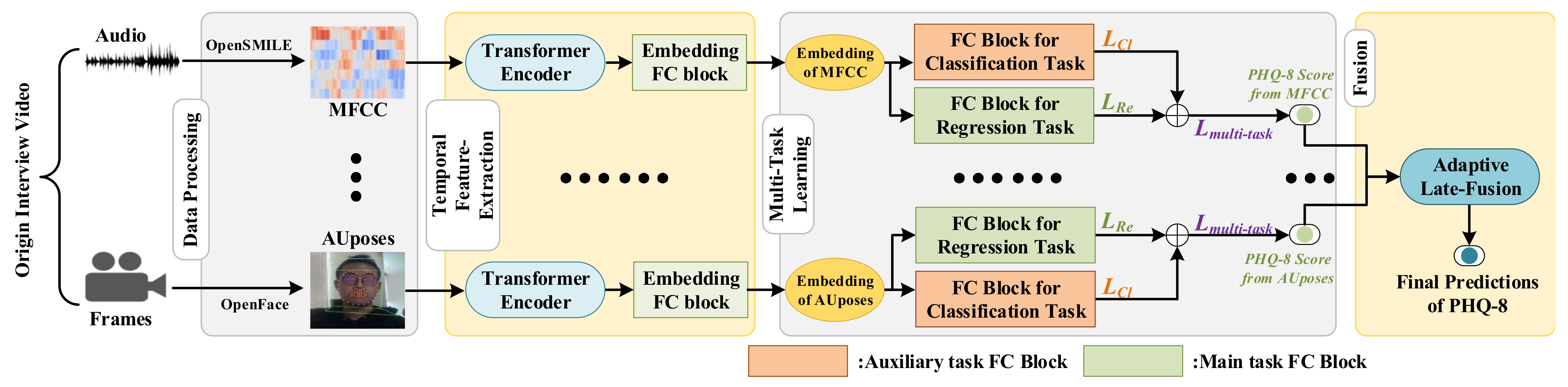
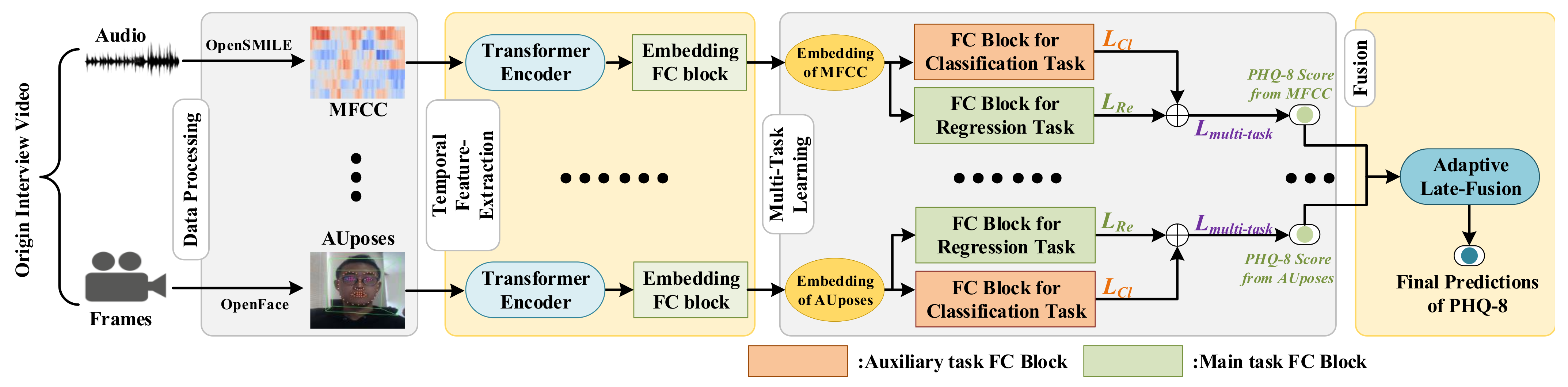
In this section, we first show an overall description of our multi-modal adaptive fusion transformer network and then provide a detailed description of the Transformer Encoder module, encoding the time series data from each modality. Subsequently, we elaborate on how our multi-task methods use a multi-task representation learning network for PHQ-8 regression and 5-class classification. Finally, we fuse acoustic and visual modalities in Adaptive Late-Fusion to conduct the final depression level prediction. The architecture of the proposed method is presented in
Figure 1.
