Abstract
Accurately tailored support such as advice or assistance can increase user satisfaction from interactions with smart devices; however, in order to achieve high accuracy, the device must obtain and exploit private user data and thus confidential user information might be jeopardized. We provide an analysis of this privacy–accuracy trade-off. We assume two positive correlations: a user’s utility from a device is positively correlated with the user’s privacy risk and also with the quality of the advice or assistance offered by the device. The extent of the privacy risk is unknown to the user. Thus, privacy concerned users might choose not to interact with devices they deem as unsafe. We suggest that at the first period of usage, the device should choose not to employ the full capability of its advice or assistance capabilities, since this may intimidate users from adopting it. Using three analytical propositions, we further offer an optimal policy for smart device exploitation of private data for the purpose of interactions with users.
1. Introduction
Personal data can improve user experience as users receive personally tailored advice or assistance. For example, smart watch devices that track user movements suggest exercise when they detect the user is inactive for a long period of time [1]. Similarly, infrared sensors can detect falls and call for assistance [2]. However, in order to advise or assist, devices require access to personal information and these data require protection.
It is often unclear to the user what private information is collected, and if and how it is protected. Citing from a survey on the economics of privacy of [3]: “[Users’] ability to make informed decisions about their privacy is severely hindered because consumers are often in a position of imperfect or asymmetric information regarding when their data are collected, for what purposes, and with what consequences”.
The ability of individuals to manage privacy amid increasingly complex trade-offs is a problem, as faulty decisions may lead to privacy violations, which in turn incur various consequences. First, if information about users is leaked, it enables price discrimination. A second aspect is that of the violation of the user’s right to “peace and quiet”; for example, when receiving undesired adware (see [4]). Lastly, privacy violations might make it possible to sell user information to a third party.
We herein consider devices that employ user private information collected from sensors or devices provided with sensors. For example, by wearing a smart watch, the user shares information such as his location, heartbeat and movements. Using this information, the device is able to produce more accurate services. Users may be oblivious to the privacy risk at first. After an initial period in which they use the device, and once the device collects the data that are used to offer advice or assistance, the users may become aware of the potential privacy risk. The users must trust the device to continue using it once they are aware of the privacy risk. When the device is not trusted, privacy risks and privacy violations may lead to users abandoning the device (also known as customer churn [5]). User perception of privacy and trust are therefore important [6,7,8].
Contributions: In this paper, we provide an analytical examination of how users’ considerations of privacy risk affect their interactions with sensors and devices provided with sensors. We propose a model that shows that the user–device interaction has an interesting trend for users moderately concerned about their privacy. Nothing the device suggests will impact the very concerned or the very oblivious users, since they either do not trust the device with their information or are not concerned at all. However, the device’s usage by users with a moderate privacy concern depends on how the users perceive the device’s privacy risk. When the risk is not completely known to the users upfront, the users will use the device only if they trust it. With moderately concerned users, the device should choose not to employ the full capability of its advice or assistance capabilities, since this may intimidate the user from using it. Our results are not limited to any specific device and are generally true for any sensor or device provided with sensors that utilizes information where user privacy might be compromised.
The rest of the paper proceeds as follows. We begin with some background (Section 2). We then present a game-theoretical model and analytical results (Section 3). As some of the model is without mathematical proofs, we provide a numerical solution to the model (Section 4). We conclude with a discussion of our main findings (Section 5).
2. Related Work
As Acquisti et al. [3] have stated, “privacy is difficult to define”. In a similar manner, we focus on the informational dimension of privacy. i.e., the protection or sharing of personal data. There are two attitudes to the protection of private data: the protection is either handled by the device or by the user. When the privacy is left in the hands of the users, it is known as “privacy self-management” [9]. In some cases, install-time permissions provide users with control over their privacy as users are required to decide to whom to provide consent to collect, use and disclose their personal data [10]. In other cases, the users can choose between public and personal operation mode, or switch between these modes according to their activity context [11]. Often, users require assistance in privacy-related decisions [12].
Considerable research has focused on privacy from the device side, i.e., a technical perspective such as securing the channels over which information is sent [13] or collected [14]. Some researchers suggest zero-touch non-invasive systems where users do not need to engage with the system [15], while others secure the privacy of by-standers [16]. Interviews surveying how users perceive privacy of wearable devices conclude that there are a variety of user attitudes ranging from users who are not worried at all to users that are highly concerned for their privacy [17]. However, these studies do not consider actions following what users deem as a privacy risk nor do they present recommendations for devices.
John et al. [18] have experimentally shown that privacy-related cues affect the extent to which users are concerned about their privacy. Accordingly, previous research has emphasized the role of the clarity of the privacy policies on the user trust in the device or system used; changing the look of privacy policies makes online services appear more trustworthy [19]. Deciding which IOT-related devices are appropriate depends on the user familiarity more than it does on the privacy policy [20]. Similarly, [21] analyze the effects of both cognitive trust and emotional trust on the intention to opt in to health information exchanges and willingness to disclose health information.
We study scenarios where the users implicitly deduce the extent to which their private information is being analyzed, from the behavior of the device, as displayed in the advice or assistance the device offers. A user with a new smart watch might not bother to read the privacy policy of the smart watch’s app. Nevertheless, after a short period of time, the user can easily deduce that they are being monitored, for example, when the watch suggests the user should stretch, exercise or even breathe deeply [22]. It has been experimentally shown that smart watch usage is directly influenced by perceived usefulness and perceived privacy risk has a direct negative influence on the behavioral intention to use smart watches [23,24,25].
