
Mapping Urban Air Quality from Mobile Sensors Using Spatio-Temporal Geostatistics

 ,
,  , ,
, , 
Abstract
:1. Introduction
1.1. Classical Methods of Air Quality Monitoring
- Land-Use Regression models Land-Use Regression models (LUR) make the assumption that the air quality in a given place depends only on the local characteristics of the environment, such as the land use, weather-related variables, building density, and traffic density. These models link the measurement of air quality taken at the fixed station to the chosen predictive environmental variables.A LUR model developed by Kerckhoffs et al. [7], including small-scale traffic, large-scale address density, and urban green, explained 71% of the spatial variation for ozone concentrations. Meng et al. [8] and Chen et al. [9] successfully developed a LUR model for NO2 concentrations in China.LUR models provide good results for a rather low complexity. They also describe the effect of the environmental variables on the pollutant concentration but remain limited by the amount of data from other variables needed or obtained at a relatively expensive cost.
- Deterministic interpolation methods One of the most popular deterministic interpolation methods is Inverse Distance Weighting (IDW). The value at the unknown location is calculated as the weighted average of the measurements collected from the monitoring stations. This method assumes that the value is more influenced by the nearest measurements than the distant ones, and thus the closest locations obtain greater weights. As the distance increases, less weight is given to the measurement.Given the simplicity of this method, it is often used as a benchmark. Marshall et al. [10] used it to compare the urban variability of the NO and NO2 concentration to a LUR model and an Eulerian grid model in Vancouver, Canada. Wong et al. [11] compared different interpolation methods, including IDW to estimate the ozone concentration and Particulate Matter (PM) concentrations.The weakness of deterministic interpolation methods lies in their poor extrapolation accuracy. These methods are not considered as models, because they do not describe the data in addition to not giving uncertainty associated with the prediction.
- Geostatistics Geostatistics regroup stochastic kriging methods, the value at the unsampled location is evaluated by a weighted linear combination of measurements, and the weights are calculated from the variability of the data inferred from the actual structure of the data.Kim et al. [12] developed an Ordinary Kriging (OK) prediction model to predict long-term PM concentrations in seven major Korean cities. Whitworth et al. [13] modelled the ambient air levels of benzene in an urban environment. More sophisticated than IDW and regression modelling, geostatistics also provide the uncertainty associated with the prediction. However, these techniques suffer from a relatively high computational cost.
- Dispersion models Dispersion models replicate the formation of atmospheric pollutants through physical and chemical processes. They have been widely used in traffic-related pollution prediction and make use of the environmental variables, such as the ones used in LUR models.Hamer et al. [14] described the Eulerian urban dispersion model EPISODE and its application to the modelling of NO2 pollution concentration. Fallah et al. [15] improved the characterisation of near-road air pollution using a regional Gaussian dispersion model. Gibson et al. [16] used the AERMOD Gaussian plume air dispersion model to evaluate the PM, NOx, and SO2. However, these methods suffer from numerous shortcomings, such as the computational cost and the production of uniform and imprecise maps, related to the challenging task of modelling the small scale random variations.
- Machine learning algorithms A machine learning algorithm analyses the training data and produces an inferred function, which can be used to map new examples. Machine learning is very effective in situations where insights must be discovered from large sets of diverse and changing data. Numerous studies applied this method to predict air pollution levels: Singh et al. [17] identified pollution sources and predicted urban air quality using ensemble learning methods. Cabaneros et al. [18] provided a review of Artificial Neural Network (ANN) models for ambient air pollution prediction. Some machine learning algorithms were combined with fuzzy models in order to predict air pollution levels [19]. Machine learning algorithms are considered as black boxes with poor descriptive power and struggle to provide better results than the other models with limited data.
1.2. Mobile Sensors
2. Materials and Methods
2.1. Data
Calibration Process
2.2. Methodology
2.2.1. Model Selection
- Simple kriging with a varying known mean: the time series of the fixed monitoring station was chosen to be the overall mean.
- Ordinary kriging with a constant piecewise mean, but unknown.
- Kriging with external drift: the data from the fixed monitoring station was used to estimate the underlying mean.
2.2.2. Variographic Study
2.2.3. Models Validation Process
- The first method consists of randomly choosing a proportion of points regardless of their location in space or when they were collected: this corresponds to the reconstruction of data between sampled places.
- The second, more realistic, method consists of choosing small paths of different lengths while keeping the same percentage of data in order to reproduce a real data collection from a mobile sensor: this corresponds to the extrapolation of the data to places close to the sampling places.
- The last method, uses only the data resulting from the trajectory of specific trams. This corresponds to extrapolation for places "far" from the sampling points, which will often be encountered in practice.