To illustrate the effectiveness of the transformer model in the depression detection, we employ the Transformer Encoder to extract temporal information. After features from every modality are processed by the
Transformer Encoder and the
Embedding FC Block presented in
Figure 1, they are fed to two
FC Blocks designed for multi-task learning, which will be later described in more detail in the
Section 3.3.
3.1. Input Stream
In the AVEC 2019 DDS Challenge dataset, two main modalities can be obtained, namely, audio and video modalities. Each modality type contains several kinds of features, such as MFCC from audio and AUposes from video, which can be obtained by the methods provided by the AVEC 2019 DDS Challenge. For every type of feature obtained from the AVEC 2019 DDS Challenge dataset, the model is independently trained. The results obtained from each type of feature are fused in the independent stage called Adaptive Late-Fusion. For every type of feature, the transformer model is designed to extract temporal information, and its detailed structure will be described in the next section, i.e., Transformer Encoder. Suppose pre-processed features have the shape of , where bs standard is the batch size, t standard is the temporal frames, and d standard is the feature dimension. After they have been processed by the Transformer Encoder, the features with the shape of are averaged in the temporal t dimension to obtain the shape of . The averaged features are fed to the Embedding FC Block to obtain features with the same dimension, which are treated as hidden embeddings representing every feature from each modality. Each FC Block consists of a rectified linear unit (ReLU) activation layer, a dropout