The above studies are experimental. For a general game theoretic model, where players exchange some information while being concerned about privacy, see [26] for example. In a more related context, Jullien et al. [27] discuss website users in situations where a website sells user information to third parties, which may lead to a good, a bad or a neutral experience for the users. In these situations, user vulnerability to a bad experience is unknown to the website. They consider a framework with two periods, where the users decide whether to stay with the website for the second period, depending on the first period outcome. In this work we implement the same two-period framework. However, Jullien et al. [27] study vulnerability as a property of the users, while we suggest examining risk as a property of the device.
In sum, previous studies that have focused on trust and privacy have shown that both have a direct effect on the usage of devices. However, these studies are of an experimental nature. In this paper we present a complementary analytical model that can explain the experimental results others have collected, support their claims and provide a better understanding of the privacy–accuracy trade-off for smart and sensor-based devices.
3. Model
We herein employ a game theoretic approach and examine a model containing a device with various possible degrees of privacy risks, and users that are uncertain as to the device privacy risk. In order to achieve high accuracy the device must obtain and exploit private user data and thus confidential user information might be jeopardized. We define accuracy as the degree of closeness of the advice or assistance offered by the device to the advice and assistance the user actually requires. We provide an analysis of this privacy–accuracy trade-off. We assume that a user’s utility from a device is positively correlated with:
- The user’s privacy risk.
- The advice or assistance offered by the device.
We consider an initial stage where the device only collects data, and a continuous stage where the device exploits the collected data.
For simplicity, we define two degrees of risks: (1) High risk, meaning that the user data are public or might be shared or sold to third parties and (2) Low risk, meaning that the user data are confidential. Let there be a user (C) and a device (S). The device has a high privacy risk (H) with probability and a low privacy risk (L) with probability . We denote the device type by . This is unknown to the users. For convenience, all of the notation are found in Table 1.

Table 1.
List of notations in the model.
Before usage, the user activates the device. Thus the user receives an initial signal of the device type, which is correct with probability and erroneous with probability . Namely, if , the user receives a signal h with probability and a signal l with probability . If , the user receives a signal l with probability and a signal h with probability .
At stage 1 (initial usage), the device chooses the accuracy level of its support algorithm (advice and/or assistance) . We denote by and strategies chosen by the high type and the low type devices, respectively. The user receives adjusted support with probability . That is, the device’s support depends on the algorithm’s level of accuracy, and on the extent to which the device utilizes the private information it collected from the user. With a high risk device, the private information is more likely to be utilized, and vice versa. We assume that increases in q and for every q, . Denote by a the event “support is sent to the user”, and by the complementary event. Following a, the user’s utility is and device’s utility is . For , both the user and the device obtain utility 0. Following signal and event , the user assigns a probability to the device being H:
At stage 2 (continuous usage), the user decides whether to keep using the device or to limit, reduce or abandon the device altogether. For simplicity, we look at two options: leave or not leave.
If the user leaves, both user and device obtain a utility of 0. If the user does not leave, with probability ( is S’s type), the user’s private information is leaked, exposing the user to possible damage. Let . The utilities of the user and the device in this case are and , respectively. With probability , the user uses the device, and his/her utility is and , if or , respectively. We assume that , namely, that the high type device has more value to the user, but this type has a higher privacy risk. We also assume that expected utilities of both H and L in stage 2 (denoted as and , respectively) are positive. The user’s total utility is a total sum of the outcomes of stages 1 and 2.
We now turn to analyze if and when the users will abandon the device. If the potential damage to the user is high, the user will leave the device, regardless of their belief of the device’s type. The opposite is also true. If is low, they will not leave regardless of their belief of the device type. For intermediate values of , the user’s strategy depends on the utility of leaving a high-type device, when no damage is caused. If is high, the user does not leave if they assign a sufficiently high probability to be a high-type device; however, if the utility is relatively low, the user does not leave only if they assign a sufficiently low probability to the device being high type. Recall that the risk of being damaged by not abandoning the device is higher if the device type is H. This analysis is formally stated in the following proposition. The proofs of all propositions appear in the Appendix A.
Proposition 1.
Consider a Nash pure strategy equilibrium.
- 1.
- Let . Then in Nash equilibrium:
- (a)
- If , C prefers to leave at stage 2 for any .
- (b)
- If , C prefers not to leave at stage 2 for any .
- (c)
- If , there exists such that C chooses not to leave iff .
- 2.
- Let . Then in Nash equilibrium:
- (a)
- If , C prefers not to leave at stage 2 for any .
- (b)
- If , C prefers to leave at stage 2 for any .
- (c)
- If , there exists such that C chooses not to leave iff .
The next proposition states that at stage 1, if the signal about the device type is noisy (high ), the device may choose not to offer maximal quality support (). The reason being that when the quality is maximal, the probability of tailored support increases, and thus, the user’s belief that the device type is H increases. At stage 2, if the benefit of H is sufficiently low (a low ), the user may leave the device after receiving the tailored support.
Proposition 2.