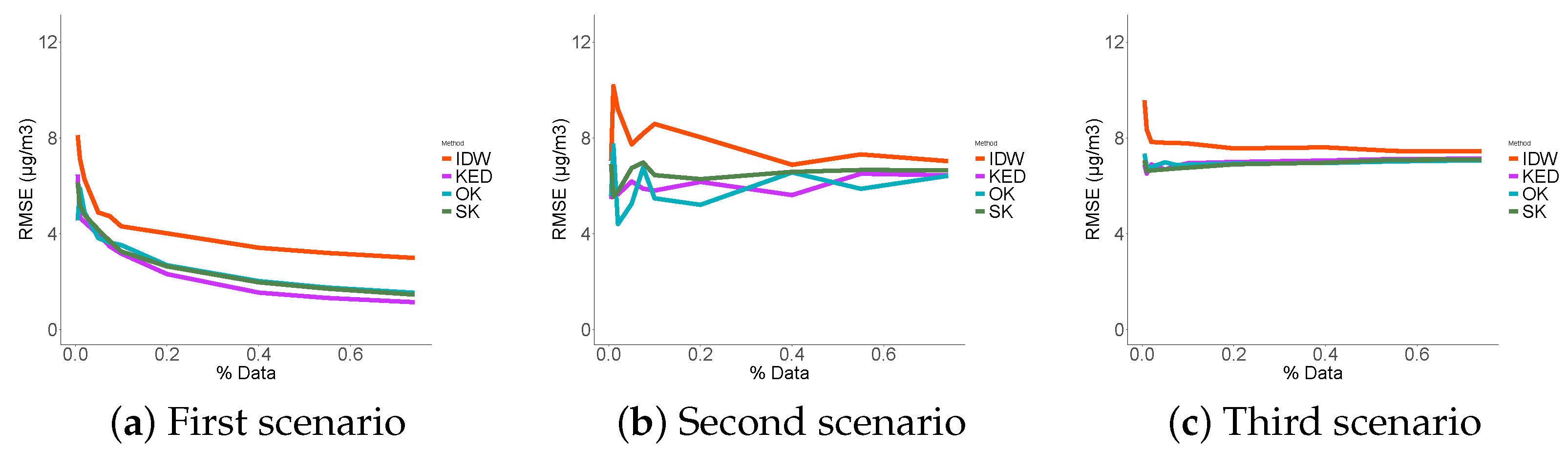
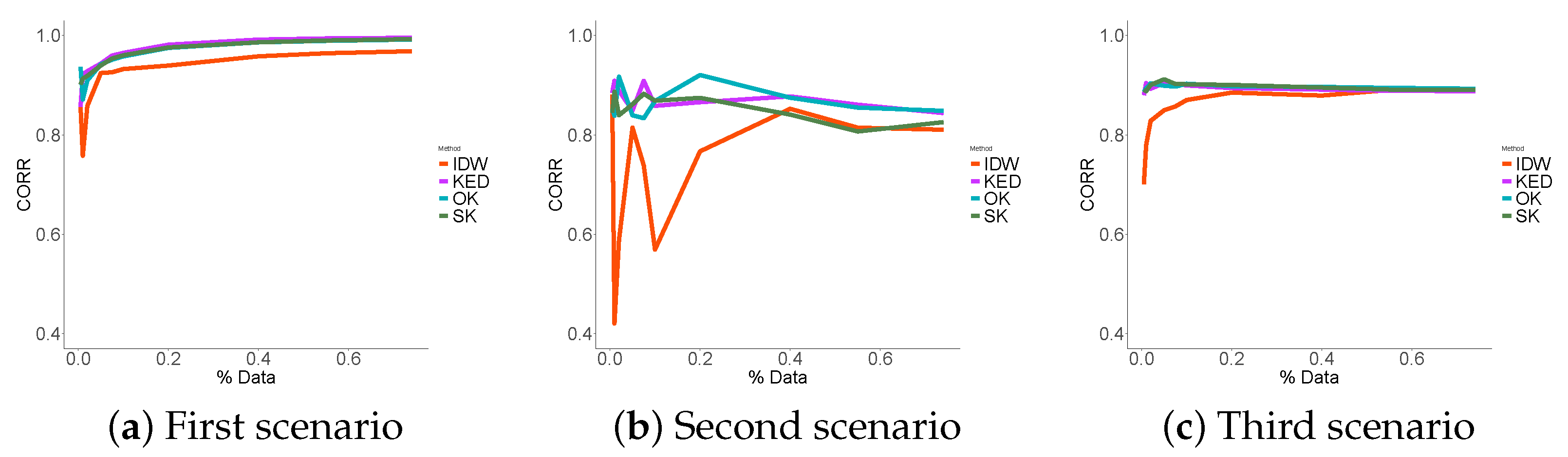
2.2.4. Performance Indicators
- The Root Mean Squared Error (RMSE) was selected as the main performance indicator to measure the error as it is the most frequently used measure to assess the differences between the predicted values by a model or an estimator and the observed values. The three geostatistical models presented in this article were built to minimize this error.