layer, and a linear layer. The dropout layer in the FC Block is designed to overcome overfitting during training. The hidden embeddings are finally passed to the two FC Layer Blocks to perform predictions on two tasks: PHQ-8 regression and 5-class classification. After the results from each modality’s feature are obtained, we employ Adaptive Late-Fusion to obtain the final prediction results in terms of the PHQ-8 scores.
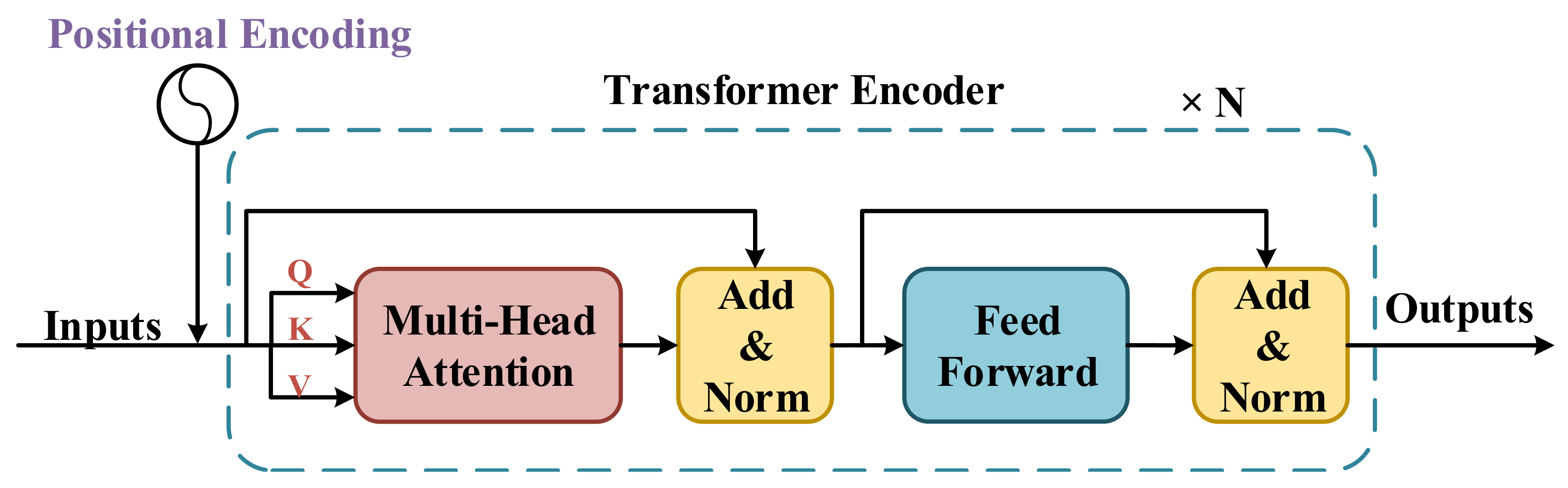
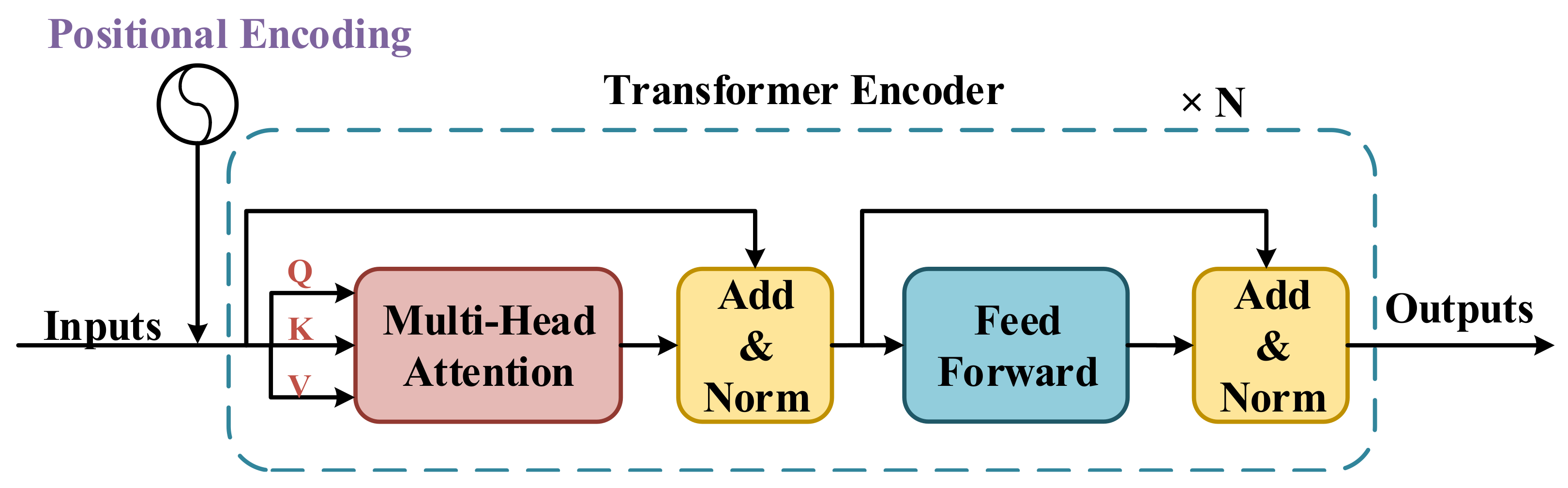
3.2. Transformer Encoder
The Transformer Encoder structure employed in this work has been detailed in
Figure 2. Following [
8], we use the naive Transformer Encoder structure, along with the Positional Encoding module, Multi-head Attention module, and Feed-Forward module in our work. In both the Multi-head Attention and Feed-Forward modules, data streams are designed as a shortcut structure with additive and normalization operations. An entire single Transformer Encoder layer architecture is repeated by
N times to form a complete Transformer Encoder. Before being fed to the Transformer Encoder, input streams are processed by the Positional Encoding module to alter the positional information. Before being fed into the Multi-head Attention module, an input stream will be independently mapped to three sub-streams represented as
Q,
K, and
V, respectively. Then, the Multi-head Attention module will perform global self-attention from
Q,
K, and
V. If the head number of the Multi-head Attention module is greater than one, the Multi-head Attention module will perform the self-attention in different temporal scales. The Feed-Forward module is a simple feed-forward structure composed of two fully connected layers.