Suppose and . Let . Assume . Then there is and such that is not a Nash equilibrium strategy of H and L.
When the signal about the device type is sufficiently precise, the user knows the device type with a high probability. Therefore, the user chooses whether to leave or not at stage 2 regardless of the outcomes of stage 1. In this case, the device chooses maximal quality (i.e., the best tailored support). Formally:
Proposition 3.
For each , there is such that for all , is a unique equilibrium.
4. Numerical Results
We present the following results using Monte Carlo simulations and computed with Matlab software. Consider a symmetric case, where the accuracy of the support algorithm (q) is similar for both device types (). We assume that the probability to receive adjusted support depends on the accuracy level of the device’s support algorithm; for high privacy risk devices it is two times more probable than for low privacy risk devices, i.e., and . We further assume the following parameters are given as input: (equal prior to each type), , , , ; , , and .
Note that these parameter values were intentionally chosen. With these values, if the device is of H-type, the expected utility of the user at stage 2 is negative: . If the device is of L-type, the expected utility of the user at stage 2 is positive: . Thus, these values present a non-trivial setting where it is unclear what the user should do. In contrast, when the expected user utility is negative for both high and low device types, the user has no incentive to use the device and will abandon it. Similarly, when the user-expected utility is positive for both device types, the user will always use the device regardless of its type. Thus, the values were specifically