- The bias performance indicator was chosen to control the unbiasedness of the estimators. The three geostatistics estimators are theoretically unbiased. This performance indicator is used to check that.
- The correlation performance indicator was selected to deal with the low-cost nature of the sensors. In case of bias, it is necessary to measure the correlation performance and compare it to the RMSE.
2.3. Methods
2.3.1. Simple Kriging with a Varying Mean
2.3.2. Ordinary Kriging
2.3.3. Kriging with External Drift
2.3.4. Spatio-Temporal Inverse Distance Weighting
3. Results
3.1. Variographic Study
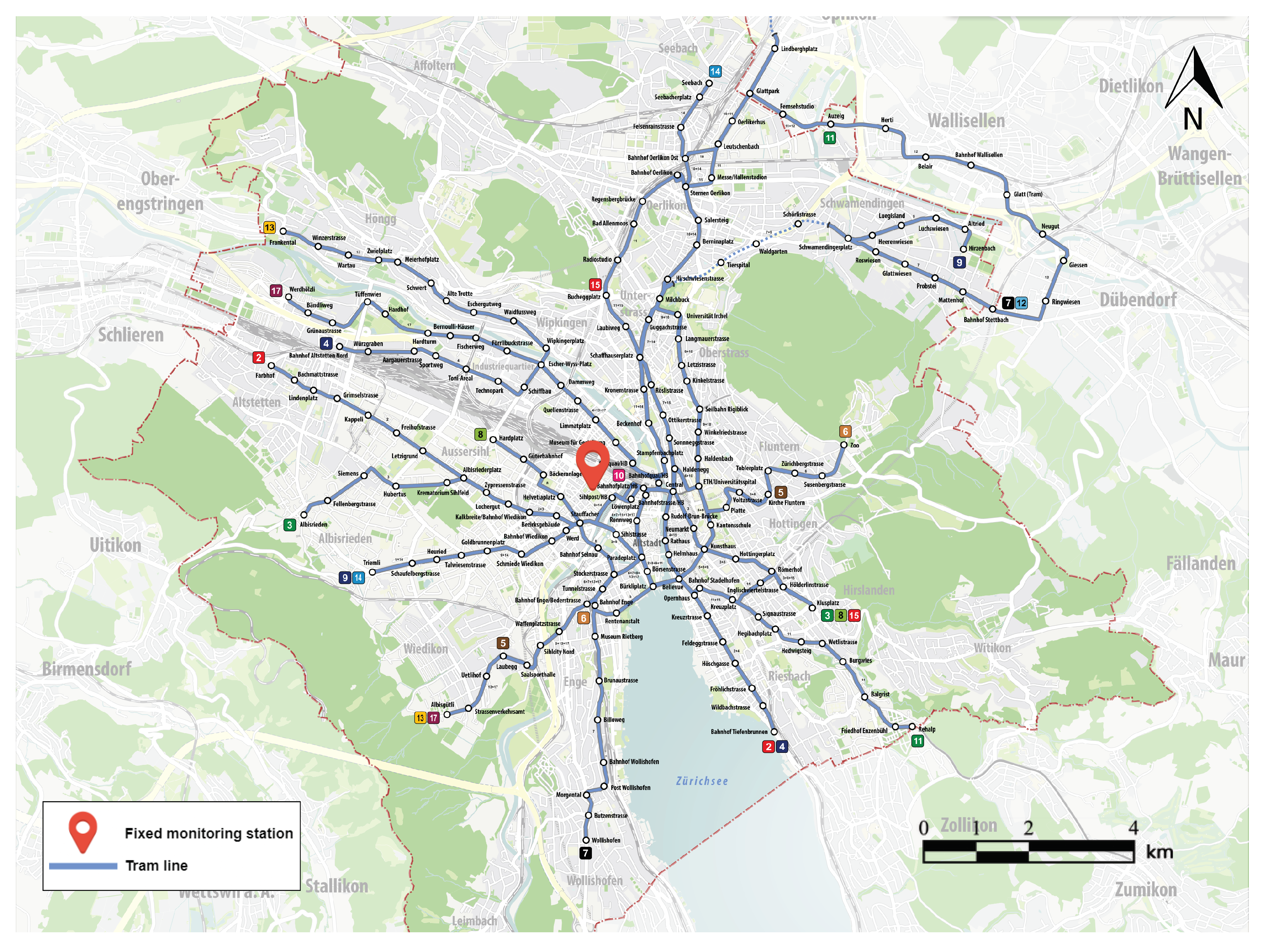
3.1.1. Anisotropy
3.1.2. Spatio-Temporal Variance
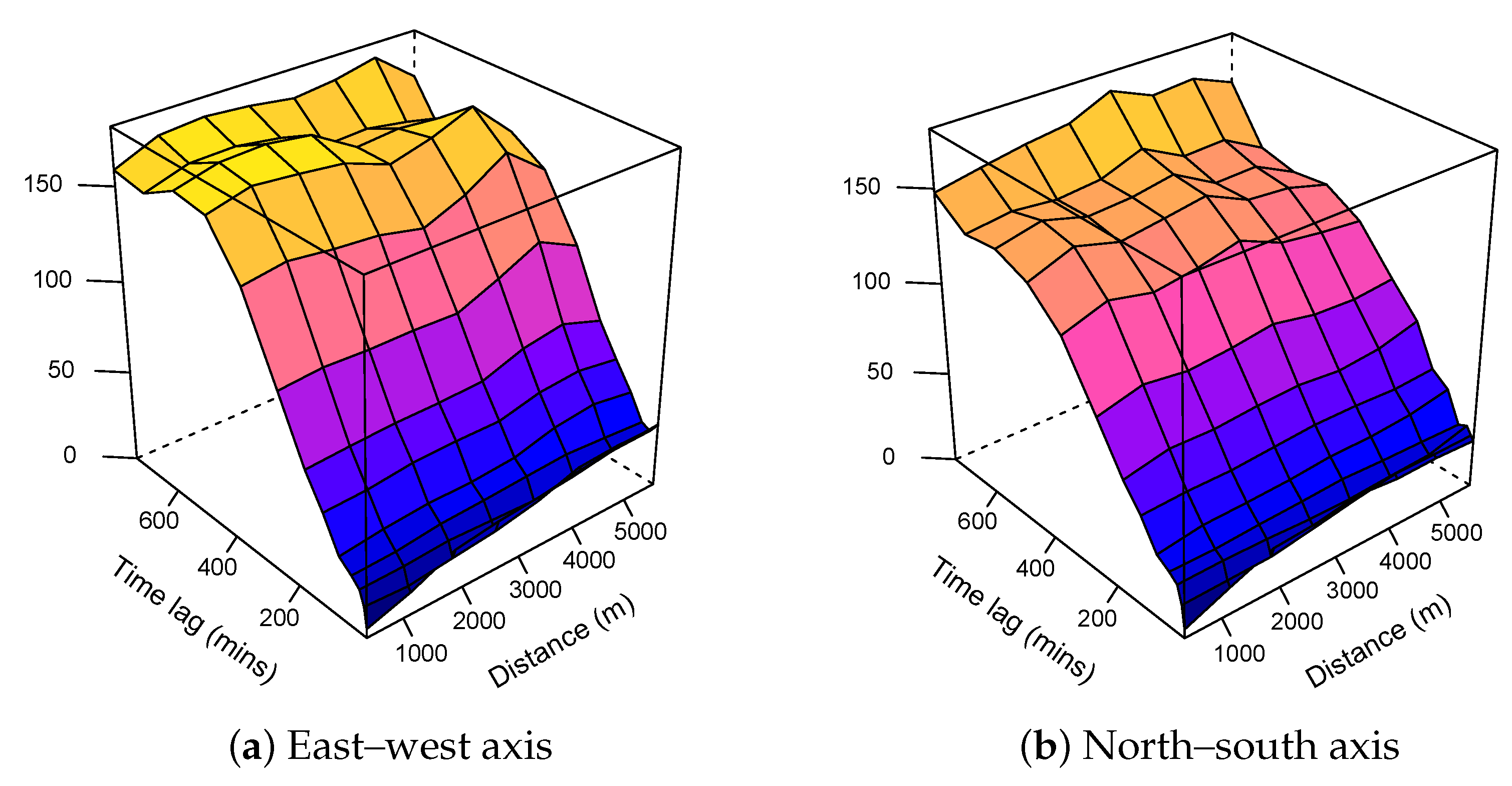
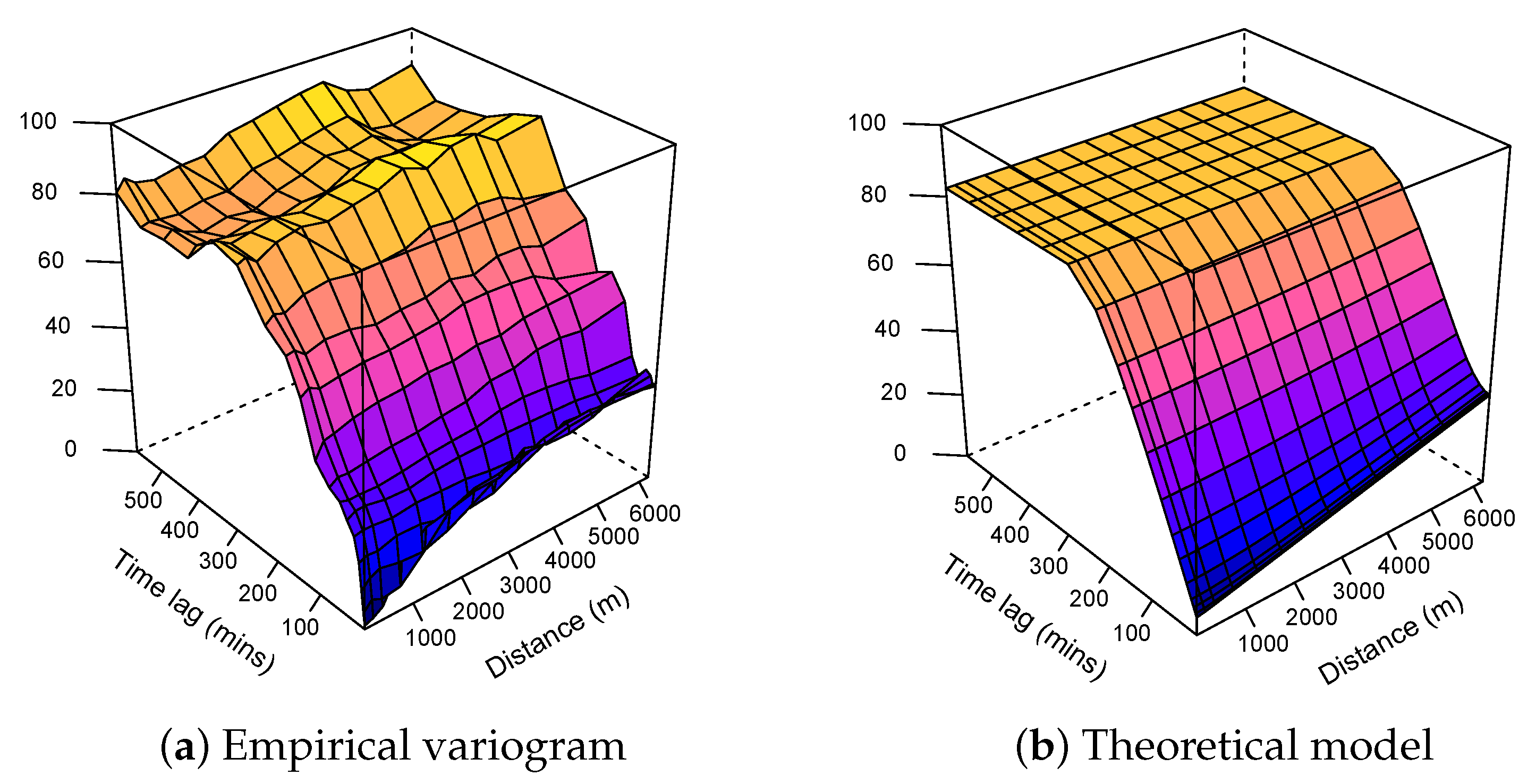
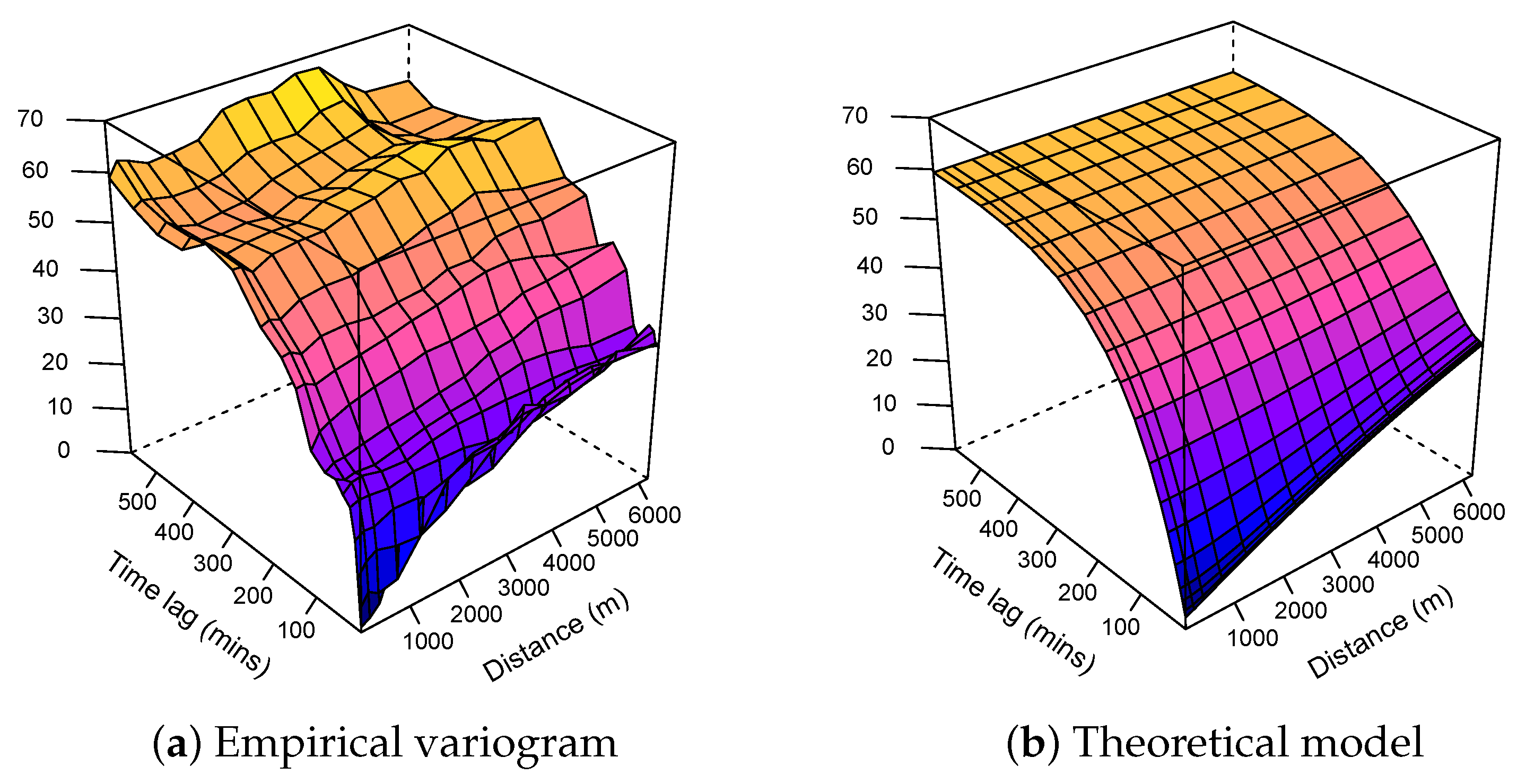
3.1.3. Modelling
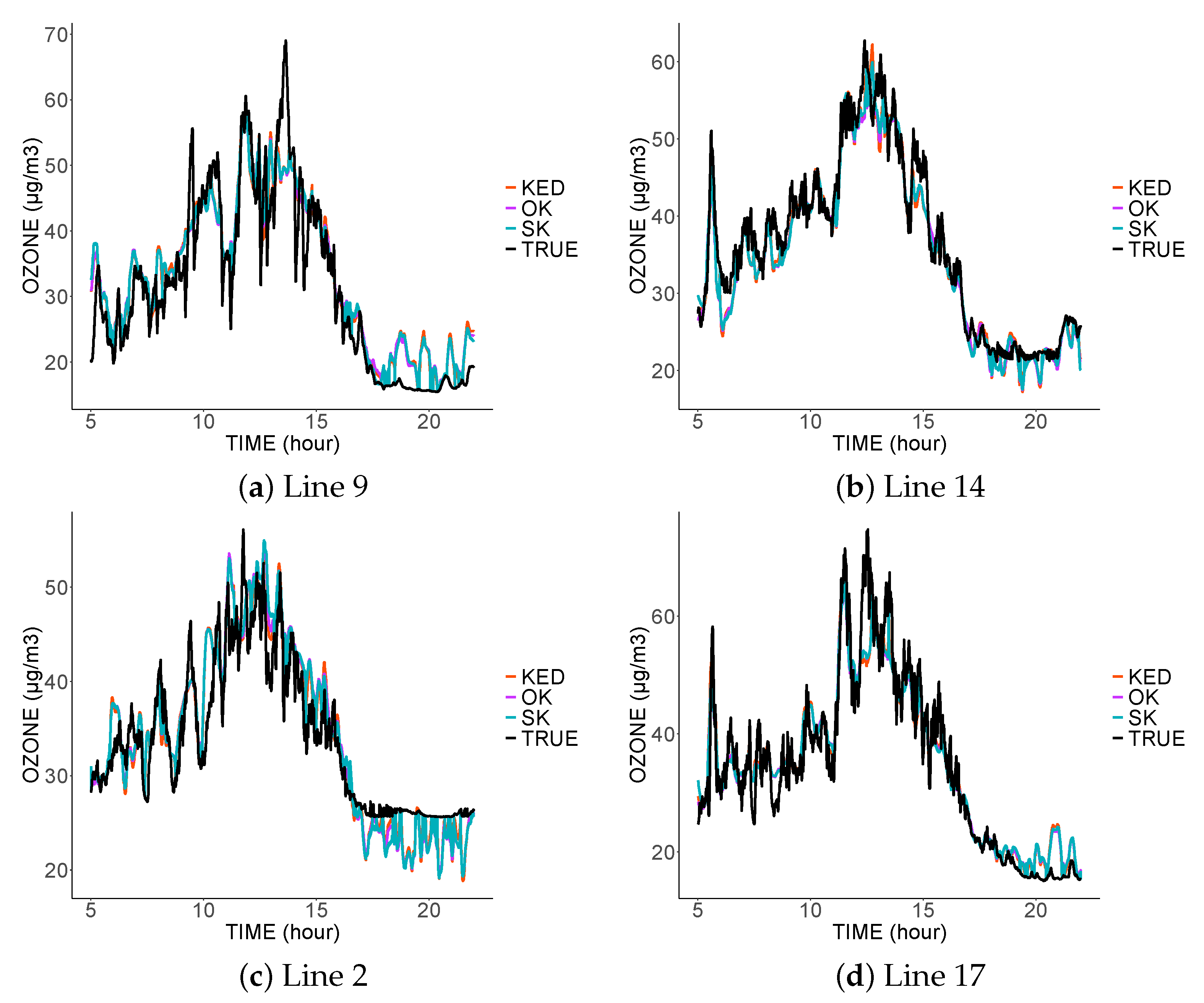
3.2. Spatio-Temporal Signals
3.3. Performance Indicators Results
3.4. Resulting Maps
4. Discussion
5. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IDW | Inverse Distance Weighting |
| SK | Simple Kriging |
| OK | Oridnary Kriging |
| KED | Kriging with external drift |
| UFP | Ultra Fine Particles |
| ANN | Artificial Neural Network |
| LUR | Land-Use Regression |
| PM | Particulate Matter |
References
- WHO. 7 Million Premature Deaths Annually Linked to Air Pollution. 2014. Available online: https://www.who.int/mediacentre/news/releases/2014/air-pollution/en/ (accessed on 30 April 2021).