The Positional Encoding (PE) module is used to add positional information to the original input. The Positional Encoding model is important because the Transformer Encoder has a pure attention structure without any positional information. We use the same positional encoding method as [
8], whose formula is shown in Equation (
1):
where
denotes the position (i.e., 0, 1, 2, ...) of every frame in features;
i denotes the indices of elements in every single frame; and
denotes the dimension of input features.
The Self-Attention module is designed to map a query (
) and a set of key (
)-value (
) pairs to an attention value (
). The
,
,
are represented as Equation (
2):
where
represents the origin inputs, while
,
, and
denote the query vector, key vector and value vector, respectively. Suppose the dimensions of
,
,
are
, respectively.
are linear transform matrices for
,
,
, respectively, which are learned to find best
,
,
during the training process.
In self-attention, we first calculate the similarity between
and
as Equation (
3):
where
is a similarity matrix or score matrix with a dimension of
. Its element
can be represented as:
where
and
are
j-th element of
and
i-th element of
, respectively. We use softmax to normalize
as:
The attention value (
) for
can be represented as:
where
is the
i-th element of
. The
can be represented as:
where
is the normalized similarity matrix, whose element is
.
The final Feed-Forward module is made up of two fully-connected layers whose hidden units can be specified as hyperparameters.
3.3. Multi-Task Learning
Inspired by current multi-task learning works, we incorporate an auxiliary task (depression classification) to enhance the main task of depression level regression (estimation). To achieve the purpose of multi-task learning, after the features are processed by the Embedding FC Block, the hidden embedding for each type of feature will be fed to two FC Blocks to separately perform two tasks, i.e., PHQ-8 regression and 5-class classification. The FC Blocks comprise of an ReLU activation, a dropout layer, and a linear layer. Since we can only achieve the original PHQ-8 regression task using the AVEC 2019 DDS Challenge dataset, we generate 5-class classification labels from the original PHQ-8 score labels, as detailed in the Data Processing section.
Our multi-task loss function in the training stage can be formulated as:
where
and
are loss functions for PHQ-8 regression and 5-class classification, respectively.
a and
b in Equation (
8) are designed to leverage the coefficient between these two tasks and can be set as hyperparameters. Specifically, the loss function for PHQ-8 regression can be formulated as follows:
where
and
y denote the predicted depression levels and true labels with
and
denoting their corresponding mean values,
and
denote the variances of
and
y and
means the covariance of them. We employ the commonly used cross-entropy loss as the loss function of our 5-class classification task, which is shown as follows:
where
C denotes the number of classification classes;
N, the number of samples;
, a binary indicator; and
, the predicted probability that sample
i belongs to class
c.
3.4. Adaptive Late-Fusion
To fuse results from different modalities and adjust weights for each type of feature adaptively, we employ the proposed late-fusion strategies called Adaptive Late-Fusion to fuse results obtained from every single feature.
The general late-fusion strategy that is widely used takes the average from results obtained from each feature of different modalities, which can be formulaically expressed as follows:
where
M denotes the number of selected features, and
denotes the predictions from feature
m. In this study, the general late-fusion strategy is known as Averaged Late-Fusion. The Adaptive Late-Fusion method proposed in our work aims to increase the weights of features with high performance while decreasing the weights of features with low performance. Specifically, we calculate the weights for each feature and take the weighted average from all modalities. Weights are calculated according to the CCC from each type of feature, and thus, the feature types with higher CCC will have larger weights in the proposed Adaptive Late-Fusion. The formulaic expression of our proposed Adaptive Late-Fusion is shown as follows:
where
M denotes the number of selected features;
, the predictions from feature
m;
, the sum of CCCs for all features; and
, the CCC score of feature
m.