chosen to accommodate the non-trivial case were the expected value is negative for one device type and positive for the other device type.
We performed the following procedure for different values of q ranging from 0 to 1. First we randomly generated two Bernoulli trials:
- A Bernoulli trial for a signal on the device type .
- A Bernoulli trial for the event that adjusted support is sent or not sent to the user .
When the signal is a the device utility is .
Then, we calculated the user belief of the device type (according to (A1)–(A4)). Next we calculated whether the user prefers to continue using the device in stage 2 (according to (A5)). If the user stays, the utility increases in and for devices with high (H) and low (L) privacy risks, respectively.
For each we ran this procedure for trials, and then computed the average total utility (profit) of high and low-risk device types.
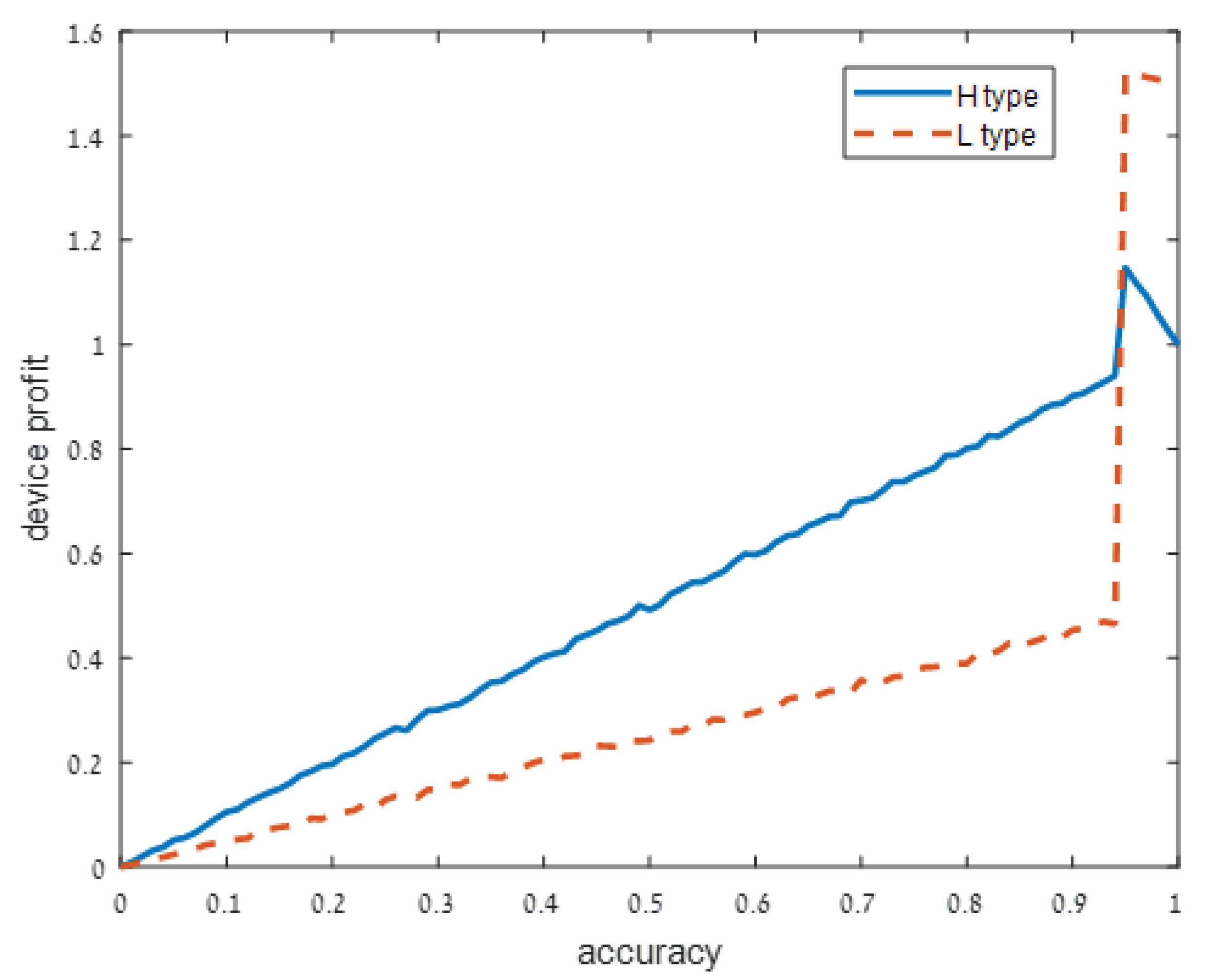
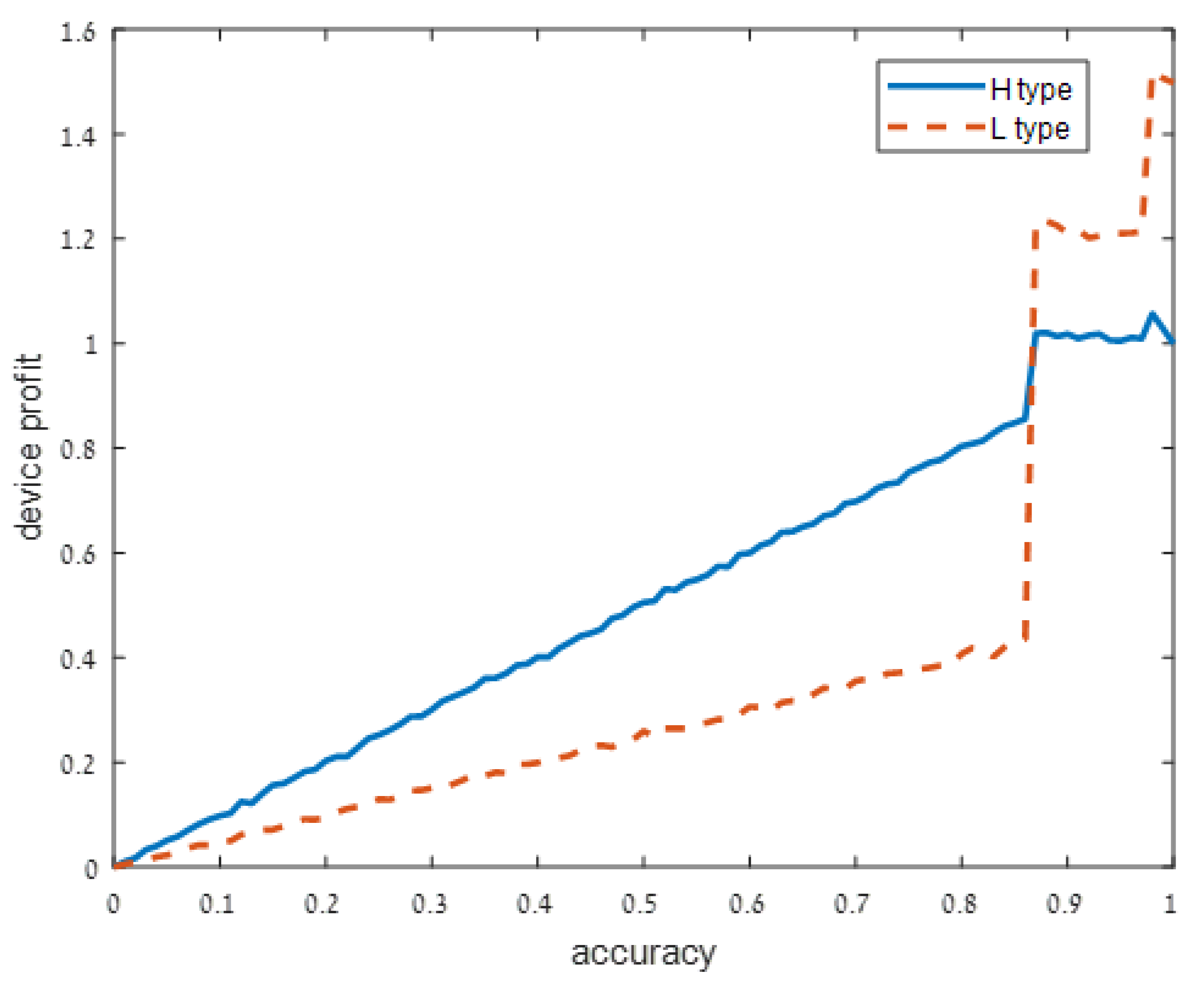
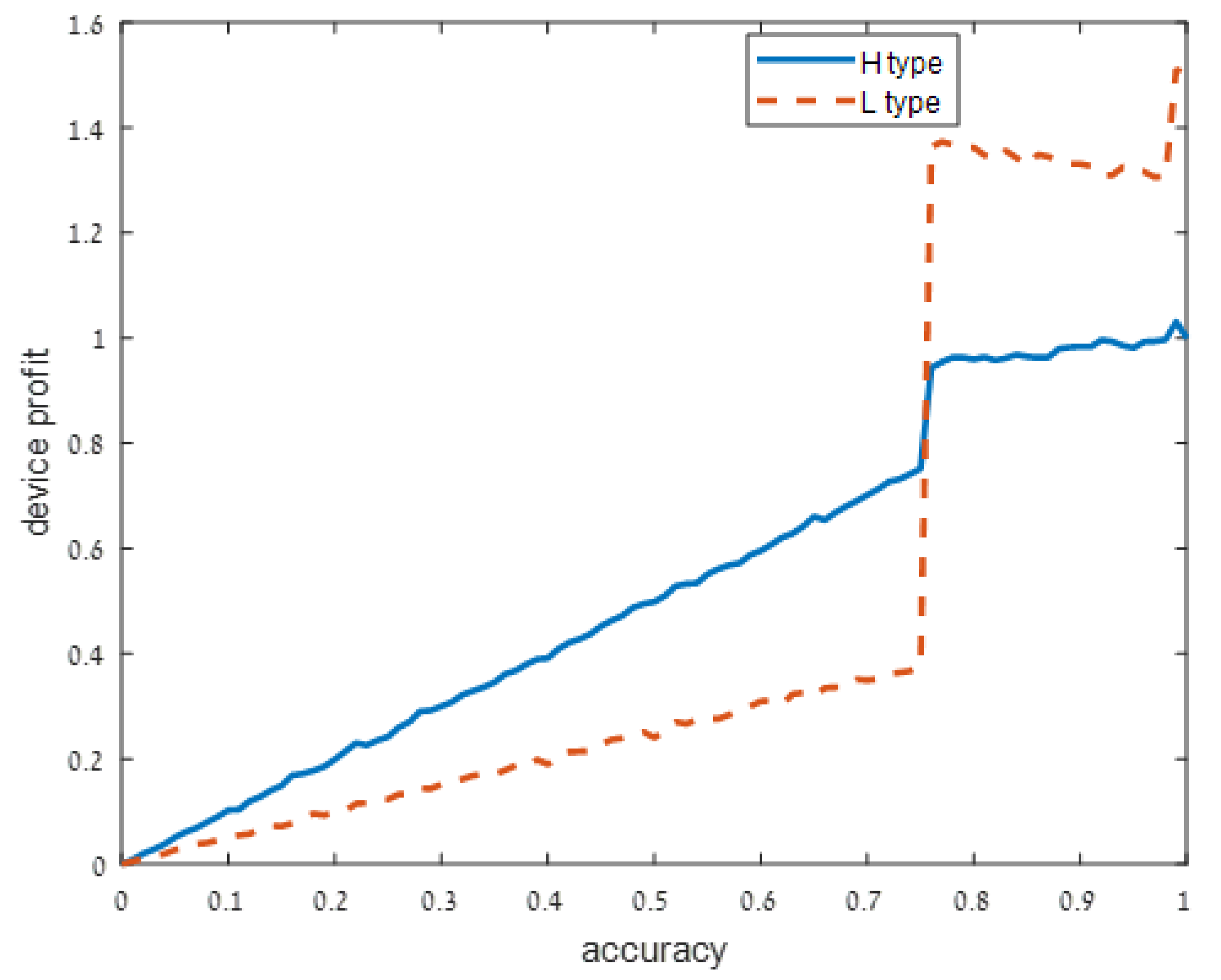
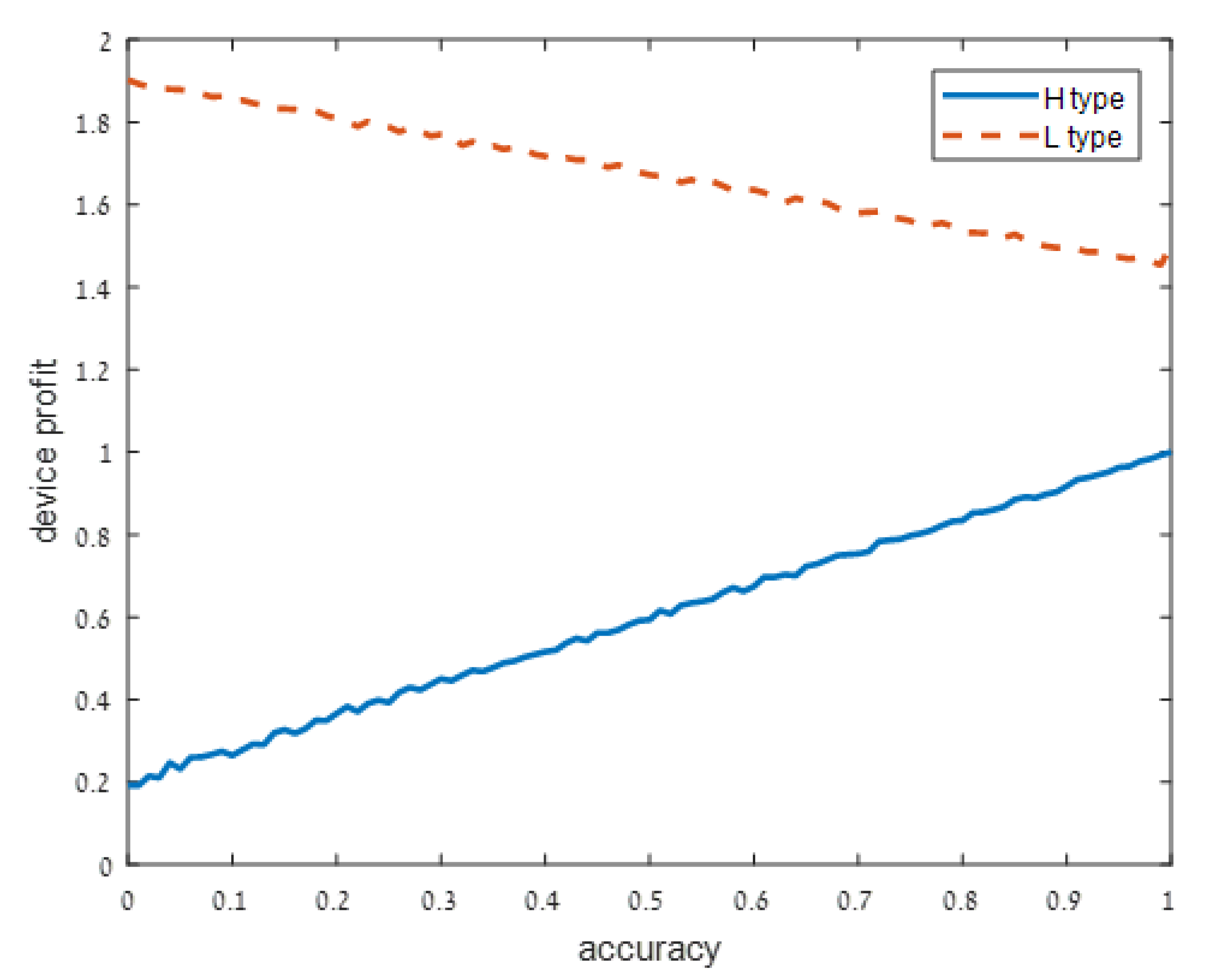
We present our numerical results in Figure 1, Figure 2, Figure 3 and Figure 4. Each figure considers one of the following four signal accuracy levels . Recall that a lower means that the user has a better understanding of what the privacy risk is (at the user knows the risk for certain). The figures illustrate the average total profit (axis y) as q, the accuracy of the support algorithm (axis x) increases.
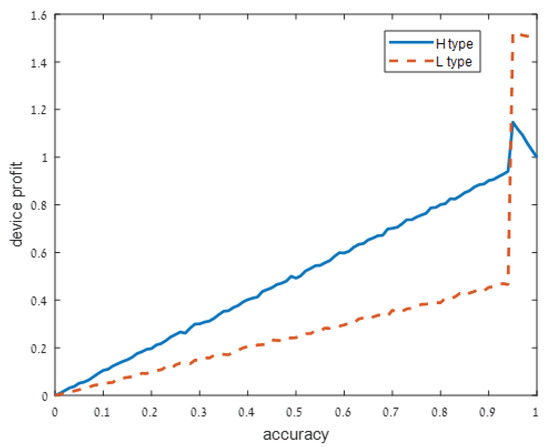
Figure 1.
Extremely noisy signal: .
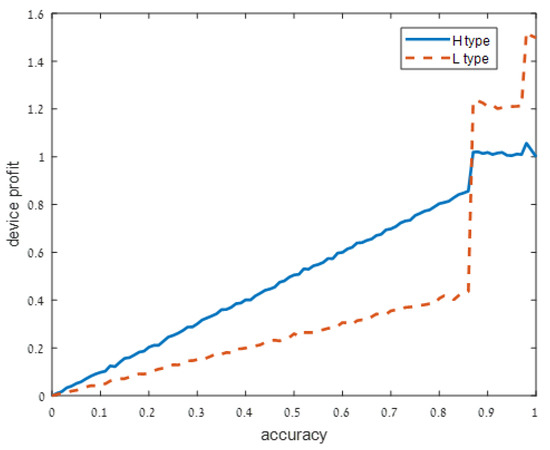
Figure 2.
Moderately noisy signal: .
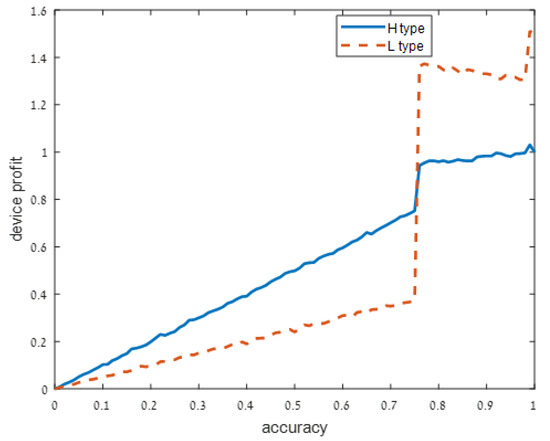
Figure 3.
Moderately noisy signal: .
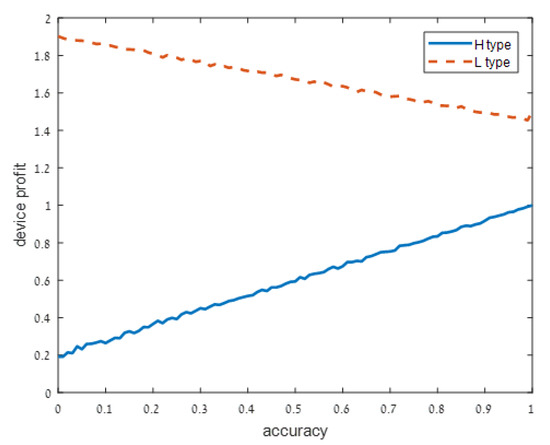
Figure 4.