- Sharma, P.; Sharma, P.; Jain, S.; Kumar, P. Response to discussion on: “An integrated statistical approach for evaluating the exceedance of criteria pollutants in the ambient air of megacity Delhi”, Atmospheric Environment. Atmos. Environ. 2013, 71, 413–414. [Google Scholar] [CrossRef]
- Manisalidis, I.; Stavropoulou, E.; Stavropoulos, A.; Bezirtzoglou, E. Environmental and health impacts of air pollution: A review. Front. Public Health 2020, 8, 14. [Google Scholar] [CrossRef] [Green Version]
- Britter, R.; Hanna, S. Flow and dispersion in urban areas. Annu. Rev. Fluid Mech. 2003, 35, 469–496. [Google Scholar] [CrossRef]
- Berkowicz, R.; Palmgren, F.; Hertel, O.; Vignati, E. Using measurements of air pollution in streets for evaluation of urban air quality—Meterological analysis and model calculations. Sci. Total Environ. 1996, 189, 259–265. [Google Scholar] [CrossRef]
- Scaperdas, A.; Colvile, R. Assessing the representativeness of monitoring data from an urban intersection site in central London, UK. Atmos. Environ. 1999, 33, 661–674. [Google Scholar] [CrossRef]
- Kerckhoffs, J.; Wang, M.; Meliefste, K.; Malmqvist, E.; Fischer, P.; Janssen, N.A.; Beelen, R.; Hoek, G. A national fine spatial scale land-use regression model for ozone. Environ. Res. 2015, 140, 440–448. [Google Scholar] [CrossRef] [PubMed]
- Meng, X.; Chen, L.; Cai, J.; Zou, B.; Wu, C.F.; Fu, Q.; Zhang, Y.; Liu, Y.; Kan, H. A land use regression model for estimating the NO2 concentration in Shanghai, China. Environ. Res. 2015, 137, 308–315. [Google Scholar] [CrossRef]
- Chen, L.; Bai, Z.; Kong, S.; Han, B.; You, Y.; Ding, X.; Du, S.; Liu, A. A land use regression for predicting NO2 and PM10 concentrations in different seasons in Tianjin region, China. J. Environ. Sci. 2010, 22, 1364–1373. [Google Scholar] [CrossRef]
- Marshall, J.D.; Nethery, E.; Brauer, M. Within-urban variability in ambient air pollution: Comparison of estimation methods. Atmos. Environ. 2008, 42, 1359–1369. [Google Scholar] [CrossRef]
- Wong, D.W.; Yuan, L.; Perlin, S.A. Comparison of spatial interpolation methods for the estimation of air quality data. J. Expo. Sci. Environ. Epidemiol. 2004, 14, 404–415. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.Y.; Yi, S.J.; Eum, Y.S.; Choi, H.J.; Shin, H.; Ryou, H.G.; Kim, H. Ordinary kriging approach to predicting long-term particulate matter concentrations in seven major Korean cities. Environ. Health Toxicol. 2014. [Google Scholar] [CrossRef]
- Whitworth, K.W.; Symanski, E.; Lai, D.; Coker, A.L. Kriged and modeled ambient air levels of benzene in an urban environment: An exposure assessment study. Environ. Health 2011, 10, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamer, P.D.; Walker, S.E.; Sousa-Santos, G.; Vogt, M.; Vo-Thanh, D.; Lopez-Aparicio, S.; Ramacher, M.O.; Karl, M. The urban dispersion model EPISODE. Part 1: A Eulerian and subgrid-scale air quality model and its application in Nordic winter conditions. Geosci. Model Dev. Discuss. 2019, 2019, 1–57. [Google Scholar]
- Fallah-Shorshani, M.; Shekarrizfard, M.; Hatzopoulou, M. Integrating a street-canyon model with a regional Gaussian dispersion model for improved characterisation of near-road air pollution. Atmos. Environ. 2017, 153, 21–31. [Google Scholar] [CrossRef]
- Gibson, M.D.; Kundu, S.; Satish, M. Dispersion model evaluation of PM2. 5, NOx and SO2 from point and major line sources in Nova Scotia, Canada using AERMOD Gaussian plume air dispersion model. Atmos. Pollut. Res. 2013, 4, 157–167. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.P.; Gupta, S.; Rai, P. Identifying pollution sources and predicting urban air quality using ensemble learning methods. Atmos. Environ. 2013, 80, 426–437. [Google Scholar] [CrossRef]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Cacciola, M.; Pellicanò, D.; Megali, G.; Lay-Ekuakille, A.; Versaci, M.; Morabito, F. Aspects about air pollution prediction on urban environment. In Proceedings of the 4th Imeko TC19 Symposium on Environmental Instrumentation and Measurements Protecting Environment, Climate Changes and Pollution Control, Lecce, Italy, 3–4 June 2013; pp. 15–20. [Google Scholar]
- Morawska, L.; Thai, P.K.; Liu, X.; Asumadu-Sakyi, A.; Ayoko, G.; Bartonova, A.; Bedini, A.; Chai, F.; Christensen, B.; Dunbabin, M.; et al. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone? Environ. Int. 2018, 116, 286–299. [Google Scholar] [CrossRef]
- Borghi, F.; Spinazzè, A.; Rovelli, S.; Campagnolo, D.; Del Buono, L.; Cattaneo, A.; Cavallo, D.M. Miniaturized monitors for assessment of exposure to air pollutants: A review. Int. J. Environ. Res. Public Health 2017, 14, 909. [Google Scholar] [CrossRef] [Green Version]
- Feinberg, S.; Williams, R.; Hagler, G.S.; Rickard, J.; Brown, R.; Garver, D.; Harshfield, G.; Stauffer, P.; Mattson, E.; Judge, R.; et al. Long-term evaluation of air sensor technology under ambient conditions in Denver, Colorado. Atmos. Meas. Tech. 2018, 11, 4605. [Google Scholar] [CrossRef] [Green Version]
- Munir, S.; Mayfield, M.; Coca, D.; Jubb, S.A.; Osammor, O. Analysing the performance of low-cost air quality sensors, their drivers, relative benefits and calibration in cities—A case study in Sheffield. Environ. Monit. Assess. 2019, 191, 94. [Google Scholar] [CrossRef] [Green Version]
- Johnson, K.K.; Bergin, M.H.; Russell, A.G.; Hagler, G.S. Field test of several low-cost particulate matter sensors in high and low concentration urban environments. Aerosol Air Qual. Res. 2018, 18, 565. [Google Scholar] [CrossRef]