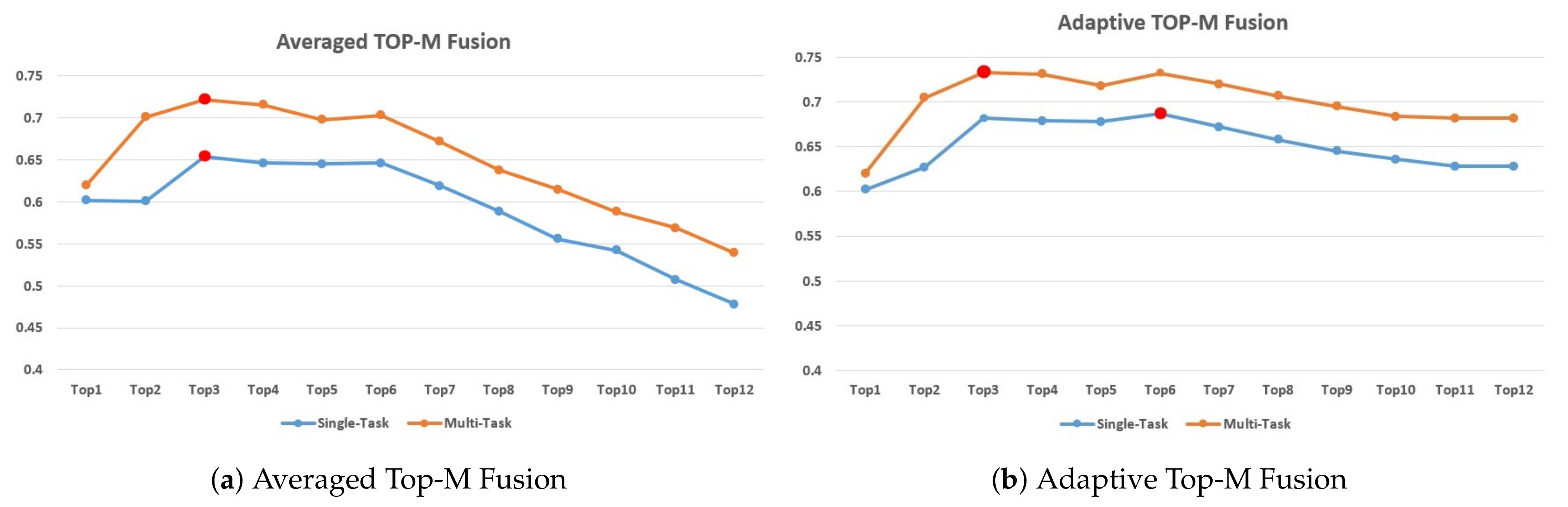
We implement our Adaptive Late-fusion Strategy in two ways. In one way, we select all modalities and all types of features and fuse the results from them, which means that the results obtained will account for every modality. In the other way, we only fuse the top
M features ranked by the CCC [
17] metric, which means that we will drop features with poor performance.
4. Experiments
4.1. The AVEC 2019 DDS Challenge Dataset
The DDS dataset was obtained from AVEC 2019 [
5], where the level of depression (PHQ-8 questionnaire [
18]) was assessed from audiovisual recordings of patients’ clinical interviews conducted by a virtual agent driven by a human as a Wizard-of-Oz (WoZ) [
19]. The recording audio has been transcribed by Google Cloud’s speech recognition service and annotated for a variety of verbal and nonverbal features. Each interview in the AVEC 2019 DDS dataset comprises interview IDs, PHQ-8 binary labels, PHQ-8 scores, and the participant’s gender. The dataset contains baseline features extracted from audiovisual recordings by common frameworks based on open-source toolboxes. It spans three expressions levels: functional low-level descriptors (hand-crafted), bag-of-words, and unsupervised deep representations. The audio features are provided by openSMILE [
20], and the video features are provided by openFace [
21].