Low noise: .
Figure 1 shows that when the signal on the device type is extremely noisy (), both high and low device types profit from a higher accuracy strategy q, but the high-risk device type is better off if . In other words, both device types profit from sharing more accurate information and support with the user, but high privacy risk devices should be careful not to fully utilize all of their capabilities.
As user understanding of the privacy increases, i.e., as decreases from in Figure 1 to and in Figure 2 and Figure 3, respectively, the devices with a high privacy risk (type H) maximize their profit at lower accuracy values. This does not hold when the user knowledge of the device’s risk is high ( in Figure 4), since in this case, the users are aware of the privacy risk and thus the profit is maximized when the device outputs accurate support.
When the noise is low, users know with high probability the type of device. It is not surprising then that the utility of the high-type device increases in q. It is more surprising that the utility of the low type device decreases in q. This may be explained by the fact that a negative effect of the adjusted support still persists (there is a small, but positive probability that following signal a the user will suspect that the device is of high risk). However, this effect is relatively weak.
5. Discussion
We analyzed how privacy risk considerations affect the decisions of both the devices and the users. Our main finding herein is that when the device’s privacy risk is unknown to the users it might be inefficient for the device to exploit its sensing technology, since this may lead users to abandon the device.
Specifically, based on our three analytical propositions, we suggest the following for optimal acceptance of devices provided with sensors when the privacy risk is unknown to the users. Our suggestions focus on the communication between the device and the user, specifically on the device feedback policy. These suggestions do not depend on technical characteristics of device, e.g., the sensor’s accuracy and cost.
- Assure low risk—Convincing the user that the device has a low privacy risk for them is of urgent importance. Risk-concerned users who are not convinced will quickly abandon the device. For example, publish a clear and easy to understand privacy policy.
- Limit initial accurate feedback—Accurate advice and assistance might be the most intuitive way to exhibit the device’s usefulness. However, at the first usage period the device should do so with caution. A risk-concerned user might abandon the device due to accurate feedback. So this feedback should sometimes be withheld. This is because, from accurate feedback, the user concludes that their privacy is being compromised.
- Second stage accurate feedback is welcome—Once the user is aware of the privacy risk, and given that they did not abandon the device in the first usage period, they will probably not abandon the device due to privacy concerns later on. If users do not identify a risk, they will keep using the device.
Each of these propositions is both grounded analytically, and also intuitive to understand. However, applying the three of them in practice is not trivial. In future work we plan to apply these recommendations to a wearable device.
Author Contributions
Conceptualization, L.D. and A.J.; methodology, L.D. and A.J.; formal analysis, L.D. and A.J.; investigation, L.D. and A.J.; resources, L.D. and A.J.; writing—original draft preparation, L.D. and A.J.; writing—review and editing, L.D. and A.J.; project administration, L.D. and A.J. Both authors have read and agreed to the published version of the manuscript.
Funding
Lihi Dery was supported by the Ariel Cyber Innovation Center in conjunction with the Israel National Cyber Directorate in the Prime Minister’s Office. Artyom Jelnov was supported by the Heth Academic Center for research of competition and regulation.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Proposition 1.
Following signal h and event a, C’s belief that S is H is
Following signal h and event , C’s belief that S is H is
Following signal l and event a, C’s belief that S is H is
Following signal l and event , C’s belief that S is H is
Let be a signal received by C about S’s type, and be the event outcome of stage 1. C prefers not to leave at stage 2 iff
which is equivalent to
Let . Then the right-hand side of (A6) increases in and its maximum, obtained for , is
and the minimum (at ) is
Therefore, for , C prefers to leave at stage 2 for any . For , C prefers not to leave at stage 2 for any . If , there exists such that (A6) holds iff .
Proof of Proposition 2.
Suppose by contrary in equilibrium. By assumption , thus by continuity there is such that , and by (A2) and (A3), .
Let be the right-hand side of (A6) for given . For , decreases in . Therefore,
Proof of Proposition 3.