- Devarakonda, S.; Sevusu, P.; Liu, H.; Liu, R.; Iftode, L.; Nath, B. Real-time air quality monitoring through mobile sensing in metropolitan areas. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11 August 2013; pp. 1–8. [Google Scholar]
- Re, G.L.; Peri, D.; Vassallo, S.D. Urban air quality monitoring using vehicular sensor networks. In Advances onto the Internet of Things; Springer: Berlin/Heidelberg, Germany, 2014; pp. 311–323. [Google Scholar]
- Hasenfratz, D.; Saukh, O.; Walser, C.; Hueglin, C.; Fierz, M.; Arn, T.; Beutel, J.; Thiele, L. Deriving high-resolution urban air pollution maps using mobile sensor nodes. Pervasive Mob. Comput. 2015, 16, 268–285. [Google Scholar] [CrossRef]
- Catlett, C.E.; Beckman, P.H.; Sankaran, R.; Galvin, K.K. Array of things: A scientific research instrument in the public way: Platform design and early lessons learned. In Proceedings of the 2nd International Workshop on Science of Smart City Operations and Platforms Engineering, Pittsburgh, PA, USA, 18–21 April 2017; pp. 26–33. [Google Scholar]
- English, P.B.; Olmedo, L.; Bejarano, E.; Lugo, H.; Murillo, E.; Seto, E.; Wong, M.; King, G.; Wilkie, A.; Meltzer, D.; et al. The Imperial County Community Air Monitoring Network: A model for community-based environmental monitoring for public health action. Environ. Health Perspect. 2017, 125, 074501. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Chen, X.; Liu, X.; Noh, H.Y.; Zhang, P.; Zhang, L. Gotcha II: Deployment of a Vehicle-based Environmental Sensing System: Poster Abstract. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems CD-ROM, Stanford, CA, USA, 14–16 November 2016; pp. 376–377. [Google Scholar] [CrossRef]
- Merbitz, H.; Fritz, S.; Schneider, C. Mobile measurements and regression modeling of the spatial particulate matter variability in an urban area. Sci. Total Environ. 2012, 438, 389–403. [Google Scholar] [CrossRef] [PubMed]
- Van den Bossche, J.; Peters, J.; Verwaeren, J.; Botteldooren, D.; Theunis, J.; De Baets, B. Mobile monitoring for mapping spatial variation in urban air quality: Development and validation of a methodology based on an extensive dataset. Atmos. Environ. 2015, 105, 148–161. [Google Scholar] [CrossRef] [Green Version]
- Gozzi, F.; Della Ventura, G.; Marcelli, A. Mobile monitoring of particulate matter: State of art and perspectives. Atmos. Pollut. Res. 2016, 7, 228–234. [Google Scholar] [CrossRef]
- Marjovi, A.; Arfire, A.; Martinoli, A. Extending urban air quality maps beyond the coverage of a mobile sensor network: Data sources, methods, and performance evaluation. In Proceedings of the International Conference on Embedded Wireless Systems and Networks, Uppsala, Sweden, 20–22 February 2017. [Google Scholar]
- Hart, R.; Liang, L.; Dong, P. Monitoring, Mapping, and Modeling Spatial–Temporal Patterns of PM2.5 for Improved Understanding of Air Pollution Dynamics Using Portable Sensing Technologies. Int. J. Environ. Res. Public Health 2020, 17, 4914. [Google Scholar] [CrossRef] [PubMed]
- Apte, J.S.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.W.; Lunden, M.M.; Marshall, J.D.; Portier, C.J.; Vermeulen, R.C.; Hamburg, S.P. High-resolution air pollution mapping with Google street view cars: Exploiting big data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef] [PubMed]
- Hasenfratz, D.; Saukh, O.; Walser, C.; Hueglin, C.; Fierz, M.; Thiele, L. Pushing the spatio-temporal resolution limit of urban air pollution maps. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 69–77. [Google Scholar]
- Marjovi, A.; Arfire, A.; Martinoli, A. High resolution air pollution maps in urban environments using mobile sensor networks. In Proceedings of the 2015 International Conference on Distributed Computing in Sensor Systems, Fortaleza, Brazil, 10–12 June 2015; pp. 11–20. [Google Scholar]
- Li, J.J.; Jutzeler, A.; Faltings, B.; Winter, S.; Rizos, C. Estimating urban ultrafine particle distributions with gaussian process models. In Proceedings of the 2014 REREARCH@LOCATE’14 Proceedings, Canberra, Australia, 7–9 April 2014; pp. 145–153. [Google Scholar]
- Lim, C.C.; Kim, H.; Vilcassim, M.R.; Thurston, G.D.; Gordon, T.; Chen, L.C.; Lee, K.; Heimbinder, M.; Kim, S.Y. Mapping urban air quality using mobile sampling with low-cost sensors and machine learning in Seoul, South Korea. Environ. Int. 2019, 131, 105022. [Google Scholar] [CrossRef]
- Adams, M.D.; Kanaroglou, P.S. Mapping real-time air pollution health risk for environmental management: Combining mobile and stationary air pollution monitoring with neural network models. J. Environ. Manag. 2016, 168, 133–141. [Google Scholar] [CrossRef] [PubMed]
- Hankey, S.; Marshall, J.D. Land use regression models of on-road particulate air pollution (particle number, black carbon, PM2.5, particle size) using mobile monitoring. Environ. Sci. Technol. 2015, 49, 9194–9202. [Google Scholar] [CrossRef] [PubMed]
- Gressent, A.; Malherbe, L.; Colette, A.; Rollin, H.; Scimia, R. Data fusion for air quality mapping using low-cost sensor observations: Feasibility and added-value. Environ. Int. 2020, 143, 105965. [Google Scholar] [CrossRef]
- Do, T.H.; Tsiligianni, E.; Qin, X.; Hofman, J.; La Manna, V.P.; Philips, W.; Deligiannis, N. Graph-Deep-Learning-Based Inference of Fine-Grained Air Quality from Mobile IoT Sensors. IEEE Internet Things J. 2020, 7, 8943–8955. [Google Scholar] [CrossRef]
- Zhang, D.; Woo, S.S. Real time localized air quality monitoring and prediction through mobile and fixed IoT sensing network. IEEE Access 2020, 8, 89584–89594. [Google Scholar] [CrossRef]