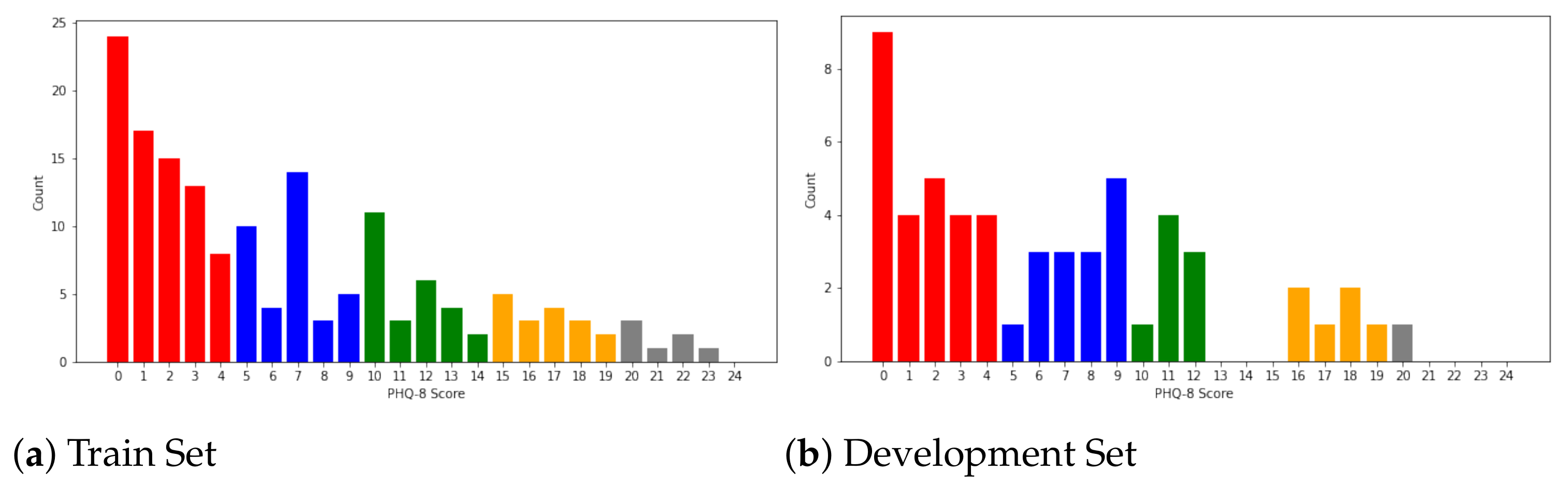
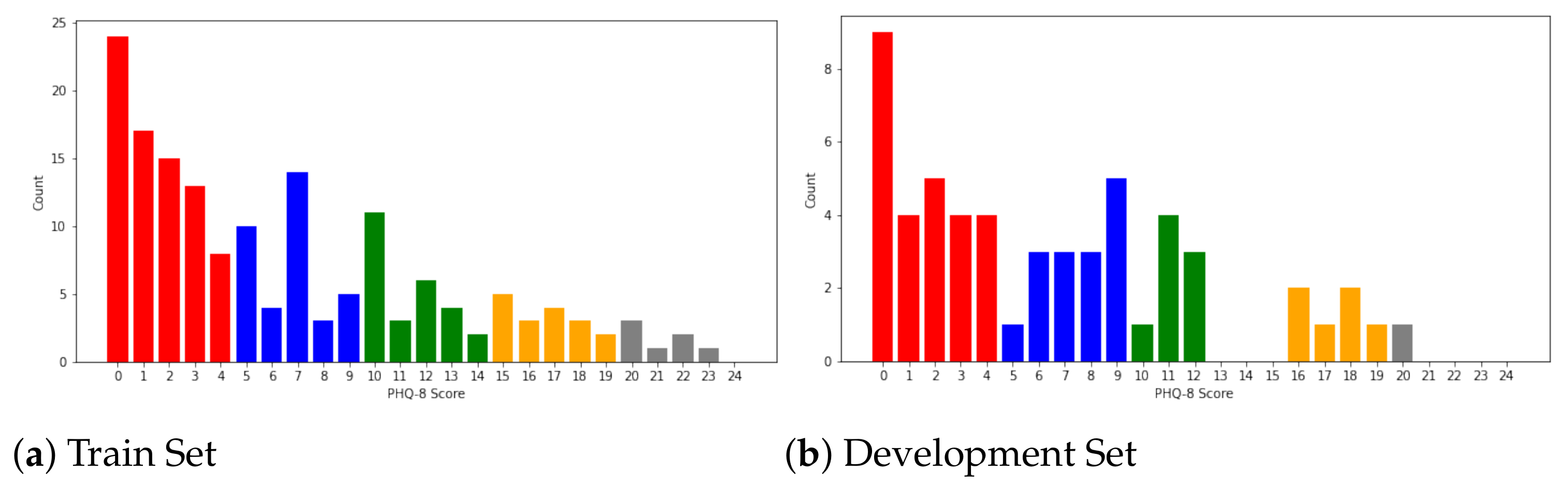
For every sample in the AVEC 2019 DDS dataset, the PHQ-8 scores range
. Following [
3], we define the cut-points at
for minimal depression, mild depression, moderate depression, moderately severe depression, and severe depression, respectively. The distribution of the AVEC 2019 DDS dataset is shown in
Figure 3. The dataset includes MFCC, Bow_MFCC, eGeMAPS, Bow_eGeMAPS, DS_DNet, and DS_VGG for audio and FAUs, BoVW, ResNet, and VGG for video, where Bow indicates the bag-of-word method; DS, the deep spectrogram; and DNet and VGG, the data processed by pretrained DenseNet and VGG_Net, respectively. In this dataset, every modality feature has the shape of
, where
t denotes the length of the sequence, and
d represents the dimension of the modality.