References
- Reeder, B.; David, A. Health at hand: A systematic review of smart watch uses for health and wellness. J. Biomed. Inform. 2016, 63, 269–276. [Google Scholar] [CrossRef] [PubMed]
- Tao, S.; Kudo, M.; Nonaka, H. Privacy-preserved behavior analysis and fall detection by an infrared ceiling sensor network. Sensors 2012, 12, 16920–16936. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Acquisti, A.; Taylor, C.; Wagman, L. The economics of privacy. J. Econ. Lit. 2016, 54, 442–492. [Google Scholar] [CrossRef] [Green Version]
- Spiegel, Y. Commercial software, adware, and consumer privacy. Int. J. Ind. Organ. 2013, 31, 702–713. [Google Scholar] [CrossRef]
- Munnia, A.; Nicotra, M.; Romano, M. Big Data, Predictive Marketing and Churn Management in the IoT Era. In The Internet of Things Entrepreneurial Ecosystems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 75–93. [Google Scholar]
- Chang, Y.; Wong, S.F.; Libaque-Saenz, C.F.; Lee, H. The role of privacy policy on consumers’ perceived privacy. Gov. Inf. Q. 2018, 35, 445–459. [Google Scholar] [CrossRef]
- Balapour, A.; Nikkhah, H.R.; Sabherwal, R. Mobile application security: Role of perceived privacy as the predictor of security perceptions. Int. J. Inf. Manag. 2020, 52, 102063. [Google Scholar] [CrossRef]
- Mutimukwe, C.; Kolkowska, E.; Grönlund, Å. Information privacy in e-service: Effect of organizational privacy assurances on individual privacy concerns, perceptions, trust and self-disclosure behavior. Gov. Inf. Q. 2020, 37, 101413. [Google Scholar] [CrossRef]
- Solove, D.J. Introduction: Privacy self-management and the consent dilemma. Harverd Law Rev. 2012, 126, 1880. [Google Scholar]
- Felt, A.P.; Chin, E.; Hanna, S.; Song, D.; Wagner, D. Android permissions demystified. In Proceedings of the 18th ACM conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; ACM: New York, NY, USA, 2011; pp. 627–638. [Google Scholar]
- Yan, H.; Li, X.; Wang, Y.; Jia, C. Centralized duplicate removal video storage system with privacy preservation in iot. Sensors 2018, 18, 1814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Acquisti, A.; Adjerid, I.; Balebako, R.; Brandimarte, L.; Cranor, L.F.; Komanduri, S.; Leon, P.G.; Sadeh, N.; Schaub, F.; Sleeper, M.; et al. Nudges for privacy and security: Understanding and assisting users’ choices online. ACM Comput. Surv. (CSUR) 2017, 50, 44. [Google Scholar] [CrossRef] [Green Version]
- Hamza, R.; Yan, Z.; Muhammad, K.; Bellavista, P.; Titouna, F. A privacy-preserving cryptosystem for IoT E-healthcare. Inf. Sci. 2020, 527, 493–510. [Google Scholar] [CrossRef]
- Kim, J.W.; Lim, J.H.; Moon, S.M.; Jang, B. Collecting health lifelog data from smartwatch users in a privacy-preserving manner. IEEE Trans. Consum. Electron. 2019, 65, 369–378. [Google Scholar] [CrossRef]
- Grgurić, A.; Mošmondor, M.; Huljenić, D. The SmartHabits: An intelligent privacy-aware home care assistance system. Sensors 2019, 19, 907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perez, A.J.; Zeadally, S.; Griffith, S.; Garcia, L.Y.M.; Mouloud, J.A. A User Study of a Wearable System to Enhance Bystanders’ Facial Privacy. IoT 2020, 1, 198–217. [Google Scholar] [CrossRef]
- Lowens, B.; Motti, V.G.; Caine, K. Wearable privacy: Skeletons in the data closet. In Proceedings of the 2017 IEEE International Conference on Healthcare Informatics (ICHI), Park City, UT, USA, 23–26 August 2017; IEEE: New York, NY, USA, 2017; pp. 295–304. [Google Scholar]
- John, L.K.; Acquisti, A.; Loewenstein, G. Strangers on a plane: Context-dependent willingness to divulge sensitive information. J. Consum. Res. 2011, 37, 858–873. [Google Scholar] [CrossRef]
- Aïmeur, E.; Lawani, O.; Dalkir, K. When changing the look of privacy policies affects user trust: An experimental study. Comput. Hum. Behav. 2016, 58, 368–379. [Google Scholar] [CrossRef]
- Kaupins, G.; Coco, M. Perceptions of internet-of-things surveillance by human resource managers. SAM Adv. Manag. J. 2017, 82, 53. [Google Scholar]
- Esmaeilzadeh, P. The Impacts of the Privacy Policy on Individual Trust in Health Information Exchanges (HIEs); Internet Research: Toulouse, France, 2020. [Google Scholar] [CrossRef]
- Hatamian, M.; Momen, N.; Fritsch, L.; Rannenberg, K. A multilateral privacy impact analysis method for android apps. In Annual Privacy Forum; Springer: Berlin/Heidelberg, Germany, 2019; pp. 87–106. [Google Scholar]
- Ernst, C.P.H.; Ernst, A.W. The Influence of Privacy Risk on Smartwatch Usage. Available online: https://www.frankfurt-university.de/fileadmin/standard/Hochschule/Fachbereich_3/Kontakt/Professor_inn_en/Ernst/Publikationen/The_Influence_of_Privacy_Risk_on_Smartwatch_Usage.pdf (accessed on 2 June 2021).
- Lee, J.M.; Rha, J.Y. Personalization–privacy paradox and consumer conflict with the use of location-based mobile commerce. Comput. Hum. Behav. 2016, 63, 453–462. [Google Scholar] [CrossRef]
- Kang, H.; Jung, E.H. The Smart Wearables-Privacy Paradox: A Cluster Analysis of Smartwatch Users. Available online: https://www.tandfonline.com/doi/abs/10.1080/0144929X.2020.1778787?journalCode=tbit20 (accessed on 2 June 2021).
- Dziuda, W.; Gradwohl, R. Achieving cooperation under privacy concerns. Am. Econ. J. Microeconomics 2015, 7, 142–173. [Google Scholar] [CrossRef] [Green Version]
- Jullien, B.; Lefouili, Y.; Riordan, M. Privacy Protection and Consumer Retention; Technical Report; Toulouse School of Economics (TSE): Toulouse, France, 2018. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).