- Song, J.; Han, K.; Stettler, M. Deep-MAPS: Machine Learning based Mobile Air Pollution Sensing. IEEE Internet Things J. 2020, 8, 7649–7660. [Google Scholar] [CrossRef]
- Van den Hove, A.; Verwaeren, J.; Van den Bossche, J.; Theunis, J.; De Baets, B. Development of a land use regression model for black carbon using mobile monitoring data and its application to pollution-avoiding routing. Environ. Res. 2020, 183, 108619. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guan, Y.; Johnson, M.C.; Katzfuss, M.; Mannshardt, E.; Messier, K.P.; Reich, B.J.; Song, J.J. Fine-scale spatiotemporal air pollution analysis using mobile monitors on Google Street View vehicles. J. Am. Stat. Assoc. 2020, 115, 1111–1124. [Google Scholar] [CrossRef] [Green Version]
- Mariano, P.; Almeida, S.M.; Santana, P. Pollution Prediction Model Using Data Collected by a Mobile Sensor Network. In Proceedings of the 2020 5th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 23–26 September 2020; pp. 1–6. [Google Scholar]
- Ma, R.; Liu, N.; Xu, X.; Wang, Y.; Noh, H.Y.; Zhang, P.; Zhang, L. Fine-Grained Air Pollution Inference with Mobile Sensing Systems: A Weather-Related Deep Autoencoder Model. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, New York, NY, USA, 15 June 2020; Volume 4, pp. 1–21. [Google Scholar]
- Hatzopoulou, M.; Valois, M.F.; Levy, I.; Mihele, C.; Lu, G.; Bagg, S.; Minet, L.; Brook, J. Robustness of land-use regression models developed from mobile air pollutant measurements. Environ. Sci. Technol. 2017, 51, 3938–3947. [Google Scholar] [CrossRef]
- Kerckhoffs, J.; Hoek, G.; Vlaanderen, J.; van Nunen, E.; Messier, K.; Brunekreef, B.; Gulliver, J.; Vermeulen, R. Robustness of intra urban land-use regression models for ultrafine particles and black carbon based on mobile monitoring. Environ. Res. 2017, 159, 500–508. [Google Scholar] [CrossRef]
- Aberer, K.; Sathe, S.; Chakraborty, D.; Martinoli, A.; Barrenetxea, G.; Faltings, B.; Thiele, L. OpenSense: Open community driven sensing of environment. In Proceedings of the ACM SIGSPATIAL International Workshop on GeoStreaming, San Jose, CA, USA, 2 November 2010; pp. 39–42. [Google Scholar]
- Li, J.J.; Faltings, B.; Saukh, O.; Hasenfratz, D.; Beutel, J. Sensing the air we breathe-the opensense zurich dataset. In Proceedings of the National Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 1, pp. 323–325. [Google Scholar]
- Arnaud, M.; Emery, X. Estimation et Interpolation Spatiale: Méthodes Déterministes et Méthodes Géostatistiques; Hermès: Paris, France, 2000. [Google Scholar]
- Chiles, J.P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 497. [Google Scholar]
- Pebesma, E.; Heuvelink, G. Spatio-temporal interpolation using gstat. RFID J. 2016, 8, 204–218. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Method | Area | Pollutant | Sensor Carrier |
|---|---|---|---|---|
| Marjovi et al. [34] | LUR, machine learning (ANN) | Lausane, Switzerland | UFP | Bus |
| Hart et al. [35] | LUR | Texas, USA | PM2.5 | Bike |
| Apte et al. [36] | Reduction algorithm | Oakland, USA | NO, NO2, BC | Car |
| Hasenfratz et al. [37] | LUR | Zurich, Switzerland | UFP | Tram |
| Hasenfratz et al. [27] | LUR | Zurich, Switzerland | UFP | Tram |
| Marjovi et al. [38] | LUR, Probabilistic Graphical Model | Lausanne, Switzerland | UFP | Bus |
| Li et al. [39] | Kriging | Zurich, Switzerland | UFP | Tram |
| Lim et al. [40] | LUR, machine learning | Seoul, South Korea | PM2.5 | Pedestrian |
| Adams et al. [41] | ANN | Hamilton, Canada | NO2 | Van |
| Hankey et al. [42] | LUR | Minneapolis, USA | BC, PM2.5 | Bike |
| Gressent et al. [43] | Kriging | Nantes, France | PM10 | Car |
| Do et al. [44] | Autoencoders | Antwerp, Belgium | Several pollutants | Bike |
| Zhang et al. [45] | Machine learning | Songdo, Korea | CO2, PM2.5, PM10 | Car |
| Song et al. [46] | Machine learning | Beijing, China | PM2.5 | Car |
| Van et al. [47] | LUR | Ghent, Belgium | BC | Bike |
| Guan et al. [48] | LUR, kriging | Oakland, California | NO2 | Car |
| Mariano et al. [49] | Decision trees | Zurich, Switzerland | UFP | Tram |
| Ma et al. [50] | Machine learning | China | PM2.5 | Car |
| Method | S-P Model | K | Join Model | Sill | Nugget | Range |
|---|---|---|---|---|---|---|
| Simple kriging | Metric | 105.16 | Spheric | 82.30 | 5.00 | 30,415.43 |
| Ordinary kriging | Metric | 91.18 | Linear | 148.8 | 5.00 | 38,073.4 |
| Kriging with external drift | Metric | 83.03 | Exponential | 59.86 | 2.00 | 9872.405 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Idir, Y.M.; Orfila, O.; Judalet, V.; Sagot, B.; Chatellier, P. Mapping Urban Air Quality from Mobile Sensors Using Spatio-Temporal Geostatistics. Sensors 2021, 21, 4717. https://doi.org/10.3390/s21144717
Idir YM, Orfila O, Judalet V, Sagot B, Chatellier P. Mapping Urban Air Quality from Mobile Sensors Using Spatio-Temporal Geostatistics. Sensors. 2021; 21(14):4717. https://doi.org/10.3390/s21144717
Chicago/Turabian StyleIdir, Yacine Mohamed, Olivier Orfila, Vincent Judalet, Benoit Sagot, and Patrice Chatellier. 2021. "Mapping Urban Air Quality from Mobile Sensors Using Spatio-Temporal Geostatistics" Sensors 21, no. 14: 4717. https://doi.org/10.3390/s21144717
APA StyleIdir, Y. M., Orfila, O., Judalet, V., Sagot, B., & Chatellier, P. (2021). Mapping Urban Air Quality from Mobile Sensors Using Spatio-Temporal Geostatistics. Sensors, 21(14), 4717. https://doi.org/10.3390/s21144717