4.2. Data Processing
Because the data sequences are too long to fit in 48GB of memory, which is our best GPU capacity with double RTX3090 GPU cards, we must shorten the dataset’s original data. To shorten the sequences, we sample N frames from the original features for every modality feature. Specifically, we evenly split the sequence into s segments; for each segment, we randomly sample L = N/s successive frames. Finally, we concatenate the s segments obtained from each segment. Consequently, we can obtain N frames from each kind of feature in this manner. For different types of features in the AVEC 2019 DDS dataset, we select different N and s, which can be treated as hyperparameters as the dimensions of different features are different.
We generate the MFCC_functional, eGeMAPS_functional, and AUpose_functional from MFCC, eGeMAPS, and AUpose, respectively, using the approach provided by the AVEC 2019 DDS to enhance the modality and avoid the side effect of processing extremely long-term sequences. Specifically, the functional features have the same lengths as 1768 and the mean value and standard deviation of the original data.
To achieve the goal of multi-task learning, we obtain classification labels from the original PHQ-8 scores, as illustrated by [
3]. The corresponding relationships between the original PHQ-8 scores and 5-class classification labels and the label distributions are presented in
Table 1.
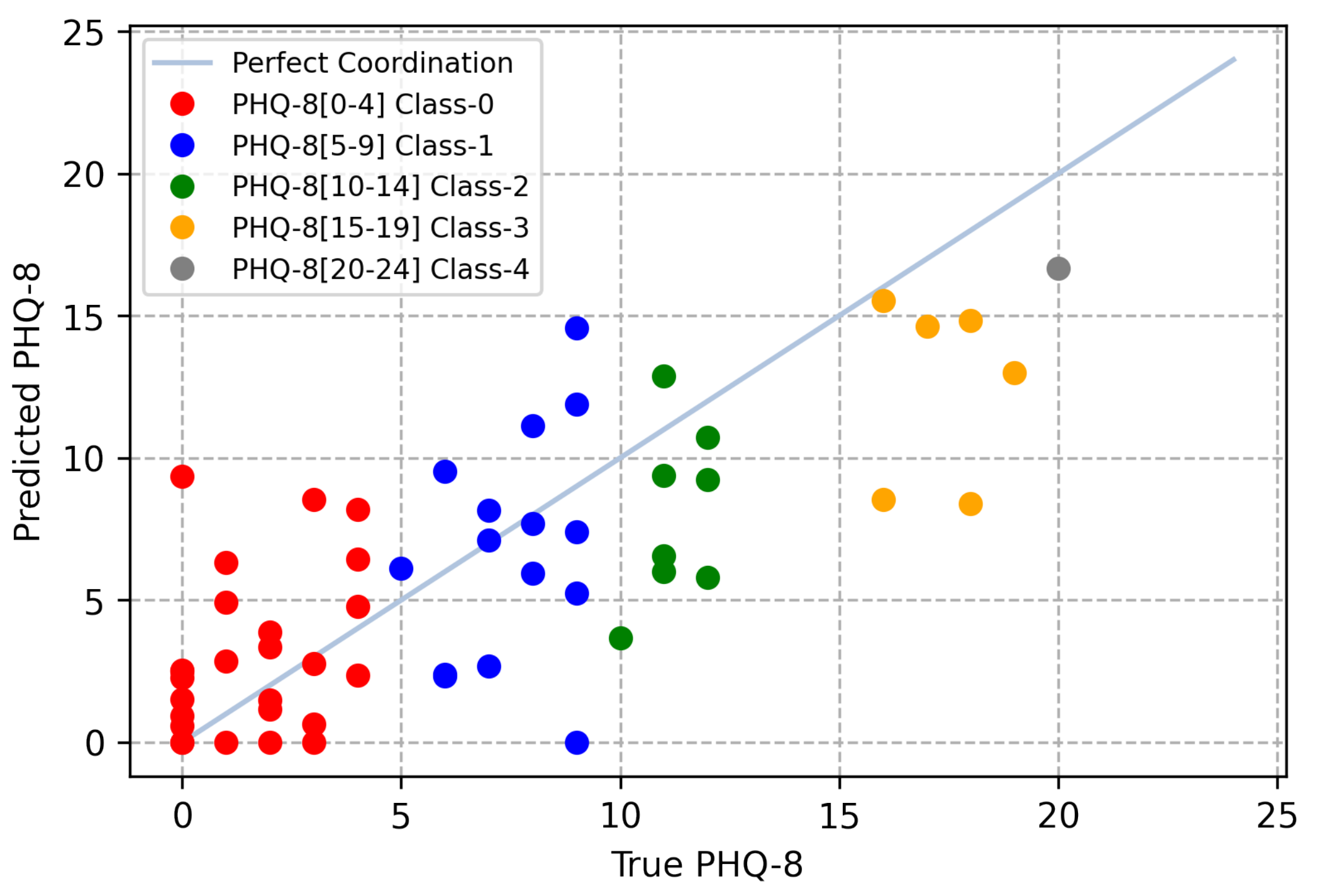
4.3. Evaluation Functions
We use well-known standard evaluation metrics for depression detection to evaluate regression/classification results. We use the Concordance Correlation Coefficient (CCC) [
17] as a measure of PHQ-8 estimated scores (regression task), which is the common metric in dimensional depression detection to measure the agreement between true PHQ-8 scores (
y) and predicted PHQ-8 scores (
). The CCC is formulated as follows:
where
and
denote the variances of
and
y, whereas
denote the corresponding covariance value. The CCC is based on Lin’s calculation [
17]. The range of the CCC is from
to 1, where
represents perfect disagreement and 1 represents perfect agreement.
As another measure for the regression task, we also use the root mean square error (RMSE), which is defined as Equation (
14), where
and
y denote the predicted and true depression levels, respectively, and
N represents the number of samples.
4.4. Experimental Setup
To demonstrate the effectiveness of our proposed method, we apply it, along with the original baseline GRU model [
5], to obtain a direct comparison between them. The AVEC 2019 DDS dataset is split into training, development, and test sets. We utilized only the training and development sets for a fair comparison with the state-of-the-art methods following [
3,
4]. Our experiments were conducted on 219 subjects: 163 subjects for training and 56 subjects for development. The Adam optimization algorithm [
22] was employed to learn the parameters in our networks. The learning rate was set to
. The batch size was set to 48 for low- and middle-level features and 24 for high-level features. We trained our model for 500 epochs for low and middle-level features and 200 epochs for high-level features. During training, we set
to 1.0, 0.0 for single-task and 0.9, 0.1 for multi-task in the loss function of Equation (
8). For the Transformer Encoder block, we set the head number of Multi-head Attention to 1, the hidden dimension of the Feed-Forward layer to 2048, and the number of the encoder layer to 6 following the original Transformer structure [
8]. Our model is implemented with the framework of PyTorch [
23], whereas our experiments are conducted on double Nvidia RTX 3090 GPU cards.
Our proposed networks have several hyperparameters to be optimized. The length of inputs for the Transformer Encoder (
N) and the number of selected modalities for fusion (
M) are the most important architectural decisions. After the exploration, we select
N = 2048 for low- and middle-level features and
N = 720 for for high-level features in this work. For
M,
and
are the best choices for multi-task and single-task in Adaptive Late-Fusion, respectively. We will elaborate our exploration procedure in more detail in the
Section 6.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}